
Programa
Fundamentos da IA
10 h
Os modelos de linguagem de grande porte (LLMs) estão revolucionando vários setores. De chatbots de atendimento ao cliente a sofisticadas ferramentas de análise de dados, os recursos dessa poderosa tecnologia estão remodelando o cenário da interação e automação digital.
No entanto, as aplicações práticas dos LLMs podem ser limitadas pela necessidade de computação de alta potência ou pela necessidade de tempos de resposta rápidos. Esses modelos normalmente exigem hardware sofisticado e dependências extensas, o que pode dificultar sua adoção em ambientes mais restritos.
É nesse ponto que o LLaMa.cpp (ou LLaMa C++) vem em seu socorro, oferecendo uma alternativa mais leve e portátil às estruturas mais pesadas.

Logotipo Llama.cpp(fonte)
O Llama.cpp foi desenvolvido por Georgi Gerganov. Ele implementa a arquitetura LLaMa do Meta em C/C++ eficiente e é uma das comunidades de código aberto mais dinâmicas em torno da inferência LLM, com mais de 900 colaboradores, mais de 69.000 estrelas no repositório oficial do GitHub e mais de 2.600 versões.
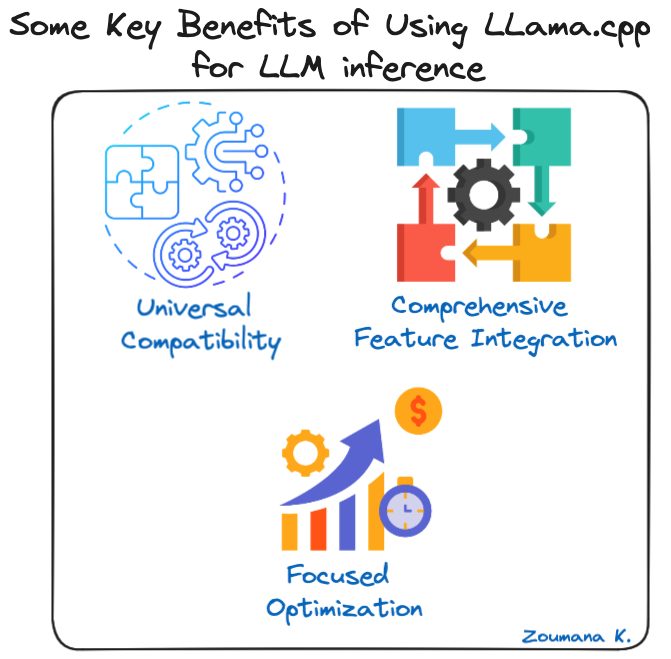
Algumas das principais vantagens de usar o LLama.cpp para inferência LLM
Com esse entendimento do Llama.cpp, as próximas seções deste tutorial abordam o processo de implementação de um caso de uso de geração de texto. Começamos explorando os fundamentos do LLama.cpp, compreendendo o fluxo de trabalho geral de ponta a ponta do projeto em questão e analisando algumas de suas aplicações em diferentes setores.
A espinha dorsal do Llama.cpp são os modelos originais do Llama, que também se baseiam na arquitetura do transformador. Os autores do Llama aproveitam vários aprimoramentos que foram propostos posteriormente e usaram modelos diferentes, como o PaLM.
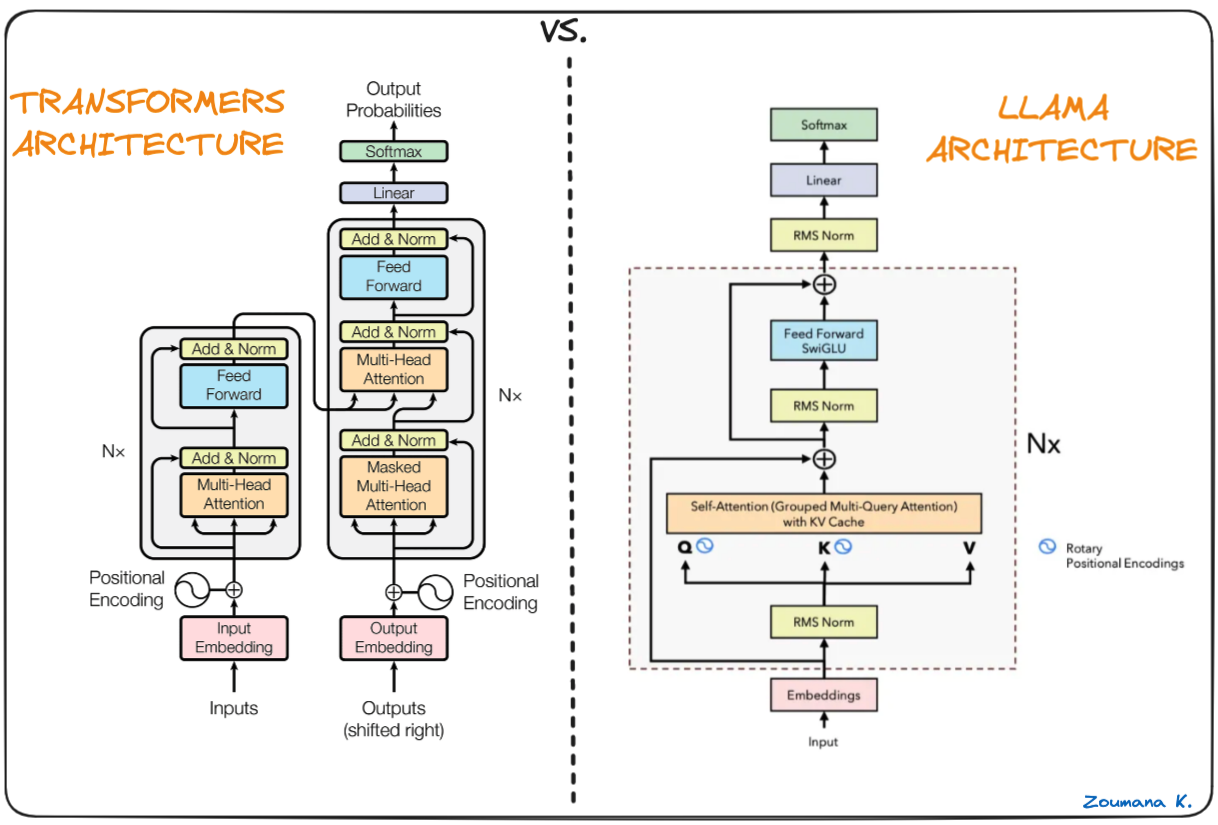
Diferença entre Transformers e arquitetura Llama (arquitetura Llama por Umar Jamil)
A principal diferença entre a arquitetura LLaMa e a dos transformadores:
Os pré-requisitos para você começar a trabalhar com o LLama.cpp incluem:
PythonVocê pode usar o pip para executar o pip, que é o gerenciador de pacotes PythonLlama-cpp-pythonVocê pode usar o Python binding para llama.cppRecomenda-se que você crie um ambiente virtual para evitar qualquer problema relacionado ao processo de instalação, e o conda pode ser um bom candidato para a criação do ambiente.
Todos os comandos desta seção são executados em um terminal. Usando a instrução conda create, criamos um ambiente virtual chamado llama-cpp-env.
conda create --name llama-cpp-envApós a criação bem-sucedida do ambiente virtual, ativamos o ambiente virtual acima usando a instrução conda activate, como segue:
conda activate llama-cpp-envA instrução acima deve exibir o nome da variável de ambiente entre colchetes no início do terminal, da seguinte forma:

Nome do ambiente virtual após a ativação
Agora, podemos instalar o pacote llama-cpp-python da seguinte forma:
pip install llama-cpp-python
or
pip install llama-cpp-python==0.1.48A execução bem-sucedida do site llama_cpp_script.py significa que a biblioteca está instalada corretamente.
Para garantir que a instalação seja bem-sucedida, vamos criar e adicionar a instrução import e, em seguida, executar o script.
from llama_cpp import Llama ao arquivo llama_cpp_script.py e, em seguida, adicione o endereço ao arquivo .llama_cpp_script.py para executar o arquivo. Se a biblioteca não for importada, será gerado um erro; portanto, você precisará de um diagnóstico adicional para o processo de instalação.Nesse estágio, o processo de instalação deve ser bem-sucedido. Vamos nos aprofundar na compreensão dos conceitos básicos do LLama.cpp.
A classe Llama importada acima é o principal construtor utilizado ao usar o Llama.cpp e recebe vários parâmetros, não se limitando aos que estão abaixo. A lista completa de parâmetros é fornecida na documentação oficial:
model_path: O caminho para o arquivo do modelo Llama que está sendo usadoprompt: O prompt de entrada para o modelo. Esse texto é tokenizado e passado para o modelo.device: O dispositivo a ser usado para executar o modelo Llama; esse dispositivo pode ser CPU ou GPU.max_tokens: O número máximo de tokens a serem gerados na resposta do modelostop: Uma lista de cadeias de caracteres que farão com que o processo de geração de modelos seja interrompidotemperature: Esse valor varia entre 0 e 1. Quanto mais baixo for o valor, mais determinístico será o resultado final. Por outro lado, um valor mais alto leva a mais aleatoriedade e, portanto, a um resultado mais diversificado e criativo.top_p: É usado para controlar a diversidade das previsões, o que significa que ele seleciona os tokens mais prováveis cuja probabilidade cumulativa excede um determinado limite. A partir de zero, um valor mais alto aumenta a chance de encontrar um resultado melhor, mas exige cálculos adicionais.echo: Um booleano usado para determinar se o modelo inclui o prompt original no início (True) ou não o inclui (False)Por exemplo, vamos considerar que queremos usar um modelo de linguagem grande chamado armazenado no diretório de trabalho atual. O processo de instanciação será parecido com o seguinte:
# Instanciate the model
my_aweseome_llama_model = Llama(model_path="./MY_AWESOME_MODEL")
prompt = "This is a prompt"
max_tokens = 100
temperature = 0.3
top_p = 0.1
echo = True
stop = ["Q", "\n"]
# Define the parameters
model_output = my_aweseome_llama_model(
prompt,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
echo=echo,
stop=stop,
)
final_result = model_output["choices"][0]["text"].strip()O código é autoexplicativo e pode ser facilmente compreendido a partir dos pontos iniciais que indicam o significado de cada parâmetro.
O resultado do modelo é um dicionário que contém a resposta gerada junto com alguns metadados adicionais. O formato da saída é explorado nas próximas seções do artigo.
Agora, é hora de começar a implementação do projeto de geração de texto. Para iniciar um novo projeto Llama.The cpp, você só precisa seguir o modelo de código Python acima, que explica todas as etapas, desde o carregamento do modelo de linguagem grande de interesse até a geração da resposta final.
O projeto utiliza a versão GGUF do Zephyr-7B-Beta da Hugging Face. É uma versão ajustada do mistralai/Mistral-7B-v0.1 que foi treinada em uma mistura de conjuntos de dados sintéticos disponíveis publicamente usando a otimização de preferência direta (DPO).
Em nossa Introdução ao uso de transformadores e do Hugging Face, você terá uma melhor compreensão dos transformadores e de como aproveitar seu poder para resolver problemas da vida real. Também temos um tutorial do Mistral 7B.
Modelo Zephyr da Hugging Face(fonte)
Depois que o modelo for baixado localmente, você poderá movê-lo para o local do projeto na pasta model. Antes de mergulhar na implementação, vamos entender a estrutura do projeto:

A estrutura do projeto
A primeira etapa é carregar o modelo usando o construtor Llama. Como esse é um modelo grande, é importante que você especifique o tamanho máximo do contexto do modelo a ser carregado. Neste projeto específico, usamos 512 tokens.
from llama_cpp import Llama
# GLOBAL VARIABLES
my_model_path = "./model/zephyr-7b-beta.Q4_0.gguf"
CONTEXT_SIZE = 512
# LOAD THE MODEL
zephyr_model = Llama(model_path=my_model_path,
n_ctx=CONTEXT_SIZE)Depois que o modelo é carregado, a próxima etapa é a fase de geração de texto, usando o modelo de código original, mas, em vez disso, usamos uma função auxiliar chamada generate_text_from_prompt.
def generate_text_from_prompt(user_prompt,
max_tokens = 100,
temperature = 0.3,
top_p = 0.1,
echo = True,
stop = ["Q", "\n"]):
# Define the parameters
model_output = zephyr_model(
user_prompt,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
echo=echo,
stop=stop,
)
return model_outputNa cláusula __main__, a função pode ser executada usando um determinado prompt.
if __name__ == "__main__":
my_prompt = "What do you think about the inclusion policies in Tech companies?"
zephyr_model_response = generate_text_from_prompt(my_prompt)
print(zephyr_model_response)A resposta do modelo é fornecida abaixo:

A resposta do modelo
A resposta gerada pelo modelo é e a resposta exata do modelo é destacada na caixa laranja.
Embora essa saída completa possa ser útil para uso posterior, talvez estejamos interessados apenas na resposta textual do modelo. Podemos formatar a resposta para obter esse resultado selecionando o campo “text” do elemento "choices” da seguinte forma:
final_result = model_output["choices"][0]["text"].strip()
A função strip() é usada para remover todos os espaços em branco à esquerda e à direita de uma cadeia de caracteres e o resultado é:
Tech companies want diverse workforces to build better products.Esta seção apresenta uma aplicação do LLama.cpp no mundo real e fornece o problema subjacente, a possível solução e os benefícios de usar o Llama.cpp.
Imagine a ETP4Africa, uma startup de tecnologia que precisa de um modelo de idioma que possa operar com eficiência em vários dispositivos para seu aplicativo educacional sem causar atrasos.
Eles implementam o Llama.cpp, aproveitando seu desempenho otimizado para CPU e a capacidade de interagir com seu backend baseado em Go.
A integração do Llama.cpp permite que o aplicativo ETP4Africa ofereça orientação de programação imediata e interativa, melhorando a experiência e o envolvimento do usuário.
A engenharia de dados é um componente essencial de qualquer projeto de ciência de dados e IA, e nosso tutorial Introdução ao LangChain para engenharia de dados e aplicativos de dados fornece um guia completo para incluir IA de grandes modelos de linguagem em pipelines e aplicativos de dados.
Em resumo, este artigo forneceu uma visão geral abrangente da configuração e utilização de modelos de linguagem grandes com o LLama.cpp.
Foram fornecidas instruções detalhadas para ajudar você a entender os conceitos básicos do Llama.cpp, configurar o ambiente de trabalho, instalar a biblioteca necessária e implementar um caso de uso de geração de texto (resposta a perguntas).
Por fim, foram fornecidos insights práticos sobre um aplicativo do mundo real e como o Llama.cpp pode ser usado para resolver o problema subjacente com eficiência.
Você está pronto para se aprofundar no mundo dos grandes modelos de linguagem? Aprimore suas habilidades com as poderosas estruturas de aprendizagem profunda LangChain e Pytorch usadas por profissionais de IA com nosso tutorial Como criar aplicativos LLM com LangChain e Como treinar um LLM com PyTorch.
Comece sua jornada de IA hoje mesmo!
Programa
Curso
Curso
blog
Abid Ali Awan
8 min
Tutorial
Josep Ferrer
Tutorial
Ryan Ong
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Moez Ali

