Kurs
Python’a Giriş
4 sa
6.9M
Naive Bayes, Bayes Teoremine dayalı istatistiksel bir sınıflandırma tekniğidir. En basit denetimli öğrenme algoritmalarından biridir. Naive Bayes sınıflandırıcı hızlı, doğru ve güvenilir bir algoritmadır. Büyük veri kümelerinde yüksek doğruluk ve hız sunar.
Naive Bayes sınıflandırıcı, bir sınıftaki belirli bir özelliğin etkisinin diğer özelliklerden bağımsız olduğunu varsayar. Örneğin, bir kredi başvuru sahibinin tercih edilir olup olmadığı; gelirine, önceki kredi ve işlem geçmişine, yaşına ve konumuna bağlıdır. Bu özellikler birbiriyle ilişkili olsa bile, yine de bağımsız kabul edilir. Bu varsayım hesaplamayı basitleştirir ve bu yüzden “naive” olarak adlandırılır. Bu varsayıma sınıfa koşullu bağımsızlık denir.
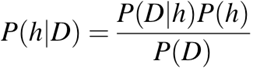
P(h): veriden bağımsız olarak h hipotezinin doğru olma olasılığı. Buna h’nin önsel olasılığı denir.
P(D): hipotezden bağımsız olarak verinin olasılığı. Buna önsel olasılık denir.
P(h|D): D verisi verildiğinde h hipotezinin olasılığı. Buna artgösterim olasılığı denir.
P(D|h): h hipotezinin doğru olduğu varsayımı altında d verisinin olasılığı. Bu da artgösterim olasılığı olarak bilinir.
Ne zaman bir sınıflandırma yapsanız, ilk adım problemi anlamak ve potansiyel özellikleri ve etiketi belirlemektir. Özellikler, etiketin sonucunu etkileyen nitelik ya da özelliklerdir. Örneğin, kredi dağıtımı durumunda, banka yöneticileri müşterinin mesleğini, gelirini, yaşını, konumunu, önceki kredi geçmişini, işlem geçmişini ve kredi notunu belirler. Bu nitelikler, modelin müşterileri sınıflandırmasına yardımcı olan özellikler olarak bilinir.
Sınıflandırmanın iki aşaması vardır: öğrenme ve değerlendirme. Öğrenme aşamasında sınıflandırıcı, verilen veri kümesi üzerinde modelini eğitir; değerlendirme aşamasında ise sınıflandırıcının performansını test eder. Performans; doğruluk, hata, kesinlik (precision) ve duyarlılık (recall) gibi çeşitli ölçütlere göre değerlendirilir.
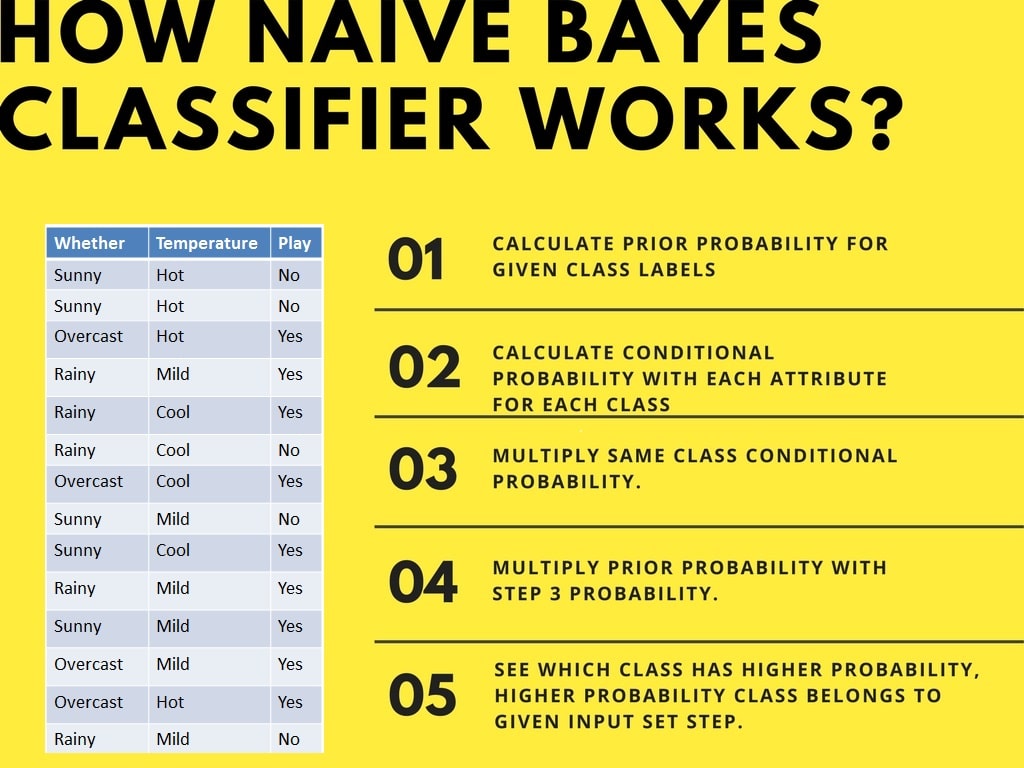
Naive Bayes’in çalışma şeklini bir örnek üzerinden anlayalım. Hava koşulları ve spor yapma örneği verildiğinde, spor yapma olasılığını hesaplamanız gerekir. Şimdi, hava durumuna göre oyuncuların oynayıp oynamayacağını sınıflandırmanız gerekiyor.
Naive Bayes sınıflandırıcı bir olayın olasılığını şu adımlarla hesaplar:
Önsel ve artgösterim olasılık hesaplarını basitleştirmek için frekans ve olasılık tabloları olmak üzere iki tablo kullanabilirsiniz. Her iki tablo da önsel ve artgösterim olasılıklarını hesaplamanıza yardımcı olur. Frekans tablosu, tüm özellikler için etiketlerin görülme sıklığını içerir. İki olasılık tablosu vardır. Olasılık Tablosu 1, etiketlerin önsel olasılıklarını; Olasılık Tablosu 2 ise artgösterim olasılığını gösterir.
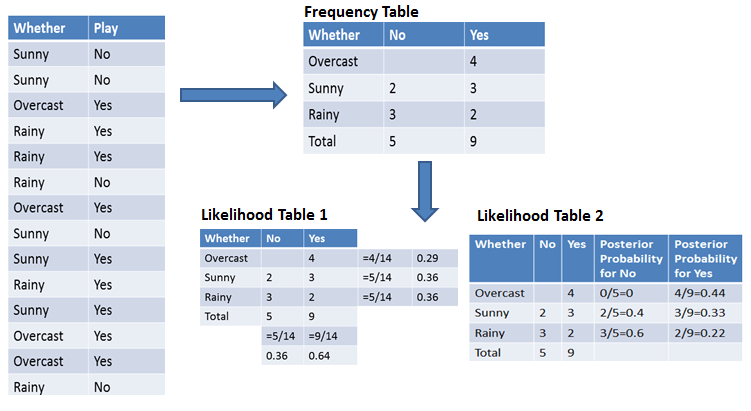
Şimdi, hava bulutluyken oynama olasılığını hesaplamak istediğinizi varsayalım.
Oynama olasılığı:
P(Yes | Overcast) = P(Overcast | Yes) × P(Yes) / P(Overcast)
Adım 1: Önsel olasılıkları hesaplayın
Adım 2: Artgösterim olasılığını hesaplayın
Adım 3: Bayes Formülünü uygulayın
Burada, önsel ve artgösterim olasılıklarını ilk denkleme yerleştiriyoruz.
P(Yes | Overcast) = 0.44 × 0.64 / 0.29 = 0.98
Benzer şekilde, oynamama olasılığını da hesaplayabilirsiniz:
Oynamama olasılığı:
P(No | Overcast) = P(Overcast | No) × P(No) / P(Overcast)
Adım 1: Önsel olasılıkları hesaplayın
Adım 2: Koşullu olasılığı (likelihood) hesaplayın
Adım 3: Bayes Formülünü uygulayın
Burada, önsel ve koşullu olasılıkları denkleme koyup artgösterim olasılığını elde ediyoruz.
P(No | Overcast) = 0 × 0.36 / 0.29 = 0
'Yes' sınıfının olasılığı daha yüksek. Dolayısıyla hava bulutluysa, oyuncuların sporu oynayacağını söyleyebilirsiniz.
Şimdi, hava bulutluyken ve sıcaklık ılıman olduğunda oynama olasılığını hesaplamak istediğinizi varsayalım.
Oynama olasılığı:
P(Play = Yes | Weather = Overcast, Temp = Mild) = P(Weather = Overcast, Temp = Mild | Play = Yes) × P(Play = Yes)
Naive Bayes bağımsızlık varsayımını kullanarak:
P(Weather = Overcast, Temp = Mild | Play = Yes) = P(Overcast | Yes) × P(Mild | Yes)
Adım 1: Önsel olasılığı hesaplayın
Adım 2: Koşullu olasılıkları hesaplayın
Adım 3: Birleşik koşullu olasılığı hesaplayın
P(Weather = Overcast, Temp = Mild | Play = Yes) = 0.44 × 0.44 = 0.1936
Adım 4: Bayes Formülünü uygulayın
P(Play = Yes | Weather = Overcast, Temp = Mild) = 0.1936 × 0.64 = 0.124
Benzer şekilde, oynamama olasılığını da hesaplayabilirsiniz:
Oynamama olasılığı:
P(Play = No | Weather = Overcast, Temp = Mild) = P(Weather = Overcast, Temp = Mild | Play = No) × P(Play = No)
Naive Bayes bağımsızlık varsayımını kullanarak:
P(Weather = Overcast, Temp = Mild | Play = No) = P(Overcast | No) × P(Mild | No)
Adım 1: Önsel olasılığı hesaplayın
Adım 2: Koşullu olasılıkları hesaplayın
Adım 3: Birleşik koşullu olasılığı hesaplayın
P(Weather = Overcast, Temp = Mild | Play = No) = 0 × 0.4 = 0
Adım 4: Bayes Formülünü uygulayın
P(Play = No | Weather = Overcast, Temp = Mild) = 0 × 0.36 = 0
'Yes' sınıfının olasılığı daha yüksektir (0.124’e karşı 0), bu nedenle hava bulutlu ve sıcaklık ılıman olduğunda oyuncular sporu oynayacaktır.
İlk örnekte, scikit-learn kullanarak sentetik veri üretecek ve Gaussian Naive Bayes algoritmasını eğitip değerlendireceğiz.
Scikit-learn, veri kümesi oluşturup çeşitli makine öğrenimi algoritmalarını değerlendirebileceğimiz bir makine öğrenimi ekosistemi sağlar.
Bizim durumumuzda, make_classification() fonksiyonunu kullanarak altı özellikli, üç sınıflı ve 800 örnekten oluşan bir veri kümesi oluşturuyoruz.
from sklearn.datasets import make_classification
X, y = make_classification(
n_features=6,
n_classes=3,
n_samples=800,
n_informative=2,
random_state=1,
n_clusters_per_class=1,
)Veri kümesini görselleştirmek için matplotlib.pyplot’un scatter() fonksiyonunu kullanacağız.
import matplotlib.pyplot as plt
plt.scatter(X[:, 0], X[:, 1], c=y, marker="*");Gözlemlenebileceği gibi üç tür hedef etiket var ve çok sınıflı bir sınıflandırma modeli eğiteceğiz.
Eğitim sürecine başlamadan önce, model değerlendirmesi için veri kümesini eğitim ve test olarak ayırmamız gerekir.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.33, random_state=125
)Genel bir Gaussian Naive Bayes modeli oluşturup eğitim veri kümesi üzerinde eğitin. Ardından, modele rastgele bir test örneği vererek tahmin edilen bir değer elde edin.
from sklearn.naive_bayes import GaussianNB
# Build a Gaussian Classifier
model = GaussianNB()
# Model training
model.fit(X_train, y_train)
# Predict Output
predicted = model.predict([X_test[6]])
print("Actual Value:", y_test[6])
print("Predicted Value:", predicted[0])Gerçek ve tahmin edilen değerler aynıdır.
Actual Value: 0
Predicted Value: 0Modeli, görülmemiş bir test veri kümesi üzerinde değerlendireceğiz. Önce test veri kümesi için değerleri tahmin edecek, ardından bunları kullanarak doğruluk ve F1 puanını hesaplayacağız.
from sklearn.metrics import (
accuracy_score,
confusion_matrix,
ConfusionMatrixDisplay,
f1_score,
)
y_pred = model.predict(X_test)
accuray = accuracy_score(y_pred, y_test)
f1 = f1_score(y_pred, y_test, average="weighted")
print("Accuracy:", accuray)
print("F1 Score:", f1)Modelimiz varsayılan hiperparametrelerle oldukça iyi performans gösterdi.
Accuracy: 0.8484848484848485
F1 Score: 0.8491119695890328Karmaşıklık matrisini görselleştirmek için, gerçek-pozitif ve gerçek-negatifleri hesaplamak üzere confusion_matrix’i ve etiketlerle birlikte matrisi göstermek için ConfusionMatrixDisplay kullanacağız.
labels = [0,1,2]
cm = confusion_matrix(y_test, y_pred, labels=labels)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=labels)
disp.plot();Modelimiz oldukça iyi performans gösterdi ve ölçekleme, ön işleme, çapraz doğrulamalar ve hiperparametre optimizasyonuyla performansı daha da iyileştirebiliriz.
Naive Bayes Sınıflandırıcıyı gerçek bir veri kümesi üzerinde eğitelim. Ön işleme ve veri keşfi dışında görevlerin çoğunu tekrarlayacağız.
Bu örnekte, pandas’ın read_csv fonksiyonunu kullanarak DataLab’den Kredi Verisini yükleyeceğiz.
import pandas as pd
df = pd.read_csv('loan_data.csv')
df.head()Veri kümesi hakkında daha fazla bilgi edinmek için .info() kullanacağız.
Veri kümesi 14 sütun ve 9578 satırdan oluşur.
purpose dışında, sütunlar ya float ya da integer’dır.
Hedef sütunumuz not.fully.paid.
df.info()RangeIndex: 9578 entries, 0 to 9577
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 credit.policy 9578 non-null int64
1 purpose 9578 non-null object
2 int.rate 9578 non-null float64
3 installment 9578 non-null float64
4 log.annual.inc 9578 non-null float64
5 dti 9578 non-null float64
6 fico 9578 non-null int64
7 days.with.cr.line 9578 non-null float64
8 revol.bal 9578 non-null int64
9 revol.util 9578 non-null float64
10 inq.last.6mths 9578 non-null int64
11 delinq.2yrs 9578 non-null int64
12 pub.rec 9578 non-null int64
13 not.fully.paid 9578 non-null int64
dtypes: float64(6), int64(7), object(1)
memory usage: 1.0+ MBBu örnekte, krediyi tamamen ödememiş müşterileri tahmin edecek bir model geliştireceğiz. Hedef ve amaç sütunlarını seaborn’un countplot’u ile inceleyelim.
import seaborn as sns
import matplotlib.pyplot as plt
sns.countplot(data=df,x='purpose',hue='not.fully.paid')
plt.xticks(rotation=45, ha='right');Veri kümemiz dengesiz ve bu durum modelin performansını etkileyecektir. Dengesiz veri kümeleriyle pratik yapmak için Dengesiz Bir Veri Kümesini Yeniden Örnekleme eğitimine göz atabilirsiniz.
purpose sütununu pandas get_dummies() fonksiyonunu kullanarak kategorikten tamsayıya dönüştüreceğiz.
pre_df = pd.get_dummies(df,columns=['purpose'],drop_first=True)
pre_df.head()Ardından, özellik (X) ve hedef (y) değişkenlerini tanımlayıp veri kümesini eğitim ve test olarak ayıracağız.
from sklearn.model_selection import train_test_split
X = pre_df.drop('not.fully.paid', axis=1)
y = pre_df['not.fully.paid']
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.33, random_state=125
)Model kurma ve eğitim oldukça basittir. Varsayılan hiperparametrelerle eğitim veri kümesi üzerinde bir model eğiteceğiz.
from sklearn.naive_bayes import GaussianNB
model = GaussianNB()
model.fit(X_train, y_train);Model performansını belirlemek için doğruluk ve f1 skoru kullanacağız ve Gaussian Naive Bayes algoritmasının oldukça iyi performans gösterdiği görülüyor.
from sklearn.metrics import (
accuracy_score,
confusion_matrix,
ConfusionMatrixDisplay,
f1_score,
classification_report,
)
y_pred = model.predict(X_test)
accuray = accuracy_score(y_pred, y_test)
f1 = f1_score(y_pred, y_test, average="weighted")
print("Accuracy:", accuray)
print("F1 Score:", f1)Accuracy: 0.8206263840556786
F1 Score: 0.8686606980013266Verinin dengesiz doğası nedeniyle, karmaşıklık matrisi farklı bir tablo çizer. Azınlık hedefi olan not fully paid üzerinde daha fazla yanlış etiketleme vardır.
labels = ["Fully Paid", "Not fully Paid"]
cm = confusion_matrix(y_test, y_pred)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=labels)
disp.plot();Eğitim veya model değerlendirme sırasında sorun yaşıyorsanız, Scikit-learn kullanarak Naive Bayes Sınıflandırma Eğitimi için DataLab çalışma defterine göz atabilirsiniz. Veri kümesi, kaynak kodu ve çıktılarla birlikte gelir.
Veri kümesinde riskli kredi için hiç kayıt olmadığını varsayalım; bu senaryoda artgösterim olasılığı sıfır olur ve model tahmin yapamaz. Bu probleme, belirli bir sınıfın görülme sıklığının sıfır olmasından ötürü Sıfır Olasılık denir.
Bu tür bir sorun için çözüm, Laplace düzeltmesi veya Laplace Dönüşümüdür. Laplace düzeltmesi, yumuşatma tekniklerinden biridir. Burada, veri kümesinin yeterince büyük olduğunu ve her sınıfa bir satır eklemenin tahmini olasılığı etkilemeyeceğini varsayabilirsiniz. Bu, olasılık değerlerinin sıfıra inmesi sorununu ortadan kaldırır.
Örneğin: Riskli kredi sınıfı için veritabanında 1000 eğitim kaydı olduğunu varsayalım. Bu veritabanında gelir sütununda düşük gelir için 0 kayıt, orta gelir için 990 kayıt ve yüksek gelir için 10 kayıt vardır. Laplace düzeltmesi olmadan bu olayların olasılıkları sırasıyla 0, 0.990 (990/1000’den) ve 0.010’dur (10/1000’den)
Şimdi, verilen veri kümesine Laplace düzeltmesini uygulayın. Her gelir-değer çifti için 1 kayıt daha ekleyelim. Bu olayların olasılıkları:
Tebrikler, bu eğitimin sonuna ulaştınız!
Bu eğitimde Naive Bayes algoritmasını, çalışma şeklini, Naive Bayes varsayımını, sorunlarını, uygulamasını, avantaj ve dezavantajlarını öğrendiniz. Yol boyunca ayrıca scikit-learn’de ikili ve çok terimli (multinomial) sınıflar için model kurma ve değerlendirmeyi de öğrendiniz.
Naive Bayes en basit ve en güçlü algoritmalardan biridir. Son birkaç yıldaki önemli makine öğrenimi ilerlemelerine rağmen değerini kanıtlamıştır. Metin analizinden öneri motorlarına kadar birçok uygulamada başarıyla hayata geçirilmiştir.
Python’da scikit-learn hakkında daha fazla bilgi edinmek isterseniz, scikit-learn ile Denetimli Öğrenme kursumuzu alın ve Scikit-Learn Eğitimi: Beyzbol Analitiği Bölüm 1 içeriğimize göz atın.
Python Kursları
Kurs
Kurs
Kurs
blog
Dario Radečić
15 dk.
blog
Abid Ali Awan
14 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
