
Program
AI Temelleri
10 sa
Büyük dil modelleri (LLM'ler) birçok sektörde devrim yaratıyor. Müşteri hizmetleri sohbet botlarından sofistike veri analizi araçlarına kadar, bu güçlü teknolojinin yetenekleri dijital etkileşim ve otomasyon alanını yeniden şekillendiriyor.
Ancak LLM'lerin pratik uygulamaları, yüksek güçlü hesaplamaya duyulan ihtiyaç veya hızlı yanıt süreleri gerekliliği nedeniyle sınırlı olabilir. Bu modeller genellikle karmaşık donanım ve kapsamlı bağımlılıklar gerektirir; bu da daha kısıtlı ortamlarda benimsenmelerini zorlaştırabilir.
İşte burada LLaMa.cpp (veya LLaMa C++) imdada yetişiyor ve ağır çerçevelere kıyasla daha hafif, daha taşınabilir bir alternatif sunuyor.

Llama.cpp logosu (kaynak)
Llama.cpp, Georgi Gerganov tarafından geliştirildi. Meta'nın LLaMa mimarisini verimli C/C++ ile uygular ve LLM çıkarımı alanındaki en dinamik açık kaynak topluluklarından biridir; resmi GitHub deposunda 900'den fazla katkıcı, 69.000+ yıldız ve 2600+ sürüm bulunmaktadır.
LLama.cpp kullanarak LLM çıkarımının bazı temel faydaları
Bu Llama.cpp anlayışıyla, bu eğitimin sonraki bölümleri bir metin üretimi kullanım senaryosunun uygulanması sürecini adım adım ele alır. LLama.cpp temellerini keşfederek başlıyor, eldeki projenin uçtan uca iş akışını anlıyor ve farklı sektörlerdeki bazı uygulamalarını inceliyoruz.
Llama.cpp'nin belkemiği, dönüştürücü (transformer) mimarisine dayanan orijinal Llama modelleridir. Llama yazarları, sonrasında önerilen çeşitli iyileştirmelerden yararlanmış ve PaLM gibi farklı modellerde kullanılan yaklaşımları benimsemiştir.
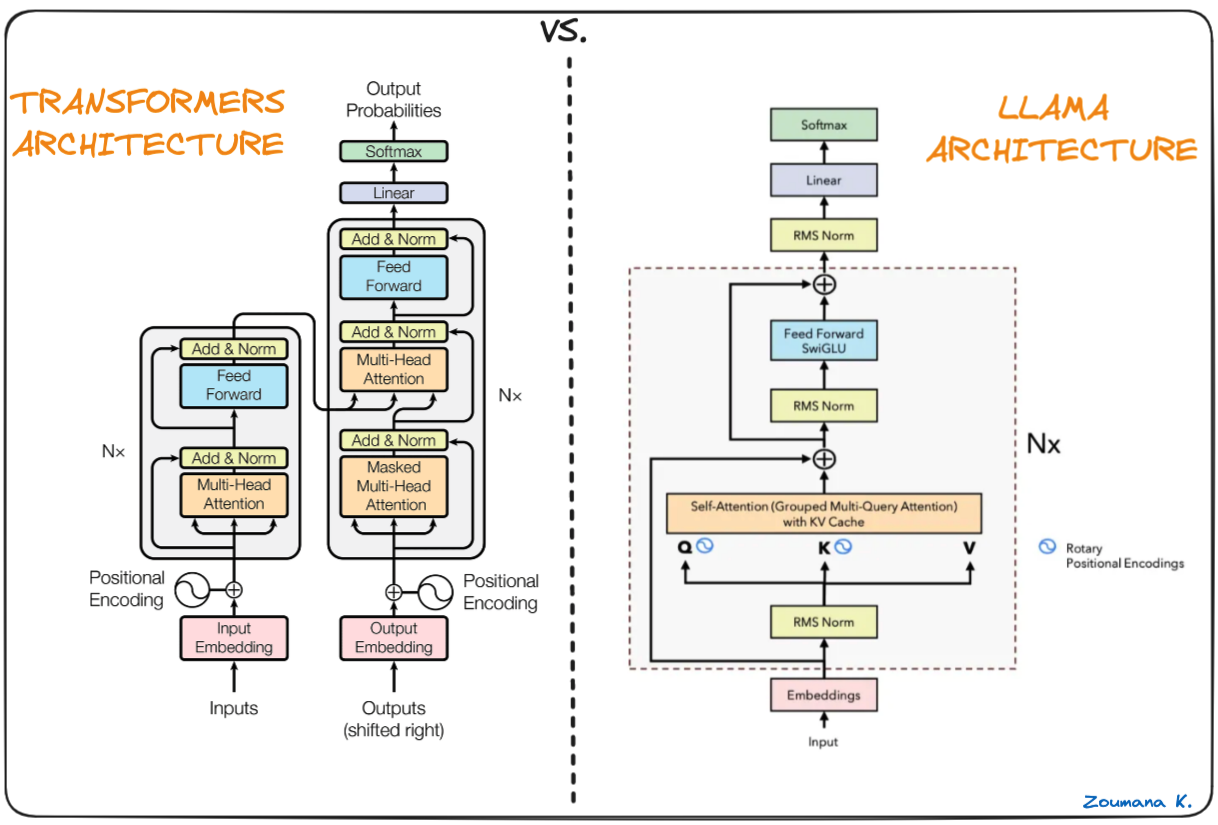
Transformer ve Llama mimarisi arasındaki fark (Llama mimarisi: Umar Jamil)
LLaMa mimarisi ile transformer'lar arasındaki başlıca farklar:
LLama.cpp ile çalışmaya başlamak için gereken ön koşullar şunlardır:
Python: Python paket yöneticisi pip'i çalıştırabilmek içinLlama-cpp-python: llama.cpp için Python bağlayıcısıKurulum sürecine ilişkin sorunları önlemek için bir sanal ortam oluşturulması önerilir; bu amaçla conda iyi bir adaydır.
Bu bölümdeki tüm komutlar bir terminalden çalıştırılır. conda create ifadesini kullanarak llama-cpp-env adlı bir sanal ortam oluşturuyoruz.
conda create --name llama-cpp-envSanal ortam başarıyla oluşturulduktan sonra, aşağıdaki gibi conda activate ifadesini kullanarak bu sanal ortamı etkinleştiriyoruz:
conda activate llama-cpp-envYukarıdaki ifade, terminalin başında köşeli parantezler içinde ortam değişkeninin adını aşağıdaki gibi göstermelidir:

Etkinleştirmeden sonra sanal ortamın adı
Artık llama-cpp-python paketini aşağıdaki gibi kurabiliriz:
pip install llama-cpp-python
or
pip install llama-cpp-python==0.1.48llama_cpp_script.py dosyasının başarıyla çalıştırılması, kitaplığın doğru şekilde kurulduğu anlamına gelir.
Kurulumun başarılı olduğundan emin olmak için bir import ifadesi oluşturalım ve ardından betiği çalıştıralım.
from llama_cpp import Llama ifadesini llama_cpp_script.py dosyasına ekleyin, ardındanllama_cpp_script.py dosyasını çalıştırın. Kitaplık içe aktarılamazsa bir hata oluşur; bu durumda kurulum sürecinin daha ayrıntılı incelenmesi gerekir.Bu aşamada kurulum sürecinin başarılı olması gerekir. Şimdi LLama.cpp'nin temellerini anlamaya dalalım.
Yukarıda içe aktarılan Llama sınıfı, Llama.cpp kullanılırken başvurulan ana kurucudur ve birkaç parametre alır; aşağıdakilerle sınırlı değildir. Parametrelerin tam listesi resmi belgelerde verilmiştir:
model_path: Kullanılan Llama model dosyasının yoluprompt: Modele verilecek giriş istemi. Bu metin belirteçlere ayrılır ve modele iletilir.device: Llama modelini çalıştırmak için kullanılacak aygıt; CPU veya GPU olabilir.max_tokens: Modelin yanıtında üretilecek azami belirteç sayısıstop: Modelin üretim sürecini durduracak dizelerin listesitemperature: 0 ile 1 arasında bir değerdir. Değer ne kadar düşükse sonuç o kadar belirleyicidir. Öte yandan, daha yüksek bir değer daha fazla rastgelelik ve dolayısıyla daha çeşitli ve yaratıcı çıktı sağlar.top_p: Tahminlerin çeşitliliğini kontrol etmek için kullanılır; kümülatif olasılığı belirli bir eşiği aşan en olası belirteçleri seçer. Sıfırdan başlayarak, daha yüksek bir değer daha iyi bir çıktı bulma şansını artırır ancak ek hesaplama gerektirir.echo: Modelin orijinal istemi başta dahil edip etmeyeceğini (True) veya etmeyeceğini (False) belirlemek için kullanılan bir booleanÖrneğin, geçerli çalışma dizininde depolanan <MY_AWESOME_MODEL> adlı bir büyük dil modelini kullanmak istediğimizi düşünelim. Örnekleme işlemi şu şekilde olacaktır:
# Instanciate the model
my_aweseome_llama_model = Llama(model_path="./MY_AWESOME_MODEL")
prompt = "This is a prompt"
max_tokens = 100
temperature = 0.3
top_p = 0.1
echo = True
stop = ["Q", "\n"]
# Define the parameters
model_output = my_aweseome_llama_model(
prompt,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
echo=echo,
stop=stop,
)
final_result = model_output["choices"][0]["text"].strip()Kod kendini açıklar niteliktedir ve her bir parametrenin anlamını belirten ilk madde işaretlerinden kolayca anlaşılabilir.
Modelin sonucu, üretilen yanıtı ve bazı ek üst verileri içeren bir sözlüktür. Çıktının formatı, makalenin sonraki bölümlerinde incelenmektedir.
Artık metin üretim projesinin uygulanmasına başlama zamanı. Yeni bir Llama.cpp projesine başlamak, ilgi duyulan büyük dil modelini yüklemekten nihai yanıtı üretmeye kadar tüm adımları açıklayan yukarıdaki Python kod şablonunu izlemekten ibarettir.
Proje, Hugging Face kaynağındaki Zephyr-7B-Beta'nın GGUF sürümünden yararlanır. Bu model, mistralai/Mistral-7B-v0.1'in, Direct Preference Optimization (DPO) kullanılarak kamuya açık, sentetik veri kümelerinin bir karışımı üzerinde ince ayar yapılmış bir sürümüdür.
Transformers ve Hugging Face Kullanımına Giriş yazımız, Transformers hakkında daha iyi bir kavrayış ve gerçek hayattaki problemleri çözmek için güçlerinden nasıl yararlanılacağını sunar. Ayrıca bir Mistral 7B eğitimi de hazırladık.
Hugging Face'ten Zephyr modeli (kaynak)
Model yerel olarak indirildikten sonra, proje konumundaki model klasörüne taşıyabiliriz. Uygulamaya dalmadan önce, projenin yapısını anlayalım:

Projenin yapısı
İlk adım, Llama kurucusunu kullanarak modeli yüklemektir. Bu büyük bir model olduğundan, yüklenecek modelin azami bağlam boyutunu belirtmek önemlidir. Bu özel projede 512 belirteç kullanıyoruz.
from llama_cpp import Llama
# GLOBAL VARIABLES
my_model_path = "./model/zephyr-7b-beta.Q4_0.gguf"
CONTEXT_SIZE = 512
# LOAD THE MODEL
zephyr_model = Llama(model_path=my_model_path,
n_ctx=CONTEXT_SIZE)Model yüklendikten sonra, sonraki adım özgün kod şablonunu kullanarak metin üretimi aşamasıdır; ancak bunun yerine generate_text_from_prompt adlı bir yardımcı işlev kullanıyoruz.
def generate_text_from_prompt(user_prompt,
max_tokens = 100,
temperature = 0.3,
top_p = 0.1,
echo = True,
stop = ["Q", "\n"]):
# Define the parameters
model_output = zephyr_model(
user_prompt,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
echo=echo,
stop=stop,
)
return model_output__main__ koşulu içinde, işlev belirli bir istemle çalıştırılabilir.
if __name__ == "__main__":
my_prompt = "What do you think about the inclusion policies in Tech companies?"
zephyr_model_response = generate_text_from_prompt(my_prompt)
print(zephyr_model_response)Model yanıtı aşağıda verilmiştir:

Modelin yanıtı
Model tarafından üretilen yanıt <What do you think about the inclusion policies in Tech companies?> olup, modelin tam yanıtı turuncu kutuda vurgulanmıştır.
Bu tam çıktı, sonraki kullanım için faydalı olsa da, yalnızca modelin metinsel yanıtıyla ilgileniyor olabiliriz. Yanıtı, aşağıdaki gibi “choices” öğesinin “text” alanını seçerek bu sonucu elde edecek şekilde biçimlendirebiliriz:
final_result = model_output["choices"][0]["text"].strip()
strip() işlevi, bir dizgenin başındaki ve sonundaki boşlukları kaldırmak için kullanılır ve sonuç şudur:
Tech companies want diverse workforces to build better products.Bu bölüm, LLama.cpp'nin gerçek dünyadaki bir uygulamasını ele alır ve altta yatan problemi, olası çözümü ve Llama.cpp kullanmanın faydalarını sunar.
ETP4Africa adlı, eğitim uygulamaları için çeşitli cihazlarda verimli şekilde çalışabilen ve gecikmeye neden olmayan bir dil modeline ihtiyaç duyan bir teknoloji girişimini hayal edin.
CPU'ya optimize edilmiş performansından ve Go tabanlı arka uçlarıyla arayüz oluşturabilme yeteneğinden yararlanarak Llama.cpp'yi uygularlar.
Llama.cpp entegrasyonu, ETP4Africa uygulamasının anında, etkileşimli programlama rehberliği sunmasına olanak tanıyarak kullanıcı deneyimini ve etkileşimini artırır.
Veri Mühendisliği, herhangi bir Veri Bilimi ve Yapay Zekâ projesinin temel bir bileşenidir ve Veri Mühendisliği ve Veri Uygulamaları için LangChain'e Giriş eğitimiz, büyük dil modellerinden gelen yapay zekâyı veri hatlarına ve uygulamalara dahil etmek için kapsamlı bir rehber sunar.
Özetle, bu makale LLama.cpp ile büyük dil modellerinin kurulumu ve kullanımı hakkında kapsamlı bir genel bakış sundu.
Llama.cpp'nin temellerini anlamanıza, çalışma ortamını kurmanıza, gerekli kitaplığı yüklemenize ve bir metin üretimi (soru-cevap) kullanım senaryosunu uygulamanıza yardımcı olacak ayrıntılı talimatlar verildi.
Son olarak, gerçek bir uygulama için pratik içgörüler ve Llama.cpp'nin altta yatan problemi verimli bir şekilde nasıl ele alabileceği aktarıldı.
Daha büyük dil modelleri dünyasına daha derinlemesine dalmaya hazır mısınız? Yapay zekâ profesyonellerinin kullandığı güçlü derin öğrenme çerçeveleri LangChain ve Pytorch ile becerilerinizi geliştirin: LangChain ile LLM Uygulamaları Nasıl Geliştirilir eğitimi ve PyTorch ile Bir LLM Nasıl Eğitilir.
Yapay Zekâ Yolculuğunuza Bugün Başlayın!
Program
Kurs
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Kurtis Pykes
Eğitim
Adel Nehme
