
Kurs
Datenbearbeitung in SQL
4 Std.
324.1K
Wenn du nie wieder mit inkonsistenten, doppelten Daten rumschnüffeln willst, ist Datenbank-Normalisierung genau das Richtige für dich.
Du kennst das frustrierende Gefühl, wenn du Kundendaten in einer Tabelle aktualisierst und dann feststellst, dass veraltete Versionen in fünf anderen Tabellen verstreut sind. Deine Abfragen liefern widersprüchliche Ergebnisse, deine Berichte zeigen unterschiedliche Zahlen, je nachdem, aus welcher Tabelle du sie ziehst, und du verbringst Stunden damit, Datenintegritätsprobleme zu beheben, die gar nicht existieren sollten. Diese Probleme werden mit zunehmender Größe deiner Datenbank immer größer.
Die Datenbank-Normalisierung macht Schluss mit solchen Problemen, indem sie deine Daten nach bewährten mathematischen Prinzipien organisiert. Der Prozess nutzt Normalformen, um sicherzustellen, dass jede Information genau an einem Ort gespeichert ist, wodurch deine Datenbank zuverlässig und effizient bleibt.
Ich zeige dir den kompletten Normalisierungsprozess, von den Grundlagen bis hin zu fortgeschrittenen Normalformen, mit praktischen Beispielen, die unübersichtliche Daten in übersichtliche, pflegbare Datenbankstrukturen verwandeln.
Normalisierung verhindert, dass deine Datenbank zu einem Wartungsalbtraum wird. Schauen wir mal, warum die richtige Normalisierung für echte Anwendungen wichtig ist.
Redundanz ist der heimliche Feind der Datenbankleistung. Wenn du dieselben Infos an mehreren Orten speicherst, verschwendest du nicht nur Speicherplatz, sondern riskierst auch, dass deine App-Logik durch Inkonsistenzen durcheinandergerät.
Ohne Normalisierung musst du für die Aktualisierung der Adresse eines Kunden alle Tabellen durchsuchen, in denen Adressdaten gespeichert sind. Wenn du eins vergisst, zeigen deine Berichte widersprüchliche Infos. Deine Benutzer sehen auf verschiedenen Bildschirmen unterschiedliche Adressen. Deine Analysen werden unzuverlässig.
Die Normalisierung behebt das, indem sie sicherstellt, dass jedes Datenelement genau an einem Ort gespeichert wird. Wenn du die Adresse des Kunden aktualisierst, wird sie automatisch überall geändert, weil alles auf dieselbe Quelle verweist.
Integrität wird unverwüstlich, wenn du sie richtig normalisierst. Fremdschlüsselbeschränkungen verhindern verwaiste Datensätze. Du kannst keinen Kunden löschen, der noch aktive Bestellungen hat. Deine Datenbank hält sich an die Geschäftsregeln auf Datenebene, nicht nur im Anwendungscode.
Das heißt weniger Fehler, sauberer Code und Programme, die auch dann wie erwartet funktionieren, wenn mehrere Systeme auf dieselben Daten zugreifen.
Änderungsanomalien verschwinden bei korrekter Normalisierung. Das passiert, wenn du Daten einfügst, aktualisierst oder löschst und dabei Inkonsistenzen verursachst oder komplizierte Workarounds erforderlich machst.
Durch Einfügefehler musst du Dummy-Daten hinzufügen, nur um einen Datensatz zu erstellen. Bei Aktualisierungsanomalien musst du dieselben Infos in mehreren Zeilen ändern. Beim Löschen von Anomalien werden mehr Infos gelöscht als beabsichtigt, wenn du einen einzelnen Datensatz löschst.
Normalisierte Datenbanken machen Schluss mit diesen Problemen, indem sie die Daten so organisieren, dass jede Info nur einmal vorkommt.
Die Leistung und Skalierbarkeit werden besser, wenn deine Datenbankstruktur übersichtlich ist. Normalisierte Tabellen sind normalerweise kleiner, was schnellere Abfragen und eine bessere Cache-Nutzung bedeutet. Indizes funktionieren besser bei kleineren, fokussierten Tabellen.
Deine Datenbank kann horizontal skaliert werden, weil normalisierte Daten klare Grenzen haben. Du kannst Tabellen logisch partitionieren, ohne Infos über Shards zu duplizieren.
In normalisierten Datenbanken ist die Sicherheit einfacher zu verwalten. Du kannst den Zugriff auf Tabellen sicher regeln, weil sensible Daten an bestimmten, klar definierten Orten gespeichert sind. Du musst dir keine Sorgen machen, dass Kreditkartennummern von Kunden in unerwarteten Tabellen versteckt sind.
Auch die Audit-Trails sind übersichtlicher – du weißt immer genau, wo Änderungen vorgenommen wurden, und kannst sie auf einem Lernpfad verfolgen, ohne dich durch überflüssige Daten in deinem Schema wühlen zu müssen.
Kurz gesagt, die Normalisierung macht aus chaotischen Daten eine zuverlässige Basis, die mit deiner Anwendung mitwächst.
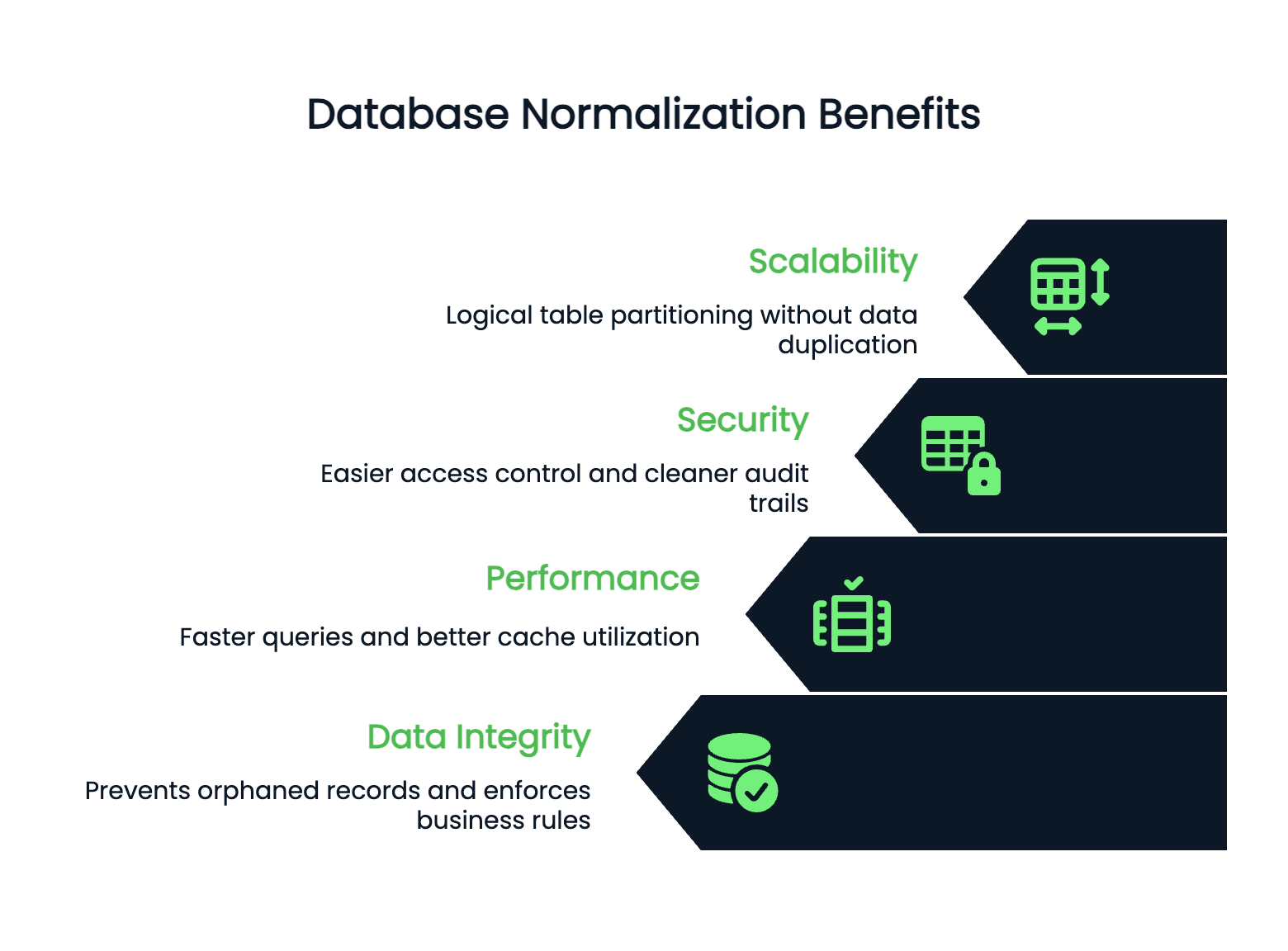
Schauen wir mal, was man für die Normalisierung braucht.
Bevor du mit der Normalisierung von Tabellen anfängst, solltest du wissen, wie das Ganze funktioniert. Lass uns die wichtigsten Sachen durchgehen, die dir bei deinen Entscheidungen helfen werden.
Schlüssel sind das A und O beim Entwerfen relationaler Datenbanken – sie identifizieren Datensätze und verbinden Tabellen miteinander.
Ein Primärschlüssel t ein eindeutiges ID für jede Zeile in einer Tabelle. Keine zwei Zeilen dürfen denselben Primärschlüsselwert haben, und dieser darf nicht null sein. Stell dir das wie eine Sozialversicherungsnummer für deine Daten vor – jeder Datensatz hat genau eine, und es gibt keine Duplikate.
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
email VARCHAR(255),
name VARCHAR(100)
);Hier ist „ customer_id “ der Primärschlüssel. Jeder Kunde bekommt eine eindeutige ID, die du verwenden kannst, um diesen bestimmten Kunden in anderen Tabellen zu finden.
Ein Kandidatenschlüssel ist eine Spalte (oder eine Kombination von Spalten), die als Primärschlüssel dienen könnte. Deine Tabelle „ customers “ könnte sowohl „ customer_id “ als auch „ email “ als Kandidatenschlüssel haben, da beide Kunden eindeutig identifizieren. Du wählst eins als Primärschlüssel aus, und die anderen bleiben Kandidatenschlüssel.
Fremdschlüssel verbinden Tabellen miteinander. Sie verweisen auf den Primärschlüssel einer anderen Tabelle und stellen Verbindungen her, die die Datenintegrität aufrechterhalten.
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
order_date DATE,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);Der Feld „ customer_id “ in der Tabelle „ orders “ ist ein Fremdschlüssel. Sie muss mit einem „ customer_id ” übereinstimmen, der in der Tabelle „ customers ” vorhanden ist. Das verhindert, dass Bestellungen verloren gehen, und stellt sicher, dass jede Bestellung zu einem echten Kunden gehört.
Schlüssel sorgen dafür, dass Geschäftsregeln auf Datenbankebene eingehalten werden, was deine Daten zuverlässiger macht als eine Validierung nur auf Anwendungsebene.
Funktionale Abhängigkeiten zeigen, wie Spalten in einer Tabelle miteinander verbunden sind. Sie sind die mathematische Grundlage, die Normalisierungsentscheidungen vorantreibt.
Eine funktionale Abhängigkeit ist da, wenn der Wert einer Spalte den Wert einer anderen Spalte bestimmt. Wir schreiben das als „ A → B ”, was so viel heißt wie „A bestimmt B” oder „B hängt von A ab”.
customer_id → email In einer Tabelle „ customers “ heißt die Tabelle „customer_email“, weil jede Kunden-ID genau einer E-Mail-Adresse zugeordnet ist. Wenn du die Kunden-ID kennst, kannst du die E-Mail ganz sicher finden.

Bild 1 – Beispiel für funktionale Abhängigkeit
Hier sind „ customer_id → email “ und „ customer_id → name “, weil die Kunden-ID sowohl die E-Mail-Adresse als auch den Namen bestimmt.
Funktionale Abhängigkeiten zeigen, wo es Probleme mit Redundanz gibt.
Wenn du eine Tabelle hast, in der „ order_id → customer_name ” steht, du aber den Kundennamen in jeder Bestellzeile speicherst, hast du Redundanz. Der Name des Kunden hängt von seiner ID ab, nicht von der Bestellnummer.
Mit der Abhängigkeitserhaltungs, bleiben in deinen normalisierten Tabellen alle ursprünglichen funktionalen Abhängigkeiten erhalten. Wenn du eine Tabelle während der Normalisierung aufteilst, solltest du nicht die Möglichkeit verlieren, die in der ursprünglichen Tabelle vorhandenen Geschäftsregeln durchzusetzen.
Die verlustfreie Zerlegungs garantiert, dass du die ursprüngliche Tabelle durch Zusammenführen der normalisierten Tabellen wiederherstellen kannst. Beim Teilen von Tabellen gehen keine Infos verloren – die Verknüpfungen bringen genau die Daten zurück, mit denen du angefangen hast.
Diese Konzepte hängen zusammen: Funktionale Abhängigkeiten zeigen, was getrennt werden muss, während die Erhaltung von Abhängigkeiten und die verlustfreie Zerlegung dafür sorgen, dass dabei nichts kaputt geht.
Wenn du diese Zusammenhänge verstehst, kannst du kluge Entscheidungen zur Normalisierung treffen, die deine Datenbank verbessern, ohne dass dabei Funktionen verloren gehen.
Lass uns jetzt den eigentlichen Normalisierungsprozess durchgehen, beginnend mit unordentlichen Daten, die wir Schritt für Schritt umwandeln. Jede Normalform baut auf der vorherigen auf, sodass du nicht direkt von unnormalisierten Daten zur 3NF springen kannst.
Die erste Normalform räumt wiederholte Gruppen auf und sorgt dafür, dass jede Spalte nur einzelne Werte hat. Mehr über „” erfährst du in unserem ausführlichen Leitfaden zur ersten Normalform (1NF).
Atomare Werte bedeuten, dass jede Zelle genau eine Information enthält – keine Listen, keine durch Kommas getrennten Werte, keine mehreren Datenpunkte, die in ein einziges Feld gepackt sind. Das ist die Basis, die alles andere möglich macht.
Hier ist, was gegen 1NF verstößt:
CREATE TABLE orders_bad (
order_id INT,
customer_name VARCHAR(100),
products VARCHAR(500),
quantities VARCHAR(50)
);
Bild 2 – Tabelle, die gegen 1NF verstößt
Die Spalten „ products “ und „ quantities “ haben mehrere Werte, die durch Kommas getrennt sind. Ohne String-Parsing kannst du nicht einfach „alle Bestellungen mit Laptops” abfragen oder Gesamtmengen berechnen.
Um das in 1NF umzuwandeln, teil die sich wiederholenden Gruppen in separate Zeilen auf:
-- First normal form (1NF)
CREATE TABLE orders_1nf (
order_id INT,
customer_name VARCHAR(100),
product VARCHAR(100),
quantity INT
);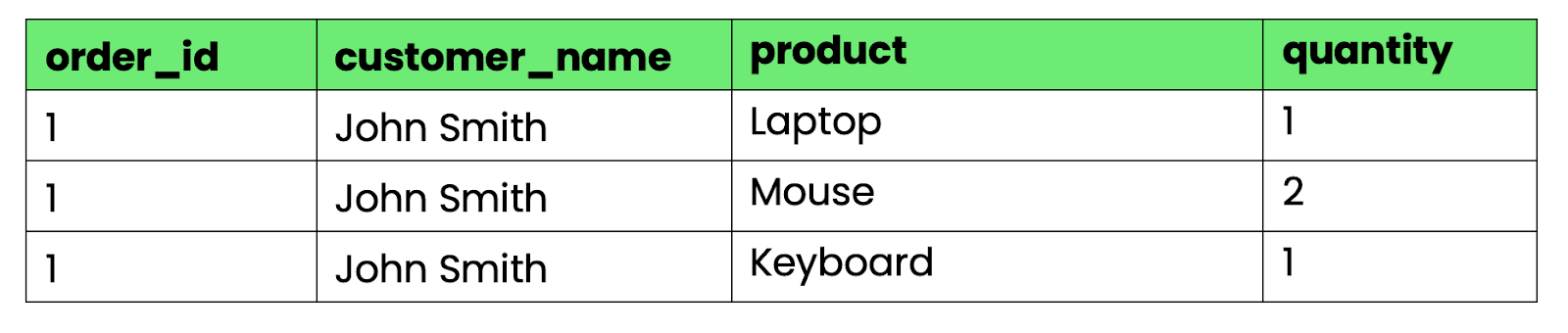
Bild 3 – Tabelle, die 1NF erfüllt
Jetzt hat jede Zelle genau einen Wert. Du kannst die Daten mit Standard-SQL-Operationen abfragen, sortieren und zusammenfassen.
Die zweite Normalform beseitigt Teilabhängigkeiten – wenn Spalten, die keine Schlüssel sind, nur von einem Teil eines zusammengesetzten Primärschlüssels abhängen.
Die zweite Normalform (2NF) hat mehr zu bieten, als man auf den ersten Blick sieht. Mehr Infos zu „“ findest du in unserem ausführlichen Leitfaden.
Eine Tabelle ist in 2NF, wenn sie in 1NF ist und jede Nicht-Schlüsselspalte vom ganzen Primärschlüssel abhängt, nicht nur von einem Teil davon.
Unsere 1NF-Tabelle hat ein Problem. Wenn wir „ order_id “ und „ product “ als zusammengesetzten Primärschlüssel verwenden, hängt „ customer_name “ nur von „ order_id “ ab, nicht vom Produkt. Das führt zu Redundanz – der Kundenname wird für jedes Produkt in einer Bestellung wiederholt.
-- Still has partial dependencies
-- customer_name depends only on order_id, not on (order_id, product)
CREATE TABLE orders_1nf (
order_id INT,
customer_name VARCHAR(100), -- Partial dependency!
product VARCHAR(100),
quantity INT,
PRIMARY KEY (order_id, product)
);Um 2NF zu erreichen, teil die Tabelle anhand der Abhängigkeiten auf:
-- Orders table (customer info depends on order_id)
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_name VARCHAR(100)
);
-- Order items table (quantity depends on both order_id and product)
CREATE TABLE order_items (
order_id INT,
product VARCHAR(100),
quantity INT,
PRIMARY KEY (order_id, product),
FOREIGN KEY (order_id) REFERENCES orders(order_id)
);Jetzt kommt „ customer_name “ nur noch einmal pro Bestellung vor, was Redundanzen vermeidet. Jede Tabelle hat Spalten, die vom gesamten Primärschlüssel abhängen.
Die dritte Normalform beseitigt transitive Abhängigkeiten, die auftreten, wenn Nicht-Schlüsselspalten von anderen Nicht-Schlüsselspalten statt vom Primärschlüssel abhängen. Tauch ein in die dritte Normalform (3NF) und lerne mehr als nur die Grundlagen.
Eine transitive Abhängigkeit ist da, wenn „Spalte A“ „Spalte B“ bestimmt und „Spalte B“ „Spalte C“ bestimmt, sodass eine indirekte Abhängigkeit von A zu C entsteht.
Erweitern wir unsere Tabelle „Bestellungen” um die Adressdaten der Kunden:
-- Has transitive dependencies
CREATE TABLE orders_2nf (
order_id INT PRIMARY KEY,
customer_name VARCHAR(100),
customer_city VARCHAR(50),
customer_state VARCHAR(50),
customer_zip VARCHAR(10)
);Hier ist das Problem: customer_name → customer_city und customer_city → customer_state. Der Staat hängt von der Stadt ab, nicht direkt von der Bestellung. Das führt zu Redundanz – bei jeder Bestellung aus derselben Stadt werden die Angaben zum Bundesland doppelt angegeben.
Um 3NF zu erreichen, musst du transitive Abhängigkeiten loswerden, indem du separate Tabellen erstellst:
-- Customers table (removes transitive dependencies)
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
customer_name VARCHAR(100),
city_id INT,
FOREIGN KEY (city_id) REFERENCES cities(city_id)
);
-- Cities table
CREATE TABLE cities (
city_id INT PRIMARY KEY,
city_name VARCHAR(50),
state VARCHAR(50),
zip VARCHAR(10)
);
-- Orders table (now references customer, not customer details)
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
order_date DATE,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);Jetzt sind alle geografischen Infos an einem Ort. Wenn eine Stadt den Bundesstaat wechselt (selten, aber möglich), musst du nur eine Zeile aktualisieren, anstatt alle Bestellungen aus dieser Stadt durchsuchen zu müssen.
Jede Normalform beseitigt bestimmte Redundanzprobleme und sorgt dafür, dass du deine Originaldaten über Verknüpfungen wieder zusammenfügen kannst.
Die ersten drei Normalformen klären die meisten echten Datenbankprobleme, aber manchmal braucht man eine genauere Normalisierung. Diese fortgeschrittenen Formen kümmern sich um bestimmte Abhängigkeitsprobleme, die mit 3NF nicht gelöst werden können.
BCNF behebt ein kleines Problem, das 3NF übersieht: wenn sich in einer Tabelle Kandidatenschlüssel überschneiden.
3NF lässt zu, dass Spalten, die keine Schlüssel sind, von Kandidaten-Schlüsseln abhängen, aber BCNF ist da strenger. In BCNF muss jeder Determinante (eine Spalte, die eine andere Spalte bestimmt) ein Superkey sein – entweder ein Primärschlüssel oder ein Kandidatenschlüssel.
Hier bricht die 3NF zusammen:
-- Table in 3NF but violates BCNF
CREATE TABLE course_instructors (
student_id INT,
course VARCHAR(50),
instructor VARCHAR(50),
PRIMARY KEY (student_id, course)
);Die Geschäftsregeln lauten:
Dadurch werden Abhängigkeiten zu „ course → instructor “ und „ instructor → course “ erstellt. Sowohl „ (student_id, course) ” als auch „ (student_id, instructor) ” sind Kandidatenschlüssel, aber „ course ” und „ instructor ” bestimmen sich gegenseitig, ohne selbst Superkeys zu sein.
Das Problem tritt auf, wenn du versuchst, einen neuen Dozenten ohne Studierende hinzuzufügen. Du kannst nicht einfach „Professor Smith unterrichtet Datenbankdesign” hinzufügen, ohne auch einen Studenten für diesen Kurs hinzuzufügen.
Um BCNF zu erreichen, zerlegst du die Abhängigkeiten anhand der problematischen Abhängigkeit:
-- BCNF solution
CREATE TABLE course_assignments (
course VARCHAR(50) PRIMARY KEY,
instructor VARCHAR(50) UNIQUE
);
CREATE TABLE student_enrollments (
student_id INT,
course VARCHAR(50),
PRIMARY KEY (student_id, course),
FOREIGN KEY (course) REFERENCES course_assignments(course)
);Jetzt kannst du Lehrer ohne Schüler hinzufügen, und die Datenbankstruktur passt genau zu den Geschäftsregeln.
4NF beseitigt mehrwertige Abhängigkeiten – also wenn eine Spalte mehrere unabhängige Wertesätze bestimmt.
Eine mehrwertige Abhängigkeit liegt vor, wenn „Spalte A“ mehrere Werte in „Spalte B“ bestimmt und diese Werte unabhängig von anderen Spalten in der Tabelle sind.
Schau dir mal diese Tabelle an, in der die Fähigkeiten und Hobbys von Schülern erfasst sind:
-- Violates 4NF due to multi-valued dependencies
CREATE TABLE student_info (
student_id INT,
skill VARCHAR(50),
hobby VARCHAR(50),
PRIMARY KEY (student_id, skill, hobby)
);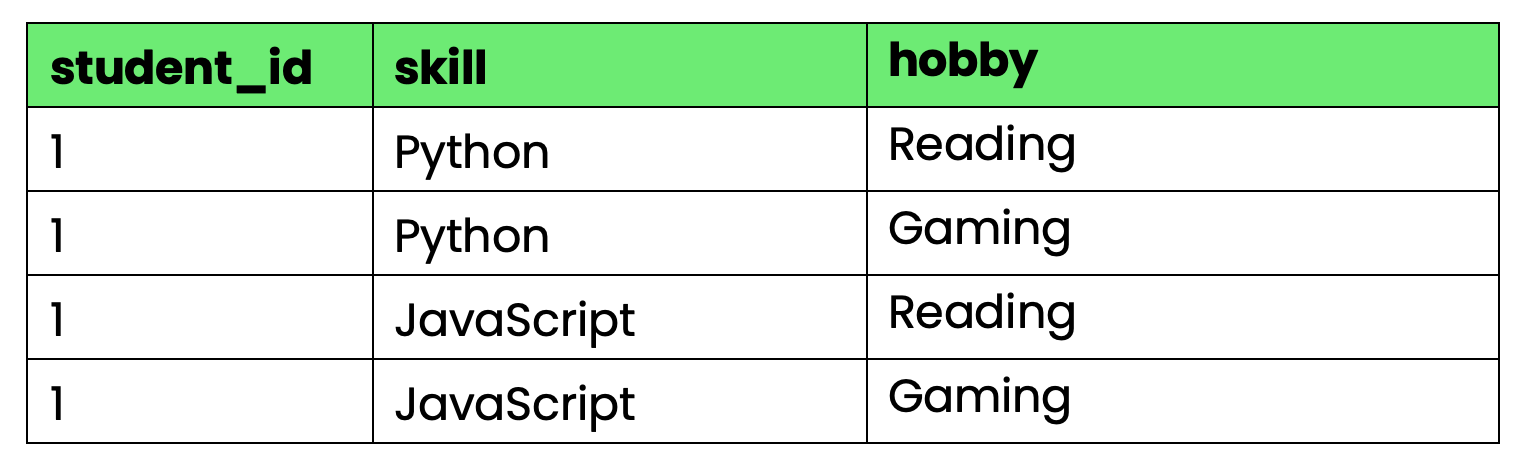
Bild 4 – Tabelle, die gegen die 4NF verstößt
Das Problem: „ student_id “ (Fähigkeiten und Hobbys) legt sowohl Fähigkeiten als auch Hobbys fest, aber Fähigkeiten und Hobbys sind voneinander unabhängig. Wenn Schüler 1 eine neue Fähigkeit lernt, musst du für jede Hobbykombination eine Zeile erstellen. Wenn sie ein neues Hobby anfangen, brauchst du Reihen für jede Kombination von Fähigkeiten.
Das führt zu einer explosiven Redundanz, wenn die Anzahl der Fähigkeiten und Hobbys wächst.
Um 4NF zu erreichen, trennst du die unabhängigen mehrwertigen Abhängigkeiten:
-- 4NF solution
CREATE TABLE student_skills (
student_id INT,
skill VARCHAR(50),
PRIMARY KEY (student_id, skill)
);
CREATE TABLE student_hobbies (
student_id INT,
hobby VARCHAR(50),
PRIMARY KEY (student_id, hobby)
);Jetzt kannst du Fähigkeiten und Hobbys ganz einfach hinzufügen, ohne dass du dabei alles durcheinander bringst.
5NF (Projekt-Join-Normalform) macht Join-Abhängigkeiten überflüssig: komplexe Beziehungen, bei denen man drei oder mehr Tabellen braucht, um Daten ohne Verluste wieder zusammenzufügen.
Eine Join-Abhängigkeit liegt vor, wenn du die ursprüngliche Tabelle nicht durch Verknüpfen zweier zerlegter Tabellen wiederherstellen kannst, aber durch Verknüpfen von drei oder mehr Tabellen.
Beachte bei Lieferanten, Teilen und Projekten diese Regel: „Ein Lieferant kann ein Teil nur dann für ein Projekt liefern, wenn er dieses Teil liefert UND an diesem Projekt arbeitet.“
-- Original table with join dependency
CREATE TABLE supplier_part_project (
supplier_id INT,
part_id INT,
project_id INT,
PRIMARY KEY (supplier_id, part_id, project_id)
);Um 5NF zu erreichen, zerlegst du das Ganze in drei binäre Beziehungen:
-- 5NF decomposition
CREATE TABLE supplier_parts (supplier_id INT, part_id INT);
CREATE TABLE supplier_projects (supplier_id INT, project_id INT);
CREATE TABLE project_parts (project_id INT, part_id INT);Du kannst gültige Lieferanten-Teil-Projekt-Kombinationen nur wiederherstellen, indem du alle drei Tabellen zusammenführst, wodurch die Geschäftsregel auf Schemaebene durchgesetzt wird.
6NF geht bei der Normalisierung richtig weit, indem jedes Attribut in eine eigene Tabelle mit temporären Schlüsseln kommt.
6NF ist für Data Warehouses und temporäre Datenbanken gedacht, wo du verfolgen musst, wie sich jedes Attribut im Laufe der Zeit unabhängig voneinander verändert.
-- 6NF example for temporal data
CREATE TABLE customer_names (
customer_id INT,
name VARCHAR(100),
valid_from DATE,
valid_to DATE
);
CREATE TABLE customer_addresses (
customer_id INT,
address VARCHAR(200),
valid_from DATE,
valid_to DATE
);So kannst du verfolgen, wann sich jedes Attribut geändert hat, ohne andere zu beeinflussen. Das macht Abfragen aber kompliziert und wird außerhalb spezieller temporärer Datenbanksysteme kaum benutzt.
Die meisten Anwendungen bleiben bei 3NF oder BCNF stehen. Diese fortgeschrittenen Formen lösen bestimmte Sonderfälle, machen das Ganze aber komplizierter, was sich für normale Geschäftsanwendungen nicht lohnt.
Lerne mit diesen Kursen mehr über Datenbanken und SQL!
Kurs
Kurs
Kurs
Tutorial
Moez Ali
Tutorial
Derrick Mwiti
Tutorial
Sejal Jaiswal
Tutorial
Matt Crabtree
Tutorial
Mark Pedigo
Tutorial
Javier Canales Luna
