
Kursus
Manipulasi Data di SQL
4 Hr
328.2K
Jika Anda tidak ingin berurusan lagi dengan data yang tidak konsisten dan redundan, normalisasi basis data adalah jawabannya.
Anda tahu rasa frustasi saat memperbarui informasi pelanggan di satu tabel, tetapi menemukan versi lama tersebar di lima tabel lainnya. Kueri Anda mengembalikan hasil yang saling bertentangan, laporan Anda menunjukkan angka berbeda tergantung dari tabel mana Anda mengambil data, dan Anda menghabiskan berjam-jam men-debug masalah integritas data yang seharusnya tidak ada. Masalah-masalah ini hanya akan berlipat ganda seiring pertumbuhan basis data Anda.
Normalisasi basis data menghilangkan sakit kepala ini dengan mengatur data Anda berdasarkan prinsip matematika yang telah teruji. Proses ini menggunakan bentuk normal untuk memastikan setiap potongan informasi hanya ada di satu tempat, sehingga basis data Anda andal dan efisien.
Saya akan menunjukkan proses normalisasi lengkap, dari konsep dasar hingga bentuk normal lanjutan, dengan contoh praktik yang mengubah data berantakan menjadi struktur basis data yang rapi dan mudah dipelihara.
Normalisasi mencegah basis data Anda berubah menjadi mimpi buruk pemeliharaan. Mari lihat mengapa normalisasi yang tepat penting untuk aplikasi dunia nyata.
Redundansi adalah pembunuh diam-diam kinerja basis data. Saat Anda menyimpan informasi yang sama di banyak tempat, Anda bukan hanya membuang ruang penyimpanan—Anda sedang menciptakan ketidak konsistenan yang merusak logika aplikasi Anda.
Tanpa normalisasi, memperbarui alamat pelanggan berarti harus melacak setiap tabel yang menyimpan data alamat. Jika ada yang terlewat, laporan Anda menampilkan informasi yang bertentangan. Pengguna Anda melihat alamat berbeda di layar yang berbeda. Analitik Anda menjadi tidak dapat diandalkan.
Normalisasi memperbaikinya dengan memastikan setiap data berada tepat di satu tempat. Ketika Anda memperbarui alamat pelanggan, perubahan berlaku di mana-mana secara otomatis karena semuanya mereferensikan sumber yang sama.
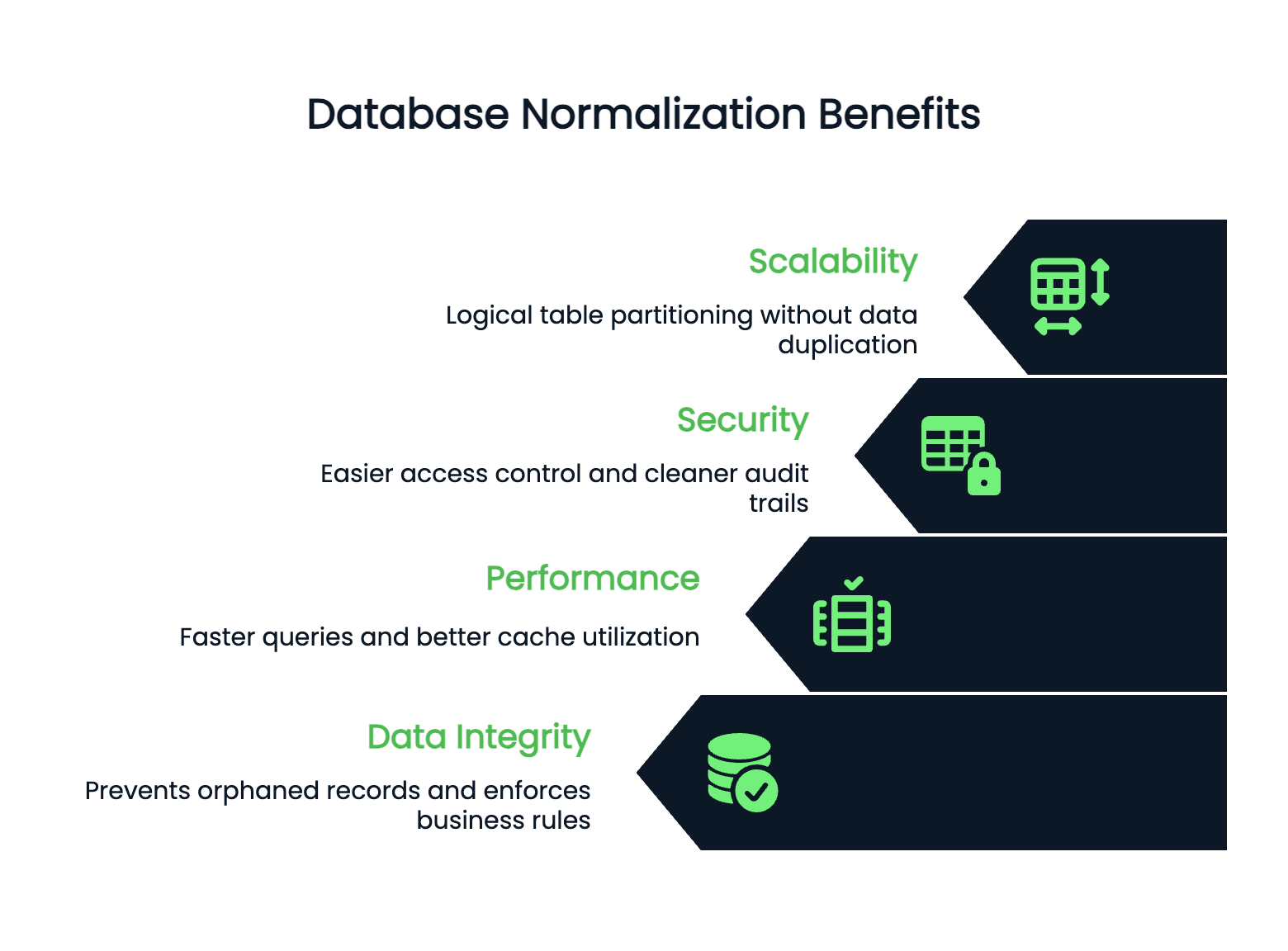
Integritas menjadi sangat kuat saat Anda melakukan normalisasi dengan benar. Foreign key constraint mencegah rekaman yatim piatu. Anda tidak bisa tanpa sengaja menghapus pelanggan yang masih memiliki pesanan aktif. Basis data Anda menegakkan aturan bisnis di tingkat data, bukan hanya di kode aplikasi.
Ini berarti lebih sedikit bug, kode lebih bersih, dan aplikasi berperilaku dapat diprediksi meskipun banyak sistem mengakses data yang sama.
Anomali modifikasi hilang dengan normalisasi yang tepat. Ini terjadi saat Anda menyisipkan, memperbarui, atau menghapus data dan menimbulkan inkonsistensi atau membutuhkan solusi rumit.
Anomali sisip memaksa Anda menambahkan data dummy hanya untuk membuat rekaman. Anomali pembaruan mengharuskan Anda mengubah informasi yang sama di banyak baris. Anomali hapus menghilangkan lebih banyak informasi daripada yang dimaksud saat Anda menghapus satu rekaman.
Basis data ternormalisasi menghilangkan masalah ini dengan mengatur data sehingga setiap fakta muncul sekali dan hanya sekali.
Kinerja dan skalabilitas meningkat saat struktur basis data Anda bersih. Tabel yang ternormalisasi biasanya lebih kecil, yang berarti kueri lebih cepat dan pemanfaatan cache lebih baik. Indeks bekerja lebih efektif pada tabel yang lebih kecil dan fokus.
Basis data Anda dapat diskalakan secara horizontal karena data yang ternormalisasi memiliki batas yang jelas. Anda dapat melakukan partisi tabel secara logis tanpa menduplikasi informasi di seluruh shard.
Keamanan menjadi lebih mudah dikelola dalam basis data yang ternormalisasi. Anda dapat mengendalikan akses pada tingkat tabel dengan percaya diri karena data sensitif berada di tempat yang spesifik dan terdefinisi jelas. Tidak perlu khawatir nomor kartu kredit pelanggan tersembunyi di tabel yang tidak terduga.
Jejak audit juga lebih bersih—Anda tahu persis di mana perubahan terjadi dan dapat melacaknya tanpa harus mencari di data redundan yang tersebar di seluruh skema.
Singkatnya, normalisasi mengubah data yang kacau menjadi fondasi andal yang tumbuh bersama aplikasi Anda.
Selanjutnya, mari lihat apa saja prasyarat untuk normalisasi.
Sebelum Anda mulai menormalisasi tabel, Anda perlu memahami apa yang membuat normalisasi bekerja. Mari bahas konsep penting yang akan memandu keputusan Anda sepanjang proses.
Kunci adalah dasar dari desain basis data relasional—kunci mengidentifikasi rekaman dan menghubungkan tabel satu sama lain.
Sebuah primary key mengidentifikasi setiap baris dalam tabel secara unik. Tidak ada dua baris yang dapat memiliki nilai primary key yang sama, dan nilainya tidak boleh null. Anggap saja seperti nomor induk untuk data Anda—setiap rekaman mendapatkan satu nomor, dan tidak ada duplikasi.
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
email VARCHAR(255),
name VARCHAR(100)
);Di sini, customer_id adalah primary key. Setiap pelanggan mendapatkan ID unik yang akan Anda gunakan untuk mereferensikan pelanggan tersebut dari tabel lain.
Candidate key adalah kolom (atau kombinasi kolom) apa pun yang dapat dijadikan primary key. Tabel customers Anda mungkin memiliki customer_id dan email sebagai candidate key karena keduanya mengidentifikasi pelanggan secara unik. Anda memilih salah satunya sebagai primary key, dan yang lain tetap sebagai candidate key.
Foreign key membuat relasi antar tabel. Foreign key mereferensikan primary key dari tabel lain dan membentuk koneksi yang menjaga integritas data.
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
order_date DATE,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);Kolom customer_id di tabel orders adalah foreign key. Nilainya harus cocok dengan customer_id yang ada di tabel customers. Ini mencegah pesanan yatim piatu dan memastikan setiap pesanan milik pelanggan yang valid.
Kunci menegakkan aturan bisnis di tingkat basis data, sehingga data Anda lebih andal dibandingkan validasi di aplikasi saja.
Functional dependency menggambarkan bagaimana kolom saling terkait dalam sebuah tabel. Ini adalah dasar matematis yang mendorong keputusan normalisasi.
Functional dependency ada ketika nilai satu kolom menentukan nilai kolom lain. Kita menuliskannya sebagai A → B, yang berarti "A menentukan B" atau "B bergantung pada A."
Dalam tabel customers, customer_id → email karena setiap ID pelanggan dipetakan ke tepat satu alamat email. Jika Anda mengetahui ID pelanggan, Anda dapat menentukan emailnya dengan pasti.

Gambar 1 - Contoh functional dependency
Di sini, customer_id → email dan customer_id → name karena ID pelanggan menentukan baik email maupun nama.
Functional dependency mengungkap masalah redundansi.
Jika Anda memiliki tabel di mana order_id → customer_name tetapi Anda menyimpan nama pelanggan di setiap baris pesanan, Anda memiliki redundansi. Nama pelanggan bergantung pada ID pelanggan, bukan pada ID pesanan.
Pelestarian ketergantungan (dependency preservation) berarti tabel-tabel hasil normalisasi tetap mempertahankan semua functional dependency asli. Saat Anda memecah tabel selama normalisasi, Anda tidak boleh kehilangan kemampuan untuk menegakkan aturan bisnis yang ada di tabel asli.
Dekomposisi tanpa rugi (lossless decomposition) menjamin Anda dapat merekonstruksi tabel asli dengan menggabungkan (join) tabel-tabel yang ternormalisasi. Anda tidak kehilangan informasi apa pun ketika memecah tabel—join akan mengembalikan data yang persis sama seperti saat awal.
Konsep-konsep ini bekerja bersama: functional dependency mengidentifikasi apa yang perlu dipisahkan, sedangkan pelestarian ketergantungan dan dekomposisi tanpa rugi memastikan Anda tidak merusak apa pun dalam prosesnya.
Memahami relasi ini membantu Anda membuat keputusan normalisasi yang cerdas untuk meningkatkan basis data tanpa kehilangan fungsionalitas.
Sekarang mari kita telusuri proses normalisasi yang sebenarnya, mulai dari data yang berantakan dan mengubahnya langkah demi langkah. Setiap bentuk normal dibangun di atas bentuk sebelumnya, jadi Anda tidak bisa langsung melompat dari data yang belum ternormalisasi ke 3NF.
Bentuk normal pertama menghilangkan grup berulang dan memastikan setiap kolom berisi nilai atomik. Pelajari lebih lanjut di panduan mendalam First Normal Form (1NF).
Nilai atomik berarti setiap sel hanya memuat satu potong informasi—tidak ada daftar, tidak ada nilai yang dipisahkan koma, tidak ada banyak titik data yang dijejalkan ke satu kolom. Ini adalah fondasi yang membuat hal lainnya menjadi mungkin.
Berikut yang melanggar 1NF:
CREATE TABLE orders_bad (
order_id INT,
customer_name VARCHAR(100),
products VARCHAR(500),
quantities VARCHAR(50)
);
Gambar 2 - Tabel yang melanggar 1NF
Kolom products dan quantities berisi banyak nilai yang dipisahkan koma. Anda tidak bisa dengan mudah menanyakan "semua pesanan yang berisi laptop" atau menghitung total kuantitas tanpa memparsing string.
Untuk mengonversi ke 1NF, pisahkan grup berulang menjadi baris terpisah:
-- First normal form (1NF)
CREATE TABLE orders_1nf (
order_id INT,
customer_name VARCHAR(100),
product VARCHAR(100),
quantity INT
);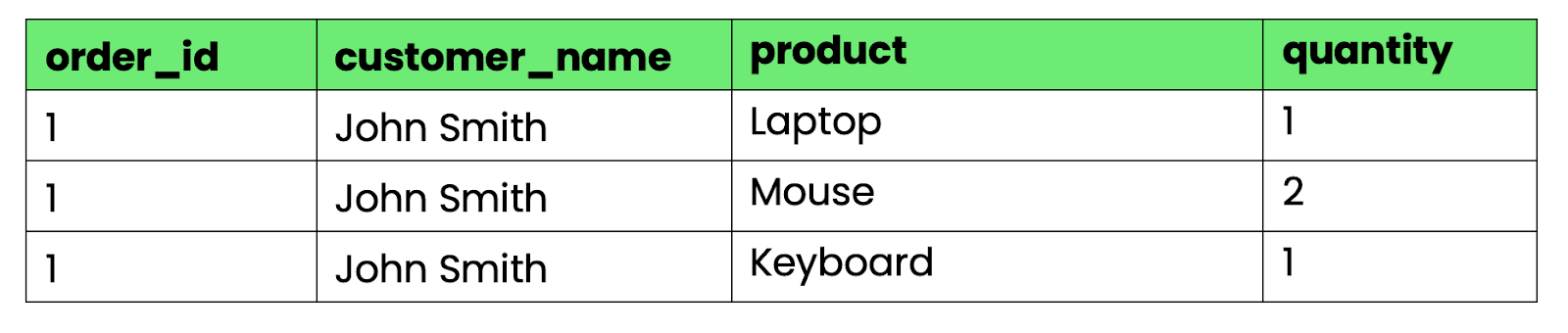
Gambar 3 - Tabel yang memenuhi 1NF
Sekarang, setiap sel berisi tepat satu nilai. Anda dapat melakukan kueri, mengurutkan, dan mengagregasi data dengan operasi SQL standar.
Bentuk normal kedua menghilangkan ketergantungan parsial—ketika kolom non-kunci bergantung hanya pada sebagian dari primary key komposit.
Ada lebih banyak hal pada Second Normal Form (2NF) daripada yang terlihat. Pelajari lebih lanjut di panduan mendalam kami.
Sebuah tabel berada pada 2NF jika sudah 1NF dan setiap kolom non-kunci bergantung pada seluruh primary key, bukan hanya sebagian darinya.
Tabel 1NF kita punya masalah. Jika kita menggunakan order_id dan product sebagai primary key komposit, customer_name hanya bergantung pada order_id, bukan pada produk. Ini menimbulkan redundansi—nama pelanggan berulang untuk setiap produk dalam satu pesanan.
-- Still has partial dependencies
-- customer_name depends only on order_id, not on (order_id, product)
CREATE TABLE orders_1nf (
order_id INT,
customer_name VARCHAR(100), -- Partial dependency!
product VARCHAR(100),
quantity INT,
PRIMARY KEY (order_id, product)
);Untuk mencapai 2NF, pecah tabel berdasarkan ketergantungan:
-- Orders table (customer info depends on order_id)
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_name VARCHAR(100)
);
-- Order items table (quantity depends on both order_id and product)
CREATE TABLE order_items (
order_id INT,
product VARCHAR(100),
quantity INT,
PRIMARY KEY (order_id, product),
FOREIGN KEY (order_id) REFERENCES orders(order_id)
);Sekarang customer_name muncul hanya sekali per pesanan, menghilangkan redundansi. Setiap tabel memiliki kolom yang bergantung pada seluruh primary key.
Bentuk normal ketiga menghilangkan ketergantungan transitif, yang terjadi ketika kolom non-kunci bergantung pada kolom non-kunci lain alih-alih pada primary key. Dalami Third Normal Form (3NF) lebih dari sekadar dasar-dasarnya.
Ketergantungan transitif ada ketika “Kolom A” menentukan “Kolom B”, dan “Kolom B” menentukan “Kolom C”, menciptakan ketergantungan tidak langsung dari A ke C.
Mari perluas tabel pesanan kita dengan informasi alamat pelanggan:
-- Has transitive dependencies
CREATE TABLE orders_2nf (
order_id INT PRIMARY KEY,
customer_name VARCHAR(100),
customer_city VARCHAR(50),
customer_state VARCHAR(50),
customer_zip VARCHAR(10)
);Inilah masalahnya: customer_name → customer_city, dan customer_city → customer_state. State bergantung pada city, bukan langsung pada pesanan. Ini menciptakan redundansi—setiap pesanan dari kota yang sama mengulang informasi state.
Untuk mencapai 3NF, hilangkan ketergantungan transitif dengan membuat tabel terpisah:
-- Customers table (removes transitive dependencies)
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
customer_name VARCHAR(100),
city_id INT,
FOREIGN KEY (city_id) REFERENCES cities(city_id)
);
-- Cities table
CREATE TABLE cities (
city_id INT PRIMARY KEY,
city_name VARCHAR(50),
state VARCHAR(50),
zip VARCHAR(10)
);
-- Orders table (now references customer, not customer details)
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
order_date DATE,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);Sekarang informasi geografis berada di satu tempat. Jika sebuah kota berganti state (langka tetapi mungkin), Anda memperbarui satu baris alih-alih memburu setiap pesanan dari kota tersebut.
Setiap bentuk normal menyelesaikan masalah redundansi tertentu sambil mempertahankan kemampuan untuk merekonstruksi data asli Anda melalui join.
Tiga bentuk normal pertama menangani sebagian besar masalah basis data di dunia nyata, tetapi beberapa kasus tepi memerlukan normalisasi yang lebih dalam. Bentuk lanjutan ini menangani masalah ketergantungan spesifik yang tidak dapat diselesaikan oleh 3NF.
BCNF memperbaiki masalah halus yang terlewat oleh 3NF: ketika sebuah tabel memiliki candidate key yang saling tumpang tindih.
3NF mengizinkan kolom non-kunci bergantung pada candidate key, tetapi BCNF lebih ketat. Dalam BCNF, setiap determinant (kolom yang menentukan kolom lain) harus merupakan superkey—baik primary maupun candidate key.
Berikut titik di mana 3NF gagal:
-- Table in 3NF but violates BCNF
CREATE TABLE course_instructors (
student_id INT,
course VARCHAR(50),
instructor VARCHAR(50),
PRIMARY KEY (student_id, course)
);Aturan bisnisnya adalah:
Ini menciptakan ketergantungan course → instructor dan instructor → course. Baik (student_id, course) maupun (student_id, instructor) adalah candidate key, tetapi course dan instructor saling menentukan tanpa menjadi superkey itu sendiri.
Masalah muncul saat Anda mencoba menambahkan pengajar baru tanpa mahasiswa. Anda tidak bisa menyisipkan "Profesor Smith mengajar Desain Basis Data" tanpa juga menambahkan seorang mahasiswa ke mata kuliah itu.
Untuk mencapai BCNF, dekomposisi berdasarkan ketergantungan yang bermasalah:
-- BCNF solution
CREATE TABLE course_assignments (
course VARCHAR(50) PRIMARY KEY,
instructor VARCHAR(50) UNIQUE
);
CREATE TABLE student_enrollments (
student_id INT,
course VARCHAR(50),
PRIMARY KEY (student_id, course),
FOREIGN KEY (course) REFERENCES course_assignments(course)
);Sekarang Anda dapat menambahkan pengajar tanpa mahasiswa, dan struktur basis data cocok dengan aturan bisnis secara tepat.
4NF menghilangkan multi-valued dependency—ketika satu kolom menentukan beberapa himpunan nilai yang independen.
Multi-valued dependency ada ketika “Kolom A” menentukan banyak nilai di “Kolom B”, dan nilai-nilai tersebut independen dari kolom lain dalam tabel.
Pertimbangkan tabel berikut yang melacak keterampilan dan hobi mahasiswa:
-- Violates 4NF due to multi-valued dependencies
CREATE TABLE student_info (
student_id INT,
skill VARCHAR(50),
hobby VARCHAR(50),
PRIMARY KEY (student_id, skill, hobby)
);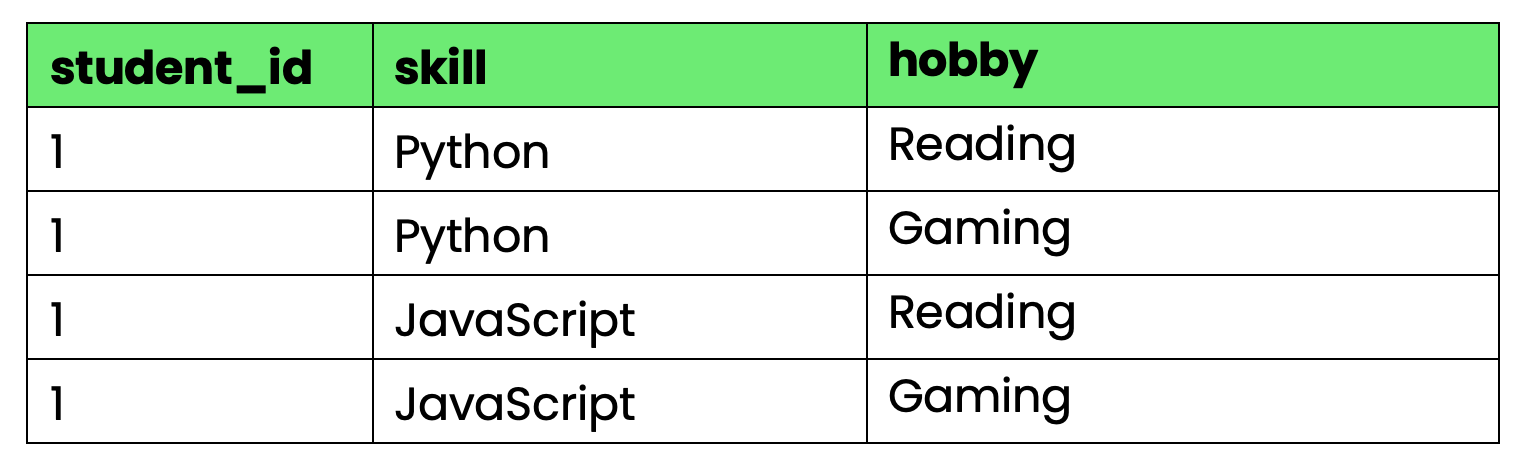
Gambar 4 - Tabel yang melanggar 4NF
Masalahnya: student_id menentukan baik keterampilan maupun hobi, tetapi keduanya saling independen. Saat mahasiswa 1 mempelajari keterampilan baru, Anda perlu membuat baris untuk setiap kombinasi hobi. Saat mereka menekuni hobi baru, Anda perlu baris untuk setiap kombinasi keterampilan.
Ini menciptakan redundansi yang meledak seiring bertambahnya jumlah keterampilan dan hobi.
Untuk mencapai 4NF, pisahkan multi-valued dependency yang independen:
-- 4NF solution
CREATE TABLE student_skills (
student_id INT,
skill VARCHAR(50),
PRIMARY KEY (student_id, skill)
);
CREATE TABLE student_hobbies (
student_id INT,
hobby VARCHAR(50),
PRIMARY KEY (student_id, hobby)
);Sekarang Anda dapat menambahkan keterampilan dan hobi secara independen tanpa menciptakan ledakan produk Kartesius.
5NF (Project-Join Normal Form) menghilangkan join dependency: relasi kompleks yang memerlukan tiga atau lebih tabel untuk merekonstruksi data tanpa kehilangan.
Join dependency ada ketika Anda tidak bisa merekonstruksi tabel asli dengan menggabungkan dua tabel yang didekomposisi, tetapi bisa jika menggabungkan tiga atau lebih tabel.
Pertimbangkan pemasok, suku cadang, dan proyek dengan aturan: "Seorang pemasok dapat memasok sebuah suku cadang ke suatu proyek hanya jika pemasok tersebut memasok suku cadang itu DAN bekerja pada proyek tersebut."
-- Original table with join dependency
CREATE TABLE supplier_part_project (
supplier_id INT,
part_id INT,
project_id INT,
PRIMARY KEY (supplier_id, part_id, project_id)
);Untuk mencapai 5NF, dekomposisi menjadi tiga relasi biner:
-- 5NF decomposition
CREATE TABLE supplier_parts (supplier_id INT, part_id INT);
CREATE TABLE supplier_projects (supplier_id INT, project_id INT);
CREATE TABLE project_parts (project_id INT, part_id INT);Anda hanya dapat merekonstruksi kombinasi pemasok-suku cadang-proyek yang valid dengan menggabungkan ketiga tabel, yang menegakkan aturan bisnis pada tingkat skema.
6NF membawa normalisasi ke tingkat ekstrem dengan menempatkan setiap atribut dalam tabelnya sendiri dengan kunci temporal.
6NF dirancang untuk gudang data dan basis data temporal di mana Anda perlu melacak bagaimana setiap atribut berubah seiring waktu secara independen.
-- 6NF example for temporal data
CREATE TABLE customer_names (
customer_id INT,
name VARCHAR(100),
valid_from DATE,
valid_to DATE
);
CREATE TABLE customer_addresses (
customer_id INT,
address VARCHAR(200),
valid_from DATE,
valid_to DATE
);Ini memungkinkan Anda melacak kapan setiap atribut berubah tanpa memengaruhi atribut lain, tetapi membuat kueri menjadi kompleks dan jarang digunakan di luar sistem basis data temporal khusus.
Kebanyakan aplikasi berhenti pada 3NF atau BCNF. Bentuk lanjutan ini menyelesaikan kasus tepi tertentu tetapi menambah kompleksitas yang tidak sebanding untuk aplikasi bisnis tipikal.
Pelajari lebih lanjut tentang basis data dan SQL dengan kursus-kursus ini!
Kursus
Kursus
Kursus
blogs
Dario Radečić
15 mnt
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Javier Canales Luna
14 mnt
