
Courses
Suy luận cho hồi quy tuyến tính trong R
4 giờ
16K

Các phương pháp hồi quy được sử dụng trong nhiều ngành để hiểu những biến nào ảnh hưởng đến một chủ đề quan tâm nhất định.
Chẳng hạn, các nhà kinh tế có thể dùng chúng để phân tích mối quan hệ giữa chi tiêu tiêu dùng và tăng trưởng Tổng sản phẩm quốc nội (GDP). Các cán bộ y tế công cộng có thể muốn hiểu chi phí của từng cá nhân dựa trên thông tin lịch sử của họ. Trong cả hai trường hợp, trọng tâm không phải dự đoán các kịch bản đơn lẻ mà là có được cái nhìn tổng quan về mối quan hệ tổng thể.
Trong bài viết này, trước tiên chúng tôi sẽ cung cấp cách hiểu chung về hồi quy. Sau đó, chúng tôi sẽ giải thích điều gì khiến hồi quy tuyến tính đơn và hồi quy tuyến tính bội khác nhau trước khi đi vào triển khai kỹ thuật và cung cấp các công cụ giúp bạn hiểu và diễn giải kết quả hồi quy.
Hãy hiểu hồi quy tuyến tính đơn là gì trước khi đi vào hồi quy tuyến tính bội, vốn chỉ là phần mở rộng của hồi quy tuyến tính đơn.
Hồi quy tuyến tính đơn nhằm mô hình hóa mối quan hệ giữa độ lớn của một biến độc lập X và biến phụ thuộc Y bằng cách ước lượng chính xác Y sẽ thay đổi bao nhiêu khi X thay đổi một lượng nhất định.
Biến độc lập X, còn gọi là biến dự báo (predictor), là biến được dùng để đưa ra dự đoán.
Biến phụ thuộc Y, còn gọi là biến phản hồi (response), là biến mà chúng ta đang cố gắng dự đoán.
Khía cạnh “tuyến tính” của hồi quy tuyến tính là chúng ta cố gắng dự đoán Y từ X bằng phương trình “tuyến tính” sau.
Y = b0 + b1X
b0 là hệ số chặn của đường hồi quy, tương ứng với giá trị dự đoán khi X bằng 0.
b1 là độ dốc của đường hồi quy.
Vậy còn hồi quy tuyến tính bội thì sao?
Đó là việc sử dụng hồi quy tuyến tính với nhiều biến, và phương trình là:
Y = b0 + b1X1 + b2X2 + b3X3 + … + bnXn + e
Y và b0 giống như trong mô hình hồi quy tuyến tính đơn.
b1X1 biểu thị hệ số hồi quy (b1) của biến độc lập thứ nhất (X1). Phân tích tương tự áp dụng cho tất cả các hệ số hồi quy và biến còn lại.
e là sai số mô hình (phần dư), biểu thị lượng biến thiên được đưa vào mô hình khi ước lượng Y.
Không phải lúc nào chúng ta cũng nhận được một đường thẳng trong trường hợp hồi quy bội. Tuy nhiên, chúng ta có thể kiểm soát hình dạng của đường bằng cách khớp một mô hình phù hợp hơn.
Dưới đây là một số yếu tố chính được tính toán bởi hồi quy tuyến tính bội để tìm đường phù hợp nhất cho mỗi biến dự báo.
Một khía cạnh quan trọng khi xây dựng mô hình hồi quy tuyến tính bội là đảm bảo đáp ứng các giả định then chốt sau.
Trong các phần tiếp theo, chúng ta sẽ đề cập đến một số giả định này.
Trong phần này, chúng ta sẽ đi vào triển khai kỹ thuật một mô hình hồi quy tuyến tính bội bằng ngôn ngữ lập trình R.
Chúng ta sẽ sử dụng bộ dữ liệu rời bỏ khách hàng từ Workspace của DataCamp để ước lượng giá trị khách hàng.
“Giá trị khách hàng” là gì? Về cơ bản, nó xác định một sản phẩm hoặc dịch vụ có giá trị như thế nào đối với khách hàng, và ta có thể tính như sau:
Giá trị khách hàng = Lợi ích — Chi phí. Trong đó Lợi ích và Chi phí lần lượt là lợi ích và chi phí của một sản phẩm hoặc dịch vụ.
Giá trị này cao hơn nếu công ty có thể cung cấp cho người tiêu dùng lợi ích cao hơn và chi phí thấp hơn, hoặc lý tưởng là kết hợp cả hai.
Phân tích này có thể giúp doanh nghiệp xác định cơ hội nhắm mục tiêu hứa hẹn nhất hoặc hành động tiếp theo tối ưu dựa trên giá trị của một khách hàng nhất định.
Hãy có cái nhìn tổng quan nhanh về bộ dữ liệu để chúng ta có thể áp dụng tiền xử lý phù hợp trước khi khớp mô hình.
churn_data = read_csv('data/customer_churn.csv', show_col_types = FALSE)
# Look at the first 6 observations
head(churn_data)
# Check the dimension
dim(churn_data)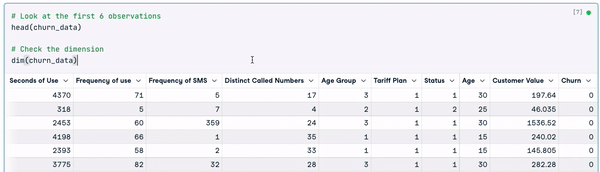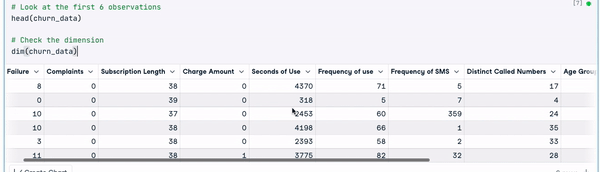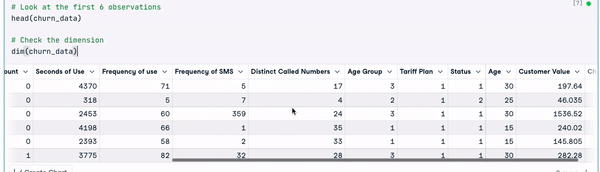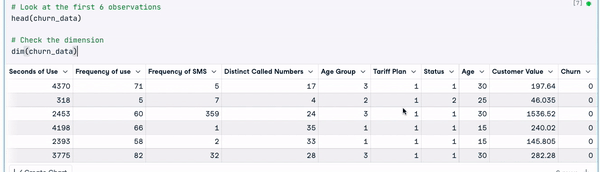
6 dòng đầu của dữ liệu (Hoạt ảnh của tác giả)
Từ kết quả trước đó, chúng ta có thể quan sát rằng bộ dữ liệu có 3150 quan sát và 14 cột.
Tuy nhiên, dựa trên phát biểu bài toán, chúng ta sẽ không cần cột churn vì hiện tại chúng ta đang xử lý một bài toán hồi quy.
Trước khi khớp mô hình, hãy tiền xử lý tên cột bằng cách thay thế khoảng trắng trong tên cột bằng dấu gạch dưới để tránh phải viết dấu ngoặc kép quanh tên biến mỗi lần.
# Change the column names
names(churn_data) = gsub(" ", "_", names(churn_data))
head(churn_data)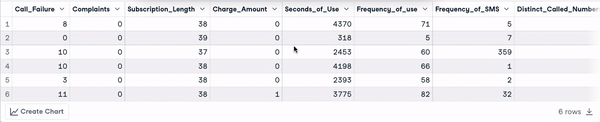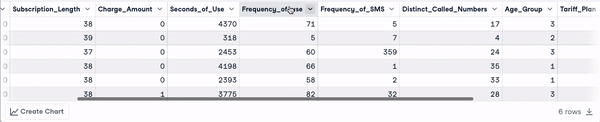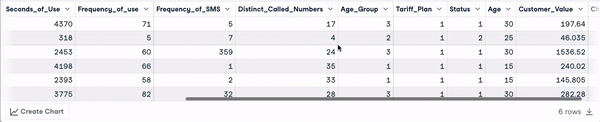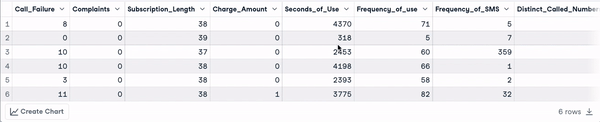
6 dòng đầu sau khi chuyển đổi tên cột (hoạt ảnh của tác giả)
Với dữ liệu đã được định dạng mới này, chúng ta có thể đưa vào khung hồi quy bội bằng hàm lm() trong R như sau:
# Fit the multiple linear regression model
cust_value_model = lm(formula = Customer_Value ~ Call_Failure +
Complaints + Subscription_Length + Charge_Amount +
Seconds_of_Use +Frequency_of_use + Frequency_of_SMS +
Distinct_Called_Numbers + Age_Group + Tariff_Plan +
Status + Age,data = churn_data)Hãy hiểu những gì chúng ta vừa làm.
Hàm lm() có dạng: lm(formula = Y ~Sum(Xi), data = our_data)
Y là cột Customer_Value vì đó là biến chúng ta muốn ước lượng.
Tổng(Xi) biểu diễn biểu thức tổng trong phương trình hồi quy tuyến tính bội.
our_data là churn_data.
Bạn có thể tìm hiểu thêm từ khóa học Hồi quy trung cấp trong R của chúng tôi.
Một lựa chọn thay thế R là Python: Hồi quy trung cấp với statsmodels trong Python. Cả hai đều giúp bạn học hồi quy tuyến tính và logistic với nhiều biến giải thích.
Sau khi xây dựng mô hình, bước tiếp theo là kiểm tra các giả định và diễn giải kết quả. Để đơn giản, chúng tôi sẽ không đề cập đến mọi khía cạnh.
Có thể hiển thị trong R bằng hàm hist().
# Get the model residuals
model_residuals = cust_value_model$residuals
# Plot the result
hist(model_residuals)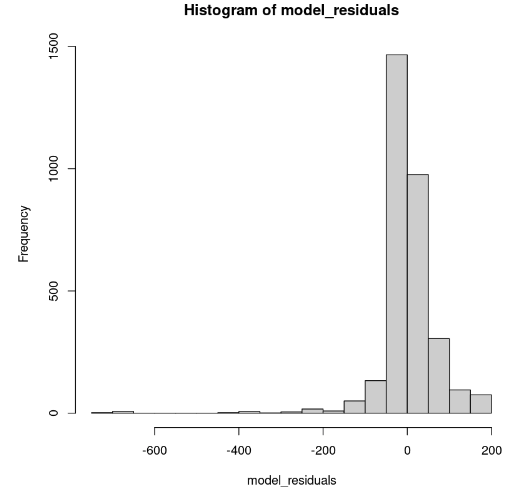
Phân phối phần dư của mô hình (Hình ảnh của tác giả)
Biểu đồ tần suất có vẻ lệch trái; do đó, chúng ta không thể kết luận tính chuẩn với đủ độ tin cậy. Thay vì biểu đồ tần suất, hãy xem phần dư trên đồ thị Q-Q chuẩn. Nếu có tính chuẩn, các giá trị sẽ theo một đường thẳng.
# Plot the residuals
qqnorm(model_residuals)
# Plot the Q-Q line
qqline(model_residuals)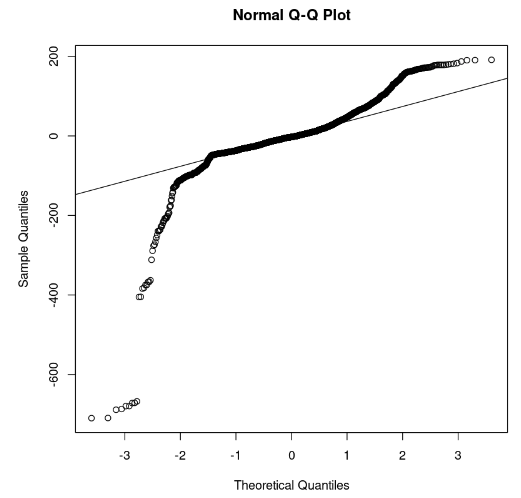
Biểu đồ Q-Q và phần dư (Hình ảnh của tác giả)
Từ đồ thị, ta có thể quan sát rằng chỉ một vài phần của phần dư nằm trên đường thẳng. Khi đó có thể giả định rằng phần dư của mô hình không tuân theo phân phối chuẩn.
Thực hiện thông qua đoạn mã R sau. Nhưng trước đó chúng ta phải loại bỏ cột Customer_Value.
# Install and load the ggcorrplot package
install.packages("ggcorrplot")
library(ggcorrplot)
# Remove the Customer Value column
reduced_data <- subset(churn_data, select = -Customer_Value)
# Compute correlation at 2 decimal places
corr_matrix = round(cor(reduced_data), 2)
# Compute and show the result
ggcorrplot(corr_matrix, hc.order = TRUE, type = "lower",
lab = TRUE)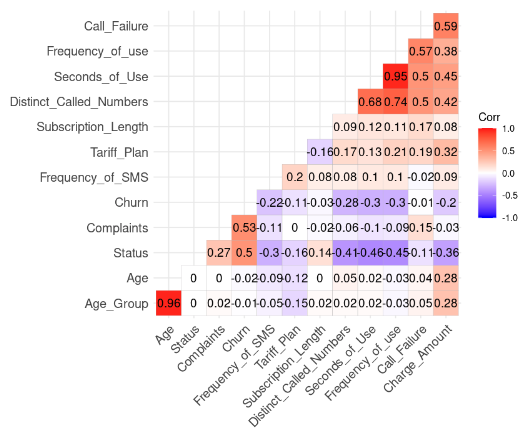
Kết quả tương quan từ dữ liệu (Hình ảnh của tác giả)
Chúng ta có thể nhận thấy hai mối tương quan mạnh vì giá trị của chúng lớn hơn 0.8.
Age và Age_Group: 0.96
Frequency_of_use và Seconds_of_Use: 0.95
Kết quả này hợp lý vì Age_Group được tính từ Age. Ngoài ra, tổng số giây (Seconds_of_Use) được suy ra từ tổng số cuộc gọi (Frequency_of_Use).
Trong trường hợp này, chúng ta có thể loại Age_Group và Seconds_of_Use khỏi bộ dữ liệu.
Hãy thử xây dựng mô hình thứ hai không có hai biến đó.
second_model = lm(formula = Customer_Value ~ Call_Failure + Complaints +
Subscription_Length + Charge_Amount +
Frequency_of_use + Frequency_of_SMS +
Distinct_Called_Numbers + Tariff_Plan +
Status + Age,
data = churn_data)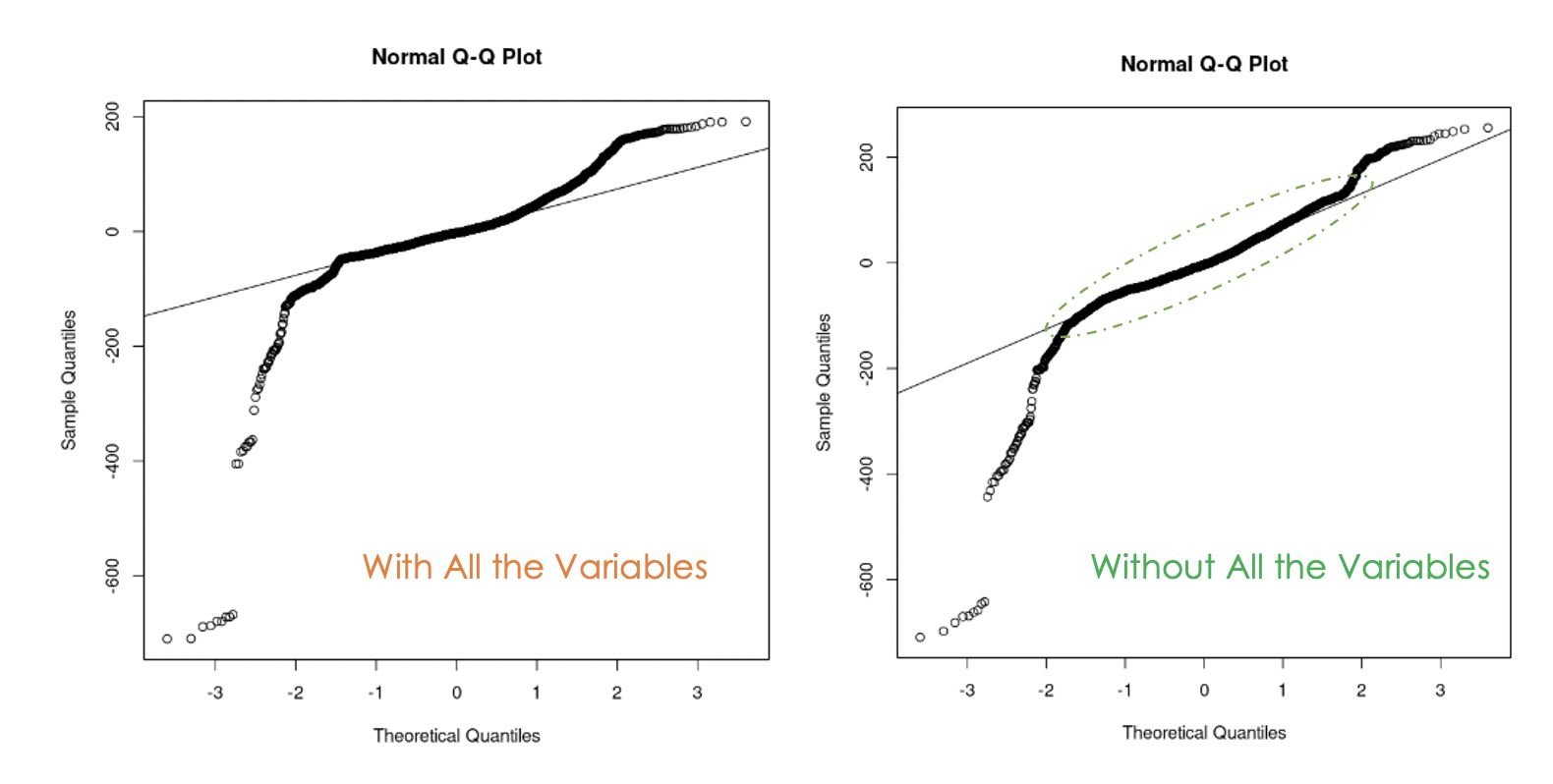
Biểu đồ Q-Q của mô hình thứ nhất (trái) và mô hình thứ hai (phải)
Chúng ta có thể nhận thấy rằng loại bỏ đa cộng tuyến trong dữ liệu là hữu ích vì với mô hình thứ hai, nhiều giá trị phần dư nằm trên đường thẳng hơn so với mô hình thứ nhất.
Giờ đây, còn lại một câu hỏi: Trong hai mô hình hồi quy tuyến tính bội, mô hình nào tốt hơn?
Một cách để trả lời là chạy kiểm định phân tích phương sai (ANOVA) cho hai mô hình. Kiểm định này xem xét giả thuyết không (H0), trong đó các biến mà ta đã loại bỏ trước đó không có ý nghĩa, so với giả thuyết đối (H1) rằng các biến đó có ý nghĩa.
Nếu mô hình mới là cải tiến so với mô hình gốc, thì chúng ta không bác bỏ H0. Nếu không phải vậy, nghĩa là các biến đó có ý nghĩa; do đó, chúng ta bác bỏ H0.
Biểu thức tổng quát: anova(original_model, new_model)
# Anova test
anova(cust_value_model, second_model)
Kết quả kiểm định ANOVA (Hình ảnh của tác giả)
Từ kết quả ANOVA, chúng ta quan sát thấy p-value (8.0893e-316) rất nhỏ (nhỏ hơn 0.05), nên chúng ta bác bỏ giả thuyết không, nghĩa là mô hình thứ hai không phải sự cải thiện so với mô hình thứ nhất.
Một cách khác để xem các biến quan trọng trong mô hình là thông qua kiểm định ý nghĩa.
Một biến sẽ có ý nghĩa nếu p-value của nó nhỏ hơn 0.05. Kết quả này có thể tạo ra bằng hàm summary(). Ngoài việc cung cấp thông tin đó về mô hình, nó còn trả về R-bình phương hiệu chỉnh, dùng để đánh giá hiệu năng giữa các mô hình.
# Print the result of the model
summary(cust_value_model)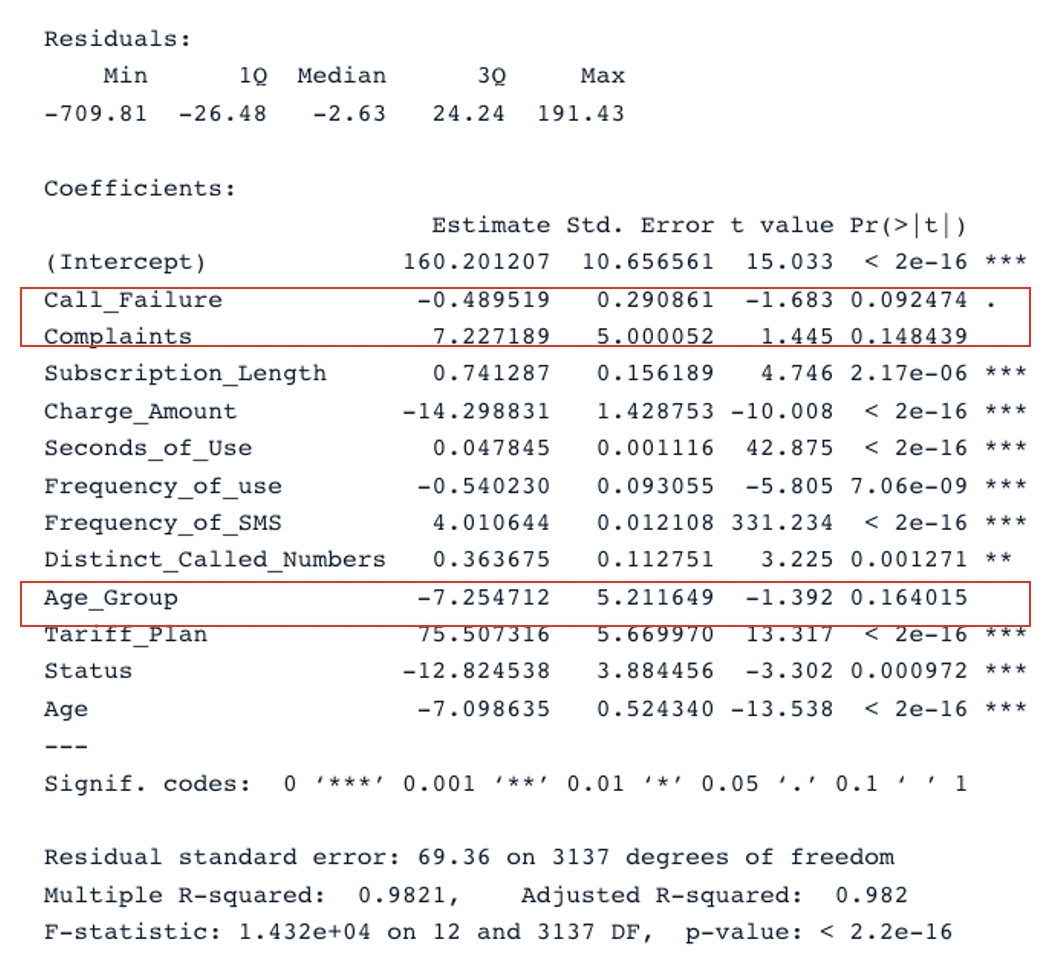
Kết quả tóm tắt cho mô hình gốc với tất cả biến dự báo (Hình ảnh của tác giả)
Chúng ta có hai phần chính trong bảng: Residuals và Coefficients. Các biểu đồ Q-Q cung cấp thông tin tương tự phần Residuals. Ở phần Coefficients, Call_Failure, Complaints và Age_Group không được mô hình xem là có ý nghĩa vì p-value của chúng lớn hơn 0.05. Giữ chúng lại không mang thêm giá trị cho mô hình.
Áp dụng phân tích tương tự cho mô hình thứ hai, chúng ta được kết quả sau:
summary(second_model)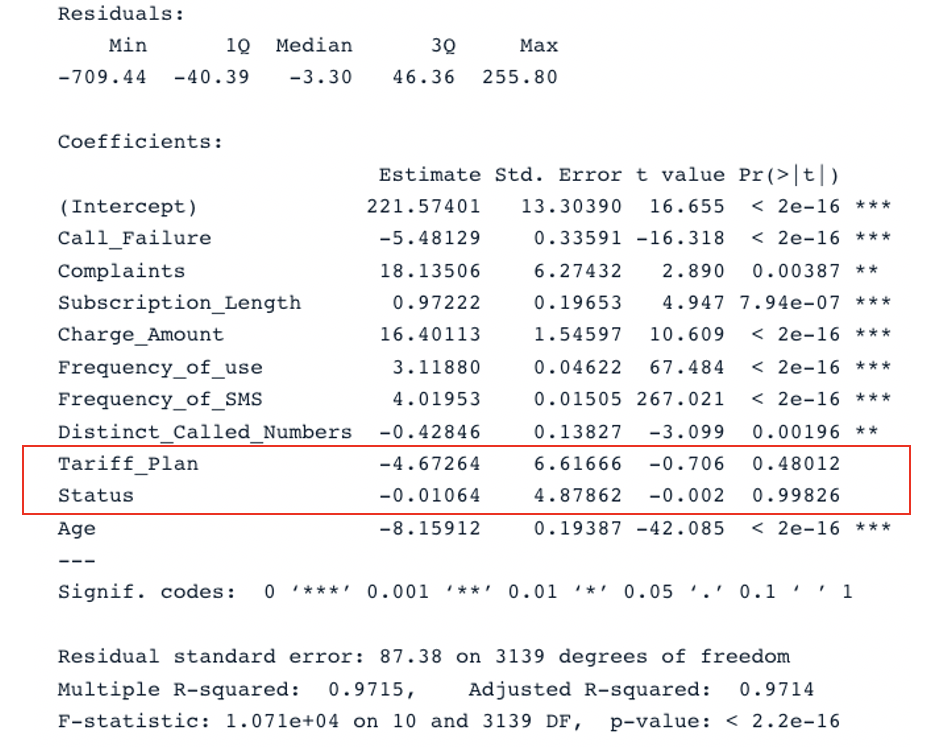
Kết quả tóm tắt cho mô hình thứ hai với tất cả biến dự báo (Hình ảnh của tác giả)
Mô hình gốc có R-bình phương hiệu chỉnh là 0.98, cao hơn R-bình phương hiệu chỉnh của mô hình thứ hai (0.97). Điều này có nghĩa mô hình gốc với tất cả biến dự báo tốt hơn mô hình thứ hai.
Bước hợp lý tiếp theo của phân tích này là loại bỏ các biến không có ý nghĩa và khớp lại mô hình để xem hiệu năng có được cải thiện không.
Một chiến lược khác để lựa chọn hiệu quả các biến dự báo liên quan là thông qua Tiêu chí thông tin Akaike (AIC).
Phương pháp này bắt đầu với tất cả đặc trưng, sau đó dần dần loại biến dự báo tệ nhất từng cái một cho đến khi tìm được mô hình tốt nhất. Điểm AIC càng nhỏ, mô hình càng tốt. Có thể thực hiện bằng hàm stepAIC().
Hướng dẫn này đã bao quát các khía cạnh chính của hồi quy tuyến tính bội và khám phá một số chiến lược để xây dựng các mô hình vững chắc.
Chúng tôi hy vọng hướng dẫn này cung cấp cho bạn các kỹ năng phù hợp để rút ra insight có thể hành động từ dữ liệu của mình. Bạn có thể thử cải thiện các mô hình này bằng cách áp dụng những cách tiếp cận khác nhau sử dụng mã nguồn có sẵn từ workspace của chúng tôi.
Khóa học
Courses
Courses
Courses