
Kurs
Python ile Deep Learning'e Giriş
4 sa
264K
Bu eğitimde, Uzun Kısa Süreli Bellek (Long Short-Term Memory) adı verilen bir zaman serisi modelini nasıl kullanacağınızı öğreneceksiniz. LSTM modelleri, tasarımları gereği özellikle uzun süreli belleği koruma konusunda güçlüdür; bunu ileride göreceksiniz. Bu eğitimde aşağıdaki konulara değineceksiniz:
Derin öğrenme veya sinir ağlarına aşina değilseniz, Python ile Derin Öğrenme kursumuza göz atmalısınız. Temelleri ve Keras ile kendi sinir ağınızı nasıl kuracağınızı kapsar. Bu paket, bu eğitimde kullanacağınız TensorFlow’dan farklıdır, ancak fikir aynıdır.
Hisse senedi alıcısı olarak, kâr etmek için hangi zamanlarda alım-satım yapacağınıza makul şekilde karar verebilmek adına hisse senedi fiyatlarını doğru biçimde modellemek istersiniz. İşte zaman serisi modellemesi burada devreye girer. Bir veri dizisinin geçmişine bakarak dizinin gelecekteki öğelerini doğru şekilde tahmin edebilecek iyi makine öğrenmesi modellerine ihtiyacınız vardır.
Uyarı: Borsa fiyatları son derece öngörülemez ve oynaktır. Bu, verilerde zaman içinde hisse senedi fiyatlarını neredeyse mükemmele yakın modellemenize izin verecek tutarlı kalıpların bulunmadığı anlamına gelir. Bunu benden değil, Princeton Üniversitesi ekonomisti Burton Malkiel’den alın: 1973 tarihli “A Random Walk Down Wall Street” kitabında, eğer piyasa gerçekten verimliyse ve bir hisse fiyatı tüm faktörleri kamuya açıklandıkları anda derhal yansıtıyorsa, gözleri bağlı bir maymunun gazetedeki hisse listesine dart atması, herhangi bir yatırım uzmanı kadar başarılı olmalıdır, diye savunur.
Yine de bunun tamamen stokastik ya da rastgele bir süreç olduğuna ve makine öğrenmesi için hiç umut olmadığına tümüyle inanmaya gerek yok. En azından, yaptığınız tahminlerin verinin gerçek davranışıyla korelasyon göstermesini sağlayacak şekilde veriyi modelleyip modelleyemeyeceğinize bakalım. Başka bir deyişle, geleceğin tam hisse değerlerine değil, hisse fiyat hareketlerine (yakın gelecekte yükselip yükselmeyeceğine ya da düşüp düşmeyeceğine) ihtiyacınız var.
# Make sure that you have all these libaries available to run the code successfully
from pandas_datareader import data
import matplotlib.pyplot as plt
import pandas as pd
import datetime as dt
import urllib.request, json
import os
import numpy as np
import tensorflow as tf # This code has been tested with TensorFlow 1.6
from sklearn.preprocessing import MinMaxScalerAşağıdaki kaynaklardan veri kullanacaksınız:
Alpha Vantage Stock API. Başlamadan önce bir API anahtarına ihtiyacınız var; bunu ücretsiz olarak buradan edinebilirsiniz. Ardından bu anahtarı api_key değişkenine atayabilirsiniz. Bu eğitim, American Airlines hissesine ait 20 yıllık geçmiş veriyi getirir. İsteğe bağlı olarak, geçmiş piyasa verileriyle çalışma konusundaki en iyi uygulamalar için bu başlangıç kılavuzuna göz atabilirsiniz.
Bu sayfadaki verileri kullanın. Zip dosyasındaki Stocks klasörünü proje ana klasörünüze kopyalayın.
Hisse fiyatları birden fazla türde gelir. Bunlar:
Önce verileri Alpha Vantage’tan yükleyeceksiniz. Tahminler yapmak için American Airlines hisse fiyatlarını kullanacağınızdan, sembolü "AAL" olarak belirliyorsunuz. Ek olarak, son 20 yıl içinde American Airlines’a ait tüm hisse senedi verilerini içeren bir JSON dosyası döndürecek bir url_string ve veriyi kaydedeceğiniz file_to_save tanımlıyorsunuz. Bu dosyanın adlandırılmasına yardımcı olması için önceden tanımladığınız ticker değişkenini kullanacaksınız.
Sonraki adımda bir koşul belirleyeceksiniz: Veriyi daha önce kaydetmediyseniz, url_string içinde belirlediğiniz URL’den veriyi alacaksınız; tarih, low, high, volume, close, open değerlerini bir pandas DataFrame’i df’e kaydedip file_to_save dosyasına yazacaksınız. Ancak veri zaten varsa, doğrudan CSV’den yükleyeceksiniz.
Kaggle’da bulunan veriler CSV dosyalarının bir koleksiyonudur ve herhangi bir ön işleme gerek yoktur; bu nedenle veriyi doğrudan bir Pandas DataFrame’e yükleyebilirsiniz.
data_source = 'kaggle' # alphavantage or kaggle
if data_source == 'alphavantage':
# ====================== Loading Data from Alpha Vantage ==================================
api_key = '<your API key>'
# American Airlines stock market prices
ticker = "AAL"
# JSON file with all the stock market data for AAL from the last 20 years
url_string = "https://www.alphavantage.co/query?function=TIME_SERIES_DAILY&symbol=%s&outputsize=full&apikey=%s"%(ticker,api_key)
# Save data to this file
file_to_save = 'stock_market_data-%s.csv'%ticker
# If you haven't already saved data,
# Go ahead and grab the data from the url
# And store date, low, high, volume, close, open values to a Pandas DataFrame
if not os.path.exists(file_to_save):
with urllib.request.urlopen(url_string) as url:
data = json.loads(url.read().decode())
# extract stock market data
data = data['Time Series (Daily)']
df = pd.DataFrame(columns=['Date','Low','High','Close','Open'])
for k,v in data.items():
date = dt.datetime.strptime(k, '%Y-%m-%d')
data_row = [date.date(),float(v['3. low']),float(v['2. high']),
float(v['4. close']),float(v['1. open'])]
df.loc[-1,:] = data_row
df.index = df.index + 1
print('Data saved to : %s'%file_to_save)
df.to_csv(file_to_save)
# If the data is already there, just load it from the CSV
else:
print('File already exists. Loading data from CSV')
df = pd.read_csv(file_to_save)
else:
# ====================== Loading Data from Kaggle ==================================
# You will be using HP's data. Feel free to experiment with other data.
# But while doing so, be careful to have a large enough dataset and also pay attention to the data normalization
df = pd.read_csv(os.path.join('Stocks','hpq.us.txt'),delimiter=',',usecols=['Date','Open','High','Low','Close'])
print('Loaded data from the Kaggle repository')
Data saved to : stock_market_data-AAL.csv
Burada, DataFrame’e topladığınız veriyi yazdıracaksınız. Ayrıca verinin tarihe göre sıralandığından emin olun; çünkü zaman serisi modellemesinde verinin sırası kritik önemdedir.
# Sort DataFrame by date
df = df.sort_values('Date')
# Double check the result
df.head()
| Date | Open | High | Low | Close | |
|---|---|---|---|---|---|
| 0 | 1970-01-02 | 0.30627 | 0.30627 | 0.30627 | 0.30627 |
| 1 | 1970-01-05 | 0.30627 | 0.31768 | 0.30627 | 0.31385 |
| 2 | 1970-01-06 | 0.31385 | 0.31385 | 0.30996 | 0.30996 |
| 3 | 1970-01-07 | 0.31385 | 0.31385 | 0.31385 | 0.31385 |
| 4 | 1970-01-08 | 0.31385 | 0.31768 | 0.31385 | 0.31385 |
Şimdi, elinizde ne tür veriler olduğuna bakalım. Zaman içinde çeşitli örüntülerin oluştuğu veriler istiyorsunuz.
plt.figure(figsize = (18,9))
plt.plot(range(df.shape[0]),(df['Low']+df['High'])/2.0)
plt.xticks(range(0,df.shape[0],500),df['Date'].loc[::500],rotation=45)
plt.xlabel('Date',fontsize=18)
plt.ylabel('Mid Price',fontsize=18)
plt.show()
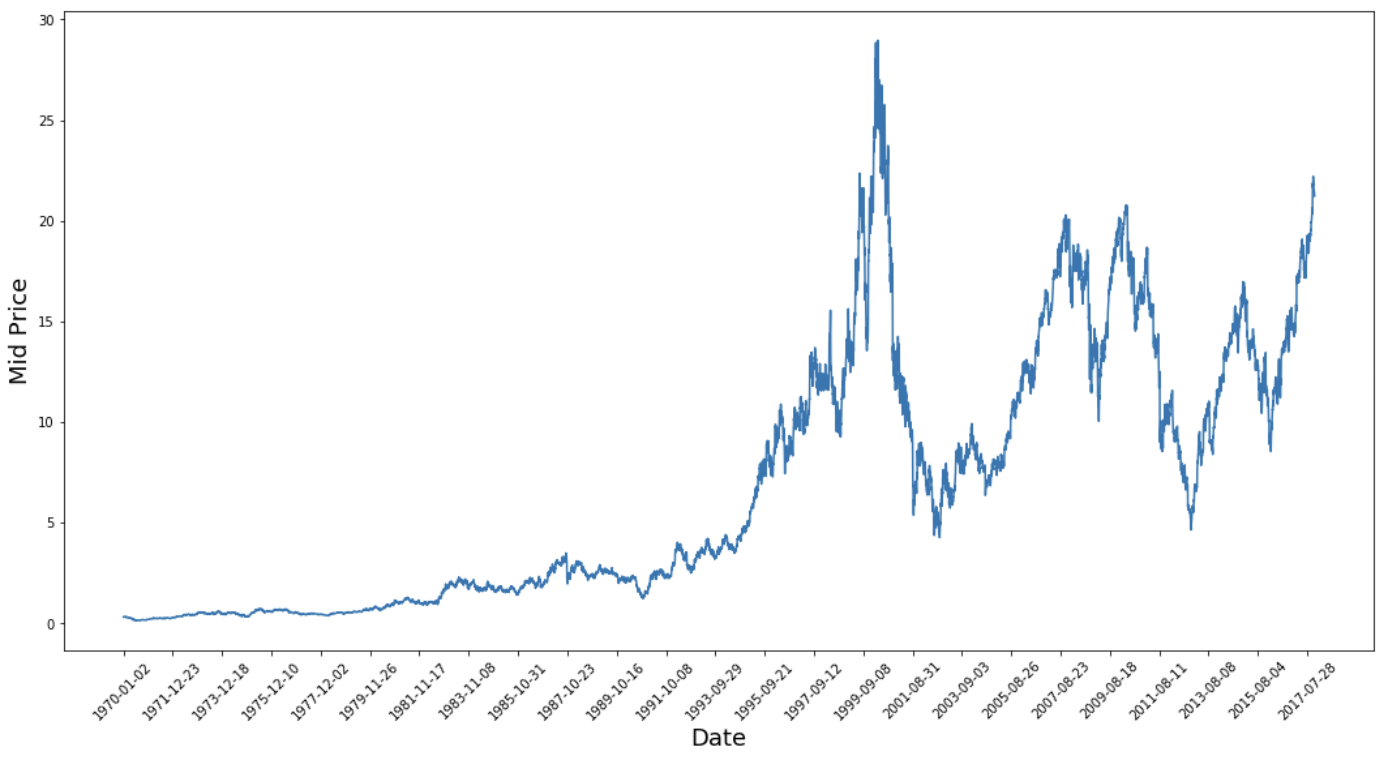
Bu grafik zaten çok şey söylüyor. Bu şirketi diğerlerine tercih etmemin belirli nedeni, zaman içinde çok farklı hisse fiyatı davranışları barındırmasıdır. Bu, öğrenmeyi daha sağlam hale getirecek ve çeşitli durumlar için tahminlerin ne kadar iyi olduğunu test etme şansı verecektir.
Dikkat edilmesi gereken bir başka nokta da 2017’ye yakın değerlerin çok daha yüksek olması ve 1970’lere yakın değerlere kıyasla daha fazla dalgalanmasıdır. Bu nedenle, zaman aralığı boyunca verinin benzer değer aralıklarında davrandığından emin olmanız gerekir. Bunu veri normalleştirme aşamasında ele alacaksınız.
Gün içinde kaydedilen en yüksek ve en düşük fiyatların ortalaması alınarak hesaplanan orta fiyatı kullanacaksınız.
# First calculate the mid prices from the highest and lowest
high_prices = df.loc[:,'High'].as_matrix()
low_prices = df.loc[:,'Low'].as_matrix()
mid_prices = (high_prices+low_prices)/2.0
Şimdi eğitim ve test verilerini ayırabilirsiniz. Eğitim verisi zaman serisinin ilk 11.000 veri noktası, geri kalanı ise test verisi olacaktır.
train_data = mid_prices[:11000]
test_data = mid_prices[11000:]
Şimdi veriyi normalize etmek için bir ölçekleyici tanımlamanız gerekiyor. MinMaxScalar, tüm verileri 0 ile 1 aralığına ölçekler. Ayrıca eğitim ve test verilerini [data_size, num_features] şeklinde yeniden şekillendirebilirsiniz.
# Scale the data to be between 0 and 1
# When scaling remember! You normalize both test and train data with respect to training data
# Because you are not supposed to have access to test data
scaler = MinMaxScaler()
train_data = train_data.reshape(-1,1)
test_data = test_data.reshape(-1,1)
Daha önce yaptığınız, farklı zaman dönemlerindeki verilerin farklı değer aralıklarına sahip olduğu gözlemi nedeniyle, tam seriyi pencerelere bölerek normalleştirme yapıyorsunuz. Bunu yapmazsanız, eski veriler 0’a yakın olacak ve öğrenme sürecine fazla katkı sağlamayacaktır. Burada pencere boyutu olarak 2500 seçiyorsunuz.
İpucu: Pencere boyutunu seçerken çok küçük olmamasına dikkat edin. Pencereli normalleştirme yaptığınızda, her pencere bağımsız olarak normalize edildiği için her pencerenin en sonunda bir kırılma oluşturabilir.
Bu örnekte 4 veri noktası bundan etkilenecektir. Ancak elinizde 11.000 veri noktası olduğuna göre, 4 nokta bir sorun yaratmayacaktır.
# Train the Scaler with training data and smooth data
smoothing_window_size = 2500
for di in range(0,10000,smoothing_window_size):
scaler.fit(train_data[di:di+smoothing_window_size,:])
train_data[di:di+smoothing_window_size,:] = scaler.transform(train_data[di:di+smoothing_window_size,:])
# You normalize the last bit of remaining data
scaler.fit(train_data[di+smoothing_window_size:,:])
train_data[di+smoothing_window_size:,:] = scaler.transform(train_data[di+smoothing_window_size:,:])
Veriyi tekrar [data_size] şekline geri döndürün
# Reshape both train and test data
train_data = train_data.reshape(-1)
# Normalize test data
test_data = scaler.transform(test_data).reshape(-1)
Artık veriyi üssel hareketli ortalama ile yumuşatabilirsiniz. Bu, hisse fiyatlarının doğasında bulunan girintili çıkıntılı yapıyı azaltarak daha düzgün bir eğri elde etmenize yardımcı olur.
Not: Yalnızca eğitim verisini yumuşatmalısınız.
# Now perform exponential moving average smoothing
# So the data will have a smoother curve than the original ragged data
EMA = 0.0
gamma = 0.1
for ti in range(11000):
EMA = gamma*train_data[ti] + (1-gamma)*EMA
train_data[ti] = EMA
# Used for visualization and test purposes
all_mid_data = np.concatenate([train_data,test_data],axis=0)
Ortalama alma mekanizmaları, gelecekteki hisse fiyatını daha önce gözlemlenen hisse fiyatlarının ortalaması olarak temsil ederek (genellikle bir adım ileri) tahmin yapmanıza olanak tanır. Bunu birden fazla zaman adımı için yapmak oldukça kötü sonuçlar üretebilir. İki ortalama alma tekniğine bakacaksınız: aşağıda standart ortalama ve üssel hareketli ortalama. Her iki algoritmanın ürettiği sonuçları nitel (görsel inceleme) ve nicel (Ortalama Kare Hata) olarak değerlendireceksiniz.
Ortalama Kare Hata (MSE), bir adım ilerideki gerçek değer ile tahmin edilen değer arasındaki Kare Hatanın alınması ve tüm tahminler üzerinde ortalamasının alınmasıyla hesaplanabilir.
Bu problemin zorluğunu, önce bunu bir ortalama hesaplama problemi olarak modellemeye çalışarak anlayabilirsiniz. Önce, gelecekteki hisse piyasası fiyatlarını (örneğin xt+1) sabit boyutlu bir pencere içindeki (örneğin xt-N, ..., xt) daha önce gözlemlenen hisse piyasası fiyatlarının ortalaması olarak (örneğin önceki 100 gün) tahmin etmeyi deneyeceksiniz. Sonrasında, biraz daha süslü bir “üssel hareketli ortalama” yöntemini deneyecek ve bunun ne kadar iyi sonuç verdiğini göreceksiniz. Ardından zaman serisi tahmininin “kutsal kasesi”ne, yani Uzun Kısa Süreli Bellek modellerine geçeceksiniz.
Önce normal ortalamanın nasıl çalıştığını göreceksiniz. Yani şöyle diyorsunuz,
Başka bir deyişle, $t+1$ anındaki tahminin, $t$ ile $t-N$ penceresi içinde gözlemlediğiniz tüm hisse fiyatlarının ortalama değeri olduğunu söylersiniz.
window_size = 100
N = train_data.size
std_avg_predictions = []
std_avg_x = []
mse_errors = []
for pred_idx in range(window_size,N):
if pred_idx >= N:
date = dt.datetime.strptime(k, '%Y-%m-%d').date() + dt.timedelta(days=1)
else:
date = df.loc[pred_idx,'Date']
std_avg_predictions.append(np.mean(train_data[pred_idx-window_size:pred_idx]))
mse_errors.append((std_avg_predictions[-1]-train_data[pred_idx])**2)
std_avg_x.append(date)
print('MSE error for standard averaging: %.5f'%(0.5*np.mean(mse_errors)))
MSE error for standard averaging: 0.00418
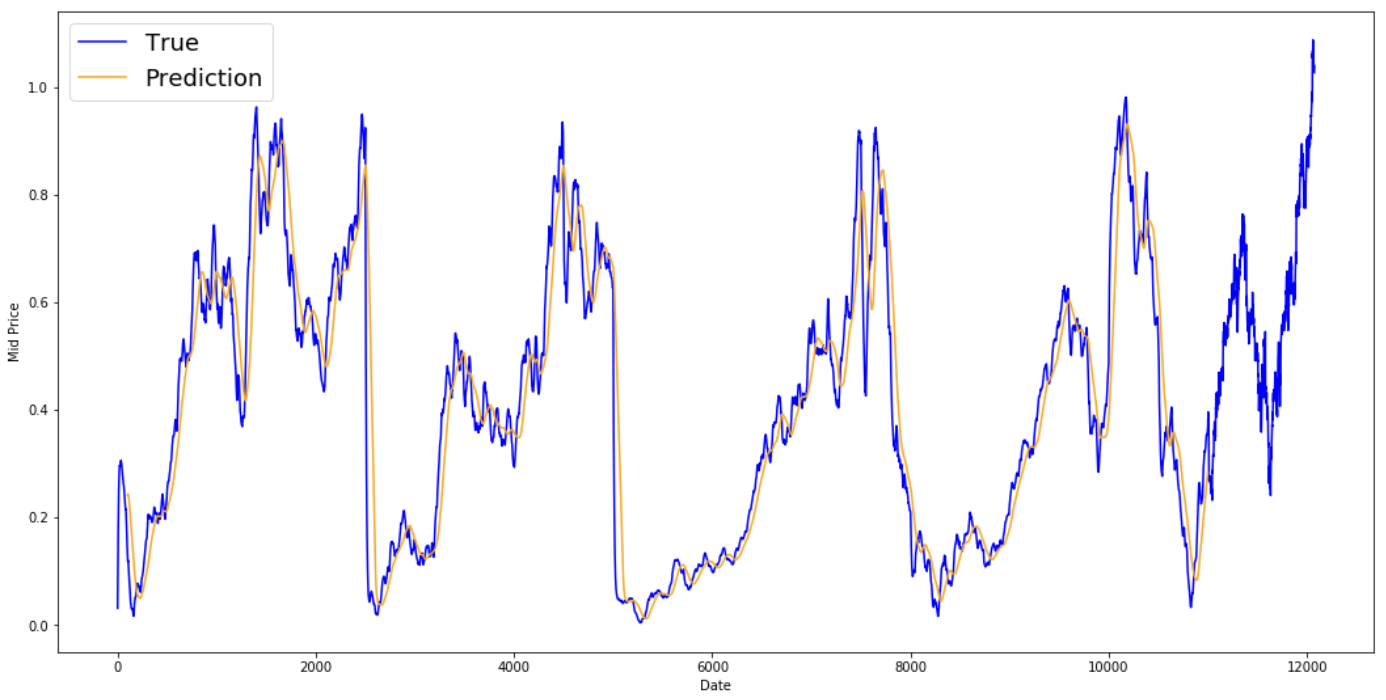
Aşağıdaki ortalama sonuçlara bir göz atın. Hissenin gerçek davranışını oldukça yakından takip ediyorlar. Sırada daha doğru bir bir-adım tahmin yöntemi var.
plt.figure(figsize = (18,9)) plt.plot(range(df.shape[0]),all_mid_data,color='b',label='True') plt.plot(range(window_size,N),std_avg_predictions,color='orange',label='Prediction') #plt.xticks(range(0,df.shape[0],50),df['Date'].loc[::50],rotation=45) plt.xlabel('Date') plt.ylabel('Mid Price') plt.legend(fontsize=18) plt.show()
Peki yukarıdaki grafikler (ve MSE) ne söylüyor?
Çok kısa vadeli tahminler (bir gün sonrası) için o kadar da kötü bir model olmadığı görülüyor. Bu davranış mantıklıdır çünkü hisse fiyatları bir gecede 0’dan 100’e çıkmaz. Şimdi, daha süslü bir ortalama tekniğine, üssel hareketli ortalamaya bakacaksınız.
İnternette çok karmaşık modeller kullanan ve borsanın neredeyse tam davranışını tahmin eden bazı yazılar görmüş olabilirsiniz. Ancak dikkat! Bunlar yararlı bir şey öğrenildiğinden değil, optik illüzyonlardan kaynaklanır. Aşağıda bu davranışı basit bir ortalama yöntemiyle nasıl tekrar üretebileceğinizi göreceksiniz.
Üssel hareketli ortalama yönteminde, $x_{t+1}$’i şöyle hesaplarsınız:
Yukarıdaki denklem, temelde $t+1$ zaman adımından itibaren üssel hareketli ortalamayı hesaplar ve bunu bir adım ileri tahmin olarak kullanır. $\gamma$, en son tahminin EMA’ya katkısını belirler. Örneğin $\gamma=0.1$, mevcut değerin sadece %10’unu EMA’ya dahil eder. En son değerden yalnızca çok küçük bir pay aldığınız için, ortalamanın çok erken dönemlerde gördüğünüz daha eski değerleri korumasına imkân tanır. Aşağıda, bir adım ilerisini tahmin etmek için kullanıldığında ne kadar iyi göründüğüne bakın.
window_size = 100
N = train_data.size
run_avg_predictions = []
run_avg_x = []
mse_errors = []
running_mean = 0.0
run_avg_predictions.append(running_mean)
decay = 0.5
for pred_idx in range(1,N):
running_mean = running_mean*decay + (1.0-decay)*train_data[pred_idx-1]
run_avg_predictions.append(running_mean)
mse_errors.append((run_avg_predictions[-1]-train_data[pred_idx])**2)
run_avg_x.append(date)
print('MSE error for EMA averaging: %.5f'%(0.5*np.mean(mse_errors)))
MSE error for EMA averaging: 0.00003
plt.figure(figsize = (18,9))
plt.plot(range(df.shape[0]),all_mid_data,color='b',label='True')
plt.plot(range(0,N),run_avg_predictions,color='orange', label='Prediction')
#plt.xticks(range(0,df.shape[0],50),df['Date'].loc[::50],rotation=45)
plt.xlabel('Date')
plt.ylabel('Mid Price')
plt.legend(fontsize=18)
plt.show()
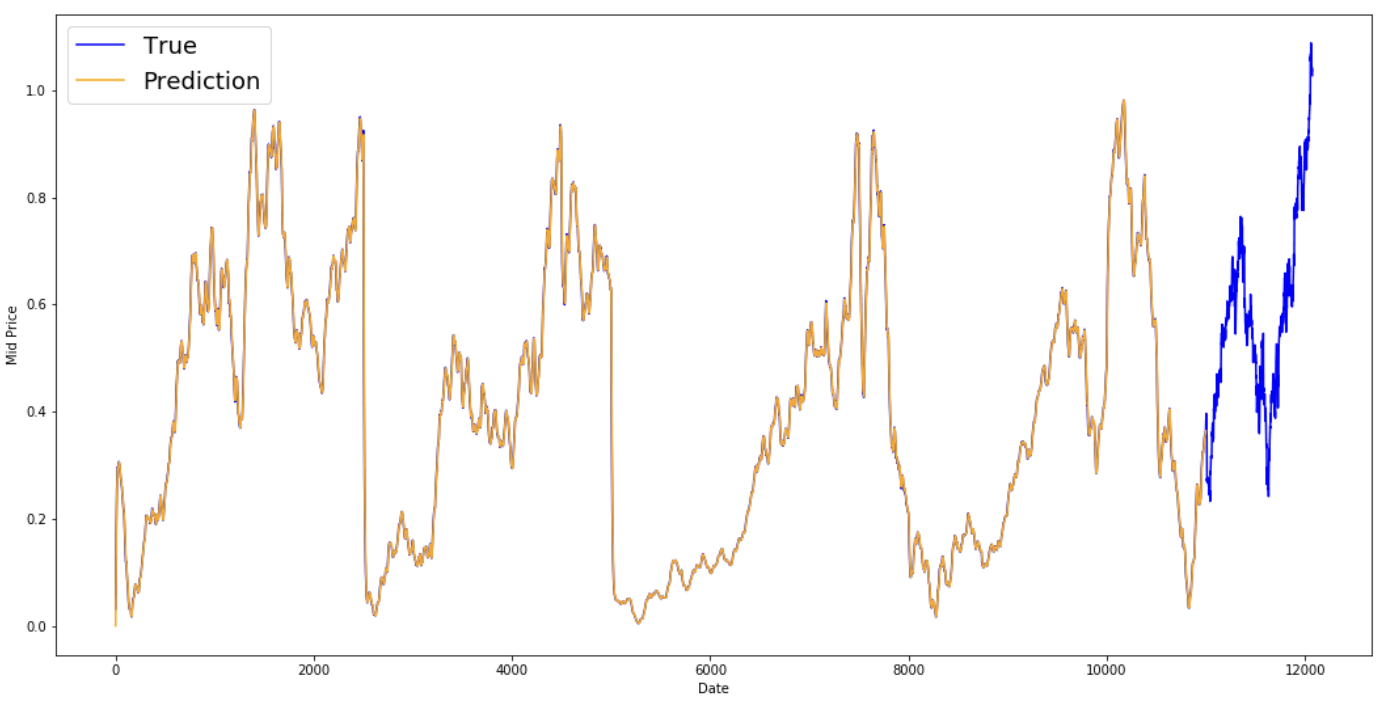
True dağılımını takip eden kusursuz bir çizgiye oturduğunu görüyorsunuz (ve çok düşük MSE ile de doğrulanıyor). Pratik açıdan bakıldığında, yalnızca ertesi günün hisse piyasa değeriyle pek bir şey yapamazsınız. Şahsen benim istediğim, ertesi günün tam hisse piyasası fiyatı değil de, önümüzdeki 30 günde hisse fiyatları yükselecek mi yoksa düşecek mi? Bunu yapmayı deneyin ve EMA yönteminin yetersizliğini ortaya çıkarın.
Şimdi, pencereler halinde tahmin yapmayı deneyin (örneğin yalnızca ertesi gün yerine, sonraki 2 günlük pencereyi tahmin edin). O zaman EMA’nın ne kadar hataya sapabileceğini fark edeceksiniz. İşte bir örnek:
Somutlaştırmak için, diyelim ki değerler $x_t=0.4$, $EMA=0.5$ ve $\gamma = 0.5$
Dolayısıyla, gelecekte kaç adım tahmin yaparsanız yapın, tüm gelecekteki tahmin adımları için aynı cevabı almaya devam edeceksiniz.
İşe yarar çıktılar elde etmek için bir çözüm, momentum tabanlı algoritmalara bakmaktır. Bunlar, (kesin değerlere değil) geçmiş yakın değerlerin yükselip yükselmediğine veya düşüp düşmediğine göre tahmin yapar. Örneğin, son birkaç gündür fiyatlar düşüyorsa, ertesi gün fiyatın muhtemelen daha düşük olacağını söyleyeceklerdir ki bu mantıklı gelir. Ancak siz daha karmaşık bir model kullanacaksınız: bir LSTM modeli.
Bu modeller, zaman serisi tahmini alanını kasıp kavuruyor çünkü zaman serisi verilerini modellemede çok iyiler. Veride gizli kalıplar olup olmadığını ve bunlardan yararlanıp yararlanamayacağınızı göreceksiniz.
Uzun-kısa süreli bellek modelleri son derece güçlü zaman serisi modelleridir. Geleceğe yönelik keyfi sayıda adımı tahmin edebilirler. Bir LSTM modülü (veya hücresi) hem uzun hem kısa vadeli veriyi modellemesine olanak tanıyan 5 temel bileşene sahiptir.
Bir hücre aşağıda resmedilmiştir:
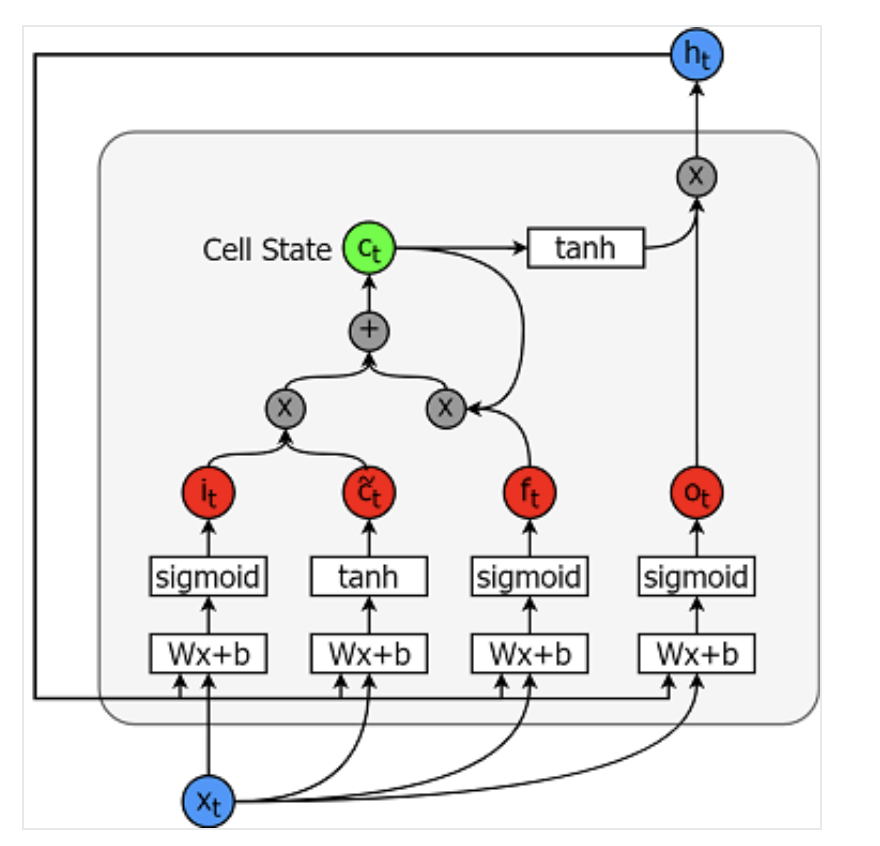
Bu öğelerin her birinin hesaplanmasına ilişkin denklemler aşağıdaki gibidir.
Daha iyi (daha teknik) bir LSTM anlayışı için bu makaleye başvurabilirsiniz.
TensorFlow, zaman serisi modellerini uygulamak için güzel bir API (RNN API) sunar. Uygulamalarınızda bunu kullanacaksınız.
Önce modelinizi eğitmek için bir veri üretici uygulayacaksınız. Bu veri üreticide, art arda elde edilen num_unrollings adet girdi veri grubunu çıktısı ile birlikte veren .unroll_batches(...) adlı bir yöntem bulunacak; burada bir veri grubu [batch_size, 1] boyutundadır. Ardından her girdi veri grubunun karşılık gelen bir çıktı veri grubu olacaktır.
Örneğin num_unrollings=3 ve batch_size=4 ise sarılmış veri kümeleri şöyle görünebilir,
Ayrıca, modelinizi sağlamlaştırmak için, $x\_t$’nin çıktısını her zaman $x\_{t+1}$ olarak yapmayacaksınız. Bunun yerine, küçük bir pencere boyutuna sahip $x\_{t+1},x\_{t+2},\ldots,x_{t+N}$ kümesinden rastgele bir çıktı örnekleyeceksiniz.
Burada şu varsayımı yapıyorsunuz:
Şahsen bunun hisse hareketi tahminleri için makul bir varsayım olduğunu düşünüyorum.
Aşağıda bir veri grubunun görsel olarak nasıl oluşturulduğunu gösteriyorsunuz.
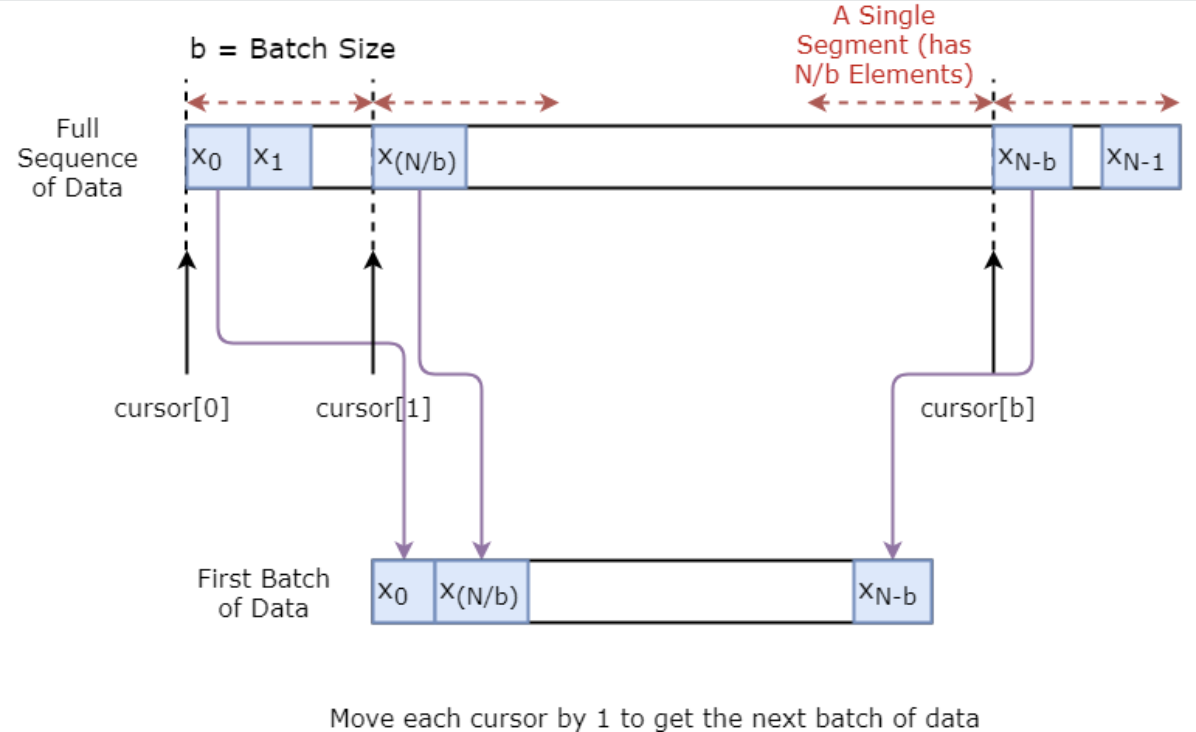
class DataGeneratorSeq(object):
def __init__(self,prices,batch_size,num_unroll):
self._prices = prices
self._prices_length = len(self._prices) - num_unroll
self._batch_size = batch_size
self._num_unroll = num_unroll
self._segments = self._prices_length //self._batch_size
self._cursor = [offset * self._segments for offset in range(self._batch_size)]
def next_batch(self):
batch_data = np.zeros((self._batch_size),dtype=np.float32)
batch_labels = np.zeros((self._batch_size),dtype=np.float32)
for b in range(self._batch_size):
if self._cursor[b]+1>=self._prices_length:
#self._cursor[b] = b * self._segments
self._cursor[b] = np.random.randint(0,(b+1)*self._segments)
batch_data[b] = self._prices[self._cursor[b]]
batch_labels[b]= self._prices[self._cursor[b]+np.random.randint(0,5)]
self._cursor[b] = (self._cursor[b]+1)%self._prices_length
return batch_data,batch_labels
def unroll_batches(self):
unroll_data,unroll_labels = [],[]
init_data, init_label = None,None
for ui in range(self._num_unroll):
data, labels = self.next_batch()
unroll_data.append(data)
unroll_labels.append(labels)
return unroll_data, unroll_labels
def reset_indices(self):
for b in range(self._batch_size):
self._cursor[b] = np.random.randint(0,min((b+1)*self._segments,self._prices_length-1))
dg = DataGeneratorSeq(train_data,5,5)
u_data, u_labels = dg.unroll_batches()
for ui,(dat,lbl) in enumerate(zip(u_data,u_labels)):
print('\n\nUnrolled index %d'%ui)
dat_ind = dat
lbl_ind = lbl
print('\tInputs: ',dat )
print('\n\tOutput:',lbl)
Unrolled index 0
Inputs: [0.03143791 0.6904868 0.82829314 0.32585657 0.11600105]
Output: [0.08698314 0.68685144 0.8329321 0.33355275 0.11785509]
Unrolled index 1
Inputs: [0.06067836 0.6890754 0.8325337 0.32857886 0.11785509]
Output: [0.15261841 0.68685144 0.8325337 0.33421066 0.12106793]
Unrolled index 2
Inputs: [0.08698314 0.68685144 0.8329321 0.33078218 0.11946969]
Output: [0.11098009 0.6848606 0.83387965 0.33421066 0.12106793]
Unrolled index 3
Inputs: [0.11098009 0.6858036 0.83294916 0.33219692 0.12106793]
Output: [0.132895 0.6836884 0.83294916 0.33219692 0.12288672]
Unrolled index 4
Inputs: [0.132895 0.6848606 0.833369 0.33355275 0.12158521]
Output: [0.15261841 0.6836884 0.83383167 0.33355275 0.12230608]
Bu bölümde birkaç hiperparametre tanımlayacaksınız. D girdinin boyutsallığıdır. Oldukça basittir; önceki hisse fiyatını girdi olarak alır ve bir sonrakini tahmin edersiniz, bu da 1 olmalıdır.
Sonra num_unrollings var; bu, LSTM modelini optimize etmek için kullanılan zaman içinde geriye yayılım (BPTT) ile ilgili bir hiperparametredir. Bu, tek bir optimizasyon adımı için kaç kesintisiz zaman adımını ele aldığınızı belirtir. Bunu, tek bir zaman adımına bakarak optimize etmek yerine, ağı num_unrollings zaman adımına bakarak optimize etmek olarak düşünebilirsiniz. Ne kadar büyük olursa o kadar iyidir.
Ardından batch_size gelir. Yığın boyutu, tek bir zaman adımında kaç veri örneğini dikkate aldığınızı ifade eder.
Sonrasında num_nodes tanımlarsınız; bu, her hücredeki gizli nöron sayısını temsil eder. Bu örnekte üç katmanlı bir LSTM yapısı olduğunu görebilirsiniz.
D = 1 # Dimensionality of the data. Since your data is 1-D this would be 1
num_unrollings = 50 # Number of time steps you look into the future.
batch_size = 500 # Number of samples in a batch
num_nodes = [200,200,150] # Number of hidden nodes in each layer of the deep LSTM stack we're using
n_layers = len(num_nodes) # number of layers
dropout = 0.2 # dropout amount
tf.reset_default_graph() # This is important in case you run this multiple times
Sonraki adımda eğitim girdileri ve etiketleri için yer tutucular tanımlarsınız. Bu oldukça basittir; her biri tek bir veri yığını içeren girdi yer tutucularından oluşan bir listeniz vardır. Ve bu liste, tek bir optimizasyon adımı için bir defada kullanılacak num_unrollings yer tutucu içerir.
# Input data.
train_inputs, train_outputs = [],[]
# You unroll the input over time defining placeholders for each time step
for ui in range(num_unrollings):
train_inputs.append(tf.placeholder(tf.float32, shape=[batch_size,D],name='train_inputs_%d'%ui))
train_outputs.append(tf.placeholder(tf.float32, shape=[batch_size,1], name = 'train_outputs_%d'%ui))
Üç katmanlı bir LSTM ve, son LSTM hücresinin çıktısını alıp bir sonraki zaman adımı tahminini üreten w ve b ile gösterilen bir doğrusal regresyon katmanınız olacak. Oluşturduğunuz üç LSTMCell nesnesini kapsüllemek için TensorFlow’daki MultiRNNCell’i kullanabilirsiniz. Ayrıca, performansı artırıp aşırı uyumu azaltan drop-out uygulamalı LSTM hücrelerine de sahip olabilirsiniz.
lstm_cells = [
tf.contrib.rnn.LSTMCell(num_units=num_nodes[li],
state_is_tuple=True,
initializer= tf.contrib.layers.xavier_initializer()
)
for li in range(n_layers)]
drop_lstm_cells = [tf.contrib.rnn.DropoutWrapper(
lstm, input_keep_prob=1.0,output_keep_prob=1.0-dropout, state_keep_prob=1.0-dropout
) for lstm in lstm_cells]
drop_multi_cell = tf.contrib.rnn.MultiRNNCell(drop_lstm_cells)
multi_cell = tf.contrib.rnn.MultiRNNCell(lstm_cells)
w = tf.get_variable('w',shape=[num_nodes[-1], 1], initializer=tf.contrib.layers.xavier_initializer())
b = tf.get_variable('b',initializer=tf.random_uniform([1],-0.1,0.1))
Bu bölümde önce, LSTM hücresinin hücre durumunu (c) ve gizli durumunu (h) tutacak TensorFlow değişkenlerini oluşturursunuz. Ardından, train_inputs listesini [num_unrollings, batch_size, D] şekline dönüştürürsünüz; bu, tf.nn.dynamic_rnn işleviyle çıktıları hesaplamak için gereklidir. Daha sonra tf.nn.dynamic_rnn işleviyle LSTM çıktıları hesaplanır ve çıktı tekrar num_unrolling tensörden oluşan bir listeye bölünür. tahminlerle gerçek hisse fiyatları arasındaki kayıp.
# Create cell state and hidden state variables to maintain the state of the LSTM
c, h = [],[]
initial_state = []
for li in range(n_layers):
c.append(tf.Variable(tf.zeros([batch_size, num_nodes[li]]), trainable=False))
h.append(tf.Variable(tf.zeros([batch_size, num_nodes[li]]), trainable=False))
initial_state.append(tf.contrib.rnn.LSTMStateTuple(c[li], h[li]))
# Do several tensor transofmations, because the function dynamic_rnn requires the output to be of
# a specific format. Read more at: https://www.tensorflow.org/api_docs/python/tf/nn/dynamic_rnn
all_inputs = tf.concat([tf.expand_dims(t,0) for t in train_inputs],axis=0)
# all_outputs is [seq_length, batch_size, num_nodes]
all_lstm_outputs, state = tf.nn.dynamic_rnn(
drop_multi_cell, all_inputs, initial_state=tuple(initial_state),
time_major = True, dtype=tf.float32)
all_lstm_outputs = tf.reshape(all_lstm_outputs, [batch_size*num_unrollings,num_nodes[-1]])
all_outputs = tf.nn.xw_plus_b(all_lstm_outputs,w,b)
split_outputs = tf.split(all_outputs,num_unrollings,axis=0)
Şimdi kaybı hesaplayacaksınız. Ancak, kayıp hesaplanırken benzersiz bir özellik olduğunu not etmelisiniz. Her bir tahmin ve gerçek çıktı yığını için Ortalama Kare Hata’yı hesaplarsınız. Ve bu ortalama kare kayıpların hepsini (ortalamasını değil) birlikte toplarsınız. Son olarak, sinir ağını optimize etmek için kullanacağınız iyileştiriciyi tanımlarsınız. Bu durumda, oldukça yeni ve iyi performans gösteren Adam’ı kullanabilirsiniz.
# When calculating the loss you need to be careful about the exact form, because you calculate
# loss of all the unrolled steps at the same time
# Therefore, take the mean error or each batch and get the sum of that over all the unrolled steps
print('Defining training Loss')
loss = 0.0
with tf.control_dependencies([tf.assign(c[li], state[li][0]) for li in range(n_layers)]+
[tf.assign(h[li], state[li][1]) for li in range(n_layers)]):
for ui in range(num_unrollings):
loss += tf.reduce_mean(0.5*(split_outputs[ui]-train_outputs[ui])**2)
print('Learning rate decay operations')
global_step = tf.Variable(0, trainable=False)
inc_gstep = tf.assign(global_step,global_step + 1)
tf_learning_rate = tf.placeholder(shape=None,dtype=tf.float32)
tf_min_learning_rate = tf.placeholder(shape=None,dtype=tf.float32)
learning_rate = tf.maximum(
tf.train.exponential_decay(tf_learning_rate, global_step, decay_steps=1, decay_rate=0.5, staircase=True),
tf_min_learning_rate)
# Optimizer.
print('TF Optimization operations')
optimizer = tf.train.AdamOptimizer(learning_rate)
gradients, v = zip(*optimizer.compute_gradients(loss))
gradients, _ = tf.clip_by_global_norm(gradients, 5.0)
optimizer = optimizer.apply_gradients(
zip(gradients, v))
print('\tAll done')
Defining training Loss
Learning rate decay operations
TF Optimization operations
All done
Burada tahminle ilgili TensorFlow işlemlerini tanımlarsınız. İlk olarak girdi beslemek için bir yer tutucu (sample_inputs) tanımlayın, sonra eğitim aşamasına benzer şekilde tahmin için durum değişkenlerini (sample_c ve sample_h) tanımlayın. Son olarak tf.nn.dynamic_rnn işleviyle tahmini hesaplayın ve ardından çıktıyı regresyon katmanından (w ve b) geçirin. Ayrıca hücre durumu ve gizli durumu sıfırlayan reset_sample_state işlemini de tanımlamalısınız. Her tahmin dizisine başladığınızda bu işlemi çalıştırmalısınız.
print('Defining prediction related TF functions')
sample_inputs = tf.placeholder(tf.float32, shape=[1,D])
# Maintaining LSTM state for prediction stage
sample_c, sample_h, initial_sample_state = [],[],[]
for li in range(n_layers):
sample_c.append(tf.Variable(tf.zeros([1, num_nodes[li]]), trainable=False))
sample_h.append(tf.Variable(tf.zeros([1, num_nodes[li]]), trainable=False))
initial_sample_state.append(tf.contrib.rnn.LSTMStateTuple(sample_c[li],sample_h[li]))
reset_sample_states = tf.group(*[tf.assign(sample_c[li],tf.zeros([1, num_nodes[li]])) for li in range(n_layers)],
*[tf.assign(sample_h[li],tf.zeros([1, num_nodes[li]])) for li in range(n_layers)])
sample_outputs, sample_state = tf.nn.dynamic_rnn(multi_cell, tf.expand_dims(sample_inputs,0),
initial_state=tuple(initial_sample_state),
time_major = True,
dtype=tf.float32)
with tf.control_dependencies([tf.assign(sample_c[li],sample_state[li][0]) for li in range(n_layers)]+
[tf.assign(sample_h[li],sample_state[li][1]) for li in range(n_layers)]):
sample_prediction = tf.nn.xw_plus_b(tf.reshape(sample_outputs,[1,-1]), w, b)
print('\tAll done')
Defining prediction related TF functions
All done
Burada birkaç dönem boyunca hisse fiyat hareketlerini eğitip tahmin edeceksiniz ve zamanla tahminlerin daha iyi mi daha kötü mü olduğuna bakacaksınız. Aşağıdaki prosedürü izlersiniz.
test_points_seq) tanımlayınnum_unrollings adet sarılmış veri grubu oluşturunnum_unrollings veri noktası üzerinden yineleme yaparak LSTM durumunu güncelleyinn_predict_once adım için tahmin yapınn_predict_once nokta ile bu zaman damgalarındaki gerçek hisse fiyatları arasındaki MSE kaybını hesaplayınepochs = 30
valid_summary = 1 # Interval you make test predictions
n_predict_once = 50 # Number of steps you continously predict for
train_seq_length = train_data.size # Full length of the training data
train_mse_ot = [] # Accumulate Train losses
test_mse_ot = [] # Accumulate Test loss
predictions_over_time = [] # Accumulate predictions
session = tf.InteractiveSession()
tf.global_variables_initializer().run()
# Used for decaying learning rate
loss_nondecrease_count = 0
loss_nondecrease_threshold = 2 # If the test error hasn't increased in this many steps, decrease learning rate
print('Initialized')
average_loss = 0
# Define data generator
data_gen = DataGeneratorSeq(train_data,batch_size,num_unrollings)
x_axis_seq = []
# Points you start your test predictions from
test_points_seq = np.arange(11000,12000,50).tolist()
for ep in range(epochs):
# ========================= Training =====================================
for step in range(train_seq_length//batch_size):
u_data, u_labels = data_gen.unroll_batches()
feed_dict = {}
for ui,(dat,lbl) in enumerate(zip(u_data,u_labels)):
feed_dict[train_inputs[ui]] = dat.reshape(-1,1)
feed_dict[train_outputs[ui]] = lbl.reshape(-1,1)
feed_dict.update({tf_learning_rate: 0.0001, tf_min_learning_rate:0.000001})
_, l = session.run([optimizer, loss], feed_dict=feed_dict)
average_loss += l
# ============================ Validation ==============================
if (ep+1) % valid_summary == 0:
average_loss = average_loss/(valid_summary*(train_seq_length//batch_size))
# The average loss
if (ep+1)%valid_summary==0:
print('Average loss at step %d: %f' % (ep+1, average_loss))
train_mse_ot.append(average_loss)
average_loss = 0 # reset loss
predictions_seq = []
mse_test_loss_seq = []
# ===================== Updating State and Making Predicitons ========================
for w_i in test_points_seq:
mse_test_loss = 0.0
our_predictions = []
if (ep+1)-valid_summary==0:
# Only calculate x_axis values in the first validation epoch
x_axis=[]
# Feed in the recent past behavior of stock prices
# to make predictions from that point onwards
for tr_i in range(w_i-num_unrollings+1,w_i-1):
current_price = all_mid_data[tr_i]
feed_dict[sample_inputs] = np.array(current_price).reshape(1,1)
_ = session.run(sample_prediction,feed_dict=feed_dict)
feed_dict = {}
current_price = all_mid_data[w_i-1]
feed_dict[sample_inputs] = np.array(current_price).reshape(1,1)
# Make predictions for this many steps
# Each prediction uses previous prediciton as it's current input
for pred_i in range(n_predict_once):
pred = session.run(sample_prediction,feed_dict=feed_dict)
our_predictions.append(np.asscalar(pred))
feed_dict[sample_inputs] = np.asarray(pred).reshape(-1,1)
if (ep+1)-valid_summary==0:
# Only calculate x_axis values in the first validation epoch
x_axis.append(w_i+pred_i)
mse_test_loss += 0.5*(pred-all_mid_data[w_i+pred_i])**2
session.run(reset_sample_states)
predictions_seq.append(np.array(our_predictions))
mse_test_loss /= n_predict_once
mse_test_loss_seq.append(mse_test_loss)
if (ep+1)-valid_summary==0:
x_axis_seq.append(x_axis)
current_test_mse = np.mean(mse_test_loss_seq)
# Learning rate decay logic
if len(test_mse_ot)>0 and current_test_mse > min(test_mse_ot):
loss_nondecrease_count += 1
else:
loss_nondecrease_count = 0
if loss_nondecrease_count > loss_nondecrease_threshold :
session.run(inc_gstep)
loss_nondecrease_count = 0
print('\tDecreasing learning rate by 0.5')
test_mse_ot.append(current_test_mse)
print('\tTest MSE: %.5f'%np.mean(mse_test_loss_seq))
predictions_over_time.append(predictions_seq)
print('\tFinished Predictions')
Initialized
Average loss at step 1: 1.703350
Test MSE: 0.00318
Finished Predictions
...
...
...
Average loss at step 30: 0.033753
Test MSE: 0.00243
Finished Predictions
Eğitim miktarı arttıkça MSE kaybının azaldığını görebilirsiniz. Bu, modelin faydalı bir şey öğrendiğinin iyi bir göstergesidir. Bulgularınızı nicelleştirmek için, ağın MSE kaybını standart ortalama alma yaparken elde ettiğiniz MSE kaybıyla (0,004) karşılaştırabilirsiniz. LSTM’nin standart ortalama almadan daha iyi performans sergilediğini görebilirsiniz. Ve standart ortalamanın (mükemmel olmasa da) gerçek hisse fiyatı hareketlerini makul ölçüde takip ettiğini biliyorsunuz.
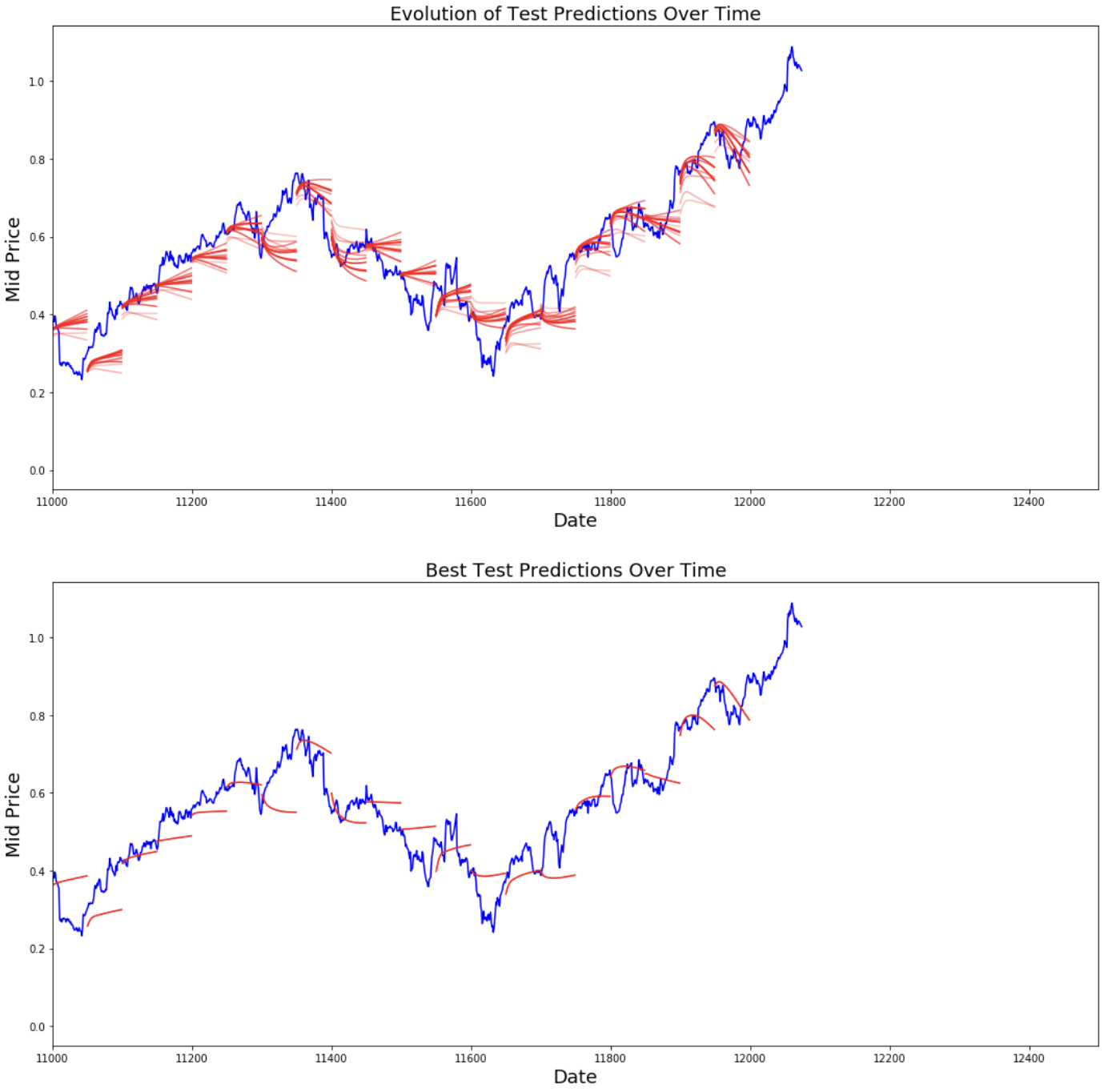
best_prediction_epoch = 28 # replace this with the epoch that you got the best results when running the plotting code plt.figure(figsize = (18,18)) plt.subplot(2,1,1) plt.plot(range(df.shape[0]),all_mid_data,color='b') # Plotting how the predictions change over time # Plot older predictions with low alpha and newer predictions with high alpha start_alpha = 0.25 alpha = np.arange(start_alpha,1.1,(1.0-start_alpha)/len(predictions_over_time[::3])) for p_i,p in enumerate(predictions_over_time[::3]): for xval,yval in zip(x_axis_seq,p): plt.plot(xval,yval,color='r',alpha=alpha[p_i]) plt.title('Evolution of Test Predictions Over Time',fontsize=18) plt.xlabel('Date',fontsize=18) plt.ylabel('Mid Price',fontsize=18) plt.xlim(11000,12500) plt.subplot(2,1,2) # Predicting the best test prediction you got plt.plot(range(df.shape[0]),all_mid_data,color='b') for xval,yval in zip(x_axis_seq,predictions_over_time[best_prediction_epoch]): plt.plot(xval,yval,color='r') plt.title('Best Test Predictions Over Time',fontsize=18) plt.xlabel('Date',fontsize=18) plt.ylabel('Mid Price',fontsize=18) plt.xlim(11000,12500) plt.show()
Mükemmel olmasa da, LSTM’ler çoğu zaman hisse fiyatı davranışını doğru tahmin edebiliyor gibi görünüyor. Unutmayın, yaklaşık 0 ile 1,0 aralığında tahminler yapıyorsunuz (yani gerçek hisse fiyatları değil). Bu sorun değil; çünkü fiyatların kendisini değil, hisse fiyatı hareketini tahmin ediyorsunuz.
Umarım bu eğitim size faydalı olmuştur. Benim için de ödüllendirici bir deneyimdi. Bu eğitimde, hisse fiyatı hareketlerini doğru tahmin edebilen bir model tasarlamanın ne kadar zor olabileceğini öğrendim. Hisse fiyatlarını neden modellemeniz gerektiğine dair bir motivasyonla başladınız. Bunu veri indirmeye ilişkin açıklama ve kod izledi. Ardından, bir adım ilerisini tahmin etmeye olanak tanıyan iki ortalama alma tekniğine baktınız. Daha sonra, gelecekte birden fazla adımı tahmin etmeniz gerektiğinde bu yöntemlerin beyhude olduğunu gördünüz. Akabinde, LSTM’leri kullanarak geleceğe dönük çok sayıda adım için nasıl tahmin yapabileceğinizi tartıştınız. Son olarak, sonuçları görselleştirdiniz ve modelinizin (mükemmel olmasa da) hisse fiyatı hareketlerini doğru tahmin etmede oldukça iyi olduğunu gördünüz.
Derin öğrenme hakkında daha fazla bilgi edinmek isterseniz, mutlaka Python ile Derin Öğrenme kursumuza göz atın. Temelleri ve Keras ile kendi sinir ağınızı nasıl kuracağınızı kapsar. Bu, bu eğitimde kullanılacak TensorFlow’dan farklı bir pakettir, ancak fikir aynıdır.
Burada, bu eğitimden çıkarılacak birkaç ders sıralıyorum.
Hisse fiyatı/hareketi tahmini son derece zor bir görevdir. Şahsen, dışarıdaki hiçbir hisse tahmin modelinin sorgusuz sualsiz kabullenilip körü körüne güvenilmemesi gerektiğini düşünüyorum. Ancak, modeller çoğu zaman hisse fiyatı hareketini doğru tahmin edebilir, ama her zaman değil.
Gerçek hisse fiyatlarıyla mükemmel şekilde çakışan tahmin eğrileri gösteren yazılara aldanmayın. Bu, basit bir ortalama tekniğiyle de tekrarlanabilir ve pratikte işe yaramaz. Daha makul olan, hisse fiyatı hareketlerini tahmin etmektir.
Modelin hiperparametreleri, elde ettiğiniz sonuçlara son derece duyarlıdır. Bu nedenle, hiperparametreler üzerinde bazı optimizasyon tekniklerini (örneğin, Izgara arama / Rastgele arama) çalıştırmak çok iyi olacaktır. Aşağıda en kritik hiperparametrelerden bazılarını listeledim:
Bu eğitimde hatalı bir şey yaptınız (veri setinin küçük olması nedeniyle)! Yani, öğrenme oranını düşürmek için test kaybını kullandınız. Bu, test kümesi hakkında bilgiyi dolaylı olarak eğitim prosedürüne sızdırır. Bunu ele almanın daha iyi yolu, ayrı bir doğrulama kümesine (test kümesinden farklı) sahip olmak ve öğrenme oranını doğrulama kümesi performansına göre düşürmektir.
Benimle iletişime geçmek isterseniz, thushv@gmail.com adresine e-posta atabilir veya LinkedIn’de bağlantı kurabilirsiniz.
Hisse tahminleri için LSTM’lerin nasıl kullanılacağını anlamak üzere bu depoya başvurdum. Ancak ayrıntılar, referansta bulunan uygulamadan büyük ölçüde farklı olabilir.
Python ve Derin Öğrenme hakkında daha fazlasını öğrenin
Kurs
Kurs
Kurs
blog
Dario Radečić
15 dk.
blog
Abid Ali Awan
14 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
