
Cursus
Inference for Linear Regression in R
4 Hr
16K

Regressiemethoden worden in verschillende sectoren gebruikt om te begrijpen welke variabelen invloed hebben op een bepaald onderwerp van interesse.
Zo kunnen economen ze gebruiken om de relatie te analyseren tussen consumentenbestedingen en de groei van het bruto binnenlands product (bbp). Medewerkers in de publieke gezondheidszorg willen misschien de kosten per individu begrijpen op basis van hun historische gegevens. In beide gevallen ligt de focus niet op het voorspellen van individuele scenario’s, maar op het krijgen van een overzicht van de algehele relatie.
In dit artikel beginnen we met een algemene uitleg van regressies. Vervolgens leggen we uit wat het verschil is tussen eenvoudige en meervoudige lineaire regressie, waarna we de technische implementatie induiken en hulpmiddelen aanreiken om de regressieresultaten te begrijpen en te interpreteren.
Laten we eerst begrijpen wat een eenvoudige lineaire regressie is, voordat we ingaan op meervoudige lineaire regressie, wat simpelweg een uitbreiding is van eenvoudige lineaire regressie.
Een eenvoudige lineaire regressie heeft als doel de relatie te modelleren tussen de grootte van één onafhankelijke variabele X en een afhankelijke variabele Y door te proberen precies te schatten hoeveel Y verandert wanneer X met een bepaalde hoeveelheid verandert.
De onafhankelijke variabele X, ook wel de voorspeller genoemd, is de variabele die gebruikt wordt om de voorspelling te maken.
De afhankelijke variabele Y, ook wel de respons genoemd, is degene die we proberen te voorspellen.
Het “lineaire” aspect van lineaire regressie is dat we proberen Y te voorspellen uit X met behulp van de volgende “lineaire” vergelijking.
Y = b0 + b1X
b0 is het snijpunt (intercept) van de regressielijn en komt overeen met de voorspelde waarde wanneer X nul is.
b1 is de helling (slope) van de regressielijn.
Hoe zit het dan met meervoudige lineaire regressie?
Dit is het gebruik van lineaire regressie met meerdere variabelen, en de vergelijking luidt:
Y = b0 + b1X1 + b2X2 + b3X3 + … + bnXn + e
Y en b0 zijn hetzelfde als in het model voor eenvoudige lineaire regressie.
b1X1 staat voor de regressiecoëfficiënt (b1) op de eerste onafhankelijke variabele (X1). Dezelfde analyse geldt voor alle overige regressiecoëfficiënten en variabelen.
e is de modelerror (residuen), die aangeeft hoeveel variatie in het model wordt geïntroduceerd bij het schatten van Y.
Bij meervoudige regressie krijgen we niet altijd een rechte lijn. We kunnen de vorm van de lijn echter beïnvloeden door een geschikter model te fitten.
Dit zijn enkele van de belangrijkste elementen die door meervoudige lineaire regressie worden berekend om voor elke voorspeller de best passende lijn te vinden.
Een belangrijk aspect bij het bouwen van een meervoudig lineair regressiemodel is erop te letten dat de volgende kernaannames gelden.
In de volgende secties behandelen we enkele van deze aannames.
In deze sectie gaan we in op de technische implementatie van een meervoudig lineair regressiemodel met de programmeertaal R.
We gebruiken de dataset over klantverloop uit DataCamp’s Workspace om de klantwaarde te schatten.
Wat bedoelen we met klantwaarde? In feite bepaalt het hoe waardevol een product of dienst is voor een klant, en we kunnen het als volgt berekenen:
Customer Value = Benefit — Cost. Waarbij Benefit en Cost respectievelijk de baten en kosten van een product of dienst zijn.
Deze waarde is hoger als het bedrijf consumenten hogere baten en lagere kosten kan bieden, of idealiter een combinatie van beide.
Deze analyse kan het bedrijf helpen om op basis van de waarde van een bepaalde klant de meest veelbelovende doelgroep of volgende beste actie te identificeren.
Laten we snel een overzicht nemen van de dataset zodat we de relevante preprocessing kunnen toepassen voordat we het model fitten.
churn_data = read_csv('data/customer_churn.csv', show_col_types = FALSE)
# Look at the first 6 observations
head(churn_data)
# Check the dimension
dim(churn_data)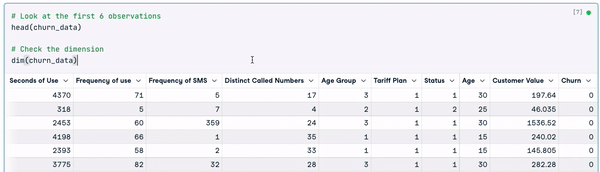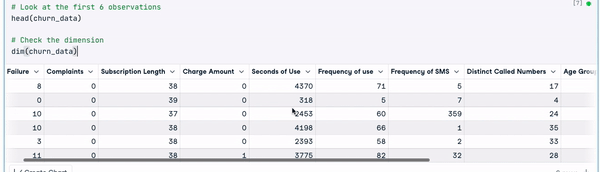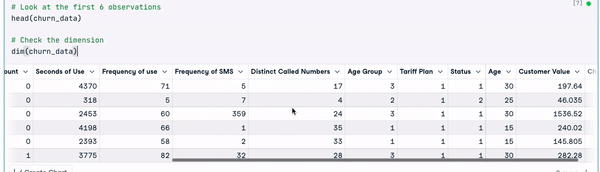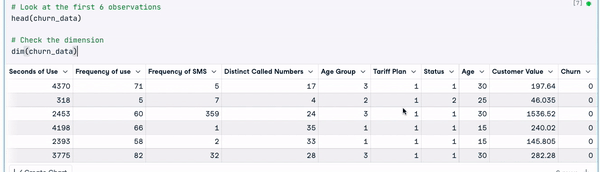
Eerste 6 rijen van de data (animatie door auteur)
Uit de bovenstaande resultaten zien we dat de dataset 3150 observaties en 14 kolommen heeft.
Maar op basis van de probleemstelling hebben we de kolom churn niet nodig, omdat we nu met een regressieprobleem te maken hebben.
Voordat we het model fitten, laten we de kolomnamen voorbewerken door spaties in de kolomnamen te vervangen door underscores. Zo vermijden we dat we telkens aanhalingstekens rond variabelenamen moeten zetten.
# Change the column names
names(churn_data) = gsub(" ", "_", names(churn_data))
head(churn_data)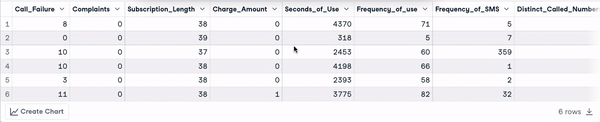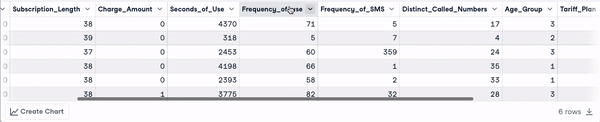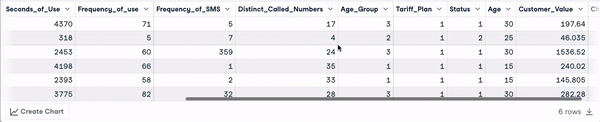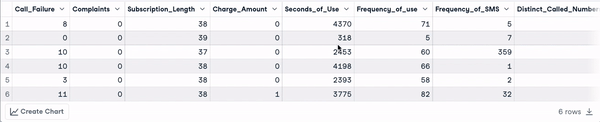
Eerste 6 rijen na transformatie van kolomnamen (animatie door auteur)
Met deze nieuw geformatteerde data kunnen we het inpassen in het meervoudige regressiekader met de functie lm() in R als volgt:
# Fit the multiple linear regression model
cust_value_model = lm(formula = Customer_Value ~ Call_Failure +
Complaints + Subscription_Length + Charge_Amount +
Seconds_of_Use +Frequency_of_use + Frequency_of_SMS +
Distinct_Called_Numbers + Age_Group + Tariff_Plan +
Status + Age,data = churn_data)Laten we begrijpen wat we hier precies gedaan hebben.
De functie lm() heeft het volgende formaat: lm(formula = Y ~Sum(Xi), data = our_data)
Y is de kolom Customer_Value, omdat dat de grootheid is die we proberen te schatten.
Sum(Xi) stelt de som uit de vergelijking voor meervoudige lineaire regressie voor.
our_data is de churn_data.
Je kunt meer leren in onze cursus Intermediate Regression in R.
Een alternatief voor R is Python: Intermediate Regression with statsmodels in Python. Beide helpen je lineaire en logistische regressie met meerdere verklarende variabelen te leren.
Nu we het model hebben gebouwd, is de volgende stap de aannames controleren en de resultaten interpreteren. Voor de eenvoud behandelen we niet alle aspecten.
Dit kun je in R weergeven met de functie hist().
# Get the model residuals
model_residuals = cust_value_model$residuals
# Plot the result
hist(model_residuals)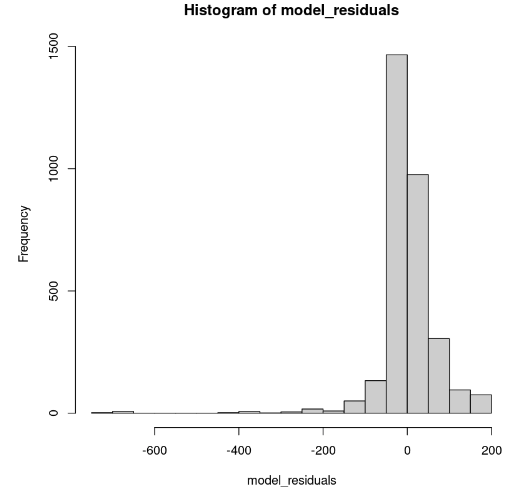
Verdeling van modelresiduen (afbeelding door auteur)
Het histogram is links-scheef; we kunnen de normaliteit dus niet met voldoende vertrouwen aannemen. In plaats van het histogram bekijken we de residuen in een normale Q-Q-plot. Als er normaliteit is, zouden de waarden een rechte lijn volgen.
# Plot the residuals
qqnorm(model_residuals)
# Plot the Q-Q line
qqline(model_residuals)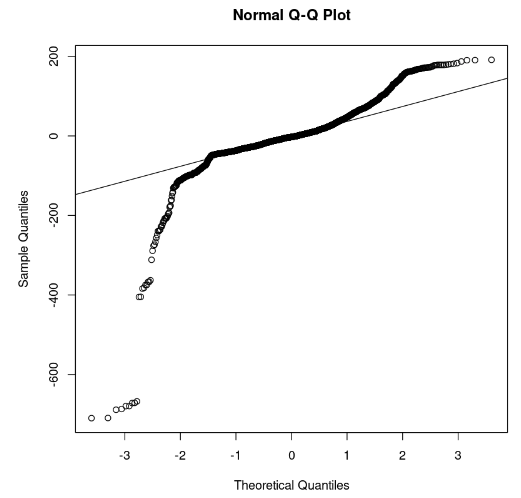
Q-Q-plot en residuen (afbeelding door auteur)
Uit de plot zien we dat delen van de residuen op een rechte lijn liggen. We kunnen dan aannemen dat de residuen van het model geen normale verdeling volgen.
Dit doen we met de volgende R-code. We moeten vooraf wel de kolom Customer_Value verwijderen.
# Install and load the ggcorrplot package
install.packages("ggcorrplot")
library(ggcorrplot)
# Remove the Customer Value column
reduced_data <- subset(churn_data, select = -Customer_Value)
# Compute correlation at 2 decimal places
corr_matrix = round(cor(reduced_data), 2)
# Compute and show the result
ggcorrplot(corr_matrix, hc.order = TRUE, type = "lower",
lab = TRUE)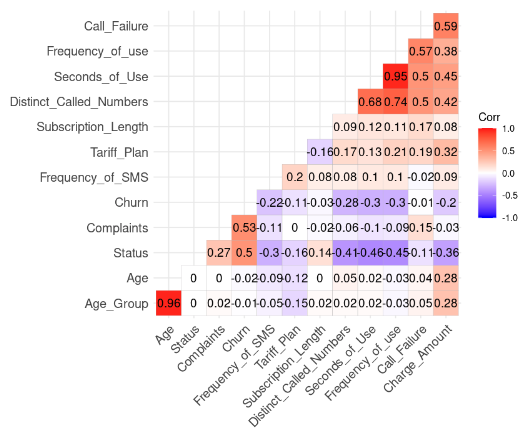
Correlatieresultaat uit de data (afbeelding door auteur)
We zien twee sterke correlaties omdat hun waarde hoger is dan 0,8.
Age en Age_Group: 0,96
Frequency_of_use en Seconds_of_Use: 0,95
Dit resultaat is logisch, omdat Age_Group is afgeleid van Age. Ook is het totale aantal seconden (Seconds_of_Use) afgeleid van het totale aantal oproepen (Frequency_of_Use).
In dit geval kunnen we Age_Group en Seconds_of_Use uit de dataset verwijderen.
Laten we proberen een tweede model te bouwen zonder deze twee variabelen.
second_model = lm(formula = Customer_Value ~ Call_Failure + Complaints +
Subscription_Length + Charge_Amount +
Frequency_of_use + Frequency_of_SMS +
Distinct_Called_Numbers + Tariff_Plan +
Status + Age,
data = churn_data)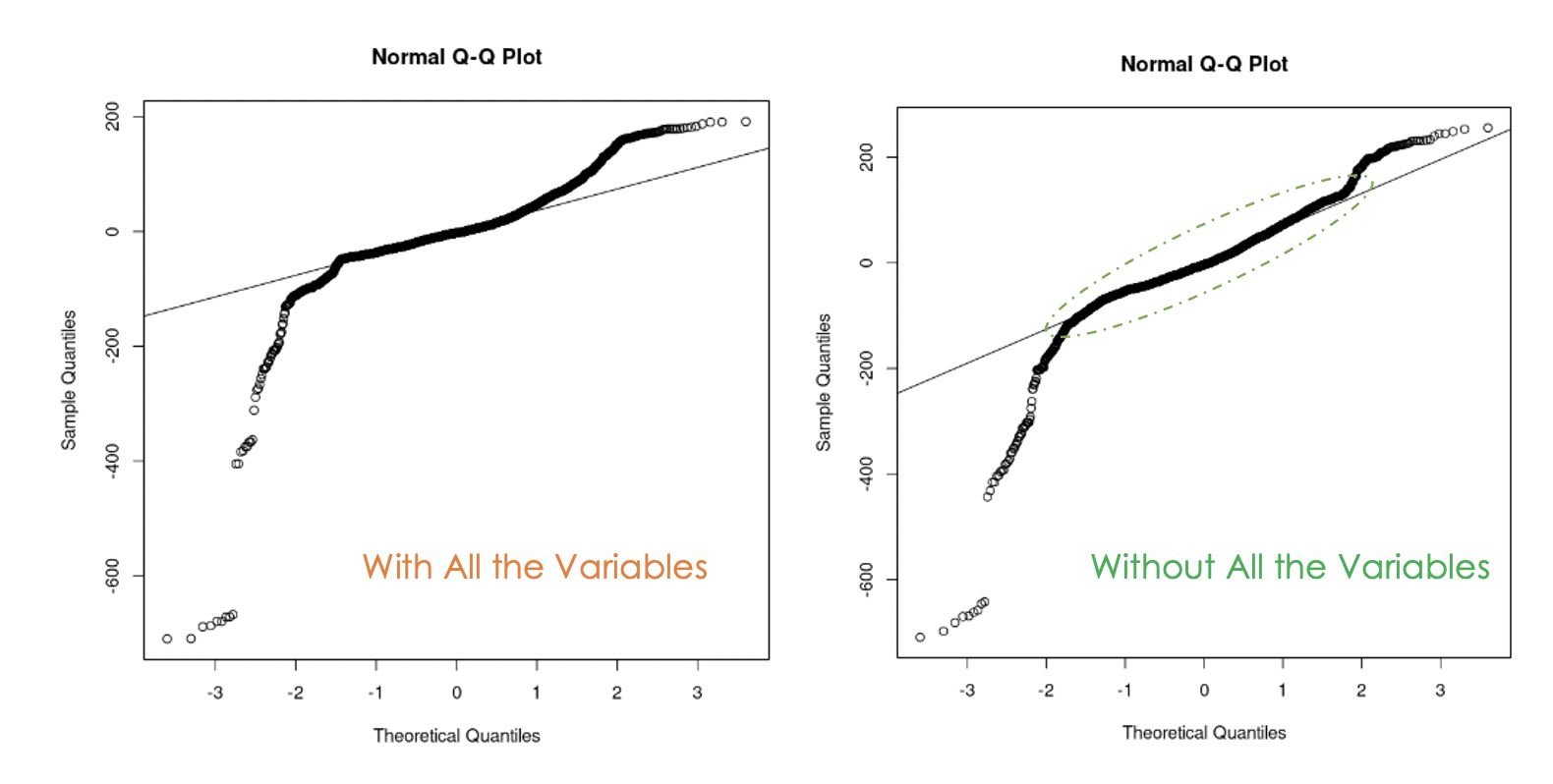
Q-Q-plots van het eerste model (links) en het tweede model (rechts)
We zien dat het verwijderen van multicollineariteit in de data heeft geholpen, want in het tweede model liggen meer residuwaarden op de rechte lijn dan in het eerste model.
Dan blijft de vraag: welk van de twee meervoudige lineaire regressiemodellen is beter?
Eén manier om die vraag te beantwoorden is een variantieanalyse (ANOVA) van de twee modellen uitvoeren. Hierbij testen we de nulhypothese (H0), waarin de eerder verwijderde variabelen geen betekenis hebben, tegen de alternatieve hypothese (H1) dat die variabelen wél significant zijn.
Als het nieuwe model een verbetering is van het oorspronkelijke model, dan verwerpen we H0 niet. Is dat niet het geval, dan betekent dit dat die variabelen significant waren; we verwerpen H0 dan.
De algemene uitdrukking is: anova(original_model, new_model)
# Anova test
anova(cust_value_model, second_model)
ANOVA-testresultaat (afbeelding door auteur)
Uit het ANOVA-resultaat zien we dat de p-waarde (8.0893e-316) zeer klein is (kleiner dan 0,05), dus we verwerpen de nulhypothese. Dit betekent dat het tweede model geen verbetering is van het eerste.
Een andere manier om naar de belangrijke variabelen in het model te kijken is via een significantietest.
Een variabele is significant als de p-waarde kleiner is dan 0,05. Dit resultaat krijg je met de functie summary(). Naast die informatie geeft het ook de aangepaste R-kwadraat, waarmee je de prestaties van modellen onderling kunt vergelijken.
# Print the result of the model
summary(cust_value_model)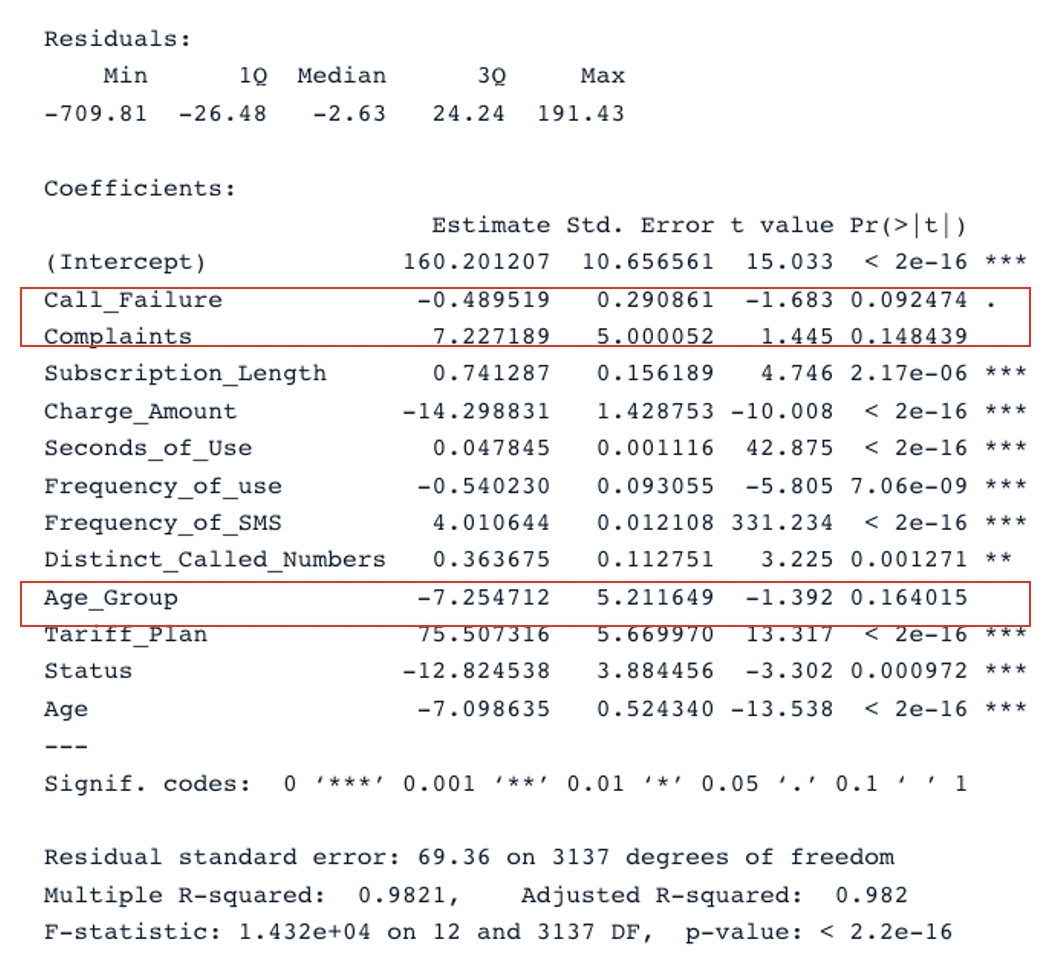
Samenvatting van het oorspronkelijke model met alle voorspellers (afbeelding door auteur)
De tabel heeft twee sleutelsecties: Residuals en Coefficients. De Q-Q-plots geven dezelfde informatie als de sectie Residuals. In de sectie Coefficients worden Call_Failure, Complaints en Age_Group door het model niet als significant beschouwd, omdat hun p-waarde hoger is dan 0,05. Ze toevoegen levert geen extra waarde op voor het model.
Toegepast op het tweede model krijgen we dit resultaat:
summary(second_model)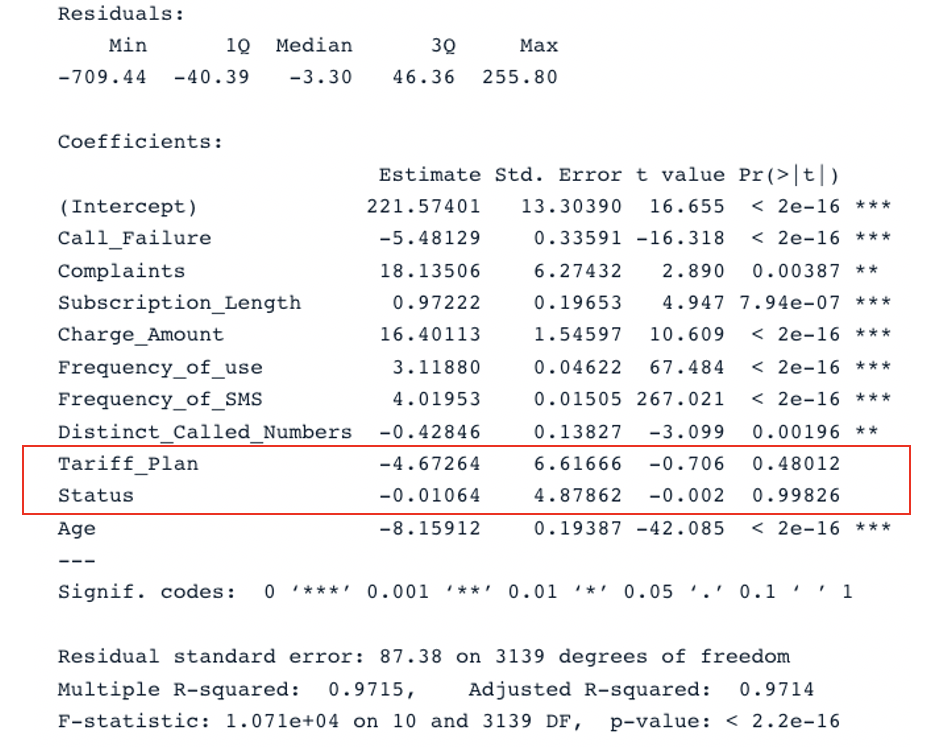
Samenvatting van het tweede model met alle voorspellers (afbeelding door auteur)
Het oorspronkelijke model heeft een aangepaste R-kwadraat van 0,98, die hoger is dan de aangepaste R-kwadraat van het tweede model (0,97). Dit betekent dat het oorspronkelijke model met alle voorspellers beter is dan het tweede model.
De logische volgende stap in deze analyse is de niet-significante variabelen verwijderen en het model opnieuw fitten om te zien of de prestaties verbeteren.
Een andere strategie om efficiënt relevante voorspellers te kiezen, is via het Akaike Information Criterion (AIC).
Je begint met alle features en laat vervolgens stapsgewijs de slechtste voorspellers één voor één vallen totdat je het beste model vindt. Hoe kleiner de AIC-score, hoe beter het model. Dit kan met de functie stepAIC().
Deze tutorial heeft de belangrijkste aspecten van meervoudige lineaire regressie behandeld en enkele strategieën verkend om robuuste modellen te bouwen.
We hopen dat deze tutorial je de juiste vaardigheden geeft om actiegerichte inzichten uit je data te halen. Je kunt proberen deze modellen te verbeteren door verschillende benaderingen toe te passen met de broncode die beschikbaar is in onze Workspace.
Cursussen
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
