
Cours
Manipulation de données en SQL
4 h
324.3K
Si vous ne souhaitez plus jamais être confronté à des données incohérentes et redondantes, la normalisation des bases de données est la solution idéale.
Vous connaissez certainement la frustration de mettre à jour les informations d'un client dans un tableau, pour ensuite découvrir que des versions obsolètes sont dispersées dans cinq autres tableaux. Vos requêtes renvoient des résultats contradictoires, vos rapports affichent des chiffres différents selon le tableau d'où ils proviennent et vous passez des heures à déboguer des problèmes d'intégrité des données qui ne devraient pas exister. Ces problèmes ne font que se multiplier à mesure que votre base de données s'agrandit.
La normalisation des bases de données élimine ces difficultés en organisant vos données selon des principes mathématiques éprouvés. Le processus utilise des formes normales pour s'assurer que chaque élément d'information n'existe qu'à un seul endroit, ce qui rend votre base de données fiable et efficace.
Je vais vous présenter le processus complet de normalisation, depuis les concepts de base jusqu'aux formes normales avancées, à l'aide d'exemples pratiques qui transforment des données désordonnées en structures de base de données claires et faciles à gérer.
La normalisation est ce qui empêche votre base de données de devenir un cauchemar en termes de maintenance. Examinons pourquoi une normalisation adéquate est importante pour les applications concrètes.
La redondance est le facteur silencieux qui nuit à la performance des bases de données. Lorsque vous stockez les mêmes informations à plusieurs endroits, vous ne faites pas que gaspiller de l'espace de stockage, vous vous exposez également à des incohérences susceptibles de perturber la logique de votre application.
Sans normalisation, la mise à jour de l'adresse d'un client implique de rechercher tous les tableaux qui contiennent des données relatives à son adresse. Si vous en oubliez un, vos rapports présenteront des informations contradictoires. Vos utilisateurs voient des adresses différentes selon les écrans. Vos analyses deviennent peu fiables.
La normalisation résout ce problème en garantissant que chaque donnée se trouve à un seul endroit. Lorsque vous mettez à jour l'adresse de ce client, elle est automatiquement modifiée partout, car toutes les références renvoient à la même source.
L'intégrité devient à toute épreuve lorsque vous normalisez correctement. Les contraintes de clé étrangère empêchent la création d'enregistrements orphelins. Il n'est pas possible de supprimer accidentellement un client qui a encore des commandes en cours. Votre base de données applique les règles métier au niveau des données, et pas seulement dans le code de l'application.
Cela se traduit par moins de bugs, un code plus propre et des applications qui se comportent de manière prévisible, même lorsque plusieurs systèmes accèdent aux mêmes données.
Les anomalies de modification disparaissent avec une normalisation adéquate. Ces problèmes surviennent lorsque vous insérez, mettez à jour ou supprimez des données et créez des incohérences ou nécessitez des solutions de contournement complexes.
Les anomalies d'insertion vous obligent à ajouter des données factices uniquement pour créer un enregistrement. Les anomalies de mise à jour vous obligent à modifier les mêmes informations sur plusieurs lignes. La suppression des anomalies supprime plus d'informations que prévu lorsque vous supprimez un seul enregistrement.
Les bases de données normalisées éliminent ces problèmes en organisant les données de manière à ce que chaque fait n'apparaisse qu'une seule fois.
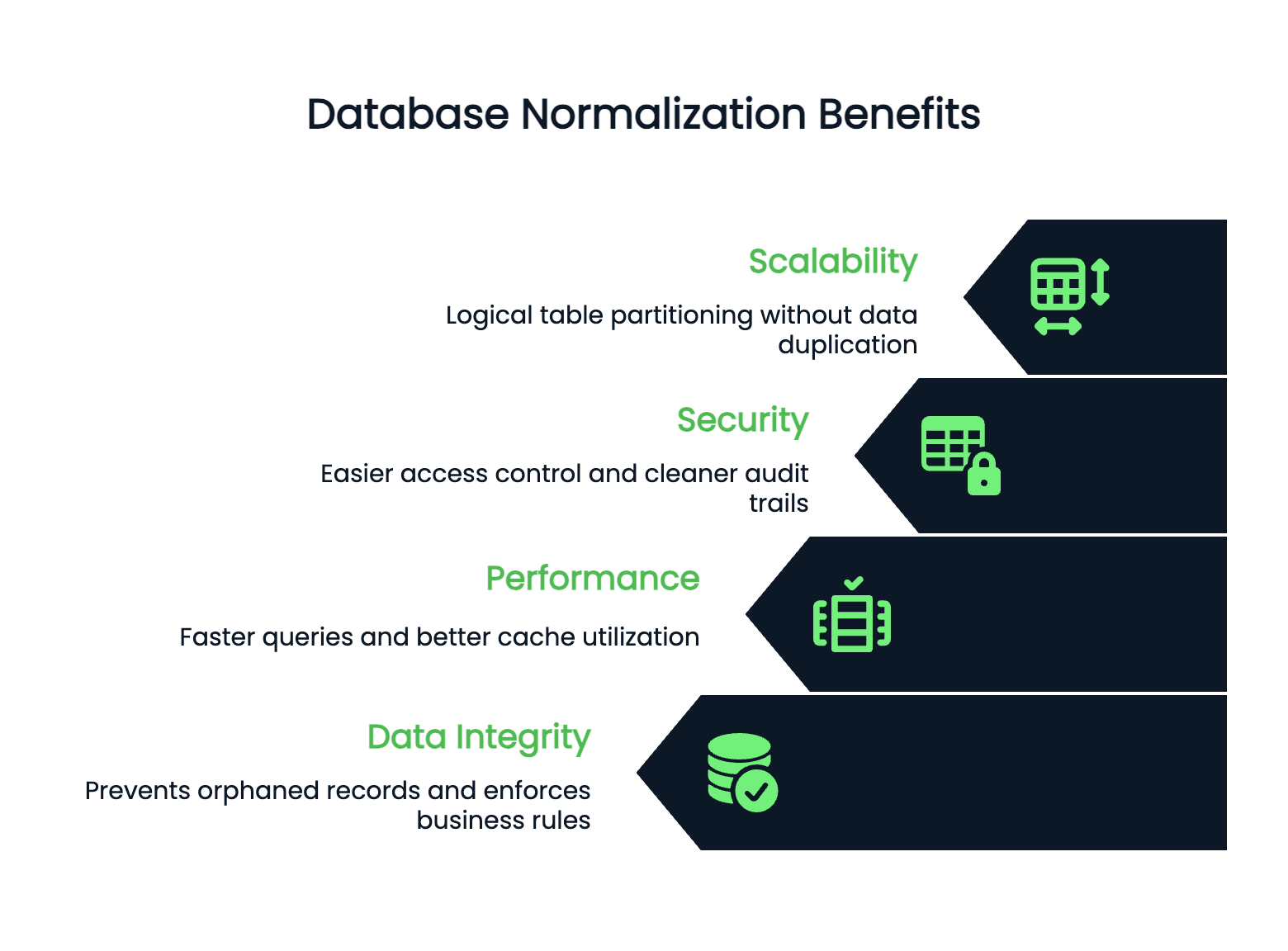
Les performances et l'évolutivité sont améliorées lorsque la structure de votre base de données est claire. Les tableaux normalisés sont généralement plus petits, ce qui se traduit par des requêtes plus rapides et une meilleure utilisation du cache. Les index fonctionnent plus efficacement sur des tableaux plus petits et plus ciblés.
Votre base de données peut évoluer horizontalement, car les données normalisées ont des limites claires. Vous pouvez partitionner les tableaux de manière logique sans dupliquer les informations entre les fragments.
La sécurité est plus facile à gérer dans les bases de données normalisées. Vous pouvez contrôler l'accès au niveau des tableaux en toute confiance, car les données sensibles sont stockées dans des emplacements spécifiques et bien définis. Vous n'avez pas à vous soucier des numéros de carte de crédit de vos clients qui pourraient être cachés dans des tableaux inattendus.
Les pistes d'audit sont également plus claires : vous savez exactement où les modifications ont été apportées et pouvez les suivre sans avoir à rechercher des données redondantes dispersées dans votre schéma.
En résumé, la normalisation transforme des données chaotiques en une base fiable qui évolue avec votre application.
Voyons maintenant quelles sont les conditions préalables à la normalisation.
Avant de commencer à normaliser des tableaux, il est important de comprendre comment fonctionne la normalisation. Examinons les concepts essentiels qui guideront vos décisions tout au long du processus.
Les clés constituent la base de la conception des bases de données relationnelles : elles identifient les enregistrements et relient les tableaux entre eux.
Une clé primaire identifie de manière unique chaque ligne d'un tableau. Deux lignes ne peuvent pas avoir la même valeur de clé primaire, et celle-ci ne peut pas être nulle. Considérez-le comme un numéro de sécurité sociale pour vos données : chaque enregistrement en reçoit un unique, sans doublon.
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
email VARCHAR(255),
name VARCHAR(100)
);Ici, « customer_id » est la clé primaire. Chaque client reçoit un identifiant unique que vous utiliserez pour référencer ce client spécifique à partir d'autres tableaux.
Une clé candidate est une colonne (ou une combinaison de colonnes) pouvant servir de clé primaire. Votre tableau « customers » peut contenir à la fois « customer_id » et « email » comme clés candidates, car ces deux clés identifient de manière unique les clients. Vous en sélectionnez une comme clé primaire, et les autres restent des clés candidates.
Les clés étrangères créent des relations entre les tableaux. Ils font référence à la clé primaire d'un autre tableau et établissent des connexions qui garantissent l'intégrité des données.
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
order_date DATE,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);Le champ « customer_id » dans le tableau « orders » est une clé étrangère. Il doit correspondre à une entité de type « customer_id » qui existe dans le tableau « customers ». Cela évite les commandes orphelines et garantit que chaque commande appartient à un client réel.
Les clés appliquent les règles métier au niveau de la base de données, ce qui rend vos données plus fiables qu'une validation effectuée uniquement au niveau de l'application.
Les dépendances fonctionnelles décrivent comment les colonnes sont liées entre elles dans un tableau. Ils constituent la base mathématique qui guide les décisions de normalisation.
Une dépendance fonctionnelle existe lorsque la valeur d'une colonne détermine la valeur d'une autre colonne. Nous écrivons cela sous la forme « A → B », ce qui signifie « A détermine B » ou « B dépend de A ».
Dans un tableau d'customers, customer_id → email car chaque ID client correspond à une seule adresse e-mail. Si vous connaissez l'identifiant du client, vous pouvez déterminer l'adresse e-mail avec certitude.

Image 1 - Exemple de dépendance fonctionnelle
Ici, customer_id → email et customer_id → name, car l'identifiant client détermine à la fois l'adresse e-mail et le nom.
Les dépendances fonctionnelles révèlent des problèmes de redondance.
Si vous avez un tableau où order_id → customer_name, mais que vous stockez le nom du client dans chaque ligne de commande, vous avez une redondance. Le nom du client dépend de son identifiant, et non du numéro de commande.
La préservation des dépendances signifie que vos tableaux normalisés conservent toutes les dépendances fonctionnelles d'origine. Lorsque vous divisez un tableau lors de la normalisation, vous ne devez pas perdre la possibilité d'appliquer les règles métier qui existaient dans le tableau d'origine.
La garantie de décomposition sans perte ( ) vous permet de reconstruire le tableau d'origine en joignant les tableaux normalisés. Vous ne perdez aucune information lorsque vous divisez des tableaux : les jointures restituent exactement les mêmes données que celles avec lesquelles vous avez commencé.
Ces concepts fonctionnent ensemble : les dépendances fonctionnelles identifient ce qui doit être séparé, tandis que la préservation des dépendances et la décomposition sans perte garantissent que rien n'est endommagé au cours du processus.
La compréhension de ces relations vous aide à prendre des décisions de normalisation judicieuses qui améliorent votre base de données sans en altérer les fonctionnalités.
Passons maintenant en revue le processus de normalisation proprement dit, en commençant par des données désordonnées et en les transformant étape par étape. Chaque forme normale s'appuie sur la précédente, il n'est donc pas possible de passer directement de données non normalisées à la 3NF.
La première forme normale élimine les groupes répétitifs et garantit que chaque colonne contient des valeurs atomiques. Pour en savoir plus, veuillez consulter notre guide détaillé sur la première forme normale (1NF).
Les valeurs atomiques signifient que chaque cellule contient exactement une information : pas de listes, pas de valeurs séparées par des virgules, pas de points de données multiples entassés dans un seul champ. C'est la base qui rend tout le reste possible.
Voici ce qui enfreint la 1NF :
CREATE TABLE orders_bad (
order_id INT,
customer_name VARCHAR(100),
products VARCHAR(500),
quantities VARCHAR(50)
);
Image 2 - Tableau qui ne respecte pas la 1NF
Les colonnes « products » et « quantities » contiennent plusieurs valeurs séparées par des virgules. Il n'est pas facile de rechercher « toutes les commandes contenant des ordinateurs portables » ou de calculer les quantités totales sans analyse de chaîne.
Pour convertir cela en 1NF, séparez les groupes répétitifs en lignes distinctes :
-- First normal form (1NF)
CREATE TABLE orders_1nf (
order_id INT,
customer_name VARCHAR(100),
product VARCHAR(100),
quantity INT
);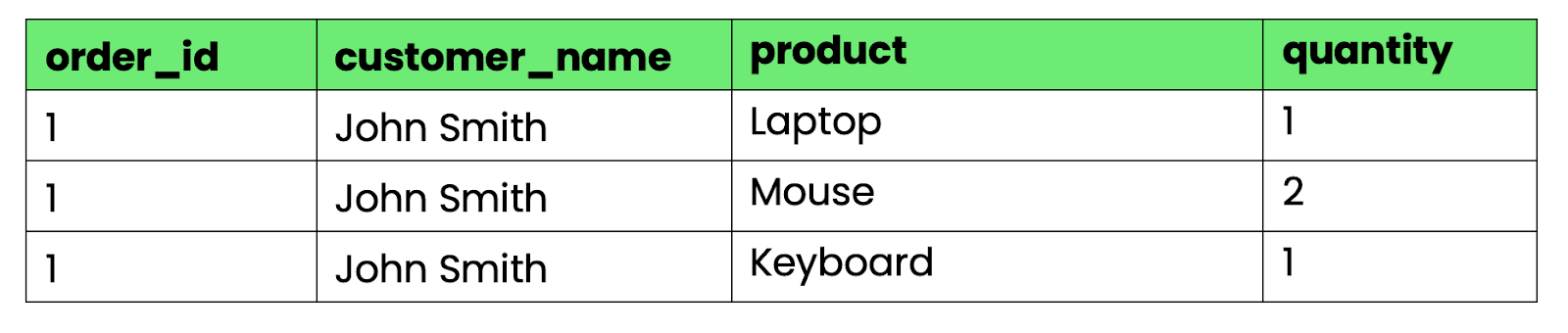
Image 3 - Tableau conforme à la 1NF
À présent, chaque cellule contient exactement une valeur. Vous pouvez interroger, trier et agréger les données à l'aide d'opérations SQL standard.
La deuxième forme normale supprime les dépendances partielles, c'est-à-dire lorsque des colonnes non clés dépendent uniquement d'une partie d'une clé primaire composite.
La deuxième forme normale (2NF) est plus complexe qu'il n'y paraît. Pour en savoir plus sur l', veuillez consulter notre guide détaillé.
Un tableau est en 2NF s'il est en 1NF et si chaque colonne non clé dépend de la clé primaire entière, et non d'une partie seulement.
Notre tableau 1NF présente un problème. Si nous utilisons order_id et product comme clé primaire composite, customer_name dépend uniquement de order_id, et non du produit. Cela crée une redondance : le nom du client est répété pour chaque produit d'une commande.
-- Still has partial dependencies
-- customer_name depends only on order_id, not on (order_id, product)
CREATE TABLE orders_1nf (
order_id INT,
customer_name VARCHAR(100), -- Partial dependency!
product VARCHAR(100),
quantity INT,
PRIMARY KEY (order_id, product)
);Pour obtenir la 2NF, divisez le tableau en fonction des dépendances :
-- Orders table (customer info depends on order_id)
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_name VARCHAR(100)
);
-- Order items table (quantity depends on both order_id and product)
CREATE TABLE order_items (
order_id INT,
product VARCHAR(100),
quantity INT,
PRIMARY KEY (order_id, product),
FOREIGN KEY (order_id) REFERENCES orders(order_id)
);Désormais, l'customer_name n'apparaît qu'une seule fois par commande, ce qui élimine toute redondance. Chaque tableau comporte des colonnes qui dépendent de la clé primaire complète.
La troisième forme normale élimine les dépendances transitives, qui se produisent lorsque des colonnes non clés dépendent d'autres colonnes non clés au lieu de laclé primaire. Explorez la troisième forme normale (3NF) au-delà des bases.
Une dépendance transitive existe lorsque la « colonne A » détermine la « colonne B » et que la « colonne B » détermine la « colonne C », créant ainsi une dépendance indirecte de A à C.
Élargissons notre tableau des commandes avec les coordonnées des clients :
-- Has transitive dependencies
CREATE TABLE orders_2nf (
order_id INT PRIMARY KEY,
customer_name VARCHAR(100),
customer_city VARCHAR(50),
customer_state VARCHAR(50),
customer_zip VARCHAR(10)
);Voici le problème : customer_name → customer_city et customer_city → customer_state. L'État dépend de la ville, pas directement de l'ordre. Cela crée une redondance : chaque commande provenant de la même ville répète les informations relatives à l'état.
Pour obtenir la 3NF, supprimez les dépendances transitives en créant des tableaux distincts :
-- Customers table (removes transitive dependencies)
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
customer_name VARCHAR(100),
city_id INT,
FOREIGN KEY (city_id) REFERENCES cities(city_id)
);
-- Cities table
CREATE TABLE cities (
city_id INT PRIMARY KEY,
city_name VARCHAR(50),
state VARCHAR(50),
zip VARCHAR(10)
);
-- Orders table (now references customer, not customer details)
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
order_date DATE,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);Désormais, toutes les informations géographiques sont regroupées en un seul endroit. Si une ville change d'État (ce qui est rare mais possible), vous mettez à jour une ligne au lieu de rechercher toutes les commandes provenant de cette ville.
Chaque forme normale résout des problèmes de redondance spécifiques tout en conservant la possibilité de reconstruire vos données d'origine à l'aide de jointures.
Les trois premières formes normales permettent de traiter la plupart des problèmes rencontrés dans les bases de données réelles, mais certains cas particuliers nécessitent une normalisation plus poussée. Ces formes avancées traitent des problèmes de dépendance spécifiques que la 3NF ne peut pas résoudre.
BCNF corrige un problème subtil que 3NF ne détecte pas : lorsqu'un tableau comporte des clés candidates qui se chevauchent.
La 3NF permet aux colonnes non clés de dépendre des clés candidates, mais la BCNF est plus stricte. Dans le BCNF, chaque déterminant (une colonne qui détermine une autre colonne) doit être une superclé, soit une clé primaire, soit une clé candidate.
Voici où la 3NF présente des lacunes :
-- Table in 3NF but violates BCNF
CREATE TABLE course_instructors (
student_id INT,
course VARCHAR(50),
instructor VARCHAR(50),
PRIMARY KEY (student_id, course)
);Les règles métier sont les suivantes :
Cela crée des dépendances vers course → instructor et instructor → course. (student_id, course) et (student_id, instructor) sont tous deux des clés candidates, mais course et instructor se déterminent mutuellement sans être eux-mêmes des superclés.
Le problème apparaît lorsque vous essayez d'ajouter un nouvel instructeur sans étudiants. Vous ne pouvez pas insérer « Le professeur Smith enseigne la conception de bases de données » sans ajouter également un étudiant à ce cours.
Pour atteindre le BCNF, décomposez en fonction de la dépendance problématique :
-- BCNF solution
CREATE TABLE course_assignments (
course VARCHAR(50) PRIMARY KEY,
instructor VARCHAR(50) UNIQUE
);
CREATE TABLE student_enrollments (
student_id INT,
course VARCHAR(50),
PRIMARY KEY (student_id, course),
FOREIGN KEY (course) REFERENCES course_assignments(course)
);Vous pouvez désormais ajouter des formateurs sans étudiants, et la structure de la base de données correspond exactement aux règles métier.
La 4NF élimine les dépendances multivaluées, c'est-à-dire lorsqu'une colonne détermine plusieurs ensembles de valeurs indépendants.
Une dépendance à valeurs multiples existe lorsque la « colonne A » détermine plusieurs valeurs dans la « colonne B » et que ces valeurs sont indépendantes des autres colonnes du tableau.
Veuillez examiner ce tableau qui suit le cursus et les loisirs des étudiants :
-- Violates 4NF due to multi-valued dependencies
CREATE TABLE student_info (
student_id INT,
skill VARCHAR(50),
hobby VARCHAR(50),
PRIMARY KEY (student_id, skill, hobby)
);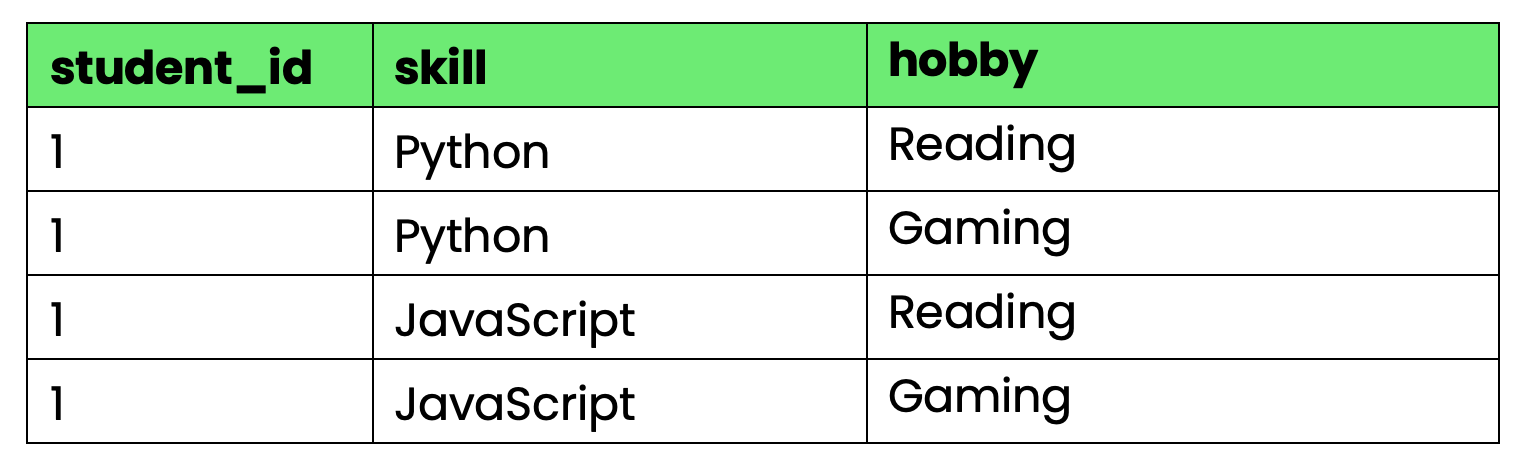
Image 4 - Tableau qui ne respecte pas la 4NF
Le problème : student_id détermine à la fois les compétences et les loisirs, mais les compétences et les loisirs sont indépendants les uns des autres. Lorsque l'élève 1 apprend une nouvelle compétence, vous devez créer des lignes pour chaque combinaison de loisirs. Lorsqu'ils se lancent dans un nouveau passe-temps, vous avez besoin de lignes pour chaque combinaison de compétences.
Cela crée une redondance considérable à mesure que le nombre de compétences et de loisirs augmente.
Pour atteindre la 4NF, séparez les dépendances multivaluées indépendantes :
-- 4NF solution
CREATE TABLE student_skills (
student_id INT,
skill VARCHAR(50),
PRIMARY KEY (student_id, skill)
);
CREATE TABLE student_hobbies (
student_id INT,
hobby VARCHAR(50),
PRIMARY KEY (student_id, hobby)
);Vous pouvez désormais ajouter des compétences et des loisirs de manière indépendante sans créer d'explosions de produits cartésiens.
La forme normale 5NF (Project-Join Normal Form) élimine les dépendances de jointure : relations complexes qui nécessitent trois tableaux ou plus pour reconstruire les données sans perte.
Une dépendance de jointure existe lorsque vous ne pouvez pas reconstruire le tableau d'origine en joignant deux tableaux décomposés, mais que vous pouvez le reconstruire en joignant trois tableaux ou plus.
Veuillez prendre en considération les fournisseurs, les pièces et les projets en appliquant la règle suivante : « Un fournisseur ne peut fournir une pièce pour un projet que s'il fournit cette pièce ET travaille sur ce projet. »
-- Original table with join dependency
CREATE TABLE supplier_part_project (
supplier_id INT,
part_id INT,
project_id INT,
PRIMARY KEY (supplier_id, part_id, project_id)
);Pour atteindre la 5NF, décomposez en trois relations binaires :
-- 5NF decomposition
CREATE TABLE supplier_parts (supplier_id INT, part_id INT);
CREATE TABLE supplier_projects (supplier_id INT, project_id INT);
CREATE TABLE project_parts (project_id INT, part_id INT);Vous ne pouvez reconstruire des combinaisons fournisseur-pièce-projet valides qu'en joignant les trois tableaux, ce qui applique la règle métier au niveau du schéma.
6NF pousse la normalisation à l'extrême en plaçant chaque attribut dans son propre tableau avec des clés temporelles.
6NF est conçu pour les entrepôts de données et les bases de données temporelles où vous devez suivre l'évolution de chaque attribut au fil du temps de manière indépendante.
-- 6NF example for temporal data
CREATE TABLE customer_names (
customer_id INT,
name VARCHAR(100),
valid_from DATE,
valid_to DATE
);
CREATE TABLE customer_addresses (
customer_id INT,
address VARCHAR(200),
valid_from DATE,
valid_to DATE
);Cela vous permet de suivre quand chaque attribut a été modifié sans affecter les autres, mais cela rend les requêtes complexes et est rarement utilisé en dehors des systèmes de bases de données temporelles spécialisées.
La plupart des applications s'arrêtent au niveau 3NF ou BCNF. Ces formes avancées résolvent des cas particuliers, mais ajoutent une complexité qui n'est pas justifiée pour les applications commerciales classiques.
Veuillez approfondir vos connaissances en matière de bases de données et de SQL grâce à ces cours.
Cours
Cours
Cours
blog
Kurtis Pykes
15 min
blog
Zoumana Keita
15 min
Tutoriel
Samuel Shaibu
Tutoriel
Moez Ali
Tutoriel
Derrick Mwiti
Tutoriel

