
Corso
Introduzione al Deep Learning in Python
4 h
264K
In questo tutorial imparerai a usare un modello per serie temporali chiamato Long Short-Term Memory. I modelli LSTM sono potenti, soprattutto per trattenere la memoria a lungo termine, per progettazione, come vedrai più avanti. In questo tutorial affronterai i seguenti argomenti:
Se non hai familiarità con il deep learning o le reti neurali, dai un’occhiata al nostro corso Deep Learning in Python. Copre le basi e mostra anche come costruire una rete neurale in autonomia con Keras. Questo package è diverso da TensorFlow, che userai in questo tutorial, ma l’idea è la stessa.
Vorresti modellare correttamente i prezzi azionari così, come acquirente di azioni, puoi decidere con criterio quando comprare e quando vendere per ottenere un profitto. È qui che entra in gioco la modellazione di serie temporali. Ti servono buoni modelli di machine learning che possano guardare alla storia di una sequenza di dati e prevedere correttamente quali saranno i futuri elementi della sequenza.
Attenzione: i prezzi di borsa sono altamente imprevedibili e volatili. Questo significa che non esistono pattern consistenti nei dati che ti permettano di modellare i prezzi nel tempo con quasi perfezione. Non crederci sulla parola; ascolta l’economista di Princeton Burton Malkiel, che nel suo libro del 1973, "A Random Walk Down Wall Street", sostiene che se il mercato è davvero efficiente e il prezzo di un’azione riflette tutti i fattori non appena vengono resi pubblici, una scimmia bendata che lancia freccette su un listino azionario farebbe bene quanto qualsiasi professionista degli investimenti.
Tuttavia, non spingiamoci fino a credere che sia solo un processo stocastico o casuale e che non ci sia speranza per il machine learning. Vediamo se almeno puoi modellare i dati in modo che le previsioni che fai correlino con il comportamento reale dei dati. In altre parole, non ti servono i valori esatti delle azioni nel futuro, ma i movimenti del prezzo (cioè se salirà o scenderà nel prossimo futuro).
# Make sure that you have all these libaries available to run the code successfully
from pandas_datareader import data
import matplotlib.pyplot as plt
import pandas as pd
import datetime as dt
import urllib.request, json
import os
import numpy as np
import tensorflow as tf # This code has been tested with TensorFlow 1.6
from sklearn.preprocessing import MinMaxScalerUserai dati provenienti dalle seguenti fonti:
Alpha Vantage Stock API. Prima di iniziare, ti serve una chiave API, che puoi ottenere gratuitamente qui. Dopodiché, puoi assegnare quella chiave alla variabile api_key. Questo tutorial recupererà 20 anni di dati storici per il titolo American Airlines. Come lettura opzionale, puoi consultare questa guida introduttiva alle API azionarie per le best practice nella gestione dei dati storici di mercato.
Usa i dati da questa pagina. Copia la cartella Stocks contenuta nello zip nella cartella principale del tuo progetto.
I prezzi azionari sono disponibili in diverse “varianti”. Sono:
Per prima cosa caricherai i dati da Alpha Vantage. Poiché userai i prezzi di mercato delle azioni American Airlines per fare le tue previsioni, imposti il ticker su "AAL". Inoltre, definisci anche un url_string, che restituirà un file JSON con tutti i dati di mercato di American Airlines negli ultimi 20 anni, e un file_to_save, che sarà il file in cui salverai i dati. Userai la variabile ticker definita in precedenza per aiutarti a nominare questo file.
Successivamente, specificherai una condizione: se non hai già salvato i dati, procederai a recuperarli dall’URL impostato in url_string; salverai le colonne data, low, high, volume, close, open in un DataFrame di pandas df e lo scriverai in file_to_save. Se i dati sono già presenti, li caricherai semplicemente dal CSV.
I dati su Kaggle sono una raccolta di file CSV e non è necessario alcun preprocessing, quindi puoi caricarli direttamente in un DataFrame Pandas.
data_source = 'kaggle' # alphavantage or kaggle
if data_source == 'alphavantage':
# ====================== Loading Data from Alpha Vantage ==================================
api_key = '<your API key>'
# American Airlines stock market prices
ticker = "AAL"
# JSON file with all the stock market data for AAL from the last 20 years
url_string = "https://www.alphavantage.co/query?function=TIME_SERIES_DAILY&symbol=%s&outputsize=full&apikey=%s"%(ticker,api_key)
# Save data to this file
file_to_save = 'stock_market_data-%s.csv'%ticker
# If you haven't already saved data,
# Go ahead and grab the data from the url
# And store date, low, high, volume, close, open values to a Pandas DataFrame
if not os.path.exists(file_to_save):
with urllib.request.urlopen(url_string) as url:
data = json.loads(url.read().decode())
# extract stock market data
data = data['Time Series (Daily)']
df = pd.DataFrame(columns=['Date','Low','High','Close','Open'])
for k,v in data.items():
date = dt.datetime.strptime(k, '%Y-%m-%d')
data_row = [date.date(),float(v['3. low']),float(v['2. high']),
float(v['4. close']),float(v['1. open'])]
df.loc[-1,:] = data_row
df.index = df.index + 1
print('Data saved to : %s'%file_to_save)
df.to_csv(file_to_save)
# If the data is already there, just load it from the CSV
else:
print('File already exists. Loading data from CSV')
df = pd.read_csv(file_to_save)
else:
# ====================== Loading Data from Kaggle ==================================
# You will be using HP's data. Feel free to experiment with other data.
# But while doing so, be careful to have a large enough dataset and also pay attention to the data normalization
df = pd.read_csv(os.path.join('Stocks','hpq.us.txt'),delimiter=',',usecols=['Date','Open','High','Low','Close'])
print('Loaded data from the Kaggle repository')
Data saved to : stock_market_data-AAL.csv
Qui stamperai i dati raccolti nel DataFrame. Assicurati anche che i dati siano ordinati per data, perché l’ordine è cruciale nella modellazione delle serie temporali.
# Sort DataFrame by date
df = df.sort_values('Date')
# Double check the result
df.head()
| Date | Open | High | Low | Close | |
|---|---|---|---|---|---|
| 0 | 1970-01-02 | 0.30627 | 0.30627 | 0.30627 | 0.30627 |
| 1 | 1970-01-05 | 0.30627 | 0.31768 | 0.30627 | 0.31385 |
| 2 | 1970-01-06 | 0.31385 | 0.31385 | 0.30996 | 0.30996 |
| 3 | 1970-01-07 | 0.31385 | 0.31385 | 0.31385 | 0.31385 |
| 4 | 1970-01-08 | 0.31385 | 0.31768 | 0.31385 | 0.31385 |
Ora vediamo che tipo di dati hai. Ti servono dati con pattern diversi che si manifestano nel tempo.
plt.figure(figsize = (18,9))
plt.plot(range(df.shape[0]),(df['Low']+df['High'])/2.0)
plt.xticks(range(0,df.shape[0],500),df['Date'].loc[::500],rotation=45)
plt.xlabel('Date',fontsize=18)
plt.ylabel('Mid Price',fontsize=18)
plt.show()
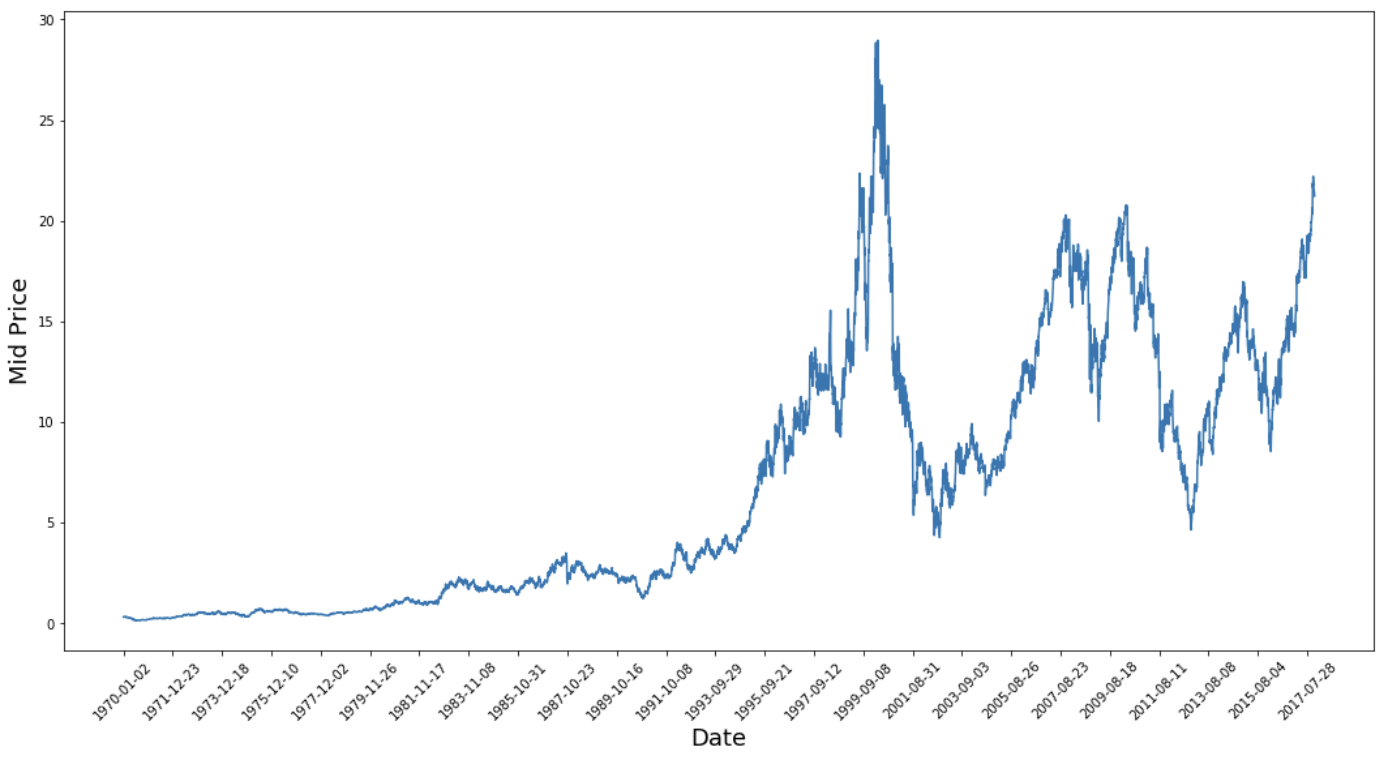
Questo grafico dice già molto. Il motivo specifico per cui ho scelto questa azienda rispetto ad altre è che è ricca di comportamenti di prezzo differenti nel tempo. Questo renderà l’apprendimento più robusto e ti darà la possibilità di testare quanto siano buone le previsioni in una varietà di situazioni.
Un’altra cosa da notare è che i valori vicini al 2017 sono molto più alti e fluttuano di più rispetto a quelli degli anni ’70. Pertanto, devi assicurarti che i dati si muovano in intervalli di valore simili lungo tutto l’arco temporale. Te ne occuperai nella fase di normalizzazione dei dati.
Userai il mid-price, calcolato facendo la media tra il prezzo massimo e minimo registrato in un giorno.
# First calculate the mid prices from the highest and lowest
high_prices = df.loc[:,'High'].as_matrix()
low_prices = df.loc[:,'Low'].as_matrix()
mid_prices = (high_prices+low_prices)/2.0
Ora puoi suddividere i dati in training e test. I dati di training saranno i primi 11.000 punti della serie temporale, il resto sarà test.
train_data = mid_prices[:11000]
test_data = mid_prices[11000:]
Ora devi definire uno scaler per normalizzare i dati. MinMaxScalar scala tutti i dati nell’intervallo 0–1. Puoi anche rimodellare i dati di training e test nella forma [data_size, num_features].
# Scale the data to be between 0 and 1
# When scaling remember! You normalize both test and train data with respect to training data
# Because you are not supposed to have access to test data
scaler = MinMaxScaler()
train_data = train_data.reshape(-1,1)
test_data = test_data.reshape(-1,1)
A causa dell’osservazione precedente, cioè che periodi diversi hanno intervalli di valore differenti, normalizzi i dati suddividendo l’intera serie in finestre. Se non lo fai, i dati più vecchi saranno vicini a 0 e aggiungeranno poco valore al processo di apprendimento. Qui scegli una finestra di 2500.
Consiglio: quando scegli la dimensione della finestra, assicurati che non sia troppo piccola. La normalizzazione per finestre può introdurre una discontinuità alla fine di ciascuna finestra, dato che ogni finestra è normalizzata in modo indipendente.
In questo esempio, 4 punti dati ne saranno influenzati. Ma dato che hai 11.000 punti, 4 non causeranno problemi.
# Train the Scaler with training data and smooth data
smoothing_window_size = 2500
for di in range(0,10000,smoothing_window_size):
scaler.fit(train_data[di:di+smoothing_window_size,:])
train_data[di:di+smoothing_window_size,:] = scaler.transform(train_data[di:di+smoothing_window_size,:])
# You normalize the last bit of remaining data
scaler.fit(train_data[di+smoothing_window_size:,:])
train_data[di+smoothing_window_size:,:] = scaler.transform(train_data[di+smoothing_window_size:,:])
Rimodella i dati di nuovo alla forma [data_size]
# Reshape both train and test data
train_data = train_data.reshape(-1)
# Normalize test data
test_data = scaler.transform(test_data).reshape(-1)
Ora puoi rendere i dati più regolari usando la media mobile esponenziale. Questo aiuta a eliminare la frastagliatura intrinseca dei prezzi azionari e a ottenere una curva più liscia.
Nota: dovresti levigare soltanto i dati di training.
# Now perform exponential moving average smoothing
# So the data will have a smoother curve than the original ragged data
EMA = 0.0
gamma = 0.1
for ti in range(11000):
EMA = gamma*train_data[ti] + (1-gamma)*EMA
train_data[ti] = EMA
# Used for visualization and test purposes
all_mid_data = np.concatenate([train_data,test_data],axis=0)
I meccanismi di media ti permettono di prevedere (spesso di un solo passo) rappresentando il prezzo futuro come una media dei prezzi osservati in precedenza. Farlo per più di un passo può produrre risultati piuttosto scadenti. Vedrai due tecniche di media: la media standard e la media mobile esponenziale. Valuterai entrambe qualitativamente (ispezione visiva) e quantitativamente (Mean Squared Error) i risultati prodotti dai due algoritmi.
Il Mean Squared Error (MSE) si calcola prendendo l’errore quadratico tra il valore vero a un passo avanti e il valore previsto e facendone la media su tutte le previsioni.
Puoi comprendere la difficoltà del problema provando prima a modellarlo come un problema di calcolo della media. Inizialmente proverai a prevedere i prezzi futuri (ad esempio xt+1) come media dei prezzi osservati in una finestra di dimensione fissa (ad esempio xt-N, ..., xt) (poniamo, gli ultimi 100 giorni). Successivamente proverai un metodo un po’ più sofisticato, la "media mobile esponenziale", e vedrai quanto funziona bene. Poi passerai al “sacro Graal” della previsione di serie temporali: i modelli Long Short-Term Memory.
Per prima cosa vedrai come funziona la media normale. Cioè, dici:
In altre parole, affermi che la previsione a t+1 è il valore medio di tutti i prezzi osservati in una finestra da t a t−N.
window_size = 100
N = train_data.size
std_avg_predictions = []
std_avg_x = []
mse_errors = []
for pred_idx in range(window_size,N):
if pred_idx >= N:
date = dt.datetime.strptime(k, '%Y-%m-%d').date() + dt.timedelta(days=1)
else:
date = df.loc[pred_idx,'Date']
std_avg_predictions.append(np.mean(train_data[pred_idx-window_size:pred_idx]))
mse_errors.append((std_avg_predictions[-1]-train_data[pred_idx])**2)
std_avg_x.append(date)
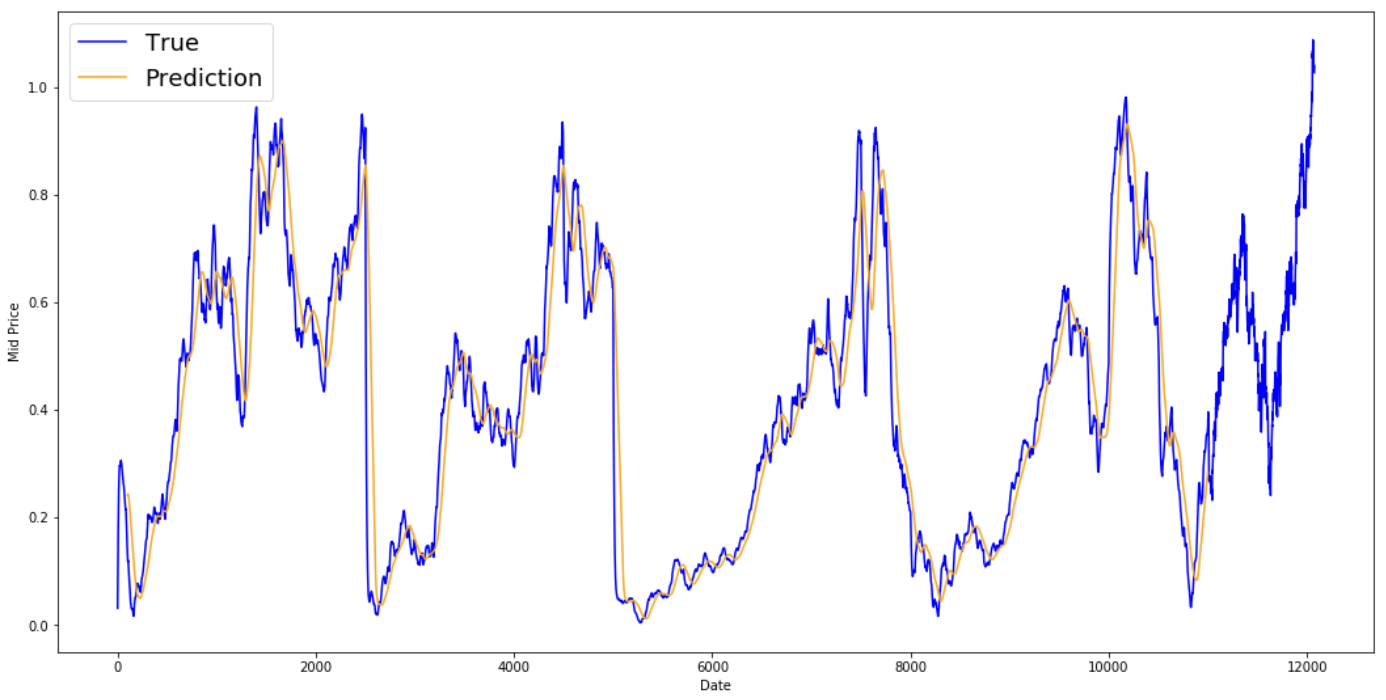
print('MSE error for standard averaging: %.5f'%(0.5*np.mean(mse_errors)))
MSE error for standard averaging: 0.00418
Guarda i risultati mediati qui sotto. Seguono piuttosto da vicino il comportamento reale del titolo. Ora esaminerai un metodo di previsione a un passo più accurato.
plt.figure(figsize = (18,9)) plt.plot(range(df.shape[0]),all_mid_data,color='b',label='True') plt.plot(range(window_size,N),std_avg_predictions,color='orange',label='Prediction') #plt.xticks(range(0,df.shape[0],50),df['Date'].loc[::50],rotation=45) plt.xlabel('Date') plt.ylabel('Mid Price') plt.legend(fontsize=18) plt.show()
Quindi, cosa dicono i grafici sopra (e l’MSE)?
Sembra che non sia un modello troppo male per previsioni molto a breve termine (un giorno avanti). Questo comportamento è sensato, dato che i prezzi non passano da 0 a 100 dall’oggi al domani. Ora guarderai una tecnica di media più raffinata, la media mobile esponenziale.
Potresti aver visto in rete articoli che usano modelli molto complessi e prevedono quasi esattamente il comportamento del mercato. Ma attenzione! Si tratta solo di illusioni ottiche e non del fatto che stiano imparando qualcosa di utile. Vedrai sotto come puoi replicare quel comportamento con una semplice media.
Nella media mobile esponenziale, calcoli $x_{t+1}$ come,
L’equazione sopra calcola sostanzialmente la media mobile esponenziale dal passo temporale t+1 e la usa come previsione a un passo. $\gamma$ decide quanto contribuisce la previsione più recente all’EMA. Per esempio, con $\gamma=0.1$ solo il 10% del valore attuale entra nell’EMA. Poiché prendi solo una piccola frazione del valore più recente, consenti di preservare molti valori più vecchi visti in precedenza nella media. Guarda quanto bene appare se usata per prevedere un passo avanti qui sotto.
window_size = 100
N = train_data.size
run_avg_predictions = []
run_avg_x = []
mse_errors = []
running_mean = 0.0
run_avg_predictions.append(running_mean)
decay = 0.5
for pred_idx in range(1,N):
running_mean = running_mean*decay + (1.0-decay)*train_data[pred_idx-1]
run_avg_predictions.append(running_mean)
mse_errors.append((run_avg_predictions[-1]-train_data[pred_idx])**2)
run_avg_x.append(date)
print('MSE error for EMA averaging: %.5f'%(0.5*np.mean(mse_errors)))
MSE error for EMA averaging: 0.00003
plt.figure(figsize = (18,9))
plt.plot(range(df.shape[0]),all_mid_data,color='b',label='True')
plt.plot(range(0,N),run_avg_predictions,color='orange', label='Prediction')
#plt.xticks(range(0,df.shape[0],50),df['Date'].loc[::50],rotation=45)
plt.xlabel('Date')
plt.ylabel('Mid Price')
plt.legend(fontsize=18)
plt.show()
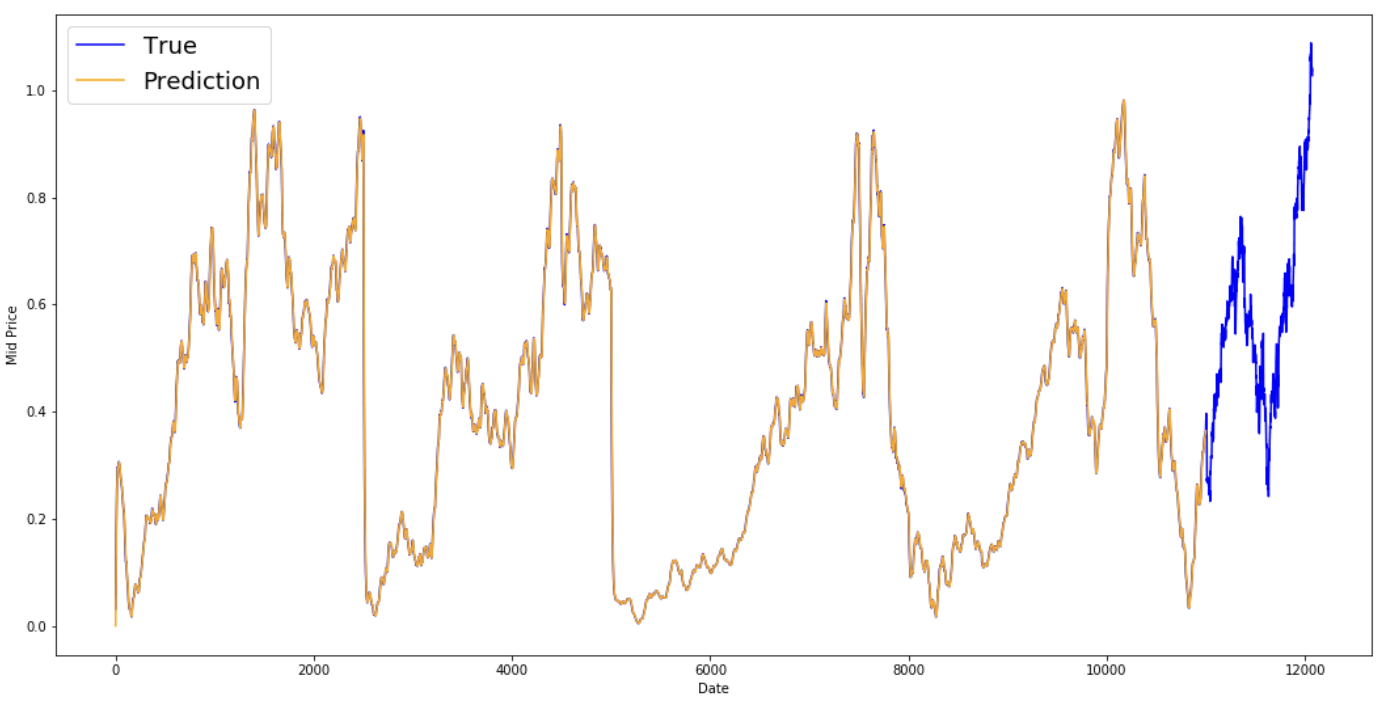
Vedi che si adatta perfettamente a una linea che segue la distribuzione True (e ciò è giustificato dall’MSE molto basso). Praticamente parlando, però, non puoi farci molto con il valore del mercato del giorno successivo. Personalmente, più che il prezzo esatto del giorno dopo, vorrei sapere se i prezzi andranno su o giù nei prossimi 30 giorni. Prova a farlo ed esporrai l’incapacità del metodo EMA.
Ora proverai a fare previsioni a finestre (ad esempio prevedi la finestra dei prossimi 2 giorni, invece di uno solo). Ti renderai conto di quanto possa sbagliare l’EMA. Ecco un esempio:
Per rendere le cose concrete, assumiamo dei valori, ad esempio $x_t=0.4$, $EMA=0.5$ e $\gamma = 0.5$
Quindi, non importa quanti passi prevedi nel futuro, continuerai a ottenere la stessa risposta per tutti i passi successivi.
Una soluzione che può restituire informazioni utili è guardare ad algoritmi basati sul momentum. Fanno previsioni in base al fatto che i valori recenti stiano salendo o scendendo (non i valori esatti). Ad esempio, diranno che il prezzo del giorno dopo sarà probabilmente più basso se i prezzi sono scesi negli ultimi giorni, il che ha senso. Tuttavia, userai un modello più complesso: un LSTM.
Questi modelli hanno rivoluzionato la previsione di serie temporali perché sono molto bravi a modellare dati sequenziali. Vedrai se esistono effettivamente pattern nascosti nei dati che puoi sfruttare.
I modelli Long Short-Term Memory sono modelli per serie temporali estremamente potenti. Possono prevedere un numero arbitrario di passi nel futuro. Un modulo (o cella) LSTM ha 5 componenti essenziali, che gli permettono di modellare sia dati a breve che a lungo termine.
Una cella è illustrata qui sotto:
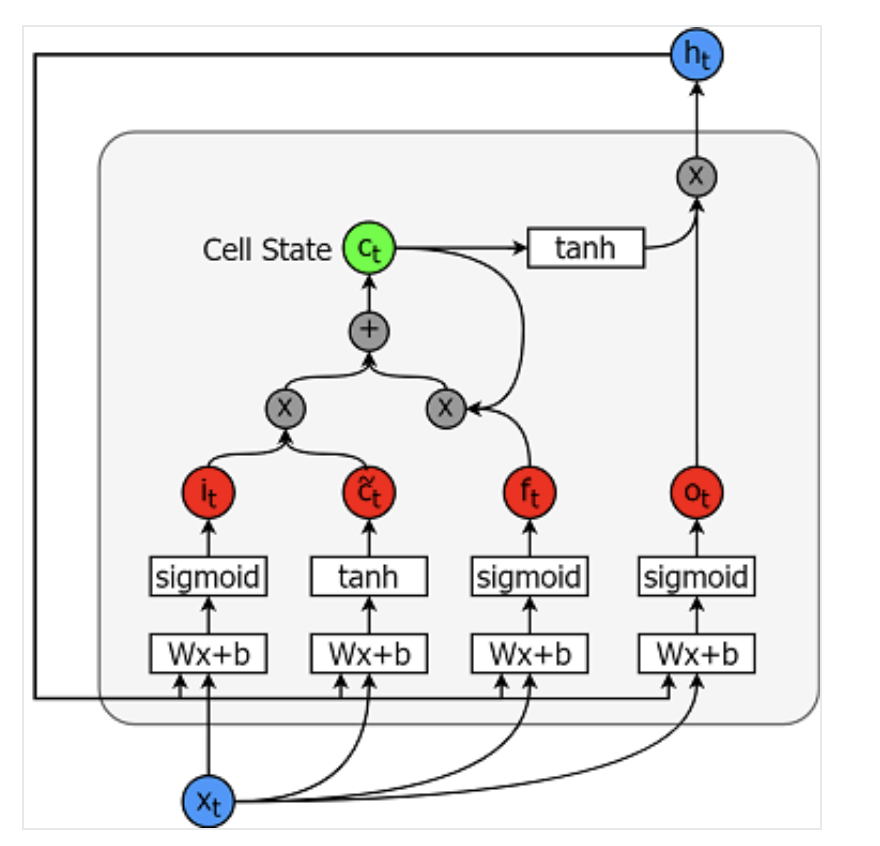
Le equazioni per calcolare ciascuna di queste entità sono le seguenti.
Per un approfondimento (più tecnico) puoi fare riferimento a questo articolo: Understanding LSTMs.
TensorFlow fornisce una comoda API (chiamata RNN API) per implementare modelli di serie temporali. La userai per le tue implementazioni.
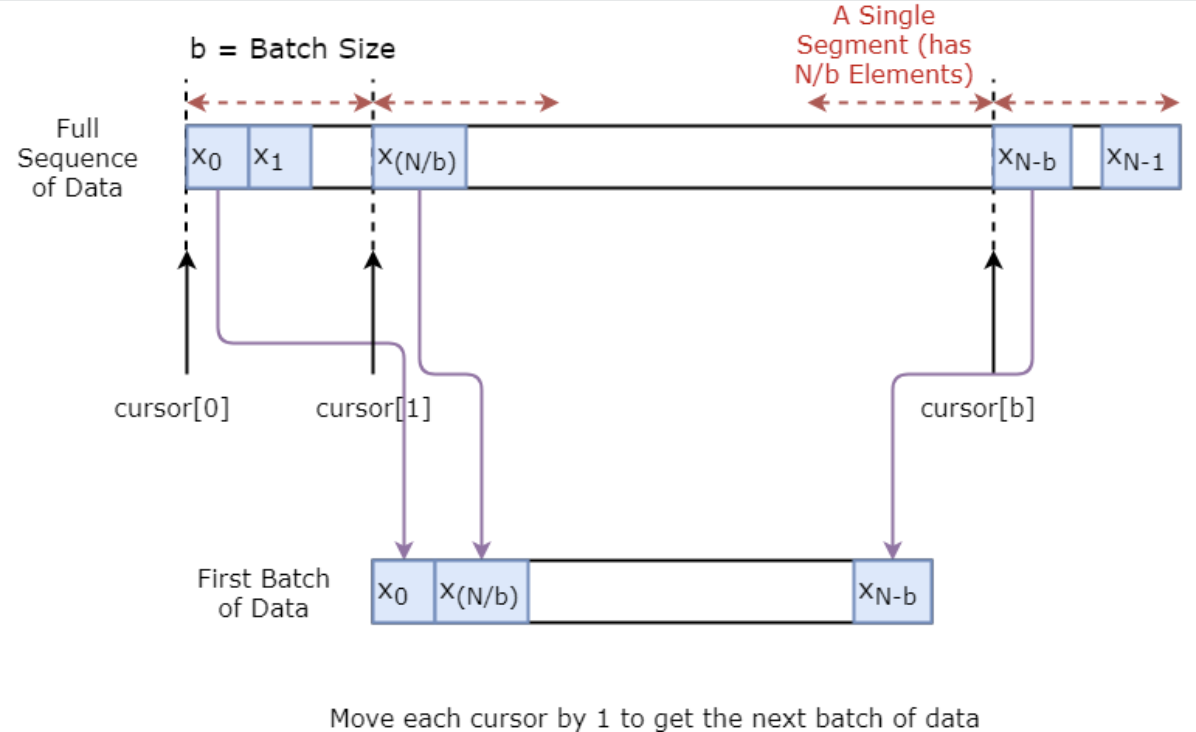
Per prima cosa implementerai un generatore di dati per addestrare il modello. Questo generatore avrà un metodo chiamato .unroll_batches(...) che restituirà un set di batch di input di dimensione num_unrollings ottenuti sequenzialmente, dove un batch ha dimensione [batch_size, 1]. Ogni batch di input avrà poi un corrispondente batch di output.
Ad esempio, se num_unrollings=3 e batch_size=4, un set di batch srotolati potrebbe essere,
Inoltre, per rendere il modello robusto, non imposterai sempre l’output per $x\_t$ come $x\_{t+1}$. Piuttosto campionerai casualmente un output dall’insieme $x\_{t+1},x\_{t+2},\ldots,x_{t+N}$ dove $N$ è una piccola finestra.
Qui stai facendo la seguente assunzione:
Personalmente penso che sia un’assunzione ragionevole per le previsioni di movimento azionario.
Sotto, illustriamo visivamente come viene creato un batch di dati.
class DataGeneratorSeq(object):
def __init__(self,prices,batch_size,num_unroll):
self._prices = prices
self._prices_length = len(self._prices) - num_unroll
self._batch_size = batch_size
self._num_unroll = num_unroll
self._segments = self._prices_length //self._batch_size
self._cursor = [offset * self._segments for offset in range(self._batch_size)]
def next_batch(self):
batch_data = np.zeros((self._batch_size),dtype=np.float32)
batch_labels = np.zeros((self._batch_size),dtype=np.float32)
for b in range(self._batch_size):
if self._cursor[b]+1>=self._prices_length:
#self._cursor[b] = b * self._segments
self._cursor[b] = np.random.randint(0,(b+1)*self._segments)
batch_data[b] = self._prices[self._cursor[b]]
batch_labels[b]= self._prices[self._cursor[b]+np.random.randint(0,5)]
self._cursor[b] = (self._cursor[b]+1)%self._prices_length
return batch_data,batch_labels
def unroll_batches(self):
unroll_data,unroll_labels = [],[]
init_data, init_label = None,None
for ui in range(self._num_unroll):
data, labels = self.next_batch()
unroll_data.append(data)
unroll_labels.append(labels)
return unroll_data, unroll_labels
def reset_indices(self):
for b in range(self._batch_size):
self._cursor[b] = np.random.randint(0,min((b+1)*self._segments,self._prices_length-1))
dg = DataGeneratorSeq(train_data,5,5)
u_data, u_labels = dg.unroll_batches()
for ui,(dat,lbl) in enumerate(zip(u_data,u_labels)):
print('\n\nUnrolled index %d'%ui)
dat_ind = dat
lbl_ind = lbl
print('\tInputs: ',dat )
print('\n\tOutput:',lbl)
Unrolled index 0
Inputs: [0.03143791 0.6904868 0.82829314 0.32585657 0.11600105]
Output: [0.08698314 0.68685144 0.8329321 0.33355275 0.11785509]
Unrolled index 1
Inputs: [0.06067836 0.6890754 0.8325337 0.32857886 0.11785509]
Output: [0.15261841 0.68685144 0.8325337 0.33421066 0.12106793]
Unrolled index 2
Inputs: [0.08698314 0.68685144 0.8329321 0.33078218 0.11946969]
Output: [0.11098009 0.6848606 0.83387965 0.33421066 0.12106793]
Unrolled index 3
Inputs: [0.11098009 0.6858036 0.83294916 0.33219692 0.12106793]
Output: [0.132895 0.6836884 0.83294916 0.33219692 0.12288672]
Unrolled index 4
Inputs: [0.132895 0.6848606 0.833369 0.33355275 0.12158521]
Output: [0.15261841 0.6836884 0.83383167 0.33355275 0.12230608]
In questa sezione definirai diversi iperparametri. D è la dimensionalità dell’input. È semplice, dato che prendi il prezzo precedente come input e prevedi il successivo, quindi dovrebbe essere 1.
Poi hai num_unrollings, un iperparametro legato al backpropagation through time (BPTT) usato per ottimizzare il modello LSTM. Indica quanti passi temporali consecutivi consideri per un singolo step di ottimizzazione. Puoi pensarla così: invece di ottimizzare il modello guardando un solo passo, ottimizzi la rete guardando a num_unrollings passi. Più è grande, meglio è.
Poi c’è il batch_size. È il numero di campioni che consideri in un singolo passo temporale.
Successivamente definisci num_nodes, che rappresenta il numero di neuroni nascosti in ciascuna cella. In questo esempio ci sono tre livelli di LSTM.
D = 1 # Dimensionality of the data. Since your data is 1-D this would be 1
num_unrollings = 50 # Number of time steps you look into the future.
batch_size = 500 # Number of samples in a batch
num_nodes = [200,200,150] # Number of hidden nodes in each layer of the deep LSTM stack we're using
n_layers = len(num_nodes) # number of layers
dropout = 0.2 # dropout amount
tf.reset_default_graph() # This is important in case you run this multiple times
Ora definisci i placeholder per input e label di training. È molto lineare: hai un elenco di placeholder di input, ciascuno contenente un singolo batch di dati. E l’elenco ha num_unrollings placeholder, usati in una sola volta per un singolo step di ottimizzazione.
# Input data.
train_inputs, train_outputs = [],[]
# You unroll the input over time defining placeholders for each time step
for ui in range(num_unrollings):
train_inputs.append(tf.placeholder(tf.float32, shape=[batch_size,D],name='train_inputs_%d'%ui))
train_outputs.append(tf.placeholder(tf.float32, shape=[batch_size,1], name = 'train_outputs_%d'%ui))
Avrai tre livelli di LSTM e uno strato di regressione lineare, indicato da w e b, che prende l’output dell’ultima cella LSTM e produce la previsione per il passo successivo. Puoi usare MultiRNNCell in TensorFlow per incapsulare i tre oggetti LSTMCell che hai creato. Inoltre, puoi usare LSTM con dropout, che migliorano le prestazioni e riducono l’overfitting.
lstm_cells = [
tf.contrib.rnn.LSTMCell(num_units=num_nodes[li],
state_is_tuple=True,
initializer= tf.contrib.layers.xavier_initializer()
)
for li in range(n_layers)]
drop_lstm_cells = [tf.contrib.rnn.DropoutWrapper(
lstm, input_keep_prob=1.0,output_keep_prob=1.0-dropout, state_keep_prob=1.0-dropout
) for lstm in lstm_cells]
drop_multi_cell = tf.contrib.rnn.MultiRNNCell(drop_lstm_cells)
multi_cell = tf.contrib.rnn.MultiRNNCell(lstm_cells)
w = tf.get_variable('w',shape=[num_nodes[-1], 1], initializer=tf.contrib.layers.xavier_initializer())
b = tf.get_variable('b',initializer=tf.random_uniform([1],-0.1,0.1))
In questa sezione, prima crei variabili TensorFlow (c e h) che conterranno lo stato di cella e lo stato nascosto della LSTM. Poi trasformi la lista di train_inputs per avere forma [num_unrollings, batch_size, D], necessaria per calcolare gli output con tf.nn.dynamic_rnn. Calcoli quindi gli output della LSTM con tf.nn.dynamic_rnn e suddividi l’output di nuovo in una lista di tensori num_unrolling. la perdita tra le previsioni e i prezzi reali.
# Create cell state and hidden state variables to maintain the state of the LSTM
c, h = [],[]
initial_state = []
for li in range(n_layers):
c.append(tf.Variable(tf.zeros([batch_size, num_nodes[li]]), trainable=False))
h.append(tf.Variable(tf.zeros([batch_size, num_nodes[li]]), trainable=False))
initial_state.append(tf.contrib.rnn.LSTMStateTuple(c[li], h[li]))
# Do several tensor transofmations, because the function dynamic_rnn requires the output to be of
# a specific format. Read more at: https://www.tensorflow.org/api_docs/python/tf/nn/dynamic_rnn
all_inputs = tf.concat([tf.expand_dims(t,0) for t in train_inputs],axis=0)
# all_outputs is [seq_length, batch_size, num_nodes]
all_lstm_outputs, state = tf.nn.dynamic_rnn(
drop_multi_cell, all_inputs, initial_state=tuple(initial_state),
time_major = True, dtype=tf.float32)
all_lstm_outputs = tf.reshape(all_lstm_outputs, [batch_size*num_unrollings,num_nodes[-1]])
all_outputs = tf.nn.xw_plus_b(all_lstm_outputs,w,b)
split_outputs = tf.split(all_outputs,num_unrollings,axis=0)
Ora calcolerai la loss. Nota però una caratteristica particolare nel calcolo: per ogni batch di previsioni e valori reali, calcoli il Mean Squared Error. E sommi (non fai la media) tutte queste perdite medie quadratiche. Infine, definisci l’ottimizzatore che userai per ottimizzare la rete neurale. In questo caso, puoi usare Adam, un ottimizzatore recente e performante.
# When calculating the loss you need to be careful about the exact form, because you calculate
# loss of all the unrolled steps at the same time
# Therefore, take the mean error or each batch and get the sum of that over all the unrolled steps
print('Defining training Loss')
loss = 0.0
with tf.control_dependencies([tf.assign(c[li], state[li][0]) for li in range(n_layers)]+
[tf.assign(h[li], state[li][1]) for li in range(n_layers)]):
for ui in range(num_unrollings):
loss += tf.reduce_mean(0.5*(split_outputs[ui]-train_outputs[ui])**2)
print('Learning rate decay operations')
global_step = tf.Variable(0, trainable=False)
inc_gstep = tf.assign(global_step,global_step + 1)
tf_learning_rate = tf.placeholder(shape=None,dtype=tf.float32)
tf_min_learning_rate = tf.placeholder(shape=None,dtype=tf.float32)
learning_rate = tf.maximum(
tf.train.exponential_decay(tf_learning_rate, global_step, decay_steps=1, decay_rate=0.5, staircase=True),
tf_min_learning_rate)
# Optimizer.
print('TF Optimization operations')
optimizer = tf.train.AdamOptimizer(learning_rate)
gradients, v = zip(*optimizer.compute_gradients(loss))
gradients, _ = tf.clip_by_global_norm(gradients, 5.0)
optimizer = optimizer.apply_gradients(
zip(gradients, v))
print('\tAll done')
Defining training Loss
Learning rate decay operations
TF Optimization operations
All done
Qui definisci le operazioni TensorFlow relative alle previsioni. Per prima cosa, definisci un placeholder per l’input (sample_inputs), poi, come nella fase di training, definisci variabili di stato per la previsione (sample_c e sample_h). Infine calcoli la previsione con tf.nn.dynamic_rnn e poi invii l’output attraverso lo strato di regressione (w e b). Dovresti anche definire l’operazione reset_sample_state, che reimposta stato di cella e stato nascosto. Esegui questa operazione all’inizio, ogni volta che fai una sequenza di previsioni.
print('Defining prediction related TF functions')
sample_inputs = tf.placeholder(tf.float32, shape=[1,D])
# Maintaining LSTM state for prediction stage
sample_c, sample_h, initial_sample_state = [],[],[]
for li in range(n_layers):
sample_c.append(tf.Variable(tf.zeros([1, num_nodes[li]]), trainable=False))
sample_h.append(tf.Variable(tf.zeros([1, num_nodes[li]]), trainable=False))
initial_sample_state.append(tf.contrib.rnn.LSTMStateTuple(sample_c[li],sample_h[li]))
reset_sample_states = tf.group(*[tf.assign(sample_c[li],tf.zeros([1, num_nodes[li]])) for li in range(n_layers)],
*[tf.assign(sample_h[li],tf.zeros([1, num_nodes[li]])) for li in range(n_layers)])
sample_outputs, sample_state = tf.nn.dynamic_rnn(multi_cell, tf.expand_dims(sample_inputs,0),
initial_state=tuple(initial_sample_state),
time_major = True,
dtype=tf.float32)
with tf.control_dependencies([tf.assign(sample_c[li],sample_state[li][0]) for li in range(n_layers)]+
[tf.assign(sample_h[li],sample_state[li][1]) for li in range(n_layers)]):
sample_prediction = tf.nn.xw_plus_b(tf.reshape(sample_outputs,[1,-1]), w, b)
print('\tAll done')
Defining prediction related TF functions
All done
Qui allenerai e prevedrai i movimenti dei prezzi per diverse epoche e vedrai se le previsioni migliorano o peggiorano nel tempo. Segui la procedura seguente.
test_points_seq) sulla serie temporale su cui valutare il modellonum_unrollingsnum_unrollings punti precedenti al punto di testn_predict_once passi continuativamente, usando la previsione precedente come input correnten_predict_once punti previsti e i prezzi reali a quegli istantiepochs = 30
valid_summary = 1 # Interval you make test predictions
n_predict_once = 50 # Number of steps you continously predict for
train_seq_length = train_data.size # Full length of the training data
train_mse_ot = [] # Accumulate Train losses
test_mse_ot = [] # Accumulate Test loss
predictions_over_time = [] # Accumulate predictions
session = tf.InteractiveSession()
tf.global_variables_initializer().run()
# Used for decaying learning rate
loss_nondecrease_count = 0
loss_nondecrease_threshold = 2 # If the test error hasn't increased in this many steps, decrease learning rate
print('Initialized')
average_loss = 0
# Define data generator
data_gen = DataGeneratorSeq(train_data,batch_size,num_unrollings)
x_axis_seq = []
# Points you start your test predictions from
test_points_seq = np.arange(11000,12000,50).tolist()
for ep in range(epochs):
# ========================= Training =====================================
for step in range(train_seq_length//batch_size):
u_data, u_labels = data_gen.unroll_batches()
feed_dict = {}
for ui,(dat,lbl) in enumerate(zip(u_data,u_labels)):
feed_dict[train_inputs[ui]] = dat.reshape(-1,1)
feed_dict[train_outputs[ui]] = lbl.reshape(-1,1)
feed_dict.update({tf_learning_rate: 0.0001, tf_min_learning_rate:0.000001})
_, l = session.run([optimizer, loss], feed_dict=feed_dict)
average_loss += l
# ============================ Validation ==============================
if (ep+1) % valid_summary == 0:
average_loss = average_loss/(valid_summary*(train_seq_length//batch_size))
# The average loss
if (ep+1)%valid_summary==0:
print('Average loss at step %d: %f' % (ep+1, average_loss))
train_mse_ot.append(average_loss)
average_loss = 0 # reset loss
predictions_seq = []
mse_test_loss_seq = []
# ===================== Updating State and Making Predicitons ========================
for w_i in test_points_seq:
mse_test_loss = 0.0
our_predictions = []
if (ep+1)-valid_summary==0:
# Only calculate x_axis values in the first validation epoch
x_axis=[]
# Feed in the recent past behavior of stock prices
# to make predictions from that point onwards
for tr_i in range(w_i-num_unrollings+1,w_i-1):
current_price = all_mid_data[tr_i]
feed_dict[sample_inputs] = np.array(current_price).reshape(1,1)
_ = session.run(sample_prediction,feed_dict=feed_dict)
feed_dict = {}
current_price = all_mid_data[w_i-1]
feed_dict[sample_inputs] = np.array(current_price).reshape(1,1)
# Make predictions for this many steps
# Each prediction uses previous prediciton as it's current input
for pred_i in range(n_predict_once):
pred = session.run(sample_prediction,feed_dict=feed_dict)
our_predictions.append(np.asscalar(pred))
feed_dict[sample_inputs] = np.asarray(pred).reshape(-1,1)
if (ep+1)-valid_summary==0:
# Only calculate x_axis values in the first validation epoch
x_axis.append(w_i+pred_i)
mse_test_loss += 0.5*(pred-all_mid_data[w_i+pred_i])**2
session.run(reset_sample_states)
predictions_seq.append(np.array(our_predictions))
mse_test_loss /= n_predict_once
mse_test_loss_seq.append(mse_test_loss)
if (ep+1)-valid_summary==0:
x_axis_seq.append(x_axis)
current_test_mse = np.mean(mse_test_loss_seq)
# Learning rate decay logic
if len(test_mse_ot)>0 and current_test_mse > min(test_mse_ot):
loss_nondecrease_count += 1
else:
loss_nondecrease_count = 0
if loss_nondecrease_count > loss_nondecrease_threshold :
session.run(inc_gstep)
loss_nondecrease_count = 0
print('\tDecreasing learning rate by 0.5')
test_mse_ot.append(current_test_mse)
print('\tTest MSE: %.5f'%np.mean(mse_test_loss_seq))
predictions_over_time.append(predictions_seq)
print('\tFinished Predictions')
Initialized
Average loss at step 1: 1.703350
Test MSE: 0.00318
Finished Predictions
...
...
...
Average loss at step 30: 0.033753
Test MSE: 0.00243
Finished Predictions
Puoi vedere come la loss MSE scende con l’aumentare dell’addestramento. È un buon segno che il modello stia imparando qualcosa di utile. Per quantificare le tue osservazioni, puoi confrontare la loss MSE della rete con quella ottenuta con la media standard (0,004). Si vede che l’LSTM fa meglio della media standard. E sai che la media standard (pur non perfetta) seguiva ragionevolmente i movimenti reali dei prezzi.
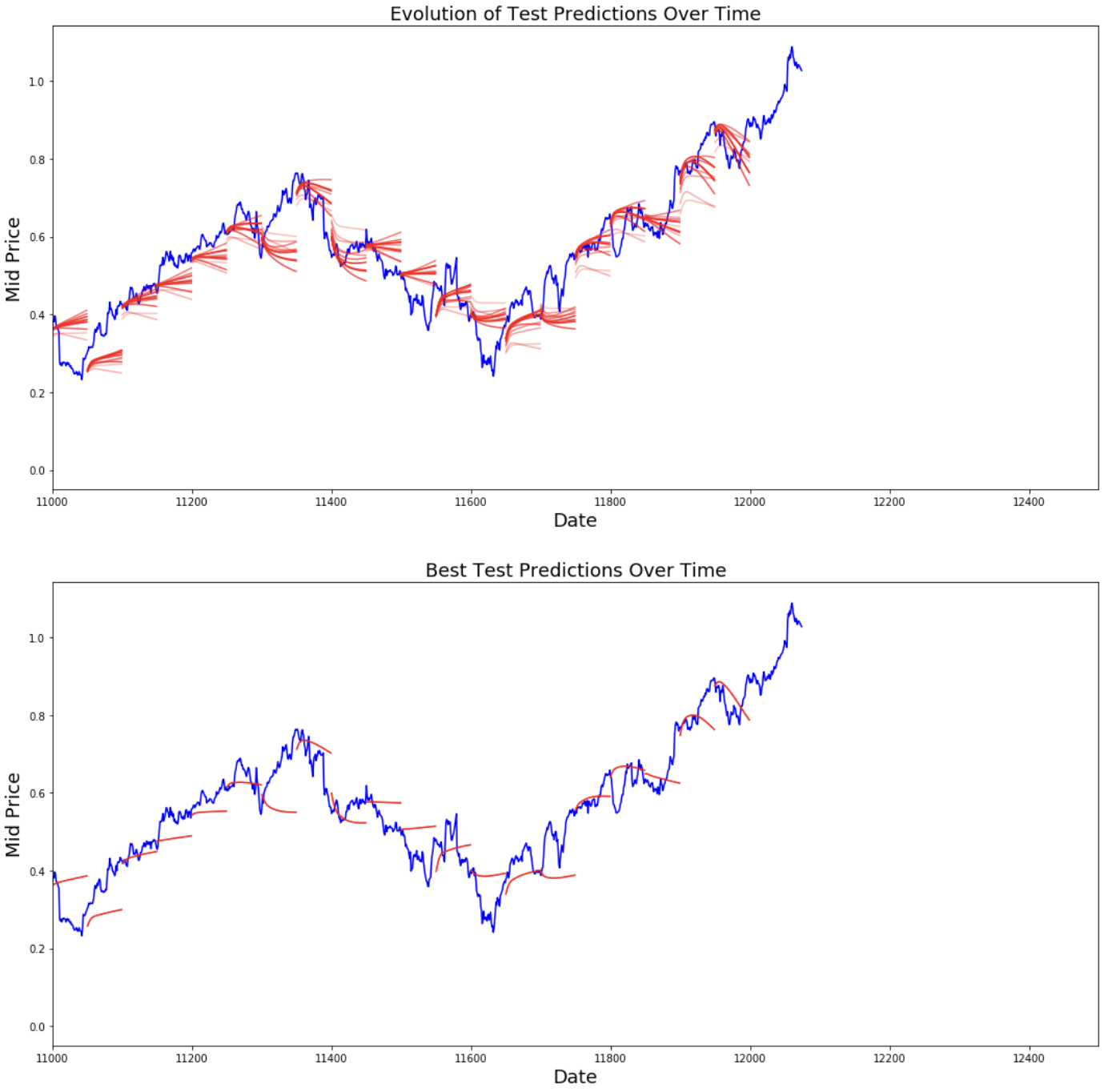
best_prediction_epoch = 28 # replace this with the epoch that you got the best results when running the plotting code plt.figure(figsize = (18,18)) plt.subplot(2,1,1) plt.plot(range(df.shape[0]),all_mid_data,color='b') # Plotting how the predictions change over time # Plot older predictions with low alpha and newer predictions with high alpha start_alpha = 0.25 alpha = np.arange(start_alpha,1.1,(1.0-start_alpha)/len(predictions_over_time[::3])) for p_i,p in enumerate(predictions_over_time[::3]): for xval,yval in zip(x_axis_seq,p): plt.plot(xval,yval,color='r',alpha=alpha[p_i]) plt.title('Evolution of Test Predictions Over Time',fontsize=18) plt.xlabel('Date',fontsize=18) plt.ylabel('Mid Price',fontsize=18) plt.xlim(11000,12500) plt.subplot(2,1,2) # Predicting the best test prediction you got plt.plot(range(df.shape[0]),all_mid_data,color='b') for xval,yval in zip(x_axis_seq,predictions_over_time[best_prediction_epoch]): plt.plot(xval,yval,color='r') plt.title('Best Test Predictions Over Time',fontsize=18) plt.xlabel('Date',fontsize=18) plt.ylabel('Mid Price',fontsize=18) plt.xlim(11000,12500) plt.show()
Pur non essendo perfette, le LSTM sembrano riuscire a prevedere correttamente il comportamento dei prezzi la maggior parte delle volte. Nota che stai facendo previsioni all’incirca nell’intervallo 0–1,0 (cioè non i prezzi reali). Va bene, perché stai prevedendo il movimento del prezzo, non i prezzi in sé.
Spero che tu abbia trovato utile questo tutorial. Devo dire che è stata un’esperienza gratificante per me. In questo tutorial ho imparato quanto possa essere difficile ideare un modello in grado di prevedere correttamente i movimenti dei prezzi. Sei partito dalla motivazione per cui serve modellare i prezzi. È seguita una spiegazione e il codice per scaricare i dati. Poi hai visto due tecniche di media che permettono di fare previsioni a un passo nel futuro. Hai quindi visto che questi metodi sono inutili quando devi prevedere più di un passo. Successivamente, hai discusso come usare le LSTM per fare previsioni su molti passi nel futuro. Infine, hai visualizzato i risultati e visto che il tuo modello (pur non perfetto) è piuttosto bravo a prevedere correttamente i movimenti dei prezzi.
Se vuoi saperne di più sul deep learning, assicurati di dare un’occhiata al nostro corso Deep Learning in Python. Copre le basi e mostra anche come costruire una rete neurale con Keras. È un package diverso da TensorFlow, che userai in questo tutorial, ma l’idea è la stessa.
Qui riporto alcuni takeaway da questo tutorial.
La previsione dei prezzi/movimenti è un compito estremamente difficile. Personalmente, non credo che i modelli di previsione azionaria in circolazione debbano essere presi per buoni e usati alla cieca. Tuttavia, i modelli potrebbero riuscire a prevedere correttamente il movimento dei prezzi la maggior parte delle volte, ma non sempre.
Non lasciarti ingannare da articoli che mostrano curve di previsione che si sovrappongono perfettamente ai prezzi reali. Questo si può replicare con una semplice tecnica di media e, nella pratica, è inutile. Una cosa più sensata è prevedere i movimenti dei prezzi.
Gli iperparametri del modello sono estremamente sensibili ai risultati che ottieni. Quindi, una cosa molto utile è eseguire tecniche di ottimizzazione degli iperparametri (ad esempio Grid search / Random search). Di seguito elenco alcuni degli iperparametri più critici:
In questo tutorial hai fatto qualcosa di scorretto (a causa della dimensione ridotta dei dati)! Hai usato la loss di test per far decadere il learning rate. Questo fa filtrare indirettamente informazioni dal test nella procedura di training. Un modo migliore è avere un set di validazione separato (oltre al test) e far decadere il learning rate rispetto alle prestazioni sul validation set.
Se vuoi contattarmi, puoi scrivermi a thushv@gmail.com o connetterti su LinkedIn.
Ho fatto riferimento a questo repository per capire come usare le LSTM per le previsioni azionarie. Ma i dettagli possono essere molto diversi dall’implementazione presente nel riferimento.
Approfondisci Python e Deep Learning
Corso
Corso
Corso
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min
blog
Tim Lu
12 min

