
Cursus
Introductie tot Deep Learning in Python
4 Hr
264K
In deze tutorial leer je hoe je een tijdreeksmodel gebruikt genaamd Long Short-Term Memory. LSTM-modellen zijn krachtig, vooral doordat ze ontworpen zijn om lange-termijngeheugen vast te houden, zoals je later zult zien. Je pakt in deze tutorial de volgende onderwerpen aan:
Als je nog niet bekend bent met deep learning of neurale netwerken, bekijk dan onze Deep Learning in Python-cursus. Die behandelt de basis en laat zien hoe je zelf een neuraal netwerk bouwt in Keras. Dit pakket is anders dan TensorFlow, dat in deze tutorial wordt gebruikt, maar het idee is hetzelfde.
Je wilt aandelenskoersen goed modelleren zodat je als koper redelijk kunt beslissen wanneer je moet kopen en wanneer je moet verkopen om winst te maken. Hier komt tijdreeksmodellering om de hoek kijken. Je hebt goede machinelearningmodellen nodig die naar de geschiedenis van een sequentie van data kunnen kijken en correct kunnen voorspellen wat de toekomstige elementen van de sequentie zullen zijn.
Waarschuwing: Aandelenkoersen zijn zeer onvoorspelbaar en volatiel. Dat betekent dat er geen consistente patronen in de data zijn die het mogelijk maken om koersen in de tijd bijna perfect te modelleren. Geloof mij niet op mijn woord; geloof econoom Burton Malkiel van Princeton University, die in zijn boek uit 1973, "A Random Walk Down Wall Street," betoogt dat als de markt echt efficiënt is en een aandelenprijs alle factoren onmiddellijk weerspiegelt zodra ze openbaar worden, een geblinddoekte aap die pijltjes gooit naar een aandelenoverzicht in de krant het net zo goed zou doen als elke beleggingsprofessional.
Laten we echter niet volledig aannemen dat dit slechts een stochastisch of willekeurig proces is en dat er geen hoop is voor machine learning. Laten we kijken of je de data in elk geval zo kunt modelleren dat de voorspellingen die je doet correleren met het daadwerkelijke gedrag van de data. Met andere woorden, je hebt niet de exacte toekomstige koerswaarden nodig, maar de koersbewegingen (dus of de koers op korte termijn gaat stijgen of dalen).
# Make sure that you have all these libaries available to run the code successfully
from pandas_datareader import data
import matplotlib.pyplot as plt
import pandas as pd
import datetime as dt
import urllib.request, json
import os
import numpy as np
import tensorflow as tf # This code has been tested with TensorFlow 1.6
from sklearn.preprocessing import MinMaxScalerJe gebruikt data uit de volgende bronnen:
Alpha Vantage Stock API. Voordat je begint, heb je een API-sleutel nodig, die je gratis kunt verkrijgen hier. Daarna kun je die sleutel toewijzen aan de variabele api_key. Deze tutorial haalt 20 jaar aan historische data op voor het aandeel American Airlines. Als optionele leestip kun je deze stock API starter guide raadplegen voor best practices bij het werken met historische marktdata.
Gebruik de data van deze pagina. Kopieer de map Stocks in het zip-bestand naar de hoofdmap van je project.
Aandelenkoersen komen in verschillende smaken. Namelijk,
Je laadt eerst de data van Alpha Vantage. Omdat je de koersen van American Airlines gaat gebruiken voor je voorspellingen, zet je de ticker op "AAL". Daarnaast definieer je ook een url_string, die een JSON-bestand zal teruggeven met alle marktdata voor American Airlines binnen de laatste 20 jaar, en een file_to_save, het bestand waarin je de data opslaat. Je gebruikt de variabele ticker die je eerder definieerde om dit bestand een naam te geven.
Vervolgens specificeer je een voorwaarde: als je nog geen data hebt opgeslagen, haal je de data op van de URL die je hebt ingesteld in url_string; Je slaat de waarden voor datum, low, high, volume, close en open op in een pandas DataFrame df en bewaart dit in file_to_save. Als de data echter al bestaat, laad je het gewoon uit de CSV.
De data op Kaggle is een verzameling CSV-bestanden, en je hoeft geen preprocessing te doen, dus je kunt de data direct inladen in een Pandas DataFrame.
data_source = 'kaggle' # alphavantage or kaggle
if data_source == 'alphavantage':
# ====================== Loading Data from Alpha Vantage ==================================
api_key = '<your API key>'
# American Airlines stock market prices
ticker = "AAL"
# JSON file with all the stock market data for AAL from the last 20 years
url_string = "https://www.alphavantage.co/query?function=TIME_SERIES_DAILY&symbol=%s&outputsize=full&apikey=%s"%(ticker,api_key)
# Save data to this file
file_to_save = 'stock_market_data-%s.csv'%ticker
# If you haven't already saved data,
# Go ahead and grab the data from the url
# And store date, low, high, volume, close, open values to a Pandas DataFrame
if not os.path.exists(file_to_save):
with urllib.request.urlopen(url_string) as url:
data = json.loads(url.read().decode())
# extract stock market data
data = data['Time Series (Daily)']
df = pd.DataFrame(columns=['Date','Low','High','Close','Open'])
for k,v in data.items():
date = dt.datetime.strptime(k, '%Y-%m-%d')
data_row = [date.date(),float(v['3. low']),float(v['2. high']),
float(v['4. close']),float(v['1. open'])]
df.loc[-1,:] = data_row
df.index = df.index + 1
print('Data saved to : %s'%file_to_save)
df.to_csv(file_to_save)
# If the data is already there, just load it from the CSV
else:
print('File already exists. Loading data from CSV')
df = pd.read_csv(file_to_save)
else:
# ====================== Loading Data from Kaggle ==================================
# You will be using HP's data. Feel free to experiment with other data.
# But while doing so, be careful to have a large enough dataset and also pay attention to the data normalization
df = pd.read_csv(os.path.join('Stocks','hpq.us.txt'),delimiter=',',usecols=['Date','Open','High','Low','Close'])
print('Loaded data from the Kaggle repository')
Data saved to : stock_market_data-AAL.csv
Hier print je de data die je in het DataFrame hebt verzameld. Zorg er ook voor dat de data op datum is gesorteerd, want de volgorde is cruciaal bij tijdreeksmodellering.
# Sort DataFrame by date
df = df.sort_values('Date')
# Double check the result
df.head()
| Date | Open | High | Low | Close | |
|---|---|---|---|---|---|
| 0 | 1970-01-02 | 0.30627 | 0.30627 | 0.30627 | 0.30627 |
| 1 | 1970-01-05 | 0.30627 | 0.31768 | 0.30627 | 0.31385 |
| 2 | 1970-01-06 | 0.31385 | 0.31385 | 0.30996 | 0.30996 |
| 3 | 1970-01-07 | 0.31385 | 0.31385 | 0.31385 | 0.31385 |
| 4 | 1970-01-08 | 0.31385 | 0.31768 | 0.31385 | 0.31385 |
Laten we nu eens kijken wat voor data je hebt. Je wilt data met verschillende patronen die zich in de tijd voordoen.
plt.figure(figsize = (18,9))
plt.plot(range(df.shape[0]),(df['Low']+df['High'])/2.0)
plt.xticks(range(0,df.shape[0],500),df['Date'].loc[::500],rotation=45)
plt.xlabel('Date',fontsize=18)
plt.ylabel('Mid Price',fontsize=18)
plt.show()
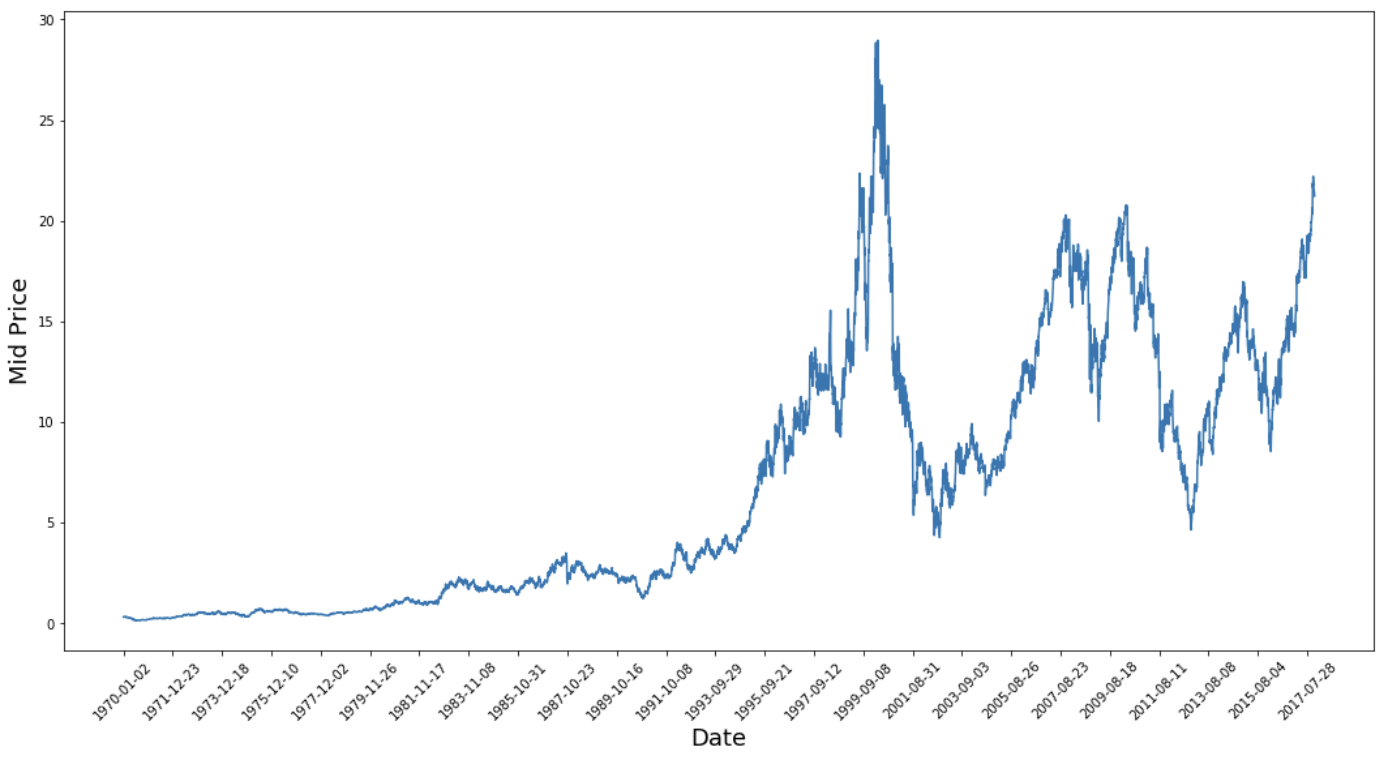
Deze grafiek zegt al veel. De specifieke reden dat ik dit bedrijf boven andere heb gekozen, is dat het barst van de verschillende koerspatronen in de tijd. Dit maakt het leren robuuster en geeft je de kans om te testen hoe goed de voorspellingen zijn in uiteenlopende situaties.
Wat ook opvalt, is dat de waarden rond 2017 veel hoger zijn en meer fluctueren dan die rond de jaren 70. Daarom moet je ervoor zorgen dat de data binnen het gehele tijdsbestek vergelijkbare waardebereiken heeft. Dit pak je aan tijdens de fase van datanormalisatie.
Je gebruikt de mid-price, die je berekent door het gemiddelde te nemen van de hoogste en laagste geregistreerde prijs op een dag.
# First calculate the mid prices from the highest and lowest
high_prices = df.loc[:,'High'].as_matrix()
low_prices = df.loc[:,'Low'].as_matrix()
mid_prices = (high_prices+low_prices)/2.0
Nu kun je de trainings- en testdata splitsen. De trainingsdata zijn de eerste 11.000 datapunten van de tijdreeks, en de rest is testdata.
train_data = mid_prices[:11000]
test_data = mid_prices[11000:]
Nu moet je een scaler definiëren om de data te normaliseren. MinMaxScalar schaalt alle data naar het bereik 0 tot 1. Je kunt de trainings- en testdata ook reshapen naar de vorm [data_size, num_features].
# Scale the data to be between 0 and 1
# When scaling remember! You normalize both test and train data with respect to training data
# Because you are not supposed to have access to test data
scaler = MinMaxScaler()
train_data = train_data.reshape(-1,1)
test_data = test_data.reshape(-1,1)
Vanwege je eerdere observatie dat verschillende perioden in de data verschillende waardebereiken hebben, normaliseer je de data door de volledige serie in vensters te splitsen. Als je dit niet doet, liggen de vroegere data dicht bij 0 en dragen ze weinig bij aan het leerproces. Hier kies je een venstergrootte van 2500.
Tip: Zorg er bij het kiezen van de venstergrootte voor dat die niet te klein is. Bij venster-normalisatie kan er een breuk ontstaan aan het einde van elk venster, omdat elk venster onafhankelijk wordt genormaliseerd.
In dit voorbeeld worden 4 datapunten hierdoor beïnvloed. Maar aangezien je 11.000 datapunten hebt, zullen 4 punten geen probleem veroorzaken.
# Train the Scaler with training data and smooth data
smoothing_window_size = 2500
for di in range(0,10000,smoothing_window_size):
scaler.fit(train_data[di:di+smoothing_window_size,:])
train_data[di:di+smoothing_window_size,:] = scaler.transform(train_data[di:di+smoothing_window_size,:])
# You normalize the last bit of remaining data
scaler.fit(train_data[di+smoothing_window_size:,:])
train_data[di+smoothing_window_size:,:] = scaler.transform(train_data[di+smoothing_window_size:,:])
Reshape de data terug naar de vorm [data_size]
# Reshape both train and test data
train_data = train_data.reshape(-1)
# Normalize test data
test_data = scaler.transform(test_data).reshape(-1)
Je kunt de data nu gladstrijken met de exponentieel voortschrijdend gemiddelde. Dit helpt de inherente ruwheid van koersen te verminderen en een vloeiendere curve te produceren.
Let op dat je alleen trainingsdata moet gladstrijken.
# Now perform exponential moving average smoothing
# So the data will have a smoother curve than the original ragged data
EMA = 0.0
gamma = 0.1
for ti in range(11000):
EMA = gamma*train_data[ti] + (1-gamma)*EMA
train_data[ti] = EMA
# Used for visualization and test purposes
all_mid_data = np.concatenate([train_data,test_data],axis=0)
Middelingsmechanismen stellen je in staat om (vaak één stap vooruit) te voorspellen door de toekomstige koers te representeren als een gemiddelde van eerder geobserveerde koersen. Dit meer dan één stap doen kan vrij slechte resultaten opleveren. Je bekijkt twee techniekken: standaard middelen en exponentieel voortschrijdend gemiddelde. Je evalueert beide kwalitatief (visuele inspectie) en kwantitatief (Mean Squared Error) op de resultaten van de twee algoritmes.
De Mean Squared Error (MSE) kun je berekenen door de kwadratische fout te nemen tussen de werkelijke waarde één stap vooruit en de voorspelde waarde, en die te middelen over alle voorspellingen.
Je kunt de moeilijkheid van dit probleem begrijpen door het eerst te benaderen als een gemiddeldeberekening. Je probeert de toekomstige koersen (bijvoorbeeld xt+1) te voorspellen als het gemiddelde van de eerder geobserveerde koersen binnen een vast venster (bijvoorbeeld xt-N, ..., xt) (zeg de vorige 100 dagen). Daarna probeer je een wat geavanceerdere methode, het "exponentieel voortschrijdend gemiddelde", en kijk je hoe goed die het doet. Vervolgens ga je door naar de "heilige graal" van tijdreeksvoorspelling: Long Short-Term Memory-modellen.
Eerst bekijk je hoe normaal middelen werkt. Dat wil zeggen, je zegt,
Met andere woorden, je zegt dat de voorspelling op $t+1$ de gemiddelde waarde is van alle koersen die je hebt geobserveerd binnen een venster van $t$ tot $t-N$.
window_size = 100
N = train_data.size
std_avg_predictions = []
std_avg_x = []
mse_errors = []
for pred_idx in range(window_size,N):
if pred_idx >= N:
date = dt.datetime.strptime(k, '%Y-%m-%d').date() + dt.timedelta(days=1)
else:
date = df.loc[pred_idx,'Date']
std_avg_predictions.append(np.mean(train_data[pred_idx-window_size:pred_idx]))
mse_errors.append((std_avg_predictions[-1]-train_data[pred_idx])**2)
std_avg_x.append(date)
print('MSE error for standard averaging: %.5f'%(0.5*np.mean(mse_errors)))
MSE error for standard averaging: 0.00418
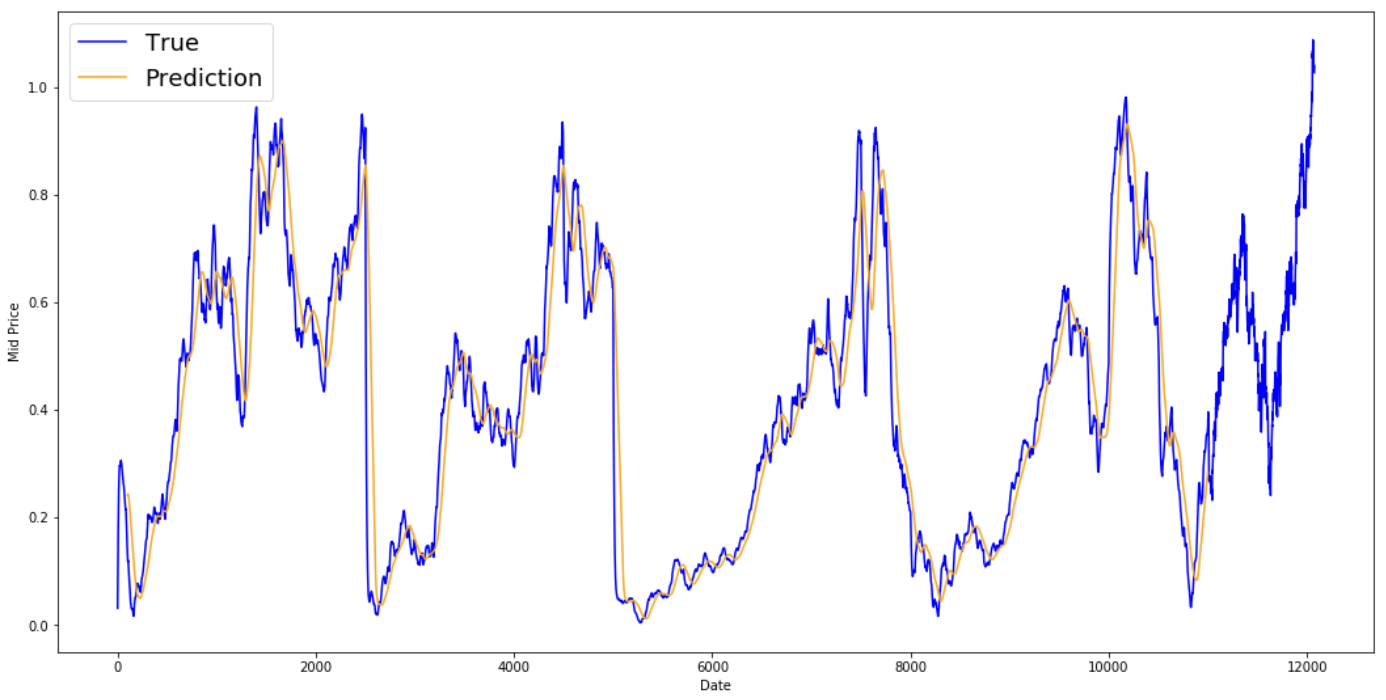
Bekijk hieronder de gemiddelde resultaten. Ze volgen het werkelijke gedrag van het aandeel vrij goed. Vervolgens bekijk je een nauwkeurigere one-step-voorspellingsmethode.
plt.figure(figsize = (18,9)) plt.plot(range(df.shape[0]),all_mid_data,color='b',label='True') plt.plot(range(window_size,N),std_avg_predictions,color='orange',label='Prediction') #plt.xticks(range(0,df.shape[0],50),df['Date'].loc[::50],rotation=45) plt.xlabel('Date') plt.ylabel('Mid Price') plt.legend(fontsize=18) plt.show()
Wat zeggen de bovenstaande grafieken (en de MSE)?
Het lijkt geen slecht model voor zeer korte voorspellingen (één dag vooruit). Dit gedrag is logisch, omdat koersen niet van 0 naar 100 springen van de ene op de andere dag. Vervolgens bekijk je een geavanceerdere middelingstechniek: het exponentieel voortschrijdend gemiddelde.
Je hebt misschien artikelen gezien die zeer complexe modellen gebruiken en bijna het exacte gedrag van de markt voorspellen. Maar pas op! Dit zijn optische illusies en niet het gevolg van het leren van iets nuttigs. Hieronder zie je hoe je dat gedrag kunt repliceren met een simpele middelingsmethode.
Bij het exponentieel voortschrijdend gemiddelde bereken je $x_{t+1}$ als,
De bovenstaande vergelijking berekent in feite het exponentieel voortschrijdend gemiddelde vanaf tijdstap $t+1$ en gebruikt dat als de één-stap-vooruit-voorspelling. $\gamma$ bepaalt hoeveel de meest recente voorspelling bijdraagt aan de EMA. Een $\gamma=0.1$ neemt bijvoorbeeld slechts 10% van de huidige waarde mee in de EMA. Doordat je maar een klein deel van de meest recente waarde meeneemt, blijven veel oudere waarden die je eerder zag bewaard in het gemiddelde. Kijk hoe goed dit eruitziet als je het hieronder gebruikt om één stap vooruit te voorspellen.
window_size = 100
N = train_data.size
run_avg_predictions = []
run_avg_x = []
mse_errors = []
running_mean = 0.0
run_avg_predictions.append(running_mean)
decay = 0.5
for pred_idx in range(1,N):
running_mean = running_mean*decay + (1.0-decay)*train_data[pred_idx-1]
run_avg_predictions.append(running_mean)
mse_errors.append((run_avg_predictions[-1]-train_data[pred_idx])**2)
run_avg_x.append(date)
print('MSE error for EMA averaging: %.5f'%(0.5*np.mean(mse_errors)))
MSE error for EMA averaging: 0.00003
plt.figure(figsize = (18,9))
plt.plot(range(df.shape[0]),all_mid_data,color='b',label='True')
plt.plot(range(0,N),run_avg_predictions,color='orange', label='Prediction')
#plt.xticks(range(0,df.shape[0],50),df['Date'].loc[::50],rotation=45)
plt.xlabel('Date')
plt.ylabel('Mid Price')
plt.legend(fontsize=18)
plt.show()
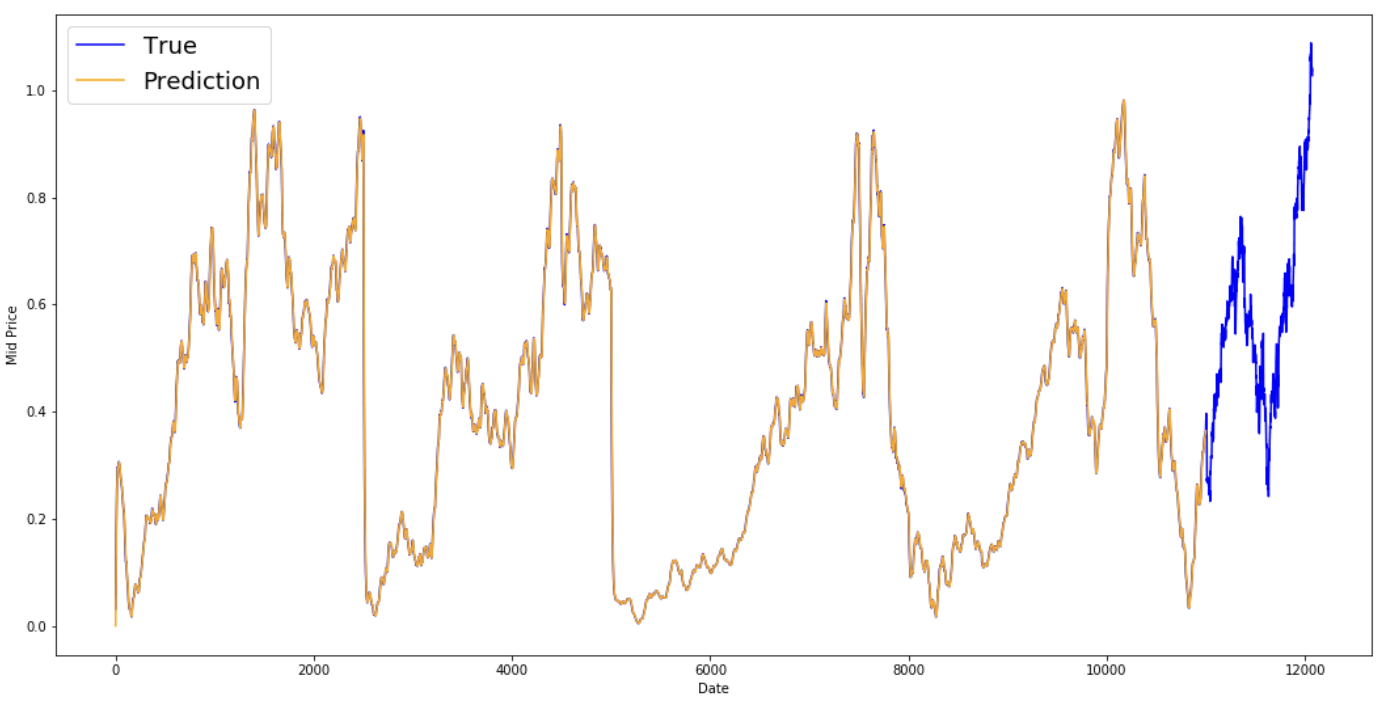
Je ziet dat het een perfecte lijn past die de True-verdeling volgt (en gerechtvaardigd door de zeer lage MSE). Praktisch gezien kun je echter weinig met alleen de koerswaarde van de volgende dag. Persoonlijk wil ik niet de exacte koers van de volgende dag, maar gaan de koersen in de komende 30 dagen omhoog of omlaag? Probeer dit te doen en je legt de onmacht van de EMA-methode bloot.
Je gaat nu voorspellingen doen in vensters (stel dat je het volgende 2-daagse venster voorspelt in plaats van alleen de volgende dag). Dan zul je zien hoe fout EMA kan gaan. Hier is een voorbeeld:
Om het concreet te maken, laten we waarden aannemen, zeg $x_t=0.4$, $EMA=0.5$ en $\gamma = 0.5$
Dus, hoeveel stappen je ook vooruit voorspelt, je krijgt steeds hetzelfde antwoord voor alle toekomstige stappen.
Een oplossing die wel bruikbare informatie oplevert, is kijken naar momentum-gebaseerde algoritmes. Die doen voorspellingen op basis van de vraag of de recente waarden aan het stijgen of dalen waren (niet de exacte waarden). Ze zullen bijvoorbeeld zeggen dat de koers van de volgende dag waarschijnlijk lager zal zijn als de koersen de afgelopen dagen zijn gedaald, wat redelijk klinkt. Jij gaat echter een complexer model gebruiken: een LSTM-model.
Deze modellen hebben het domein van tijdreeksvoorspelling veroverd omdat ze zo goed zijn in het modelleren van tijdreeksdata. Je gaat zien of er daadwerkelijk patronen in de data verborgen zitten die je kunt uitbuiten.
Long Short-Term Memory-modellen zijn extreem krachtige tijdreeksmodellen. Ze kunnen een willekeurig aantal stappen in de toekomst voorspellen. Een LSTM-module (of -cel) heeft 5 essentiële componenten, die het mogelijk maken zowel lange- als kortetermijndata te modelleren.
Een cel is hieronder afgebeeld:
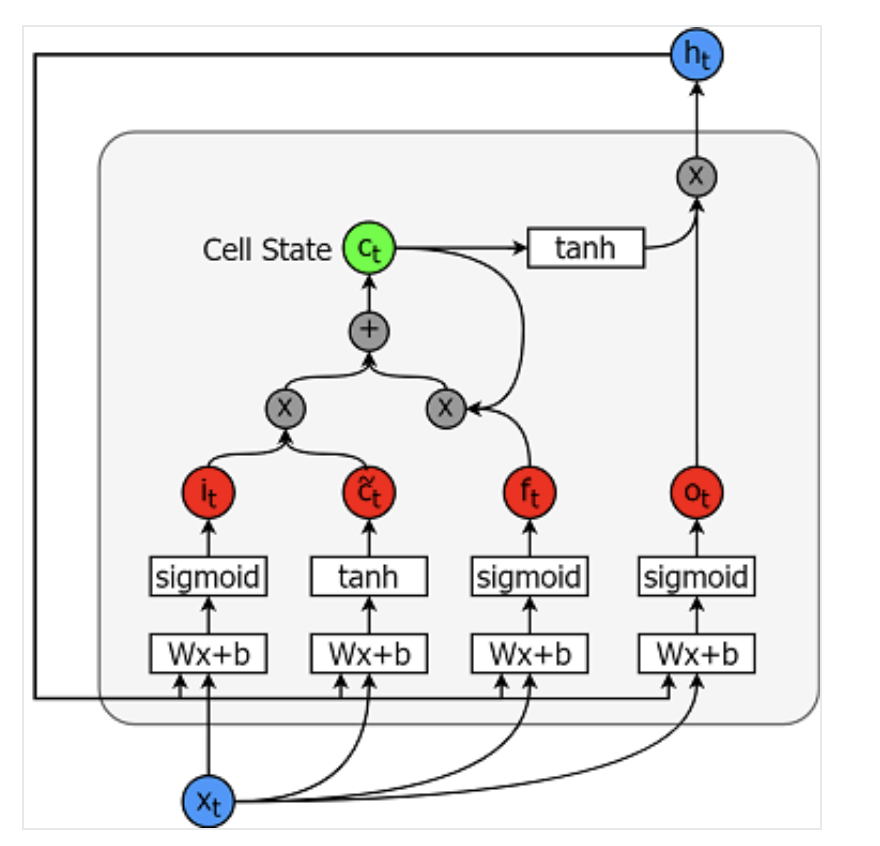
De vergelijkingen voor het berekenen van elk van deze entiteiten zijn als volgt.
Voor een betere (meer technische) uitleg van LSTMs kun je dit artikel raadplegen.
TensorFlow biedt een handige API (RNN API) voor het implementeren van tijdreeksmodellen. Die gebruik je voor je implementaties.
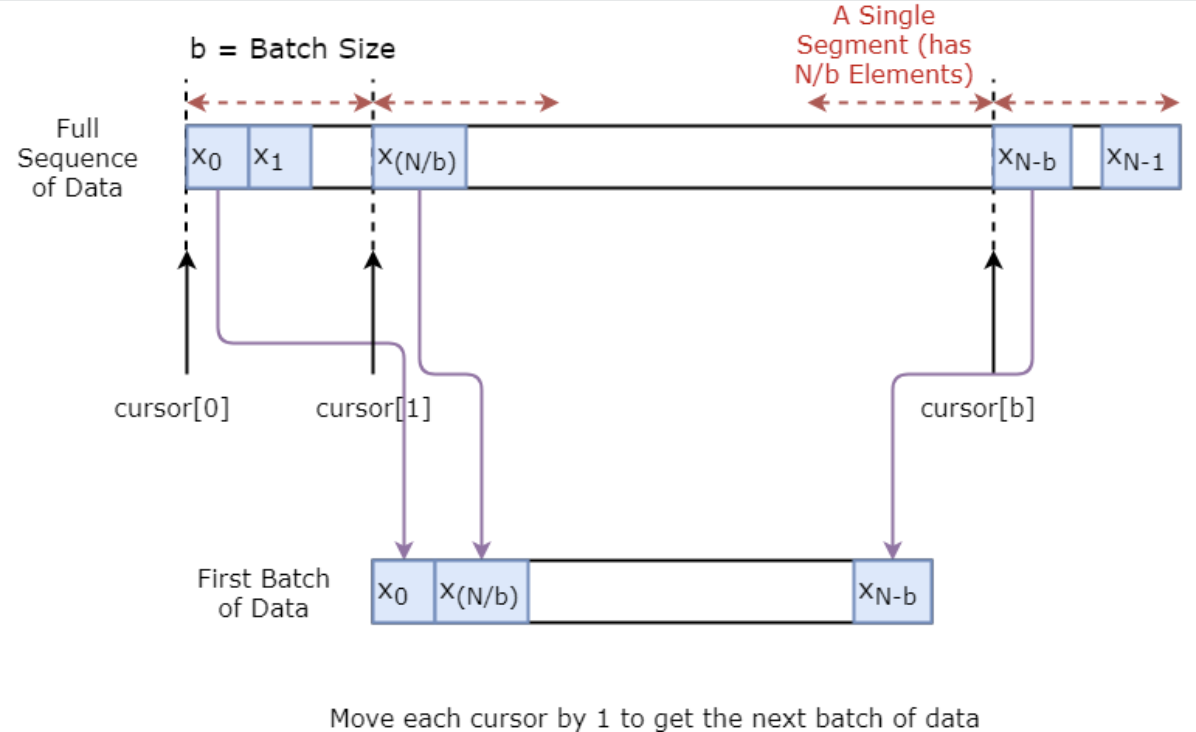
Eerst implementeer je een datagenerator om je model te trainen. Deze generator heeft een methode .unroll_batches(...) die een set van num_unrollings batches met invoerdata achtereenvolgens oplevert, waarbij een batch de vorm [batch_size, 1] heeft. Vervolgens heeft elke batch invoerdata een corresponderende batch met outputdata.
Als bijvoorbeeld num_unrollings=3 en batch_size=4 is, kan een set van unrolled batches er zo uitzien,
Om je model robuust te maken, laat je de output voor $x\_t$ niet altijd $x\_{t+1}$ zijn. In plaats daarvan sample je willekeurig een output uit de set $x\_{t+1},x\_{t+2},\ldots,x_{t+N}$ waarbij $N$ een kleine venstergrootte is.
Hierbij maak je de volgende aanname:
Persoonlijk vind ik dit een redelijke aanname voor voorspellingen van koersbewegingen.
Hieronder illustreer je visueel hoe een batch met data wordt gemaakt.
class DataGeneratorSeq(object):
def __init__(self,prices,batch_size,num_unroll):
self._prices = prices
self._prices_length = len(self._prices) - num_unroll
self._batch_size = batch_size
self._num_unroll = num_unroll
self._segments = self._prices_length //self._batch_size
self._cursor = [offset * self._segments for offset in range(self._batch_size)]
def next_batch(self):
batch_data = np.zeros((self._batch_size),dtype=np.float32)
batch_labels = np.zeros((self._batch_size),dtype=np.float32)
for b in range(self._batch_size):
if self._cursor[b]+1>=self._prices_length:
#self._cursor[b] = b * self._segments
self._cursor[b] = np.random.randint(0,(b+1)*self._segments)
batch_data[b] = self._prices[self._cursor[b]]
batch_labels[b]= self._prices[self._cursor[b]+np.random.randint(0,5)]
self._cursor[b] = (self._cursor[b]+1)%self._prices_length
return batch_data,batch_labels
def unroll_batches(self):
unroll_data,unroll_labels = [],[]
init_data, init_label = None,None
for ui in range(self._num_unroll):
data, labels = self.next_batch()
unroll_data.append(data)
unroll_labels.append(labels)
return unroll_data, unroll_labels
def reset_indices(self):
for b in range(self._batch_size):
self._cursor[b] = np.random.randint(0,min((b+1)*self._segments,self._prices_length-1))
dg = DataGeneratorSeq(train_data,5,5)
u_data, u_labels = dg.unroll_batches()
for ui,(dat,lbl) in enumerate(zip(u_data,u_labels)):
print('\n\nUnrolled index %d'%ui)
dat_ind = dat
lbl_ind = lbl
print('\tInputs: ',dat )
print('\n\tOutput:',lbl)
Unrolled index 0
Inputs: [0.03143791 0.6904868 0.82829314 0.32585657 0.11600105]
Output: [0.08698314 0.68685144 0.8329321 0.33355275 0.11785509]
Unrolled index 1
Inputs: [0.06067836 0.6890754 0.8325337 0.32857886 0.11785509]
Output: [0.15261841 0.68685144 0.8325337 0.33421066 0.12106793]
Unrolled index 2
Inputs: [0.08698314 0.68685144 0.8329321 0.33078218 0.11946969]
Output: [0.11098009 0.6848606 0.83387965 0.33421066 0.12106793]
Unrolled index 3
Inputs: [0.11098009 0.6858036 0.83294916 0.33219692 0.12106793]
Output: [0.132895 0.6836884 0.83294916 0.33219692 0.12288672]
Unrolled index 4
Inputs: [0.132895 0.6848606 0.833369 0.33355275 0.12158521]
Output: [0.15261841 0.6836884 0.83383167 0.33355275 0.12230608]
In deze sectie definieer je verschillende hyperparameters. D is de dimensionaliteit van de input. Dat is eenvoudig, want je neemt de vorige koers als input en voorspelt de volgende, wat 1 zou moeten zijn.
Dan heb je num_unrollings, een hyperparameter die te maken heeft met backpropagation through time (BPTT), waarmee het LSTM-model wordt geoptimaliseerd. Dit geeft aan hoeveel aaneengesloten tijdstappen je meeneemt voor één optimalisatiestap. Je kunt dit zien als: in plaats van optimaliseren op basis van één tijdstap, optimaliseer je het netwerk op basis van num_unrollings tijdstappen. Hoe groter, hoe beter.
Vervolgens is er de batch_size. Batchgrootte is hoeveel datamonsters je in één tijdstap meeneemt.
Daarna definieer je num_nodes, het aantal verborgen neuronen in elke cel. Je ziet dat er in dit voorbeeld drie lagen LSTMs zijn.
D = 1 # Dimensionality of the data. Since your data is 1-D this would be 1
num_unrollings = 50 # Number of time steps you look into the future.
batch_size = 500 # Number of samples in a batch
num_nodes = [200,200,150] # Number of hidden nodes in each layer of the deep LSTM stack we're using
n_layers = len(num_nodes) # number of layers
dropout = 0.2 # dropout amount
tf.reset_default_graph() # This is important in case you run this multiple times
Vervolgens definieer je placeholders voor trainingsinputs en -labels. Dit is vrij rechttoe rechtaan: je hebt een lijst met input-placeholders, elk met een enkele batch data. En de lijst heeft num_unrollings placeholders, die tegelijk worden gebruikt voor één optimalisatiestap.
# Input data.
train_inputs, train_outputs = [],[]
# You unroll the input over time defining placeholders for each time step
for ui in range(num_unrollings):
train_inputs.append(tf.placeholder(tf.float32, shape=[batch_size,D],name='train_inputs_%d'%ui))
train_outputs.append(tf.placeholder(tf.float32, shape=[batch_size,1], name = 'train_outputs_%d'%ui))
Je gebruikt drie lagen LSTMs en een lineaire regressielaag, aangeduid met w en b, die de output van de laatste LSTM-cel neemt en de voorspelling voor de volgende tijdstap geeft. Je kunt de MultiRNNCell in TensorFlow gebruiken om de drie LSTMCell-objecten te kapselen. Daarnaast kun je LSTM-cellen met dropout gebruiken, omdat die de prestaties verbeteren en overfitting verminderen.
lstm_cells = [
tf.contrib.rnn.LSTMCell(num_units=num_nodes[li],
state_is_tuple=True,
initializer= tf.contrib.layers.xavier_initializer()
)
for li in range(n_layers)]
drop_lstm_cells = [tf.contrib.rnn.DropoutWrapper(
lstm, input_keep_prob=1.0,output_keep_prob=1.0-dropout, state_keep_prob=1.0-dropout
) for lstm in lstm_cells]
drop_multi_cell = tf.contrib.rnn.MultiRNNCell(drop_lstm_cells)
multi_cell = tf.contrib.rnn.MultiRNNCell(lstm_cells)
w = tf.get_variable('w',shape=[num_nodes[-1], 1], initializer=tf.contrib.layers.xavier_initializer())
b = tf.get_variable('b',initializer=tf.random_uniform([1],-0.1,0.1))
In deze sectie maak je eerst TensorFlow-variabelen (c en h) die de cell state en hidden state van de LSTM bijhouden. Vervolgens zet je de lijst train_inputs om naar de vorm [num_unrollings, batch_size, D], wat nodig is voor het berekenen van de outputs met tf.nn.dynamic_rnn. Daarna bereken je de LSTM-outputs met tf.nn.dynamic_rnn en splits je de output terug naar een lijst van num_unrolling-tensors. het verlies tussen de voorspellingen en de werkelijke koersen.
# Create cell state and hidden state variables to maintain the state of the LSTM
c, h = [],[]
initial_state = []
for li in range(n_layers):
c.append(tf.Variable(tf.zeros([batch_size, num_nodes[li]]), trainable=False))
h.append(tf.Variable(tf.zeros([batch_size, num_nodes[li]]), trainable=False))
initial_state.append(tf.contrib.rnn.LSTMStateTuple(c[li], h[li]))
# Do several tensor transofmations, because the function dynamic_rnn requires the output to be of
# a specific format. Read more at: https://www.tensorflow.org/api_docs/python/tf/nn/dynamic_rnn
all_inputs = tf.concat([tf.expand_dims(t,0) for t in train_inputs],axis=0)
# all_outputs is [seq_length, batch_size, num_nodes]
all_lstm_outputs, state = tf.nn.dynamic_rnn(
drop_multi_cell, all_inputs, initial_state=tuple(initial_state),
time_major = True, dtype=tf.float32)
all_lstm_outputs = tf.reshape(all_lstm_outputs, [batch_size*num_unrollings,num_nodes[-1]])
all_outputs = tf.nn.xw_plus_b(all_lstm_outputs,w,b)
split_outputs = tf.split(all_outputs,num_unrollings,axis=0)
Nu bereken je het verlies. Let op een bijzonder kenmerk bij het berekenen ervan. Voor elke batch voorspellingen en echte outputs bereken je de Mean Squared Error. En je somt (niet gemiddelde) al deze mean squared losses op. Tot slot definieer je de optimizer voor het optimaliseren van het neurale netwerk. In dit geval kun je Adam gebruiken, een recente en goed presterende optimizer.
# When calculating the loss you need to be careful about the exact form, because you calculate
# loss of all the unrolled steps at the same time
# Therefore, take the mean error or each batch and get the sum of that over all the unrolled steps
print('Defining training Loss')
loss = 0.0
with tf.control_dependencies([tf.assign(c[li], state[li][0]) for li in range(n_layers)]+
[tf.assign(h[li], state[li][1]) for li in range(n_layers)]):
for ui in range(num_unrollings):
loss += tf.reduce_mean(0.5*(split_outputs[ui]-train_outputs[ui])**2)
print('Learning rate decay operations')
global_step = tf.Variable(0, trainable=False)
inc_gstep = tf.assign(global_step,global_step + 1)
tf_learning_rate = tf.placeholder(shape=None,dtype=tf.float32)
tf_min_learning_rate = tf.placeholder(shape=None,dtype=tf.float32)
learning_rate = tf.maximum(
tf.train.exponential_decay(tf_learning_rate, global_step, decay_steps=1, decay_rate=0.5, staircase=True),
tf_min_learning_rate)
# Optimizer.
print('TF Optimization operations')
optimizer = tf.train.AdamOptimizer(learning_rate)
gradients, v = zip(*optimizer.compute_gradients(loss))
gradients, _ = tf.clip_by_global_norm(gradients, 5.0)
optimizer = optimizer.apply_gradients(
zip(gradients, v))
print('\tAll done')
Defining training Loss
Learning rate decay operations
TF Optimization operations
All done
Hier definieer je de TensorFlow-bewerkingen voor voorspellen. Definieer eerst een placeholder voor de input (sample_inputs), en net als bij de trainingsfase definieer je statusvariabelen voor voorspellen (sample_c en sample_h). Ten slotte bereken je de voorspelling met tf.nn.dynamic_rnn en stuur je de output door de regressielaag (w en b). Je moet ook de operatie reset_sample_state definiëren, die de cell state en hidden state reset. Voer deze operatie aan het begin uit telkens als je een reeks voorspellingen maakt.
print('Defining prediction related TF functions')
sample_inputs = tf.placeholder(tf.float32, shape=[1,D])
# Maintaining LSTM state for prediction stage
sample_c, sample_h, initial_sample_state = [],[],[]
for li in range(n_layers):
sample_c.append(tf.Variable(tf.zeros([1, num_nodes[li]]), trainable=False))
sample_h.append(tf.Variable(tf.zeros([1, num_nodes[li]]), trainable=False))
initial_sample_state.append(tf.contrib.rnn.LSTMStateTuple(sample_c[li],sample_h[li]))
reset_sample_states = tf.group(*[tf.assign(sample_c[li],tf.zeros([1, num_nodes[li]])) for li in range(n_layers)],
*[tf.assign(sample_h[li],tf.zeros([1, num_nodes[li]])) for li in range(n_layers)])
sample_outputs, sample_state = tf.nn.dynamic_rnn(multi_cell, tf.expand_dims(sample_inputs,0),
initial_state=tuple(initial_sample_state),
time_major = True,
dtype=tf.float32)
with tf.control_dependencies([tf.assign(sample_c[li],sample_state[li][0]) for li in range(n_layers)]+
[tf.assign(sample_h[li],sample_state[li][1]) for li in range(n_layers)]):
sample_prediction = tf.nn.xw_plus_b(tf.reshape(sample_outputs,[1,-1]), w, b)
print('\tAll done')
Defining prediction related TF functions
All done
Hier train en voorspel je koersbewegingen gedurende meerdere epochs en kijk je of de voorspellingen beter of slechter worden in de tijd. Je volgt deze procedure.
test_points_seq) op de tijdreeks om het model op te evaluerennum_unrollings batches uitnum_unrollings datapunten vóór het testpuntn_predict_once stappen achter elkaar, waarbij je de vorige voorspelling als huidige input gebruiktn_predict_once voorspelde punten en de werkelijke koersen op die tijdstippenepochs = 30
valid_summary = 1 # Interval you make test predictions
n_predict_once = 50 # Number of steps you continously predict for
train_seq_length = train_data.size # Full length of the training data
train_mse_ot = [] # Accumulate Train losses
test_mse_ot = [] # Accumulate Test loss
predictions_over_time = [] # Accumulate predictions
session = tf.InteractiveSession()
tf.global_variables_initializer().run()
# Used for decaying learning rate
loss_nondecrease_count = 0
loss_nondecrease_threshold = 2 # If the test error hasn't increased in this many steps, decrease learning rate
print('Initialized')
average_loss = 0
# Define data generator
data_gen = DataGeneratorSeq(train_data,batch_size,num_unrollings)
x_axis_seq = []
# Points you start your test predictions from
test_points_seq = np.arange(11000,12000,50).tolist()
for ep in range(epochs):
# ========================= Training =====================================
for step in range(train_seq_length//batch_size):
u_data, u_labels = data_gen.unroll_batches()
feed_dict = {}
for ui,(dat,lbl) in enumerate(zip(u_data,u_labels)):
feed_dict[train_inputs[ui]] = dat.reshape(-1,1)
feed_dict[train_outputs[ui]] = lbl.reshape(-1,1)
feed_dict.update({tf_learning_rate: 0.0001, tf_min_learning_rate:0.000001})
_, l = session.run([optimizer, loss], feed_dict=feed_dict)
average_loss += l
# ============================ Validation ==============================
if (ep+1) % valid_summary == 0:
average_loss = average_loss/(valid_summary*(train_seq_length//batch_size))
# The average loss
if (ep+1)%valid_summary==0:
print('Average loss at step %d: %f' % (ep+1, average_loss))
train_mse_ot.append(average_loss)
average_loss = 0 # reset loss
predictions_seq = []
mse_test_loss_seq = []
# ===================== Updating State and Making Predicitons ========================
for w_i in test_points_seq:
mse_test_loss = 0.0
our_predictions = []
if (ep+1)-valid_summary==0:
# Only calculate x_axis values in the first validation epoch
x_axis=[]
# Feed in the recent past behavior of stock prices
# to make predictions from that point onwards
for tr_i in range(w_i-num_unrollings+1,w_i-1):
current_price = all_mid_data[tr_i]
feed_dict[sample_inputs] = np.array(current_price).reshape(1,1)
_ = session.run(sample_prediction,feed_dict=feed_dict)
feed_dict = {}
current_price = all_mid_data[w_i-1]
feed_dict[sample_inputs] = np.array(current_price).reshape(1,1)
# Make predictions for this many steps
# Each prediction uses previous prediciton as it's current input
for pred_i in range(n_predict_once):
pred = session.run(sample_prediction,feed_dict=feed_dict)
our_predictions.append(np.asscalar(pred))
feed_dict[sample_inputs] = np.asarray(pred).reshape(-1,1)
if (ep+1)-valid_summary==0:
# Only calculate x_axis values in the first validation epoch
x_axis.append(w_i+pred_i)
mse_test_loss += 0.5*(pred-all_mid_data[w_i+pred_i])**2
session.run(reset_sample_states)
predictions_seq.append(np.array(our_predictions))
mse_test_loss /= n_predict_once
mse_test_loss_seq.append(mse_test_loss)
if (ep+1)-valid_summary==0:
x_axis_seq.append(x_axis)
current_test_mse = np.mean(mse_test_loss_seq)
# Learning rate decay logic
if len(test_mse_ot)>0 and current_test_mse > min(test_mse_ot):
loss_nondecrease_count += 1
else:
loss_nondecrease_count = 0
if loss_nondecrease_count > loss_nondecrease_threshold :
session.run(inc_gstep)
loss_nondecrease_count = 0
print('\tDecreasing learning rate by 0.5')
test_mse_ot.append(current_test_mse)
print('\tTest MSE: %.5f'%np.mean(mse_test_loss_seq))
predictions_over_time.append(predictions_seq)
print('\tFinished Predictions')
Initialized
Average loss at step 1: 1.703350
Test MSE: 0.00318
Finished Predictions
...
...
...
Average loss at step 30: 0.033753
Test MSE: 0.00243
Finished Predictions
Je ziet dat het MSE-verlies daalt naarmate er meer getraind wordt. Dit is een goed teken dat het model iets nuttigs leert. Om je bevindingen te kwantificeren, kun je de MSE van het netwerk vergelijken met de MSE die je kreeg bij standaard middelen (0.004). Je ziet dat de LSTM beter presteert dan standaard middelen. En je weet dat standaard middelen (hoewel niet perfect) de werkelijke koersbewegingen redelijk volgde.
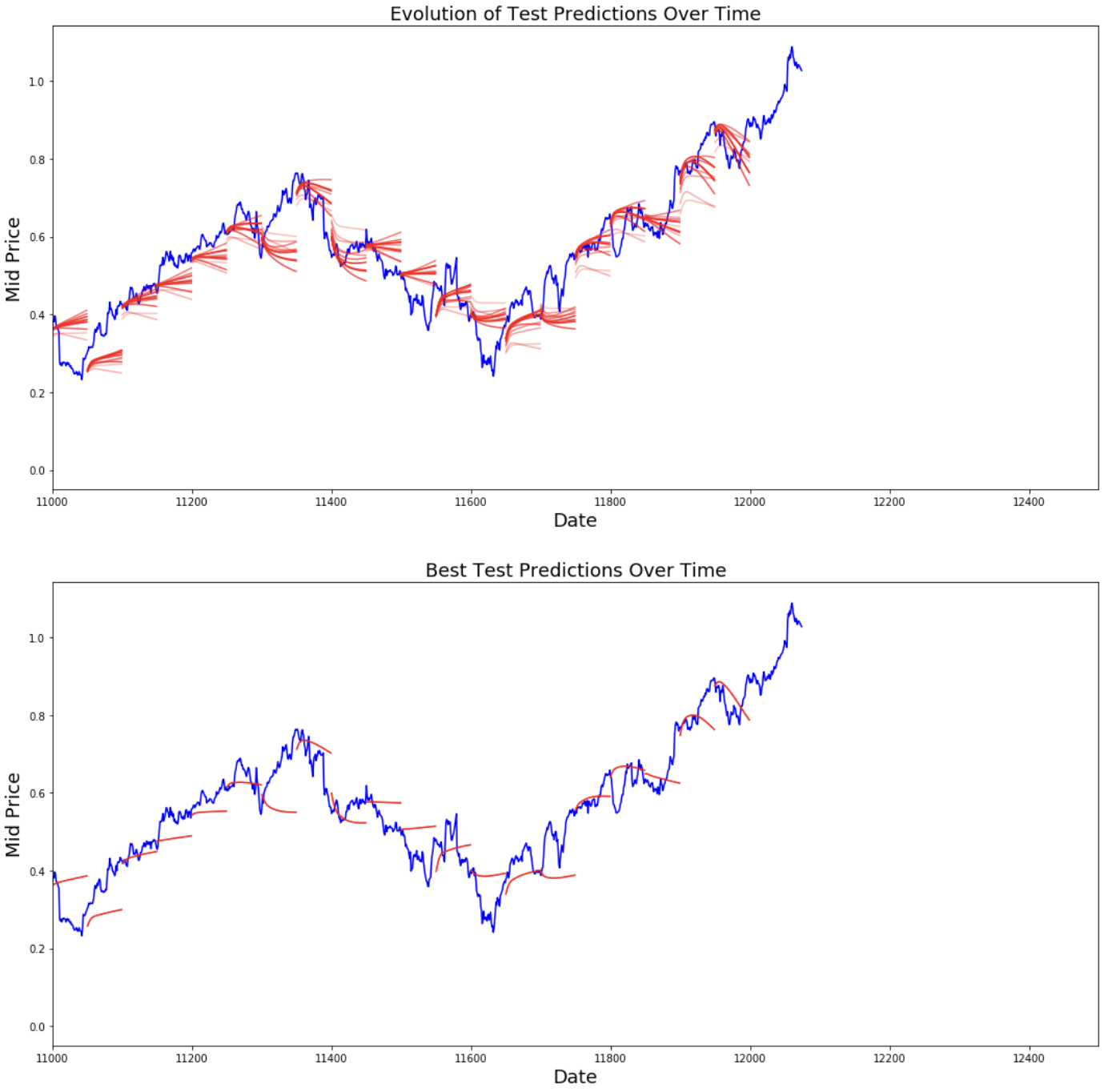
best_prediction_epoch = 28 # replace this with the epoch that you got the best results when running the plotting code plt.figure(figsize = (18,18)) plt.subplot(2,1,1) plt.plot(range(df.shape[0]),all_mid_data,color='b') # Plotting how the predictions change over time # Plot older predictions with low alpha and newer predictions with high alpha start_alpha = 0.25 alpha = np.arange(start_alpha,1.1,(1.0-start_alpha)/len(predictions_over_time[::3])) for p_i,p in enumerate(predictions_over_time[::3]): for xval,yval in zip(x_axis_seq,p): plt.plot(xval,yval,color='r',alpha=alpha[p_i]) plt.title('Evolution of Test Predictions Over Time',fontsize=18) plt.xlabel('Date',fontsize=18) plt.ylabel('Mid Price',fontsize=18) plt.xlim(11000,12500) plt.subplot(2,1,2) # Predicting the best test prediction you got plt.plot(range(df.shape[0]),all_mid_data,color='b') for xval,yval in zip(x_axis_seq,predictions_over_time[best_prediction_epoch]): plt.plot(xval,yval,color='r') plt.title('Best Test Predictions Over Time',fontsize=18) plt.xlabel('Date',fontsize=18) plt.ylabel('Mid Price',fontsize=18) plt.xlim(11000,12500) plt.show()
Hoewel niet perfect, lijken LSTMs het koersgedrag meestal correct te kunnen voorspellen. Let op dat je voorspellingen doet ruwweg in het bereik 0 tot 1,0 (dus niet de echte koersen). Dat is prima, want je voorspelt de koersbeweging, niet de koers zelf.
Ik hoop dat je deze tutorial nuttig vond. Voor mij was dit een waardevolle ervaring. In deze tutorial leerde ik hoe lastig het kan zijn om een model te bedenken dat koersbewegingen correct kan voorspellen. Je begon met de motivatie waarom je koersen wilt modelleren. Daarna volgden uitleg en code voor het downloaden van data. Vervolgens bekeek je twee middelingsmethoden die voorspellingen één stap vooruit mogelijk maken. Je zag daarna dat deze methoden nutteloos zijn als je meer dan één stap vooruit moet voorspellen. Vervolgens besprak je hoe je LSTMs kunt gebruiken om veel stappen vooruit te voorspellen. Tot slot visualiseerde je de resultaten en zag je dat je model (hoewel niet perfect) vrij goed is in het correct voorspellen van koersbewegingen.
Als je meer wilt leren over deep learning, bekijk dan zeker onze Deep Learning in Python-cursus. Die behandelt de basis en laat zien hoe je zelf een neuraal netwerk bouwt in Keras. Dit is een ander pakket dan TensorFlow, dat in deze tutorial wordt gebruikt, maar het idee is hetzelfde.
Hier noem ik enkele belangrijke takeaways uit deze tutorial.
Koers-/bewegingvoorspellingen zijn extreem moeilijk. Persoonlijk vind ik dat geen enkel koersvoorspellingsmodel klakkeloos voor waar moet worden aangenomen of dat je er blind op moet vertrouwen. Modellen kunnen koersbewegingen vaak wel correct voorspellen, maar niet altijd.
Laat je niet misleiden door artikelen die voorspelde curves tonen die perfect overlappen met de echte koersen. Dit is te reproduceren met een eenvoudige middelingsmethode en is in de praktijk nutteloos. Zinvoller is het om koersbewegingen te voorspellen.
De hyperparameters van het model zijn extreem gevoelig voor de resultaten die je krijgt. Een goed idee is daarom om hyperparameteroptimalisatie (bijvoorbeeld Grid search / Random search) toe te passen. Hieronder staan enkele van de meest kritieke hyperparameters:
In deze tutorial heb je iets gedaan dat niet helemaal zuiver is (vanwege de kleine hoeveelheid data)! Je gebruikte namelijk de testloss om de learning rate te verlagen. Dit lekt indirect informatie over de testset in de trainingsprocedure. Een betere aanpak is een aparte validatieset te hebben (naast de testset) en de learning rate te verlagen op basis van de prestaties op de validatieset.
Als je contact met me wilt opnemen, kun je me mailen op thushv@gmail.com of connecten op LinkedIn.
Ik heb deze repository geraadpleegd om te begrijpen hoe je LSTMs kunt gebruiken voor koersvoorspellingen. De details kunnen echter sterk afwijken van de implementatie in de referentie.
Leer meer over Python en Deep Learning
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
