
Corso
Inferenza per la regressione lineare in R
4 h
16K

I metodi di regressione sono usati in diversi settori per capire quali variabili influenzano un determinato fenomeno di interesse.
Per esempio, gli economisti possono usarli per analizzare la relazione tra la spesa dei consumatori e la crescita del Prodotto Interno Lordo (PIL). I responsabili della sanità pubblica potrebbero voler comprendere i costi degli individui in base alle loro informazioni storiche. In entrambi i casi, l’obiettivo non è prevedere singoli scenari, ma ottenere una visione d’insieme della relazione complessiva.
In questo articolo inizieremo fornendo una comprensione generale delle regressioni. Poi spiegheremo che cosa differenzia le regressioni lineari semplici da quelle multiple, prima di addentrarci nelle implementazioni tecniche e offrire strumenti per aiutarti a comprendere e interpretare i risultati della regressione.
Prima di entrare nella regressione lineare multipla, capiamo cos’è una regressione lineare semplice: la multipla ne è solo un’estensione.
Una regressione lineare semplice mira a modellare la relazione tra l’entità di un’unica variabile indipendente X e una variabile dipendente Y cercando di stimare di quanto cambierà esattamente Y quando X varia di una certa quantità.
La variabile indipendente X, detta anche predittore, è la variabile usata per effettuare la previsione.
La variabile dipendente Y, detta anche risposta, è quella che stiamo cercando di prevedere.
L’aspetto “lineare” della regressione lineare è che cerchiamo di prevedere Y a partire da X usando la seguente equazione “lineare”.
Y = b0 + b1X
b0 è l’intercetta della retta di regressione, corrispondente al valore previsto quando X è nullo.
b1 è il coefficiente angolare della retta di regressione.
E la regressione lineare multipla?
È l’uso della regressione lineare con più variabili, e l’equazione è:
Y = b0 + b1X1 + b2X2 + b3X3 + … + bnXn + e
Y e b0 sono gli stessi del modello di regressione lineare semplice.
b1X1 rappresenta il coefficiente di regressione (b1) sulla prima variabile indipendente (X1). La stessa analisi vale per tutti i restanti coefficienti e variabili.
e è l’errore del modello (residui), che definisce quanta variazione viene introdotta nel modello quando si stima Y.
Nel caso di regressione multipla potremmo non ottenere sempre una retta. Tuttavia possiamo controllarne l’andamento adattando un modello più appropriato.
Ecco alcuni degli elementi chiave calcolati dalla regressione lineare multipla per trovare la retta di best fit per ciascun predittore.
Un aspetto importante nella costruzione di un modello di regressione lineare multipla è assicurarsi che siano soddisfatte le seguenti ipotesi chiave.
Nelle prossime sezioni tratteremo alcune di queste ipotesi.
In questa sezione entreremo nell’implementazione tecnica di un modello di regressione lineare multipla usando il linguaggio R.
Useremo il data set sul churn dei clienti dal workspace di DataCamp per stimare il valore del cliente.
Cosa intendiamo per valore del cliente? In pratica, determina quanto vale un prodotto o servizio per un cliente, e possiamo calcolarlo così:
Customer Value = Benefit — Cost. Dove Benefit e Cost sono, rispettivamente, il beneficio e il costo di un prodotto o servizio.
Questo valore è più alto se l’azienda riesce a offrire ai consumatori benefici maggiori e costi inferiori, o idealmente una combinazione di entrambi.
Questa analisi può aiutare il business a identificare l’opportunità di targeting più promettente o la prossima azione migliore in base al valore di un determinato cliente.
Facciamo una rapida panoramica del data set così da applicare il preprocessing rilevante prima di adattare il modello.
churn_data = read_csv('data/customer_churn.csv', show_col_types = FALSE)
# Look at the first 6 observations
head(churn_data)
# Check the dimension
dim(churn_data)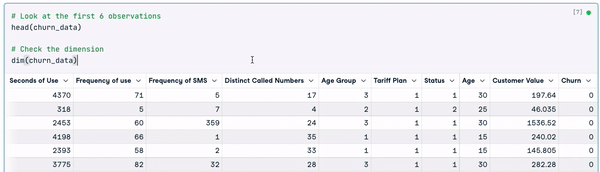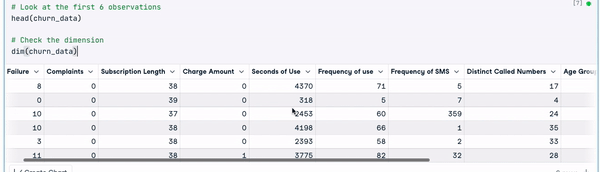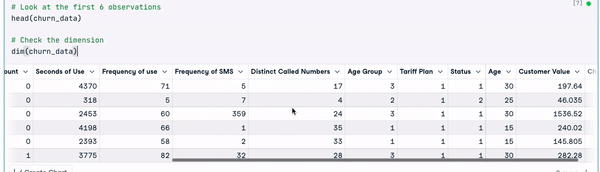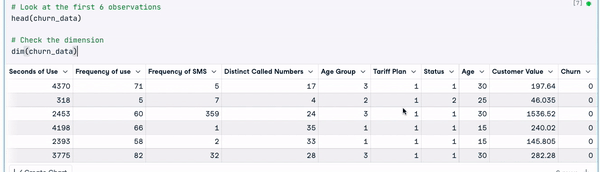
Prime 6 righe dei dati (animazione dell’autore)
Dai risultati precedenti possiamo osservare che il data set ha 3150 osservazioni e 14 colonne.
Tuttavia, in base al problema, non ci servirà la colonna churn perché stiamo affrontando un problema di regressione.
Prima di adattare il modello, effettuiamo il preprocessing dei nomi delle colonne sostituendo gli spazi con underscore, per evitare di dover mettere le virgolette attorno ai nomi delle variabili ogni volta.
# Change the column names
names(churn_data) = gsub(" ", "_", names(churn_data))
head(churn_data)
Prime 6 righe dopo la trasformazione dei nomi delle colonne (animazione dell’autore)
Con questi dati riformattati, possiamo inserirli nel framework della regressione multipla usando la funzione lm() in R come segue:
# Fit the multiple linear regression model
cust_value_model = lm(formula = Customer_Value ~ Call_Failure +
Complaints + Subscription_Length + Charge_Amount +
Seconds_of_Use +Frequency_of_use + Frequency_of_SMS +
Distinct_Called_Numbers + Age_Group + Tariff_Plan +
Status + Age,data = churn_data)Vediamo cosa abbiamo appena fatto.
La funzione lm() è nel seguente formato: lm(formula = Y ~Sum(Xi), data = our_data)
Y è la colonna Customer_Value perché è quella che stiamo cercando di stimare.
Sum(Xi) rappresenta l’espressione di somma nell’equazione della regressione lineare multipla.
our_data è churn_data.
Puoi approfondire nel nostro corso Intermediate Regression in R.
Un’alternativa a R è Python: Intermediate Regression with statsmodels in Python. Entrambi ti aiutano a imparare la regressione lineare e logistica con più variabili esplicative.
Ora che abbiamo costruito il modello, il passo successivo è verificare le assunzioni e interpretare i risultati. Per semplicità, non tratteremo tutti gli aspetti.
In R si può mostrare usando la funzione hist().
# Get the model residuals
model_residuals = cust_value_model$residuals
# Plot the result
hist(model_residuals)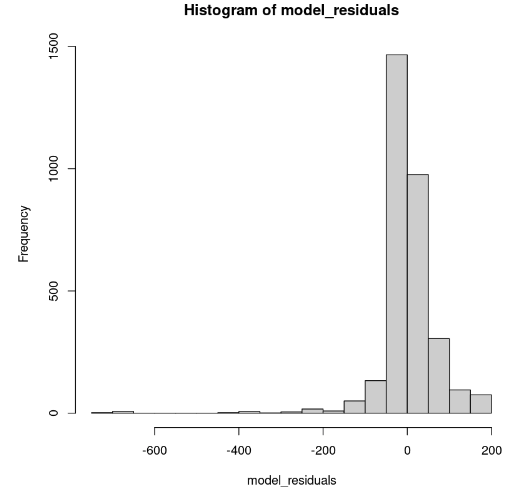
Distribuzione dei residui del modello (immagine dell’autore)
L’istogramma è asimmetrico a sinistra; quindi non possiamo concludere la normalità con sufficiente confidenza. Invece dell’istogramma, guardiamo i residui nel normal Q-Q plot. In presenza di normalità, i valori dovrebbero seguire una linea retta.
# Plot the residuals
qqnorm(model_residuals)
# Plot the Q-Q line
qqline(model_residuals)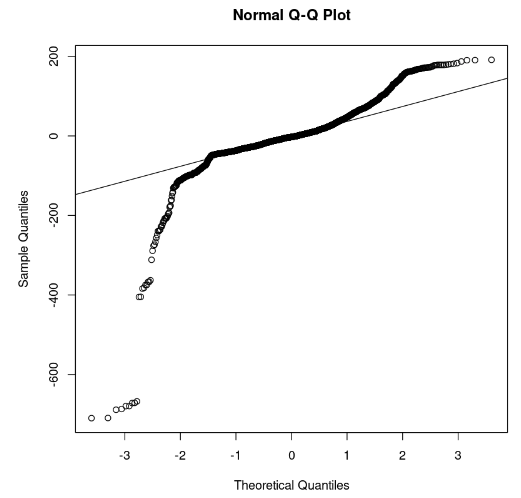
Q-Q plot e residui (immagine dell’autore)
Dal grafico possiamo osservare che alcune porzioni dei residui giacciono su una linea retta. Possiamo quindi assumere che i residui del modello non seguano una distribuzione normale.
Si effettua con il seguente codice R. Ma prima dobbiamo rimuovere la colonna Customer_Value.
# Install and load the ggcorrplot package
install.packages("ggcorrplot")
library(ggcorrplot)
# Remove the Customer Value column
reduced_data <- subset(churn_data, select = -Customer_Value)
# Compute correlation at 2 decimal places
corr_matrix = round(cor(reduced_data), 2)
# Compute and show the result
ggcorrplot(corr_matrix, hc.order = TRUE, type = "lower",
lab = TRUE)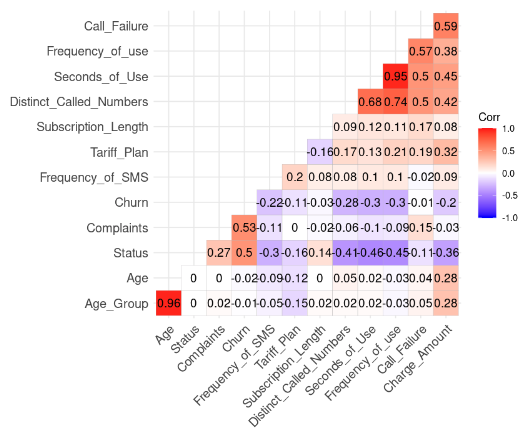
Risultato della correlazione dai dati (immagine dell’autore)
Notiamo due correlazioni forti perché il loro valore è superiore a 0,8.
Age e Age_Group: 0,96
Frequency_of_use e Seconds_of_Use: 0,95
Questo risultato ha senso perché Age_Group è calcolato da Age. Inoltre, il numero totale di secondi (Seconds_of_Use) deriva dal numero totale di chiamate (Frequency_of_Use).
In questo caso possiamo eliminare Age_Group e Seconds_of_Use dal dataset.
Proviamo a costruire un secondo modello senza queste due variabili.
second_model = lm(formula = Customer_Value ~ Call_Failure + Complaints +
Subscription_Length + Charge_Amount +
Frequency_of_use + Frequency_of_SMS +
Distinct_Called_Numbers + Tariff_Plan +
Status + Age,
data = churn_data)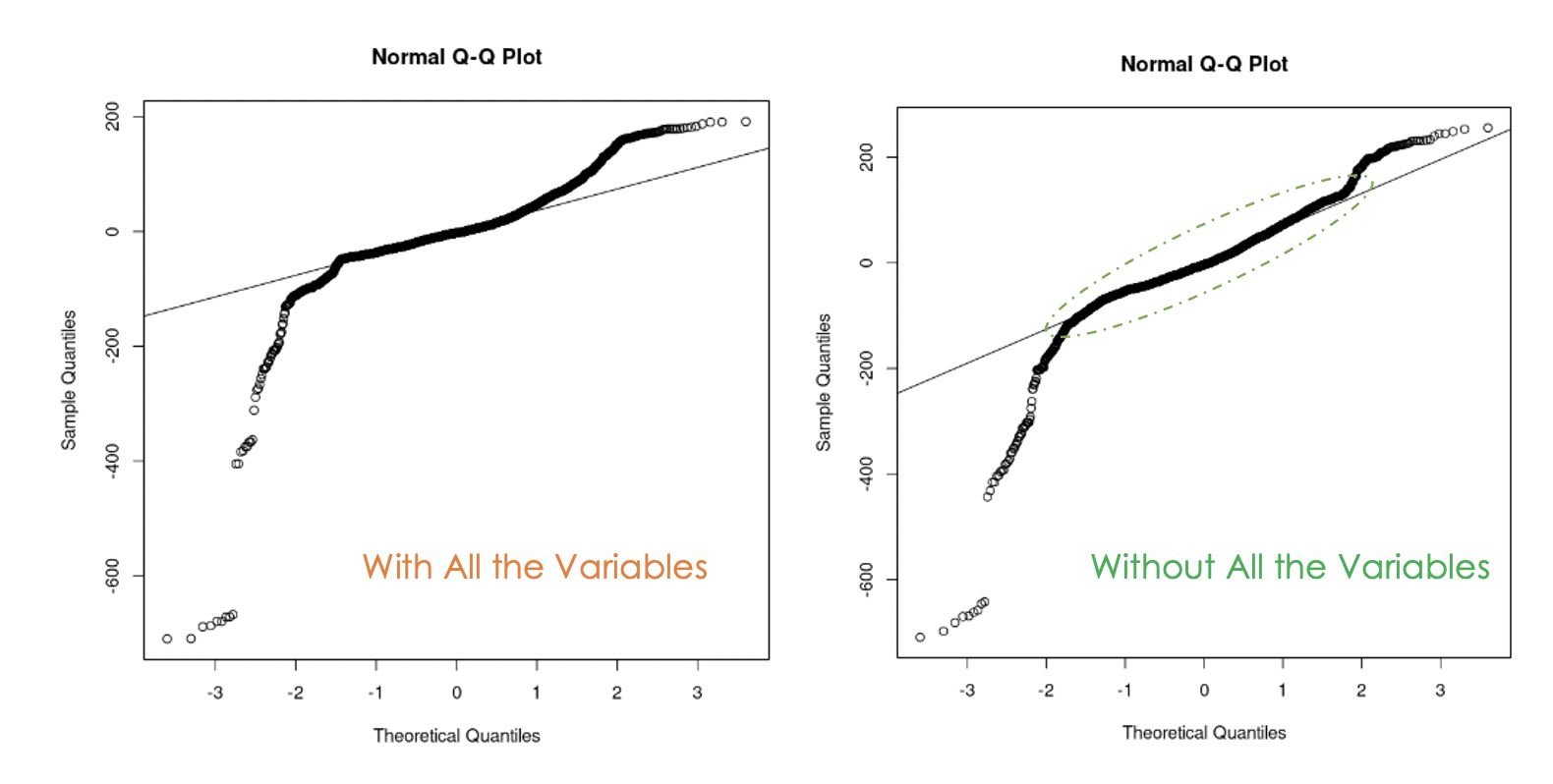
Q-Q plot del primo modello (sinistra) e del secondo modello (destra)
Possiamo notare che eliminare la multicollinearità nei dati è stato utile perché, con il secondo modello, più valori dei residui stanno sulla linea retta rispetto al primo modello.
Ci resta ora una domanda: quale dei due modelli di regressione lineare multipla è migliore?
Un modo per rispondere è eseguire un test ANOVA (analisi della varianza) sui due modelli. Verifica l’ipotesi nulla (H0), secondo cui le variabili che abbiamo rimosso in precedenza non sono significative, contro l’ipotesi alternativa (H1) che tali variabili siano significative.
Se il nuovo modello è un miglioramento dell’originale, allora non rifiutiamo H0. In caso contrario, significa che quelle variabili erano significative; quindi rifiutiamo H0.
Ecco l’espressione generale: anova(original_model, new_model)
# Anova test
anova(cust_value_model, second_model)
Risultato del test ANOVA (immagine dell’autore)
Dal risultato ANOVA osserviamo che il p-value (8.0893e-316) è molto piccolo (inferiore a 0,05), quindi rifiutiamo l’ipotesi nulla, il che significa che il secondo modello non è un miglioramento del primo.
Un altro modo per esaminare le variabili importanti nel modello è tramite un test di significatività.
Una variabile è significativa se il suo p-value è inferiore a 0,05. Questo risultato può essere generato con la funzione summary(). Oltre a fornire queste informazioni sul modello, mostra anche l’R-quadro aggiustato, che consente di confrontare le prestazioni tra modelli.
# Print the result of the model
summary(cust_value_model)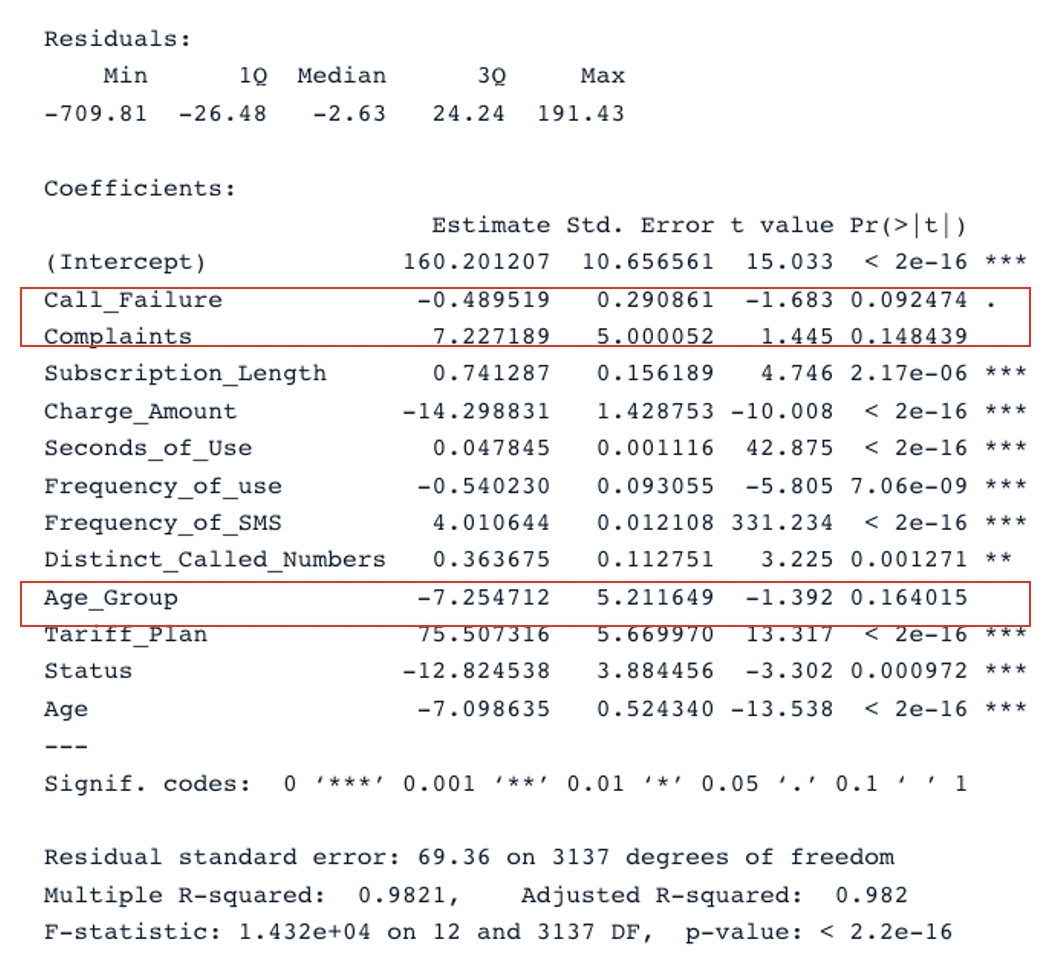
Risultato del riepilogo per il modello originale con tutti i predittori (immagine dell’autore)
Nella tabella abbiamo due sezioni chiave: Residuals e Coefficients. I Q-Q plot forniscono le stesse informazioni della sezione Residuals. Nella sezione Coefficients, Call_Failure, Complaints e Age_Group non sono considerati significativi dal modello perché il loro p-value è superiore a 0,05. Tenerli non aggiunge valore al modello.
Applicando la stessa analisi al secondo modello, otteniamo questo risultato:
summary(second_model)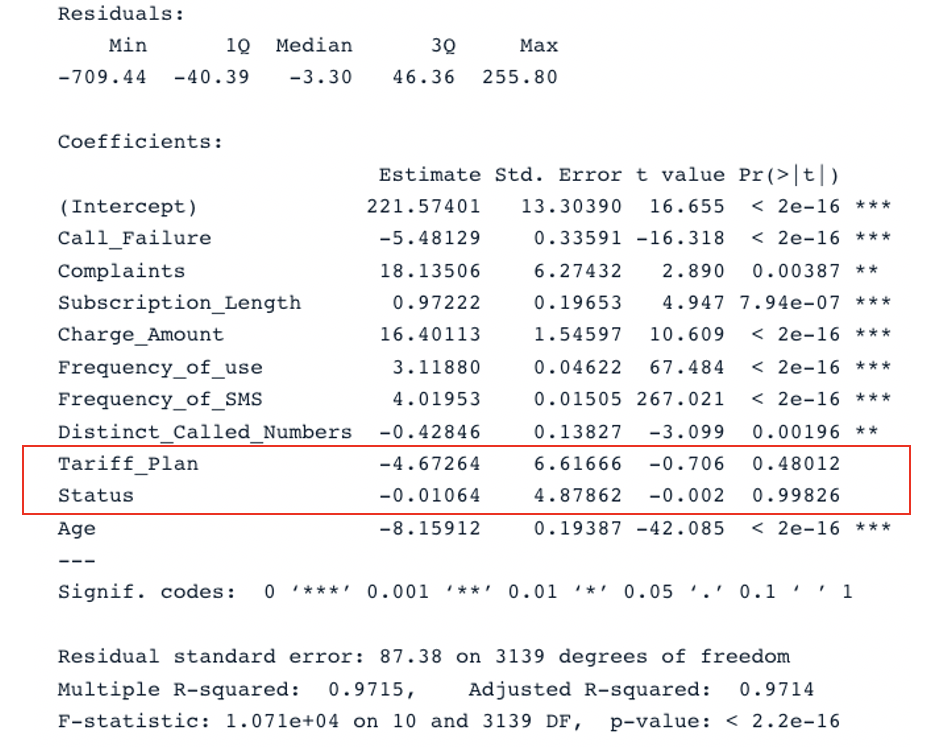
Risultato del riepilogo per il secondo modello con tutti i predittori (immagine dell’autore)
Il modello originale ha un R-quadro aggiustato di 0,98, più alto dell’R-quadro aggiustato del secondo modello (0,97). Ciò significa che il modello originale con tutti i predittori è migliore del secondo modello.
Il passo logico successivo di questa analisi è rimuovere le variabili non significative e riadattare il modello per vedere se le prestazioni migliorano.
Un’altra strategia per scegliere in modo efficiente i predittori rilevanti è l’Akaike Information Criteria (AIC).
Si parte da tutte le feature, poi si eliminano gradualmente i peggiori predittori uno alla volta finché non si trova il modello migliore. Più basso è l’AIC, migliore è il modello. Questo può essere fatto usando la funzione stepAIC().
Questo tutorial ha coperto gli aspetti principali della regressione lineare multipla ed esplorato alcune strategie per costruire modelli robusti.
Speriamo che questo tutorial ti dia le competenze necessarie per ottenere insight azionabili dai tuoi dati. Puoi provare a migliorare questi modelli applicando approcci diversi usando il codice sorgente disponibile nel nostro workspace.
Corsi
Corso
Corso
Corso
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min
blog
Abid Ali Awan
15 min

