Course
Data Manipulation in SQL
4 hr
324.1K
If you never want to deal with inconsistent, redundant data again, database normalization is the way to go.
You know the frustration of updating customer information in one table only to find outdated versions scattered across five others. Your queries return conflicting results, your reports show different numbers depending on which table you pull from, and you spend hours debugging data integrity issues that shouldn't exist. These problems only multiply as your database grows.
Database normalization eliminates these headaches by organizing your data according to proven mathematical principles. The process uses normal forms to make sure each piece of information exists in exactly one place, making your database reliable and efficient.
I'll show you the complete normalization process, from basic concepts to advanced normal forms, with hands-on examples that transform messy data into clean, maintainable database structures.
Normalization is what keeps your database from becoming a maintenance nightmare. Let's look at why proper normalization matters for real-world applications.
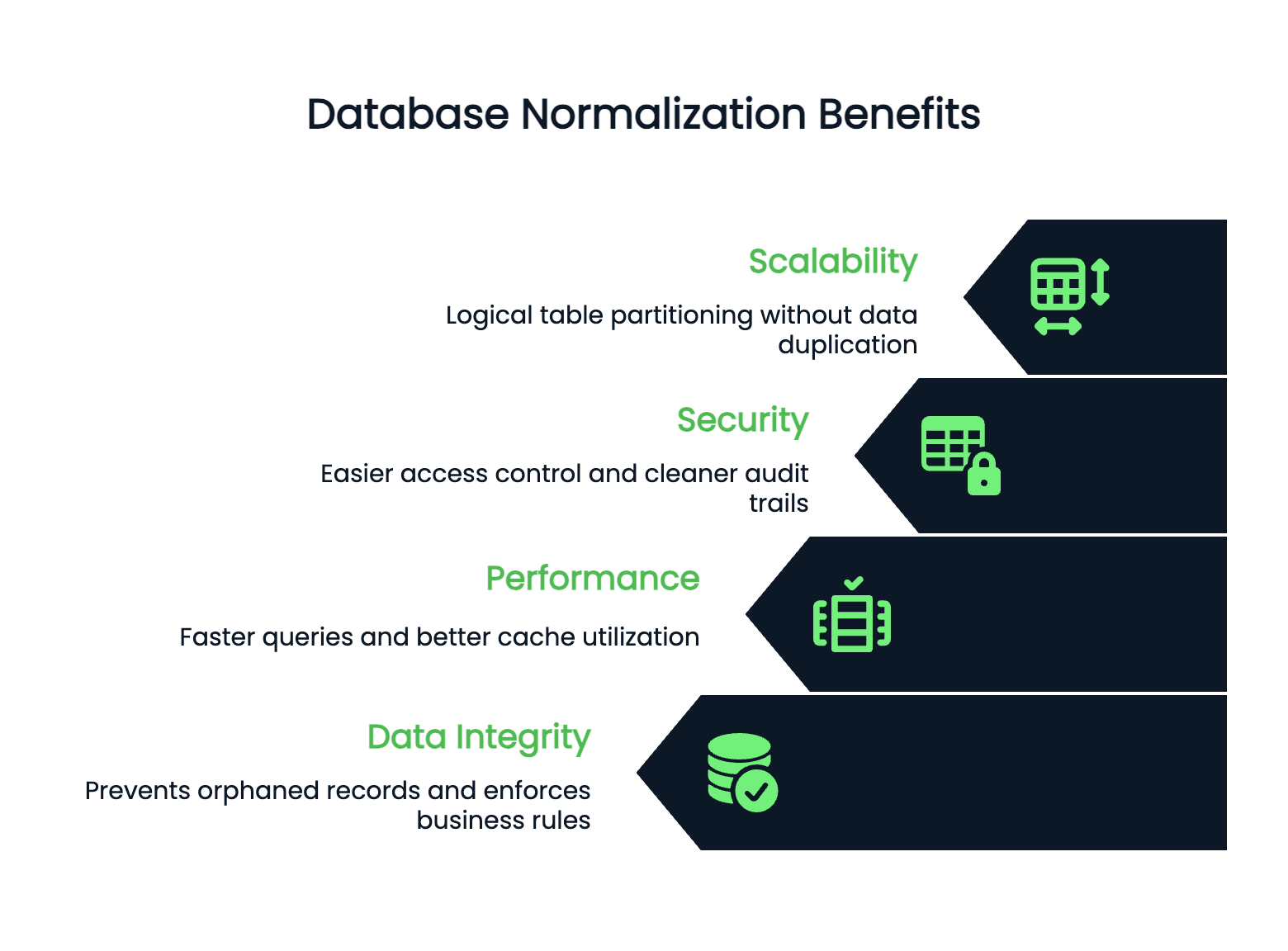
Redundancy is the silent killer of database performance. When you store the same information in multiple places, you're not just wasting storage space - you're setting yourself up for inconsistencies that break your application logic.
Without normalization, updating a customer's address means hunting down every table that stores address data. Miss one, and your reports show conflicting information. Your users see different addresses on different screens. Your analytics become unreliable.
Normalization fixes this by making sure each piece of data lives in exactly one place. When you update that customer's address, it changes everywhere automatically because everything references the same source.
Integrity becomes bulletproof when you normalize correctly. Foreign key constraints prevent orphaned records. You can't accidentally delete a customer who still has active orders. Your database enforces business rules at the data level, not just in application code.
This means fewer bugs, cleaner code, and applications that behave predictably even when multiple systems access the same data.
Modification anomalies disappear with proper normalization. These happen when you insert, update, or delete data and create inconsistencies or require complex workarounds.
Insert anomalies force you to add dummy data just to create a record. Update anomalies require you to change the same information across multiple rows. Delete anomalies remove more information than intended when you delete a single record.
Normalized databases eliminate these problems by organizing data so each fact appears once and only once.
Performance and scalability improve when your database structure is clean. Normalized tables are typically smaller, which means faster queries and better cache utilization. Indexes work more effectively on smaller, focused tables.
Your database can scale horizontally because normalized data has clear boundaries. You can partition tables logically without duplicating information across shards.
Security becomes easier to manage in normalized databases. You can control access at the table level with confidence because sensitive data lives in specific, well-defined places. No need to worry about customer credit card numbers hiding in unexpected tables.
Audit trails are cleaner too - you know exactly where changes happen and can track them without hunting through redundant data scattered across your schema.
In summary, normalization transforms chaotic data into a reliable foundation that grows with your application.
Let's see what are prerequisites for normalization next.
Before you start normalizing tables, you need to understand what makes normalization work. Let's cover the essential concepts that'll guide your decisions throughout the process.
Keys are the foundation of relational database design - they identify records and connect tables together.
A primary key uniquely identifies each row in a table. No two rows can have the same primary key value, and it can't be null. Think of it like a social security number for your data - each record gets exactly one, and no duplicates exist.
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
email VARCHAR(255),
name VARCHAR(100)
);Here, customer_id is the primary key. Every customer gets a unique ID that you'll use to reference that specific customer from other tables.
A candidate key is any column (or combination of columns) that could serve as a primary key. Your customers table might have both customer_id and email as candidate keys since both uniquely identify customers. You pick one as the primary key, and the others remain candidate keys.
Foreign keys create relationships between tables. They reference the primary key of another table and establish connections that maintain data integrity.
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
order_date DATE,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);The customer_id in the orders table is a foreign key. It must match a customer_id that exists in the customers table. This prevents orphaned orders and makes sure every order belongs to a real customer.
Keys enforce business rules at the database level, which makes your data more reliable than application-only validation.
Functional dependencies describe how columns relate to each other within a table. They're the mathematical foundation that drives normalization decisions.
A functional dependency exists when one column's value determines another column's value. We write this as A → B, meaning "A determines B" or "B depends on A."
In a customers table, customer_id → email because each customer ID maps to exactly one email address. If you know the customer ID, you can determine the email with certainty.

Image 1 - Functional dependency example
Here, customer_id → email and customer_id → name because the customer ID determines both the email and name.
Functional dependencies reveal redundancy problems.
If you have a table where order_id → customer_name but you're storing the customer name in every order row, you've got redundancy. The customer's name depends on their ID, not the order ID.
Dependency preservation means your normalized tables still maintain all the original functional dependencies. When you split a table during normalization, you shouldn't lose the ability to enforce business rules that existed in the original table.
Lossless decomposition guarantees you can reconstruct the original table by joining the normalized tables. You don't lose any information when you split tables - the joins bring back exactly the same data you started with.
These concepts work together: functional dependencies identify what needs to be separated, while dependency preservation and lossless decomposition ensure you don't break anything in the process.
Understanding these relationships helps you make smart normalization decisions that improve your database without losing functionality.
Now let's walk through the actual normalization process, starting with messy data and transforming it step by step. Each normal form builds on the previous one, so you can't go directly from unnormalized data to 3NF.
The first normal form eliminates repeating groups and makes sure every column contains atomic values. Learn more about it in the First Normal Form (1NF) in-depth guide.
Atomic values mean each cell holds exactly one piece of information - no lists, no comma-separated values, no multiple data points crammed into a single field. This is the foundation that makes everything else possible.
Here's what violates 1NF:
CREATE TABLE orders_bad (
order_id INT,
customer_name VARCHAR(100),
products VARCHAR(500),
quantities VARCHAR(50)
);
Image 2 - Table that violates 1NF
The products and quantities columns contain multiple values separated by commas. You can't easily query "all orders containing laptops" or calculate total quantities without string parsing.
To convert this to 1NF, split the repeating groups into separate rows:
-- First normal form (1NF)
CREATE TABLE orders_1nf (
order_id INT,
customer_name VARCHAR(100),
product VARCHAR(100),
quantity INT
);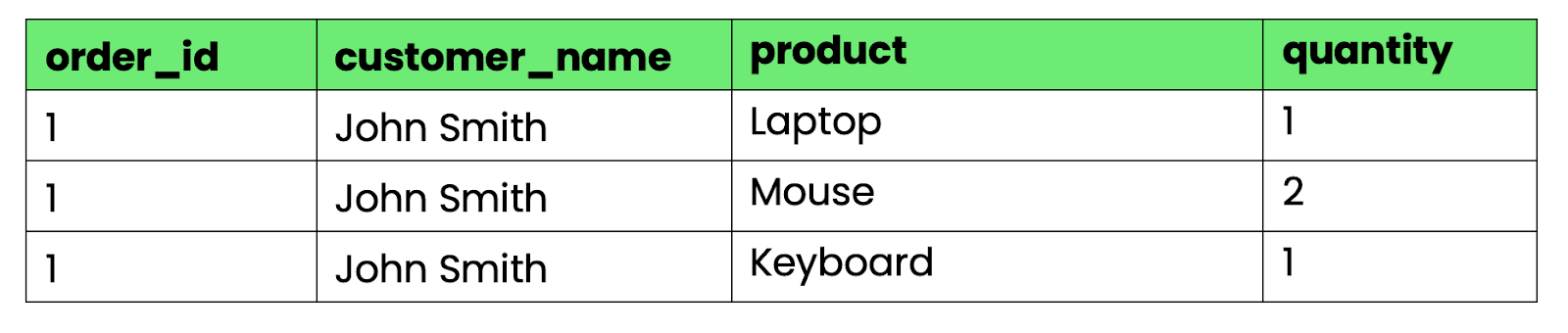
Image 3 - Table that satisfies 1NF
Now, each cell contains exactly one value. You can query, sort, and aggregate the data using standard SQL operations.
Second normal form removes partial dependencies - when non-key columns depend on only part of a composite primary key.
There's more to the Second Normal Form (2NF) than meets the eye. Learn more in our in-depth guide.
A table is in 2NF if it's in 1NF and every non-key column depends on the entire primary key, not just part of it.
Our 1NF table has a problem. If we use order_id and product as a composite primary key, customer_name depends only on order_id, not on the product. This creates redundancy - the customer name repeats for every product in an order.
-- Still has partial dependencies
-- customer_name depends only on order_id, not on (order_id, product)
CREATE TABLE orders_1nf (
order_id INT,
customer_name VARCHAR(100), -- Partial dependency!
product VARCHAR(100),
quantity INT,
PRIMARY KEY (order_id, product)
);To achieve 2NF, split the table based on dependencies:
-- Orders table (customer info depends on order_id)
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_name VARCHAR(100)
);
-- Order items table (quantity depends on both order_id and product)
CREATE TABLE order_items (
order_id INT,
product VARCHAR(100),
quantity INT,
PRIMARY KEY (order_id, product),
FOREIGN KEY (order_id) REFERENCES orders(order_id)
);Now customer_name appears only once per order, eliminating redundancy. Each table has columns that depend on the entire primary key.
The third normal form eliminates transitive dependencies, which occur when non-key columns depend on other non-key columns instead of the primary key. Dive into the Third Normal Form (3NF) beyond the basics.
A transitive dependency exists when “Column A” determines “Column B”, and “Column B” determines “Column C”, creating an indirect dependency from A to C.
Let's expand our orders table with customer address information:
-- Has transitive dependencies
CREATE TABLE orders_2nf (
order_id INT PRIMARY KEY,
customer_name VARCHAR(100),
customer_city VARCHAR(50),
customer_state VARCHAR(50),
customer_zip VARCHAR(10)
);Here's the problem: customer_name → customer_city, and customer_city → customer_state. The state depends on the city, not directly on the order. This creates redundancy - every order from the same city repeats the state information.
To achieve 3NF, remove transitive dependencies by creating separate tables:
-- Customers table (removes transitive dependencies)
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
customer_name VARCHAR(100),
city_id INT,
FOREIGN KEY (city_id) REFERENCES cities(city_id)
);
-- Cities table
CREATE TABLE cities (
city_id INT PRIMARY KEY,
city_name VARCHAR(50),
state VARCHAR(50),
zip VARCHAR(10)
);
-- Orders table (now references customer, not customer details)
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
order_date DATE,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);Now geographic information lives in one place. If a city changes states (rare but possible), you update one row instead of hunting through every order from that city.
Each normal form solves specific redundancy problems while maintaining the ability to reconstruct your original data through joins.
The first three normal forms handle most real-world database problems, but some edge cases require deeper normalization. These advanced forms deal with specific dependency issues that 3NF can't solve.
BCNF fixes a subtle problem that 3NF misses: when a table has overlapping candidate keys.
3NF allows non-key columns to depend on candidate keys, but BCNF is more strict. In BCNF, every determinant (a column that determines another column) must be a superkey - either a primary or a candidate key.
Here's where 3NF breaks down:
-- Table in 3NF but violates BCNF
CREATE TABLE course_instructors (
student_id INT,
course VARCHAR(50),
instructor VARCHAR(50),
PRIMARY KEY (student_id, course)
);The business rules are:
This creates course → instructor and instructor → course dependencies. Both (student_id, course) and (student_id, instructor) are candidate keys, but course and instructor determine each other without being superkeys themselves.
The problem shows up when you try to add a new instructor without students. You can't insert "Professor Smith teaches Database Design" without also adding a student to that course.
To achieve BCNF, decompose based on the problematic dependency:
-- BCNF solution
CREATE TABLE course_assignments (
course VARCHAR(50) PRIMARY KEY,
instructor VARCHAR(50) UNIQUE
);
CREATE TABLE student_enrollments (
student_id INT,
course VARCHAR(50),
PRIMARY KEY (student_id, course),
FOREIGN KEY (course) REFERENCES course_assignments(course)
);Now you can add instructors without students, and the database structure matches the business rules exactly.
4NF eliminates multi-valued dependencies - when one column determines multiple independent sets of values.
A multi-valued dependency exists when “Column A” determines multiple values in “Column B”, and those values are independent of other columns in the table.
Consider this table tracking student skills and hobbies:
-- Violates 4NF due to multi-valued dependencies
CREATE TABLE student_info (
student_id INT,
skill VARCHAR(50),
hobby VARCHAR(50),
PRIMARY KEY (student_id, skill, hobby)
);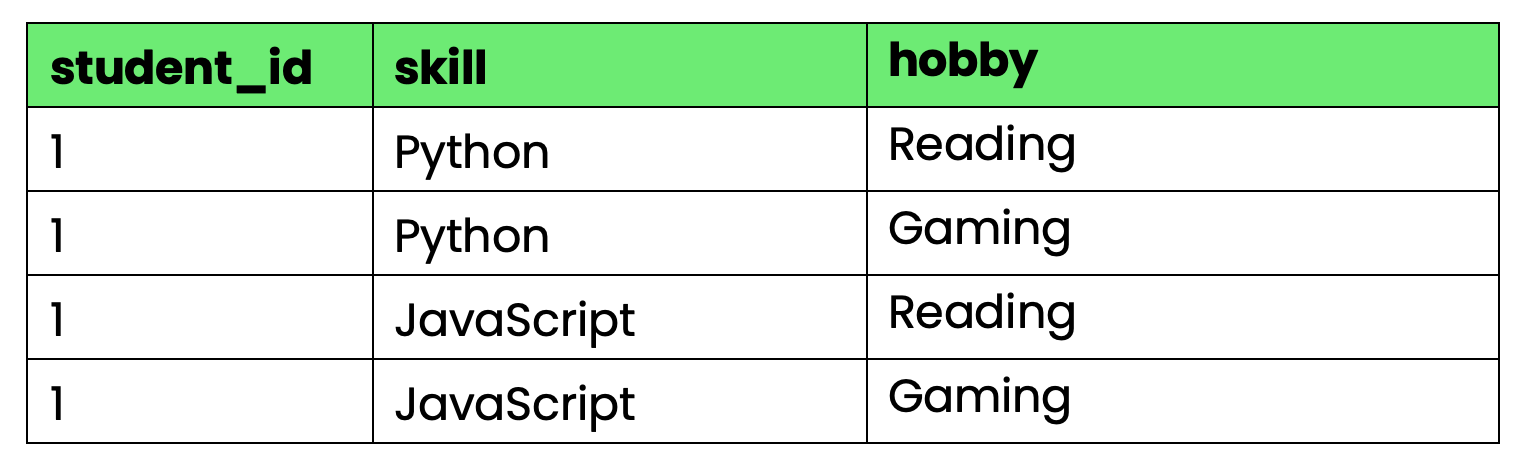
Image 4 - Table that violates 4NF
The problem: student_id determines both skills and hobbies, but skills and hobbies are independent of each other. When student 1 learns a new skill, you need to create rows for every hobby combination. When they pick up a new hobby, you need rows for every skill combination.
This creates explosive redundancy as the number of skills and hobbies grows.
To achieve 4NF, separate the independent multi-valued dependencies:
-- 4NF solution
CREATE TABLE student_skills (
student_id INT,
skill VARCHAR(50),
PRIMARY KEY (student_id, skill)
);
CREATE TABLE student_hobbies (
student_id INT,
hobby VARCHAR(50),
PRIMARY KEY (student_id, hobby)
);Now you can add skills and hobbies independently without creating Cartesian product explosions.
5NF (Project-Join Normal Form) eliminates join dependencies: complex relationships that require three or more tables to reconstruct data without loss.
A join dependency exists when you can't reconstruct the original table by joining two decomposed tables, but you can reconstruct it by joining three or more tables.
Consider suppliers, parts, and projects with this rule: "A supplier can supply a part to a project only if the supplier supplies that part AND works on that project."
-- Original table with join dependency
CREATE TABLE supplier_part_project (
supplier_id INT,
part_id INT,
project_id INT,
PRIMARY KEY (supplier_id, part_id, project_id)
);To achieve 5NF, decompose into three binary relationships:
-- 5NF decomposition
CREATE TABLE supplier_parts (supplier_id INT, part_id INT);
CREATE TABLE supplier_projects (supplier_id INT, project_id INT);
CREATE TABLE project_parts (project_id INT, part_id INT);You can only reconstruct valid supplier-part-project combinations by joining all three tables, which enforces the business rule at the schema level.
6NF takes normalization to the extreme by putting each attribute in its own table with temporal keys.
6NF is designed for data warehouses and temporal databases where you need to track how every attribute changes over time independently.
-- 6NF example for temporal data
CREATE TABLE customer_names (
customer_id INT,
name VARCHAR(100),
valid_from DATE,
valid_to DATE
);
CREATE TABLE customer_addresses (
customer_id INT,
address VARCHAR(200),
valid_from DATE,
valid_to DATE
);This allows you to track when each attribute changed without affecting others, but it makes queries complex and is rarely used outside specialized temporal database systems.
Most applications stop at 3NF or BCNF. These advanced forms solve specific edge cases but add complexity that isn't worth it for typical business applications.
Learn more about databases and SQL with these courses!
Course
Course
Course
blog
Tim Lu
12 min
Tutorial
Samuel Shaibu
Tutorial
Austin Chia
Tutorial
Dario Radečić
Tutorial
Marie Fayard
Tutorial
Marie Fayard