Cursus
Introductie tot Python
4 Hr
6.9M
Naive Bayes is een statistische classificatietechniek gebaseerd op de stelling van Bayes. Het is een van de eenvoudigste algoritmes voor supervised learning. De Naive Bayes-classifier is snel, nauwkeurig en betrouwbaar. Op grote datasets behalen Naive Bayes-classifiers hoge accuratesse en snelheid.
De Naive Bayes-classifier gaat ervan uit dat het effect van een bepaalde feature binnen een klasse onafhankelijk is van andere features. Bijvoorbeeld: of een kredietaanvrager wenselijk is, hangt af van zijn/haar inkomen, eerdere leningen en transactiegeschiedenis, leeftijd en locatie. Ook al zijn deze features onderling afhankelijk, ze worden toch als onafhankelijk beschouwd. Deze aanname vereenvoudigt de berekeningen, en daarom heet het naive. Deze aanname staat bekend als class conditionele onafhankelijkheid.
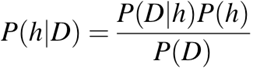
P(h): de kans dat hypothese h waar is (ongeacht de data). Dit heet de prior-kans van h.
P(D): de kans op de data (ongeacht de hypothese). Dit heet de prior-kans.
P(h|D): de kans op hypothese h gegeven de data D. Dit heet de posterior-kans.
P(D|h): de kans op data d gegeven dat hypothese h waar is. Dit heet de posterior-kans.
Wanneer je gaat classificeren, is de eerste stap het probleem begrijpen en mogelijke features en label identificeren. Features zijn kenmerken of attributen die het resultaat van het label beïnvloeden. Bij een kredietverstrekking identificeren bankmanagers bijvoorbeeld het beroep, inkomen, leeftijd, locatie, eerdere leningen, transactiehistorie en kredietscore van de klant. Dit zijn de features die het model helpen om klanten te classificeren.
Classificatie kent twee fasen: een leersfase en een evaluatiefase. In de leersfase traint de classifier zijn model op een gegeven dataset, en in de evaluatiefase test hij de prestaties. De prestaties worden beoordeeld aan de hand van verschillende maatstaven zoals accuratesse, fout, precisie en recall.
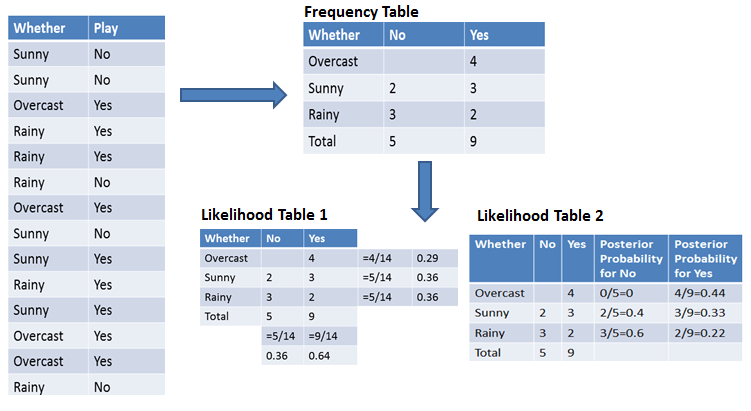
Laten we het werkingsprincipe van Naive Bayes verduidelijken met een voorbeeld. Stel dat je weercondities en het al dan niet spelen van een sport observeert. Je wilt de kans berekenen dat er gespeeld wordt. Op basis van de weersomstandigheden moet je nu classificeren of spelers wel of niet zullen spelen.
De Naive Bayes-classifier berekent de kans op een gebeurtenis in de volgende stappen:
Om het berekenen van prior- en posterior-kansen te vereenvoudigen, kun je twee tabellen gebruiken: frequentie- en likelihoodtabellen. Beide helpen je bij het bepalen van de prior- en posterior-kans. De frequentietabel bevat het aantal voorkomens van labels voor alle features. Er zijn twee likelihoodtabellen. Likelihoodtabel 1 toont de prior-kansen van labels en Likelihoodtabel 2 toont de posterior-kans.
Stel nu dat je de kans wilt berekenen dat er gespeeld wordt als het bewolkt is.
Kans op spelen:
P(Yes | Overcast) = P(Overcast | Yes) × P(Yes) / P(Overcast)
Stap 1: Bereken prior-kansen
Stap 2: Bereken posterior-kans
Stap 3: Pas de formule van Bayes toe
Hier vullen we de prior- en posterior-kansen in de eerste vergelijking in.
P(Yes | Overcast) = 0,44 × 0,64 / 0,29 = 0,98
Op dezelfde manier kun je de kans berekenen dat er niet gespeeld wordt:
Kans op niet spelen:
P(No | Overcast) = P(Overcast | No) × P(No) / P(Overcast)
Stap 1: Bereken prior-kansen
Stap 2: Bereken likelihood
Stap 3: Pas de formule van Bayes toe
We vullen hier de prior- en likelihood-kansen in de vergelijking in om de posterior-kans te krijgen.
P(No | Overcast) = 0 × 0,36 / 0,29 = 0
De kans op de klasse 'Yes' is hoger. Je kunt dus bepalen dat als het bewolkt is, de spelers zullen spelen.
Stel nu dat je de kans wilt berekenen dat er gespeeld wordt als het bewolkt is en de temperatuur mild is.
Kans op spelen:
P(Play = Yes | Weather = Overcast, Temp = Mild) = P(Weather = Overcast, Temp = Mild | Play = Yes) × P(Play = Yes)
Met de onafhankelijkheidsaanname van Naive Bayes:
P(Weather = Overcast, Temp = Mild | Play = Yes) = P(Overcast | Yes) × P(Mild | Yes)
Stap 1: Bereken prior-kans
Stap 2: Bereken likelihoods
Stap 3: Bereken gecombineerde likelihood
P(Weather = Overcast, Temp = Mild | Play = Yes) = 0,44 × 0,44 = 0,1936
Stap 4: Pas de formule van Bayes toe
P(Play = Yes | Weather = Overcast, Temp = Mild) = 0,1936 × 0,64 = 0,124
Op dezelfde manier kun je de kans berekenen dat er niet gespeeld wordt:
Kans op niet spelen:
P(Play = No | Weather = Overcast, Temp = Mild) = P(Weather = Overcast, Temp = Mild | Play = No) × P(Play = No)
Met de onafhankelijkheidsaanname van Naive Bayes:
P(Weather = Overcast, Temp = Mild | Play = No) = P(Overcast | No) × P(Mild | No)
Stap 1: Bereken prior-kans
Stap 2: Bereken likelihoods
Stap 3: Bereken gecombineerde likelihood
P(Weather = Overcast, Temp = Mild | Play = No) = 0 × 0,4 = 0
Stap 4: Pas de formule van Bayes toe
P(Play = No | Weather = Overcast, Temp = Mild) = 0 × 0,36 = 0
De kans op de klasse 'Yes' is hoger (0,124 vs 0), dus als het bewolkt is en de temperatuur mild, zullen de spelers spelen.
In het eerste voorbeeld genereren we synthetische data met scikit-learn en trainen en evalueren we het Gaussian Naive Bayes-algoritme.
Scikit-learn biedt een machinelearning-ecosysteem waarmee we een dataset kunnen genereren en verschillende machinelearning-algoritmen kunnen evalueren.
In ons geval maken we een dataset met zes features, drie klassen en 800 samples met de functie make_classification().
from sklearn.datasets import make_classification
X, y = make_classification(
n_features=6,
n_classes=3,
n_samples=800,
n_informative=2,
random_state=1,
n_clusters_per_class=1,
)We gebruiken de functie scatter() van matplotlib.pyplot om de dataset te visualiseren.
import matplotlib.pyplot as plt
plt.scatter(X[:, 0], X[:, 1], c=y, marker="*");Zoals je ziet zijn er drie soorten targetlabels, en trainen we een multiclass-classificatiemodel.
Voordat we met trainen beginnen, splitsen we de dataset in training en testing voor de modelevaluatie.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.33, random_state=125
)Bouw een generiek Gaussian Naive Bayes-model en train het op de trainingsset. Geef daarna een willekeurig testvoorbeeld aan het model om een voorspelde waarde te krijgen.
from sklearn.naive_bayes import GaussianNB
# Build a Gaussian Classifier
model = GaussianNB()
# Model training
model.fit(X_train, y_train)
# Predict Output
predicted = model.predict([X_test[6]])
print("Actual Value:", y_test[6])
print("Predicted Value:", predicted[0])Zowel de werkelijke als de voorspelde waarde zijn hetzelfde.
Actual Value: 0
Predicted Value: 0We evalueren het model op een onzichtbare testset. Eerst voorspellen we de waarden voor de testset en gebruiken die om accuratesse en F1-score te berekenen.
from sklearn.metrics import (
accuracy_score,
confusion_matrix,
ConfusionMatrixDisplay,
f1_score,
)
y_pred = model.predict(X_test)
accuray = accuracy_score(y_pred, y_test)
f1 = f1_score(y_pred, y_test, average="weighted")
print("Accuracy:", accuray)
print("F1 Score:", f1)Ons model presteerde behoorlijk goed met de standaardhyperparameters.
Accuracy: 0.8484848484848485
F1 Score: 0.8491119695890328Om de confusion matrix te visualiseren gebruiken we confusion_matrix om de true positives en true negatives te berekenen en ConfusionMatrixDisplay om de confusion matrix met labels te tonen.
labels = [0,1,2]
cm = confusion_matrix(y_test, y_pred, labels=labels)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=labels)
disp.plot();Ons model heeft het best goed gedaan, en we kunnen de prestaties verder verbeteren met schalen, preprocessing, kruisvalidaties en hyperparameteroptimalisatie.
Laten we de Naive Bayes-classifier trainen op een echte dataset. We herhalen de meeste stappen, behalve preprocessing en data-exploratie.
In dit voorbeeld laden we Loan Data uit DataLab met de pandas-functie read_csv.
import pandas as pd
df = pd.read_csv('loan_data.csv')
df.head()Om de dataset beter te begrijpen gebruiken we .info().
De dataset bestaat uit 14 kolommen en 9578 rijen.
Afgezien van purpose zijn de kolommen floats of integers.
Onze targetkolom is not.fully.paid.
df.info()RangeIndex: 9578 entries, 0 to 9577
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 credit.policy 9578 non-null int64
1 purpose 9578 non-null object
2 int.rate 9578 non-null float64
3 installment 9578 non-null float64
4 log.annual.inc 9578 non-null float64
5 dti 9578 non-null float64
6 fico 9578 non-null int64
7 days.with.cr.line 9578 non-null float64
8 revol.bal 9578 non-null int64
9 revol.util 9578 non-null float64
10 inq.last.6mths 9578 non-null int64
11 delinq.2yrs 9578 non-null int64
12 pub.rec 9578 non-null int64
13 not.fully.paid 9578 non-null int64
dtypes: float64(6), int64(7), object(1)
memory usage: 1.0+ MBIn dit voorbeeld ontwikkelen we een model om klanten te voorspellen die hun lening niet volledig hebben afgelost. Laten we de kolommen purpose en target verkennen met de countplot van seaborn.
import seaborn as sns
import matplotlib.pyplot as plt
sns.countplot(data=df,x='purpose',hue='not.fully.paid')
plt.xticks(rotation=45, ha='right');Onze dataset is uit balans, wat de modelprestaties zal beïnvloeden. Bekijk de tutorial Resample an Imbalanced Dataset voor hands-on ervaring met onevenwichtige datasets.
We zetten nu de kolom purpose om van categorisch naar integer met de pandas-functie get_dummies().
pre_df = pd.get_dummies(df,columns=['purpose'],drop_first=True)
pre_df.head()Daarna definiëren we feature- (X) en target- (y) variabelen en splitsen we de dataset in training en testing.
from sklearn.model_selection import train_test_split
X = pre_df.drop('not.fully.paid', axis=1)
y = pre_df['not.fully.paid']
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.33, random_state=125
)Een model bouwen en trainen is vrij eenvoudig. We trainen een model op de trainingsset met standaardhyperparameters.
from sklearn.naive_bayes import GaussianNB
model = GaussianNB()
model.fit(X_train, y_train);We gebruiken accuratesse en F1-score om de modelprestaties te bepalen, en het lijkt erop dat het Gaussian Naive Bayes-algoritme het behoorlijk goed doet.
from sklearn.metrics import (
accuracy_score,
confusion_matrix,
ConfusionMatrixDisplay,
f1_score,
classification_report,
)
y_pred = model.predict(X_test)
accuray = accuracy_score(y_pred, y_test)
f1 = f1_score(y_pred, y_test, average="weighted")
print("Accuracy:", accuray)
print("F1 Score:", f1)Accuracy: 0.8206263840556786
F1 Score: 0.8686606980013266Door het onevenwicht in de data vertelt de confusion matrix een ander verhaal. Bij de minderheidsklasse not fully paid hebben we meer verkeerd gelabelde voorbeelden.
labels = ["Fully Paid", "Not fully Paid"]
cm = confusion_matrix(y_test, y_pred)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=labels)
disp.plot();Loop je tegen problemen aan tijdens het trainen of evalueren, bekijk dan de Naive Bayes Classification Tutorial met scikit-learn in het DataLab-werkboek. Dat bevat een dataset, broncode en outputs.
Stel dat er in de dataset geen enkele rij is voor een risicovolle lening; in dat geval wordt de posterior-kans nul en kan het model geen voorspelling doen. Dit probleem staat bekend als het nul-kansprobleem, omdat het voorkomen van die specifieke klasse nul is.
De oplossing hiervoor is de Laplace-correctie of Laplace-smoothing. Laplace-correctie is een van de smoothingtechnieken. Je gaat er hierbij van uit dat de dataset groot genoeg is dat het toevoegen van één rij voor elke klasse de geschatte kansen niet wezenlijk verandert. Zo voorkom je kanswaarden van nul.
Voorbeeld: stel dat er voor de klasse ‘lening risicovol’ 1000 trainingsrijen in de database staan. In deze database heeft de inkomenskolom 0 rijen met laag inkomen, 990 rijen met middeninkomen en 10 rijen met hoog inkomen. De kansen op deze gebeurtenissen, zonder Laplace-correctie, zijn respectievelijk 0, 0,990 (uit 990/1000) en 0,010 (uit 10/1000)
Pas nu de Laplace-correctie toe op de dataset. Laten we voor elke inkomenswaarde 1 rij toevoegen. De kansen op deze gebeurtenissen:
Gefeliciteerd, je bent aan het einde van deze tutorial gekomen!
In deze tutorial heb je geleerd over het Naive Bayes-algoritme, hoe het werkt, de aanname van Naive Bayes, aandachtspunten, implementatie, voordelen en nadelen. Onderweg heb je ook modelbouw en -evaluatie in scikit-learn geleerd voor binaire en multiklassen.
Naive Bayes is een van de eenvoudigste en krachtigste algoritmes. Ondanks de grote vooruitgang in machine learning van de afgelopen jaren heeft het zijn waarde bewezen. Het wordt met succes ingezet in veel toepassingen, van tekstanalyse tot aanbevelingssystemen.
Wil je meer leren over scikit-learn in Python? Volg dan onze cursus Supervised Learning with scikit-learn en bekijk onze Scikit-Learn Tutorial: Baseball Analytics Pt 1.
Pythoncursussen
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
