
Cursus
Gegevens manipuleren in SQL
4 Hr
328.2K
Als je nooit meer te maken wilt hebben met inconsistente, redundante data, is database-normalisatie de manier om het aan te pakken.
Je kent de frustratie: klantinformatie bijwerken in één tabel om vervolgens verouderde versies terug te vinden in vijf andere. Je queries geven tegenstrijdige resultaten, je rapporten tonen verschillende cijfers afhankelijk van welke tabel je gebruikt, en je besteedt uren aan het debuggen van integriteitsproblemen die niet zouden moeten bestaan. Deze problemen nemen alleen maar toe naarmate je database groeit.
Database-normalisatie voorkomt deze hoofdpijn door je data te organiseren volgens beproefde wiskundige principes. Het proces gebruikt normale vormen om ervoor te zorgen dat elk gegeven precies op één plek bestaat, waardoor je database betrouwbaar en efficiënt wordt.
Ik laat je het volledige normalisatieproces zien, van basisconcepten tot geavanceerde normale vormen, met praktische voorbeelden die rommelige data omtoveren tot schone, onderhoudbare databasestructuren.
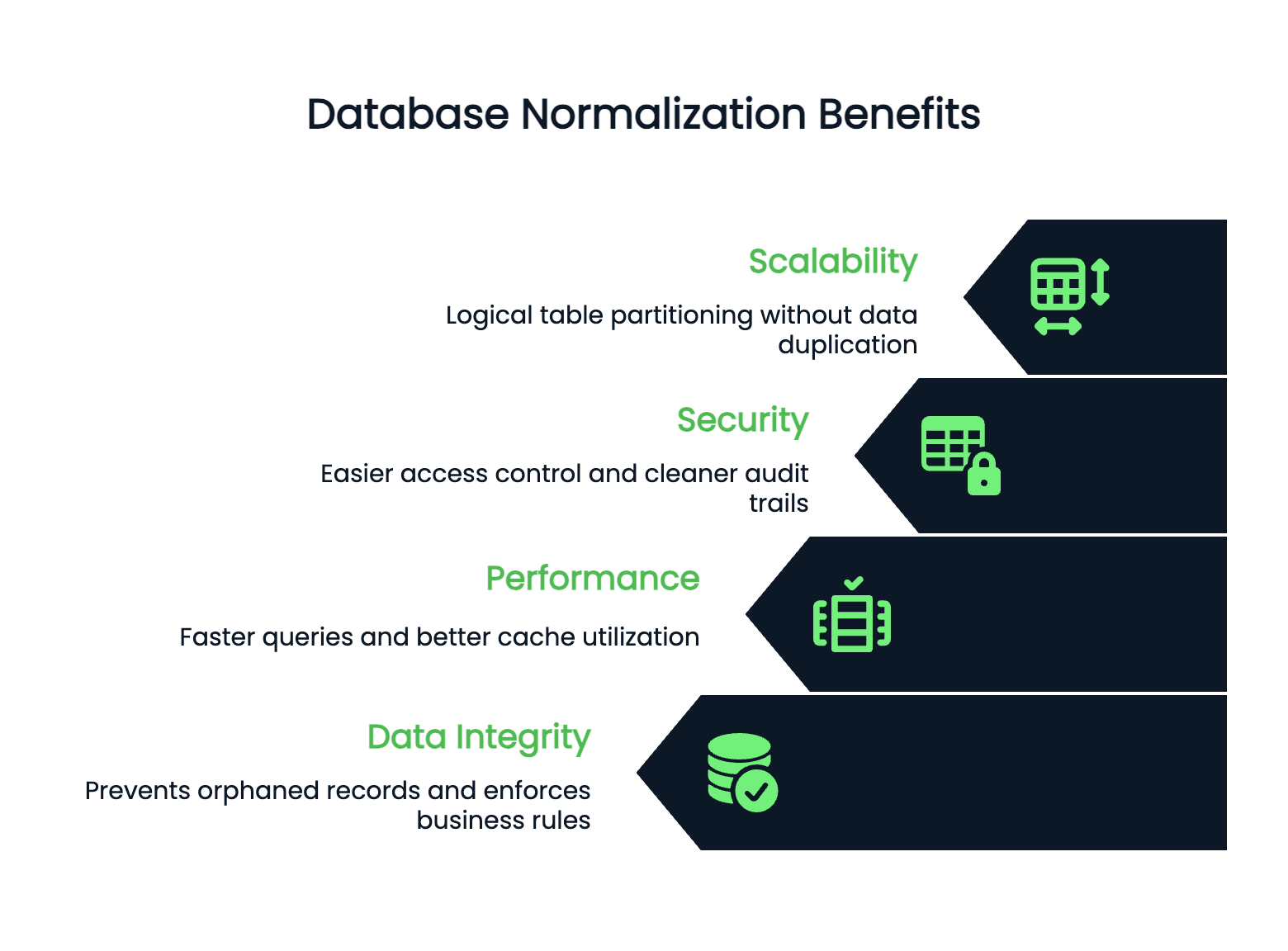
Normalisatie voorkomt dat je database een onderhoudsnachtmerrie wordt. Laten we kijken waarom goede normalisatie telt voor toepassingen in de echte wereld.
Redundantie is de stille killer van databaseprestaties. Als je dezelfde informatie op meerdere plekken opslaat, verspil je niet alleen opslagruimte – je creëert ook inconsistenties die je applicatielogica breken.
Zonder normalisatie betekent het bijwerken van het adres van een klant dat je elke tabel moet afspeuren die adresdata bevat. Sla je er één over, dan tonen je rapporten tegenstrijdige informatie. Je gebruikers zien verschillende adressen op verschillende schermen. Je analytics worden onbetrouwbaar.
Normalisatie lost dit op door te zorgen dat elk datapunt precies op één plek staat. Werk je dat klantenadres bij, dan verandert het overal automatisch, omdat alles naar dezelfde bron verwijst.
Integriteit wordt ijzersterk wanneer je correct normaliseert. Foreign key-constraints voorkomen verweesde records. Je kunt niet per ongeluk een klant verwijderen die nog actieve bestellingen heeft. Je database handhaaft bedrijfsregels op dataniveau, niet alleen in applicatiecode.
Dat betekent minder bugs, schonere code en applicaties die voorspelbaar werken, zelfs wanneer meerdere systemen dezelfde data benaderen.
Wijzigingsanomalieën verdwijnen met goede normalisatie. Die ontstaan wanneer je data invoegt, bijwerkt of verwijdert en zo inconsistenties creëert of complexe workarounds nodig hebt.
Insert-anomalieën dwingen je om nepdata toe te voegen om een record te kunnen aanmaken. Update-anomalieën vereisen dat je dezelfde informatie in meerdere rijen wijzigt. Delete-anomalieën verwijderen meer informatie dan bedoeld wanneer je één record verwijdert.
Genormaliseerde databases elimineren deze problemen door data zo te organiseren dat elk feit precies één keer voorkomt.
Prestaties en schaalbaarheid verbeteren wanneer je databasestructuur schoon is. Genormaliseerde tabellen zijn doorgaans kleiner, wat snellere queries en betere cachebenutting betekent. Indexen werken effectiever op kleinere, gefocuste tabellen.
Je database kan horizontaal schalen omdat genormaliseerde data duidelijke grenzen heeft. Je kunt tabellen logisch partitioneren zonder informatie te dupliceren over shards heen.
Beveiliging wordt eenvoudiger te beheren in genormaliseerde databases. Je kunt met vertrouwen op tabelniveau toegang regelen, omdat gevoelige data op specifieke, goed gedefinieerde plekken staat. Geen zorgen meer over creditcardnummers die in onverwachte tabellen rondzwerven.
Audittrails zijn ook schoner – je weet precies waar wijzigingen plaatsvinden en kunt ze volgen zonder te hoeven speuren in redundante data verspreid over je schema.
Kortom, normalisatie verandert chaotische data in een betrouwbare basis die met je applicatie meegroeit.
Laten we vervolgens kijken wat de randvoorwaarden voor normalisatie zijn.
Voordat je tabellen gaat normaliseren, moet je begrijpen wat normalisatie doet werken. We behandelen de essentiële concepten die je beslissingen tijdens het hele proces sturen.
Sleutels vormen de basis van relationeel databaseontwerp – ze identificeren records en verbinden tabellen met elkaar.
Een primaire sleutel identificeert elke rij in een tabel uniek. Geen twee rijen mogen dezelfde primaire sleutelwaarde hebben en die mag niet null zijn. Zie het als een burgerservicenummer voor je data – elk record krijgt er precies één en er bestaan geen duplicaten.
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
email VARCHAR(255),
name VARCHAR(100)
);Hier is customer_id de primaire sleutel. Elke klant krijgt een uniek ID dat je gebruikt om die specifieke klant vanuit andere tabellen te refereren.
Een kandidaatsleutel is elke kolom (of combinatie van kolommen) die als primaire sleutel zou kunnen dienen. Je customers-tabel kan zowel customer_id als email als kandidaatsleutels hebben, omdat beide klanten uniek identificeren. Je kiest er één als primaire sleutel; de rest blijft kandidaatsleutel.
Vreemde sleutels creëren relaties tussen tabellen. Ze verwijzen naar de primaire sleutel van een andere tabel en leggen verbindingen die de gegevensintegriteit bewaken.
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
order_date DATE,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);De customer_id in de orders-tabel is een vreemde sleutel. Die moet overeenkomen met een customer_id die bestaat in de customers-tabel. Dat voorkomt verweesde bestellingen en zorgt dat elke bestelling bij een echte klant hoort.
Sleutels handhaven bedrijfsregels op databaseniveau, waardoor je data betrouwbaarder is dan bij alleen validatie in de applicatie.
Functionele afhankelijkheden beschrijven hoe kolommen zich tot elkaar verhouden binnen een tabel. Ze zijn de wiskundige basis die normalisatiebeslissingen aandrijft.
Een functionele afhankelijkheid bestaat wanneer de waarde van de ene kolom de waarde van een andere kolom bepaalt. We noteren dit als A → B, wat betekent: "A bepaalt B" of "B hangt af van A".
In een customers-tabel geldt customer_id → email omdat elk klant-ID naar precies één e-mailadres verwijst. Als je het klant-ID weet, kun je het e-mailadres met zekerheid bepalen.

Afbeelding 1 - Voorbeeld van functionele afhankelijkheid
Hier geldt customer_id → email en customer_id → name omdat het klant-ID zowel het e-mailadres als de naam bepaalt.
Functionele afhankelijkheden onthullen redundantieproblemen.
Als je een tabel hebt waar order_id → customer_name geldt maar je de klantnaam in elke bestelrij opslaat, heb je redundantie. De klantnaam hangt af van het klant-ID, niet van het bestel-ID.
Behoud van afhankelijkheden betekent dat je genormaliseerde tabellen nog steeds alle oorspronkelijke functionele afhankelijkheden waarborgen. Wanneer je tijdens normalisatie een tabel opsplitst, mag je niet het vermogen verliezen om bedrijfsregels te afdwingen die in de originele tabel bestonden.
Verliesloze decompositie garandeert dat je de oorspronkelijke tabel kunt reconstrueren door de genormaliseerde tabellen te joinen. Je verliest geen informatie bij het splitsen – de joins leveren exact dezelfde data op waarmee je begon.
Deze concepten werken samen: functionele afhankelijkheden identificeren wat gescheiden moet worden, terwijl behoud van afhankelijkheden en verliesloze decompositie ervoor zorgen dat je niets breekt in het proces.
Door deze relaties te begrijpen, kun je slimme normalisatiebeslissingen nemen die je database verbeteren zonder functionaliteit te verliezen.
Laten we nu door het daadwerkelijke normalisatieproces lopen, beginnend met rommelige data en die stap voor stap transformeren. Elke normale vorm bouwt voort op de vorige, dus je kunt niet rechtstreeks van ongenormaliseerde data naar 3NF gaan.
De eerste normale vorm elimineert herhalende groepen en zorgt dat elke kolom atomaire waarden bevat. Lees er meer over in de diepgaande gids over First Normal Form (1NF).
Atomaire waarden betekenen dat elke cel precies één stukje informatie bevat – geen lijsten, geen door komma’s gescheiden waarden, geen meerdere datapunten in één veld gepropt. Dit is de basis die de rest mogelijk maakt.
Dit schendt 1NF:
CREATE TABLE orders_bad (
order_id INT,
customer_name VARCHAR(100),
products VARCHAR(500),
quantities VARCHAR(50)
);
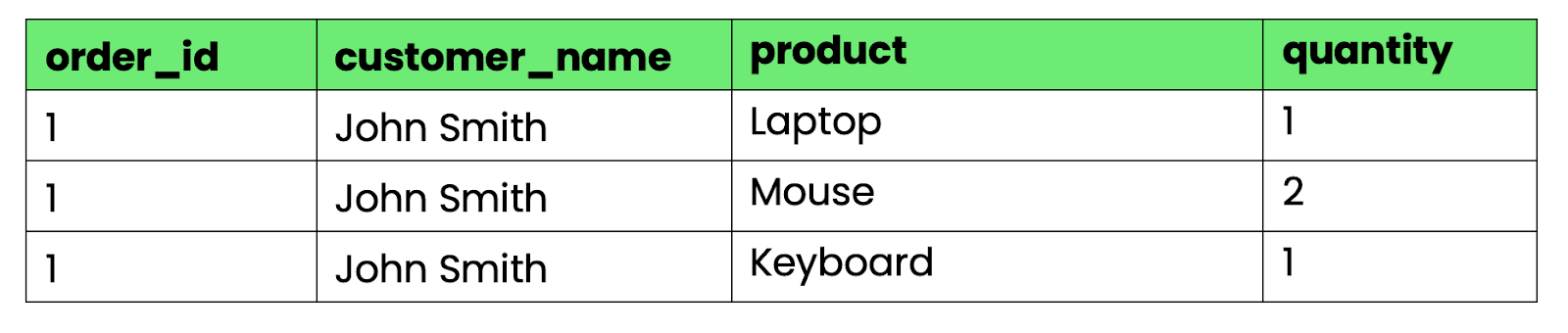
Afbeelding 2 - Tabel die 1NF schendt
De kolommen products en quantities bevatten meerdere waarden gescheiden door komma’s. Je kunt niet eenvoudig "alle bestellingen met laptops" opvragen of totale hoeveelheden berekenen zonder strings te parsen.
Om dit naar 1NF om te zetten, splits je de herhalende groepen op in afzonderlijke rijen:
-- First normal form (1NF)
CREATE TABLE orders_1nf (
order_id INT,
customer_name VARCHAR(100),
product VARCHAR(100),
quantity INT
);
Afbeelding 3 - Tabel die voldoet aan 1NF
Nu bevat elke cel precies één waarde. Je kunt de data met standaard SQL-bewerkingen opvragen, sorteren en aggregeren.
De tweede normale vorm verwijdert partiële afhankelijkheden – wanneer niet-sleutelkolommen slechts van een deel van een samengestelde primaire sleutel afhangen.
Er zit meer achter de Tweede Normale Vorm (2NF) dan je denkt. Lees meer in onze diepgaande gids.
Een tabel is in 2NF als hij in 1NF is en elke niet-sleutelkolom afhankelijk is van de volledige primaire sleutel, niet slechts van een deel ervan.
Onze 1NF-tabel heeft een probleem. Als we order_id en product als samengestelde primaire sleutel gebruiken, hangt customer_name alleen af van order_id, niet van het product. Dit creëert redundantie – de klantnaam herhaalt voor elk product in een bestelling.
-- Still has partial dependencies
-- customer_name depends only on order_id, not on (order_id, product)
CREATE TABLE orders_1nf (
order_id INT,
customer_name VARCHAR(100), -- Partial dependency!
product VARCHAR(100),
quantity INT,
PRIMARY KEY (order_id, product)
);Om 2NF te bereiken, splits je de tabel op basis van afhankelijkheden:
-- Orders table (customer info depends on order_id)
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_name VARCHAR(100)
);
-- Order items table (quantity depends on both order_id and product)
CREATE TABLE order_items (
order_id INT,
product VARCHAR(100),
quantity INT,
PRIMARY KEY (order_id, product),
FOREIGN KEY (order_id) REFERENCES orders(order_id)
);Nu komt customer_name nog maar één keer per bestelling voor, wat redundantie elimineert. Elke tabel heeft kolommen die van de volledige primaire sleutel afhangen.
De derde normale vorm elimineert transitieve afhankelijkheden, die ontstaan wanneer niet-sleutelkolommen afhangen van andere niet-sleutelkolommen in plaats van van de primaire sleutel. Duik dieper in de Third Normal Form (3NF) dan de basis.
Een transitieve afhankelijkheid bestaat wanneer “Kolom A” “Kolom B” bepaalt, en “Kolom B” “Kolom C” bepaalt, waardoor een indirecte afhankelijkheid van A naar C ontstaat.
Laten we onze ordertabel uitbreiden met adresgegevens van de klant:
-- Has transitive dependencies
CREATE TABLE orders_2nf (
order_id INT PRIMARY KEY,
customer_name VARCHAR(100),
customer_city VARCHAR(50),
customer_state VARCHAR(50),
customer_zip VARCHAR(10)
);Hier is het probleem: customer_name → customer_city, en customer_city → customer_state. De staat hangt af van de stad, niet direct van de bestelling. Dit creëert redundantie – elke bestelling uit dezelfde stad herhaalt de staatinformatie.
Om 3NF te bereiken, verwijder je transitieve afhankelijkheden door afzonderlijke tabellen te maken:
-- Customers table (removes transitive dependencies)
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
customer_name VARCHAR(100),
city_id INT,
FOREIGN KEY (city_id) REFERENCES cities(city_id)
);
-- Cities table
CREATE TABLE cities (
city_id INT PRIMARY KEY,
city_name VARCHAR(50),
state VARCHAR(50),
zip VARCHAR(10)
);
-- Orders table (now references customer, not customer details)
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
order_date DATE,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);Nu staan geografische gegevens op één plek. Als een stad van staat verandert (zeldzaam maar mogelijk), werk je één rij bij in plaats van elke bestelling uit die stad te moeten nalopen.
Elke normale vorm lost specifieke redundantieproblemen op, terwijl je nog steeds in staat blijft om je oorspronkelijke data via joins te reconstrueren.
De eerste drie normale vormen lossen de meeste databaseproblemen in de praktijk op, maar sommige randgevallen vereisen diepere normalisatie. Deze geavanceerde vormen behandelen specifieke afhankelijkheidskwesties die 3NF niet kan oplossen.
BCNF verhelpt een subtiel probleem dat 3NF mist: wanneer een tabel overlappende kandidaatsleutels heeft.
3NF staat toe dat niet-sleutelkolommen afhangen van kandidaatsleutels, maar BCNF is strenger. In BCNF moet elke determinant (een kolom die een andere kolom bepaalt) een superkey zijn – ofwel een primaire of een kandidaatsleutel.
Hier loopt 3NF spaak:
-- Table in 3NF but violates BCNF
CREATE TABLE course_instructors (
student_id INT,
course VARCHAR(50),
instructor VARCHAR(50),
PRIMARY KEY (student_id, course)
);De bedrijfsregels zijn:
Dit creëert afhankelijkheden course → instructor en instructor → course. Zowel (student_id, course) als (student_id, instructor) zijn kandidaatsleutels, maar course en instructor bepalen elkaar zonder zelf superkeys te zijn.
Het probleem verschijnt wanneer je een nieuwe docent zonder studenten wilt toevoegen. Je kunt "Professor Smith geeft Database Design" niet invoegen zonder ook een student aan dat vak toe te voegen.
Om BCNF te bereiken, decomponeer je op basis van de problematische afhankelijkheid:
-- BCNF solution
CREATE TABLE course_assignments (
course VARCHAR(50) PRIMARY KEY,
instructor VARCHAR(50) UNIQUE
);
CREATE TABLE student_enrollments (
student_id INT,
course VARCHAR(50),
PRIMARY KEY (student_id, course),
FOREIGN KEY (course) REFERENCES course_assignments(course)
);Nu kun je docenten toevoegen zonder studenten, en de databasestructuur sluit exact aan op de bedrijfsregels.
4NF elimineert multivalued dependencies – wanneer één kolom meerdere onafhankelijke sets waarden bepaalt.
Een multivalued dependency bestaat wanneer “Kolom A” meerdere waarden in “Kolom B” bepaalt, en die waarden onafhankelijk zijn van andere kolommen in de tabel.
Neem deze tabel die vaardigheden en hobby’s van studenten bijhoudt:
-- Violates 4NF due to multi-valued dependencies
CREATE TABLE student_info (
student_id INT,
skill VARCHAR(50),
hobby VARCHAR(50),
PRIMARY KEY (student_id, skill, hobby)
);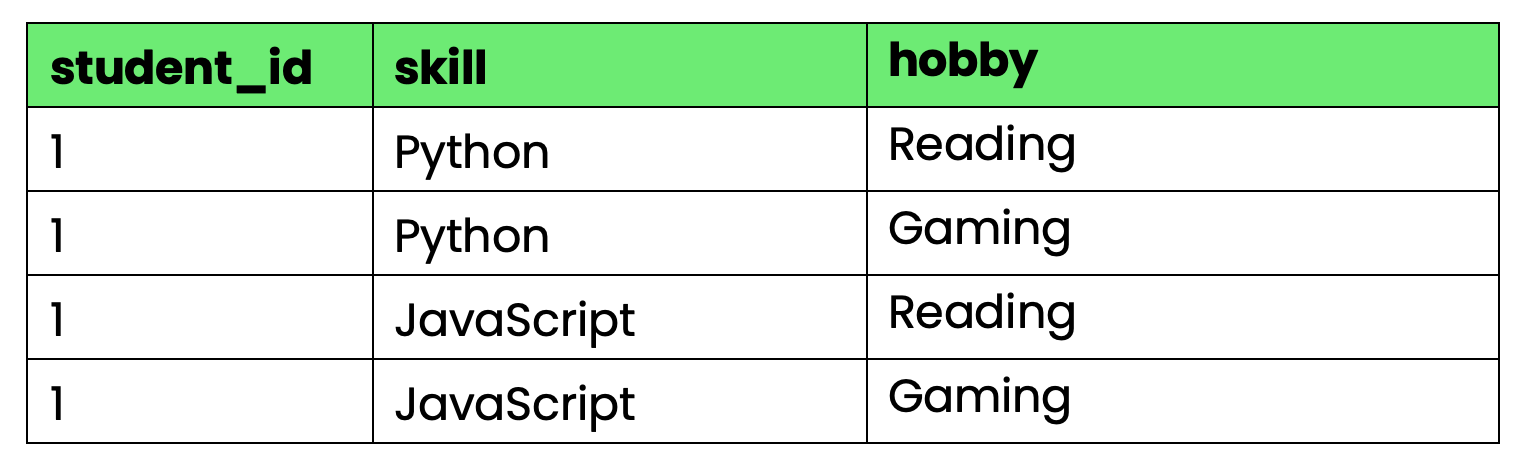
Afbeelding 4 - Tabel die 4NF schendt
Het probleem: student_id bepaalt zowel vaardigheden als hobby’s, maar vaardigheden en hobby’s zijn onafhankelijk van elkaar. Als student 1 een nieuwe vaardigheid leert, moet je rijen voor elke hobbycombinatie aanmaken. Krijgen ze een nieuwe hobby, dan heb je rijen nodig voor elke vaardigheidscombinatie.
Dit creëert explosieve redundantie naarmate het aantal vaardigheden en hobby’s groeit.
Om 4NF te bereiken, scheid je de onafhankelijke multivalued dependencies:
-- 4NF solution
CREATE TABLE student_skills (
student_id INT,
skill VARCHAR(50),
PRIMARY KEY (student_id, skill)
);
CREATE TABLE student_hobbies (
student_id INT,
hobby VARCHAR(50),
PRIMARY KEY (student_id, hobby)
);Nu kun je vaardigheden en hobby’s onafhankelijk toevoegen zonder cartesiaanse productexplosies te creëren.
5NF (Project-Join Normal Form) elimineert join-afhankelijkheden: complexe relaties die drie of meer tabellen vereisen om data zonder verlies te reconstrueren.
Een join-afhankelijkheid bestaat wanneer je de oorspronkelijke tabel niet kunt reconstrueren door twee gedecomponeerde tabellen te joinen, maar wel door drie of meer tabellen te joinen.
Neem leveranciers, onderdelen en projecten met deze regel: "Een leverancier kan een onderdeel aan een project leveren alleen als de leverancier dat onderdeel levert EN aan dat project werkt."
-- Original table with join dependency
CREATE TABLE supplier_part_project (
supplier_id INT,
part_id INT,
project_id INT,
PRIMARY KEY (supplier_id, part_id, project_id)
);Om 5NF te bereiken, decomponer je naar drie binaire relaties:
-- 5NF decomposition
CREATE TABLE supplier_parts (supplier_id INT, part_id INT);
CREATE TABLE supplier_projects (supplier_id INT, project_id INT);
CREATE TABLE project_parts (project_id INT, part_id INT);Je kunt alleen geldige combinaties leverancier-onderdeel-project reconstrueren door alle drie de tabellen te joinen, wat de bedrijfsregel op schema-niveau afdwingt.
6NF drijft normalisatie tot het uiterste door elk attribuut in een eigen tabel met temporele sleutels te plaatsen.
6NF is ontworpen voor datawarehouses en temporele databases waar je moet bijhouden hoe elk attribuut onafhankelijk in de tijd verandert.
-- 6NF example for temporal data
CREATE TABLE customer_names (
customer_id INT,
name VARCHAR(100),
valid_from DATE,
valid_to DATE
);
CREATE TABLE customer_addresses (
customer_id INT,
address VARCHAR(200),
valid_from DATE,
valid_to DATE
);Dit stelt je in staat om bij te houden wanneer elk attribuut is gewijzigd zonder andere te beïnvloeden, maar het maakt queries complex en wordt zelden gebruikt buiten gespecialiseerde temporele systemen.
De meeste applicaties stoppen bij 3NF of BCNF. Deze geavanceerde vormen lossen specifieke randgevallen op, maar voegen complexiteit toe die het voor typische bedrijfsapplicaties niet waard is.
Leer meer over databases en SQL met deze cursussen!
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
