
Courses
Xử lý dữ liệu trong SQL
4 giờ
328.2K
Nếu bạn không còn muốn đối mặt với dữ liệu không nhất quán, dư thừa, thì chuẩn hoá cơ sở dữ liệu là con đường nên đi.
Bạn hẳn đã trải qua cảm giác bực bội khi cập nhật thông tin khách hàng ở một bảng nhưng lại thấy phiên bản cũ nằm rải rác ở năm bảng khác. Truy vấn trả về kết quả mâu thuẫn, báo cáo hiển thị số liệu khác nhau tuỳ bảng bạn lấy, và bạn mất hàng giờ để gỡ lỗi các vấn đề toàn vẹn dữ liệu vốn không nên tồn tại. Những vấn đề này sẽ chỉ nhân lên khi cơ sở dữ liệu của bạn lớn dần.
Chuẩn hoá cơ sở dữ liệu loại bỏ những nhức đầu này bằng cách tổ chức dữ liệu theo các nguyên lý toán học đã được kiểm chứng. Quy trình sử dụng các dạng chuẩn để đảm bảo mỗi mẩu thông tin chỉ tồn tại ở đúng một nơi, giúp cơ sở dữ liệu đáng tin cậy và hiệu quả.
Tôi sẽ trình bày cho bạn toàn bộ quy trình chuẩn hoá, từ khái niệm cơ bản đến các dạng chuẩn nâng cao, kèm ví dụ thực hành để biến dữ liệu lộn xộn thành cấu trúc cơ sở dữ liệu sạch và dễ bảo trì.
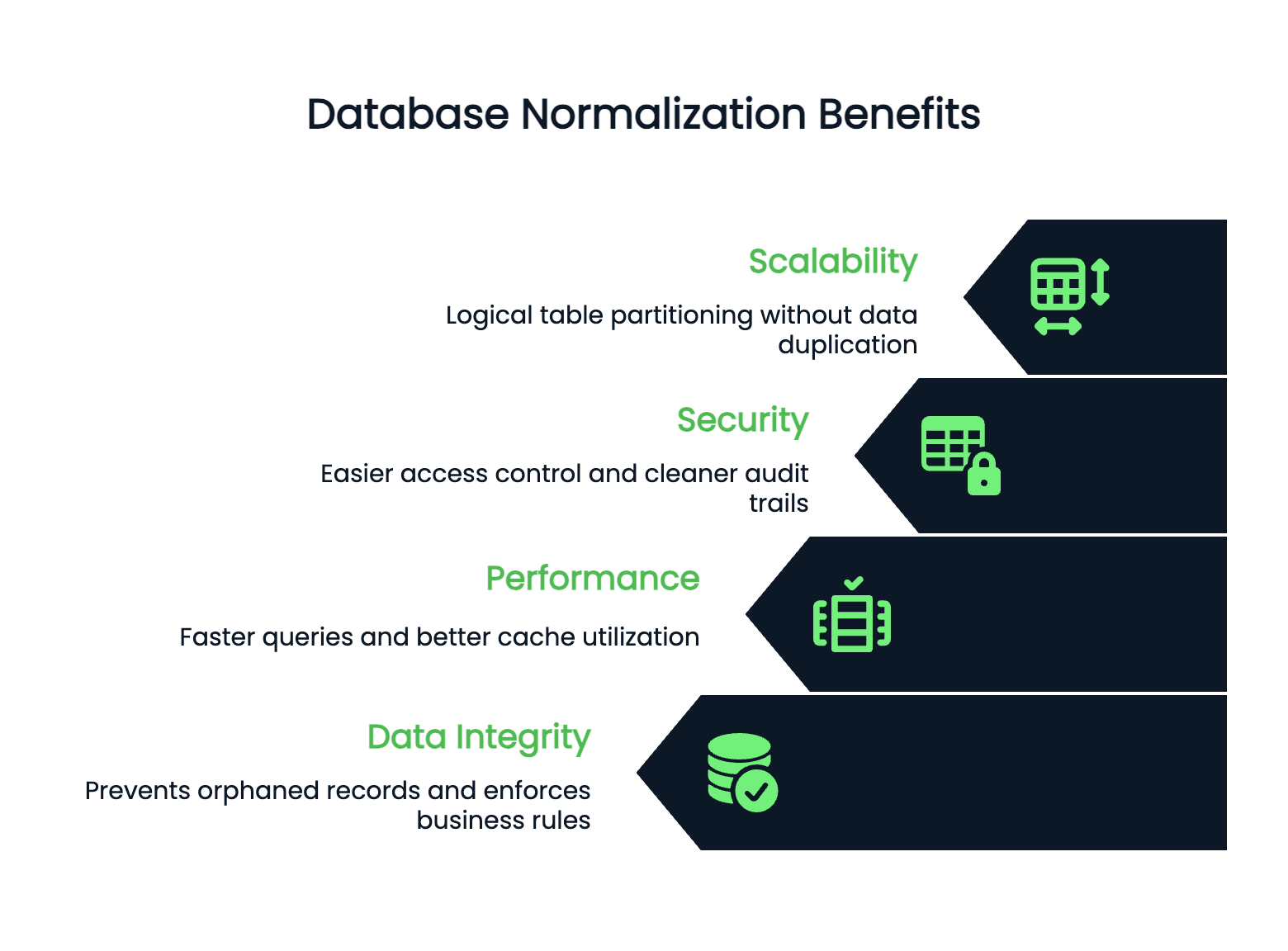
Chuẩn hoá là thứ giữ cho cơ sở dữ liệu của bạn không trở thành cơn ác mộng bảo trì. Hãy xem vì sao chuẩn hoá đúng cách lại quan trọng với các ứng dụng thực tế.
Dư thừa là kẻ giết hiệu năng âm thầm của cơ sở dữ liệu. Khi bạn lưu cùng một thông tin ở nhiều nơi, bạn không chỉ lãng phí dung lượng lưu trữ - bạn còn tự tạo ra những bất nhất phá vỡ logic ứng dụng.
Không có chuẩn hoá, cập nhật địa chỉ của khách hàng đồng nghĩa với việc phải lần theo mọi bảng có lưu dữ liệu địa chỉ. Bỏ sót một nơi, báo cáo của bạn sẽ hiển thị thông tin mâu thuẫn. Người dùng thấy địa chỉ khác nhau trên các màn hình khác nhau. Phân tích trở nên thiếu tin cậy.
Chuẩn hoá khắc phục điều này bằng cách đảm bảo mỗi mẩu dữ liệu chỉ sống ở đúng một nơi. Khi bạn cập nhật địa chỉ của khách hàng đó, nó thay đổi ở khắp nơi một cách tự động vì mọi thứ đều tham chiếu đến cùng một nguồn.
Toàn vẹn trở nên vững như thép khi bạn chuẩn hoá đúng. Ràng buộc khoá ngoại ngăn chặn bản ghi mồ côi. Bạn không thể vô tình xoá một khách hàng vẫn còn đơn hàng đang hoạt động. Cơ sở dữ liệu thực thi quy tắc nghiệp vụ ở cấp dữ liệu, không chỉ trong mã ứng dụng.
Điều này đồng nghĩa với ít lỗi hơn, mã sạch hơn, và ứng dụng hoạt động dự đoán được ngay cả khi nhiều hệ thống cùng truy cập dữ liệu.
Các bất thường khi sửa đổi biến mất với chuẩn hoá đúng cách. Chúng xảy ra khi bạn chèn, cập nhật, hoặc xoá dữ liệu và tạo ra bất nhất hoặc buộc phải dùng cách lách phức tạp.
Bất thường khi chèn buộc bạn phải thêm dữ liệu giả chỉ để tạo một bản ghi. Bất thường khi cập nhật yêu cầu bạn thay đổi cùng một thông tin ở nhiều hàng. Bất thường khi xoá làm mất nhiều thông tin hơn dự định khi xoá một bản ghi duy nhất.
Cơ sở dữ liệu đã chuẩn hoá loại bỏ các vấn đề này bằng cách tổ chức dữ liệu để mỗi sự thật xuất hiện một lần và chỉ một lần.
Hiệu năng và khả năng mở rộng được cải thiện khi cấu trúc cơ sở dữ liệu gọn gàng. Bảng đã chuẩn hoá thường nhỏ hơn, nghĩa là truy vấn nhanh hơn và tận dụng bộ nhớ đệm tốt hơn. Chỉ mục hoạt động hiệu quả hơn trên các bảng nhỏ, tập trung.
Cơ sở dữ liệu của bạn có thể mở rộng theo chiều ngang vì dữ liệu đã chuẩn hoá có ranh giới rõ ràng. Bạn có thể phân mảnh bảng một cách logic mà không cần nhân bản thông tin giữa các shard.
Bảo mật trở nên dễ quản lý hơn trong cơ sở dữ liệu đã chuẩn hoá. Bạn có thể kiểm soát truy cập ở cấp bảng một cách tự tin vì dữ liệu nhạy cảm nằm ở những nơi cụ thể, được định nghĩa rõ. Không cần lo số thẻ tín dụng của khách hàng ẩn ở các bảng ngoài dự kiến.
Dấu vết kiểm toán cũng sạch hơn - bạn biết chính xác thay đổi xảy ra ở đâu và có thể theo dõi mà không phải lục tìm dữ liệu dư thừa rải rác khắp schema.
Tóm lại, chuẩn hoá biến dữ liệu hỗn loạn thành nền tảng đáng tin cậy, phát triển cùng ứng dụng của bạn.
Tiếp theo, hãy xem những điều kiện tiên quyết cho chuẩn hoá.
Trước khi bắt đầu chuẩn hoá bảng, bạn cần hiểu điều gì làm cho chuẩn hoá hoạt động. Hãy điểm qua các khái niệm cốt lõi sẽ dẫn dắt quyết định của bạn trong suốt quy trình.
Khoá là nền tảng của thiết kế cơ sở dữ liệu quan hệ - chúng nhận diện bản ghi và kết nối các bảng với nhau.
Một khoá chính (primary key) xác định duy nhất mỗi hàng trong một bảng. Không có hai hàng nào có cùng giá trị khoá chính, và nó không được null. Hãy coi nó như số an sinh xã hội cho dữ liệu của bạn - mỗi bản ghi có đúng một số, và không có bản sao.
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
email VARCHAR(255),
name VARCHAR(100)
);Ở đây, customer_id là khoá chính. Mỗi khách hàng nhận một ID duy nhất mà bạn sẽ dùng để tham chiếu khách hàng đó từ các bảng khác.
Khoá ứng viên là bất kỳ cột (hoặc tổ hợp cột) nào có thể đóng vai trò khoá chính. Bảng customers của bạn có thể có cả customer_id và email là khoá ứng viên vì cả hai đều định danh khách hàng một cách duy nhất. Bạn chọn một làm khoá chính, các khoá còn lại vẫn là khoá ứng viên.
Khoá ngoại tạo quan hệ giữa các bảng. Chúng tham chiếu khoá chính của một bảng khác và thiết lập kết nối nhằm duy trì toàn vẹn dữ liệu.
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
order_date DATE,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);customer_id trong bảng orders là khoá ngoại. Nó phải khớp với một customer_id tồn tại trong bảng customers. Điều này ngăn đơn hàng mồ côi và đảm bảo mọi đơn hàng đều thuộc về một khách hàng thực sự.
Các khoá thực thi quy tắc nghiệp vụ ở cấp cơ sở dữ liệu, nhờ đó dữ liệu của bạn đáng tin cậy hơn so với chỉ xác thực trong ứng dụng.
Phụ thuộc hàm mô tả cách các cột liên quan với nhau trong một bảng. Chúng là nền tảng toán học thúc đẩy các quyết định chuẩn hoá.
Một phụ thuộc hàm tồn tại khi giá trị của một cột quyết định giá trị của cột khác. Ta viết là A → B, nghĩa là "A quyết định B" hoặc "B phụ thuộc vào A."
Trong bảng customers, customer_id → email vì mỗi ID khách hàng ánh xạ chính xác đến một địa chỉ email. Nếu bạn biết ID khách hàng, bạn có thể xác định email một cách chắc chắn.

Hình 1 - Ví dụ về phụ thuộc hàm
Ở đây, customer_id → email và customer_id → name vì ID khách hàng quyết định cả email và tên.
Phụ thuộc hàm phơi bày vấn đề dư thừa.
Nếu bạn có bảng nơi order_id → customer_name nhưng bạn lại lưu tên khách hàng trong mọi hàng của đơn hàng, bạn đang có dư thừa. Tên khách hàng phụ thuộc vào ID của họ, không phải vào ID đơn hàng.
Bảo toàn phụ thuộc nghĩa là các bảng đã chuẩn hoá vẫn duy trì mọi phụ thuộc hàm ban đầu. Khi bạn tách bảng trong quá trình chuẩn hoá, bạn không nên đánh mất khả năng thực thi các quy tắc nghiệp vụ vốn có trong bảng gốc.
Phân rã không mất mát đảm bảo bạn có thể tái tạo bảng gốc bằng cách JOIN các bảng đã chuẩn hoá. Bạn không mất thông tin khi tách bảng - các phép nối mang lại chính xác dữ liệu ban đầu.
Các khái niệm này phối hợp với nhau: phụ thuộc hàm chỉ ra điều gì cần tách, trong khi bảo toàn phụ thuộc và phân rã không mất mát đảm bảo bạn không làm hỏng điều gì trong quá trình.
Hiểu các mối quan hệ này giúp bạn đưa ra quyết định chuẩn hoá sáng suốt để cải thiện cơ sở dữ liệu mà không đánh mất chức năng.
Giờ hãy đi qua quy trình chuẩn hoá thực tế, bắt đầu từ dữ liệu lộn xộn và biến đổi từng bước. Mỗi dạng chuẩn xây trên dạng trước đó, vì vậy bạn không thể đi thẳng từ dữ liệu chưa chuẩn hoá lên 3NF.
Dạng chuẩn thứ nhất loại bỏ nhóm lặp và đảm bảo mỗi cột chứa giá trị nguyên tử. Tìm hiểu thêm trong hướng dẫn chuyên sâu về Dạng chuẩn thứ nhất (1NF).
Giá trị nguyên tử nghĩa là mỗi ô chỉ nắm đúng một mẩu thông tin - không danh sách, không giá trị phân tách bằng dấu phẩy, không nhồi nhiều điểm dữ liệu vào một trường. Đây là nền tảng cho mọi thứ khác.
Những gì vi phạm 1NF:
CREATE TABLE orders_bad (
order_id INT,
customer_name VARCHAR(100),
products VARCHAR(500),
quantities VARCHAR(50)
);
Hình 2 - Bảng vi phạm 1NF
Các cột products và quantities chứa nhiều giá trị, phân tách bằng dấu phẩy. Bạn không thể dễ dàng truy vấn "tất cả đơn hàng chứa laptop" hoặc tính tổng số lượng mà không phải phân tích chuỗi.
Để chuyển sang 1NF, tách nhóm lặp thành các hàng riêng:
-- First normal form (1NF)
CREATE TABLE orders_1nf (
order_id INT,
customer_name VARCHAR(100),
product VARCHAR(100),
quantity INT
);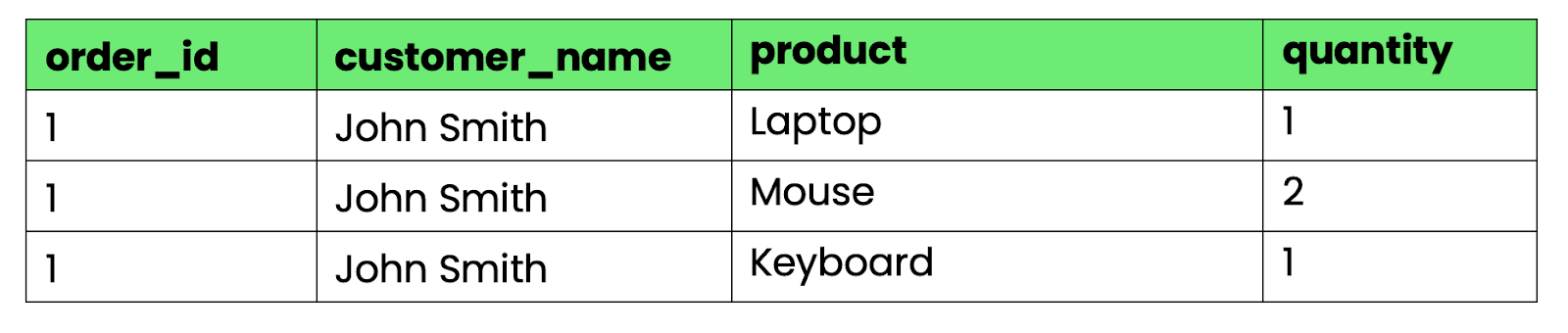
Hình 3 - Bảng thoả mãn 1NF
Giờ đây, mỗi ô chứa đúng một giá trị. Bạn có thể truy vấn, sắp xếp và tổng hợp dữ liệu bằng các thao tác SQL tiêu chuẩn.
Dạng chuẩn thứ hai loại bỏ phụ thuộc bộ phận - khi các cột không khoá chỉ phụ thuộc vào một phần của khoá chính tổng hợp.
2NF có nhiều điều hơn vẻ bề ngoài. Tìm hiểu thêm trong hướng dẫn chuyên sâu của chúng tôi.
Một bảng đạt 2NF nếu nó ở 1NF và mọi cột không khoá phụ thuộc vào toàn bộ khoá chính, không chỉ một phần của nó.
Bảng 1NF của chúng ta có vấn đề. Nếu ta dùng order_id và product làm khoá chính tổng hợp, thì customer_name chỉ phụ thuộc vào order_id, không phụ thuộc vào sản phẩm. Điều này tạo dư thừa - tên khách hàng lặp lại cho mỗi sản phẩm trong một đơn hàng.
-- Still has partial dependencies
-- customer_name depends only on order_id, not on (order_id, product)
CREATE TABLE orders_1nf (
order_id INT,
customer_name VARCHAR(100), -- Partial dependency!
product VARCHAR(100),
quantity INT,
PRIMARY KEY (order_id, product)
);Để đạt 2NF, hãy tách bảng dựa trên phụ thuộc:
-- Orders table (customer info depends on order_id)
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_name VARCHAR(100)
);
-- Order items table (quantity depends on both order_id and product)
CREATE TABLE order_items (
order_id INT,
product VARCHAR(100),
quantity INT,
PRIMARY KEY (order_id, product),
FOREIGN KEY (order_id) REFERENCES orders(order_id)
);Giờ customer_name chỉ xuất hiện một lần cho mỗi đơn hàng, loại bỏ dư thừa. Mỗi bảng có các cột phụ thuộc vào toàn bộ khoá chính.
Dạng chuẩn thứ ba loại bỏ phụ thuộc bắc cầu, xảy ra khi các cột không khoá phụ thuộc vào những cột không khoá khác thay vì khoá chính. Tìm hiểu sâu về Dạng chuẩn thứ ba (3NF) vượt ra ngoài những điều cơ bản.
Phụ thuộc bắc cầu tồn tại khi “Cột A” quyết định “Cột B”, và “Cột B” quyết định “Cột C”, tạo ra phụ thuộc gián tiếp từ A tới C.
Hãy mở rộng bảng đơn hàng với thông tin địa chỉ khách hàng:
-- Has transitive dependencies
CREATE TABLE orders_2nf (
order_id INT PRIMARY KEY,
customer_name VARCHAR(100),
customer_city VARCHAR(50),
customer_state VARCHAR(50),
customer_zip VARCHAR(10)
);Vấn đề là: customer_name → customer_city, và customer_city → customer_state. Bang phụ thuộc vào thành phố, không phụ thuộc trực tiếp vào đơn hàng. Điều này tạo dư thừa - mọi đơn hàng từ cùng một thành phố đều lặp lại thông tin bang.
Để đạt 3NF, loại bỏ phụ thuộc bắc cầu bằng cách tạo bảng riêng:
-- Customers table (removes transitive dependencies)
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
customer_name VARCHAR(100),
city_id INT,
FOREIGN KEY (city_id) REFERENCES cities(city_id)
);
-- Cities table
CREATE TABLE cities (
city_id INT PRIMARY KEY,
city_name VARCHAR(50),
state VARCHAR(50),
zip VARCHAR(10)
);
-- Orders table (now references customer, not customer details)
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
order_date DATE,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);Giờ thông tin địa lý chỉ sống ở một nơi. Nếu một thành phố đổi bang (hiếm nhưng có thể), bạn cập nhật một hàng thay vì lục tìm mọi đơn hàng từ thành phố đó.
Mỗi dạng chuẩn giải quyết những vấn đề dư thừa cụ thể trong khi vẫn giữ khả năng tái tạo dữ liệu gốc thông qua JOIN.
Ba dạng chuẩn đầu xử lý hầu hết các vấn đề cơ sở dữ liệu trong thực tế, nhưng một số trường hợp ngoại lệ đòi hỏi chuẩn hoá sâu hơn. Các dạng nâng cao này xử lý những vấn đề phụ thuộc cụ thể mà 3NF không giải quyết được.
BCNF khắc phục một vấn đề tinh vi mà 3NF bỏ sót: khi một bảng có các khoá ứng viên chồng lấp.
3NF cho phép các cột không khoá phụ thuộc vào khoá ứng viên, nhưng BCNF nghiêm ngặt hơn. Trong BCNF, mọi yếu tố quyết định (cột quyết định cột khác) phải là siêu khoá - hoặc khoá chính, hoặc khoá ứng viên.
Đây là nơi 3NF thất bại:
-- Table in 3NF but violates BCNF
CREATE TABLE course_instructors (
student_id INT,
course VARCHAR(50),
instructor VARCHAR(50),
PRIMARY KEY (student_id, course)
);Quy tắc nghiệp vụ là:
Điều này tạo ra các phụ thuộc course → instructor và instructor → course. Cả (student_id, course) và (student_id, instructor) đều là khoá ứng viên, nhưng course và instructor quyết định lẫn nhau mà bản thân chúng không phải siêu khoá.
Vấn đề lộ ra khi bạn cố thêm một giảng viên mới mà chưa có sinh viên. Bạn không thể chèn "Giáo sư Smith dạy Thiết kế CSDL" mà không đồng thời thêm một sinh viên vào khoá đó.
Để đạt BCNF, hãy phân rã dựa trên phụ thuộc có vấn đề:
-- BCNF solution
CREATE TABLE course_assignments (
course VARCHAR(50) PRIMARY KEY,
instructor VARCHAR(50) UNIQUE
);
CREATE TABLE student_enrollments (
student_id INT,
course VARCHAR(50),
PRIMARY KEY (student_id, course),
FOREIGN KEY (course) REFERENCES course_assignments(course)
);Giờ bạn có thể thêm giảng viên mà không cần sinh viên, và cấu trúc cơ sở dữ liệu khớp chính xác với quy tắc nghiệp vụ.
4NF loại bỏ phụ thuộc đa trị - khi một cột quyết định nhiều tập giá trị độc lập.
Phụ thuộc đa trị tồn tại khi “Cột A” quyết định nhiều giá trị ở “Cột B”, và các giá trị đó độc lập với các cột khác trong bảng.
Xét bảng theo dõi kỹ năng và sở thích của sinh viên:
-- Violates 4NF due to multi-valued dependencies
CREATE TABLE student_info (
student_id INT,
skill VARCHAR(50),
hobby VARCHAR(50),
PRIMARY KEY (student_id, skill, hobby)
);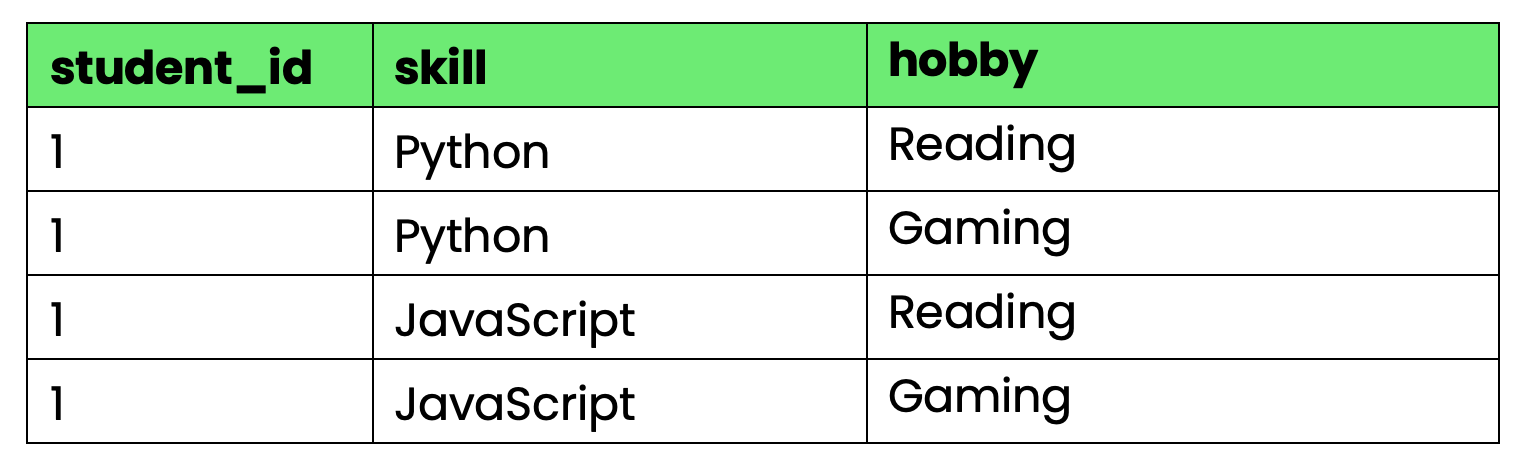
Hình 4 - Bảng vi phạm 4NF
Vấn đề: student_id quyết định cả kỹ năng và sở thích, nhưng kỹ năng và sở thích độc lập với nhau. Khi sinh viên 1 học kỹ năng mới, bạn phải tạo hàng cho mọi tổ hợp sở thích. Khi họ có sở thích mới, bạn lại cần hàng cho mọi tổ hợp kỹ năng.
Điều này tạo dư thừa bùng nổ khi số kỹ năng và sở thích tăng.
Để đạt 4NF, tách các phụ thuộc đa trị độc lập:
-- 4NF solution
CREATE TABLE student_skills (
student_id INT,
skill VARCHAR(50),
PRIMARY KEY (student_id, skill)
);
CREATE TABLE student_hobbies (
student_id INT,
hobby VARCHAR(50),
PRIMARY KEY (student_id, hobby)
);Giờ bạn có thể thêm kỹ năng và sở thích độc lập mà không tạo ra bùng nổ tích Descartes.
5NF (Dạng chuẩn Phép chiếu - Phép nối) loại bỏ phụ thuộc JOIN: các quan hệ phức tạp yêu cầu ba hoặc nhiều bảng để tái tạo dữ liệu mà không mất mát.
Phụ thuộc JOIN tồn tại khi bạn không thể tái tạo bảng gốc bằng cách JOIN hai bảng đã phân rã, nhưng có thể tái tạo bằng cách JOIN ba hoặc nhiều bảng.
Xét nhà cung cấp, linh kiện và dự án với quy tắc: "Một nhà cung cấp có thể cung cấp một linh kiện cho một dự án chỉ khi nhà cung cấp đó cung cấp linh kiện đó VÀ tham gia dự án đó."
-- Original table with join dependency
CREATE TABLE supplier_part_project (
supplier_id INT,
part_id INT,
project_id INT,
PRIMARY KEY (supplier_id, part_id, project_id)
);Để đạt 5NF, phân rã thành ba quan hệ nhị phân:
-- 5NF decomposition
CREATE TABLE supplier_parts (supplier_id INT, part_id INT);
CREATE TABLE supplier_projects (supplier_id INT, project_id INT);
CREATE TABLE project_parts (project_id INT, part_id INT);Bạn chỉ có thể tái tạo các tổ hợp nhà cung cấp - linh kiện - dự án hợp lệ bằng cách JOIN cả ba bảng, từ đó thực thi quy tắc nghiệp vụ ở cấp lược đồ.
6NF đẩy chuẩn hoá đến cực hạn bằng cách đặt mỗi thuộc tính vào bảng riêng với khoá thời gian.
6NF được thiết kế cho kho dữ liệu và cơ sở dữ liệu thời gian, nơi bạn cần theo dõi cách mỗi thuộc tính thay đổi theo thời gian một cách độc lập.
-- 6NF example for temporal data
CREATE TABLE customer_names (
customer_id INT,
name VARCHAR(100),
valid_from DATE,
valid_to DATE
);
CREATE TABLE customer_addresses (
customer_id INT,
address VARCHAR(200),
valid_from DATE,
valid_to DATE
);Điều này cho phép bạn theo dõi thời điểm mỗi thuộc tính thay đổi mà không ảnh hưởng đến các thuộc tính khác, nhưng khiến truy vấn phức tạp và hiếm khi dùng ngoài các hệ thống cơ sở dữ liệu thời gian chuyên biệt.
Hầu hết ứng dụng dừng ở 3NF hoặc BCNF. Các dạng nâng cao này giải quyết trường hợp biên cụ thể nhưng thêm độ phức tạp không đáng cho ứng dụng doanh nghiệp điển hình.
Tìm hiểu thêm về cơ sở dữ liệu và SQL với các khoá học này!
Courses
Courses
Courses