Kursus
Pengantar Python
4 Hr
6.9M
Naive Bayes adalah teknik klasifikasi statistik berdasarkan Teorema Bayes. Ini adalah salah satu algoritme pembelajaran terawasi yang paling sederhana. Classifier Naive Bayes adalah algoritme yang cepat, akurat, dan andal. Classifier Naive Bayes memiliki akurasi dan kecepatan tinggi pada dataset besar.
Classifier Naive Bayes mengasumsikan bahwa pengaruh suatu fitur tertentu dalam sebuah kelas bersifat independen dari fitur lainnya. Misalnya, seorang pemohon pinjaman diinginkan atau tidak bergantung pada pendapatan, riwayat pinjaman dan transaksi sebelumnya, usia, dan lokasi. Meskipun fitur-fitur ini saling bergantung, fitur-fitur tersebut tetap dianggap independen. Asumsi ini menyederhanakan komputasi, dan karena itulah disebut naive. Asumsi ini disebut independensi bersyarat kelas.
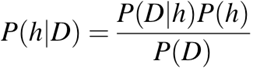
P(h): probabilitas hipotesis h benar (terlepas dari data). Ini dikenal sebagai probabilitas prior dari h.
P(D): probabilitas data (terlepas dari hipotesis). Ini dikenal sebagai probabilitas prior.
P(h|D): probabilitas hipotesis h diberikan data D. Ini dikenal sebagai probabilitas posterior.
P(D|h): probabilitas data d dengan asumsi hipotesis h benar. Ini dikenal sebagai probabilitas posterior.
Setiap kali Anda melakukan klasifikasi, langkah pertama adalah memahami masalah dan mengidentifikasi fitur serta label yang potensial. Fitur adalah karakteristik atau atribut yang memengaruhi hasil label. Misalnya, dalam kasus penyaluran pinjaman, manajer bank mengidentifikasi pekerjaan, pendapatan, usia, lokasi, riwayat pinjaman sebelumnya, riwayat transaksi, dan skor kredit nasabah. Karakteristik ini dikenal sebagai fitur yang membantu model mengklasifikasikan nasabah.
Klasifikasi memiliki dua fase, fase pembelajaran dan fase evaluasi. Pada fase pembelajaran, classifier melatih modelnya pada dataset yang diberikan, dan pada fase evaluasi, ia menguji kinerja classifier. Kinerja dievaluasi berdasarkan berbagai parameter seperti akurasi, kesalahan, presisi, dan recall.
Mari pahami cara kerja Naive Bayes melalui sebuah contoh. Diberikan contoh kondisi cuaca dan kegiatan bermain olahraga. Anda perlu menghitung probabilitas bermain olahraga. Sekarang, Anda perlu mengklasifikasikan apakah pemain akan bermain atau tidak, berdasarkan kondisi cuaca.
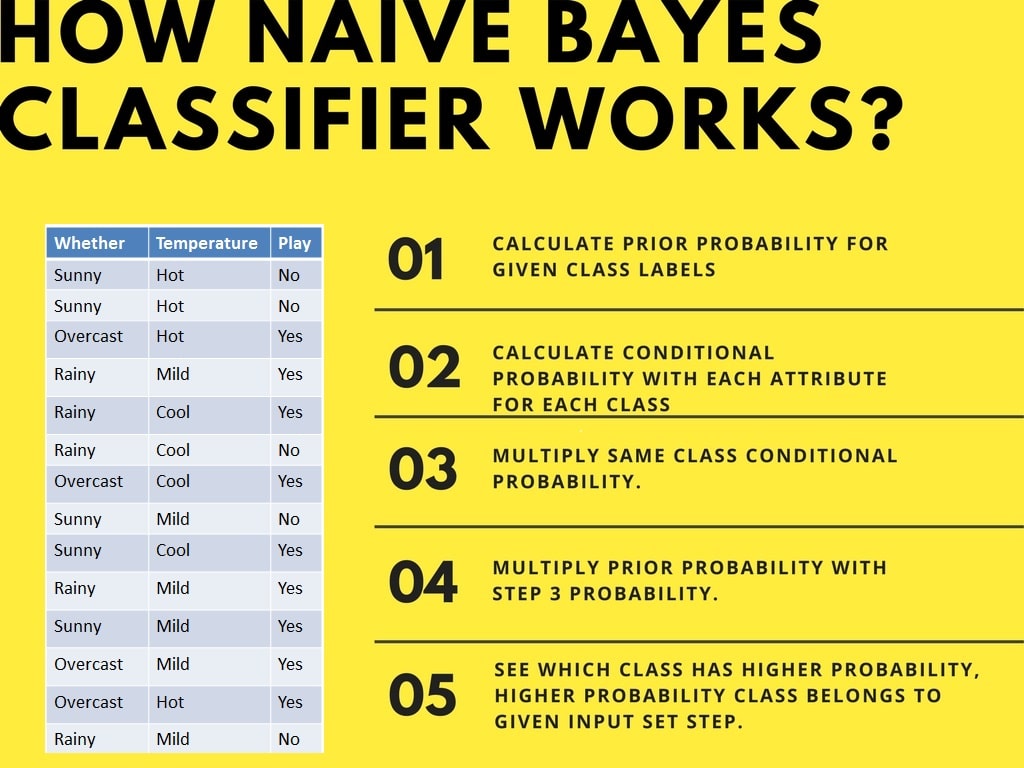
Classifier Naive Bayes menghitung probabilitas suatu kejadian dalam langkah-langkah berikut:
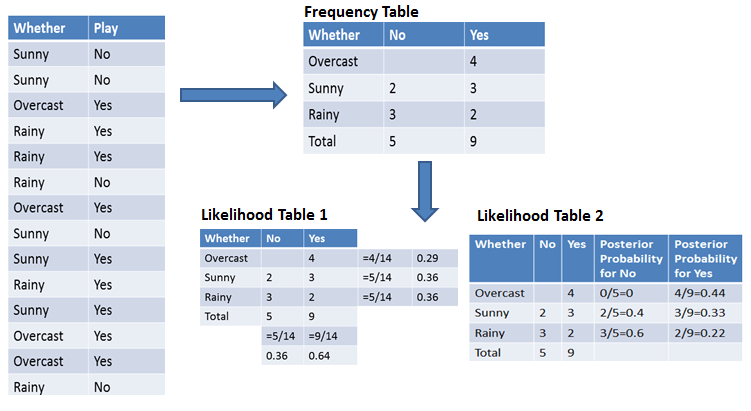
Untuk menyederhanakan perhitungan probabilitas prior dan posterior, Anda dapat menggunakan dua tabel: tabel frekuensi dan tabel likelihood. Kedua tabel ini akan membantu Anda menghitung probabilitas prior dan posterior. Tabel frekuensi memuat kemunculan label untuk semua fitur. Ada dua tabel likelihood. Tabel Likelihood 1 menampilkan probabilitas prior label dan Tabel Likelihood 2 menampilkan probabilitas posterior.
Sekarang, misalkan Anda ingin menghitung probabilitas bermain ketika cuaca mendung (overcast).
Probabilitas bermain:
P(Yes | Overcast) = P(Overcast | Yes) × P(Yes) / P(Overcast)
Langkah 1: Hitung Probabilitas Prior
Langkah 2: Hitung probabilitas posterior
Langkah 3: Terapkan Rumus Bayes
Di sini, kita memasukkan probabilitas prior dan posterior ke persamaan pertama.
P(Yes | Overcast) = 0.44 × 0.64 / 0.29 = 0.98
Serupa, Anda dapat menghitung probabilitas tidak bermain:
Probabilitas tidak bermain:
P(No | Overcast) = P(Overcast | No) × P(No) / P(Overcast)
Langkah 1: Hitung probabilitas prior
Langkah 2: Hitung likelihood
Langkah 3: Terapkan Rumus Bayes
Di sini, kita memasukkan probabilitas prior dan likelihood ke persamaan untuk mendapatkan probabilitas posterior.
P(No | Overcast) = 0 × 0.36 / 0.29 = 0
Probabilitas kelas 'Yes' lebih tinggi. Jadi Anda dapat menentukan bahwa jika cuaca mendung, para pemain akan bermain olahraga.
Sekarang, misalkan Anda ingin menghitung probabilitas bermain ketika cuaca mendung dan temperaturnya sejuk (mild).
Probabilitas bermain:
P(Play = Yes | Weather = Overcast, Temp = Mild) = P(Weather = Overcast, Temp = Mild | Play = Yes) × P(Play = Yes)
Menggunakan asumsi independensi Naive Bayes:
P(Weather = Overcast, Temp = Mild | Play = Yes) = P(Overcast | Yes) × P(Mild | Yes)
Langkah 1: Hitung probabilitas prior
Langkah 2: Hitung likelihood
Langkah 3: Hitung likelihood gabungan
P(Weather = Overcast, Temp = Mild | Play = Yes) = 0.44 × 0.44 = 0.1936
Langkah 4: Terapkan Rumus Bayes
P(Play = Yes | Weather = Overcast, Temp = Mild) = 0.1936 × 0.64 = 0.124
Serupa, Anda dapat menghitung probabilitas tidak bermain:
Probabilitas tidak bermain:
P(Play = No | Weather = Overcast, Temp = Mild) = P(Weather = Overcast, Temp = Mild | Play = No) × P(Play = No)
Menggunakan asumsi independensi Naive Bayes:
P(Weather = Overcast, Temp = Mild | Play = No) = P(Overcast | No) × P(Mild | No)
Langkah 1: Hitung probabilitas prior
Langkah 2: Hitung likelihood
Langkah 3: Hitung likelihood gabungan
P(Weather = Overcast, Temp = Mild | Play = No) = 0 × 0.4 = 0
Langkah 4: Terapkan Rumus Bayes
P(Play = No | Weather = Overcast, Temp = Mild) = 0 × 0.36 = 0
Probabilitas kelas 'Yes' lebih tinggi (0.124 vs 0), jadi jika cuaca mendung dan temperaturnya sejuk, para pemain akan bermain olahraga.
Pada contoh pertama, kita akan menghasilkan data sintetis menggunakan scikit-learn lalu melatih dan mengevaluasi algoritme Gaussian Naive Bayes.
Scikit-learn menyediakan ekosistem machine learning sehingga kita dapat menghasilkan dataset dan mengevaluasi berbagai algoritme machine learning.
Pada kasus kita, kita membuat dataset dengan enam fitur, tiga kelas, dan 800 sampel menggunakan fungsi make_classification().
from sklearn.datasets import make_classification
X, y = make_classification(
n_features=6,
n_classes=3,
n_samples=800,
n_informative=2,
random_state=1,
n_clusters_per_class=1,
)Kita akan menggunakan fungsi scatter() dari matplotlib.pyplot untuk memvisualisasikan dataset.
import matplotlib.pyplot as plt
plt.scatter(X[:, 0], X[:, 1], c=y, marker="*");Seperti dapat kita lihat, ada tiga jenis label target, dan kita akan melatih model klasifikasi multikelas.
Sebelum memulai proses pelatihan, kita perlu membagi dataset menjadi data latih dan uji untuk evaluasi model.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.33, random_state=125
)Buat Gaussian Naive Bayes generik dan latih pada dataset pelatihan. Setelah itu, berikan satu sampel uji acak ke model untuk mendapatkan nilai prediksi.
from sklearn.naive_bayes import GaussianNB
# Build a Gaussian Classifier
model = GaussianNB()
# Model training
model.fit(X_train, y_train)
# Predict Output
predicted = model.predict([X_test[6]])
print("Actual Value:", y_test[6])
print("Predicted Value:", predicted[0])Nilai aktual dan prediksi sama.
Actual Value: 0
Predicted Value: 0Kita tidak akan mengembangkan model pada dataset uji yang belum terlihat. Pertama, kita akan memprediksi nilai untuk dataset uji dan menggunakannya untuk menghitung akurasi dan skor F1.
from sklearn.metrics import (
accuracy_score,
confusion_matrix,
ConfusionMatrixDisplay,
f1_score,
)
y_pred = model.predict(X_test)
accuray = accuracy_score(y_pred, y_test)
f1 = f1_score(y_pred, y_test, average="weighted")
print("Accuracy:", accuray)
print("F1 Score:", f1)Model kita berkinerja cukup baik dengan hiperparameter bawaan.
Accuracy: 0.8484848484848485
F1 Score: 0.8491119695890328Untuk memvisualisasikan confusion matrix, kita akan menggunakan confusion_matrix untuk menghitung true positive dan true negative serta ConfusionMatrixDisplay untuk menampilkan confusion matrix dengan label.
labels = [0,1,2]
cm = confusion_matrix(y_test, y_pred, labels=labels)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=labels)
disp.plot();Model kita berkinerja cukup baik, dan kita dapat meningkatkan kinerja model dengan penskalaan, praproses, validasi silang, dan pengoptimalan hiperparameter.
Mari melatih Classifier Naive Bayes pada dataset nyata. Kita akan mengulangi sebagian besar tugas kecuali praproses dan eksplorasi data.
Pada contoh ini, kita akan memuat Loan Data dari DataLab menggunakan fungsi pandas read_csv.
import pandas as pd
df = pd.read_csv('loan_data.csv')
df.head()Untuk memahami lebih jauh tentang dataset, kita akan menggunakan .info().
Dataset terdiri dari 14 kolom dan 9578 baris.
Selain purpose, kolom lainnya bertipe float atau integer.
Kolom target kita adalah not.fully.paid.
df.info()RangeIndex: 9578 entries, 0 to 9577
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 credit.policy 9578 non-null int64
1 purpose 9578 non-null object
2 int.rate 9578 non-null float64
3 installment 9578 non-null float64
4 log.annual.inc 9578 non-null float64
5 dti 9578 non-null float64
6 fico 9578 non-null int64
7 days.with.cr.line 9578 non-null float64
8 revol.bal 9578 non-null int64
9 revol.util 9578 non-null float64
10 inq.last.6mths 9578 non-null int64
11 delinq.2yrs 9578 non-null int64
12 pub.rec 9578 non-null int64
13 not.fully.paid 9578 non-null int64
dtypes: float64(6), int64(7), object(1)
memory usage: 1.0+ MBPada contoh ini, kita akan mengembangkan model untuk memprediksi pelanggan yang belum melunasi pinjaman sepenuhnya. Mari telusuri kolom purpose dan target menggunakan countplot dari seaborn.
import seaborn as sns
import matplotlib.pyplot as plt
sns.countplot(data=df,x='purpose',hue='not.fully.paid')
plt.xticks(rotation=45, ha='right');Dataset kita tidak seimbang yang akan memengaruhi kinerja model. Anda dapat melihat tutorial Resample an Imbalanced Dataset untuk praktik langsung menangani dataset tidak seimbang.
Kita sekarang akan mengonversi kolom purpose dari kategorikal menjadi integer menggunakan fungsi pandas get_dummies().
pre_df = pd.get_dummies(df,columns=['purpose'],drop_first=True)
pre_df.head()Setelah itu, kita akan mendefinisikan variabel fitur (X) dan target (y), serta membagi dataset menjadi set pelatihan dan pengujian.
from sklearn.model_selection import train_test_split
X = pre_df.drop('not.fully.paid', axis=1)
y = pre_df['not.fully.paid']
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.33, random_state=125
)Pembangunan dan pelatihan model cukup sederhana. Kita akan melatih model pada dataset pelatihan menggunakan hiperparameter bawaan.
from sklearn.naive_bayes import GaussianNB
model = GaussianNB()
model.fit(X_train, y_train);Kita akan menggunakan akurasi dan skor f1 untuk menilai kinerja model, dan tampaknya algoritme Gaussian Naive Bayes berkinerja cukup baik.
from sklearn.metrics import (
accuracy_score,
confusion_matrix,
ConfusionMatrixDisplay,
f1_score,
classification_report,
)
y_pred = model.predict(X_test)
accuray = accuracy_score(y_pred, y_test)
f1 = f1_score(y_pred, y_test, average="weighted")
print("Accuracy:", accuray)
print("F1 Score:", f1)Accuracy: 0.8206263840556786
F1 Score: 0.8686606980013266Karena sifat data yang tidak seimbang, kita dapat melihat bahwa confusion matrix menunjukkan cerita berbeda. Pada target minoritas: not fully paid, kita memiliki lebih banyak label yang salah.
labels = ["Fully Paid", "Not fully Paid"]
cm = confusion_matrix(y_test, y_pred)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=labels)
disp.plot();Jika Anda mengalami masalah selama pelatihan atau evaluasi model, Anda dapat melihat DataLab workbook Naive Bayes Classification Tutorial using Scikit-learn. Workbook ini dilengkapi dataset, kode sumber, dan keluaran.
Misalkan tidak ada tuple untuk pinjaman berisiko dalam dataset; dalam skenario ini, probabilitas posterior akan bernilai nol, dan model tidak dapat membuat prediksi. Masalah ini dikenal sebagai Zero Probability karena kemunculan kelas tertentu adalah nol.
Solusi untuk masalah semacam ini adalah koreksi Laplace atau Transformasi Laplace. Koreksi Laplace adalah salah satu teknik smoothing. Di sini, Anda dapat berasumsi bahwa dataset cukup besar sehingga menambahkan satu baris untuk setiap kelas tidak akan membuat perbedaan dalam probabilitas estimasi. Ini akan mengatasi masalah nilai probabilitas menjadi nol.
Contoh: Misalkan untuk kelas pinjaman berisiko, ada 1000 tuple pelatihan dalam basis data. Dalam basis data ini, kolom pendapatan memiliki 0 tuple untuk pendapatan rendah, 990 tuple untuk pendapatan menengah, dan 10 tuple untuk pendapatan tinggi. Probabilitas kejadian ini, tanpa koreksi Laplace, adalah 0, 0,990 (dari 990/1000), dan 0,010 (dari 10/1000)
Sekarang, terapkan koreksi Laplace pada dataset yang diberikan. Mari tambahkan 1 tuple lagi untuk setiap pasangan nilai-pendapatan. Probabilitas kejadian ini:
Selamat, Anda telah mencapai akhir tutorial ini!
Dalam tutorial ini, Anda mempelajari algoritme Naive Bayes, cara kerjanya, asumsi Naive Bayes, isu-isu terkait, implementasi, kelebihan, dan kekurangannya. Sepanjang jalan, Anda juga mempelajari pembangunan dan evaluasi model di scikit-learn untuk kelas biner dan multinomial.
Naive Bayes adalah algoritme yang paling sederhana dan ampuh. Terlepas dari kemajuan besar dalam machine learning dalam beberapa tahun terakhir, algoritme ini telah membuktikan nilainya. Algoritme ini telah berhasil diterapkan dalam banyak aplikasi, dari analitik teks hingga mesin rekomendasi.
Jika Anda ingin mempelajari lebih lanjut tentang scikit-learn di Python, ikuti kursus Supervised Learning with scikit-learn kami dan lihat Scikit-Learn Tutorial: Baseball Analytics Pt 1.
Kursus Python
Kursus
Kursus
Kursus
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
