
Tracks
Cơ bản về Trí tuệ Nhân tạo
10 giờ
Các mô hình ngôn ngữ lớn (LLM) đang tạo ra cuộc cách mạng trong nhiều ngành. Từ chatbot chăm sóc khách hàng đến công cụ phân tích dữ liệu tinh vi, năng lực của công nghệ mạnh mẽ này đang định hình lại bối cảnh tương tác số và tự động hóa.
Tuy nhiên, việc ứng dụng LLM vào thực tiễn có thể bị hạn chế bởi nhu cầu tính toán hiệu năng cao hoặc yêu cầu thời gian phản hồi nhanh. Các mô hình này thường đòi hỏi phần cứng tinh vi và nhiều phụ thuộc, khiến việc áp dụng trong môi trường hạn chế trở nên khó khăn.
Đó là lúc LLaMa.cpp (hay LLaMa C++) xuất hiện như cứu tinh, mang lại một lựa chọn nhẹ và linh hoạt hơn so với các nền tảng nặng nề.

Logo Llama.cpp (nguồn)
Llama.cpp được phát triển bởi Georgi Gerganov. Nó hiện thực kiến trúc LLaMa của Meta bằng C/C++ hiệu quả, và là một trong những cộng đồng mã nguồn mở năng động nhất quanh suy luận LLM, với hơn 900 cộng tác viên, 69.000+ sao trên kho GitHub chính thức và 2.600+ bản phát hành.
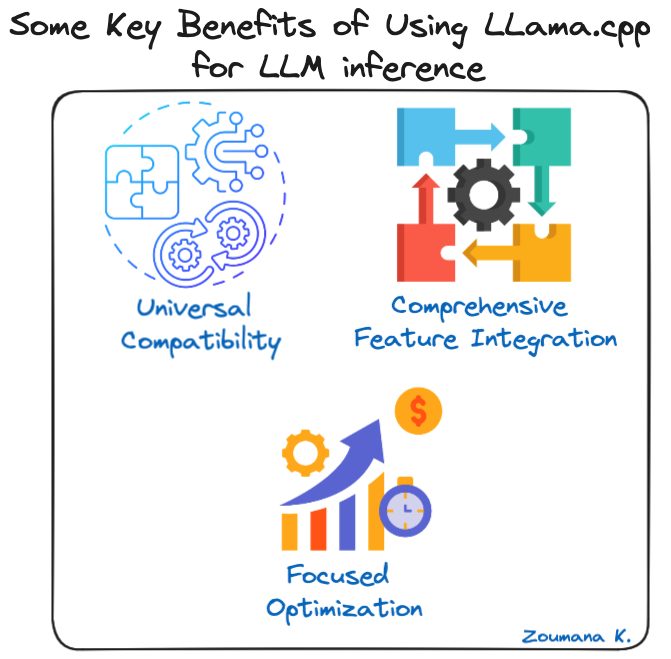
Một số lợi ích chính khi dùng LLama.cpp cho suy luận LLM
Với hiểu biết này về Llama.cpp, các phần tiếp theo của bài hướng dẫn sẽ đi qua quy trình hiện thực một trường hợp tạo văn bản. Chúng ta bắt đầu bằng việc khám phá những điều cơ bản về LLama.cpp, hiểu quy trình end-to-end tổng thể của dự án và phân tích một số ứng dụng của nó trong các ngành khác nhau.
Xương sống của Llama.cpp là các mô hình Llama gốc, vốn cũng dựa trên kiến trúc transformer. Các tác giả của Llama tận dụng nhiều cải tiến được đề xuất sau này và dùng trong các mô hình khác như PaLM.
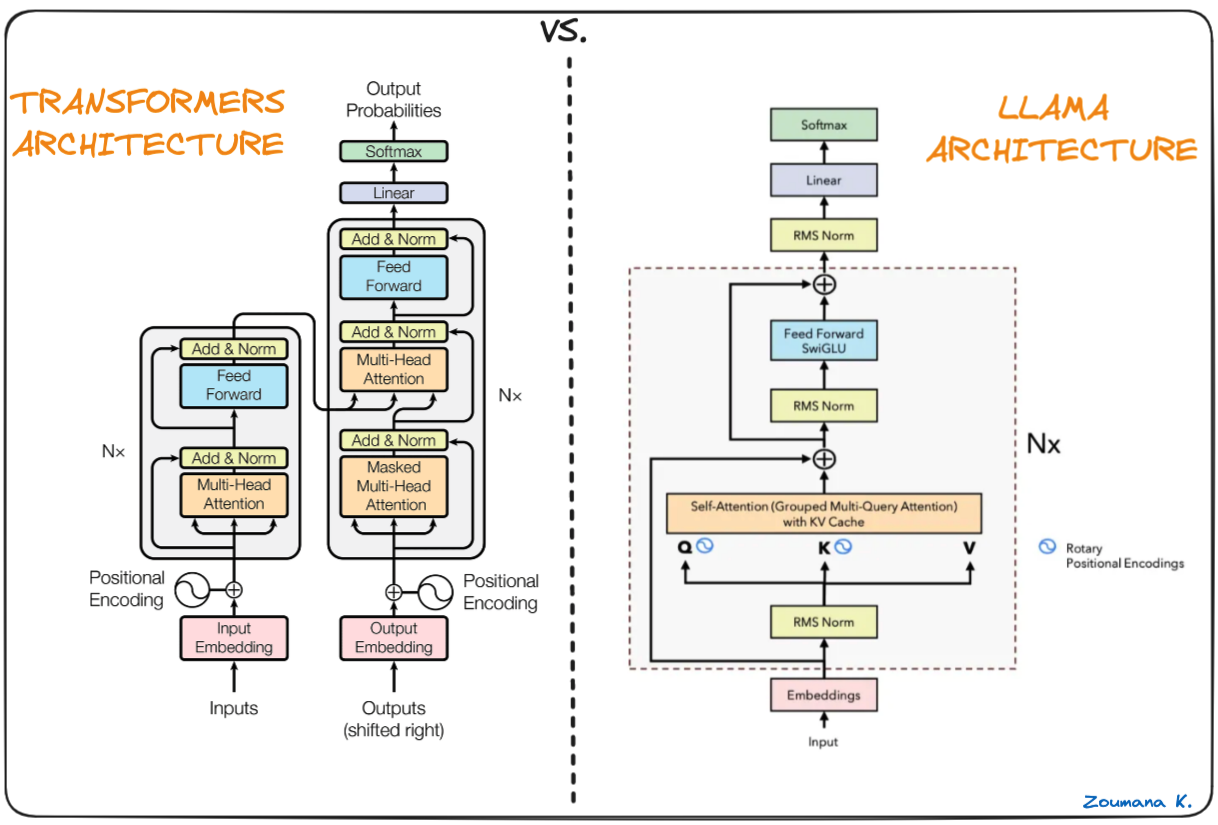
Khác biệt giữa Transformers và kiến trúc Llama (kiến trúc Llama bởi Umar Jamil)
Một số khác biệt chính giữa kiến trúc LLaMa và transformer:
Các điều kiện tiên quyết để bắt đầu làm việc với LLama.cpp gồm:
Python: để có thể chạy pip, trình quản lý gói của PythonLlama-cpp-python: binding Python cho llama.cppKhuyến nghị tạo môi trường ảo để tránh rắc rối liên quan đến cài đặt, và conda là một lựa chọn tốt để tạo môi trường.
Tất cả lệnh trong phần này được chạy từ terminal. Dùng câu lệnh conda create, chúng ta tạo môi trường ảo tên llama-cpp-env.
conda create --name llama-cpp-envSau khi tạo môi trường ảo thành công, chúng ta kích hoạt môi trường trên bằng câu lệnh conda activate như sau:
conda activate llama-cpp-envCâu lệnh trên sẽ hiển thị tên biến môi trường trong ngoặc ở đầu dòng lệnh như sau:

Tên môi trường ảo sau khi kích hoạt
Giờ chúng ta có thể cài gói llama-cpp-python như sau:
pip install llama-cpp-python
or
pip install llama-cpp-python==0.1.48Việc chạy thành công llama_cpp_script.py có nghĩa là thư viện đã được cài đặt đúng.
Để chắc chắn cài đặt thành công, hãy tạo và thêm câu lệnh import, rồi chạy script.
from llama_cpp import Llama vào file llama_cpp_script.py, sau đóllama_cpp_script.py để thực thi file. Nếu thư viện không import được, sẽ có lỗi; khi đó cần chẩn đoán thêm quá trình cài đặt.Ở giai đoạn này, quá trình cài đặt lẽ ra đã thành công. Hãy cùng tìm hiểu những điều cơ bản của LLama.cpp.
Lớp Llama đã import ở trên là bộ khởi tạo chính khi dùng Llama.cpp; nó nhận nhiều tham số, không chỉ giới hạn ở các tham số dưới đây. Danh sách đầy đủ có trong tài liệu chính thức:
model_path: Đường dẫn tới file mô hình Llama được sử dụngprompt: Prompt đầu vào cho mô hình. Văn bản này sẽ được token hóa và đưa vào mô hình.device: Thiết bị dùng để chạy mô hình Llama; có thể là CPU hoặc GPU.max_tokens: Số token tối đa được tạo trong phản hồi của mô hìnhstop: Danh sách chuỗi khiến quá trình sinh của mô hình dừng lạitemperature: Giá trị trong khoảng 0 đến 1. Giá trị càng thấp, kết quả càng mang tính xác định. Ngược lại, giá trị cao tạo nhiều ngẫu nhiên hơn, vì thế đầu ra đa dạng và sáng tạo hơn.top_p: Dùng để kiểm soát độ đa dạng của dự đoán, tức chọn các token có xác suất cao nhất sao cho tổng xác suất vượt ngưỡng cho trước. Bắt đầu từ 0, giá trị cao hơn tăng cơ hội tìm đầu ra tốt hơn nhưng cần thêm tính toán.echo: Boolean quyết định mô hình có bao gồm prompt gốc ở đầu (True) hay không (False)Ví dụ, giả sử chúng ta muốn dùng một mô hình ngôn ngữ lớn tên <MY_AWESOME_MODEL> lưu tại thư mục làm việc hiện tại. Quá trình khởi tạo sẽ như sau:
# Instanciate the model
my_aweseome_llama_model = Llama(model_path="./MY_AWESOME_MODEL")
prompt = "This is a prompt"
max_tokens = 100
temperature = 0.3
top_p = 0.1
echo = True
stop = ["Q", "\n"]
# Define the parameters
model_output = my_aweseome_llama_model(
prompt,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
echo=echo,
stop=stop,
)
final_result = model_output["choices"][0]["text"].strip()Đoạn mã trên khá tự minh họa và có thể hiểu dễ dàng dựa trên các gạch đầu dòng ban đầu giải thích ý nghĩa từng tham số.
Kết quả của mô hình là một dictionary chứa phản hồi sinh ra cùng một số metadata bổ sung. Định dạng đầu ra sẽ được khám phá ở các phần tiếp theo.
Giờ là lúc bắt tay vào triển khai dự án tạo văn bản. Bắt đầu một dự án Llama.cpp không có gì hơn ngoài việc theo mẫu mã Python ở trên, mẫu này giải thích toàn bộ các bước từ tải mô hình ngôn ngữ lớn quan tâm đến việc tạo phản hồi cuối cùng.
Dự án sử dụng phiên bản GGUF của Zephyr-7B-Beta từ Hugging Face. Đây là phiên bản fine-tune của mistralai/Mistral-7B-v0.1 được huấn luyện trên tập hợp dữ liệu tổng hợp, công khai bằng Direct Preference Optimization (DPO).
Bài Giới thiệu về Transformers và Hugging Face của chúng tôi giúp bạn hiểu rõ hơn về Transformers và cách khai thác sức mạnh của chúng để giải quyết bài toán thực tế. Chúng tôi cũng có hướng dẫn Mistral 7B.
Mô hình Zephyr từ Hugging Face (nguồn)
Sau khi tải mô hình về máy, chúng ta có thể chuyển nó vào vị trí dự án trong thư mục model. Trước khi đi vào triển khai, hãy hiểu cấu trúc dự án:

Cấu trúc của dự án
Bước đầu tiên là tải mô hình bằng bộ khởi tạo Llama. Vì đây là mô hình lớn, cần chỉ định kích thước ngữ cảnh tối đa của mô hình khi tải. Trong dự án này, chúng ta dùng 512 token.
from llama_cpp import Llama
# GLOBAL VARIABLES
my_model_path = "./model/zephyr-7b-beta.Q4_0.gguf"
CONTEXT_SIZE = 512
# LOAD THE MODEL
zephyr_model = Llama(model_path=my_model_path,
n_ctx=CONTEXT_SIZE)Sau khi mô hình được tải, bước tiếp theo là giai đoạn tạo văn bản, sử dụng mẫu mã gốc, nhưng chúng ta dùng một hàm trợ giúp tên generate_text_from_prompt.
def generate_text_from_prompt(user_prompt,
max_tokens = 100,
temperature = 0.3,
top_p = 0.1,
echo = True,
stop = ["Q", "\n"]):
# Define the parameters
model_output = zephyr_model(
user_prompt,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
echo=echo,
stop=stop,
)
return model_outputTrong mệnh đề __main__, hàm có thể được thực thi với một prompt nhất định.
if __name__ == "__main__":
my_prompt = "What do you think about the inclusion policies in Tech companies?"
zephyr_model_response = generate_text_from_prompt(my_prompt)
print(zephyr_model_response)Phản hồi của mô hình được cung cấp dưới đây:

Phản hồi của mô hình
Phản hồi được mô hình sinh ra là <What do you think about the inclusion policies in Tech companies?> và phần trả lời chính xác của mô hình được đánh dấu trong khung màu cam.
Mặc dù đầu ra đầy đủ này hữu ích cho các mục đích khác, đôi khi chúng ta chỉ quan tâm đến phần văn bản phản hồi của mô hình. Ta có thể định dạng phản hồi để lấy kết quả đó bằng cách chọn trường “text” của phần tử “choices” như sau:
final_result = model_output["choices"][0]["text"].strip()
Hàm strip() dùng để loại bỏ khoảng trắng ở đầu và cuối chuỗi, và kết quả là:
Tech companies want diverse workforces to build better products.Phần này đi qua một ứng dụng thực tế của LLama.cpp và nêu vấn đề cốt lõi, giải pháp có thể có, cùng lợi ích khi dùng Llama.cpp.
Hãy hình dung ETP4Africa, một startup công nghệ cần một mô hình ngôn ngữ có thể vận hành hiệu quả trên nhiều thiết bị cho ứng dụng giáo dục của họ mà không gây chậm trễ.
Họ triển khai Llama.cpp, tận dụng hiệu năng tối ưu cho CPU và khả năng giao tiếp với backend viết bằng Go.
Việc tích hợp Llama.cpp giúp ứng dụng ETP4Africa mang đến hướng dẫn lập trình tương tác tức thì, cải thiện trải nghiệm và mức độ gắn kết của người dùng.
Kỹ thuật dữ liệu là thành phần then chốt của mọi dự án Khoa học dữ liệu và AI, và hướng dẫn Giới thiệu LangChain cho Kỹ thuật dữ liệu & Ứng dụng dữ liệu của chúng tôi cung cấp cẩm nang đầy đủ để đưa AI từ các mô hình ngôn ngữ lớn vào pipeline và ứng dụng dữ liệu.
Tóm lại, bài viết đã cung cấp cái nhìn tổng quan toàn diện về việc thiết lập và sử dụng các mô hình ngôn ngữ lớn với LLama.cpp.
Hướng dẫn chi tiết đã được đưa ra để giúp bạn hiểu các cơ bản của Llama.cpp, thiết lập môi trường làm việc, cài đặt thư viện cần thiết và triển khai một trường hợp tạo văn bản (hỏi đáp).
Cuối cùng, các góc nhìn thực tiễn đã được trình bày cho một ứng dụng thực tế và cách Llama.cpp có thể được dùng để giải quyết hiệu quả vấn đề nền tảng.
Sẵn sàng đi sâu hơn vào thế giới các mô hình ngôn ngữ lớn? Nâng cao kỹ năng với các framework học sâu mạnh mẽ LangChain và Pytorch được các chuyên gia AI sử dụng qua hướng dẫn Cách xây dựng ứng dụng LLM với LangChain và Cách huấn luyện LLM với PyTorch.
Bắt đầu hành trình AI của bạn ngay hôm nay!
Tracks
Courses
Courses