Courses
Nhập môn Python
4 giờ
6.9M
Naive Bayes là kỹ thuật phân loại thống kê dựa trên Định lý Bayes. Đây là một trong những thuật toán học có giám sát đơn giản nhất. Bộ phân loại Naive Bayes là thuật toán nhanh, chính xác và đáng tin cậy. Các bộ phân loại Naive Bayes đạt độ chính xác và tốc độ cao trên các tập dữ liệu lớn.
Bộ phân loại Naive Bayes giả định rằng ảnh hưởng của một đặc trưng cụ thể trong một lớp là độc lập với các đặc trưng khác. Ví dụ, một người nộp đơn vay có đáng mong muốn hay không phụ thuộc vào thu nhập, lịch sử khoản vay và giao dịch trước đó, độ tuổi và vị trí của họ. Ngay cả khi các đặc trưng này phụ thuộc lẫn nhau, chúng vẫn được coi là độc lập. Giả định này đơn giản hóa tính toán, và đó là lý do nó được coi là “naive” (ngây thơ). Giả định này được gọi là độc lập điều kiện theo lớp (class conditional independence).
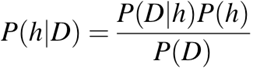
P(h): xác suất giả thuyết h là đúng (bất kể dữ liệu). Đây được gọi là xác suất tiên nghiệm của h.
P(D): xác suất của dữ liệu (bất kể giả thuyết). Đây được gọi là xác suất tiên nghiệm.
P(h|D): xác suất giả thuyết h khi biết dữ liệu D. Đây được gọi là xác suất hậu nghiệm.
P(D|h): xác suất dữ liệu d khi giả thuyết h là đúng. Đây được gọi là xác suất hậu nghiệm.
Mỗi khi bạn thực hiện phân loại, bước đầu tiên là hiểu bài toán và xác định các đặc trưng tiềm năng và nhãn. Đặc trưng là những đặc điểm hoặc thuộc tính ảnh hưởng đến kết quả của nhãn. Ví dụ, trong trường hợp phân bổ khoản vay, các quản lý ngân hàng xác định nghề nghiệp, thu nhập, độ tuổi, vị trí, lịch sử khoản vay trước đây, lịch sử giao dịch và điểm tín dụng của khách hàng. Những đặc điểm này được gọi là đặc trưng và giúp mô hình phân loại khách hàng.
Phân loại có hai giai đoạn: giai đoạn học và giai đoạn đánh giá. Ở giai đoạn học, bộ phân loại huấn luyện mô hình trên một tập dữ liệu cho trước; ở giai đoạn đánh giá, nó kiểm tra hiệu suất của bộ phân loại. Hiệu suất được đánh giá dựa trên nhiều tham số như độ chính xác, lỗi, độ chính xác (precision) và độ bao phủ (recall).
Hãy hiểu cách hoạt động của Naive Bayes qua một ví dụ. Cho ví dụ về điều kiện thời tiết và việc chơi thể thao. Bạn cần tính xác suất chơi thể thao. Giờ bạn cần phân loại liệu người chơi có chơi hay không, dựa trên điều kiện thời tiết.
Bộ phân loại Naive Bayes tính xác suất của một sự kiện theo các bước sau:
Để đơn giản hóa việc tính toán xác suất tiên nghiệm và hậu nghiệm, bạn có thể dùng hai bảng: bảng tần suất và bảng khả dĩ. Cả hai bảng này sẽ giúp bạn tính xác suất tiên nghiệm và hậu nghiệm. Bảng tần suất chứa số lần xuất hiện của nhãn cho tất cả đặc trưng. Có hai bảng khả dĩ. Bảng Khả dĩ 1 thể hiện xác suất tiên nghiệm của nhãn và Bảng Khả dĩ 2 thể hiện xác suất hậu nghiệm.
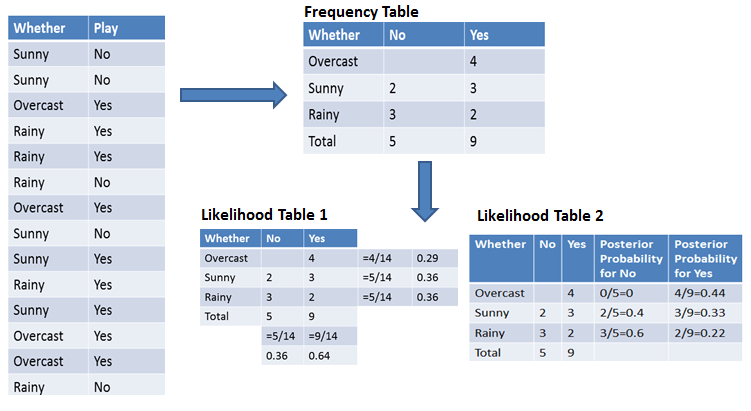
Giờ giả sử bạn muốn tính xác suất chơi khi thời tiết u ám (overcast).
Xác suất chơi:
P(Yes | Overcast) = P(Overcast | Yes) × P(Yes) / P(Overcast)
Bước 1: Tính xác suất tiên nghiệm
Bước 2: Tính xác suất hậu nghiệm
Bước 3: Áp dụng Công thức Bayes
Tại đây, ta thay các xác suất tiên nghiệm và hậu nghiệm vào phương trình ban đầu.
P(Yes | Overcast) = 0.44 × 0.64 / 0.29 = 0.98
Tương tự, bạn có thể tính xác suất không chơi:
Xác suất không chơi:
P(No | Overcast) = P(Overcast | No) × P(No) / P(Overcast)
Bước 1: Tính xác suất tiên nghiệm
Bước 2: Tính khả dĩ
Bước 3: Áp dụng Công thức Bayes
Tại đây, ta thay xác suất tiên nghiệm và khả dĩ vào phương trình để nhận được xác suất hậu nghiệm.
P(No | Overcast) = 0 × 0.36 / 0.29 = 0
Xác suất của lớp 'Yes' cao hơn. Vì vậy, bạn có thể xác định rằng nếu thời tiết u ám, người chơi sẽ tham gia môn thể thao.
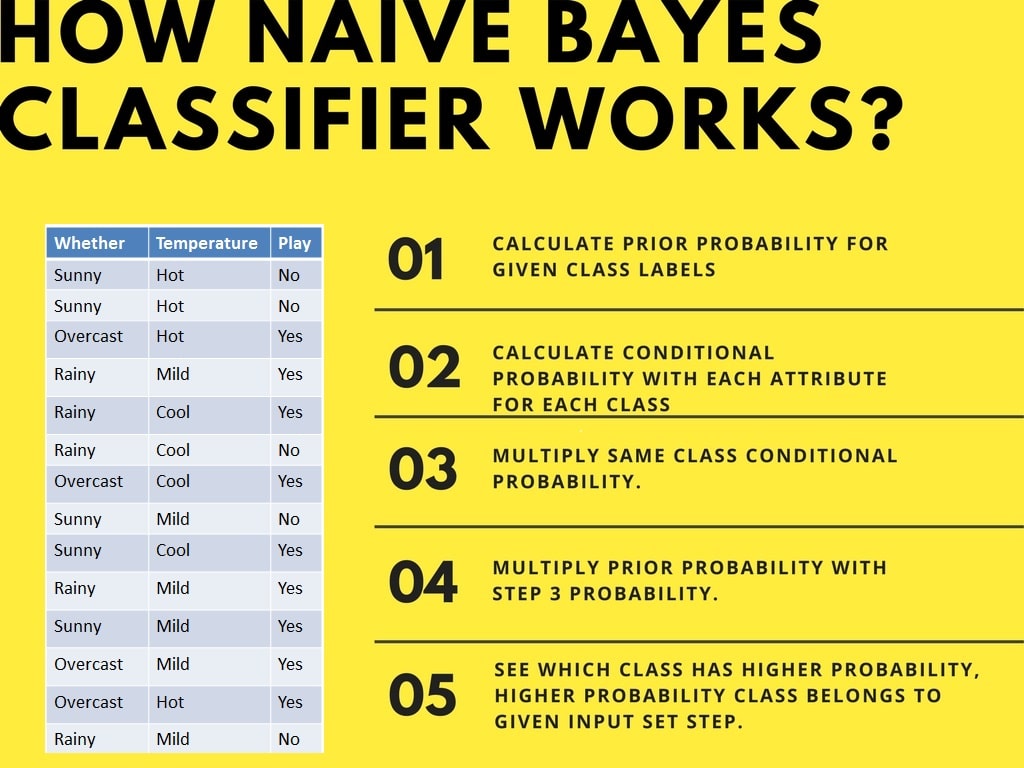
Giờ giả sử bạn muốn tính xác suất chơi khi thời tiết u ám và nhiệt độ ôn hòa.
Xác suất chơi:
P(Play = Yes | Weather = Overcast, Temp = Mild) = P(Weather = Overcast, Temp = Mild | Play = Yes) × P(Play = Yes)
Sử dụng giả định độc lập của Naive Bayes:
P(Weather = Overcast, Temp = Mild | Play = Yes) = P(Overcast | Yes) × P(Mild | Yes)
Bước 1: Tính xác suất tiên nghiệm
Bước 2: Tính các khả dĩ
Bước 3: Tính khả dĩ kết hợp
P(Weather = Overcast, Temp = Mild | Play = Yes) = 0.44 × 0.44 = 0.1936
Bước 4: Áp dụng Công thức Bayes
P(Play = Yes | Weather = Overcast, Temp = Mild) = 0.1936 × 0.64 = 0.124
Tương tự, bạn có thể tính xác suất không chơi:
Xác suất không chơi:
P(Play = No | Weather = Overcast, Temp = Mild) = P(Weather = Overcast, Temp = Mild | Play = No) × P(Play = No)
Sử dụng giả định độc lập của Naive Bayes:
P(Weather = Overcast, Temp = Mild | Play = No) = P(Overcast | No) × P(Mild | No)
Bước 1: Tính xác suất tiên nghiệm
Bước 2: Tính các khả dĩ
Bước 3: Tính khả dĩ kết hợp
P(Weather = Overcast, Temp = Mild | Play = No) = 0 × 0.4 = 0
Bước 4: Áp dụng Công thức Bayes
P(Play = No | Weather = Overcast, Temp = Mild) = 0 × 0.36 = 0
Xác suất của lớp 'Yes' cao hơn (0.124 so với 0), nên nếu trời u ám và nhiệt độ ôn hòa, người chơi sẽ tham gia môn thể thao.
Trong ví dụ đầu tiên, chúng ta sẽ tạo dữ liệu tổng hợp bằng scikit-learn và huấn luyện, đánh giá thuật toán Gaussian Naive Bayes.
Scikit-learn cung cấp cho chúng ta một hệ sinh thái học máy để có thể tạo tập dữ liệu và đánh giá nhiều thuật toán học máy khác nhau.
Trong trường hợp này, chúng ta tạo một tập dữ liệu với sáu đặc trưng, ba lớp và 800 mẫu bằng hàm make_classification().
from sklearn.datasets import make_classification
X, y = make_classification(
n_features=6,
n_classes=3,
n_samples=800,
n_informative=2,
random_state=1,
n_clusters_per_class=1,
)Chúng ta sẽ dùng hàm scatter() của matplotlib.pyplot để trực quan hóa tập dữ liệu.
import matplotlib.pyplot as plt
plt.scatter(X[:, 0], X[:, 1], c=y, marker="*");Như có thể quan sát, có ba loại nhãn đích và chúng ta sẽ huấn luyện một mô hình phân loại đa lớp.
Trước khi bắt đầu quá trình huấn luyện, chúng ta cần chia tập dữ liệu thành huấn luyện và kiểm tra để đánh giá mô hình.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.33, random_state=125
)Xây dựng một Gaussian Naive Bayes tổng quát và huấn luyện nó trên tập huấn luyện. Sau đó, đưa một mẫu kiểm tra ngẫu nhiên vào mô hình để nhận giá trị dự đoán.
from sklearn.naive_bayes import GaussianNB
# Build a Gaussian Classifier
model = GaussianNB()
# Model training
model.fit(X_train, y_train)
# Predict Output
predicted = model.predict([X_test[6]])
print("Actual Value:", y_test[6])
print("Predicted Value:", predicted[0])Giá trị thực tế và giá trị dự đoán đều giống nhau.
Actual Value: 0
Predicted Value: 0Chúng ta sẽ đánh giá mô hình trên tập kiểm tra chưa thấy. Trước hết, chúng ta dự đoán các giá trị cho tập kiểm tra và dùng chúng để tính độ chính xác và điểm F1.
from sklearn.metrics import (
accuracy_score,
confusion_matrix,
ConfusionMatrixDisplay,
f1_score,
)
y_pred = model.predict(X_test)
accuray = accuracy_score(y_pred, y_test)
f1 = f1_score(y_pred, y_test, average="weighted")
print("Accuracy:", accuray)
print("F1 Score:", f1)Mô hình của chúng ta hoạt động khá tốt với các siêu tham số mặc định.
Accuracy: 0.8484848484848485
F1 Score: 0.8491119695890328Để trực quan hóa ma trận nhầm lẫn, chúng ta sẽ dùng confusion_matrix để tính số dương tính thật và âm tính thật và ConfusionMatrixDisplay để hiển thị ma trận nhầm lẫn kèm nhãn.
labels = [0,1,2]
cm = confusion_matrix(y_test, y_pred, labels=labels)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=labels)
disp.plot();Mô hình của chúng ta thể hiện khá tốt, và chúng ta có thể cải thiện hiệu năng bằng cách chuẩn hóa, tiền xử lý, cross-validation và tối ưu siêu tham số.
Hãy huấn luyện Bộ phân loại Naive Bayes trên tập dữ liệu thực. Chúng ta sẽ lặp lại hầu hết các bước, ngoại trừ tiền xử lý và khám phá dữ liệu.
Trong ví dụ này, chúng ta sẽ tải Dữ liệu khoản vay từ DataLab bằng hàm read_csv của pandas.
import pandas as pd
df = pd.read_csv('loan_data.csv')
df.head()Để hiểu thêm về tập dữ liệu, chúng ta sẽ dùng .info().
Tập dữ liệu gồm 14 cột và 9578 hàng.
Ngoài purpose, các cột còn lại là số thực hoặc số nguyên.
Cột đích của chúng ta là not.fully.paid.
df.info()RangeIndex: 9578 entries, 0 to 9577
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 credit.policy 9578 non-null int64
1 purpose 9578 non-null object
2 int.rate 9578 non-null float64
3 installment 9578 non-null float64
4 log.annual.inc 9578 non-null float64
5 dti 9578 non-null float64
6 fico 9578 non-null int64
7 days.with.cr.line 9578 non-null float64
8 revol.bal 9578 non-null int64
9 revol.util 9578 non-null float64
10 inq.last.6mths 9578 non-null int64
11 delinq.2yrs 9578 non-null int64
12 pub.rec 9578 non-null int64
13 not.fully.paid 9578 non-null int64
dtypes: float64(6), int64(7), object(1)
memory usage: 1.0+ MBTrong ví dụ này, chúng ta sẽ phát triển một mô hình để dự đoán các khách hàng chưa thanh toán đầy đủ khoản vay. Hãy khám phá cột mục đích và cột đích bằng countplot của seaborn.
import seaborn as sns
import matplotlib.pyplot as plt
sns.countplot(data=df,x='purpose',hue='not.fully.paid')
plt.xticks(rotation=45, ha='right');Tập dữ liệu của chúng ta bị mất cân bằng, điều này sẽ ảnh hưởng đến hiệu suất mô hình. Bạn có thể xem hướng dẫn Lấy mẫu lại một tập dữ liệu mất cân bằng để thực hành xử lý các tập dữ liệu mất cân bằng.
Bây giờ chúng ta sẽ chuyển cột purpose từ phân loại sang số nguyên bằng hàm get_dummies() của pandas.
pre_df = pd.get_dummies(df,columns=['purpose'],drop_first=True)
pre_df.head()Sau đó, chúng ta sẽ xác định biến đặc trưng (X) và biến đích (y), và chia tập dữ liệu thành các tập huấn luyện và kiểm tra.
from sklearn.model_selection import train_test_split
X = pre_df.drop('not.fully.paid', axis=1)
y = pre_df['not.fully.paid']
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.33, random_state=125
)Xây dựng và huấn luyện mô hình khá đơn giản. Chúng ta sẽ huấn luyện mô hình trên tập huấn luyện với các siêu tham số mặc định.
from sklearn.naive_bayes import GaussianNB
model = GaussianNB()
model.fit(X_train, y_train);Chúng ta sẽ dùng độ chính xác và điểm f1 để đánh giá hiệu năng mô hình, và có vẻ như thuật toán Gaussian Naive Bayes hoạt động khá tốt.
from sklearn.metrics import (
accuracy_score,
confusion_matrix,
ConfusionMatrixDisplay,
f1_score,
classification_report,
)
y_pred = model.predict(X_test)
accuray = accuracy_score(y_pred, y_test)
f1 = f1_score(y_pred, y_test, average="weighted")
print("Accuracy:", accuray)
print("F1 Score:", f1)Accuracy: 0.8206263840556786
F1 Score: 0.8686606980013266Do dữ liệu bị mất cân bằng, chúng ta có thể thấy rằng ma trận nhầm lẫn cho thấy một câu chuyện khác. Ở lớp đích thiểu số: not fully paid, chúng ta có nhiều mẫu bị gán nhãn sai hơn.
labels = ["Fully Paid", "Not fully Paid"]
cm = confusion_matrix(y_test, y_pred)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=labels)
disp.plot();Nếu bạn gặp vấn đề trong quá trình huấn luyện hoặc đánh giá mô hình, bạn có thể xem sổ làm việc DataLab về Hướng dẫn Phân loại Naive Bayes dùng Scikit-learn. Sổ này đi kèm tập dữ liệu, mã nguồn và kết quả.
Giả sử không có bộ dữ liệu (tuple) nào cho khoản vay rủi ro trong tập dữ liệu; trong trường hợp này, xác suất hậu nghiệm sẽ bằng 0 và mô hình không thể đưa ra dự đoán. Vấn đề này được gọi là Xác suất bằng 0 vì số lần xuất hiện của lớp cụ thể là bằng 0.
Giải pháp cho vấn đề như vậy là hiệu chỉnh Laplace (Laplacian correction) hay phép biến đổi Laplace. Hiệu chỉnh Laplace là một trong các kỹ thuật làm trơn. Ở đây, bạn có thể giả định rằng tập dữ liệu đủ lớn để việc thêm một hàng cho mỗi lớp sẽ không làm thay đổi đáng kể xác suất ước lượng. Điều này sẽ khắc phục vấn đề giá trị xác suất bằng 0.
Ví dụ: Giả sử với lớp khoản vay rủi ro, có 1000 bộ huấn luyện trong cơ sở dữ liệu. Trong cơ sở dữ liệu này, cột thu nhập có 0 bộ cho thu nhập thấp, 990 bộ cho thu nhập trung bình và 10 bộ cho thu nhập cao. Xác suất của các sự kiện này, nếu không áp dụng hiệu chỉnh Laplace, là 0, 0.990 (từ 990/1000) và 0.010 (từ 10/1000)
Giờ hãy áp dụng hiệu chỉnh Laplace lên tập dữ liệu đã cho. Hãy thêm 1 bộ nữa cho mỗi cặp giá trị thu nhập. Khi đó xác suất của các sự kiện:
Chúc mừng bạn đã đi đến cuối hướng dẫn này!
Trong hướng dẫn này, bạn đã học về thuật toán Naive Bayes, cách thức hoạt động, giả định của Naive Bayes, các vấn đề, cách triển khai, ưu và nhược điểm. Trên hành trình đó, bạn cũng đã học cách xây dựng và đánh giá mô hình trong scikit-learn cho các lớp nhị phân và đa thức.
Naive Bayes là thuật toán đơn giản và mạnh mẽ. Bất chấp những tiến bộ đáng kể trong học máy vài năm qua, nó vẫn chứng tỏ giá trị của mình. Nó đã được triển khai thành công trong nhiều ứng dụng, từ phân tích văn bản đến các bộ máy gợi ý.
Nếu bạn muốn tìm hiểu thêm về scikit-learn trong Python, hãy tham gia khóa học Học có giám sát với scikit-learn và xem Hướng dẫn Scikit-Learn: Phân tích Bóng chày Phần 1.
Khóa học Python
Courses
Courses
Courses