
Cursus
Principes fondamentaux de l'IA
10 h
Les grands modèles de langage (LLM) sont en train de révolutionner divers secteurs d'activité. Des chatbots de service à la clientèle aux outils d'analyse de données sophistiqués, les capacités de cette puissante technologie redessinent le paysage de l'interaction numérique et de l'automatisation.
Cependant, les applications pratiques des LLM peuvent être limitées par la nécessité de disposer d'une puissance de calcul élevée ou de temps de réponse rapides. Ces modèles nécessitent généralement du matériel sophistiqué et des dépendances importantes, ce qui peut rendre difficile leur adoption dans des environnements plus contraignants.
C'est là que LLaMa.cpp (ou LLaMa C++) vient à la rescousse, en fournissant une alternative plus légère et plus portable aux frameworks lourds.

Logo Llama.cpp(source)
Llama.cpp a été développé par Georgi Gerganov. Il implémente l'architecture LLaMa de Meta en C/C++ efficace, et c'est l'une des communautés open-source les plus dynamiques autour de l'inférence LLM avec plus de 900 contributeurs, plus de 69000 étoiles sur le dépôt officiel GitHub, et plus de 2600 versions.
Quelques avantages clés de l'utilisation de LLama.cpp pour l'inférence LLM
Avec cette compréhension de Llama.cpp, les sections suivantes de ce tutoriel passent en revue le processus de mise en œuvre d'un cas d'utilisation de génération de texte. Nous commençons par explorer les bases de LLama.cpp, en comprenant le déroulement global du projet et en analysant certaines de ses applications dans différentes industries.
L'épine dorsale de Llama.cpp est le modèle original de Llama, qui est également basé sur l'architecture des transformateurs. Les auteurs de Llama tirent parti de diverses améliorations qui ont été proposées par la suite et utilisent différents modèles tels que PaLM.
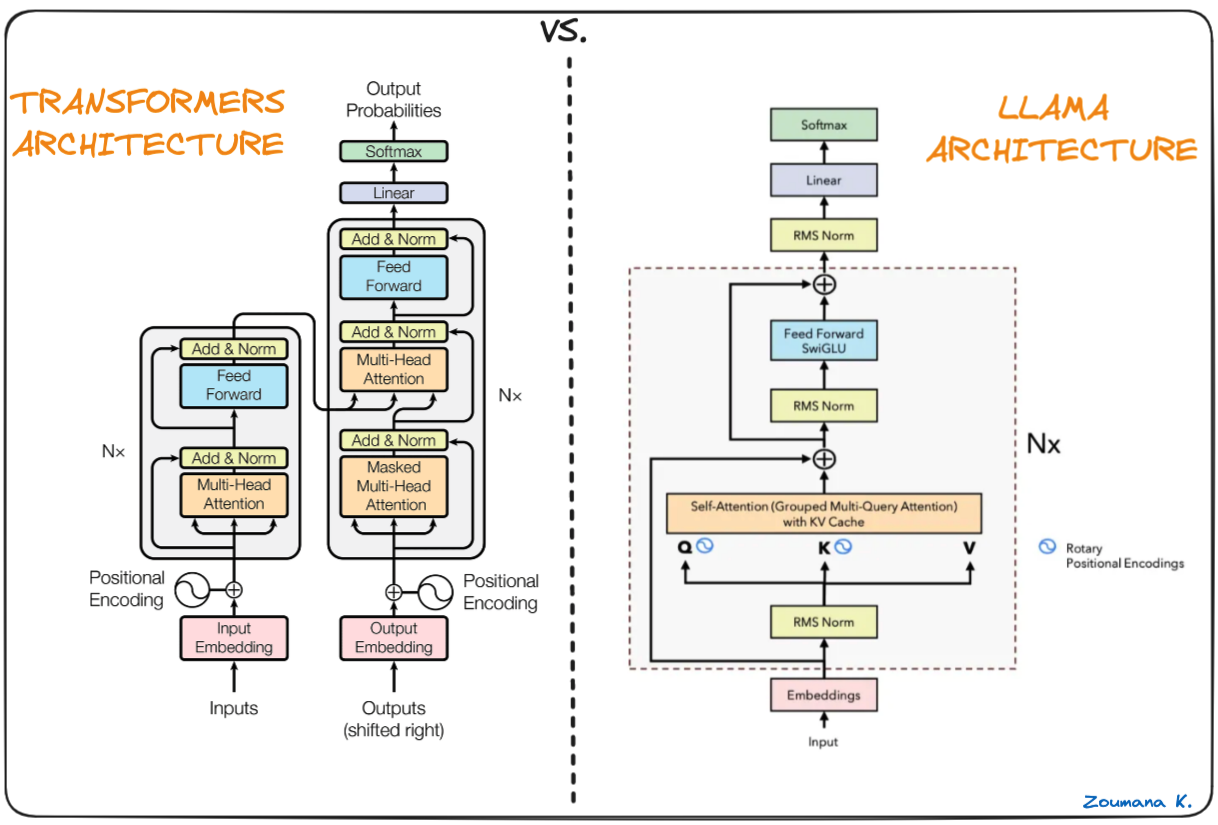
Différence entre les transformateurs et l'architecture des lamas (Architecture des lamas par Umar Jamil)
La principale différence entre l'architecture LLaMa et celle des transformateurs :
Les conditions préalables pour commencer à travailler avec LLama.cpp sont les suivantes :
PythonPour les autres pays de l'Union européenne, vous pouvez utiliser le logiciel pip, qui est le gestionnaire de paquets de Python.Llama-cpp-python: le binding Python pour llama.cppIl est recommandé de créer un environnement virtuel pour éviter tout problème lié au processus d'installation, et conda peut être un bon candidat pour la création de l'environnement.
Toutes les commandes de cette section sont exécutées à partir d'un terminal. En utilisant l'instruction conda create, nous créons un environnement virtuel appelé llama-cpp-env.
conda create --name llama-cpp-envAprès avoir créé avec succès l'environnement virtuel, nous l'activons à l'aide de l'instruction conda activate, comme suit :
conda activate llama-cpp-envL'instruction ci-dessus doit afficher le nom de la variable d'environnement entre parenthèses au début du terminal, comme suit :

Nom de l'environnement virtuel après activation
Nous pouvons maintenant installer le paquetage llama-cpp-python comme suit :
pip install llama-cpp-python
or
pip install llama-cpp-python==0.1.48L'exécution réussie du site llama_cpp_script.py signifie que la bibliothèque est correctement installée.
Pour nous assurer que l'installation est réussie, créons et ajoutons la déclaration import, puis exécutons le script.
from llama_cpp import Llama au fichier llama_cpp_script.py, puisllama_cpp_script.py pour exécuter le fichier. Si la bibliothèque ne parvient pas à être importée, une erreur est générée ; elle nécessite donc un diagnostic plus approfondi pour le processus d'installation.À ce stade, le processus d'installation devrait avoir réussi. Commençons par comprendre les bases de LLama.cpp.
La classe Llama importée ci-dessus est le constructeur principal utilisé lors de l'utilisation de Llama.cpp, et elle prend plusieurs paramètres qui ne sont pas limités aux suivants. La liste complète des paramètres est fournie dans la documentation officielle :
model_path: Le chemin d'accès au fichier du modèle Llama utiliséprompt: L'invite d'entrée du modèle. Ce texte est symbolisé et transmis au modèle.device: Le dispositif à utiliser pour exécuter le modèle Llama ; il peut s'agir d'un processeur ou d'un processeur graphique.max_tokens: Le nombre maximum de jetons à générer dans la réponse du modèle.stop: Une liste de chaînes de caractères qui entraîneront l'arrêt du processus de génération du modèle.temperature: Cette valeur est comprise entre 0 et 1. Plus la valeur est faible, plus le résultat final est déterministe. D'autre part, une valeur plus élevée conduit à plus d'aléatoire, et donc à une production plus diversifiée et plus créative.top_p: Est utilisé pour contrôler la diversité des prédictions, ce qui signifie qu'il sélectionne les tokens les plus probables dont la probabilité cumulée dépasse un seuil donné. En partant de zéro, une valeur plus élevée augmente les chances de trouver un meilleur résultat, mais nécessite des calculs supplémentaires.echo: Un booléen utilisé pour déterminer si le modèle inclut l'invite originale au début (True) ou ne l'inclut pas (False).Par exemple, considérons que nous voulons utiliser un grand modèle linguistique appelé stocké dans le répertoire de travail actuel. Le processus d'instanciation se déroule comme suit :
# Instanciate the model
my_aweseome_llama_model = Llama(model_path="./MY_AWESOME_MODEL")
prompt = "This is a prompt"
max_tokens = 100
temperature = 0.3
top_p = 0.1
echo = True
stop = ["Q", "\n"]
# Define the parameters
model_output = my_aweseome_llama_model(
prompt,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
echo=echo,
stop=stop,
)
final_result = model_output["choices"][0]["text"].strip()Le code est explicite et peut être facilement compris à partir des points initiaux indiquant la signification de chaque paramètre.
Le résultat du modèle est un dictionnaire contenant la réponse générée ainsi que quelques métadonnées supplémentaires. Le format de sortie est étudié dans les sections suivantes de l'article.
Il est maintenant temps de commencer à mettre en œuvre le projet de génération de texte. Démarrer un nouveau projet Llama.The cpp n'a rien d'autre à faire que de suivre le modèle de code Python ci-dessus, qui explique toutes les étapes depuis le chargement du grand modèle de langage d'intérêt jusqu'à la génération de la réponse finale.
Le projet s'appuie sur la version GGUF du Zephyr-7B-Beta de Hugging Face. Il s'agit d'une version affinée de mistralai/Mistral-7B-v0.1 qui a été entraînée sur un ensemble d'ensembles de données synthétiques accessibles au public à l'aide de l'optimisation directe des préférences (DPO).
Notre introduction à l'utilisation des transformateurs et de Hugging Face permet de mieux comprendre les transformateurs et d'exploiter leur puissance pour résoudre des problèmes de la vie réelle. Nous avons également un tutoriel sur le Mistral 7B.
Modèle Zephyr de Hugging Face(source)
Une fois le modèle téléchargé localement, nous pouvons le déplacer vers l'emplacement du projet dans le dossier model. Avant de plonger dans la mise en œuvre, il convient de comprendre la structure du projet :

La structure du projet
La première étape consiste à charger le modèle à l'aide du constructeur Llama. Comme il s'agit d'un modèle de grande taille, il est important de spécifier la taille maximale du contexte du modèle à charger. Dans ce projet spécifique, nous utilisons 512 jetons.
from llama_cpp import Llama
# GLOBAL VARIABLES
my_model_path = "./model/zephyr-7b-beta.Q4_0.gguf"
CONTEXT_SIZE = 512
# LOAD THE MODEL
zephyr_model = Llama(model_path=my_model_path,
n_ctx=CONTEXT_SIZE)Une fois le modèle chargé, l'étape suivante est la phase de génération du texte, en utilisant le modèle de code original, mais nous utilisons une fonction d'aide appelée generate_text_from_prompt.
def generate_text_from_prompt(user_prompt,
max_tokens = 100,
temperature = 0.3,
top_p = 0.1,
echo = True,
stop = ["Q", "\n"]):
# Define the parameters
model_output = zephyr_model(
user_prompt,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
echo=echo,
stop=stop,
)
return model_outputDans la clause __main__, la fonction peut être exécutée à l'aide d'une invite donnée.
if __name__ == "__main__":
my_prompt = "What do you think about the inclusion policies in Tech companies?"
zephyr_model_response = generate_text_from_prompt(my_prompt)
print(zephyr_model_response)La réponse du modèle est fournie ci-dessous :

La réponse du modèle
La réponse générée par le modèle est et la réponse exacte du modèle est mise en évidence dans la boîte orange.
Même si cette sortie complète peut être utile pour une utilisation ultérieure, il se peut que nous ne soyons intéressés que par la réponse textuelle du modèle. Nous pouvons formater la réponse pour obtenir un tel résultat en sélectionnant le champ “text” de l'élément "choices” " comme suit :
final_result = model_output["choices"][0]["text"].strip()
La fonction strip() est utilisée pour supprimer les espaces blancs de début et de fin d'une chaîne de caractères et le résultat est le suivant :
Tech companies want diverse workforces to build better products.Cette section présente une application réelle de LLama.cpp et fournit le problème sous-jacent, la solution possible et les avantages de l'utilisation de Llama.cpp.
Imaginez ETP4Africa, une startup technologique qui a besoin d'un modèle linguistique capable de fonctionner efficacement sur différents appareils pour son application éducative, sans causer de retards.
Ils implémentent Llama.cpp, profitant de ses performances optimisées pour le processeur et de sa capacité à s'interfacer avec leur backend basé sur Go.
L'intégration de Llama.cpp permet à l'application ETP4Africa d'offrir des conseils de programmation immédiats et interactifs, améliorant ainsi l'expérience et l'engagement de l'utilisateur.
L'ingénierie des données est un élément clé de tout projet de science des données et d'IA, et notre tutoriel Introduction à LangChain pour l'ingénierie des données et les applications de données fournit un guide complet pour inclure l'IA à partir de grands modèles de langage dans les pipelines de données et les applications.
En résumé, cet article a fourni une vue d'ensemble complète de la configuration et de l'utilisation de grands modèles de langage avec LLama.cpp.
Des instructions détaillées ont été fournies pour vous aider à comprendre les bases de Llama.cpp, à mettre en place l'environnement de travail, à installer la bibliothèque requise et à mettre en œuvre un cas d'utilisation de génération de texte (question-réponse).
Enfin, des aperçus pratiques ont été fournis pour une application réelle et la manière dont Llama.cpp peut être utilisé pour résoudre efficacement le problème sous-jacent.
Prêt à plonger plus profondément dans le monde des grands modèles linguistiques ? Améliorez vos compétences avec les puissants frameworks d'apprentissage profond LangChain et Pytorch utilisés par les professionnels de l'IA grâce à nos tutoriels Comment construire des applications LLM avec LangChain et Comment former un LLM avec PyTorch.
Commencez dès aujourd'hui votre voyage dans l'IA !
Cursus
Cours
Cours
blog
Kurtis Pykes
9 min
Tutoriel
Tutoriel
Mark Pedigo
Tutoriel
Satyabrata Pal
Tutoriel
Matt Crabtree
Tutoriel
Adel Nehme
