
Lernpfad
Grundlagen der KI
10 Std.
Große Sprachmodelle (LLMs) revolutionieren verschiedene Branchen. Von Chatbots für den Kundenservice bis hin zu ausgefeilten Datenanalysetools - die Möglichkeiten dieser leistungsstarken Technologie verändern die Landschaft der digitalen Interaktion und Automatisierung.
Praktische Anwendungen von LLMs können jedoch durch den Bedarf an leistungsstarken Computern oder die Notwendigkeit schneller Reaktionszeiten eingeschränkt sein. Diese Modelle erfordern in der Regel anspruchsvolle Hardware und umfangreiche Abhängigkeiten, was ihren Einsatz in begrenzteren Umgebungen erschweren kann.
An dieser Stelle kommt LLaMa.cpp (oder LLaMa C++) zur Hilfe und bietet eine leichtere, portablere Alternative zu den schwergewichtigen Frameworks.

Llama.cpp logo(Quelle)
Llama.cpp wurde von Georgi Gerganov entwickelt. Es implementiert die LLaMa-Architektur von Meta in effizientem C/C++ und ist eine der dynamischsten Open-Source-Communities rund um die LLM-Inferenz mit mehr als 900 Mitwirkenden, 69000+ Sternen im offiziellen GitHub-Repository und 2600+ Veröffentlichungen.
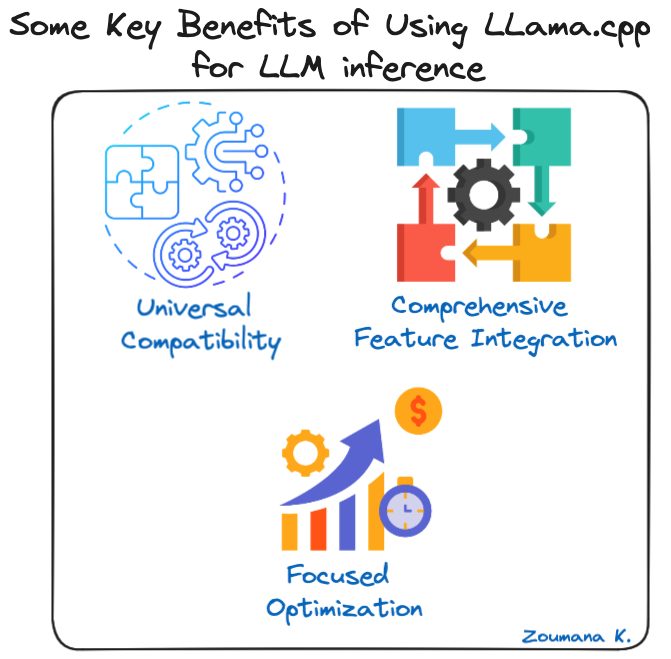
Einige wichtige Vorteile der Verwendung von LLama.cpp für LLM-Inferenz
Mit diesem Verständnis von Llama.cpp gehen wir in den nächsten Abschnitten dieses Tutorials durch die Implementierung eines Anwendungsfalls der Texterstellung. Wir beginnen damit, die Grundlagen von LLama.cpp zu erkunden, den gesamten Arbeitsablauf des vorliegenden Projekts zu verstehen und einige seiner Anwendungen in verschiedenen Branchen zu analysieren.
Das Rückgrat von Llama.cpp sind die ursprünglichen Llama-Modelle, die ebenfalls auf der Transformer-Architektur basieren. Die Autoren von Llama nutzen verschiedene Verbesserungen, die später vorgeschlagen wurden, und verwendeten verschiedene Modelle wie PaLM.
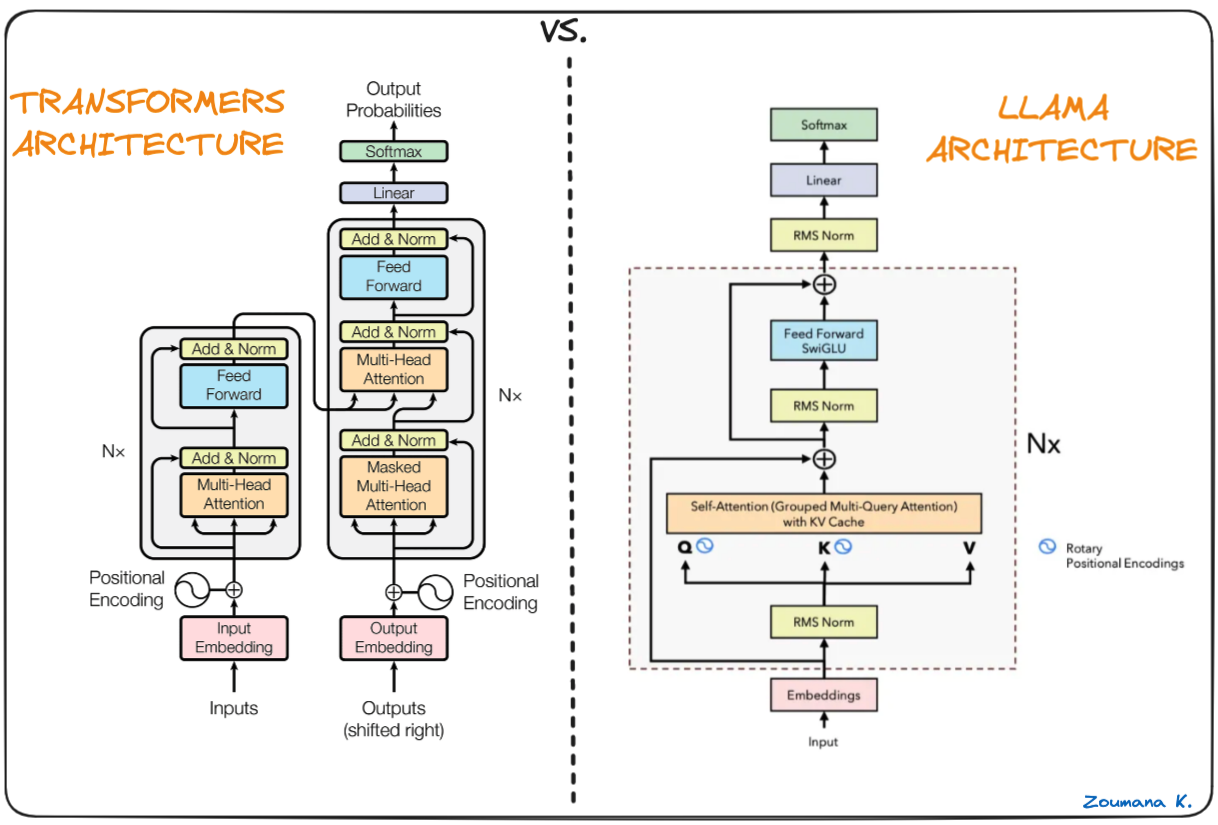
Der Unterschied zwischen Transformers und Llama-Architektur (Llama-Architektur von Umar Jamil)
Der Hauptunterschied zwischen der LLaMa-Architektur und der der Transformatoren:
Zu den Voraussetzungen für die Arbeit mit LLama.cpp gehören:
Python: um pip, den Python-Paketmanager, ausführen zu könnenLlama-cpp-python: die Python-Bindung für llama.cppEs wird empfohlen, eine virtuelle Umgebung zu erstellen, um Probleme bei der Installation zu vermeiden. conda ist ein guter Kandidat für die Erstellung einer solchen Umgebung.
Alle Befehle in diesem Abschnitt werden über ein Terminal ausgeführt. Mit der Anweisung conda create erstellen wir eine virtuelle Umgebung namens llama-cpp-env.
conda create --name llama-cpp-envNachdem wir die virtuelle Umgebung erfolgreich erstellt haben, aktivieren wir die oben genannte virtuelle Umgebung mit der Anweisung conda activate, wie folgt:
conda activate llama-cpp-envDie obige Anweisung sollte den Namen der Umgebungsvariablen zwischen Klammern am Anfang des Terminals wie folgt anzeigen:

Name der virtuellen Umgebung nach der Aktivierung
Jetzt können wir das Paket llama-cpp-python wie folgt installieren:
pip install llama-cpp-python
or
pip install llama-cpp-python==0.1.48Die erfolgreiche Ausführung von llama_cpp_script.py bedeutet, dass die Bibliothek korrekt installiert ist.
Um sicherzustellen, dass die Installation erfolgreich ist, erstellen wir die Anweisung import, fügen sie hinzu und führen das Skript aus.
from llama_cpp import Llama zur Datei llama_cpp_script.py hinzu, dannllama_cpp_script.py aus, um die Datei auszuführen. Wenn die Bibliothek nicht importiert werden kann, wird eine Fehlermeldung ausgegeben; daher ist eine weitere Diagnose für den Installationsprozess erforderlich.In diesem Stadium sollte der Installationsprozess erfolgreich sein. Lass uns die Grundlagen von LLama.cpp verstehen.
Die oben importierte Llama-Klasse ist der Hauptkonstruktor, der bei der Verwendung von Llama.cpp verwendet wird. Er nimmt mehrere Parameter entgegen und ist nicht auf die unten aufgeführten beschränkt. Die vollständige Liste der Parameter findest du in der offiziellen Dokumentation:
model_path: Der Pfad zu der verwendeten Llama-Modelldateiprompt: Die Eingabeaufforderung für das Modell. Dieser Text wird tokenisiert und an das Modell übergeben.device: Das Gerät, auf dem das Llama-Modell ausgeführt wird; dies kann entweder eine CPU oder eine GPU sein.max_tokens: Die maximale Anzahl von Token, die in der Antwort des Modells generiert werdenstop: Eine Liste von Zeichenketten, die dazu führen, dass der Modellerstellungsprozess gestoppt wirdtemperature: Dieser Wert liegt zwischen 0 und 1. Je niedriger der Wert, desto deterministischer ist das Endergebnis. Andererseits führt ein höherer Wert zu mehr Zufälligkeit und damit zu einem vielfältigeren und kreativeren Ergebnis.top_p: Wird verwendet, um die Vielfalt der Vorhersagen zu kontrollieren, d.h. es werden die wahrscheinlichsten Token ausgewählt, deren kumulative Wahrscheinlichkeit einen bestimmten Schwellenwert überschreitet. Ausgehend von Null erhöht ein höherer Wert die Chance, ein besseres Ergebnis zu finden, erfordert aber zusätzliche Berechnungen.echo: Ein Boolescher Wert, der bestimmt, ob das Modell die ursprüngliche Aufforderung am Anfang enthält (True) oder nicht (False).Nehmen wir zum Beispiel an, dass wir ein großes Sprachmodell namens verwenden wollen, das im aktuellen Arbeitsverzeichnis gespeichert ist. Der Instanzierungsprozess sieht folgendermaßen aus:
# Instanciate the model
my_aweseome_llama_model = Llama(model_path="./MY_AWESOME_MODEL")
prompt = "This is a prompt"
max_tokens = 100
temperature = 0.3
top_p = 0.1
echo = True
stop = ["Q", "\n"]
# Define the parameters
model_output = my_aweseome_llama_model(
prompt,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
echo=echo,
stop=stop,
)
final_result = model_output["choices"][0]["text"].strip()Der Code ist selbsterklärend und kann anhand der ersten Aufzählungspunkte, die die Bedeutung der einzelnen Parameter angeben, leicht verstanden werden.
Das Ergebnis des Modells ist ein Wörterbuch, das die generierte Antwort zusammen mit einigen zusätzlichen Metadaten enthält. Das Format der Ausgabe wird in den nächsten Abschnitten des Artikels erforscht.
Jetzt ist es an der Zeit, mit der Umsetzung des Texterstellungsprojekts zu beginnen. Wenn du ein neues Llama.cpp-Projekt startest, musst du nichts weiter tun, als der obigen Python-Codevorlage zu folgen, in der alle Schritte vom Laden des großen Sprachmodells, das dich interessiert, bis zur Erzeugung der endgültigen Antwort erklärt werden.
Das Projekt nutzt die GGUF-Version des Zephyr-7B-Beta von Hugging Face. Es ist eine fein abgestimmte Version von mistralai/Mistral-7B-v0.1, die auf einer Mischung aus öffentlich zugänglichen, synthetischen Datensätzen mit Hilfe von Direct Preference Optimization (DPO) trainiert wurde.
Unsere Einführung in die Nutzung von Transformers und Hugging Face vermittelt ein besseres Verständnis von Transformers und wie man ihre Kraft zur Lösung von Problemen im Alltag nutzen kann. Wir haben auch ein Mistral 7B-Tutorial.
Zephyr-Modell von Hugging Face(Quelle)
Sobald das Modell lokal heruntergeladen ist, können wir es in den Projektordner model verschieben. Bevor wir uns mit der Umsetzung beschäftigen, sollten wir die Projektstruktur verstehen:

Die Struktur des Projekts
Der erste Schritt besteht darin, das Modell mit dem Llama Konstruktor zu laden. Da es sich um ein großes Modell handelt, ist es wichtig, die maximale Kontextgröße des zu ladenden Modells anzugeben. In diesem speziellen Projekt verwenden wir 512 Token.
from llama_cpp import Llama
# GLOBAL VARIABLES
my_model_path = "./model/zephyr-7b-beta.Q4_0.gguf"
CONTEXT_SIZE = 512
# LOAD THE MODEL
zephyr_model = Llama(model_path=my_model_path,
n_ctx=CONTEXT_SIZE)Sobald das Modell geladen ist, ist der nächste Schritt die Phase der Texterzeugung, wobei wir die ursprüngliche Codevorlage verwenden, aber stattdessen eine Hilfsfunktion namens generate_text_from_prompt einsetzen.
def generate_text_from_prompt(user_prompt,
max_tokens = 100,
temperature = 0.3,
top_p = 0.1,
echo = True,
stop = ["Q", "\n"]):
# Define the parameters
model_output = zephyr_model(
user_prompt,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
echo=echo,
stop=stop,
)
return model_outputIn der __main__ Klausel kann die Funktion mit einer bestimmten Eingabeaufforderung ausgeführt werden.
if __name__ == "__main__":
my_prompt = "What do you think about the inclusion policies in Tech companies?"
zephyr_model_response = generate_text_from_prompt(my_prompt)
print(zephyr_model_response)Die Antwort des Modells findest du weiter unten:

Die Antwort des Modells
Die vom Modell erzeugte Reaktion ist und die genaue Reaktion des Modells ist in dem orangefarbenen Kasten hervorgehoben.
Auch wenn diese vollständige Ausgabe für die weitere Verwendung nützlich sein kann, sind wir vielleicht nur an der textlichen Antwort des Modells interessiert. Wir können die Antwort so formatieren, dass wir ein solches Ergebnis erhalten, indem wir das Feld “text” des Elements "choices” wie folgt auswählen:
final_result = model_output["choices"][0]["text"].strip()
Die Funktion strip() wird verwendet, um alle führenden und nachfolgenden Leerzeichen aus einer Zeichenkette zu entfernen, und das Ergebnis ist:
Tech companies want diverse workforces to build better products.Dieser Abschnitt geht durch eine reale Anwendung von LLama.cpp und zeigt das zugrunde liegende Problem, die mögliche Lösung und die Vorteile der Verwendung von Llama.cpp auf.
Stell dir vor, ETP4Africa, ein Tech-Startup, braucht für seine Bildungs-App ein Sprachmodell, das auf verschiedenen Geräten effizient funktioniert, ohne Verzögerungen zu verursachen.
Sie implementieren Llama.cpp und nutzen die Vorteile der CPU-optimierten Leistung und der Möglichkeit, eine Schnittstelle zu ihrem Go-basierten Backend herzustellen.
Durch die Integration von Llama.cpp bietet die ETP4Africa-App sofortige, interaktive Programmierungsanleitungen und verbessert so das Nutzererlebnis und das Engagement.
Data Engineering ist eine Schlüsselkomponente jedes Data Science- und KI-Projekts. Unser Tutorial Introduction to LangChain for Data Engineering & Data Applications bietet einen vollständigen Leitfaden für die Integration von KI aus großen Sprachmodellen in Datenpipelines und Anwendungen.
Zusammenfassend lässt sich sagen, dass dieser Artikel einen umfassenden Überblick über das Einrichten und Nutzen großer Sprachmodelle mit LLama.cpp gegeben hat.
Eine ausführliche Anleitung hilft dir, die Grundlagen von Llama.cpp zu verstehen, die Arbeitsumgebung einzurichten, die benötigte Bibliothek zu installieren und einen Anwendungsfall zur Texterzeugung (Fragenbeantwortung) zu implementieren.
Schließlich wurden praktische Einblicke in eine reale Anwendung gegeben und gezeigt, wie Llama.cpp verwendet werden kann, um das zugrunde liegende Problem effizient zu lösen.
Bist du bereit, tiefer in die Welt der großen Sprachmodelle einzutauchen? Verbessere deine Kenntnisse über die leistungsstarken Deep-Learning-Frameworks LangChain und Pytorch, die von KI-Profis verwendet werden, mit unserem Tutorial How to Build LLM Applications with LangChain und How to Train a LLM with PyTorch.
Beginne deine KI-Reise noch heute!
Lernpfad
Kurs
Kurs
Blog
Tutorial
Mark Pedigo
Tutorial
Javier Canales Luna
Tutorial
Matt Crabtree
Tutorial
Sejal Jaiswal
Tutorial
Sejal Jaiswal
