
Courses
Nhập môn Deep Learning với Python
4 giờ
264K
Trong hướng dẫn này, bạn sẽ học cách sử dụng một mô hình chuỗi thời gian gọi là Bộ nhớ Dài Ngắn hạn (Long Short-Term Memory). Mô hình LSTM rất mạnh, đặc biệt về khả năng ghi nhớ dài hạn theo thiết kế, như bạn sẽ thấy sau. Bạn sẽ xử lý các chủ đề sau trong hướng dẫn này:
Nếu bạn chưa quen với học sâu hoặc mạng nơ-ron, bạn nên xem khóa Deep Learning in Python của chúng tôi. Khóa học này bao quát các kiến thức cơ bản, cũng như cách tự xây dựng một mạng nơ-ron bằng Keras. Gói này khác với TensorFlow, vốn sẽ được dùng trong hướng dẫn này, nhưng ý tưởng thì giống nhau.
Bạn muốn mô hình hóa giá cổ phiếu một cách chính xác để với tư cách người mua cổ phiếu, bạn có thể đưa ra quyết định hợp lý khi nào nên mua và khi nào nên bán để có lợi nhuận. Đây là lúc mô hình hóa chuỗi thời gian phát huy tác dụng. Bạn cần các mô hình máy học tốt có thể nhìn vào lịch sử của một dãy dữ liệu và dự đoán chính xác các phần tử tương lai của dãy sẽ như thế nào.
Cảnh báo: Giá thị trường chứng khoán rất khó lường và biến động mạnh. Điều này có nghĩa là không có các mẫu lặp lại nhất quán trong dữ liệu cho phép bạn mô hình hóa giá cổ phiếu theo thời gian một cách gần như hoàn hảo. Đừng chỉ nghe tôi nói; hãy nghe nhà kinh tế học Burton Malkiel của Đại học Princeton, người lập luận trong cuốn sách năm 1973, "A Random Walk Down Wall Street", rằng nếu thị trường thực sự hiệu quả và giá cổ phiếu phản ánh tất cả các yếu tố ngay khi chúng được công bố, thì một con khỉ bị bịt mắt ném phi tiêu vào danh sách cổ phiếu trên báo cũng có thể làm tốt như bất kỳ chuyên gia đầu tư nào.
Tuy nhiên, đừng vội tin hoàn toàn rằng đây chỉ là quá trình ngẫu nhiên và không có hy vọng cho máy học. Hãy xem liệu bạn có thể ít nhất mô hình hóa dữ liệu sao cho các dự đoán của bạn tương quan với hành vi thực tế của dữ liệu hay không. Nói cách khác, bạn không cần chính xác các giá trị cổ phiếu trong tương lai mà là các chuyển động giá (tức là liệu nó sẽ tăng hay giảm trong tương lai gần).
# Make sure that you have all these libaries available to run the code successfully
from pandas_datareader import data
import matplotlib.pyplot as plt
import pandas as pd
import datetime as dt
import urllib.request, json
import os
import numpy as np
import tensorflow as tf # This code has been tested with TensorFlow 1.6
from sklearn.preprocessing import MinMaxScalerBạn sẽ dùng dữ liệu từ các nguồn sau:
Alpha Vantage Stock API. Trước khi bắt đầu, bạn cần một khóa API, có thể nhận miễn phí tại đây. Sau đó, bạn gán khóa đó cho biến api_key. Hướng dẫn này sẽ truy xuất 20 năm dữ liệu lịch sử cho cổ phiếu American Airlines. Đọc thêm tùy chọn: bạn có thể tham khảo hướng dẫn khởi đầu về API cổ phiếu để biết các thực hành tốt nhất khi làm việc với dữ liệu thị trường lịch sử.
Dùng dữ liệu từ trang này. Sao chép thư mục Stocks trong tệp zip vào thư mục gốc dự án của bạn.
Giá cổ phiếu có một số dạng khác nhau. Bao gồm,
Trước tiên bạn sẽ tải dữ liệu từ Alpha Vantage. Vì bạn sẽ sử dụng giá cổ phiếu American Airlines để dự đoán, bạn đặt mã cổ phiếu là "AAL". Ngoài ra, bạn cũng định nghĩa một url_string, sẽ trả về một tệp JSON với tất cả dữ liệu thị trường của American Airlines trong 20 năm qua, và một file_to_save, là tệp để lưu dữ liệu. Bạn sẽ dùng biến ticker đã định nghĩa trước đó để hỗ trợ đặt tên tệp này.
Tiếp theo, bạn sẽ chỉ định một điều kiện: nếu bạn chưa lưu dữ liệu, bạn sẽ lấy dữ liệu từ URL được đặt trong url_string; Bạn sẽ lưu trữ các giá trị date, low, high, volume, close, open vào một pandas DataFrame df và lưu nó vào file_to_save. Tuy nhiên, nếu dữ liệu đã có, bạn chỉ cần tải nó từ tệp CSV.
Dữ liệu trên Kaggle là một tập hợp các tệp CSV, và bạn không cần tiền xử lý, nên có thể tải trực tiếp vào một Pandas DataFrame.
data_source = 'kaggle' # alphavantage or kaggle
if data_source == 'alphavantage':
# ====================== Loading Data from Alpha Vantage ==================================
api_key = '<your API key>'
# American Airlines stock market prices
ticker = "AAL"
# JSON file with all the stock market data for AAL from the last 20 years
url_string = "https://www.alphavantage.co/query?function=TIME_SERIES_DAILY&symbol=%s&outputsize=full&apikey=%s"%(ticker,api_key)
# Save data to this file
file_to_save = 'stock_market_data-%s.csv'%ticker
# If you haven't already saved data,
# Go ahead and grab the data from the url
# And store date, low, high, volume, close, open values to a Pandas DataFrame
if not os.path.exists(file_to_save):
with urllib.request.urlopen(url_string) as url:
data = json.loads(url.read().decode())
# extract stock market data
data = data['Time Series (Daily)']
df = pd.DataFrame(columns=['Date','Low','High','Close','Open'])
for k,v in data.items():
date = dt.datetime.strptime(k, '%Y-%m-%d')
data_row = [date.date(),float(v['3. low']),float(v['2. high']),
float(v['4. close']),float(v['1. open'])]
df.loc[-1,:] = data_row
df.index = df.index + 1
print('Data saved to : %s'%file_to_save)
df.to_csv(file_to_save)
# If the data is already there, just load it from the CSV
else:
print('File already exists. Loading data from CSV')
df = pd.read_csv(file_to_save)
else:
# ====================== Loading Data from Kaggle ==================================
# You will be using HP's data. Feel free to experiment with other data.
# But while doing so, be careful to have a large enough dataset and also pay attention to the data normalization
df = pd.read_csv(os.path.join('Stocks','hpq.us.txt'),delimiter=',',usecols=['Date','Open','High','Low','Close'])
print('Loaded data from the Kaggle repository')
Data saved to : stock_market_data-AAL.csv
Tại đây, bạn sẽ in dữ liệu đã thu thập vào DataFrame. Bạn cũng nên đảm bảo dữ liệu được sắp xếp theo ngày vì thứ tự dữ liệu rất quan trọng trong mô hình hóa chuỗi thời gian.
# Sort DataFrame by date
df = df.sort_values('Date')
# Double check the result
df.head()
| Ngày | Mở cửa | Cao nhất | Thấp nhất | Đóng cửa | |
|---|---|---|---|---|---|
| 0 | 1970-01-02 | 0.30627 | 0.30627 | 0.30627 | 0.30627 |
| 1 | 1970-01-05 | 0.30627 | 0.31768 | 0.30627 | 0.31385 |
| 2 | 1970-01-06 | 0.31385 | 0.31385 | 0.30996 | 0.30996 |
| 3 | 1970-01-07 | 0.31385 | 0.31385 | 0.31385 | 0.31385 |
| 4 | 1970-01-08 | 0.31385 | 0.31768 | 0.31385 | 0.31385 |
Giờ hãy xem bạn có kiểu dữ liệu nào. Bạn muốn dữ liệu có nhiều mẫu hình xuất hiện theo thời gian.
plt.figure(figsize = (18,9))
plt.plot(range(df.shape[0]),(df['Low']+df['High'])/2.0)
plt.xticks(range(0,df.shape[0],500),df['Date'].loc[::500],rotation=45)
plt.xlabel('Date',fontsize=18)
plt.ylabel('Mid Price',fontsize=18)
plt.show()
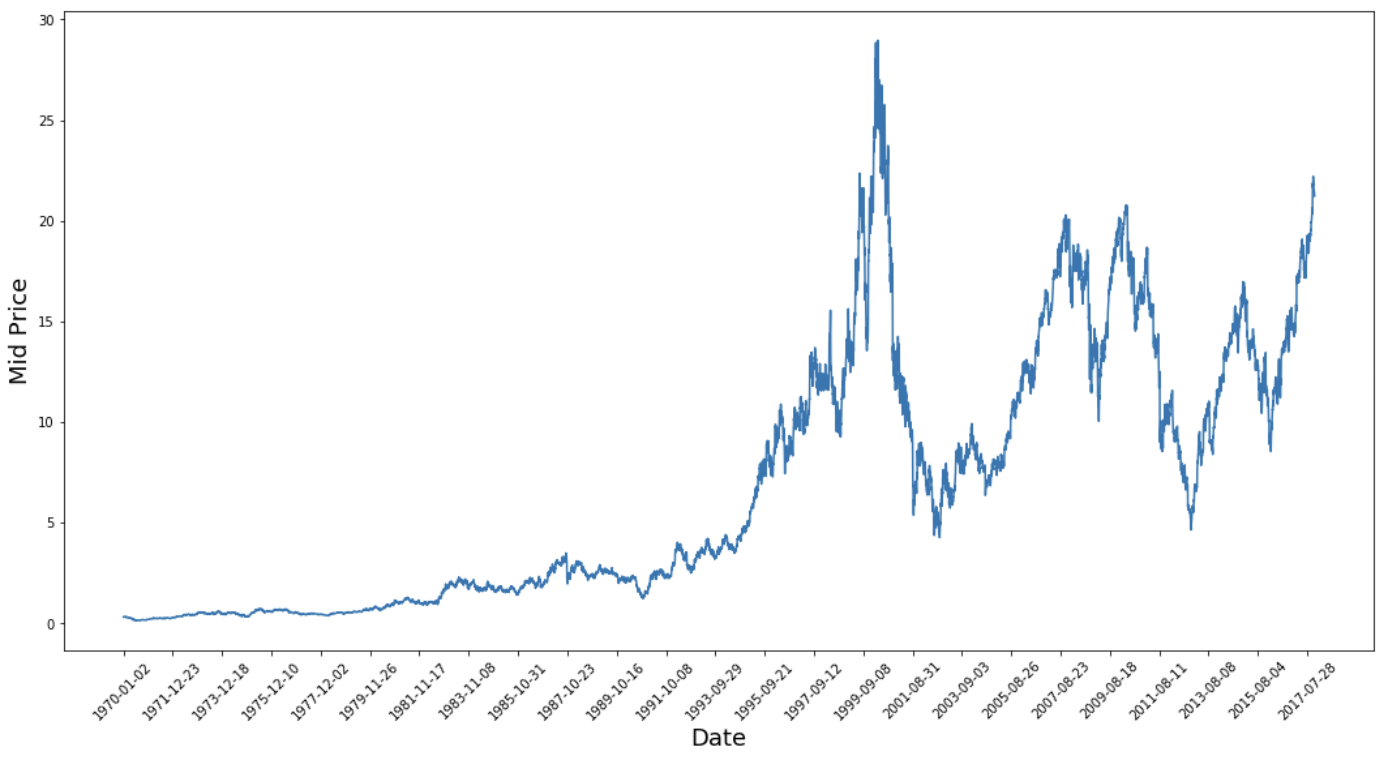
Biểu đồ này đã nói lên nhiều điều. Lý do cụ thể tôi chọn công ty này thay vì những công ty khác là vì nó có rất nhiều hành vi giá cổ phiếu khác nhau theo thời gian. Điều này sẽ làm cho việc học trở nên vững vàng hơn và cho bạn cơ hội kiểm tra chất lượng dự đoán trong nhiều tình huống.
Một điểm khác cần lưu ý là các giá trị gần 2017 cao hơn nhiều và dao động mạnh hơn so với giai đoạn những năm 1970. Do đó, bạn cần đảm bảo dữ liệu có hành vi trong những khoảng giá trị tương tự trong suốt khung thời gian. Bạn sẽ xử lý điều này trong giai đoạn chuẩn hóa dữ liệu.
Bạn sẽ dùng giá giữa, được tính bằng trung bình của giá cao nhất và thấp nhất được ghi nhận trong ngày.
# First calculate the mid prices from the highest and lowest
high_prices = df.loc[:,'High'].as_matrix()
low_prices = df.loc[:,'Low'].as_matrix()
mid_prices = (high_prices+low_prices)/2.0
Giờ bạn có thể tách dữ liệu huấn luyện và dữ liệu kiểm thử. Dữ liệu huấn luyện sẽ là 11.000 điểm dữ liệu đầu tiên của chuỗi thời gian, phần còn lại là dữ liệu kiểm thử.
train_data = mid_prices[:11000]
test_data = mid_prices[11000:]
Giờ bạn cần định nghĩa một bộ biến đổi để chuẩn hóa dữ liệu. MinMaxScalar co giãn tất cả dữ liệu về khoảng từ 0 đến 1. Bạn cũng có thể reshape dữ liệu huấn luyện và kiểm thử về dạng [data_size, num_features].
# Scale the data to be between 0 and 1
# When scaling remember! You normalize both test and train data with respect to training data
# Because you are not supposed to have access to test data
scaler = MinMaxScaler()
train_data = train_data.reshape(-1,1)
test_data = test_data.reshape(-1,1)
Do quan sát trước đó rằng các giai đoạn thời gian khác nhau có các khoảng giá trị khác nhau, bạn chuẩn hóa dữ liệu bằng cách chia chuỗi đầy đủ thành các cửa sổ. Nếu không làm vậy, dữ liệu sớm sẽ gần 0 và không đóng góp nhiều cho quá trình học. Ở đây, bạn chọn kích thước cửa sổ là 2500.
Mẹo: Khi chọn kích thước cửa sổ, đảm bảo nó không quá nhỏ. Khi bạn chuẩn hóa theo cửa sổ, có thể xuất hiện điểm gãy ở cuối mỗi cửa sổ, do mỗi cửa sổ được chuẩn hóa độc lập.
Trong ví dụ này, 4 điểm dữ liệu sẽ bị ảnh hưởng. Nhưng với 11.000 điểm dữ liệu, 4 điểm sẽ không gây vấn đề.
# Train the Scaler with training data and smooth data
smoothing_window_size = 2500
for di in range(0,10000,smoothing_window_size):
scaler.fit(train_data[di:di+smoothing_window_size,:])
train_data[di:di+smoothing_window_size,:] = scaler.transform(train_data[di:di+smoothing_window_size,:])
# You normalize the last bit of remaining data
scaler.fit(train_data[di+smoothing_window_size:,:])
train_data[di+smoothing_window_size:,:] = scaler.transform(train_data[di+smoothing_window_size:,:])
Đưa dữ liệu về lại dạng [data_size]
# Reshape both train and test data
train_data = train_data.reshape(-1)
# Normalize test data
test_data = scaler.transform(test_data).reshape(-1)
Bây giờ bạn có thể làm mượt dữ liệu bằng trung bình động hàm mũ. Điều này giúp loại bỏ độ gồ ghề vốn có của giá cổ phiếu và tạo ra đường cong mượt hơn.
Lưu ý rằng bạn chỉ nên làm mượt dữ liệu huấn luyện.
# Now perform exponential moving average smoothing
# So the data will have a smoother curve than the original ragged data
EMA = 0.0
gamma = 0.1
for ti in range(11000):
EMA = gamma*train_data[ti] + (1-gamma)*EMA
train_data[ti] = EMA
# Used for visualization and test purposes
all_mid_data = np.concatenate([train_data,test_data],axis=0)
Cơ chế lấy trung bình cho phép bạn dự đoán (thường là một bước thời gian phía trước) bằng cách biểu diễn giá cổ phiếu tương lai như trung bình của các giá cổ phiếu quan sát trước đó. Làm điều này cho nhiều hơn một bước thời gian có thể cho kết quả khá tệ. Bạn sẽ xem xét hai kỹ thuật lấy trung bình: lấy trung bình tiêu chuẩn và trung bình động hàm mũ. Bạn sẽ đánh giá cả định tính (quan sát trực quan) và định lượng (Sai số Bình phương Trung bình - MSE) các kết quả do hai thuật toán tạo ra.
MSE có thể được tính bằng cách lấy bình phương sai số giữa giá trị thật ở một bước phía trước và giá trị dự đoán, rồi lấy trung bình trên tất cả dự đoán.
Bạn có thể hiểu mức độ khó của bài toán này bằng cách trước tiên thử mô hình hóa như một bài toán tính trung bình. Đầu tiên, bạn sẽ cố dự đoán giá cổ phiếu tương lai (ví dụ, xt+1) như trung bình của các giá cổ phiếu đã quan sát trong một cửa sổ kích thước cố định (ví dụ, xt-N, ..., xt) (giả sử 100 ngày trước). Sau đó, bạn sẽ thử phương pháp “trung bình động hàm mũ” phức tạp hơn một chút và xem nó hiệu quả thế nào. Rồi bạn sẽ chuyển sang “chén thánh” của dự đoán chuỗi thời gian: các mô hình LSTM.
Trước hết, bạn sẽ xem cách lấy trung bình thông thường hoạt động. Tức là, bạn nói,
Nói cách khác, bạn nói dự đoán tại $t+1$ là giá trị trung bình của tất cả giá cổ phiếu bạn quan sát trong một cửa sổ từ $t$ đến $t-N$.
window_size = 100
N = train_data.size
std_avg_predictions = []
std_avg_x = []
mse_errors = []
for pred_idx in range(window_size,N):
if pred_idx >= N:
date = dt.datetime.strptime(k, '%Y-%m-%d').date() + dt.timedelta(days=1)
else:
date = df.loc[pred_idx,'Date']
std_avg_predictions.append(np.mean(train_data[pred_idx-window_size:pred_idx]))
mse_errors.append((std_avg_predictions[-1]-train_data[pred_idx])**2)
std_avg_x.append(date)
print('MSE error for standard averaging: %.5f'%(0.5*np.mean(mse_errors)))
MSE error for standard averaging: 0.00418
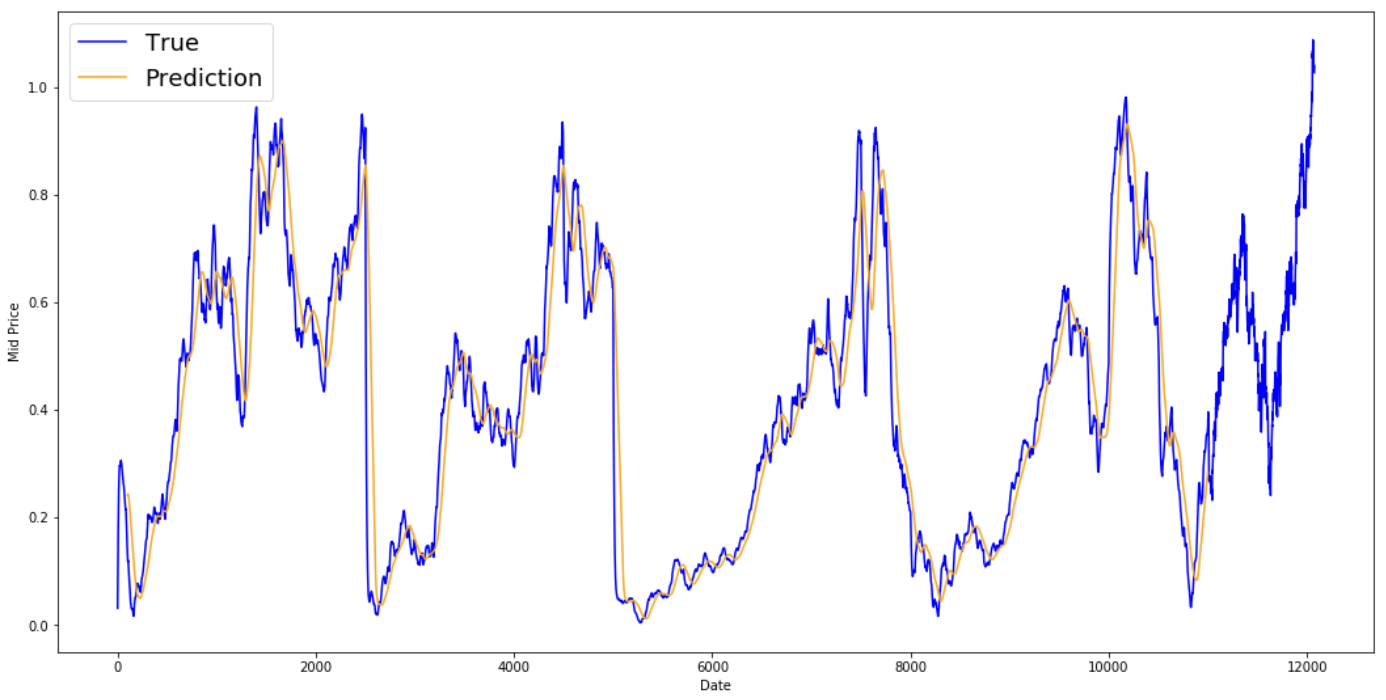
Hãy xem các kết quả đã lấy trung bình dưới đây. Chúng bám khá sát hành vi thực tế của cổ phiếu. Tiếp theo, bạn sẽ xem một phương pháp dự đoán một bước chính xác hơn.
plt.figure(figsize = (18,9)) plt.plot(range(df.shape[0]),all_mid_data,color='b',label='True') plt.plot(range(window_size,N),std_avg_predictions,color='orange',label='Prediction') #plt.xticks(range(0,df.shape[0],50),df['Date'].loc[::50],rotation=45) plt.xlabel('Date') plt.ylabel('Mid Price') plt.legend(fontsize=18) plt.show()
Vậy các biểu đồ trên (và MSE) nói gì?
Có vẻ đây không phải là mô hình tệ cho các dự đoán rất ngắn hạn (một ngày tới). Hành vi này hợp lý vì giá cổ phiếu không thay đổi từ 0 lên 100 chỉ sau một đêm. Tiếp theo, bạn sẽ xem kỹ thuật lấy trung bình tinh vi hơn, trung bình động hàm mũ.
Bạn có thể đã thấy một số bài viết trên mạng dùng các mô hình rất phức tạp và dự đoán gần như chính xác hành vi thị trường chứng khoán. Nhưng hãy cẩn thận! Đây chỉ là ảo giác thị giác chứ không phải do học được điều gì hữu ích. Bạn sẽ thấy bên dưới cách bạn có thể tái tạo hành vi đó với một phương pháp lấy trung bình đơn giản.
Trong phương pháp trung bình động hàm mũ, bạn tính $x_{t+1}$ như sau,
Phương trình trên về cơ bản tính trung bình động hàm mũ từ thời điểm $t+1$ và dùng nó làm dự đoán một bước phía trước. $\gamma$ quyết định mức đóng góp của dự đoán gần nhất vào EMA. Ví dụ, $\gamma=0.1$ chỉ lấy 10% giá trị hiện tại vào EMA. Vì bạn chỉ lấy một phần rất nhỏ của giá trị gần nhất, nó cho phép giữ lại nhiều giá trị cũ đã thấy từ rất sớm trong trung bình. Xem nó trông “đẹp” thế nào khi dùng để dự đoán một bước phía trước bên dưới.
window_size = 100
N = train_data.size
run_avg_predictions = []
run_avg_x = []
mse_errors = []
running_mean = 0.0
run_avg_predictions.append(running_mean)
decay = 0.5
for pred_idx in range(1,N):
running_mean = running_mean*decay + (1.0-decay)*train_data[pred_idx-1]
run_avg_predictions.append(running_mean)
mse_errors.append((run_avg_predictions[-1]-train_data[pred_idx])**2)
run_avg_x.append(date)
print('MSE error for EMA averaging: %.5f'%(0.5*np.mean(mse_errors)))
MSE error for EMA averaging: 0.00003
plt.figure(figsize = (18,9))
plt.plot(range(df.shape[0]),all_mid_data,color='b',label='True')
plt.plot(range(0,N),run_avg_predictions,color='orange', label='Prediction')
#plt.xticks(range(0,df.shape[0],50),df['Date'].loc[::50],rotation=45)
plt.xlabel('Date')
plt.ylabel('Mid Price')
plt.legend(fontsize=18)
plt.show()
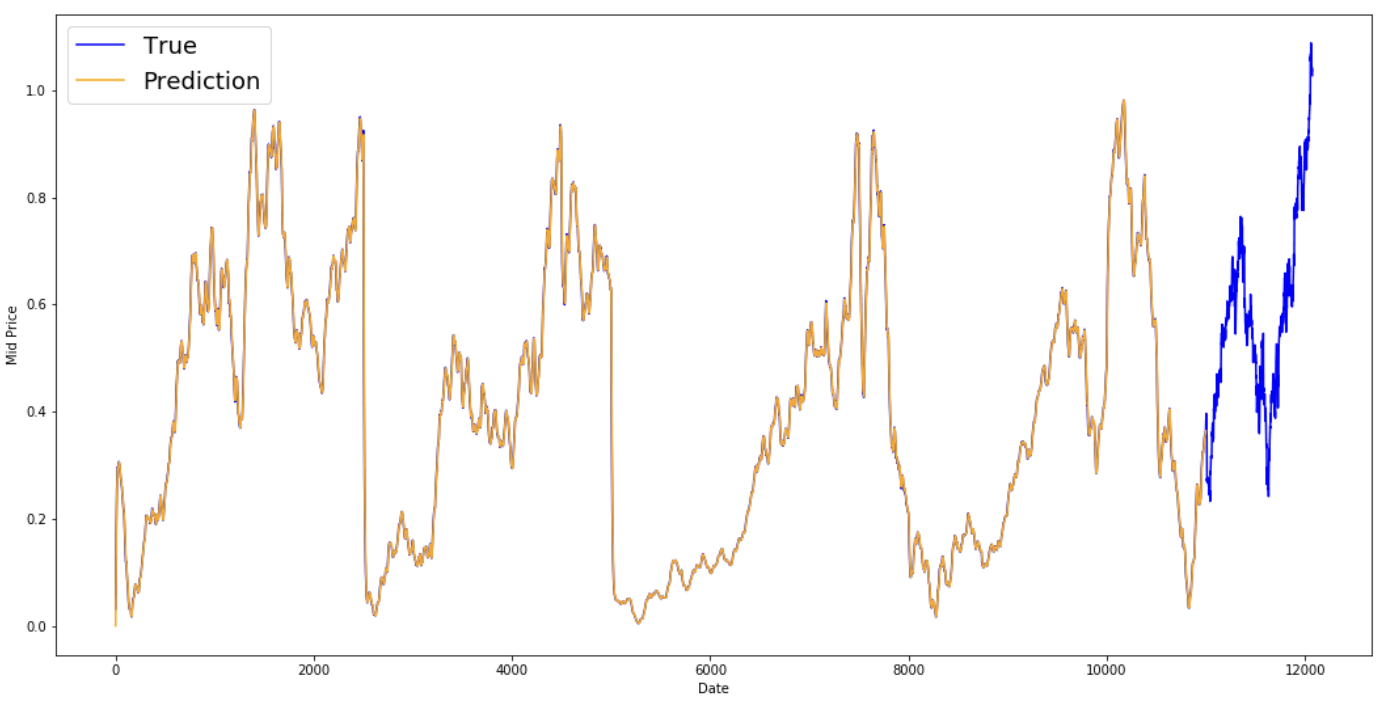
Bạn thấy nó khớp một đường hoàn hảo theo phân phối True (và được xác nhận bởi MSE rất thấp). Thực tế, bạn không làm được nhiều với chỉ giá trị thị trường ngày hôm sau. Cá nhân tôi, điều tôi muốn không phải là giá thị trường chính xác của ngày mai, mà là giá cổ phiếu sẽ tăng hay giảm trong 30 ngày tới? Hãy thử làm điều này, và bạn sẽ thấy EMA bất lực.
Giờ bạn sẽ thử dự đoán theo cửa sổ (giả sử bạn dự đoán cửa sổ 2 ngày tiếp theo, thay vì chỉ ngày kế tiếp). Khi đó bạn sẽ nhận ra EMA có thể sai đến mức nào. Đây là một ví dụ:
Để cụ thể, giả sử các giá trị, $x_t=0.4$, $EMA=0.5$ và $\gamma = 0.5$
Vì vậy, dù bạn dự đoán bao nhiêu bước trong tương lai, bạn vẫn sẽ nhận cùng một đáp án cho tất cả các bước dự đoán.
Một giải pháp có thể cung cấp thông tin hữu ích là xem các thuật toán dựa trên động lượng. Chúng đưa ra dự đoán dựa trên việc các giá trị gần đây tăng hay giảm (không phải giá trị tuyệt đối). Ví dụ, chúng sẽ nói giá ngày mai có khả năng thấp hơn nếu giá đã giảm trong vài ngày qua, điều này nghe hợp lý. Tuy nhiên, bạn sẽ dùng một mô hình phức tạp hơn: mô hình LSTM.
Những mô hình này đã làm mưa làm gió trong lĩnh vực dự đoán chuỗi thời gian vì chúng rất giỏi trong việc mô hình hóa dữ liệu chuỗi. Bạn sẽ xem liệu thực sự có các mẫu ẩn trong dữ liệu mà bạn có thể khai thác hay không.
Các mô hình bộ nhớ dài ngắn hạn cực kỳ mạnh cho chuỗi thời gian. Chúng có thể dự đoán một số bước tùy ý trong tương lai. Một mô-đun (hay cell) LSTM có 5 thành phần thiết yếu, cho phép mô hình hóa cả dữ liệu ngắn hạn và dài hạn.
Một ô được minh họa bên dưới:
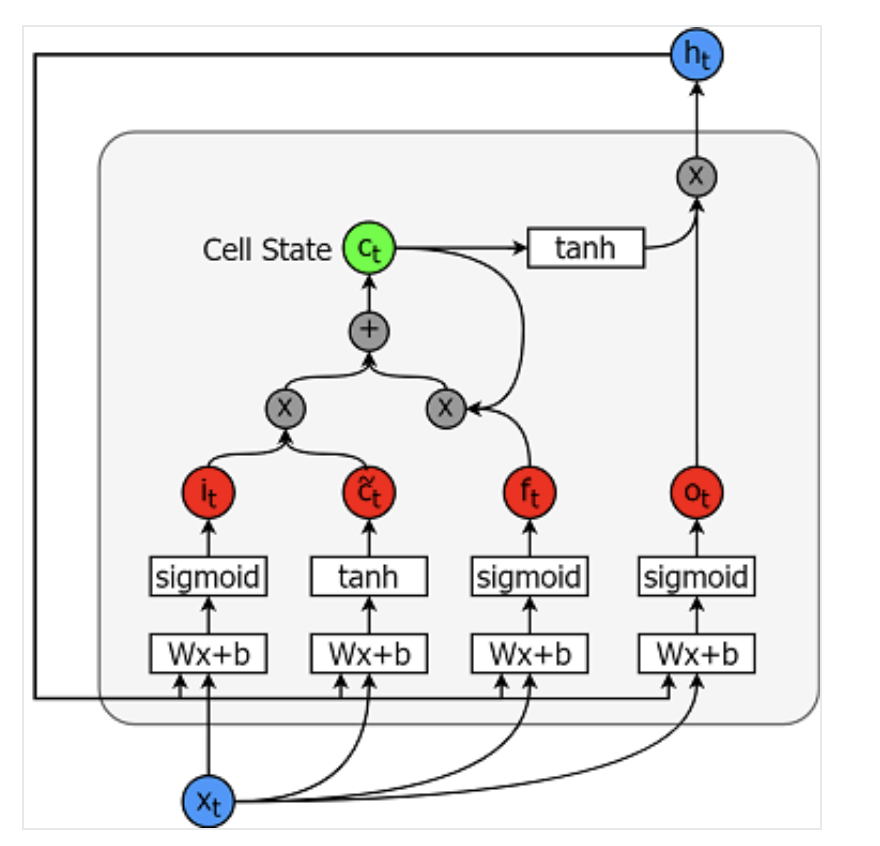
Các phương trình để tính mỗi thực thể như sau.
Bạn có thể tham khảo bài viết này để có hiểu biết (kỹ thuật) sâu hơn về LSTM.
TensorFlow cung cấp một API hay (gọi là RNN API) để triển khai các mô hình chuỗi thời gian. Bạn sẽ dùng nó cho các triển khai của mình.
Trước tiên bạn sẽ triển khai một bộ sinh dữ liệu để huấn luyện mô hình. Bộ sinh dữ liệu này sẽ có phương thức .unroll_batches(...) xuất ra một tập các lô dữ liệu đầu vào num_unrollings thu được tuần tự, trong đó một lô dữ liệu có kích thước [batch_size, 1]. Sau đó, mỗi lô đầu vào sẽ có một lô đầu ra tương ứng.
Ví dụ nếu num_unrollings=3 và batch_size=4 một tập lô đã cuộn có thể trông như,
Đồng thời, để làm mô hình của bạn vững vàng, bạn sẽ không đặt đầu ra cho $x\_t$ luôn là $x\_{t+1}$. Thay vào đó, bạn sẽ lấy mẫu ngẫu nhiên một đầu ra từ tập $x\_{t+1},x\_{t+2},\ldots,x_{t+N}$ trong đó $N$ là kích thước cửa sổ nhỏ.
Ở đây, bạn đưa ra giả định sau:
Cá nhân tôi nghĩ đây là giả định hợp lý cho dự đoán chuyển động cổ phiếu.
Bên dưới, bạn minh họa trực quan cách một lô dữ liệu được tạo.
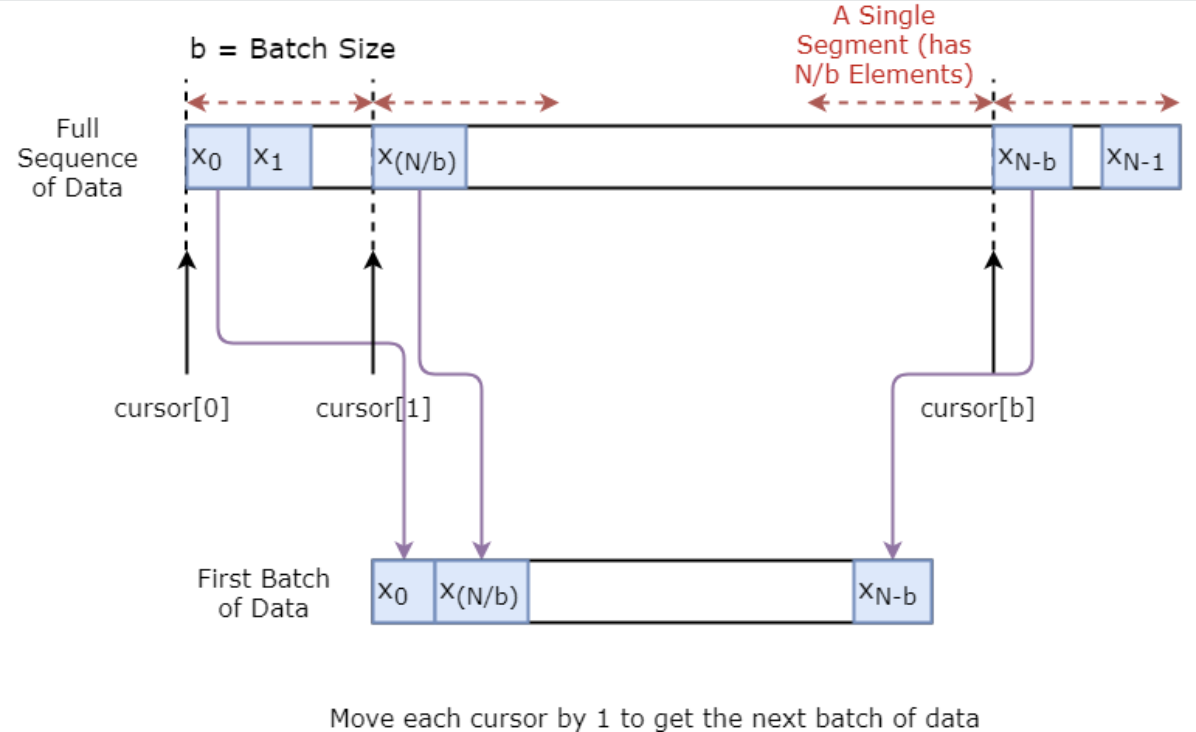
class DataGeneratorSeq(object):
def __init__(self,prices,batch_size,num_unroll):
self._prices = prices
self._prices_length = len(self._prices) - num_unroll
self._batch_size = batch_size
self._num_unroll = num_unroll
self._segments = self._prices_length //self._batch_size
self._cursor = [offset * self._segments for offset in range(self._batch_size)]
def next_batch(self):
batch_data = np.zeros((self._batch_size),dtype=np.float32)
batch_labels = np.zeros((self._batch_size),dtype=np.float32)
for b in range(self._batch_size):
if self._cursor[b]+1>=self._prices_length:
#self._cursor[b] = b * self._segments
self._cursor[b] = np.random.randint(0,(b+1)*self._segments)
batch_data[b] = self._prices[self._cursor[b]]
batch_labels[b]= self._prices[self._cursor[b]+np.random.randint(0,5)]
self._cursor[b] = (self._cursor[b]+1)%self._prices_length
return batch_data,batch_labels
def unroll_batches(self):
unroll_data,unroll_labels = [],[]
init_data, init_label = None,None
for ui in range(self._num_unroll):
data, labels = self.next_batch()
unroll_data.append(data)
unroll_labels.append(labels)
return unroll_data, unroll_labels
def reset_indices(self):
for b in range(self._batch_size):
self._cursor[b] = np.random.randint(0,min((b+1)*self._segments,self._prices_length-1))
dg = DataGeneratorSeq(train_data,5,5)
u_data, u_labels = dg.unroll_batches()
for ui,(dat,lbl) in enumerate(zip(u_data,u_labels)):
print('\n\nUnrolled index %d'%ui)
dat_ind = dat
lbl_ind = lbl
print('\tInputs: ',dat )
print('\n\tOutput:',lbl)
Unrolled index 0
Inputs: [0.03143791 0.6904868 0.82829314 0.32585657 0.11600105]
Output: [0.08698314 0.68685144 0.8329321 0.33355275 0.11785509]
Unrolled index 1
Inputs: [0.06067836 0.6890754 0.8325337 0.32857886 0.11785509]
Output: [0.15261841 0.68685144 0.8325337 0.33421066 0.12106793]
Unrolled index 2
Inputs: [0.08698314 0.68685144 0.8329321 0.33078218 0.11946969]
Output: [0.11098009 0.6848606 0.83387965 0.33421066 0.12106793]
Unrolled index 3
Inputs: [0.11098009 0.6858036 0.83294916 0.33219692 0.12106793]
Output: [0.132895 0.6836884 0.83294916 0.33219692 0.12288672]
Unrolled index 4
Inputs: [0.132895 0.6848606 0.833369 0.33355275 0.12158521]
Output: [0.15261841 0.6836884 0.83383167 0.33355275 0.12230608]
Trong phần này, bạn sẽ định nghĩa một số siêu tham số. D là số chiều của đầu vào. Điều này đơn giản vì bạn lấy giá cổ phiếu trước đó làm đầu vào và dự đoán giá tiếp theo, nên sẽ là 1.
Tiếp theo là num_unrollings, đây là siêu tham số liên quan đến lan truyền ngược theo thời gian (BPTT) dùng để tối ưu mô hình LSTM. Nó biểu thị bạn xét bao nhiêu bước thời gian liên tục cho một bước tối ưu. Bạn có thể hiểu là, thay vì tối ưu mô hình bằng cách nhìn vào một bước thời gian, bạn tối ưu mạng bằng cách nhìn vào num_unrollings bước. Càng lớn càng tốt.
Rồi bạn có batch_size. Kích thước lô là số mẫu dữ liệu bạn xét trong một bước thời gian.
Tiếp theo bạn định nghĩa num_nodes đại diện số nơ-ron ẩn trong mỗi ô. Bạn có thể thấy có ba lớp LSTM trong ví dụ này.
D = 1 # Dimensionality of the data. Since your data is 1-D this would be 1
num_unrollings = 50 # Number of time steps you look into the future.
batch_size = 500 # Number of samples in a batch
num_nodes = [200,200,150] # Number of hidden nodes in each layer of the deep LSTM stack we're using
n_layers = len(num_nodes) # number of layers
dropout = 0.2 # dropout amount
tf.reset_default_graph() # This is important in case you run this multiple times
Tiếp theo, bạn định nghĩa các placeholder cho đầu vào huấn luyện và nhãn. Điều này khá thẳng thắn vì bạn có một danh sách các placeholder đầu vào, mỗi placeholder chứa một lô dữ liệu. Và danh sách có num_unrollings placeholder, sẽ được dùng cùng lúc cho một bước tối ưu.
# Input data.
train_inputs, train_outputs = [],[]
# You unroll the input over time defining placeholders for each time step
for ui in range(num_unrollings):
train_inputs.append(tf.placeholder(tf.float32, shape=[batch_size,D],name='train_inputs_%d'%ui))
train_outputs.append(tf.placeholder(tf.float32, shape=[batch_size,1], name = 'train_outputs_%d'%ui))
Bạn sẽ có ba lớp LSTM và một lớp hồi quy tuyến tính, ký hiệu bởi w và b, nhận đầu ra của ô LSTM cuối cùng và xuất dự đoán cho bước thời gian tiếp theo. Bạn có thể dùng MultiRNNCell trong TensorFlow để bao gói ba đối tượng LSTMCell bạn tạo. Ngoài ra, bạn có thể dùng các ô LSTM có dropout, vì chúng cải thiện hiệu năng và giảm quá khớp.
lstm_cells = [
tf.contrib.rnn.LSTMCell(num_units=num_nodes[li],
state_is_tuple=True,
initializer= tf.contrib.layers.xavier_initializer()
)
for li in range(n_layers)]
drop_lstm_cells = [tf.contrib.rnn.DropoutWrapper(
lstm, input_keep_prob=1.0,output_keep_prob=1.0-dropout, state_keep_prob=1.0-dropout
) for lstm in lstm_cells]
drop_multi_cell = tf.contrib.rnn.MultiRNNCell(drop_lstm_cells)
multi_cell = tf.contrib.rnn.MultiRNNCell(lstm_cells)
w = tf.get_variable('w',shape=[num_nodes[-1], 1], initializer=tf.contrib.layers.xavier_initializer())
b = tf.get_variable('b',initializer=tf.random_uniform([1],-0.1,0.1))
Trong phần này, trước tiên bạn tạo các biến TensorFlow (c và h) để giữ trạng thái ô và trạng thái ẩn của ô LSTM. Sau đó bạn biến đổi danh sách train_inputs thành dạng [num_unrollings, batch_size, D], điều này cần thiết để tính đầu ra với hàm tf.nn.dynamic_rnn. Rồi bạn tính đầu ra LSTM bằng hàm tf.nn.dynamic_rnn và tách đầu ra trở lại thành danh sách num_unrolling tensor. phần mất mát giữa các dự đoán và giá cổ phiếu thật.
# Create cell state and hidden state variables to maintain the state of the LSTM
c, h = [],[]
initial_state = []
for li in range(n_layers):
c.append(tf.Variable(tf.zeros([batch_size, num_nodes[li]]), trainable=False))
h.append(tf.Variable(tf.zeros([batch_size, num_nodes[li]]), trainable=False))
initial_state.append(tf.contrib.rnn.LSTMStateTuple(c[li], h[li]))
# Do several tensor transofmations, because the function dynamic_rnn requires the output to be of
# a specific format. Read more at: https://www.tensorflow.org/api_docs/python/tf/nn/dynamic_rnn
all_inputs = tf.concat([tf.expand_dims(t,0) for t in train_inputs],axis=0)
# all_outputs is [seq_length, batch_size, num_nodes]
all_lstm_outputs, state = tf.nn.dynamic_rnn(
drop_multi_cell, all_inputs, initial_state=tuple(initial_state),
time_major = True, dtype=tf.float32)
all_lstm_outputs = tf.reshape(all_lstm_outputs, [batch_size*num_unrollings,num_nodes[-1]])
all_outputs = tf.nn.xw_plus_b(all_lstm_outputs,w,b)
split_outputs = tf.split(all_outputs,num_unrollings,axis=0)
Bây giờ bạn sẽ tính mất mát. Tuy nhiên, bạn nên lưu ý rằng có một đặc điểm riêng khi tính mất mát. Với mỗi lô dự đoán và đầu ra thật, bạn tính MSE. Và bạn cộng (không lấy trung bình) tất cả các mất mát bình phương trung bình này lại. Cuối cùng bạn định nghĩa bộ tối ưu dùng để tối ưu mạng nơ-ron. Ở đây, bạn có thể dùng Adam, một bộ tối ưu mới và hiệu quả.
# When calculating the loss you need to be careful about the exact form, because you calculate
# loss of all the unrolled steps at the same time
# Therefore, take the mean error or each batch and get the sum of that over all the unrolled steps
print('Defining training Loss')
loss = 0.0
with tf.control_dependencies([tf.assign(c[li], state[li][0]) for li in range(n_layers)]+
[tf.assign(h[li], state[li][1]) for li in range(n_layers)]):
for ui in range(num_unrollings):
loss += tf.reduce_mean(0.5*(split_outputs[ui]-train_outputs[ui])**2)
print('Learning rate decay operations')
global_step = tf.Variable(0, trainable=False)
inc_gstep = tf.assign(global_step,global_step + 1)
tf_learning_rate = tf.placeholder(shape=None,dtype=tf.float32)
tf_min_learning_rate = tf.placeholder(shape=None,dtype=tf.float32)
learning_rate = tf.maximum(
tf.train.exponential_decay(tf_learning_rate, global_step, decay_steps=1, decay_rate=0.5, staircase=True),
tf_min_learning_rate)
# Optimizer.
print('TF Optimization operations')
optimizer = tf.train.AdamOptimizer(learning_rate)
gradients, v = zip(*optimizer.compute_gradients(loss))
gradients, _ = tf.clip_by_global_norm(gradients, 5.0)
optimizer = optimizer.apply_gradients(
zip(gradients, v))
print('\tAll done')
Defining training Loss
Learning rate decay operations
TF Optimization operations
All done
Tại đây bạn định nghĩa các thao tác TensorFlow liên quan đến dự đoán. Đầu tiên, định nghĩa một placeholder để nạp đầu vào (sample_inputs), sau đó tương tự giai đoạn huấn luyện, bạn định nghĩa các biến trạng thái cho dự đoán (sample_c và sample_h). Cuối cùng bạn tính dự đoán với hàm tf.nn.dynamic_rnn rồi đưa đầu ra qua lớp hồi quy (w và b). Bạn cũng nên định nghĩa thao tác reset_sample_state, thao tác này đặt lại trạng thái ô và trạng thái ẩn. Bạn nên thực thi thao tác này lúc bắt đầu mỗi lần bạn thực hiện một chuỗi dự đoán.
print('Defining prediction related TF functions')
sample_inputs = tf.placeholder(tf.float32, shape=[1,D])
# Maintaining LSTM state for prediction stage
sample_c, sample_h, initial_sample_state = [],[],[]
for li in range(n_layers):
sample_c.append(tf.Variable(tf.zeros([1, num_nodes[li]]), trainable=False))
sample_h.append(tf.Variable(tf.zeros([1, num_nodes[li]]), trainable=False))
initial_sample_state.append(tf.contrib.rnn.LSTMStateTuple(sample_c[li],sample_h[li]))
reset_sample_states = tf.group(*[tf.assign(sample_c[li],tf.zeros([1, num_nodes[li]])) for li in range(n_layers)],
*[tf.assign(sample_h[li],tf.zeros([1, num_nodes[li]])) for li in range(n_layers)])
sample_outputs, sample_state = tf.nn.dynamic_rnn(multi_cell, tf.expand_dims(sample_inputs,0),
initial_state=tuple(initial_sample_state),
time_major = True,
dtype=tf.float32)
with tf.control_dependencies([tf.assign(sample_c[li],sample_state[li][0]) for li in range(n_layers)]+
[tf.assign(sample_h[li],sample_state[li][1]) for li in range(n_layers)]):
sample_prediction = tf.nn.xw_plus_b(tf.reshape(sample_outputs,[1,-1]), w, b)
print('\tAll done')
Defining prediction related TF functions
All done
Tại đây bạn sẽ huấn luyện và dự đoán chuyển động giá cổ phiếu trong nhiều epoch và xem liệu dự đoán tốt lên hay tệ đi theo thời gian. Bạn làm theo quy trình sau.
test_points_seq) trên chuỗi thời gian để đánh giá mô hìnhnum_unrollingsnum_unrollings điểm dữ liệu trước điểm kiểm thửn_predict_once bước, dùng dự đoán trước đó làm đầu vào hiện tạin_predict_once điểm dự đoán và giá cổ phiếu thật tại các mốc thời gian đóepochs = 30
valid_summary = 1 # Interval you make test predictions
n_predict_once = 50 # Number of steps you continously predict for
train_seq_length = train_data.size # Full length of the training data
train_mse_ot = [] # Accumulate Train losses
test_mse_ot = [] # Accumulate Test loss
predictions_over_time = [] # Accumulate predictions
session = tf.InteractiveSession()
tf.global_variables_initializer().run()
# Used for decaying learning rate
loss_nondecrease_count = 0
loss_nondecrease_threshold = 2 # If the test error hasn't increased in this many steps, decrease learning rate
print('Initialized')
average_loss = 0
# Define data generator
data_gen = DataGeneratorSeq(train_data,batch_size,num_unrollings)
x_axis_seq = []
# Points you start your test predictions from
test_points_seq = np.arange(11000,12000,50).tolist()
for ep in range(epochs):
# ========================= Training =====================================
for step in range(train_seq_length//batch_size):
u_data, u_labels = data_gen.unroll_batches()
feed_dict = {}
for ui,(dat,lbl) in enumerate(zip(u_data,u_labels)):
feed_dict[train_inputs[ui]] = dat.reshape(-1,1)
feed_dict[train_outputs[ui]] = lbl.reshape(-1,1)
feed_dict.update({tf_learning_rate: 0.0001, tf_min_learning_rate:0.000001})
_, l = session.run([optimizer, loss], feed_dict=feed_dict)
average_loss += l
# ============================ Validation ==============================
if (ep+1) % valid_summary == 0:
average_loss = average_loss/(valid_summary*(train_seq_length//batch_size))
# The average loss
if (ep+1)%valid_summary==0:
print('Average loss at step %d: %f' % (ep+1, average_loss))
train_mse_ot.append(average_loss)
average_loss = 0 # reset loss
predictions_seq = []
mse_test_loss_seq = []
# ===================== Updating State and Making Predicitons ========================
for w_i in test_points_seq:
mse_test_loss = 0.0
our_predictions = []
if (ep+1)-valid_summary==0:
# Only calculate x_axis values in the first validation epoch
x_axis=[]
# Feed in the recent past behavior of stock prices
# to make predictions from that point onwards
for tr_i in range(w_i-num_unrollings+1,w_i-1):
current_price = all_mid_data[tr_i]
feed_dict[sample_inputs] = np.array(current_price).reshape(1,1)
_ = session.run(sample_prediction,feed_dict=feed_dict)
feed_dict = {}
current_price = all_mid_data[w_i-1]
feed_dict[sample_inputs] = np.array(current_price).reshape(1,1)
# Make predictions for this many steps
# Each prediction uses previous prediciton as it's current input
for pred_i in range(n_predict_once):
pred = session.run(sample_prediction,feed_dict=feed_dict)
our_predictions.append(np.asscalar(pred))
feed_dict[sample_inputs] = np.asarray(pred).reshape(-1,1)
if (ep+1)-valid_summary==0:
# Only calculate x_axis values in the first validation epoch
x_axis.append(w_i+pred_i)
mse_test_loss += 0.5*(pred-all_mid_data[w_i+pred_i])**2
session.run(reset_sample_states)
predictions_seq.append(np.array(our_predictions))
mse_test_loss /= n_predict_once
mse_test_loss_seq.append(mse_test_loss)
if (ep+1)-valid_summary==0:
x_axis_seq.append(x_axis)
current_test_mse = np.mean(mse_test_loss_seq)
# Learning rate decay logic
if len(test_mse_ot)>0 and current_test_mse > min(test_mse_ot):
loss_nondecrease_count += 1
else:
loss_nondecrease_count = 0
if loss_nondecrease_count > loss_nondecrease_threshold :
session.run(inc_gstep)
loss_nondecrease_count = 0
print('\tDecreasing learning rate by 0.5')
test_mse_ot.append(current_test_mse)
print('\tTest MSE: %.5f'%np.mean(mse_test_loss_seq))
predictions_over_time.append(predictions_seq)
print('\tFinished Predictions')
Initialized
Average loss at step 1: 1.703350
Test MSE: 0.00318
Finished Predictions
...
...
...
Average loss at step 30: 0.033753
Test MSE: 0.00243
Finished Predictions
Bạn có thể thấy mất mát MSE giảm dần theo lượng huấn luyện. Đây là dấu hiệu tốt cho thấy mô hình học được điều gì đó hữu ích. Để định lượng phát hiện của bạn, bạn có thể so sánh mất mát MSE của mạng với MSE khi bạn thực hiện lấy trung bình tiêu chuẩn (0.004). Bạn có thể thấy LSTM làm tốt hơn lấy trung bình tiêu chuẩn. Và bạn biết rằng lấy trung bình tiêu chuẩn (dù không hoàn hảo) đã bám theo chuyển động giá cổ phiếu khá hợp lý.
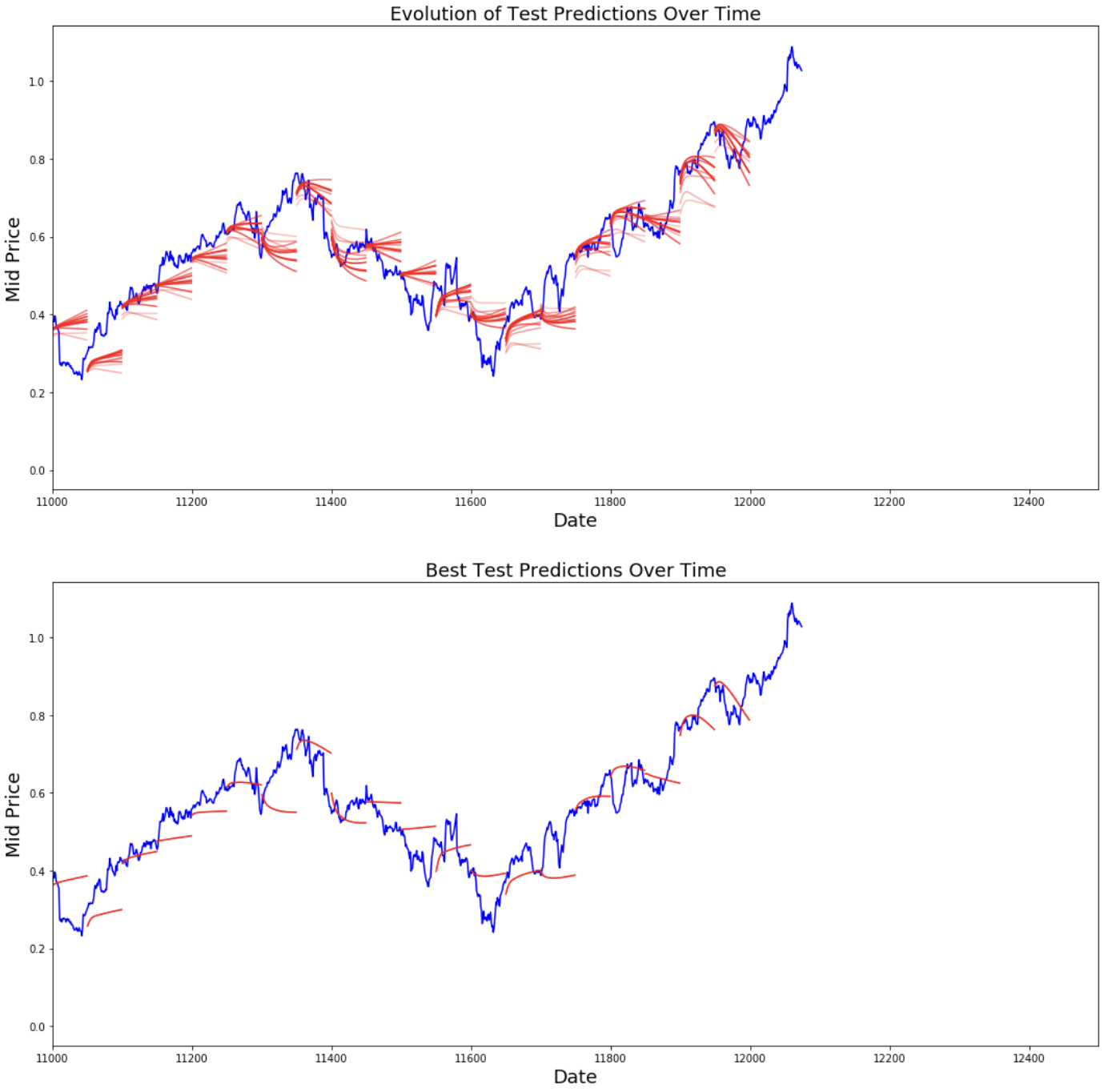
best_prediction_epoch = 28 # replace this with the epoch that you got the best results when running the plotting code plt.figure(figsize = (18,18)) plt.subplot(2,1,1) plt.plot(range(df.shape[0]),all_mid_data,color='b') # Plotting how the predictions change over time # Plot older predictions with low alpha and newer predictions with high alpha start_alpha = 0.25 alpha = np.arange(start_alpha,1.1,(1.0-start_alpha)/len(predictions_over_time[::3])) for p_i,p in enumerate(predictions_over_time[::3]): for xval,yval in zip(x_axis_seq,p): plt.plot(xval,yval,color='r',alpha=alpha[p_i]) plt.title('Evolution of Test Predictions Over Time',fontsize=18) plt.xlabel('Date',fontsize=18) plt.ylabel('Mid Price',fontsize=18) plt.xlim(11000,12500) plt.subplot(2,1,2) # Predicting the best test prediction you got plt.plot(range(df.shape[0]),all_mid_data,color='b') for xval,yval in zip(x_axis_seq,predictions_over_time[best_prediction_epoch]): plt.plot(xval,yval,color='r') plt.title('Best Test Predictions Over Time',fontsize=18) plt.xlabel('Date',fontsize=18) plt.ylabel('Mid Price',fontsize=18) plt.xlim(11000,12500) plt.show()
Dù không hoàn hảo, LSTM có vẻ có thể dự đoán hành vi giá cổ phiếu đúng phần lớn thời gian. Lưu ý rằng bạn đang thực hiện dự đoán xấp xỉ trong khoảng từ 0 đến 1.0 (tức là, không phải giá cổ phiếu thật). Điều này ổn vì bạn đang dự đoán chuyển động giá, không phải bản thân giá.
Tôi hy vọng bạn thấy hướng dẫn này hữu ích. Tôi nên nói rằng đây là một trải nghiệm đáng giá đối với tôi. Trong hướng dẫn này, tôi đã học được mức độ khó của việc xây dựng mô hình có thể dự đoán đúng chuyển động giá cổ phiếu. Bạn bắt đầu với động lực vì sao cần mô hình hóa giá cổ phiếu. Tiếp theo là giải thích và mã để tải dữ liệu. Sau đó, bạn xem xét hai kỹ thuật lấy trung bình cho phép dự đoán một bước trong tương lai. Bạn tiếp theo thấy rằng các phương pháp này trở nên vô ích khi cần dự đoán hơn một bước. Sau đó, bạn thảo luận cách dùng LSTM để dự đoán cho nhiều bước trong tương lai. Cuối cùng, bạn trực quan hóa kết quả và thấy rằng mô hình của bạn (dù không hoàn hảo) khá tốt trong việc dự đoán đúng chuyển động giá cổ phiếu.
Nếu bạn muốn học thêm về học sâu, hãy xem khóa Deep Learning in Python của chúng tôi. Khóa học này bao quát các kiến thức cơ bản, cũng như cách tự xây dựng một mạng nơ-ron bằng Keras. Đây là gói khác với TensorFlow, vốn sẽ được dùng trong hướng dẫn này, nhưng ý tưởng thì giống nhau.
Dưới đây là một số điều rút ra từ hướng dẫn này.
Dự đoán giá/chuyển động cổ phiếu là một nhiệm vụ cực kỳ khó. Cá nhân tôi nghĩ không nên xem nhẹ hay mù quáng dựa vào bất kỳ mô hình dự đoán cổ phiếu nào hiện có. Tuy vậy, các mô hình có thể dự đoán chuyển động giá đúng phần lớn thời gian, nhưng không phải luôn luôn.
Đừng bị đánh lừa bởi các bài viết ngoài kia cho thấy các đường dự đoán chồng khít hoàn hảo với giá thật. Điều này có thể tái tạo bằng một kỹ thuật lấy trung bình đơn giản và trong thực tế nó vô dụng. Điều hợp lý hơn là dự đoán chuyển động giá cổ phiếu.
Siêu tham số của mô hình cực kỳ nhạy cảm với kết quả bạn thu được. Vì vậy, một việc rất nên làm là chạy một số kỹ thuật tối ưu siêu tham số (ví dụ, Grid search / Random search) trên các siêu tham số. Dưới đây là một số siêu tham số quan trọng nhất:
Trong hướng dẫn này bạn đã làm một điều chưa chuẩn (do dữ liệu nhỏ)! Đó là bạn dùng mất mát kiểm thử để giảm tốc độ học. Điều này gián tiếp rò rỉ thông tin về tập kiểm thử vào quy trình huấn luyện. Cách tốt hơn là có một tập xác thực riêng (khác tập kiểm thử) và giảm tốc độ học theo hiệu năng trên tập xác thực.
Nếu bạn muốn liên hệ với tôi, bạn có thể gửi email tới thushv@gmail.com hoặc kết nối với tôi trên LinkedIn.
Tôi tham khảo kho mã này để hiểu cách dùng LSTM cho dự đoán cổ phiếu. Nhưng chi tiết có thể khác khá nhiều so với triển khai trong tài liệu tham khảo.
Tìm hiểu thêm về Python và Deep Learning
Courses
Courses
Courses