
Kursus
Pengantar Deep Learning dengan Python
4 Hr
264K
Dalam tutorial ini, Anda akan mempelajari cara menggunakan model deret waktu bernama Long Short-Term Memory. Model LSTM sangat andal, terutama untuk mempertahankan memori jangka panjang, sesuai desainnya, seperti yang akan Anda lihat nanti. Anda akan membahas topik-topik berikut dalam tutorial ini:
Jika Anda belum familiar dengan deep learning atau neural network, Anda sebaiknya melihat kursus Deep Learning in Python kami. Kursus ini membahas dasar-dasar, serta cara membangun neural network sendiri di Keras. Paket ini berbeda dari TensorFlow, yang akan digunakan dalam tutorial ini, tetapi idenya sama.
Anda ingin memodelkan harga saham dengan benar agar sebagai pembeli saham, Anda bisa secara wajar memutuskan kapan membeli dan kapan menjual untuk mendapatkan keuntungan. Di sinilah pemodelan deret waktu berperan. Anda memerlukan model machine learning yang baik yang dapat melihat riwayat sebuah urutan data dan dengan tepat memprediksi elemen masa depan dari urutan tersebut.
Peringatan: Harga pasar saham sangat tidak dapat diprediksi dan volatil. Ini berarti tidak ada pola konsisten dalam data yang memungkinkan Anda memodelkan harga saham dari waktu ke waktu dengan nyaris sempurna. Jangan percaya kata saya; percayalah pada ekonom Universitas Princeton, Burton Malkiel, yang berargumen dalam bukunya tahun 1973, "A Random Walk Down Wall Street," bahwa jika pasar benar-benar efisien dan harga saham mencerminkan semua faktor segera setelah dipublikasikan, maka seekor monyet yang ditutup matanya dan melempar anak panah ke daftar saham di koran seharusnya bisa berkinerja sebaik profesional investasi mana pun.
Namun, mari kita tidak serta-merta percaya bahwa ini hanyalah proses stokastik atau acak dan tidak ada harapan bagi machine learning. Mari kita lihat apakah setidaknya Anda dapat memodelkan datanya sehingga prediksi yang Anda buat berkorelasi dengan perilaku data yang sebenarnya. Dengan kata lain, Anda tidak perlu nilai saham masa depan yang persis, melainkan pergerakan harga saham (yakni, apakah akan naik atau turun dalam waktu dekat).
# Make sure that you have all these libaries available to run the code successfully
from pandas_datareader import data
import matplotlib.pyplot as plt
import pandas as pd
import datetime as dt
import urllib.request, json
import os
import numpy as np
import tensorflow as tf # This code has been tested with TensorFlow 1.6
from sklearn.preprocessing import MinMaxScalerAnda akan menggunakan data dari sumber berikut:
Alpha Vantage Stock API. Sebelum mulai, Anda perlu kunci API, yang bisa didapatkan gratis di sini. Setelah itu, Anda dapat menetapkan kunci tersebut ke variabel api_key. Tutorial ini akan mengambil 20 tahun data historis untuk saham American Airlines. Sebagai bacaan tambahan, Anda dapat merujuk ke panduan awal API saham ini untuk praktik terbaik saat bekerja dengan data pasar historis.
Gunakan data dari halaman ini. Salin folder Stocks dalam berkas zip ke folder home proyek Anda.
Harga saham memiliki beberapa jenis. Di antaranya,
Pertama, Anda akan memuat data dari Alpha Vantage. Karena Anda akan menggunakan harga pasar saham American Airlines untuk membuat prediksi, tetapkan ticker ke "AAL". Selain itu, Anda juga mendefinisikan url_string, yang akan mengembalikan berkas JSON berisi semua data pasar saham American Airlines dalam 20 tahun terakhir, dan file_to_save, yaitu berkas tempat Anda menyimpan data. Anda akan menggunakan variabel ticker yang sudah ditetapkan sebelumnya untuk membantu menamai berkas ini.
Selanjutnya, Anda akan menetapkan sebuah kondisi: jika Anda belum menyimpan data, Anda akan mengambil data dari URL yang Anda tetapkan di url_string; Anda akan menyimpan nilai date, low, high, volume, close, open ke DataFrame pandas df dan menyimpannya ke file_to_save. Namun, jika data sudah ada, Anda cukup memuatnya dari CSV.
Data yang ditemukan di Kaggle berupa kumpulan berkas CSV, dan Anda tidak perlu melakukan prapemrosesan, sehingga Anda dapat langsung memuat data ke dalam DataFrame Pandas.
data_source = 'kaggle' # alphavantage or kaggle
if data_source == 'alphavantage':
# ====================== Loading Data from Alpha Vantage ==================================
api_key = '<your API key>'
# American Airlines stock market prices
ticker = "AAL"
# JSON file with all the stock market data for AAL from the last 20 years
url_string = "https://www.alphavantage.co/query?function=TIME_SERIES_DAILY&symbol=%s&outputsize=full&apikey=%s"%(ticker,api_key)
# Save data to this file
file_to_save = 'stock_market_data-%s.csv'%ticker
# If you haven't already saved data,
# Go ahead and grab the data from the url
# And store date, low, high, volume, close, open values to a Pandas DataFrame
if not os.path.exists(file_to_save):
with urllib.request.urlopen(url_string) as url:
data = json.loads(url.read().decode())
# extract stock market data
data = data['Time Series (Daily)']
df = pd.DataFrame(columns=['Date','Low','High','Close','Open'])
for k,v in data.items():
date = dt.datetime.strptime(k, '%Y-%m-%d')
data_row = [date.date(),float(v['3. low']),float(v['2. high']),
float(v['4. close']),float(v['1. open'])]
df.loc[-1,:] = data_row
df.index = df.index + 1
print('Data saved to : %s'%file_to_save)
df.to_csv(file_to_save)
# If the data is already there, just load it from the CSV
else:
print('File already exists. Loading data from CSV')
df = pd.read_csv(file_to_save)
else:
# ====================== Loading Data from Kaggle ==================================
# You will be using HP's data. Feel free to experiment with other data.
# But while doing so, be careful to have a large enough dataset and also pay attention to the data normalization
df = pd.read_csv(os.path.join('Stocks','hpq.us.txt'),delimiter=',',usecols=['Date','Open','High','Low','Close'])
print('Loaded data from the Kaggle repository')
Data saved to : stock_market_data-AAL.csv
Di sini, Anda akan mencetak data yang dikumpulkan ke dalam DataFrame. Anda juga harus memastikan bahwa data diurutkan berdasarkan tanggal karena urutan data sangat krusial dalam pemodelan deret waktu.
# Sort DataFrame by date
df = df.sort_values('Date')
# Double check the result
df.head()
| Date | Open | High | Low | Close | |
|---|---|---|---|---|---|
| 0 | 1970-01-02 | 0.30627 | 0.30627 | 0.30627 | 0.30627 |
| 1 | 1970-01-05 | 0.30627 | 0.31768 | 0.30627 | 0.31385 |
| 2 | 1970-01-06 | 0.31385 | 0.31385 | 0.30996 | 0.30996 |
| 3 | 1970-01-07 | 0.31385 | 0.31385 | 0.31385 | 0.31385 |
| 4 | 1970-01-08 | 0.31385 | 0.31768 | 0.31385 | 0.31385 |
Sekarang, mari lihat seperti apa data yang Anda miliki. Anda menginginkan data dengan berbagai pola yang terjadi dari waktu ke waktu.
plt.figure(figsize = (18,9))
plt.plot(range(df.shape[0]),(df['Low']+df['High'])/2.0)
plt.xticks(range(0,df.shape[0],500),df['Date'].loc[::500],rotation=45)
plt.xlabel('Date',fontsize=18)
plt.ylabel('Mid Price',fontsize=18)
plt.show()
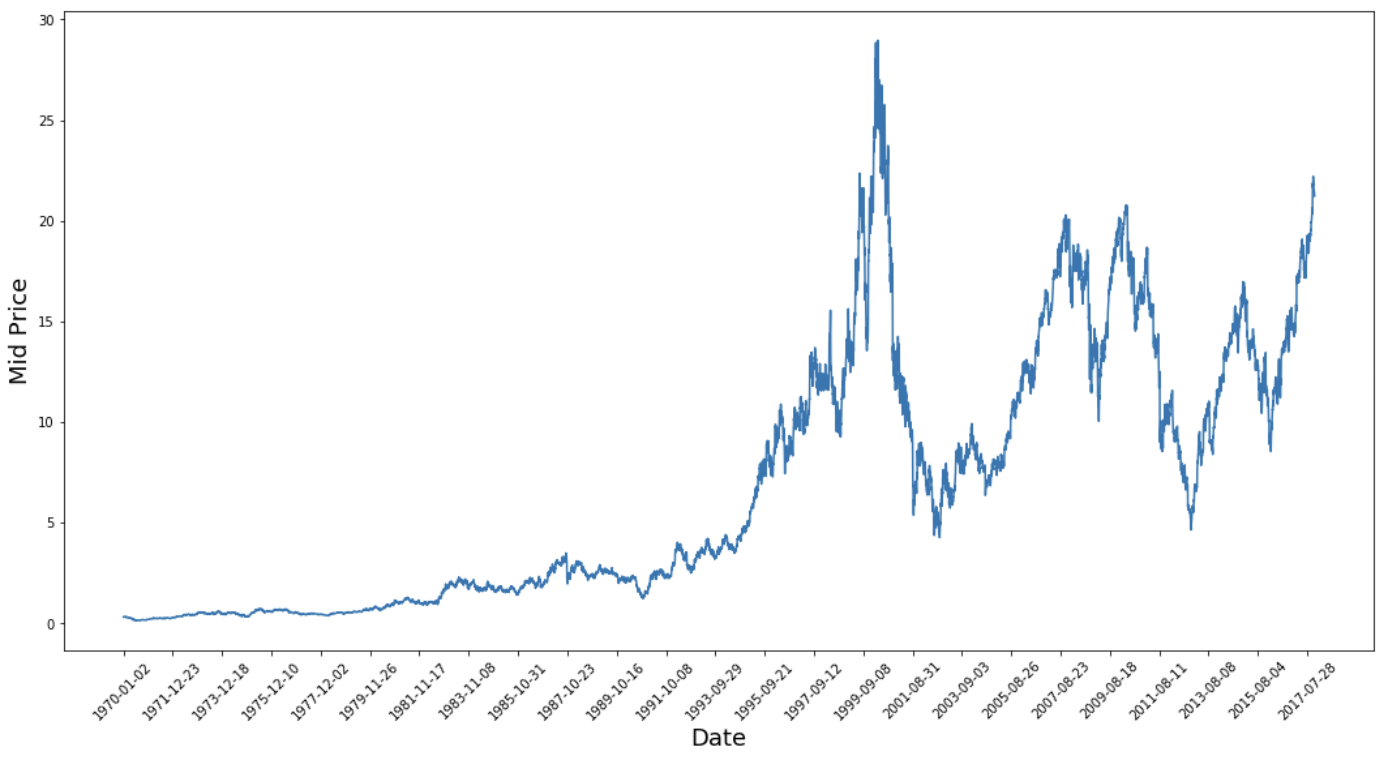
Grafik ini sudah menyampaikan banyak hal. Alasan khusus saya memilih perusahaan ini dibanding yang lain adalah karena datanya sarat dengan berbagai perilaku harga saham dari waktu ke waktu. Ini akan membuat proses pembelajaran lebih tangguh dan memberi Anda kesempatan untuk menguji seberapa baik prediksi untuk berbagai situasi.
Hal lain yang perlu diperhatikan adalah nilai mendekati 2017 jauh lebih tinggi dan lebih berfluktuasi daripada yang dekat dengan tahun 1970-an. Oleh karena itu, Anda perlu memastikan bahwa data berada dalam rentang nilai yang serupa sepanjang kerangka waktu. Anda akan menanganinya pada tahap normalisasi data.
Anda akan menggunakan harga tengah (mid-price), yang dihitung dengan mengambil rata-rata dari harga tertinggi dan terendah yang tercatat pada suatu hari.
# First calculate the mid prices from the highest and lowest
high_prices = df.loc[:,'High'].as_matrix()
low_prices = df.loc[:,'Low'].as_matrix()
mid_prices = (high_prices+low_prices)/2.0
Sekarang, Anda dapat membagi data latih dan data uji. Data latih akan berupa 11.000 titik data pertama dari deret waktu, dan sisanya akan menjadi data uji.
train_data = mid_prices[:11000]
test_data = mid_prices[11000:]
Sekarang, Anda perlu mendefinisikan sebuah scaler untuk menormalkan data. MinMaxScalar menskalakan semua data agar berada pada rentang 0 hingga 1. Anda juga dapat mengubah bentuk data latih dan uji menjadi bentuk [data_size, num_features].
# Scale the data to be between 0 and 1
# When scaling remember! You normalize both test and train data with respect to training data
# Because you are not supposed to have access to test data
scaler = MinMaxScaler()
train_data = train_data.reshape(-1,1)
test_data = test_data.reshape(-1,1)
Berdasarkan pengamatan sebelumnya bahwa periode waktu yang berbeda memiliki rentang nilai yang berbeda, Anda menormalkan data dengan membagi seluruh seri menjadi jendela. Jika tidak, data awal akan mendekati 0 dan tidak banyak menambah nilai pada proses pembelajaran. Di sini, Anda memilih ukuran jendela 2500.
Tip: Saat memilih ukuran jendela, pastikan tidak terlalu kecil. Saat Anda melakukan normalisasi berjendela, ini dapat menimbulkan patahan di akhir setiap jendela, karena setiap jendela dinormalisasi secara independen.
Dalam contoh ini, 4 titik data akan terpengaruh. Namun mengingat Anda memiliki 11.000 titik data, 4 titik tidak akan menimbulkan masalah.
# Train the Scaler with training data and smooth data
smoothing_window_size = 2500
for di in range(0,10000,smoothing_window_size):
scaler.fit(train_data[di:di+smoothing_window_size,:])
train_data[di:di+smoothing_window_size,:] = scaler.transform(train_data[di:di+smoothing_window_size,:])
# You normalize the last bit of remaining data
scaler.fit(train_data[di+smoothing_window_size:,:])
train_data[di+smoothing_window_size:,:] = scaler.transform(train_data[di+smoothing_window_size:,:])
Ubah kembali bentuk data menjadi [data_size]
# Reshape both train and test data
train_data = train_data.reshape(-1)
# Normalize test data
test_data = scaler.transform(test_data).reshape(-1)
Sekarang Anda dapat menghaluskan data menggunakan exponential moving average. Ini membantu menghilangkan kekasaran bawaan dari harga saham dan menghasilkan kurva yang lebih halus.
Catatan bahwa Anda hanya boleh menghaluskan data latih.
# Now perform exponential moving average smoothing
# So the data will have a smoother curve than the original ragged data
EMA = 0.0
gamma = 0.1
for ti in range(11000):
EMA = gamma*train_data[ti] + (1-gamma)*EMA
train_data[ti] = EMA
# Used for visualization and test purposes
all_mid_data = np.concatenate([train_data,test_data],axis=0)
Mekanisme perata-rataan memungkinkan Anda memprediksi (sering kali satu langkah ke depan) dengan merepresentasikan harga saham masa depan sebagai rata-rata dari harga saham yang diamati sebelumnya. Melakukannya untuk lebih dari satu langkah waktu dapat menghasilkan hasil yang cukup buruk. Anda akan melihat dua teknik perata-rataan: perata-rataan standar dan exponential moving average. Anda akan mengevaluasi keduanya secara kualitatif (inspeksi visual) dan kuantitatif (Mean Squared Error) atas hasil yang dihasilkan kedua algoritme.
Mean Squared Error (MSE) dapat dihitung dengan mengambil Kuadrat Error antara nilai sebenarnya satu langkah ke depan dan nilai prediksi lalu dirata-ratakan di seluruh prediksi.
Anda dapat memahami sulitnya masalah ini dengan terlebih dahulu mencoba memodelkannya sebagai masalah perhitungan rata-rata. Pertama, Anda akan mencoba memprediksi harga pasar saham masa depan (misalnya, xt+1) sebagai rata-rata dari harga pasar saham yang diamati sebelumnya dalam jendela berukuran tetap (misalnya, xt-N, ..., xt) (katakanlah 100 hari sebelumnya). Setelah itu, Anda akan mencoba metode yang sedikit lebih canggih yaitu "exponential moving average" dan melihat seberapa baik hasilnya. Lalu, Anda akan beralih ke "holy grail" dari prediksi deret waktu: model Long Short-Term Memory.
Pertama, Anda akan melihat bagaimana perata-rataan normal bekerja. Yaitu, Anda mengatakan,
Dengan kata lain, Anda mengatakan prediksi pada $t+1$ adalah nilai rata-rata dari semua harga saham yang Anda amati dalam jendela dari $t$ hingga $t-N$.
window_size = 100
N = train_data.size
std_avg_predictions = []
std_avg_x = []
mse_errors = []
for pred_idx in range(window_size,N):
if pred_idx >= N:
date = dt.datetime.strptime(k, '%Y-%m-%d').date() + dt.timedelta(days=1)
else:
date = df.loc[pred_idx,'Date']
std_avg_predictions.append(np.mean(train_data[pred_idx-window_size:pred_idx]))
mse_errors.append((std_avg_predictions[-1]-train_data[pred_idx])**2)
std_avg_x.append(date)
print('MSE error for standard averaging: %.5f'%(0.5*np.mean(mse_errors)))
MSE error for standard averaging: 0.00418
Lihat hasil rata-rataan di bawah ini. Hasilnya mengikuti perilaku saham yang sebenarnya dengan cukup dekat. Selanjutnya, Anda akan memeriksa metode prediksi satu langkah yang lebih akurat.
plt.figure(figsize = (18,9)) plt.plot(range(df.shape[0]),all_mid_data,color='b',label='True') plt.plot(range(window_size,N),std_avg_predictions,color='orange',label='Prediction') #plt.xticks(range(0,df.shape[0],50),df['Date'].loc[::50],rotation=45) plt.xlabel('Date') plt.ylabel('Mid Price') plt.legend(fontsize=18) plt.show()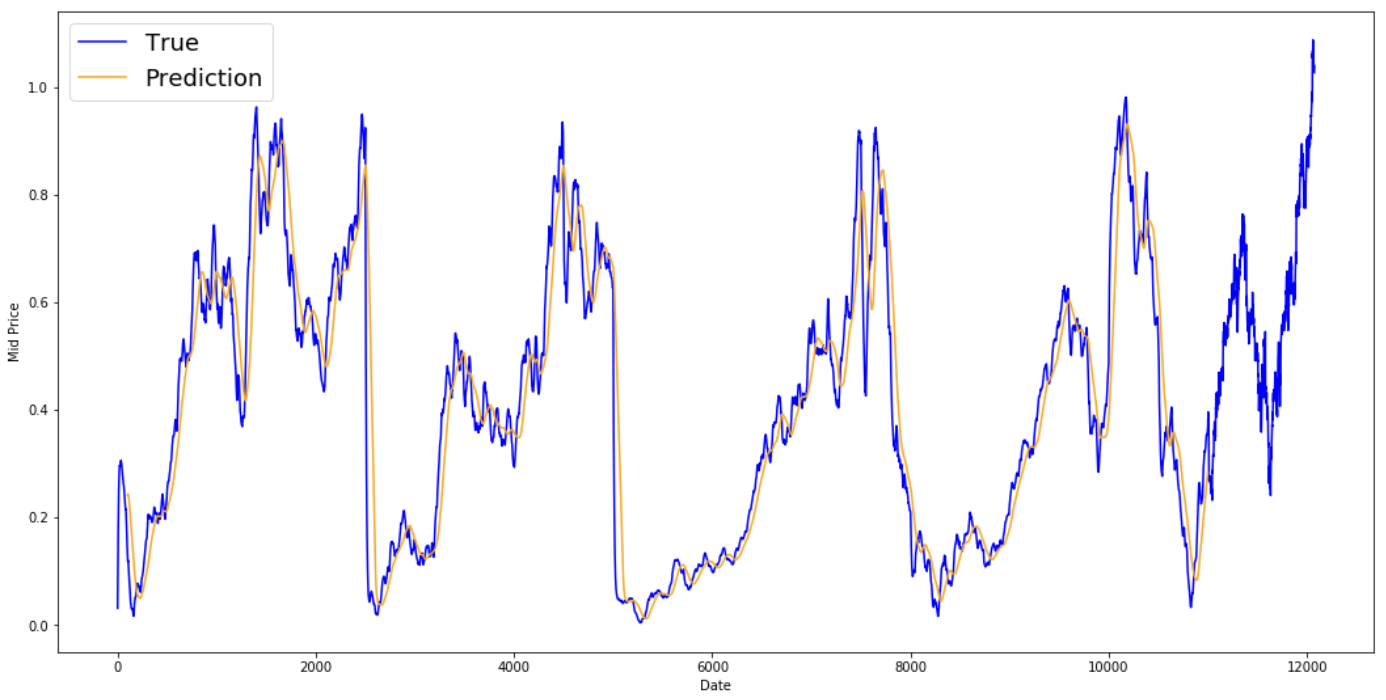
Lalu apa yang dikatakan grafik di atas (dan MSE)?
Tampaknya model ini tidak terlalu buruk untuk prediksi yang sangat pendek (satu hari ke depan). Perilaku ini masuk akal karena harga saham tidak berubah dari 0 menjadi 100 dalam semalam. Selanjutnya, Anda akan melihat teknik perata-rataan yang lebih canggih, yaitu exponential moving average.
Exponential moving average
Anda mungkin pernah melihat beberapa artikel di internet yang menggunakan model sangat kompleks dan memprediksi perilaku pasar saham hampir secara tepat. Namun hati-hati! Itu hanyalah ilusi optik dan bukan karena mempelajari sesuatu yang berguna. Anda akan melihat di bawah bagaimana Anda dapat mereplikasi perilaku tersebut dengan metode perata-rataan sederhana.
Dalam metode exponential moving average, Anda menghitung $x_{t+1}$ sebagai,
Persamaan di atas pada dasarnya menghitung exponential moving average dari langkah waktu $t+1$ dan menggunakan itu sebagai prediksi satu langkah ke depan. $\gamma$ menentukan seberapa besar kontribusi prediksi terbaru terhadap EMA. Misalnya, $\gamma=0.1$ hanya mengambil 10% dari nilai saat ini ke dalam EMA. Karena Anda hanya mengambil sebagian kecil dari nilai terbaru, ini memungkinkan untuk mempertahankan nilai lama yang Anda lihat lebih awal dalam rata-rata. Lihat betapa bagusnya ini ketika digunakan untuk memprediksi satu langkah ke depan di bawah ini.
window_size = 100
N = train_data.size
run_avg_predictions = []
run_avg_x = []
mse_errors = []
running_mean = 0.0
run_avg_predictions.append(running_mean)
decay = 0.5
for pred_idx in range(1,N):
running_mean = running_mean*decay + (1.0-decay)*train_data[pred_idx-1]
run_avg_predictions.append(running_mean)
mse_errors.append((run_avg_predictions[-1]-train_data[pred_idx])**2)
run_avg_x.append(date)
print('MSE error for EMA averaging: %.5f'%(0.5*np.mean(mse_errors)))
MSE error for EMA averaging: 0.00003
plt.figure(figsize = (18,9))
plt.plot(range(df.shape[0]),all_mid_data,color='b',label='True')
plt.plot(range(0,N),run_avg_predictions,color='orange', label='Prediction')
#plt.xticks(range(0,df.shape[0],50),df['Date'].loc[::50],rotation=45)
plt.xlabel('Date')
plt.ylabel('Mid Price')
plt.legend(fontsize=18)
plt.show()
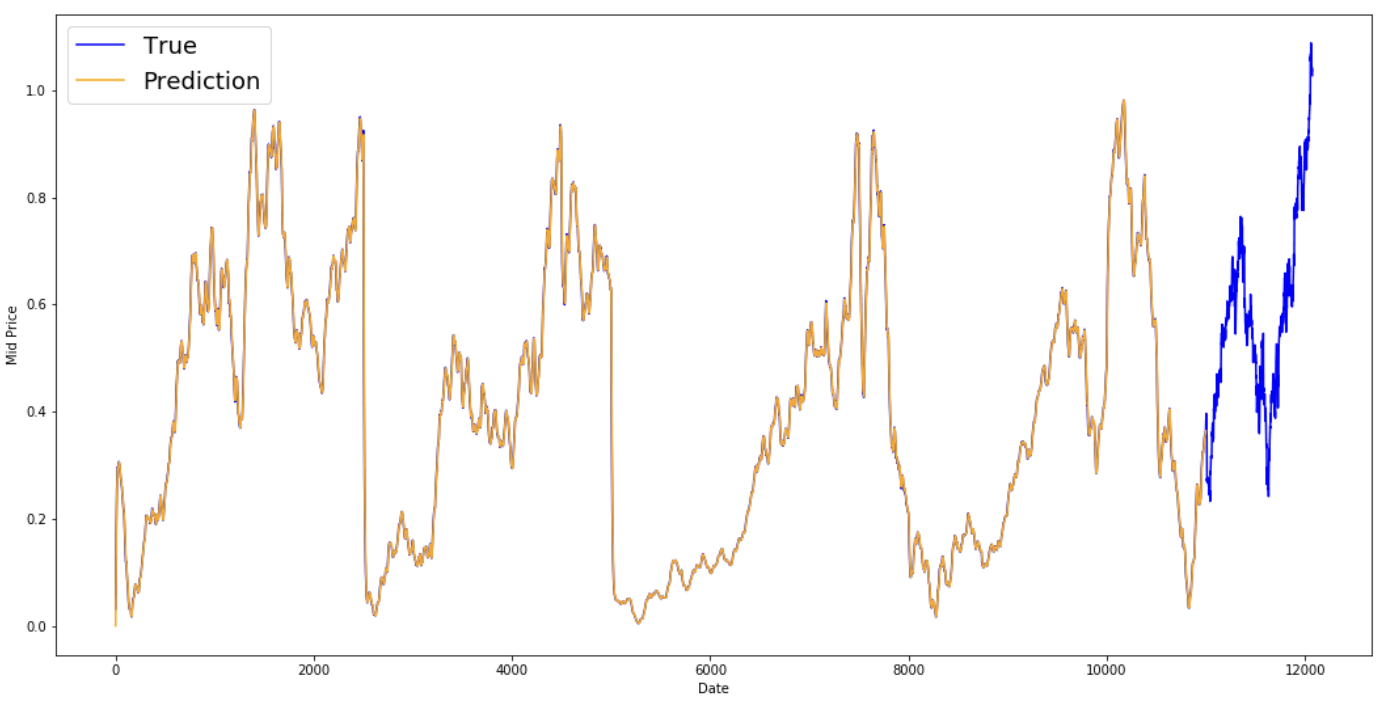
Anda melihat bahwa ia menyesuaikan garis sempurna yang mengikuti distribusi True (dan dibuktikan oleh MSE yang sangat rendah). Secara praktis, Anda tidak bisa banyak berbuat dengan hanya nilai pasar saham hari berikutnya. Secara pribadi, yang saya inginkan bukan harga pasar saham yang persis untuk hari berikutnya, melainkan apakah harga pasar saham akan naik atau turun dalam 30 hari ke depan? Cobalah melakukan ini, dan Anda akan melihat kelemahan metode EMA.
Sekarang Anda akan mencoba membuat prediksi dalam jendela (misalnya Anda memprediksi jendela 2 hari berikutnya, bukan hanya hari berikutnya). Lalu, Anda akan menyadari betapa salahnya EMA. Berikut contohnya:
Untuk membuatnya konkret, mari kita asumsikan nilai, misalnya $x_t=0.4$, $EMA=0.5$ dan $\gamma = 0.5$
Jadi, berapa pun langkah yang Anda prediksi ke masa depan, Anda akan terus mendapatkan jawaban yang sama untuk semua langkah prediksi berikutnya.
Salah satu solusi yang dapat memberikan informasi berguna adalah melihat algoritme berbasis momentum. Algoritme ini membuat prediksi berdasarkan apakah nilai-nilai terbaru sebelumnya naik atau turun (bukan nilai pastinya). Misalnya, mereka akan mengatakan harga hari berikutnya kemungkinan lebih rendah jika harga telah turun selama beberapa hari terakhir, yang terdengar masuk akal. Namun, Anda akan menggunakan model yang lebih kompleks: model LSTM.
Model-model ini mendominasi ranah prediksi deret waktu karena sangat baik dalam memodelkan data deret waktu. Anda akan melihat apakah memang ada pola tersembunyi dalam data yang dapat Anda manfaatkan.
Model long-short-term memory adalah model deret waktu yang sangat kuat. Model ini dapat memprediksi sejumlah langkah secara sewenang-wenang ke masa depan. Sebuah modul (atau sel) LSTM memiliki 5 komponen esensial, yang memungkinkannya memodelkan data jangka panjang dan jangka pendek.
Sebuah sel digambarkan di bawah ini:
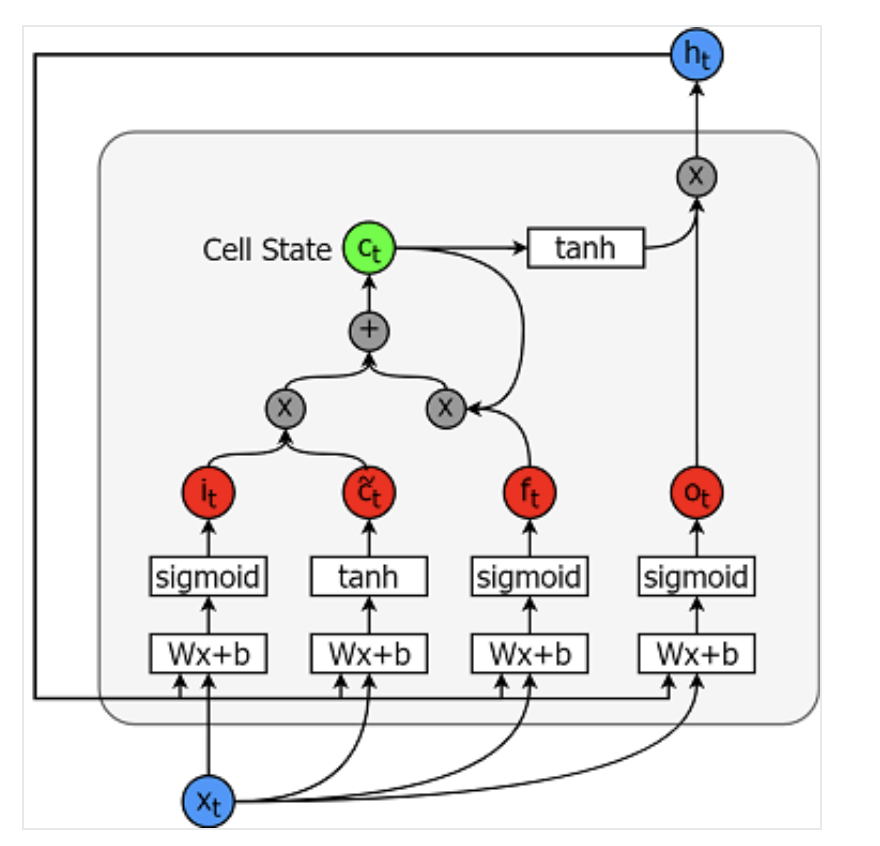
Persamaan untuk menghitung masing-masing entitas ini adalah sebagai berikut.
Anda dapat merujuk artikel ini untuk pemahaman LSTM yang lebih baik (lebih teknis).
TensorFlow menyediakan API yang bagus (disebut RNN API) untuk mengimplementasikan model deret waktu. Anda akan menggunakannya untuk implementasi Anda.
Pertama, Anda akan mengimplementasikan generator data untuk melatih model. Generator ini akan memiliki metode bernama .unroll_batches(...) yang akan menghasilkan serangkaian batch input num_unrollings yang diperoleh secara berurutan, di mana satu batch data berukuran [batch_size, 1]. Lalu, setiap batch input akan memiliki batch keluaran yang sesuai.
Misalnya jika num_unrollings=3 dan batch_size=4 satu set batch unroll mungkin terlihat seperti,
Selain itu, untuk membuat model Anda tangguh, Anda tidak akan selalu membuat keluaran untuk $x\_t$ adalah $x\_{t+1}$. Sebaliknya Anda akan secara acak mengambil sampel keluaran dari himpunan $x\_{t+1},x\_{t+2},\ldots,x_{t+N}$ di mana $N$ adalah ukuran jendela kecil.
Di sini, Anda membuat asumsi berikut:
Saya pribadi menganggap ini asumsi yang masuk akal untuk prediksi pergerakan saham.
Di bawah ini, Anda mengilustrasikan secara visual bagaimana sebuah batch data dibuat.
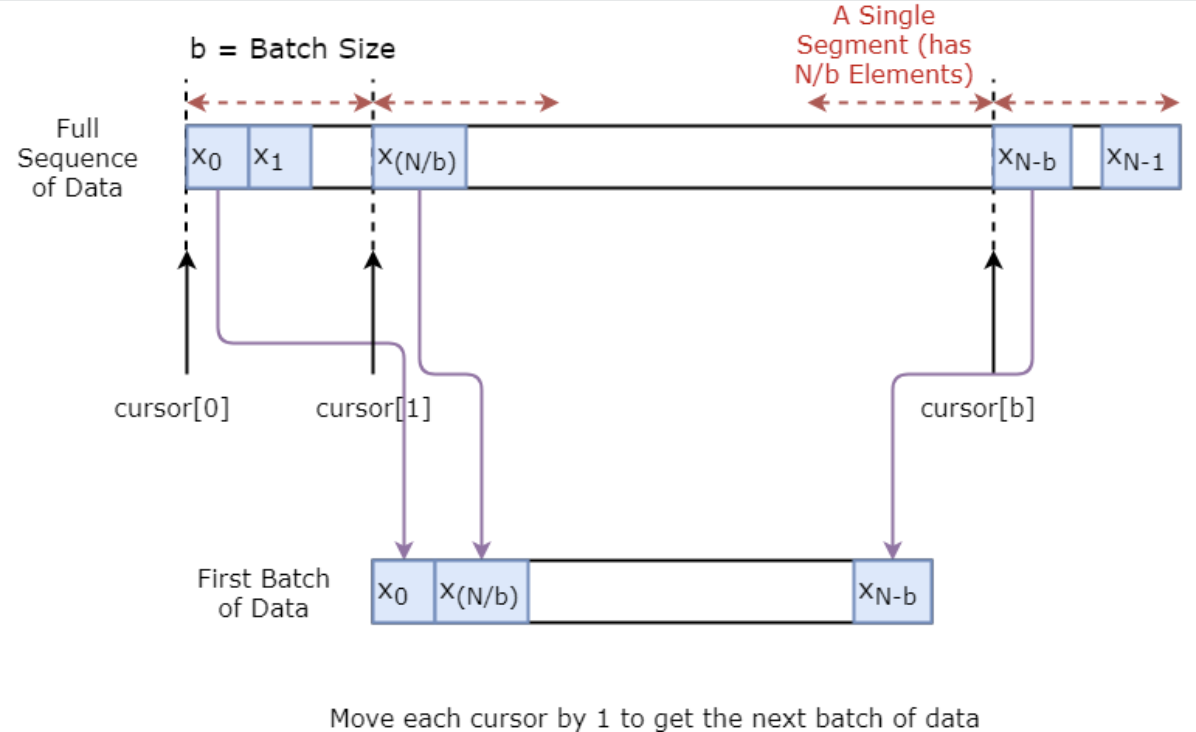
class DataGeneratorSeq(object):
def __init__(self,prices,batch_size,num_unroll):
self._prices = prices
self._prices_length = len(self._prices) - num_unroll
self._batch_size = batch_size
self._num_unroll = num_unroll
self._segments = self._prices_length //self._batch_size
self._cursor = [offset * self._segments for offset in range(self._batch_size)]
def next_batch(self):
batch_data = np.zeros((self._batch_size),dtype=np.float32)
batch_labels = np.zeros((self._batch_size),dtype=np.float32)
for b in range(self._batch_size):
if self._cursor[b]+1>=self._prices_length:
#self._cursor[b] = b * self._segments
self._cursor[b] = np.random.randint(0,(b+1)*self._segments)
batch_data[b] = self._prices[self._cursor[b]]
batch_labels[b]= self._prices[self._cursor[b]+np.random.randint(0,5)]
self._cursor[b] = (self._cursor[b]+1)%self._prices_length
return batch_data,batch_labels
def unroll_batches(self):
unroll_data,unroll_labels = [],[]
init_data, init_label = None,None
for ui in range(self._num_unroll):
data, labels = self.next_batch()
unroll_data.append(data)
unroll_labels.append(labels)
return unroll_data, unroll_labels
def reset_indices(self):
for b in range(self._batch_size):
self._cursor[b] = np.random.randint(0,min((b+1)*self._segments,self._prices_length-1))
dg = DataGeneratorSeq(train_data,5,5)
u_data, u_labels = dg.unroll_batches()
for ui,(dat,lbl) in enumerate(zip(u_data,u_labels)):
print('\n\nUnrolled index %d'%ui)
dat_ind = dat
lbl_ind = lbl
print('\tInputs: ',dat )
print('\n\tOutput:',lbl)
Unrolled index 0
Inputs: [0.03143791 0.6904868 0.82829314 0.32585657 0.11600105]
Output: [0.08698314 0.68685144 0.8329321 0.33355275 0.11785509]
Unrolled index 1
Inputs: [0.06067836 0.6890754 0.8325337 0.32857886 0.11785509]
Output: [0.15261841 0.68685144 0.8325337 0.33421066 0.12106793]
Unrolled index 2
Inputs: [0.08698314 0.68685144 0.8329321 0.33078218 0.11946969]
Output: [0.11098009 0.6848606 0.83387965 0.33421066 0.12106793]
Unrolled index 3
Inputs: [0.11098009 0.6858036 0.83294916 0.33219692 0.12106793]
Output: [0.132895 0.6836884 0.83294916 0.33219692 0.12288672]
Unrolled index 4
Inputs: [0.132895 0.6848606 0.833369 0.33355275 0.12158521]
Output: [0.15261841 0.6836884 0.83383167 0.33355275 0.12230608]
Pada bagian ini, Anda akan mendefinisikan beberapa hiperparameter. D adalah dimensi masukan. Ini mudah, karena Anda mengambil harga saham sebelumnya sebagai masukan dan memprediksi yang berikutnya, yang seharusnya 1.
Lalu ada num_unrollings, ini adalah hiperparameter terkait backpropagation through time (BPTT) yang digunakan untuk mengoptimalkan model LSTM. Ini menunjukkan berapa banyak langkah waktu berurutan yang Anda pertimbangkan untuk satu langkah optimisasi. Anda dapat menganggapnya sebagai, alih-alih mengoptimalkan model dengan melihat satu langkah waktu, Anda mengoptimalkan jaringan dengan melihat num_unrollings langkah waktu. Semakin besar semakin baik.
Kemudian ada batch_size. Ukuran batch adalah berapa banyak sampel data yang Anda pertimbangkan dalam satu langkah waktu.
Berikutnya Anda mendefinisikan num_nodes yang merepresentasikan jumlah neuron tersembunyi dalam setiap sel. Anda dapat melihat bahwa ada tiga lapisan LSTM dalam contoh ini.
D = 1 # Dimensionality of the data. Since your data is 1-D this would be 1
num_unrollings = 50 # Number of time steps you look into the future.
batch_size = 500 # Number of samples in a batch
num_nodes = [200,200,150] # Number of hidden nodes in each layer of the deep LSTM stack we're using
n_layers = len(num_nodes) # number of layers
dropout = 0.2 # dropout amount
tf.reset_default_graph() # This is important in case you run this multiple times
Berikutnya, Anda mendefinisikan placeholder untuk masukan pelatihan dan label. Ini sangat lugas karena Anda memiliki daftar placeholder masukan, masing-masing berisi satu batch data. Dan daftar tersebut memiliki num_unrollings placeholder, yang akan digunakan sekaligus untuk satu langkah optimisasi.
# Input data.
train_inputs, train_outputs = [],[]
# You unroll the input over time defining placeholders for each time step
for ui in range(num_unrollings):
train_inputs.append(tf.placeholder(tf.float32, shape=[batch_size,D],name='train_inputs_%d'%ui))
train_outputs.append(tf.placeholder(tf.float32, shape=[batch_size,1], name = 'train_outputs_%d'%ui))
Anda akan memiliki tiga lapisan LSTM dan sebuah lapisan regresi linear, dilambangkan oleh w dan b, yang mengambil keluaran dari sel LSTM terakhir dan menghasilkan prediksi untuk langkah waktu berikutnya. Anda dapat menggunakan MultiRNNCell di TensorFlow untuk membungkus tiga objek LSTMCell yang Anda buat. Selain itu, Anda dapat menggunakan sel LSTM dengan dropout, karena dapat meningkatkan kinerja dan mengurangi overfitting.
lstm_cells = [
tf.contrib.rnn.LSTMCell(num_units=num_nodes[li],
state_is_tuple=True,
initializer= tf.contrib.layers.xavier_initializer()
)
for li in range(n_layers)]
drop_lstm_cells = [tf.contrib.rnn.DropoutWrapper(
lstm, input_keep_prob=1.0,output_keep_prob=1.0-dropout, state_keep_prob=1.0-dropout
) for lstm in lstm_cells]
drop_multi_cell = tf.contrib.rnn.MultiRNNCell(drop_lstm_cells)
multi_cell = tf.contrib.rnn.MultiRNNCell(lstm_cells)
w = tf.get_variable('w',shape=[num_nodes[-1], 1], initializer=tf.contrib.layers.xavier_initializer())
b = tf.get_variable('b',initializer=tf.random_uniform([1],-0.1,0.1))
Pada bagian ini, Anda terlebih dahulu membuat variabel TensorFlow (c dan h) yang akan menampung keadaan sel dan keadaan tersembunyi dari sel LSTM. Lalu Anda mentransformasikan daftar train_inputs agar berbentuk [num_unrollings, batch_size, D], ini diperlukan untuk menghitung keluaran dengan fungsi tf.nn.dynamic_rnn. Anda kemudian menghitung keluaran LSTM dengan fungsi tf.nn.dynamic_rnn dan membagi kembali keluarannya menjadi daftar tensor num_unrolling. the loss antara prediksi dan harga saham sebenarnya.
# Create cell state and hidden state variables to maintain the state of the LSTM
c, h = [],[]
initial_state = []
for li in range(n_layers):
c.append(tf.Variable(tf.zeros([batch_size, num_nodes[li]]), trainable=False))
h.append(tf.Variable(tf.zeros([batch_size, num_nodes[li]]), trainable=False))
initial_state.append(tf.contrib.rnn.LSTMStateTuple(c[li], h[li]))
# Do several tensor transofmations, because the function dynamic_rnn requires the output to be of
# a specific format. Read more at: https://www.tensorflow.org/api_docs/python/tf/nn/dynamic_rnn
all_inputs = tf.concat([tf.expand_dims(t,0) for t in train_inputs],axis=0)
# all_outputs is [seq_length, batch_size, num_nodes]
all_lstm_outputs, state = tf.nn.dynamic_rnn(
drop_multi_cell, all_inputs, initial_state=tuple(initial_state),
time_major = True, dtype=tf.float32)
all_lstm_outputs = tf.reshape(all_lstm_outputs, [batch_size*num_unrollings,num_nodes[-1]])
all_outputs = tf.nn.xw_plus_b(all_lstm_outputs,w,b)
split_outputs = tf.split(all_outputs,num_unrollings,axis=0)
Sekarang, Anda akan menghitung loss. Namun, Anda harus mencatat bahwa ada karakteristik unik saat menghitung loss. Untuk setiap batch prediksi dan keluaran sebenarnya, Anda menghitung Mean Squared Error. Dan Anda menjumlahkan (bukan merata-ratakan) semua mean squared loss ini. Terakhir, Anda mendefinisikan optimizer yang akan digunakan untuk mengoptimalkan neural network. Dalam hal ini, Anda dapat menggunakan Adam, yang merupakan optimizer terbaru dan berkinerja baik.
# When calculating the loss you need to be careful about the exact form, because you calculate
# loss of all the unrolled steps at the same time
# Therefore, take the mean error or each batch and get the sum of that over all the unrolled steps
print('Defining training Loss')
loss = 0.0
with tf.control_dependencies([tf.assign(c[li], state[li][0]) for li in range(n_layers)]+
[tf.assign(h[li], state[li][1]) for li in range(n_layers)]):
for ui in range(num_unrollings):
loss += tf.reduce_mean(0.5*(split_outputs[ui]-train_outputs[ui])**2)
print('Learning rate decay operations')
global_step = tf.Variable(0, trainable=False)
inc_gstep = tf.assign(global_step,global_step + 1)
tf_learning_rate = tf.placeholder(shape=None,dtype=tf.float32)
tf_min_learning_rate = tf.placeholder(shape=None,dtype=tf.float32)
learning_rate = tf.maximum(
tf.train.exponential_decay(tf_learning_rate, global_step, decay_steps=1, decay_rate=0.5, staircase=True),
tf_min_learning_rate)
# Optimizer.
print('TF Optimization operations')
optimizer = tf.train.AdamOptimizer(learning_rate)
gradients, v = zip(*optimizer.compute_gradients(loss))
gradients, _ = tf.clip_by_global_norm(gradients, 5.0)
optimizer = optimizer.apply_gradients(
zip(gradients, v))
print('\tAll done')
Defining training Loss
Learning rate decay operations
TF Optimization operations
All done
Di sini Anda mendefinisikan operasi TensorFlow terkait prediksi. Pertama, definisikan placeholder untuk memasukkan input (sample_inputs), lalu serupa dengan tahap pelatihan, Anda mendefinisikan variabel state untuk prediksi (sample_c dan sample_h). Terakhir Anda menghitung prediksi dengan fungsi tf.nn.dynamic_rnn dan kemudian mengalirkan keluarannya melalui lapisan regresi (w dan b). Anda juga harus mendefinisikan operasi reset_sample_state, yang mereset keadaan sel dan keadaan tersembunyi. Anda harus mengeksekusi operasi ini di awal, setiap kali Anda membuat serangkaian prediksi.
print('Defining prediction related TF functions')
sample_inputs = tf.placeholder(tf.float32, shape=[1,D])
# Maintaining LSTM state for prediction stage
sample_c, sample_h, initial_sample_state = [],[],[]
for li in range(n_layers):
sample_c.append(tf.Variable(tf.zeros([1, num_nodes[li]]), trainable=False))
sample_h.append(tf.Variable(tf.zeros([1, num_nodes[li]]), trainable=False))
initial_sample_state.append(tf.contrib.rnn.LSTMStateTuple(sample_c[li],sample_h[li]))
reset_sample_states = tf.group(*[tf.assign(sample_c[li],tf.zeros([1, num_nodes[li]])) for li in range(n_layers)],
*[tf.assign(sample_h[li],tf.zeros([1, num_nodes[li]])) for li in range(n_layers)])
sample_outputs, sample_state = tf.nn.dynamic_rnn(multi_cell, tf.expand_dims(sample_inputs,0),
initial_state=tuple(initial_sample_state),
time_major = True,
dtype=tf.float32)
with tf.control_dependencies([tf.assign(sample_c[li],sample_state[li][0]) for li in range(n_layers)]+
[tf.assign(sample_h[li],sample_state[li][1]) for li in range(n_layers)]):
sample_prediction = tf.nn.xw_plus_b(tf.reshape(sample_outputs,[1,-1]), w, b)
print('\tAll done')
Defining prediction related TF functions
All done
Di sini Anda akan melatih dan memprediksi pergerakan harga saham selama beberapa epoch dan melihat apakah prediksi menjadi lebih baik atau lebih buruk dari waktu ke waktu. Anda mengikuti prosedur berikut.
test_points_seq) pada deret waktu untuk mengevaluasi modelnum_unrollingsnum_unrollings titik data sebelumnya yang ditemukan sebelum titik ujin_predict_once langkah, menggunakan prediksi sebelumnya sebagai input saat inin_predict_once titik yang diprediksi dan harga saham sebenarnya pada cap waktu tersebutepochs = 30
valid_summary = 1 # Interval you make test predictions
n_predict_once = 50 # Number of steps you continously predict for
train_seq_length = train_data.size # Full length of the training data
train_mse_ot = [] # Accumulate Train losses
test_mse_ot = [] # Accumulate Test loss
predictions_over_time = [] # Accumulate predictions
session = tf.InteractiveSession()
tf.global_variables_initializer().run()
# Used for decaying learning rate
loss_nondecrease_count = 0
loss_nondecrease_threshold = 2 # If the test error hasn't increased in this many steps, decrease learning rate
print('Initialized')
average_loss = 0
# Define data generator
data_gen = DataGeneratorSeq(train_data,batch_size,num_unrollings)
x_axis_seq = []
# Points you start your test predictions from
test_points_seq = np.arange(11000,12000,50).tolist()
for ep in range(epochs):
# ========================= Training =====================================
for step in range(train_seq_length//batch_size):
u_data, u_labels = data_gen.unroll_batches()
feed_dict = {}
for ui,(dat,lbl) in enumerate(zip(u_data,u_labels)):
feed_dict[train_inputs[ui]] = dat.reshape(-1,1)
feed_dict[train_outputs[ui]] = lbl.reshape(-1,1)
feed_dict.update({tf_learning_rate: 0.0001, tf_min_learning_rate:0.000001})
_, l = session.run([optimizer, loss], feed_dict=feed_dict)
average_loss += l
# ============================ Validation ==============================
if (ep+1) % valid_summary == 0:
average_loss = average_loss/(valid_summary*(train_seq_length//batch_size))
# The average loss
if (ep+1)%valid_summary==0:
print('Average loss at step %d: %f' % (ep+1, average_loss))
train_mse_ot.append(average_loss)
average_loss = 0 # reset loss
predictions_seq = []
mse_test_loss_seq = []
# ===================== Updating State and Making Predicitons ========================
for w_i in test_points_seq:
mse_test_loss = 0.0
our_predictions = []
if (ep+1)-valid_summary==0:
# Only calculate x_axis values in the first validation epoch
x_axis=[]
# Feed in the recent past behavior of stock prices
# to make predictions from that point onwards
for tr_i in range(w_i-num_unrollings+1,w_i-1):
current_price = all_mid_data[tr_i]
feed_dict[sample_inputs] = np.array(current_price).reshape(1,1)
_ = session.run(sample_prediction,feed_dict=feed_dict)
feed_dict = {}
current_price = all_mid_data[w_i-1]
feed_dict[sample_inputs] = np.array(current_price).reshape(1,1)
# Make predictions for this many steps
# Each prediction uses previous prediciton as it's current input
for pred_i in range(n_predict_once):
pred = session.run(sample_prediction,feed_dict=feed_dict)
our_predictions.append(np.asscalar(pred))
feed_dict[sample_inputs] = np.asarray(pred).reshape(-1,1)
if (ep+1)-valid_summary==0:
# Only calculate x_axis values in the first validation epoch
x_axis.append(w_i+pred_i)
mse_test_loss += 0.5*(pred-all_mid_data[w_i+pred_i])**2
session.run(reset_sample_states)
predictions_seq.append(np.array(our_predictions))
mse_test_loss /= n_predict_once
mse_test_loss_seq.append(mse_test_loss)
if (ep+1)-valid_summary==0:
x_axis_seq.append(x_axis)
current_test_mse = np.mean(mse_test_loss_seq)
# Learning rate decay logic
if len(test_mse_ot)>0 and current_test_mse > min(test_mse_ot):
loss_nondecrease_count += 1
else:
loss_nondecrease_count = 0
if loss_nondecrease_count > loss_nondecrease_threshold :
session.run(inc_gstep)
loss_nondecrease_count = 0
print('\tDecreasing learning rate by 0.5')
test_mse_ot.append(current_test_mse)
print('\tTest MSE: %.5f'%np.mean(mse_test_loss_seq))
predictions_over_time.append(predictions_seq)
print('\tFinished Predictions')
Initialized
Average loss at step 1: 1.703350
Test MSE: 0.00318
Finished Predictions
...
...
...
Average loss at step 30: 0.033753
Test MSE: 0.00243
Finished Predictions
Anda dapat melihat bagaimana loss MSE turun seiring jumlah pelatihan. Ini pertanda baik bahwa model mempelajari sesuatu yang berguna. Untuk mengkuantifikasi temuan Anda, Anda dapat membandingkan loss MSE jaringan dengan loss MSE yang Anda peroleh saat melakukan perata-rataan standar (0,004). Anda dapat melihat bahwa LSTM berkinerja lebih baik daripada perata-rataan standar. Dan Anda tahu bahwa perata-rataan standar (meski tidak sempurna) mengikuti pergerakan harga saham sebenarnya dengan cukup baik.
best_prediction_epoch = 28 # replace this with the epoch that you got the best results when running the plotting code plt.figure(figsize = (18,18)) plt.subplot(2,1,1) plt.plot(range(df.shape[0]),all_mid_data,color='b') # Plotting how the predictions change over time # Plot older predictions with low alpha and newer predictions with high alpha start_alpha = 0.25 alpha = np.arange(start_alpha,1.1,(1.0-start_alpha)/len(predictions_over_time[::3])) for p_i,p in enumerate(predictions_over_time[::3]): for xval,yval in zip(x_axis_seq,p): plt.plot(xval,yval,color='r',alpha=alpha[p_i]) plt.title('Evolution of Test Predictions Over Time',fontsize=18) plt.xlabel('Date',fontsize=18) plt.ylabel('Mid Price',fontsize=18) plt.xlim(11000,12500) plt.subplot(2,1,2) # Predicting the best test prediction you got plt.plot(range(df.shape[0]),all_mid_data,color='b') for xval,yval in zip(x_axis_seq,predictions_over_time[best_prediction_epoch]): plt.plot(xval,yval,color='r') plt.title('Best Test Predictions Over Time',fontsize=18) plt.xlabel('Date',fontsize=18) plt.ylabel('Mid Price',fontsize=18) plt.xlim(11000,12500) plt.show()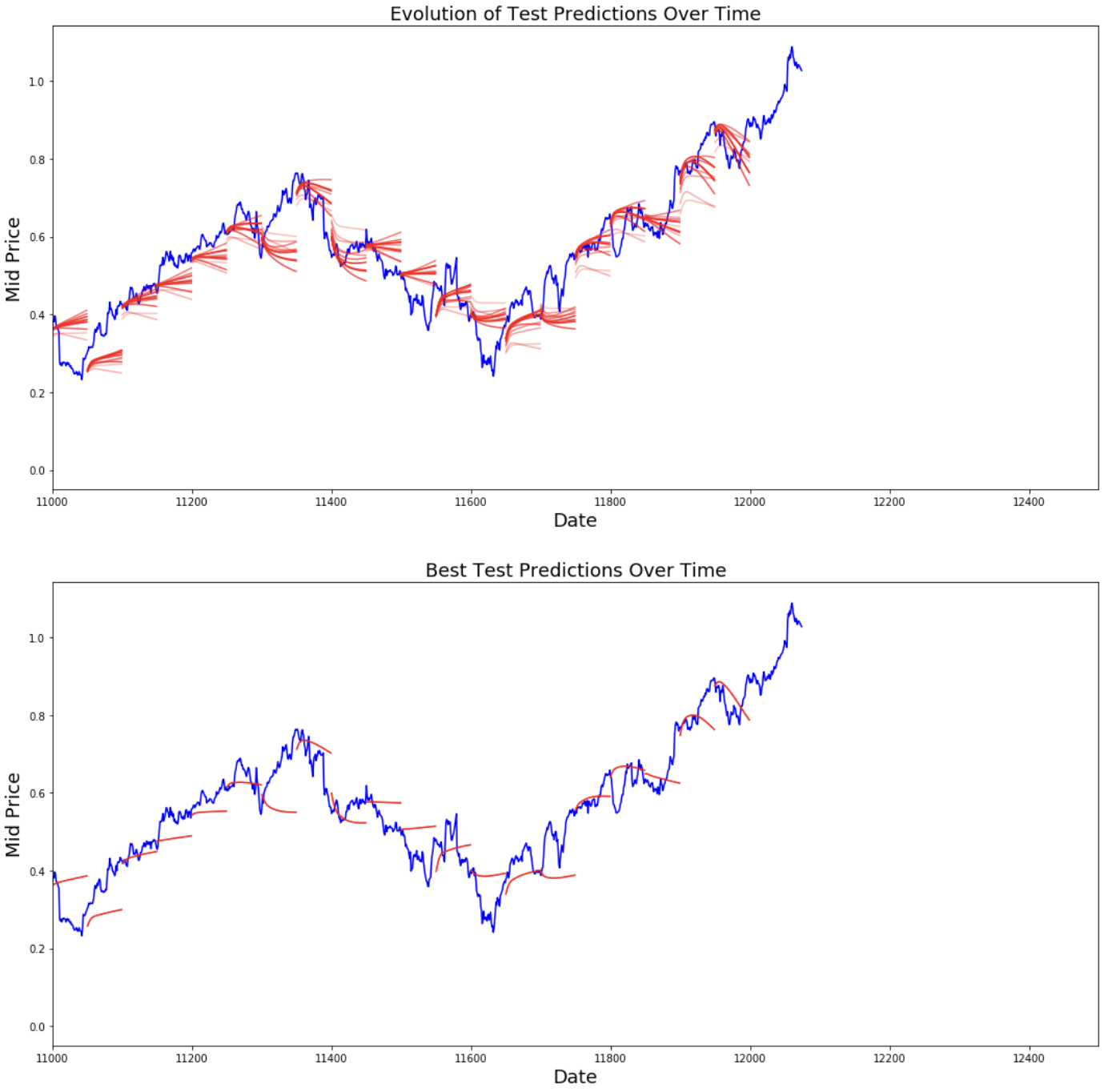
Meski tidak sempurna, LSTM tampaknya mampu memprediksi perilaku harga saham dengan benar sebagian besar waktu. Perhatikan bahwa Anda membuat prediksi kira-kira pada rentang 0 hingga 1,0 (yakni, bukan harga saham sebenarnya). Ini tidak masalah karena Anda memprediksi pergerakan harga saham, bukan harganya sendiri.
Catatan Akhir
Saya berharap Anda merasa tutorial ini bermanfaat. Perlu saya sebutkan bahwa ini merupakan pengalaman yang berharga bagi saya. Dalam tutorial ini, saya belajar betapa sulitnya merancang model yang mampu memprediksi pergerakan harga saham dengan benar. Anda memulai dengan motivasi mengapa Anda perlu memodelkan harga saham. Ini diikuti penjelasan dan kode untuk mengunduh data. Lalu, Anda melihat dua teknik perata-rataan yang memungkinkan Anda membuat prediksi satu langkah ke depan. Selanjutnya Anda melihat bahwa metode ini sia-sia saat Anda perlu memprediksi lebih dari satu langkah ke depan. Setelah itu, Anda membahas bagaimana menggunakan LSTM untuk membuat prediksi banyak langkah ke depan. Terakhir, Anda memvisualisasikan hasil dan melihat bahwa model Anda (meski tidak sempurna) cukup baik dalam memprediksi pergerakan harga saham dengan benar.
Jika Anda ingin mempelajari lebih lanjut tentang deep learning, pastikan untuk melihat kursus Deep Learning in Python kami. Kursus ini membahas dasar-dasar, serta cara membangun neural network sendiri di Keras. Ini adalah paket yang berbeda dari TensorFlow, yang akan digunakan dalam tutorial ini, tetapi idenya sama.
Berikut beberapa poin yang saya ambil dari tutorial ini.
Prediksi harga/pergerakan saham adalah tugas yang sangat sulit. Secara pribadi, saya tidak berpikir model prediksi saham mana pun di luar sana harus diterima begitu saja dan diandalkan secara membabi buta. Namun, model mungkin bisa memprediksi pergerakan harga saham dengan benar sebagian besar waktu, tetapi tidak selalu.
Jangan tertipu oleh artikel yang menampilkan kurva prediksi yang tumpang tindih sempurna dengan harga saham sebenarnya. Ini bisa direplikasi dengan teknik perata-rataan sederhana dan dalam praktiknya tidak berguna. Hal yang lebih masuk akal adalah memprediksi pergerakan harga saham.
Hiperparameter model sangat sensitif terhadap hasil yang Anda peroleh. Jadi, hal yang sangat baik untuk dilakukan adalah menjalankan teknik optimisasi hiperparameter (misalnya, Grid search / Random search) pada hiperparameter. Di bawah ini, saya cantumkan beberapa hiperparameter yang paling krusial:
- Laju pembelajaran (learning rate) dari optimizer
- Jumlah lapisan dan jumlah unit tersembunyi di setiap lapisan
- Optimizer. Saya menemukan Adam berkinerja terbaik
- Jenis model. Anda dapat mencoba GRU/ LSTM Standar/ LSTM dengan Peepholes dan evaluasi perbedaan kinerjanya
Dalam tutorial ini Anda melakukan sesuatu yang kurang tepat (karena ukuran data kecil)! Yaitu Anda menggunakan test loss untuk menurunkan laju pembelajaran. Ini secara tidak langsung membocorkan informasi tentang set uji ke prosedur pelatihan. Cara yang lebih baik adalah memiliki set validasi terpisah (di luar set uji) dan menurunkan laju pembelajaran berdasarkan kinerja set validasi.
Jika Anda ingin menghubungi saya, Anda dapat mengirim email ke thushv@gmail.com atau terhubung dengan saya di LinkedIn.
Referensi
Saya merujuk ke repositori ini untuk memahami cara menggunakan LSTM untuk prediksi saham. Namun, detailnya bisa sangat berbeda dari implementasi yang ditemukan pada referensi.
Pelajari lebih lanjut tentang Python dan Deep Learning
Kursus
Kursus
Kursus
blogs
Hugo Bowne-Anderson
13 mnt
blogs
David Woods
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
