
Kurs
R'de Doğrusal Regresyon için Çıkarım
4 sa
16K

Regresyon yöntemleri, farklı sektörlerde belirli bir ilgi konusunu hangi değişkenlerin etkilediğini anlamak için kullanılır.
Örneğin ekonomistler, tüketici harcamaları ile Gayri Safi Yurt İçi Hasıla (GSYİH) büyümesi arasındaki ilişkiyi analiz etmek için kullanabilir. Halk sağlığı yetkilileri, bireylerin geçmiş bilgilerine göre maliyetlerini anlamak isteyebilir. Her iki durumda da odak, tek tek senaryoları tahmin etmekten ziyade genel ilişkiye dair bir genel bakış elde etmektir.
Bu makalede, önce regresyonlara dair genel bir anlayış sunacağız. Ardından, basit ve çoklu doğrusal regresyonları birbirinden ayıran noktaları açıklayacak, teknik uygulamalara dalmadan önce regresyon sonuçlarını anlamanıza ve yorumlamanıza yardımcı olacak araçlar sağlayacağız.
Basit doğrusal regresyonun ne olduğunu anlamadan çoklu doğrusal regresyona geçmeyelim; çünkü çoklu doğrusal regresyon, basit doğrusal regresyonun bir uzantısıdır.
Basit doğrusal regresyon, tek bir bağımsız değişken X ile bağımlı değişken Y arasındaki ilişkiyi modellemeyi amaçlar; belirli bir miktarda X değiştiğinde Y’nin tam olarak ne kadar değişeceğini tahmin etmeye çalışır.
Bağımsız değişken X, tahmin yaparken kullanılan ve kestirici (predictor) olarak da adlandırılan değişkendir.
Bağımlı değişken Y, yanıt (response) olarak da bilinir ve tahmin etmeye çalıştığımız değişkendir.
Doğrusal regresyonun “doğrusal” yönü, aşağıdaki “doğrusal” denklemle Y’yi X’ten tahmin etmeye çalışmamızdır.
Y = b0 + b1X
b0, regresyon doğrusunun kesişim noktasıdır; X sıfır olduğunda öngörülen değere karşılık gelir.
b1, regresyon doğrusunun eğimidir.
Peki, çoklu doğrusal regresyon nedir?
Bu, birden fazla değişkenle doğrusal regresyonun kullanılmasıdır ve denklem şöyledir:
Y = b0 + b1X1 + b2X2 + b3X3 + … + bnXn + e
Y ve b0, basit doğrusal regresyon modelindekiyle aynıdır.
b1X1, ilk bağımsız değişken (X1) üzerindeki regresyon katsayısını (b1) temsil eder. Aynı analiz kalan tüm regresyon katsayıları ve değişkenler için de geçerlidir.
e, model hatasıdır (artıklar) ve Y tahmin edilirken modele ne kadar değişim girdiğini tanımlar.
Çoklu regresyon durumunda her zaman düz bir doğru elde etmeyebiliriz. Ancak daha uygun bir model uydurarak doğrunun şeklini kontrol edebiliriz.
Her bir kestirici için en iyi uyum doğrusunu bulmak üzere çoklu doğrusal regresyon tarafından hesaplanan bazı temel öğeler şunlardır:
Bir çoklu doğrusal regresyon modeli kurarken önemli bir nokta, aşağıdaki temel varsayımların sağlandığından emin olmaktır.
Bir sonraki bölümlerde bu varsayımlardan bazılarını ele alacağız.
Bu bölümde, R programlama dilini kullanarak çoklu doğrusal regresyon modelinin teknik uygulamasına giriş yapacağız.
DataCamp Workspace'teki müşteri ayrılma veri setini kullanarak müşteri değerini tahmin edeceğiz.
Müşteri değeri derken neyi kastediyoruz? Temelde, bir ürün veya hizmetin müşteri için ne kadar değerli olduğunu belirler ve şu şekilde hesaplanabilir:
Customer Value = Benefit — Cost. Burada Benefit ve Cost sırasıyla bir ürün veya hizmetin faydası ve maliyetidir.
Şirket, tüketicilere daha yüksek fayda ve daha düşük maliyet sunabildiğinde ya da ideal olarak her ikisinin birleşimini sağlayabildiğinde bu değer daha yüksektir.
Bu analiz, işletmenin belirli bir müşterinin değerine göre en umut verici hedefleme fırsatını veya bir sonraki en iyi aksiyonu belirlemesine yardımcı olabilir.
Modeli oturtmadan önce, uygun ön işleme adımlarını uygulayabilmek için veri setine hızlıca genel bir bakış atalım.
churn_data = read_csv('data/customer_churn.csv', show_col_types = FALSE)
# Look at the first 6 observations
head(churn_data)
# Check the dimension
dim(churn_data)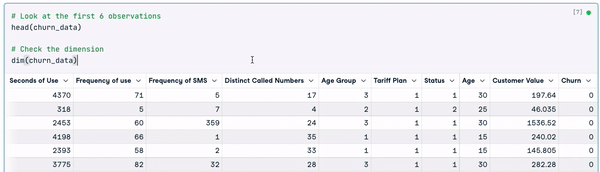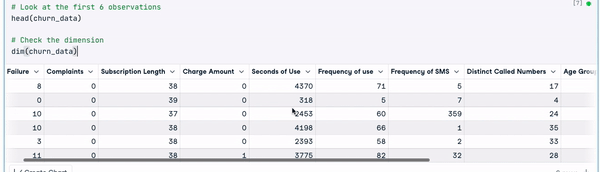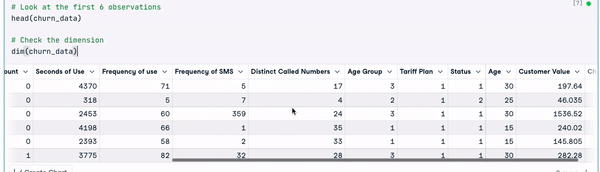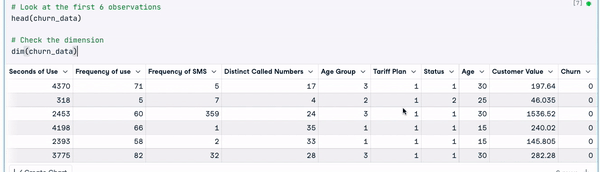
Verinin ilk 6 satırı (Animasyon: Yazar)
Önceki sonuçlardan, veri setinde 3150 gözlem ve 14 sütun bulunduğunu görebiliyoruz.
Ancak problem tanımına göre, şu anda bir regresyon problemiyle uğraştığımız için churn sütununa ihtiyaç duymayacağız.
Modeli kurmadan önce, sütun adlarını her seferinde değişken adlarının etrafına çift tırnak yazmaktan kaçınmak için sütun adlarındaki boşlukları alt çizgiyle değiştirerek ön işleme yapalım.
# Change the column names
names(churn_data) = gsub(" ", "_", names(churn_data))
head(churn_data)
Sütun adları dönüştürüldükten sonra ilk 6 satır (animasyon: yazar)
Bu yeni biçimlendirilmiş verilerle, R’de lm() fonksiyonunu kullanarak çoklu regresyon çerçevesine şu şekilde oturtabiliriz:
# Fit the multiple linear regression model
cust_value_model = lm(formula = Customer_Value ~ Call_Failure +
Complaints + Subscription_Length + Charge_Amount +
Seconds_of_Use +Frequency_of_use + Frequency_of_SMS +
Distinct_Called_Numbers + Age_Group + Tariff_Plan +
Status + Age,data = churn_data)Burada ne yaptığımızı anlayalım.
lm() fonksiyonu şu formattadır: lm(formula = Y ~Sum(Xi), data = our_data)
Y, Customer_Value sütunudur; çünkü tahmin etmeye çalıştığımız değişken odur.
Sum(Xi), çoklu doğrusal regresyon denklemindeki toplam ifadesini temsil eder.
our_data, churn_data’dır.
Daha fazlasını R’de Orta Düzey Regresyon kursumuzdan öğrenebilirsiniz.
R yerine Python da kullanabilirsiniz: Python'da statsmodels ile Orta Düzey Regresyon. Her ikisi de çoklu açıklayıcı değişkenlerle doğrusal ve lojistik regresyonu öğrenmenize yardımcı olur.
Modeli kurduğumuza göre, sonraki adım varsayımları kontrol etmek ve sonuçları yorumlamaktır. Basitlik adına tüm yönleri kapsamıyoruz.
Bu durum R’de hist() fonksiyonu ile gösterilebilir.
# Get the model residuals
model_residuals = cust_value_model$residuals
# Plot the result
hist(model_residuals)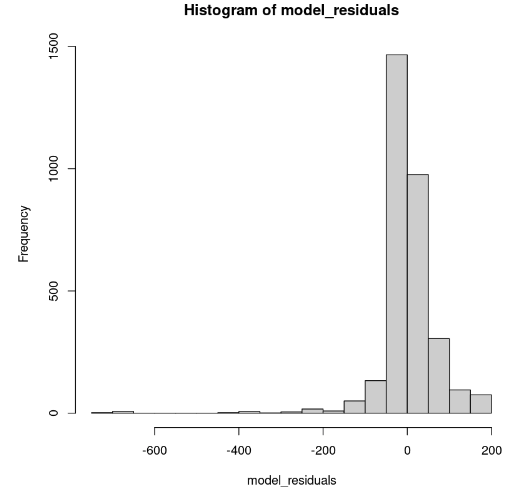
Model artıklarının dağılımı (Görsel: Yazar)
Histogram sola çarpık görünüyor; dolayısıyla normallik hakkında yeterli güvenle sonuca varamayız. Histogram yerine, artıkların normal Q-Q grafiği üzerindeki durumuna bakalım. Normallik varsa, değerler düz bir çizgiyi takip etmelidir.
# Plot the residuals
qqnorm(model_residuals)
# Plot the Q-Q line
qqline(model_residuals)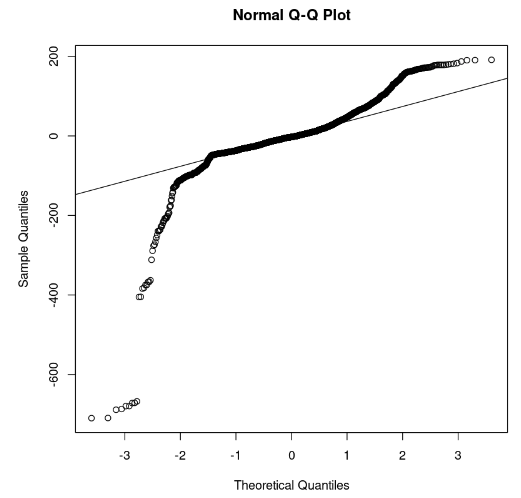
Q-Q grafiği ve artıklar (Görsel: Yazar)
Graftan, artıkların bazı kısımlarının düz bir çizgi üzerinde yer aldığını gözlemleyebiliriz. O hâlde modelin artıklarının normal dağılımı takip etmediğini varsayabiliriz.
Bu kontrol aşağıdaki R koduyla yapılır. Ancak öncesinde Customer_Value sütununu kaldırmamız gerekir.
# Install and load the ggcorrplot package
install.packages("ggcorrplot")
library(ggcorrplot)
# Remove the Customer Value column
reduced_data <- subset(churn_data, select = -Customer_Value)
# Compute correlation at 2 decimal places
corr_matrix = round(cor(reduced_data), 2)
# Compute and show the result
ggcorrplot(corr_matrix, hc.order = TRUE, type = "lower",
lab = TRUE)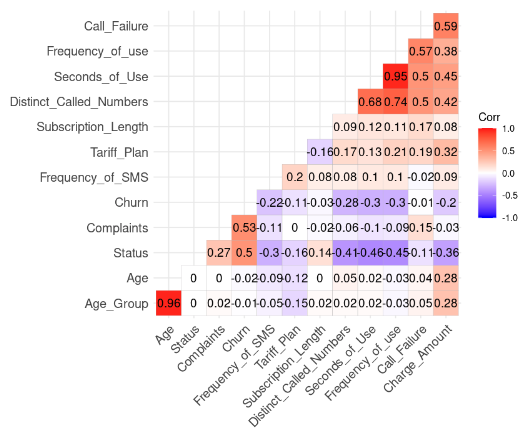
Veriden korelasyon sonucu (Görsel: Yazar)
Değerleri 0,8’den yüksek olduğu için iki güçlü korelasyon olduğunu fark edebiliyoruz.
Age ve Age_Group: 0,96
Frequency_of_use ve Seconds_of_Use: 0,95
Bu sonuç mantıklıdır; çünkü Age_Group, Age’den türetilmiştir. Ayrıca toplam saniye sayısı (Seconds_of_Use), toplam arama sayısından (Frequency_of_Use) elde edilir.
Bu durumda, veri setinden Age_Group ve Seconds_of_Use değişkenlerini kaldırabiliriz.
Bu iki değişken olmadan ikinci bir model kurmayı deneyelim.
second_model = lm(formula = Customer_Value ~ Call_Failure + Complaints +
Subscription_Length + Charge_Amount +
Frequency_of_use + Frequency_of_SMS +
Distinct_Called_Numbers + Tariff_Plan +
Status + Age,
data = churn_data)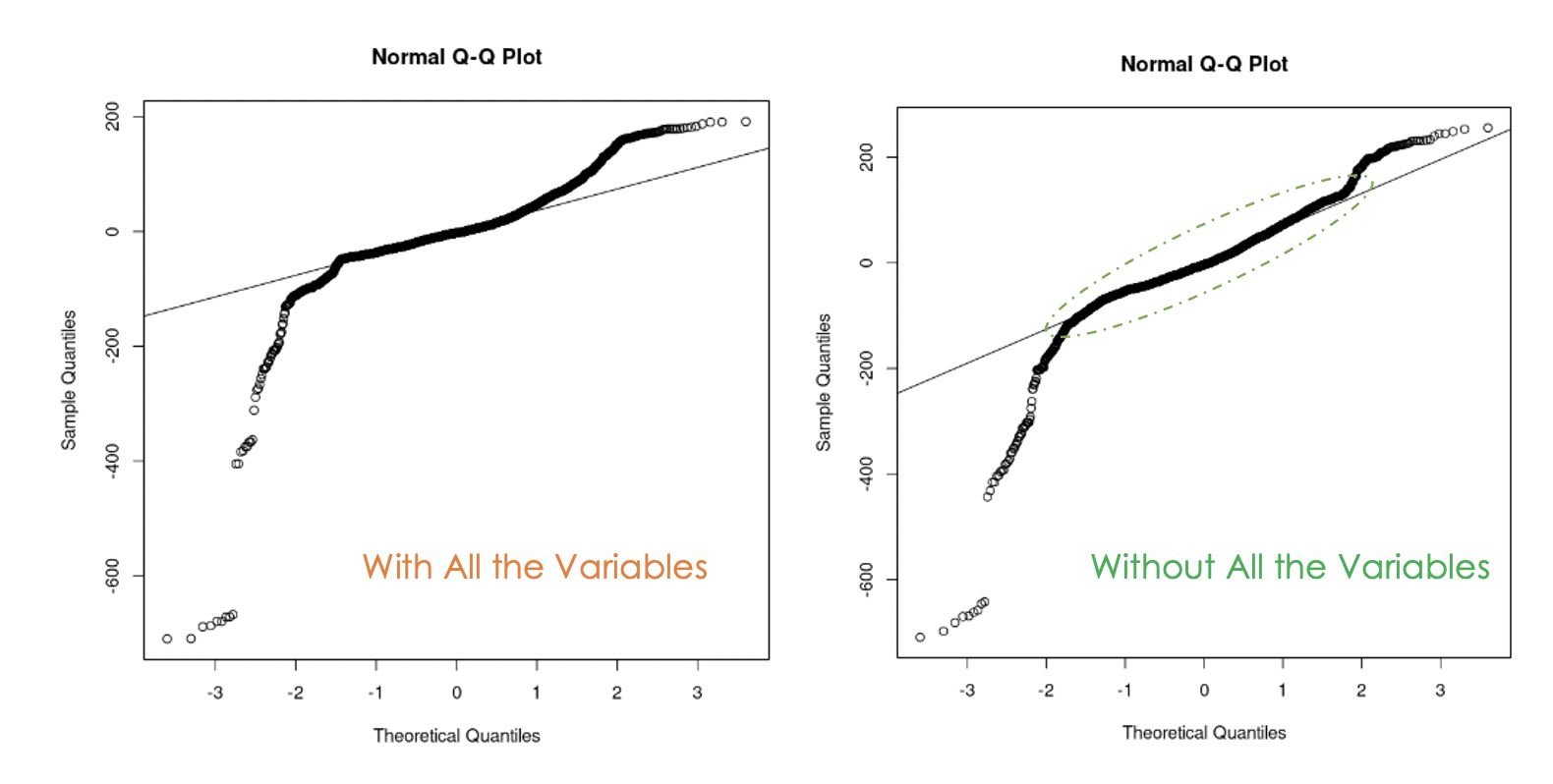
Birinci modelin (solda) ve ikinci modelin (sağda) Q-Q grafikleri
Verideki çoklu doğrusal bağlantıyı gidermenin faydalı olduğunu görebiliyoruz; çünkü ikinci modelde, birinci modele kıyasla daha fazla artık değeri düz çizgi üzerinde yer alıyor.
Şimdi şu soru kaldı: İki çoklu doğrusal regresyon modelinden hangisi daha iyi?
Bunu yanıtlamanın bir yolu, iki model için varyans analizi (ANOVA) testi yapmaktır. Bu test, daha önce kaldırdığımız değişkenlerin önemsiz olduğu boş hipotezi (H0) ile bu değişkenlerin önemli olduğunu söyleyen alternatif hipotezi (H1) karşılaştırır.
Yeni model, özgün modelin bir iyileştirmesiyse H0 reddedilemez. Aksi durumda bu değişkenlerin önemli olduğu anlamına gelir; dolayısıyla H0 reddedilir.
Genel ifade şöyledir: anova(original_model, new_model)
# Anova test
anova(cust_value_model, second_model)
ANOVA test sonucu (Görsel: Yazar)
ANOVA sonucundan, p-değerinin (8.0893e-316) çok küçük (0,05’ten az) olduğunu gözlemliyoruz; bu nedenle boş hipotezi reddediyoruz; yani ikinci model birincinin iyileştirmesi değildir.
Modeldeki önemli değişkenlere bakmanın bir başka yolu da anlamlılık testidir.
Bir değişkenin p-değeri 0,05’ten küçükse anlamlı kabul edilir. Bu sonuç summary() fonksiyonu ile üretilebilir. Bu fonksiyon, modele ilişkin bu bilgileri sağlamanın yanı sıra, modelleri birbirine karşı değerlendiren düzeltilmiş R-kare değerini de verir.
# Print the result of the model
summary(cust_value_model)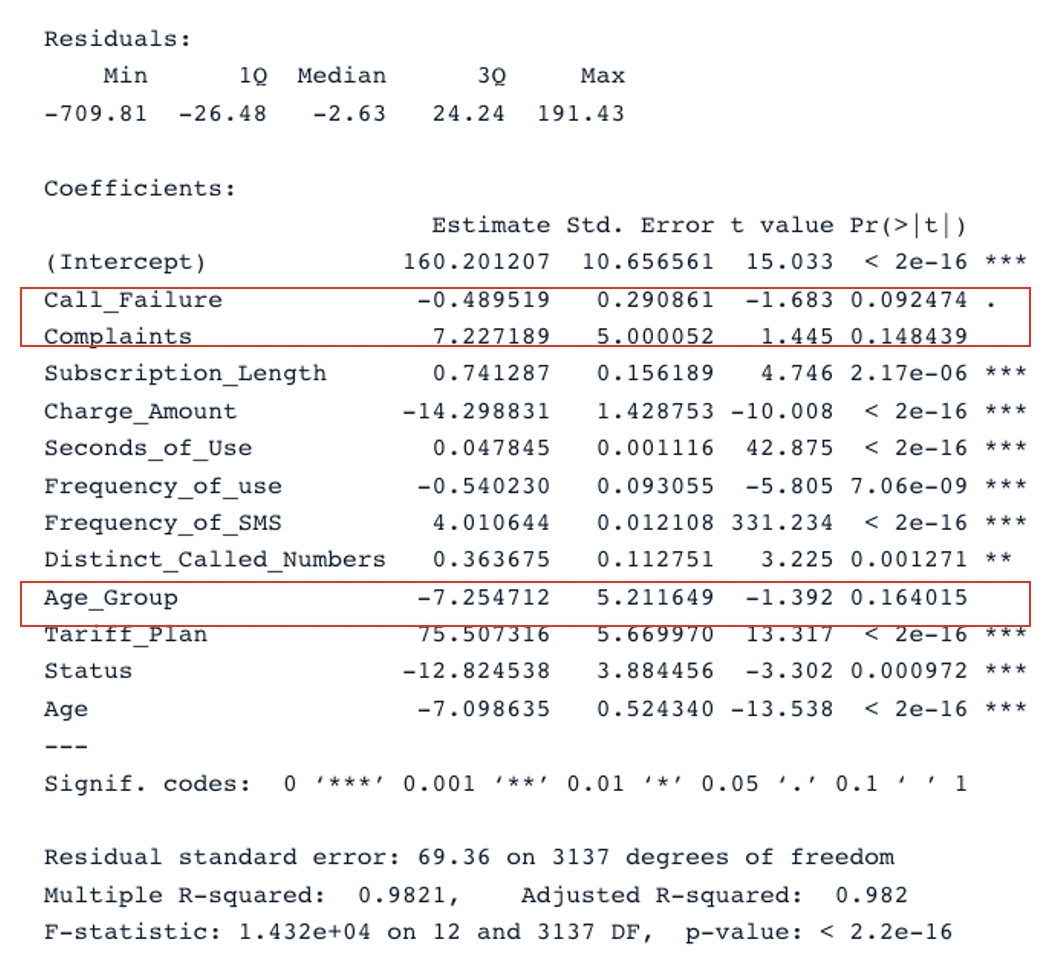
Tüm kestiricilerle özgün modelin özet sonucu (Görsel: Yazar)
Tabloda iki kilit bölüm var: Residuals ve Coefficients. Q-Q grafikleri, Residuals bölümündekiyle aynı bilgiyi verir. Coefficients bölümünde Call_Failure, Complaints ve Age_Group, p-değerleri 0,05’ten yüksek olduğu için model tarafından anlamlı kabul edilmez. Bunların tutulması modele ek bir değer sağlamaz.
Aynı analizi ikinci modele uyguladığımızda şu sonucu elde ederiz:
summary(second_model)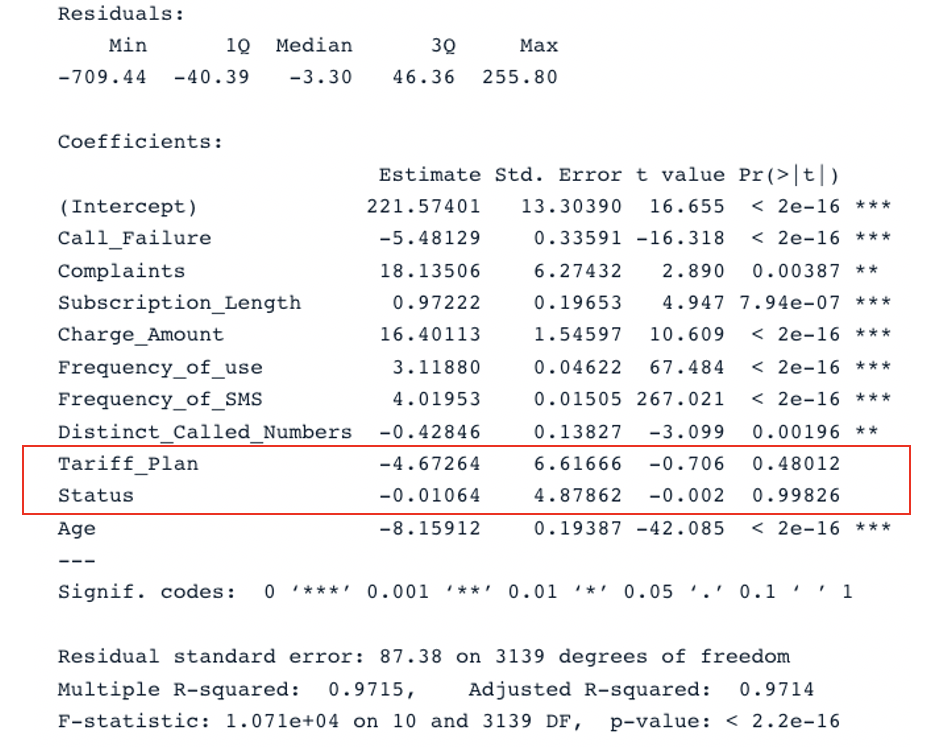
İkinci modelin tüm kestiricilerle özet sonucu (Görsel: Yazar)
Özgün modelin düzeltilmiş R-kare değeri 0,98 olup ikinci modelin düzeltilmiş R-kare değerinden (0,97) yüksektir. Bu da tüm kestiricilerin yer aldığı özgün modelin, ikinci modelden daha iyi olduğu anlamına gelir.
Bu analizin mantıksal bir sonraki adımı, anlamlı olmayan değişkenleri çıkarmak ve performansın iyileşip iyileşmediğini görmek için modeli yeniden kurmaktır.
İlgili kestiricileri verimli biçimde seçmenin bir başka stratejisi de Akaike Bilgi Kriteri (AIC)’dir.
Tüm özelliklerle başlayıp, en iyi modeli bulana dek her seferinde en zayıf kestiriciyi kademeli olarak çıkarır. AIC skoru ne kadar küçükse model o kadar iyidir. Bu işlem stepAIC() fonksiyonu ile yapılabilir.
Bu eğitim, çoklu doğrusal regresyonun temel yönlerini ele aldı ve sağlam modeller oluşturmak için bazı stratejileri inceledi.
Bu eğitimin, verilerinizden eyleme geçirilebilir içgörüler elde etmeniz için size gerekli becerileri kazandırmasını umuyoruz. workspace’imizde bulunan kaynak kodunu kullanarak farklı yaklaşımlar deneyip bu modelleri geliştirmeyi deneyebilirsiniz.
Kurslar
Kurs
Kurs
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Kurtis Pykes
Eğitim
Adel Nehme
