
Leerpad
AI-basisprincipes
10 Hr
Grote taalmodellen (LLM’s) veranderen talloze sectoren. Van klantenservice-chatbots tot geavanceerde data-analysetools: de mogelijkheden van deze krachtige technologie hertekenen het landschap van digitale interactie en automatisering.
Toch worden praktische toepassingen van LLM’s soms begrensd door de noodzaak van krachtige hardware of de eis van snelle reactietijden. Deze modellen hebben doorgaans geavanceerde hardware en veel dependencies nodig, wat hun adoptie in beperktere omgevingen lastig kan maken.
Daar komt LLaMa.cpp (of LLaMa C++) om de hoek kijken: een lichtere, draagbare alternatieve aanpak voor de zware frameworks.

Llama.cpp-logo (bron)
Llama.cpp is ontwikkeld door Georgi Gerganov. Het implementeert Meta’s LLaMa-architectuur in efficiënte C/C++ en is een van de meest dynamische open-sourcecommunity’s rondom LLM-inferentie, met meer dan 900 bijdragers, 69.000+ sterren op de officiële GitHub-repository en 2600+ releases.
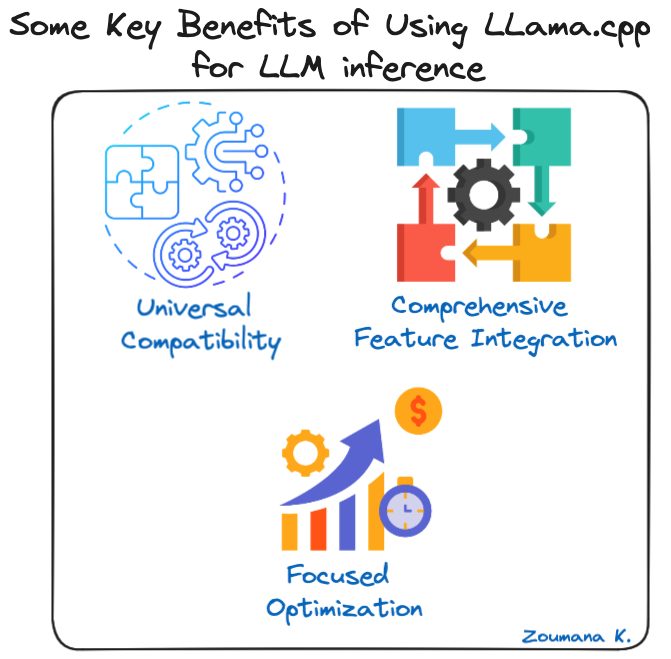
Enkele belangrijke voordelen van LLama.cpp voor LLM-inferentie
Met dit begrip van Llama.cpp doorlopen we in de volgende secties de implementatie van een tekstgeneratie-use-case. We beginnen met de basis van LLama.cpp, verkennen de end-to-end workflow van het project en bekijken enkele toepassingen in verschillende sectoren.
De ruggengraat van Llama.cpp zijn de oorspronkelijke Llama-modellen, die ook zijn gebaseerd op de transformerarchitectuur. De auteurs van Llama benutten verschillende verbeteringen die later zijn voorgesteld en gebruikt in andere modellen, zoals PaLM.
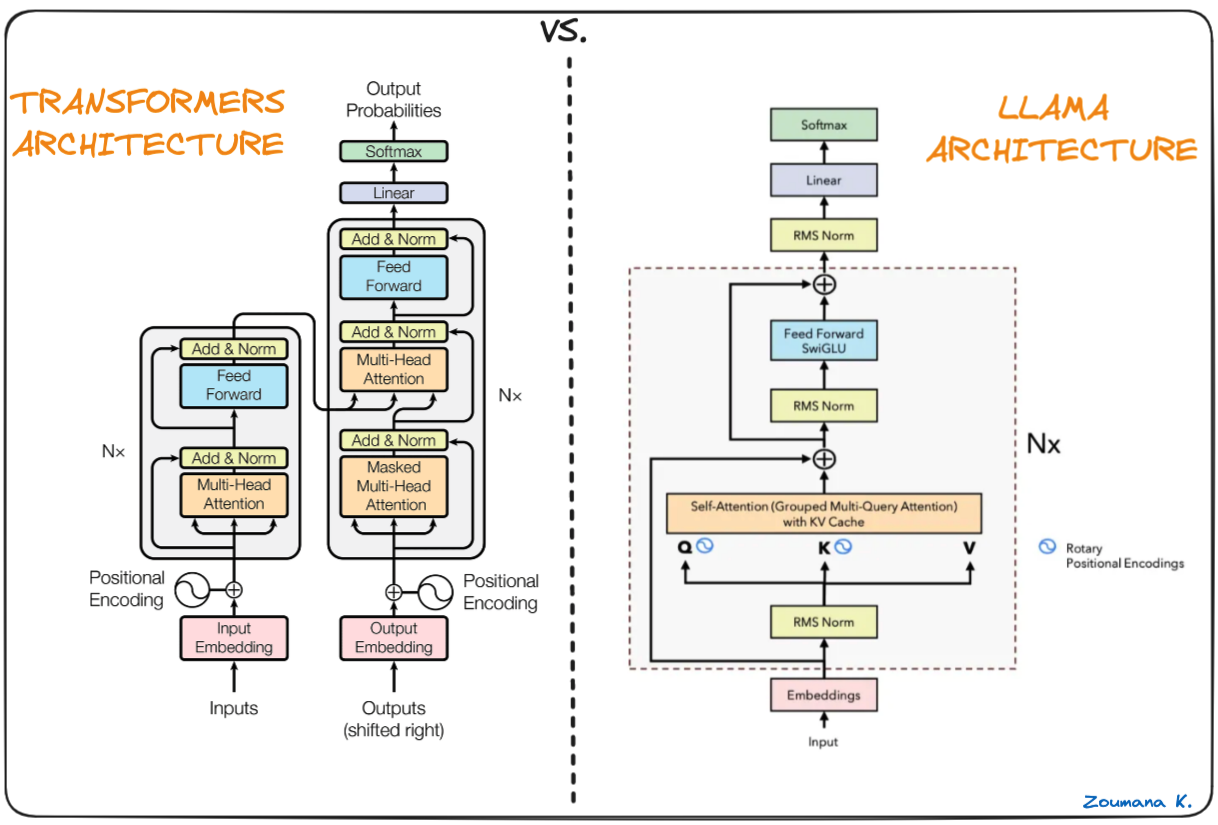
Verschil tussen Transformer en Llama-architectuur (Llama-architectuur door Umar Jamil)
Het belangrijkste verschil tussen de LLaMa-architectuur en die van transformers:
De vereisten om met LLama.cpp aan de slag te gaan, zijn onder meer:
Python: om pip te kunnen draaien, de Python-package managerLlama-cpp-python: de Python-binding voor llama.cppHet is aan te raden om een virtual environment te maken om gedoe bij de installatie te voorkomen; conda is een goede kandidaat om de omgeving te maken.
Alle commando’s in deze sectie voer je uit in een terminal. Met het statement conda create maken we een virtual environment met de naam llama-cpp-env.
conda create --name llama-cpp-envNa het succesvol aanmaken van de virtual environment activeren we deze met het statement conda activate, als volgt:
conda activate llama-cpp-envBovenstaande statement zou de naam van de environment tussen haakjes aan het begin van de terminal moeten tonen, zoals hier:

Naam van de virtual environment na activatie
Nu kunnen we het pakket llama-cpp-python installeren als volgt:
pip install llama-cpp-python
or
pip install llama-cpp-python==0.1.48Een succesvolle uitvoering van de llama_cpp_script.py betekent dat de bibliotheek correct is geïnstalleerd.
Om zeker te zijn dat de installatie is geslaagd, maken we een script en voegen we de import-regel toe, en voeren we het uit.
from llama_cpp import Llama toe aan het bestand llama_cpp_script.py, enllama_cpp_script.py uit. Als de import mislukt, verschijnt er een foutmelding en is nadere diagnose van het installatieproces nodig.Op dit punt zou de installatie gelukt moeten zijn. Laten we in de basis van LLama.cpp duiken.
De hierboven geïmporteerde klasse Llama is de belangrijkste constructor bij het gebruik van Llama.cpp. Die accepteert verschillende parameters, niet beperkt tot de onderstaande. De volledige lijst staat in de officiële documentatie:
model_path: Het pad naar het Llama-modellbestand dat je gebruiktprompt: De invoerprompt voor het model. Deze tekst wordt getokenized en aan het model doorgegeven.device: Het apparaat waarop het Llama-model draait; dit kan CPU of GPU zijn.max_tokens: Het maximumaantal tokens dat in de respons van het model wordt gegenereerdstop: Een lijst met strings die de modelgeneratie laten stoppentemperature: Deze waarde ligt tussen 0 en 1. Hoe lager de waarde, hoe deterministischer het eindresultaat. Een hogere waarde leidt juist tot meer willekeur en daarmee diversere en creatievere output.top_p: Regelt de diversiteit van de voorspellingen door de meest waarschijnlijke tokens te selecteren waarvan de cumulatieve kans een drempel overschrijdt. Vanaf nul verhoogt een hogere waarde de kans op een beter antwoord, maar vereist extra rekenwerk.echo: Een boolean die bepaalt of het model de oorspronkelijke prompt aan het begin opneemt (True) of niet (False)Stel bijvoorbeeld dat we een large language model willen gebruiken met de naam <MY_AWESOME_MODEL> dat in de huidige werkmap staat. De instantie ziet er dan zo uit:
# Instanciate the model
my_aweseome_llama_model = Llama(model_path="./MY_AWESOME_MODEL")
prompt = "This is a prompt"
max_tokens = 100
temperature = 0.3
top_p = 0.1
echo = True
stop = ["Q", "\n"]
# Define the parameters
model_output = my_aweseome_llama_model(
prompt,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
echo=echo,
stop=stop,
)
final_result = model_output["choices"][0]["text"].strip()De code spreekt grotendeels voor zich en is eenvoudig te begrijpen aan de hand van de bullets met de betekenis van elke parameter.
Het resultaat van het model is een dictionary met de gegenereerde respons en extra metadata. De structuur van de output bekijken we in de volgende secties van het artikel.
Tijd om te beginnen met de implementatie van het tekstgeneratieproject. Een nieuw Llama.cpp-project starten komt neer op het volgen van bovenstaand Python-sjabloon, dat alle stappen beschrijft van het laden van het gewenste taalmodel tot het genereren van de uiteindelijke respons.
Het project gebruikt de GGUF-versie van Zephyr-7B-Beta van Hugging Face. Het is een fijn-afgestemde versie van mistralai/Mistral-7B-v0.1 die is getraind op een mix van publiek beschikbare, synthetische datasets met behulp van Direct Preference Optimization (DPO).
Onze Introductie tot het gebruik van Transformers en Hugging Face biedt meer inzicht in Transformers en hoe je hun kracht benut om echte problemen op te lossen. We hebben ook een Mistral 7B-tutorial.
Zephyr-model van Hugging Face (bron)
Zodra het model lokaal is gedownload, kunnen we het naar de projectmap verplaatsen in de map model. Voordat we implementeren, eerst de projectstructuur:

De structuur van het project
De eerste stap is het laden van het model met de constructor Llama. Omdat dit een groot model is, is het belangrijk de maximale contextgrootte van het te laden model te specificeren. In dit project gebruiken we 512 tokens.
from llama_cpp import Llama
# GLOBAL VARIABLES
my_model_path = "./model/zephyr-7b-beta.Q4_0.gguf"
CONTEXT_SIZE = 512
# LOAD THE MODEL
zephyr_model = Llama(model_path=my_model_path,
n_ctx=CONTEXT_SIZE)Zodra het model is geladen, volgt de fase van tekstgeneratie. We gebruiken hetzelfde sjabloon, maar dan via een hulpfunctie met de naam generate_text_from_prompt.
def generate_text_from_prompt(user_prompt,
max_tokens = 100,
temperature = 0.3,
top_p = 0.1,
echo = True,
stop = ["Q", "\n"]):
# Define the parameters
model_output = zephyr_model(
user_prompt,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
echo=echo,
stop=stop,
)
return model_outputBinnen de __main__-clausule kun je de functie uitvoeren met een gegeven prompt.
if __name__ == "__main__":
my_prompt = "What do you think about the inclusion policies in Tech companies?"
zephyr_model_response = generate_text_from_prompt(my_prompt)
print(zephyr_model_response)De respons van het model staat hieronder:

De respons van het model
De door het model gegenereerde respons is <What do you think about the inclusion policies in Tech companies?> en de exacte reactie van het model is gemarkeerd in het oranje kader.
Hoewel deze volledige output nuttig kan zijn voor verder gebruik, zijn we soms alleen geïnteresseerd in de tekstuele respons van het model. We kunnen de respons formatteren door het veld “text” van het element “choices” te selecteren, als volgt:
final_result = model_output["choices"][0]["text"].strip()
De functie strip() verwijdert eventuele spaties aan het begin en einde van een string en het resultaat is:
Tech companies want diverse workforces to build better products.In deze sectie lopen we door een praktijkvoorbeeld van LLama.cpp en beschrijven we het onderliggende probleem, de mogelijke oplossing en de voordelen van Llama.cpp.
Stel: ETP4Africa, een tech-startup, heeft voor hun educatieve app een taalmodel nodig dat op verschillende apparaten efficient kan draaien zonder vertraging te veroorzaken.
Ze implementeren Llama.cpp en profiteren van de geoptimaliseerde CPU-prestaties en de mogelijkheid om te koppelen aan hun Go-gebaseerde backend.
Dankzij de integratie van Llama.cpp kan de ETP4Africa-app directe, interactieve programmeerbegeleiding bieden, wat de gebruikerservaring en betrokkenheid verbetert.
Data engineering is een sleutelelement van elk data science- en AI-project. Onze tutorial Introductie tot LangChain voor data engineering en data-applicaties biedt een complete gids om AI uit large language models in datapijplijnen en toepassingen op te nemen.
Samengevat bood dit artikel een compleet overzicht van het opzetten en gebruiken van large language models met LLama.cpp.
We gaven gedetailleerde instructies om je te helpen de basis van Llama.cpp te begrijpen, de werkomgeving in te richten, de benodigde bibliotheek te installeren en een tekstgeneratie- (vraag-antwoord-) use-case te implementeren.
Tot slot gaven we praktische inzichten voor een toepassing in de echte wereld en hoe Llama.cpp efficiënt kan worden ingezet om het onderliggende probleem aan te pakken.
Klaar om dieper te duiken in de wereld van large language models? Versterk je skills met de krachtige deep-learningframeworks LangChain en PyTorch die AI-professionals gebruiken met onze tutorial How to Build LLM Applications with LangChain en How to Train a LLM with PyTorch.
Begin vandaag aan je AI-reis!
Leerpad
Cursus
Cursus
blog
Adel Nehme
15 min
