
Kursus
Inferensi untuk Regresi Linear di R
4 Hr
16K

Metode regresi digunakan di berbagai industri untuk memahami variabel mana yang memengaruhi suatu topik yang diminati.
Misalnya, ekonom dapat menggunakannya untuk menganalisis hubungan antara pengeluaran konsumen dan pertumbuhan Produk Domestik Bruto (PDB). Pejabat kesehatan masyarakat mungkin ingin memahami biaya per individu berdasarkan informasi historisnya. Pada kedua kasus, fokusnya bukan memprediksi skenario individual, melainkan memperoleh gambaran hubungan secara keseluruhan.
Dalam artikel ini, kita akan mulai dengan memberikan pemahaman umum tentang regresi. Lalu, kita akan menjelaskan apa yang membedakan regresi linier sederhana dan berganda sebelum membahas implementasi teknis dan menyediakan alat untuk membantu Anda memahami serta menafsirkan hasil regresi.
Mari pahami dulu apa itu regresi linier sederhana sebelum membahas regresi linier berganda, yang pada dasarnya merupakan perluasan dari regresi linier sederhana.
Regresi linier sederhana bertujuan memodelkan hubungan antara besaran satu variabel independen X dan variabel dependen Y dengan mencoba mengestimasi secara tepat seberapa besar Y akan berubah ketika X berubah sejumlah tertentu.
Variabel independen X, juga disebut prediktor, adalah variabel yang digunakan untuk membuat prediksi.
Variabel dependen Y, juga dikenal sebagai respons, adalah variabel yang ingin kita prediksi.
Aspek “linier” dari regresi linier adalah bahwa kita mencoba memprediksi Y dari X menggunakan persamaan “linier” berikut.
Y = b0 + b1X
b0 adalah intersep garis regresi, yang sesuai dengan nilai prediksi ketika X bernilai nol.
b1 adalah kemiringan (slope) garis regresi.
Lalu, bagaimana dengan regresi linier berganda?
Ini adalah penggunaan regresi linier dengan banyak variabel, dan persamaannya adalah:
Y = b0 + b1X1 + b2X2 + b3X3 + … + bnXn + e
Y dan b0 sama seperti pada model regresi linier sederhana.
b1X1 merepresentasikan koefisien regresi (b1) pada variabel independen pertama (X1). Analisis yang sama berlaku untuk semua koefisien regresi dan variabel lainnya.
e adalah galat model (residual), yang mendefinisikan seberapa besar variasi yang diperkenalkan ke dalam model saat mengestimasi Y.
Kita mungkin tidak selalu mendapatkan garis lurus untuk kasus regresi berganda. Namun, kita dapat mengendalikan bentuk garis dengan menyesuaikan model yang lebih tepat.
Berikut beberapa elemen kunci yang dihitung oleh regresi linier berganda untuk menemukan garis terbaik untuk setiap prediktor.
Aspek penting saat membangun model regresi linier berganda adalah memastikan asumsi-asumsi kunci berikut terpenuhi.
Pada bagian selanjutnya, kita akan membahas beberapa asumsi ini.
Pada bagian ini, kita akan membahas implementasi teknis model regresi linier berganda menggunakan bahasa pemrograman R.
Kita akan menggunakan set data customer churn dari workspace DataCamp untuk mengestimasi nilai pelanggan.
Apa yang dimaksud dengan nilai pelanggan? Secara sederhana, ini menentukan seberapa bernilai suatu produk atau layanan bagi pelanggan, dan kita dapat menghitungnya sebagai berikut:
Customer Value = Benefit — Cost. Di mana Benefit dan Cost masing-masing adalah manfaat dan biaya dari suatu produk atau layanan.
Nilai ini lebih tinggi jika perusahaan dapat menawarkan manfaat lebih besar dan biaya lebih rendah kepada konsumen, atau idealnya, kombinasi keduanya.
Analisis ini dapat membantu bisnis mengidentifikasi peluang target yang paling menjanjikan atau tindakan terbaik berikutnya berdasarkan nilai pelanggan tertentu.
Mari melihat sekilas set data sehingga kita dapat menerapkan prapemrosesan yang relevan sebelum menyesuaikan model.
churn_data = read_csv('data/customer_churn.csv', show_col_types = FALSE)
# Look at the first 6 observations
head(churn_data)
# Check the dimension
dim(churn_data)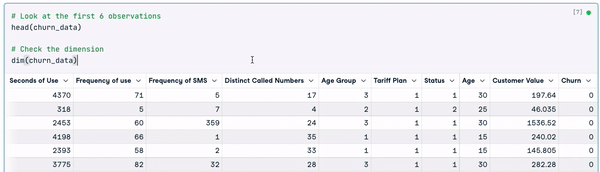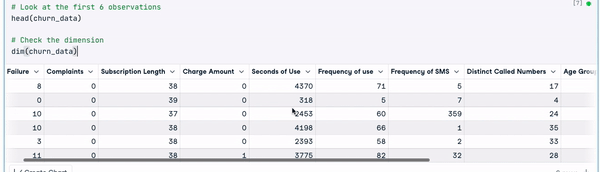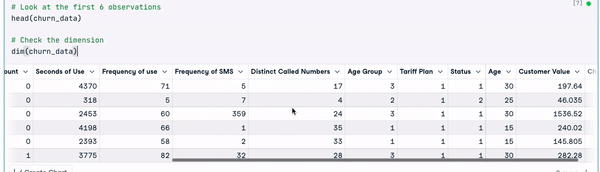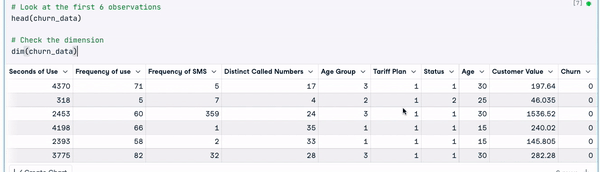
Enam baris pertama data (Animasi oleh Penulis)
Dari hasil sebelumnya, kita dapat melihat bahwa set data memiliki 3150 observasi dan 14 kolom.
Namun, berdasarkan pernyataan masalah, kita tidak memerlukan kolom churn karena kita sekarang menangani masalah regresi.
Sebelum menyesuaikan model, mari praproses nama kolom dengan mengganti spasi pada nama kolom menjadi garis bawah untuk menghindari penulisan tanda kutip ganda di sekitar nama variabel setiap saat.
# Change the column names
names(churn_data) = gsub(" ", "_", names(churn_data))
head(churn_data)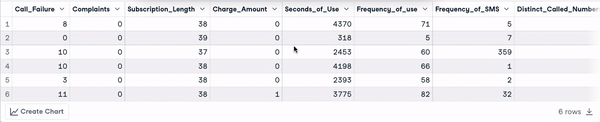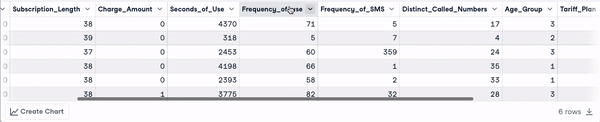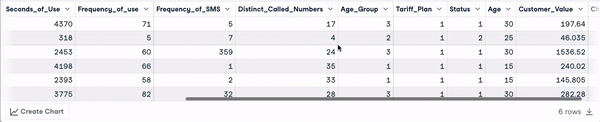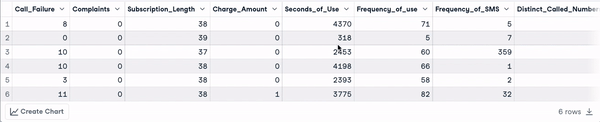
Enam baris pertama setelah transformasi nama kolom (animasi oleh penulis)
Dengan data yang telah diformat ulang ini, kita dapat memasukkannya ke dalam kerangka regresi berganda menggunakan fungsi lm() di R sebagai berikut:
# Fit the multiple linear regression model
cust_value_model = lm(formula = Customer_Value ~ Call_Failure +
Complaints + Subscription_Length + Charge_Amount +
Seconds_of_Use +Frequency_of_use + Frequency_of_SMS +
Distinct_Called_Numbers + Age_Group + Tariff_Plan +
Status + Age,data = churn_data)Mari pahami apa yang baru saja kita lakukan.
Fungsi lm() berbentuk sebagai berikut: lm(formula = Y ~Sum(Xi), data = our_data)
Y adalah kolom Customer_Value karena itulah yang kita coba estimasi.
Sum(Xi) merepresentasikan ekspresi jumlah pada persamaan regresi linier berganda.
our_data adalah churn_data.
Anda dapat mempelajari lebih lanjut dari kursus kami Intermediate Regression in R.
Alternatif untuk R adalah Python: Intermediate Regression with statsmodels in Python. Keduanya membantu Anda mempelajari regresi linier dan logistik dengan banyak variabel penjelas.
Sekarang kita telah membangun model, langkah berikutnya adalah memeriksa asumsi dan menafsirkan hasilnya. Demi kesederhanaan, kita tidak akan membahas semua aspeknya.
Ini dapat ditampilkan di R menggunakan fungsi hist().
# Get the model residuals
model_residuals = cust_value_model$residuals
# Plot the result
hist(model_residuals)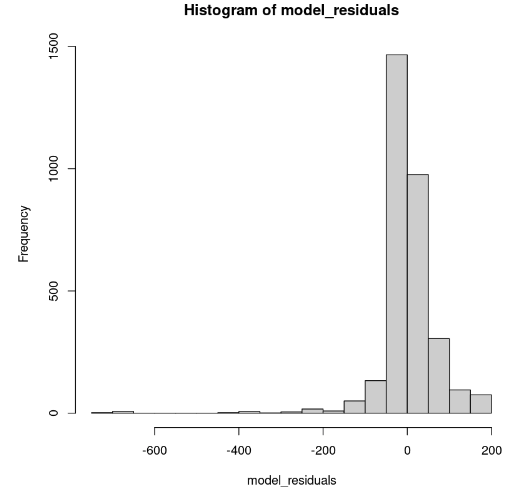
Distribusi residual model (Gambar oleh Penulis)
Histogram terlihat miring ke kiri; karenanya, kita tidak dapat menyimpulkan normalitas dengan cukup yakin. Alih-alih histogram, mari lihat residual pada plot Q-Q normal. Jika ada normalitas, maka nilainya akan mengikuti garis lurus.
# Plot the residuals
qqnorm(model_residuals)
# Plot the Q-Q line
qqline(model_residuals)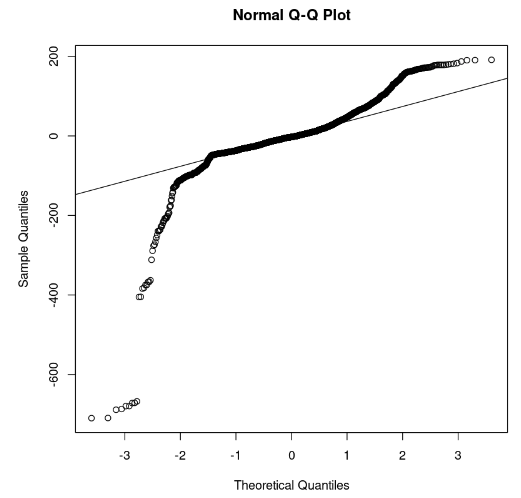
Plot Q-Q dan residual (Gambar oleh Penulis)
Dari plot, kita dapat mengamati bahwa beberapa bagian residual berada pada garis lurus. Maka kita dapat mengasumsikan bahwa residual model tidak mengikuti distribusi normal.
Ini dilakukan melalui kode R berikut. Namun kita harus menghapus kolom Customer_Value terlebih dahulu.
# Install and load the ggcorrplot package
install.packages("ggcorrplot")
library(ggcorrplot)
# Remove the Customer Value column
reduced_data <- subset(churn_data, select = -Customer_Value)
# Compute correlation at 2 decimal places
corr_matrix = round(cor(reduced_data), 2)
# Compute and show the result
ggcorrplot(corr_matrix, hc.order = TRUE, type = "lower",
lab = TRUE)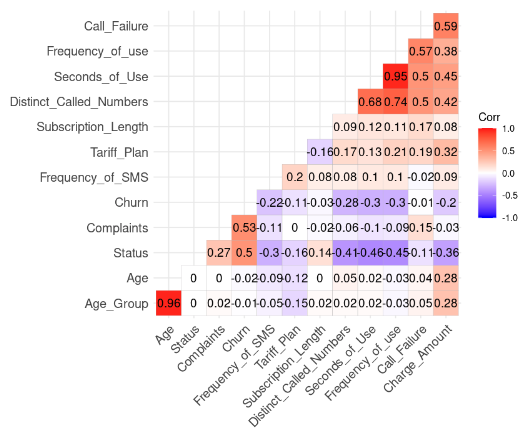
Hasil korelasi dari data (Gambar oleh Penulis)
Kita dapat melihat dua korelasi kuat karena nilainya lebih tinggi dari 0,8.
Age dan Age_Group: 0,96
Frequency_of_use dan Seconds_of_Use: 0,95
Hasil ini masuk akal karena Age_Group dihitung dari Age. Selain itu, total jumlah detik (Seconds_of_Use) diturunkan dari total jumlah panggilan (Frequency_of_Use).
Dalam kasus ini, kita dapat menyingkirkan Age_Group dan Seconds_of_Use dari dataset.
Mari coba membangun model kedua tanpa kedua variabel tersebut.
second_model = lm(formula = Customer_Value ~ Call_Failure + Complaints +
Subscription_Length + Charge_Amount +
Frequency_of_use + Frequency_of_SMS +
Distinct_Called_Numbers + Tariff_Plan +
Status + Age,
data = churn_data)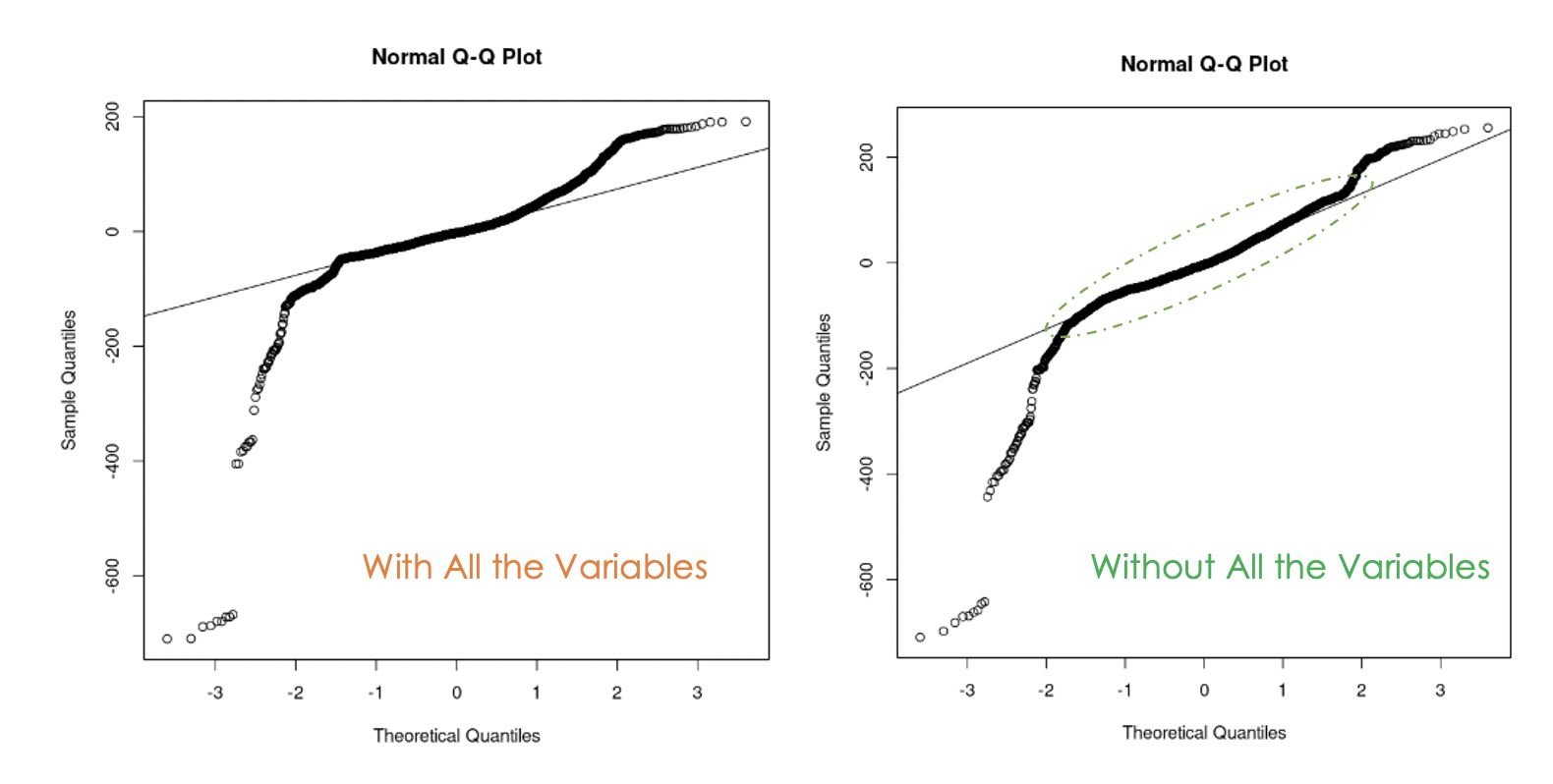
Plot Q-Q dari model pertama (kiri) dan model kedua (kanan)
Kita dapat melihat bahwa menyingkirkan multikolinearitas dalam data membantu karena pada model kedua, lebih banyak nilai residual berada pada garis lurus dibandingkan model pertama.
Sekarang tersisa satu pertanyaan: Manakah dari dua model regresi linier berganda yang lebih baik?
Salah satu cara menjawab pertanyaan ini adalah menjalankan uji analisis varians (ANOVA) pada kedua model. Uji ini menguji hipotesis nol (H0), bahwa variabel yang sebelumnya kita hapus tidak signifikan, terhadap hipotesis alternatif (H1) bahwa variabel-variabel tersebut signifikan.
Jika model baru merupakan peningkatan dari model asli, maka kita gagal menolak H0. Jika bukan demikian, artinya variabel-variabel tersebut signifikan; karenanya, kita menolak H0.
Berikut ekspresi umumnya: anova(original_model, new_model)
# Anova test
anova(cust_value_model, second_model)
Hasil uji ANOVA (Gambar oleh Penulis)
Dari hasil ANOVA, kita mengamati bahwa p-value (8.0893e-316) sangat kecil (kurang dari 0,05), sehingga kita menolak hipotesis nol, yang berarti model kedua bukan peningkatan dari model pertama.
Cara lain untuk melihat variabel penting dalam model adalah melalui uji signifikansi.
Sebuah variabel akan signifikan jika p-value kurang dari 0,05. Hasil ini dapat dihasilkan oleh fungsi summary(). Selain memberikan informasi tersebut tentang model, fungsi ini juga menampilkan adjusted R-square, yang mengevaluasi kinerja model satu sama lain.
# Print the result of the model
summary(cust_value_model)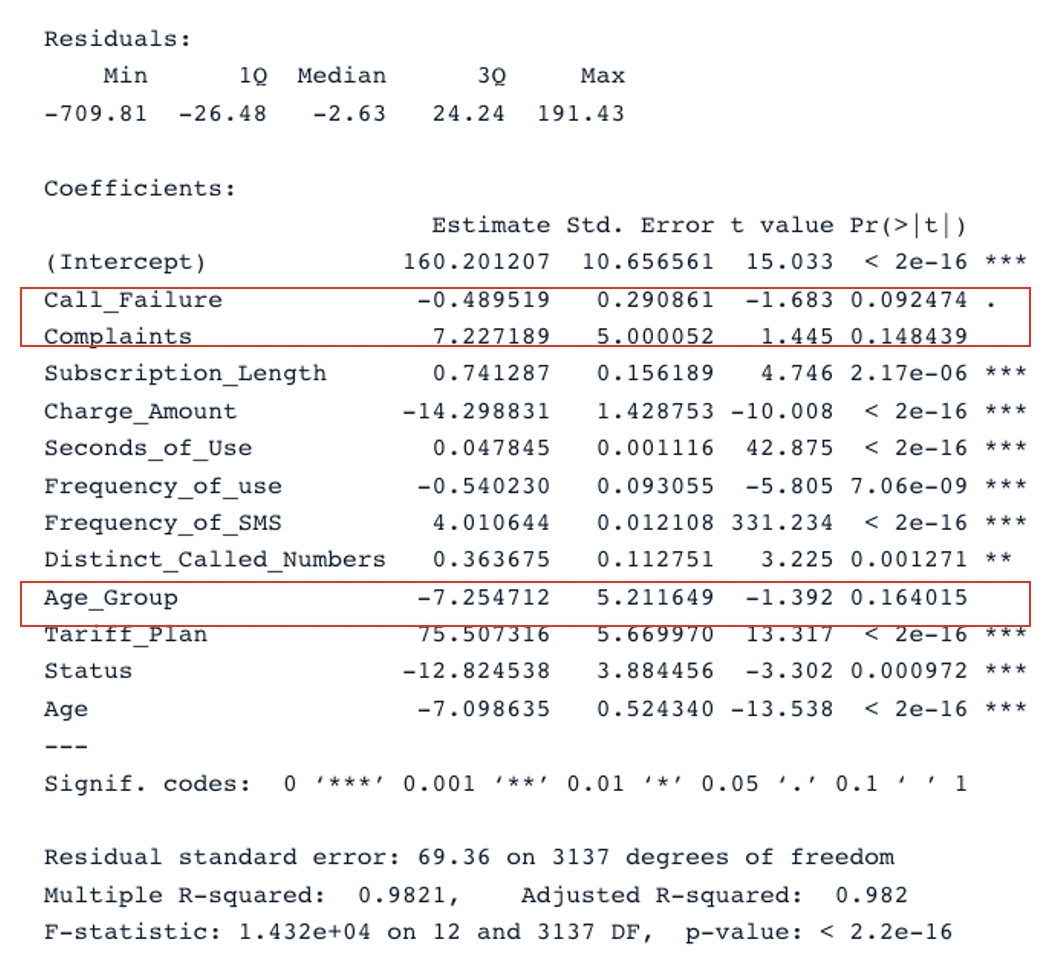
Hasil ringkasan untuk model asli dengan semua prediktor (Gambar oleh Penulis)
Ada dua bagian kunci dalam tabel: Residuals dan Coefficients. Plot Q-Q memberikan informasi yang sama seperti bagian Residuals. Pada bagian Coefficients, Call_Failure, Complaints, dan Age_Group tidak dianggap signifikan oleh model karena p-value-nya lebih tinggi dari 0,05. Mempertahankannya tidak memberikan nilai tambah bagi model.
Menerapkan analisis yang sama pada model kedua, kita memperoleh hasil berikut:
summary(second_model)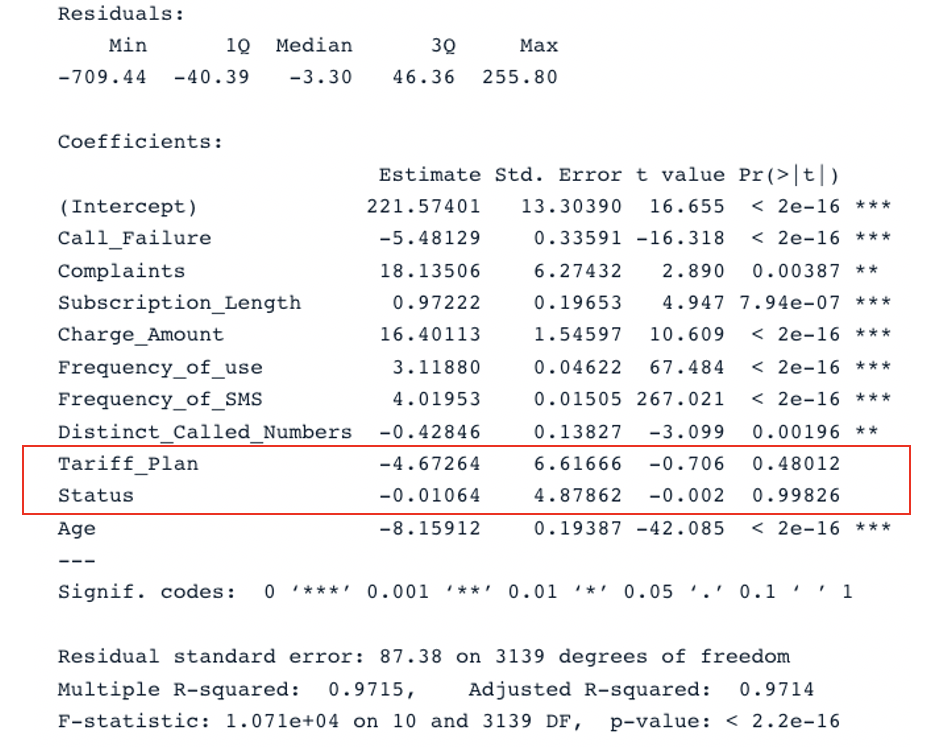
Hasil ringkasan untuk model kedua dengan semua prediktor (Gambar oleh Penulis)
Model asli memiliki adjusted R-square sebesar 0,98, yang lebih tinggi daripada adjusted R-square model kedua (0,97). Ini berarti model asli dengan semua prediktor lebih baik daripada model kedua.
Langkah logis berikut dari analisis ini adalah menghapus variabel yang tidak signifikan dan menyesuaikan model untuk melihat apakah kinerjanya meningkat.
Strategi lain untuk memilih prediktor relevan secara efisien adalah melalui Akaike Information Criteria (AIC).
Ia mulai dengan semua fitur, lalu secara bertahap menghapus prediktor terburuk satu per satu hingga menemukan model terbaik. Semakin kecil skor AIC, semakin baik modelnya. Ini dapat dilakukan menggunakan fungsi stepAIC().
Tutorial ini telah membahas aspek-aspek utama regresi linier berganda dan mengeksplorasi beberapa strategi untuk membangun model yang tangguh.
Semoga tutorial ini memberi Anda keterampilan yang relevan untuk memperoleh insight yang dapat ditindaklanjuti dari data Anda. Anda dapat mencoba meningkatkan model-model ini dengan menerapkan pendekatan berbeda menggunakan kode sumber yang tersedia dari workspace kami.
Kursus
Kursus
Kursus
Kursus
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
