Corso
Introduzione a Python
4 h
6.9M
Naive Bayes è una tecnica di classificazione statistica basata sul teorema di Bayes. È uno degli algoritmi di apprendimento supervisionato più semplici. Il classificatore Naive Bayes è un algoritmo veloce, accurato e affidabile. I classificatori Naive Bayes hanno alta accuratezza e velocità su dataset di grandi dimensioni.
Il classificatore Naive Bayes assume che l'effetto di una particolare caratteristica in una classe sia indipendente dalle altre caratteristiche. Per esempio, un richiedente un prestito è desiderabile o meno a seconda del suo reddito, dei precedenti prestiti e della cronologia delle transazioni, dell'età e della posizione. Anche se queste caratteristiche sono interdipendenti, vengono comunque considerate indipendentemente. Questa assunzione semplifica il calcolo, ed è per questo che è considerata ingenua. Questa assunzione è chiamata indipendenza condizionata di classe.
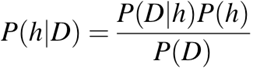
P(h): la probabilità che l'ipotesi h sia vera (indipendentemente dai dati). È nota come probabilità a priori di h.
P(D): la probabilità dei dati (indipendentemente dall'ipotesi). È nota come probabilità a priori.
P(h|D): la probabilità dell'ipotesi h dato il dato D. È nota come probabilità a posteriori.
P(D|h): la probabilità del dato d dato che l'ipotesi h è vera. È nota come probabilità a posteriori.
Ogni volta che esegui una classificazione, il primo passo è capire il problema e identificare le possibili feature e l'etichetta. Le feature sono quelle caratteristiche o attributi che influenzano il risultato dell'etichetta. Per esempio, nel caso della concessione di un prestito, i responsabili di banca identificano l'occupazione del cliente, il reddito, l'età, la posizione, la cronologia dei prestiti, la cronologia delle transazioni e il credit score. Queste caratteristiche sono note come feature e aiutano il modello a classificare i clienti.
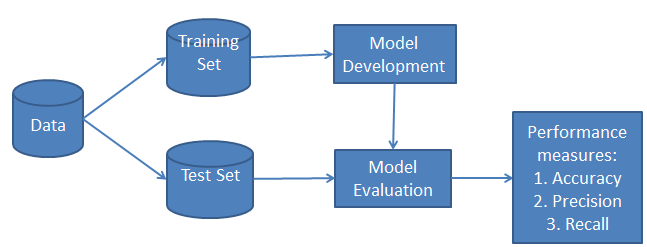
La classificazione ha due fasi: una fase di apprendimento e una fase di valutazione. Nella fase di apprendimento, il classificatore allena il suo modello su un dataset dato; nella fase di valutazione, testa le prestazioni del classificatore. Le prestazioni sono valutate in base a vari parametri come accuratezza, errore, precision e recall.
Capiremo il funzionamento di Naive Bayes con un esempio. Dati le condizioni meteo e il gioco sportivo, devi calcolare la probabilità di giocare. Ora devi classificare se i giocatori giocheranno o no, in base alle condizioni meteo.
Il classificatore Naive Bayes calcola la probabilità di un evento nei seguenti passaggi:
Per semplificare il calcolo delle probabilità a priori e a posteriori, puoi usare le due tabelle: tabella delle frequenze e delle verosimiglianze. Entrambe ti aiuteranno a calcolare le probabilità a priori e a posteriori. La tabella delle frequenze contiene le occorrenze delle etichette per tutte le feature. Ci sono due tabelle di verosimiglianza. La Tabella di verosimiglianza 1 mostra le probabilità a priori delle etichette e la Tabella di verosimiglianza 2 mostra le probabilità a posteriori.
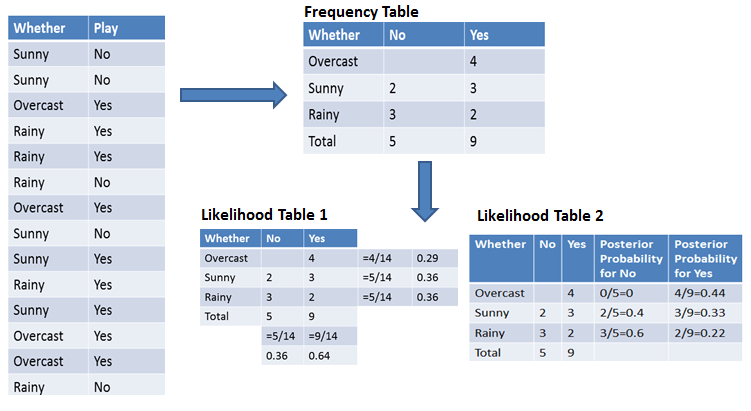
Ora, supponi di voler calcolare la probabilità di giocare quando il meteo è coperto (overcast).
Probabilità di giocare:
P(Sì | Overcast) = P(Overcast | Sì) × P(Sì) / P(Overcast)
Passaggio 1: Calcola le probabilità a priori
Passaggio 2: Calcola la probabilità a posteriori
Passaggio 3: Applica la formula di Bayes
Qui inseriamo le probabilità a priori e a posteriori nella prima equazione.
P(Sì | Overcast) = 0,44 × 0,64 / 0,29 = 0,98
Allo stesso modo, puoi calcolare la probabilità di non giocare:
Probabilità di non giocare:
P(No | Overcast) = P(Overcast | No) × P(No) / P(Overcast)
Passaggio 1: Calcola le probabilità a priori
Passaggio 2: Calcola la verosimiglianza
Passaggio 3: Applica la formula di Bayes
Qui inseriamo le probabilità a priori e di verosimiglianza nell'equazione per ottenere la probabilità a posteriori.
P(No | Overcast) = 0 × 0,36 / 0,29 = 0
La probabilità della classe "Sì" è più alta. Quindi puoi determinare che, se il meteo è coperto, i giocatori giocheranno.
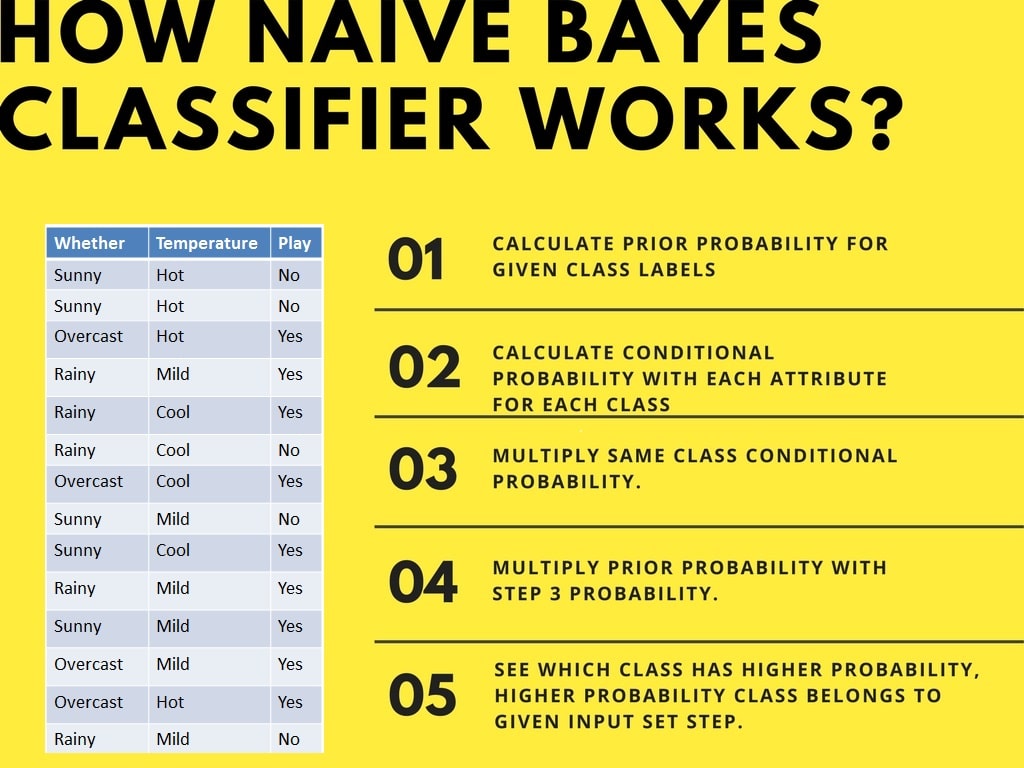
Ora, supponi di voler calcolare la probabilità di giocare quando il meteo è coperto e la temperatura è mite.
Probabilità di giocare:
P(Gioca = Sì | Meteo = Overcast, Temp = Mite) = P(Meteo = Overcast, Temp = Mite | Gioca = Sì) × P(Gioca = Sì)
Usando l'assunzione di indipendenza di Naive Bayes:
P(Meteo = Overcast, Temp = Mite | Gioca = Sì) = P(Overcast | Sì) × P(Mite | Sì)
Passaggio 1: Calcola la probabilità a priori
Passaggio 2: Calcola le verosimiglianze
Passaggio 3: Calcola la verosimiglianza combinata
P(Meteo = Overcast, Temp = Mite | Gioca = Sì) = 0,44 × 0,44 = 0,1936
Passaggio 4: Applica la formula di Bayes
P(Gioca = Sì | Meteo = Overcast, Temp = Mite) = 0,1936 × 0,64 = 0,124
Allo stesso modo, puoi calcolare la probabilità di non giocare:
Probabilità di non giocare:
P(Gioca = No | Meteo = Overcast, Temp = Mite) = P(Meteo = Overcast, Temp = Mite | Gioca = No) × P(Gioca = No)
Usando l'assunzione di indipendenza di Naive Bayes:
P(Meteo = Overcast, Temp = Mite | Gioca = No) = P(Overcast | No) × P(Mite | No)
Passaggio 1: Calcola la probabilità a priori
Passaggio 2: Calcola le verosimiglianze
Passaggio 3: Calcola la verosimiglianza combinata
P(Meteo = Overcast, Temp = Mite | Gioca = No) = 0 × 0,4 = 0
Passaggio 4: Applica la formula di Bayes
P(Gioca = No | Meteo = Overcast, Temp = Mite) = 0 × 0,36 = 0
La probabilità della classe "Sì" è più alta (0,124 vs 0), quindi se il meteo è coperto e la temperatura è mite, i giocatori giocheranno.
Nel primo esempio genereremo dati sintetici usando scikit-learn e alleneremo e valuteremo l'algoritmo Gaussian Naive Bayes.
Scikit-learn ci fornisce un ecosistema di machine learning per generare il dataset e valutare vari algoritmi di machine learning.
Nel nostro caso, creiamo un dataset con sei feature, tre classi e 800 campioni usando la funzione make_classification().
from sklearn.datasets import make_classification
X, y = make_classification(
n_features=6,
n_classes=3,
n_samples=800,
n_informative=2,
random_state=1,
n_clusters_per_class=1,
)Useremo la funzione scatter() di matplotlib.pyplot per visualizzare il dataset.
import matplotlib.pyplot as plt
plt.scatter(X[:, 0], X[:, 1], c=y, marker="*");Come possiamo osservare, ci sono tre tipi di etichette target e alleneremo un modello di classificazione multiclasse.
Prima di iniziare l'addestramento, dobbiamo suddividere il dataset in training e test per la valutazione del modello.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.33, random_state=125
)Crea un Gaussian Naive Bayes generico e addestralo su un dataset di training. Poi passa un campione di test casuale al modello per ottenere un valore predetto.
from sklearn.naive_bayes import GaussianNB
# Build a Gaussian Classifier
model = GaussianNB()
# Model training
model.fit(X_train, y_train)
# Predict Output
predicted = model.predict([X_test[6]])
print("Actual Value:", y_test[6])
print("Predicted Value:", predicted[0])Sia il valore reale che quello predetto coincidono.
Actual Value: 0
Predicted Value: 0Ora valuteremo il modello su un dataset di test non visto. Per prima cosa prediremo i valori per il dataset di test e li useremo per calcolare accuratezza e F1 score.
from sklearn.metrics import (
accuracy_score,
confusion_matrix,
ConfusionMatrixDisplay,
f1_score,
)
y_pred = model.predict(X_test)
accuray = accuracy_score(y_pred, y_test)
f1 = f1_score(y_pred, y_test, average="weighted")
print("Accuracy:", accuray)
print("F1 Score:", f1)Il nostro modello ha ottenuto risultati abbastanza buoni con gli iperparametri di default.
Accuracy: 0.8484848484848485
F1 Score: 0.8491119695890328Per visualizzare la matrice di confusione, useremo confusion_matrix per calcolare veri positivi e veri negativi e ConfusionMatrixDisplay per mostrare la matrice con le etichette.
labels = [0,1,2]
cm = confusion_matrix(y_test, y_pred, labels=labels)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=labels)
disp.plot();Il nostro modello si è comportato molto bene e possiamo migliorare le prestazioni con scaling, preprocessing, cross-validation e ottimizzazione degli iperparametri.
Alleniamo il classificatore Naive Bayes su un dataset reale. Ripeteremo la maggior parte dei passaggi, tranne preprocessing ed esplorazione dei dati.
In questo esempio caricheremo i Loan Data da DataLab usando la funzione read_csv di pandas.
import pandas as pd
df = pd.read_csv('loan_data.csv')
df.head()Per capire meglio il dataset useremo .info().
Il dataset è composto da 14 colonne e 9578 righe.
A parte purpose, le colonne sono o float o integer.
La nostra colonna target è not.fully.paid.
df.info()RangeIndex: 9578 entries, 0 to 9577
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 credit.policy 9578 non-null int64
1 purpose 9578 non-null object
2 int.rate 9578 non-null float64
3 installment 9578 non-null float64
4 log.annual.inc 9578 non-null float64
5 dti 9578 non-null float64
6 fico 9578 non-null int64
7 days.with.cr.line 9578 non-null float64
8 revol.bal 9578 non-null int64
9 revol.util 9578 non-null float64
10 inq.last.6mths 9578 non-null int64
11 delinq.2yrs 9578 non-null int64
12 pub.rec 9578 non-null int64
13 not.fully.paid 9578 non-null int64
dtypes: float64(6), int64(7), object(1)
memory usage: 1.0+ MBIn questo esempio svilupperemo un modello per prevedere i clienti che non hanno rimborsato completamente il prestito. Esploriamo la colonna purpose e la colonna target usando il countplot di seaborn.
import seaborn as sns
import matplotlib.pyplot as plt
sns.countplot(data=df,x='purpose',hue='not.fully.paid')
plt.xticks(rotation=45, ha='right');Il nostro dataset è sbilanciato, il che influenzerà le prestazioni del modello. Puoi consultare il tutorial Resample an Imbalanced Dataset per fare pratica nella gestione di dataset sbilanciati.
Ora convertirermo la colonna purpose da categorica a intera usando la funzione get_dummies() di pandas.
pre_df = pd.get_dummies(df,columns=['purpose'],drop_first=True)
pre_df.head()Dopodiché definiremo le variabili delle feature (X) e del target (y) e suddivideremo il dataset in training e test.
from sklearn.model_selection import train_test_split
X = pre_df.drop('not.fully.paid', axis=1)
y = pre_df['not.fully.paid']
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.33, random_state=125
)La costruzione e l'addestramento del modello sono piuttosto semplici. Alleneremo un modello su un dataset di training usando gli iperparametri di default.
from sklearn.naive_bayes import GaussianNB
model = GaussianNB()
model.fit(X_train, y_train);Useremo accuratezza e f1 score per determinare le prestazioni del modello, e sembra che l'algoritmo Gaussian Naive Bayes si sia comportato molto bene.
from sklearn.metrics import (
accuracy_score,
confusion_matrix,
ConfusionMatrixDisplay,
f1_score,
classification_report,
)
y_pred = model.predict(X_test)
accuray = accuracy_score(y_pred, y_test)
f1 = f1_score(y_pred, y_test, average="weighted")
print("Accuracy:", accuray)
print("F1 Score:", f1)Accuracy: 0.8206263840556786
F1 Score: 0.8686606980013266A causa della natura sbilanciata dei dati, possiamo vedere che la matrice di confusione racconta un'altra storia. Sulla classe minoritaria: not fully paid, abbiamo più etichette errate.
labels = ["Fully Paid", "Not fully Paid"]
cm = confusion_matrix(y_test, y_pred)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=labels)
disp.plot();Se riscontri problemi durante l'addestramento o la valutazione del modello, puoi consultare il DataLab workbook del tutorial Naive Bayes Classification con Scikit-learn qui. Include dataset, codice sorgente e output.
Supponi che nel dataset non ci sia alcuna tupla per un prestito rischioso; in questo scenario, la probabilità a posteriori sarà zero e il modello non sarà in grado di fare una previsione. Questo problema è noto come probabilità zero perché l'occorrenza della classe particolare è zero.
La soluzione a questo problema è la correzione di Laplace o trasformazione di Laplace. La correzione di Laplace è una delle tecniche di smoothing. Qui puoi assumere che il dataset sia abbastanza grande perché aggiungere una riga per ciascuna classe non influisca sulla probabilità stimata. Questo evita che i valori di probabilità diventino zero.
Per esempio: supponi che per la classe "prestito rischioso" ci siano 1000 tuple di training nel database. In questo database, la colonna del reddito ha 0 tuple per reddito basso, 990 tuple per reddito medio e 10 tuple per reddito alto. Le probabilità di questi eventi, senza la correzione di Laplace, sono 0, 0,990 (da 990/1000) e 0,010 (da 10/1000)
Ora applichiamo la correzione di Laplace al dataset dato. Aggiungiamo 1 tupla in più per ciascuna coppia valore-reddito. Le probabilità di questi eventi:
Congratulazioni, sei arrivato alla fine di questo tutorial!
In questo tutorial hai imparato l'algoritmo Naive Bayes, il suo funzionamento, l'assunzione di Naive Bayes, i problemi, l'implementazione, i vantaggi e gli svantaggi. Lungo la strada, hai anche imparato la costruzione e la valutazione di modelli in scikit-learn per classi binarie e multinomiali.
Naive Bayes è l'algoritmo più semplice e potente. Nonostante i notevoli progressi del machine learning negli ultimi anni, ha dimostrato il suo valore. È stato implementato con successo in molte applicazioni, dall'analisi del testo ai motori di raccomandazione.
Se vuoi imparare di più su scikit-learn in Python, segui il nostro corso Apprendimento supervisionato con scikit-learn e dai un'occhiata al nostro Tutorial Scikit-Learn: Baseball Analytics Pt 1.
Corsi Python
Corso
Corso
Corso
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min
blog
Abid Ali Awan
15 min

