
Programma
Nozioni di base sull'intelligenza artificiale
10 h
I large language model (LLM) stanno rivoluzionando vari settori. Dai chatbot per l'assistenza clienti agli strumenti avanzati di analisi dei dati, le capacità di questa potente tecnologia stanno ridefinendo il panorama dell'interazione digitale e dell'automazione.
Tuttavia, le applicazioni pratiche degli LLM possono essere limitate dalla necessità di un'elevata potenza di calcolo o di tempi di risposta rapidi. Questi modelli richiedono in genere hardware sofisticato e numerose dipendenze, il che può renderne difficile l'adozione in ambienti più vincolati.
È qui che entra in gioco LLaMa.cpp (o LLaMa C++), offrendo un'alternativa più leggera e portatile ai framework più pesanti.

Logo di Llama.cpp (fonte)
Llama.cpp è stato sviluppato da Georgi Gerganov. Implementa l'architettura LLaMa di Meta in C/C++ efficiente ed è una delle community open source più dinamiche attorno all'inferenza LLM, con oltre 900 contributor, più di 69.000 stelle sul repository GitHub ufficiale e oltre 2600 release.
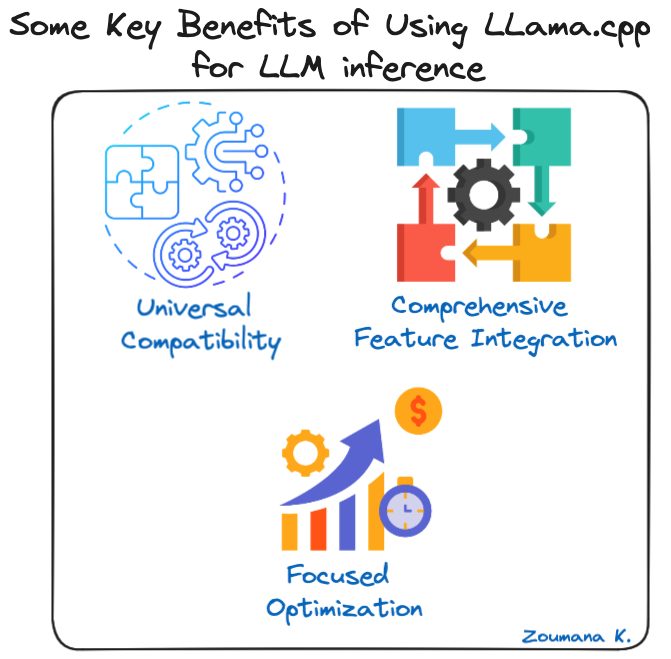
Alcuni vantaggi chiave dell'uso di LLama.cpp per l'inferenza LLM
Con questa panoramica di Llama.cpp, le prossime sezioni del tutorial illustrano il processo di implementazione di un caso d'uso di generazione di testo. Partiamo esplorando le basi di LLama.cpp, comprendendo il flusso di lavoro end-to-end del progetto e analizzando alcune applicazioni in settori diversi.
La spina dorsale di Llama.cpp sono i modelli Llama originali, anch'essi basati sull'architettura transformer. Gli autori di Llama sfruttano varie migliorie proposte successivamente e utilizzate in modelli diversi come PaLM.
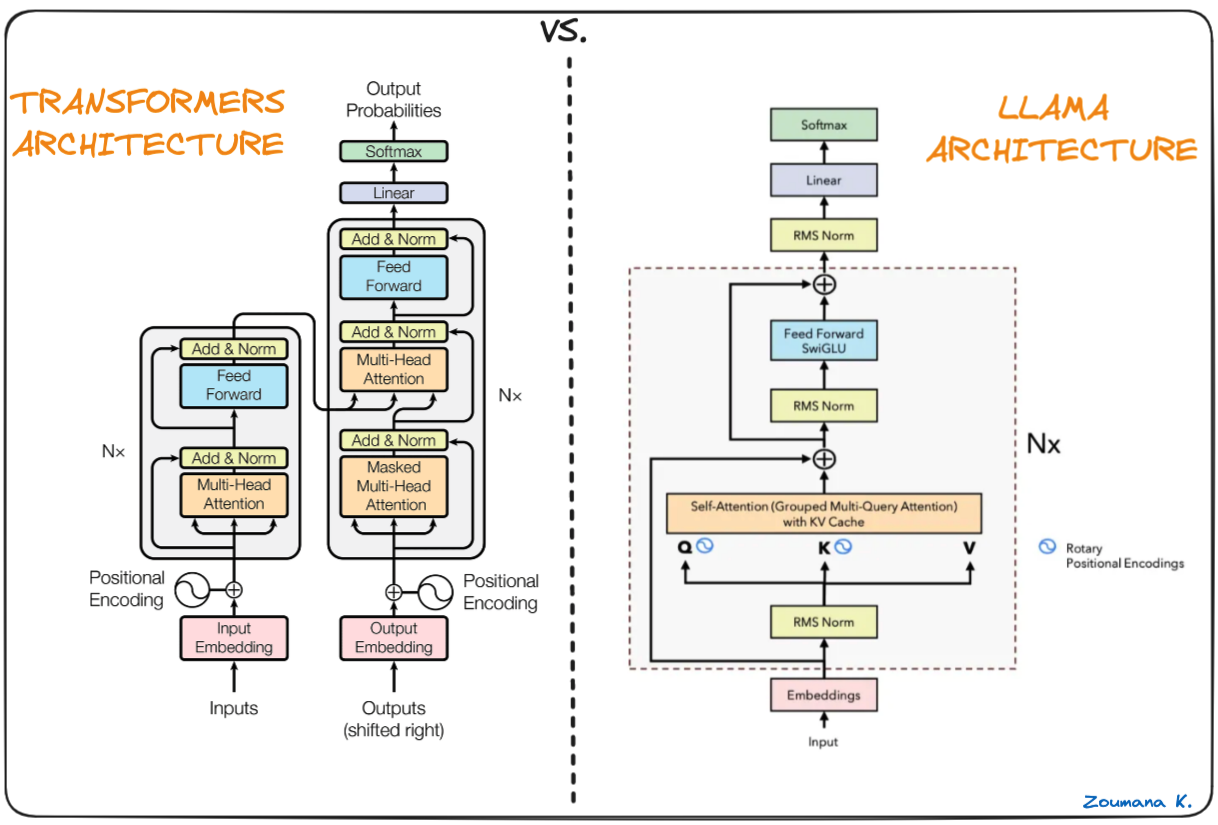
Differenza tra Transformer e architettura Llama (architettura Llama di Umar Jamil)
La principale differenza tra l'architettura LLaMa e quella dei transformer:
I prerequisiti per iniziare a lavorare con LLama.cpp includono:
Python: per poter eseguire pip, il gestore pacchetti di PythonLlama-cpp-python: il binding Python per llama.cppSi consiglia di creare un ambiente virtuale per evitare problemi legati al processo di installazione; conda è un'ottima opzione per la creazione dell'ambiente.
Tutti i comandi in questa sezione vengono eseguiti da terminale. Usando l'istruzione conda create, creiamo un ambiente virtuale chiamato llama-cpp-env.
conda create --name llama-cpp-envDopo aver creato correttamente l'ambiente virtuale, attiviamo l'ambiente con l'istruzione conda activate, come segue:
conda activate llama-cpp-envIl comando precedente dovrebbe mostrare il nome dell'ambiente tra parentesi all'inizio del terminale, come segue:

Nome dell'ambiente virtuale dopo l'attivazione
Ora possiamo installare il pacchetto llama-cpp-python come segue:
pip install llama-cpp-python
or
pip install llama-cpp-python==0.1.48L'esecuzione corretta di llama_cpp_script.py significa che la libreria è installata correttamente.
Per assicurarci che l'installazione sia andata a buon fine, creiamo e aggiungiamo l'istruzione import, quindi eseguiamo lo script.
from llama_cpp import Llama al file llama_cpp_script.py, poillama_cpp_script.py. Se la libreria non riesce a essere importata, viene generato un errore; in tal caso, è necessaria un'ulteriore diagnosi del processo di installazione.A questo punto, il processo di installazione dovrebbe essere andato a buon fine. Vediamo le basi di LLama.cpp.
La classe Llama importata sopra è il costruttore principale utilizzato con Llama.cpp. Accetta diversi parametri, non limitati a quelli seguenti. L'elenco completo dei parametri è fornito nella documentazione ufficiale:
model_path: il percorso al file del modello Llama utilizzatoprompt: il prompt di input per il modello. Questo testo viene tokenizzato e passato al modello.device: il dispositivo su cui eseguire il modello Llama; può essere CPU o GPU.max_tokens: il numero massimo di token da generare nella risposta del modellostop: un elenco di stringhe che causeranno l'arresto del processo di generazione del modellotemperature: valore compreso tra 0 e 1. Più è basso, più il risultato finale è deterministico. Al contrario, un valore più alto introduce maggiore casualità, quindi un output più vario e creativo.top_p: controlla la diversità delle previsioni, selezionando i token più probabili la cui probabilità cumulativa supera una soglia data. Partendo da zero, un valore più alto aumenta la possibilità di ottenere un output migliore, ma richiede calcoli aggiuntivi.echo: booleano che indica se il modello include il prompt originale all'inizio (True) o non lo include (False)Per esempio, supponiamo di voler usare un large language model chiamato <MY_AWESOME_MODEL> archiviato nella directory di lavoro corrente. Il processo di istanziazione sarà il seguente:
# Instanciate the model
my_aweseome_llama_model = Llama(model_path="./MY_AWESOME_MODEL")
prompt = "This is a prompt"
max_tokens = 100
temperature = 0.3
top_p = 0.1
echo = True
stop = ["Q", "\n"]
# Define the parameters
model_output = my_aweseome_llama_model(
prompt,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
echo=echo,
stop=stop,
)
final_result = model_output["choices"][0]["text"].strip()Il codice è autoesplicativo e può essere compreso facilmente dai punti elenco iniziali che indicano il significato di ciascun parametro.
Il risultato del modello è un dizionario che contiene la risposta generata insieme ad alcuni metadati aggiuntivi. Il formato dell'output è approfondito nelle prossime sezioni dell'articolo.
È il momento di iniziare a implementare il progetto di generazione di testo. Avviare un nuovo progetto Llama.cpp non è altro che seguire il template di codice Python sopra, che spiega tutti i passaggi dal caricamento del large language model di interesse fino alla generazione della risposta finale.
Il progetto sfrutta la versione GGUF di Zephyr-7B-Beta da Hugging Face. È una versione fine-tuned di mistralai/Mistral-7B-v0.1 addestrata su un mix di dataset pubblici e sintetici usando la Direct Preference Optimization (DPO).
La nostra guida Introduzione all'uso dei Transformer e di Hugging Face offre una migliore comprensione dei Transformer e di come sfruttarne la potenza per risolvere problemi reali. Abbiamo anche un tutorial su Mistral 7B.
Modello Zephyr su Hugging Face (fonte)
Una volta scaricato in locale il modello, possiamo spostarlo nella posizione del progetto nella cartella model. Prima di passare all'implementazione, capiamo la struttura del progetto:

La struttura del progetto
Il primo passaggio è caricare il modello usando il costruttore Llama. Poiché è un modello grande, è importante specificare la dimensione massima del contesto del modello da caricare. In questo progetto, usiamo 512 token.
from llama_cpp import Llama
# GLOBAL VARIABLES
my_model_path = "./model/zephyr-7b-beta.Q4_0.gguf"
CONTEXT_SIZE = 512
# LOAD THE MODEL
zephyr_model = Llama(model_path=my_model_path,
n_ctx=CONTEXT_SIZE)Una volta caricato il modello, il passo successivo è la fase di generazione del testo, utilizzando il template di codice originale, ma tramite una funzione helper chiamata generate_text_from_prompt.
def generate_text_from_prompt(user_prompt,
max_tokens = 100,
temperature = 0.3,
top_p = 0.1,
echo = True,
stop = ["Q", "\n"]):
# Define the parameters
model_output = zephyr_model(
user_prompt,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
echo=echo,
stop=stop,
)
return model_outputAll'interno della clausola __main__, la funzione può essere eseguita usando un determinato prompt.
if __name__ == "__main__":
my_prompt = "What do you think about the inclusion policies in Tech companies?"
zephyr_model_response = generate_text_from_prompt(my_prompt)
print(zephyr_model_response)La risposta del modello è riportata di seguito:

La risposta del modello
La risposta generata dal modello è <What do you think about the inclusion policies in Tech companies?> e l'esatta risposta del modello è evidenziata nel riquadro arancione.
Sebbene questo output completo possa essere utile per usi successivi, potremmo essere interessati solo alla risposta testuale del modello. Possiamo formattare la risposta per ottenere questo risultato selezionando il campo “text” dell'elemento “choices” come segue:
final_result = model_output["choices"][0]["text"].strip()
La funzione strip() viene usata per rimuovere eventuali spazi bianchi iniziali e finali da una stringa e il risultato è:
Tech companies want diverse workforces to build better products.Questa sezione illustra un'applicazione reale di LLama.cpp e presenta il problema sottostante, la possibile soluzione e i vantaggi dell'uso di Llama.cpp.
Immagina ETP4Africa, una startup tecnologica che ha bisogno di un modello linguistico in grado di operare in modo efficiente su vari dispositivi per la loro app educativa senza causare ritardi.
Implementano Llama.cpp, sfruttandone le prestazioni ottimizzate per CPU e la capacità di interfacciarsi con il loro backend basato su Go.
L'integrazione di Llama.cpp consente all'app di ETP4Africa di offrire una guida alla programmazione immediata e interattiva, migliorando l'esperienza e il coinvolgimento dell'utente.
La Data Engineering è un elemento chiave di qualsiasi progetto di Data Science e AI, e il nostro tutorial Introduzione a LangChain per la Data Engineering e le applicazioni dati offre una guida completa per includere l'AI dei large language model all'interno di pipeline e applicazioni.
In sintesi, questo articolo ha fornito una panoramica completa su come configurare e utilizzare i large language model con LLama.cpp.
Sono state fornite istruzioni dettagliate per aiutarti a comprendere le basi di Llama.cpp, configurare l'ambiente di lavoro, installare la libreria necessaria e implementare un caso d'uso di generazione di testo (domanda-risposta).
Infine, sono stati forniti spunti pratici su un'applicazione reale e su come Llama.cpp possa essere usato per affrontare in modo efficiente il problema sottostante.
Pronto ad approfondire il mondo dei large language model? Migliora le tue competenze con i potenti framework di deep learning LangChain e Pytorch usati dai professionisti dell'AI con il nostro tutorial Come creare applicazioni LLM con LangChain e Come addestrare un LLM con PyTorch.
Inizia oggi il tuo percorso nell'AI!
Programma
Corso
Corso
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min

