
Kurs
Data Manipulation in SQL
4 sa
324.1K
Tutarsız, yinelenen verilerle bir daha uğraşmak istemiyorsanız, veritabanı normalizasyonu doğru yoldur.
Bir tabloda müşteri bilgilerini güncelleyip, diğer beş tabloda eski sürümlerin dağınık halde kaldığını görmenin verdiği hayal kırıklığını bilirsiniz. Sorgularınız çelişkili sonuçlar döndürür, raporlarınız hangi tablodan veri çektiğinize bağlı olarak farklı rakamlar gösterir ve var olmaması gereken veri bütünlüğü sorunlarını saatlerce ayıklamak zorunda kalırsınız. Veritabanınız büyüdükçe bu sorunlar katlanır.
Veritabanı normalizasyonu, verilerinizi kanıtlanmış matematiksel ilkelere göre düzenleyerek bu dertleri ortadan kaldırır. Süreç, her bilginin tam olarak tek bir yerde bulunmasını sağlayan normal formları kullanır; böylece veritabanınız güvenilir ve verimli hale gelir.
Dağınık verileri tertipli, bakımı kolay veritabanı yapılarına dönüştüren uygulamalı örneklerle, temel kavramlardan gelişmiş normal formlara kadar eksiksiz normalizasyon sürecini göstereceğim.
Normalizasyon, veritabanınızın bir bakım kabusuna dönüşmesini engeller. Gerçek hayat uygulamaları için uygun normalizasyonun neden önemli olduğuna bakalım.
Fazlalık, veritabanı performansının sessiz katilidir. Aynı bilgiyi birden fazla yerde sakladığınızda, yalnızca depolama alanını israf etmekle kalmazsınız—uygulama mantığınızı bozan tutarsızlıklara davetiye çıkarırsınız.
Normalizasyon olmadan bir müşterinin adresini güncellemek, adres verisini tutan her tabloyu tek tek bulmayı gerektirir. Birini atlayın, raporlarınız çelişkili bilgiler gösterir. Kullanıcılar farklı ekranlarda farklı adresler görür. Analitikleriniz güvenilmez hale gelir.
Normalizasyon, her veri parçasının tam olarak tek bir yerde yaşamasını sağlayarak bunu düzeltir. O müşterinin adresini güncellediğinizde, her şey aynı kaynağa referans verdiği için bilgiler otomatik olarak her yerde değişir.
Doğru şekilde normalize ettiğinizde bütünlük adeta kurşun geçirmez olur. Yabancı anahtar kısıtları sahipsiz kayıtları engeller. Hâlâ aktif siparişleri olan bir müşteriyi yanlışlıkla silemezsiniz. Veritabanınız, iş kurallarını yalnızca uygulama kodunda değil, veri düzeyinde uygular.
Bu da daha az hata, daha temiz kod ve aynı veriye birden çok sistem eriştiğinde bile öngörülebilir davranan uygulamalar demektir.
Doğru normalizasyonla değişiklik anomalileri ortadan kalkar. Bunlar, veri eklediğinizde, güncellediğinizde veya sildiğinizde tutarsızlık yarattığınız ya da karmaşık çözümler gerektirdiğiniz durumlardır.
Ekleme anomalileri, yalnızca bir kayıt oluşturmak için sahte veri eklemenizi zorunlu kılar. Güncelleme anomalileri, aynı bilgiyi birden çok satırda değiştirmenizi gerektirir. Silme anomalileri, tek bir kaydı sildiğinizde amaçlanandan daha fazla bilgiyi ortadan kaldırır.
Normalize edilmiş veritabanları, her olgunun bir kez ve yalnızca bir kez görüneceği şekilde verileri düzenleyerek bu sorunları ortadan kaldırır.
Veritabanı yapınız temiz olduğunda performans ve ölçeklenebilirlik artar. Normalleştirilmiş tablolar genellikle daha küçüktür; bu da daha hızlı sorgular ve daha iyi önbellek kullanımı demektir. Dizinler daha küçük, odaklı tablolar üzerinde daha etkili çalışır.
Veritabanınız yatay olarak ölçeklenebilir, çünkü normalize edilmiş verilerin net sınırları vardır. Bilgiyi parçalar (shard) arasında çoğaltmadan tabloları mantıksal olarak bölümleyebilirsiniz.
Güvenliği normalize edilmiş veritabanlarında yönetmek daha kolaydır. Hassas veriler belirli, iyi tanımlanmış yerlerde bulunduğu için tablo düzeyinde erişimi güvenle kontrol edebilirsiniz. Beklenmedik tablolarda saklanan müşteri kredi kartı numaraları için endişelenmenize gerek kalmaz.
Denetim izleri de daha temizdir—değişikliklerin tam olarak nerede olduğunu bilirsiniz ve şemanız boyunca dağılmış fazla veriler içinde avlanmadan izleyebilirsiniz.
Özetle, normalizasyon kaotik verileri, uygulamanızla birlikte büyüyen güvenilir bir temele dönüştürür.
Şimdi normalizasyon için ön koşullara bakalım.
Tabloları normalleştirmeye başlamadan önce, normalizasyonun nasıl çalıştığını anlamanız gerekir. Süreç boyunca kararlarınıza yön verecek temel kavramları ele alalım.
Anahtarlar ilişkisel veritabanı tasarımının temelidir—kayıtları tanımlar ve tabloları birbirine bağlar.
Bir birincil anahtar bir tablodaki her satırı benzersiz olarak tanımlar. İki satır aynı birincil anahtar değerine sahip olamaz ve bu değer null olamaz. Bunu verileriniz için bir T.C. kimlik numarası gibi düşünün—her kaydın tam olarak bir tane vardır ve kopya yoktur.
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
email VARCHAR(255),
name VARCHAR(100)
);Burada customer_id birincil anahtardır. Her müşteriye, diğer tablolardan o müşteriye referans verirken kullanacağınız benzersiz bir kimlik verilir.
Aday anahtar, birincil anahtar olarak hizmet edebilecek herhangi bir sütun (veya sütun kombinasyonu) demektir. customers tablonuzda hem customer_id hem de email müşterileri benzersiz tanımladığı için aday anahtar olabilir. Birini birincil anahtar olarak seçersiniz, diğerleri aday anahtar olarak kalır.
Yabancı anahtarlar tablolar arasında ilişki kurar. Başka bir tablonun birincil anahtarını referans alır ve veri bütünlüğünü koruyan bağlantılar oluşturur.
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
order_date DATE,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);orders tablosundaki customer_id bir yabancı anahtardır. customers tablosunda var olan bir customer_id ile eşleşmelidir. Bu, sahipsiz siparişleri önler ve her siparişin gerçek bir müşteriye ait olmasını sağlar.
Anahtarlar, iş kurallarını veritabanı düzeyinde uygular; bu da verilerinizi yalnızca uygulama doğrulamasına kıyasla daha güvenilir kılar.
Fonksiyonel bağımlılıklar, bir tablo içindeki sütunların birbirleriyle nasıl ilişkili olduğunu açıklar. Normalizasyon kararlarını yönlendiren matematiksel temeldir.
Bir sütunun değeri başka bir sütunun değerini belirlediğinde fonksiyonel bağımlılık vardır. Bunu A → B şeklinde yazarız; bu, "A B'yi belirler" ya da "B, A'ya bağlıdır" anlamına gelir.
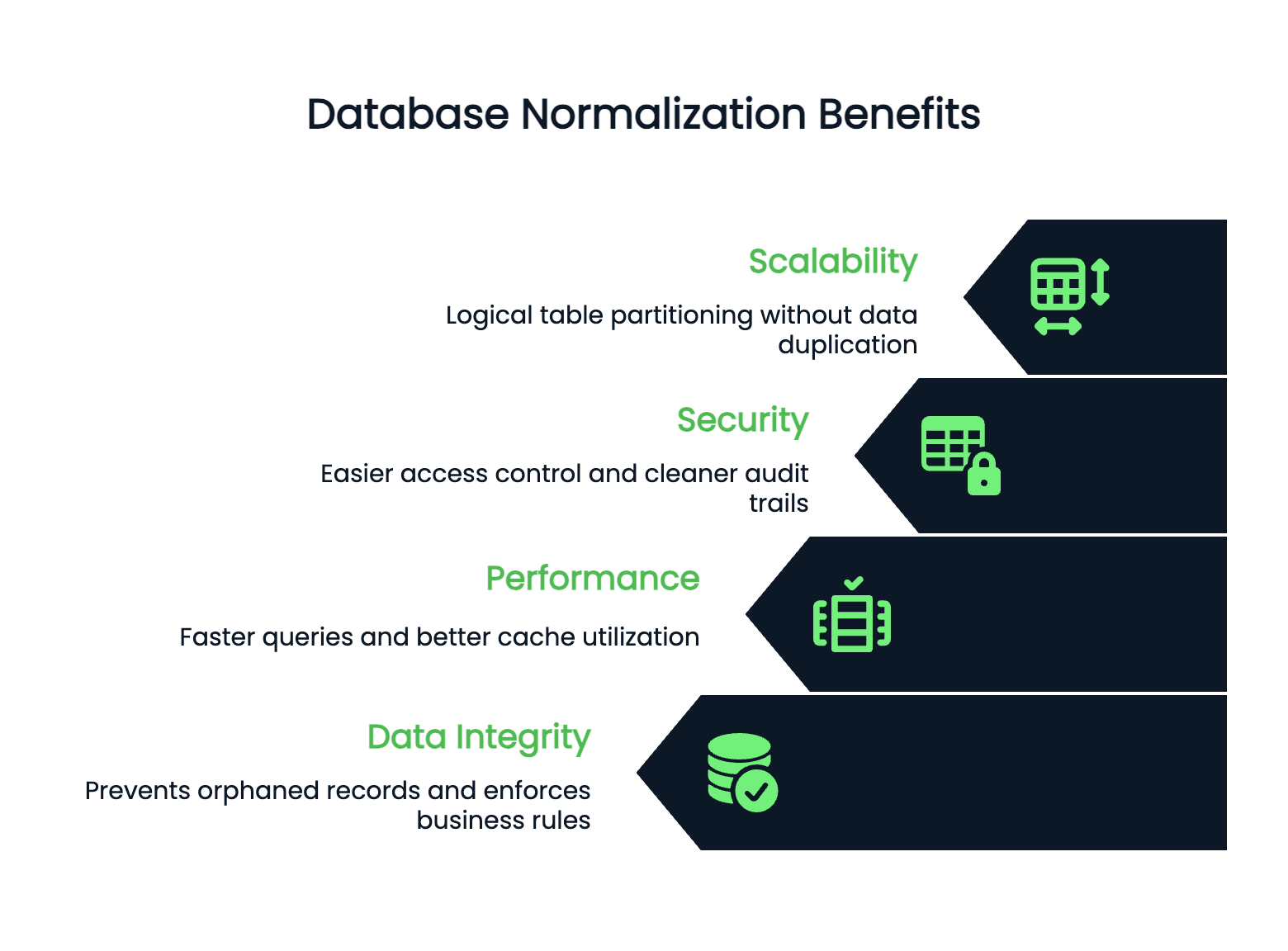
Bir customers tablosunda, customer_id → email çünkü her müşteri kimliği tam olarak bir e-posta adresine karşılık gelir. Müşteri kimliğini biliyorsanız, e-postayı kesin olarak belirleyebilirsiniz.

Görsel 1 - Fonksiyonel bağımlılık örneği
Burada, customer_id → email ve customer_id → name, çünkü müşteri kimliği hem e-postayı hem de adı belirler.
Fonksiyonel bağımlılıklar fazlalık sorunlarını açığa çıkarır.
Eğer bir tabloda order_id → customer_name var ama müşteri adını her sipariş satırında saklıyorsanız, fazlalık vardır. Müşterinin adı sipariş kimliğine değil, müşteri kimliğine bağlıdır.
Bağımlılık korunumu, normalize edilmiş tabloların orijinal fonksiyonel bağımlılıkların tamamını sürdürmesi anlamına gelir. Normalizasyon sırasında bir tabloyu böldüğünüzde, orijinal tablodaki iş kurallarını uygulama yeteneğinizi kaybetmemelisiniz.
Kayıpsız ayrıştırma, normalize edilmiş tabloları birleştirerek orijinal tabloyu yeniden oluşturabileceğinizi garanti eder. Tabloları böldüğünüzde bilgi kaybetmezsiniz—birleşimler, başladığınız veriyi tam olarak geri getirir.
Bu kavramlar birlikte çalışır: fonksiyonel bağımlılıklar neyin ayrılması gerektiğini belirlerken, bağımlılık korunumu ve kayıpsız ayrıştırma, süreçte hiçbir şeyi bozmadığınızdan emin olur.
Bu ilişkileri anlamak, işlevsellik kaybetmeden veritabanınızı iyileştiren akıllı normalizasyon kararları almanıza yardımcı olur.
Şimdi gerçek normalizasyon sürecini, dağınık verilerden başlayıp adım adım dönüştürerek inceleyelim. Her normal form bir öncekini temel alır; bu yüzden normalize edilmemiş veriden doğrudan 3NF'ye geçemezsiniz.
Birinci normal form, tekrar eden grupları ortadan kaldırır ve her sütunun atomik değerler içermesini sağlar. Bununla ilgili daha fazlasını Birinci Normal Form (1NF) derinlemesine rehberinde öğrenin.
Atomik değerler, her hücrenin tam olarak bir bilgi parçası tutması demektir—liste yok, virgülle ayrılmış değerler yok, tek bir alana tıkıştırılmış birden fazla veri noktası yok. Bu, diğer her şeyi mümkün kılan temeldir.
1NF'yi ihlal eden durumlar şunlardır:
CREATE TABLE orders_bad (
order_id INT,
customer_name VARCHAR(100),
products VARCHAR(500),
quantities VARCHAR(50)
);
Görsel 2 - 1NF'yi ihlal eden tablo
products ve quantities sütunları virgülle ayrılmış birden çok değer içeriyor. "Dizüstü bilgisayar içeren tüm siparişleri" kolayca sorgulayamaz veya toplam miktarları dize ayrıştırma olmadan hesaplayamazsınız.
Bunu 1NF'ye dönüştürmek için, tekrar eden grupları ayrı satırlara bölün:
-- First normal form (1NF)
CREATE TABLE orders_1nf (
order_id INT,
customer_name VARCHAR(100),
product VARCHAR(100),
quantity INT
);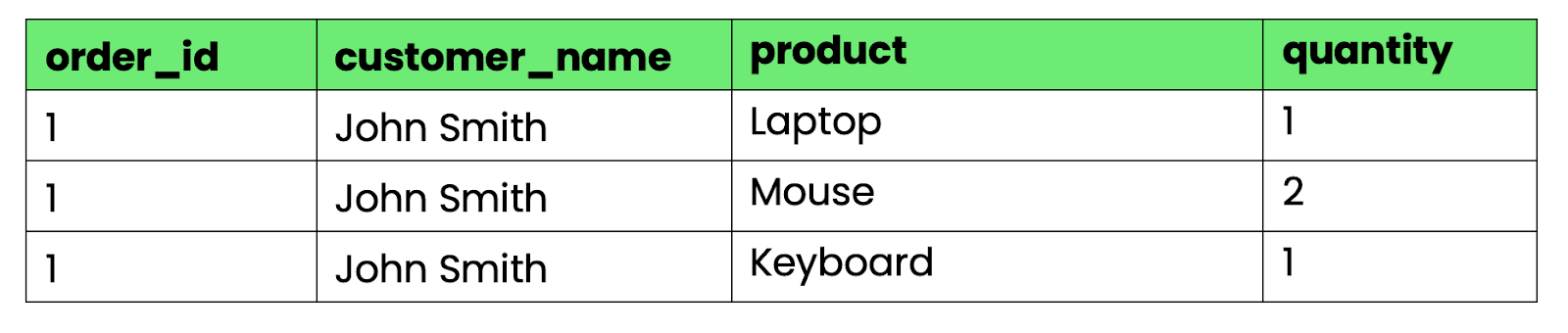
Görsel 3 - 1NF'yi sağlayan tablo
Artık her hücre tam olarak bir değer içeriyor. Veriyi standart SQL işlemleriyle sorgulayabilir, sıralayabilir ve birleştirebilirsiniz.
İkinci normal form, anahtar olmayan sütunların bileşik birincil anahtarın yalnızca bir kısmına bağlı olduğu kısmi bağımlılıkları ortadan kaldırır.
İkinci Normal Form (2NF) göründüğünden fazlasını içerir. Daha fazlasını derinlemesine rehberimizde öğrenin.
Bir tablo, 1NF'de olup her anahtar olmayan sütun tüm birincil anahtara (yalnızca bir kısmına değil) bağlıysa 2NF'dedir.
1NF tablomuzda bir sorun var. order_id ve product'ı bileşik birincil anahtar olarak kullanırsak, customer_name ürüne değil yalnızca order_id'ye bağlıdır. Bu da fazlalık yaratır—müşteri adı bir siparişteki her ürün için tekrar eder.
-- Still has partial dependencies
-- customer_name depends only on order_id, not on (order_id, product)
CREATE TABLE orders_1nf (
order_id INT,
customer_name VARCHAR(100), -- Partial dependency!
product VARCHAR(100),
quantity INT,
PRIMARY KEY (order_id, product)
);2NF'ye ulaşmak için tabloyu bağımlılıklara göre bölün:
-- Orders table (customer info depends on order_id)
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_name VARCHAR(100)
);
-- Order items table (quantity depends on both order_id and product)
CREATE TABLE order_items (
order_id INT,
product VARCHAR(100),
quantity INT,
PRIMARY KEY (order_id, product),
FOREIGN KEY (order_id) REFERENCES orders(order_id)
);Artık customer_name sipariş başına yalnızca bir kez görünür, fazlalık ortadan kalkar. Her tabloda sütunlar tüm birincil anahtara bağlıdır.
Üçüncü normal form, anahtar olmayan sütunların birincil anahtar yerine diğer anahtar olmayan sütunlara bağlı olduğu geçişli bağımlılıkları ortadan kaldırır. Üçüncü Normal Form (3NF)'u temellerin ötesinde inceleyin.
A sütunu B sütununu, B sütunu da C sütununu belirlediğinde, A'dan C'ye dolaylı bir bağımlılık oluşur; buna geçişli bağımlılık denir.
Siparişler tablomuzu müşteri adres bilgileriyle genişletelim:
-- Has transitive dependencies
CREATE TABLE orders_2nf (
order_id INT PRIMARY KEY,
customer_name VARCHAR(100),
customer_city VARCHAR(50),
customer_state VARCHAR(50),
customer_zip VARCHAR(10)
);Sorun şu: customer_name → customer_city ve customer_city → customer_state. Eyalet/bölge, doğrudan siparişe değil, şehre bağlıdır. Bu da fazlalık yaratır—aynı şehirden gelen her siparişte eyalet bilgisi tekrar eder.
3NF'ye ulaşmak için geçişli bağımlılıkları ayrı tablolar oluşturarak kaldırın:
-- Customers table (removes transitive dependencies)
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
customer_name VARCHAR(100),
city_id INT,
FOREIGN KEY (city_id) REFERENCES cities(city_id)
);
-- Cities table
CREATE TABLE cities (
city_id INT PRIMARY KEY,
city_name VARCHAR(50),
state VARCHAR(50),
zip VARCHAR(10)
);
-- Orders table (now references customer, not customer details)
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
order_date DATE,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);Artık coğrafi bilgiler tek bir yerde bulunuyor. Bir şehir eyalet değiştirirse (nadir de olsa mümkün), o şehirden gelen her siparişi aramak yerine tek bir satırı güncellersiniz.
Her normal form, orijinal verilerinizi birleştirmelerle yeniden oluşturma yeteneğini korurken belirli fazlalık sorunlarını çözer.
İlk üç normal form çoğu gerçek dünya veritabanı sorununu ele alır, ancak bazı uç durumlar daha derin normalizasyon gerektirir. Bu gelişmiş formlar, 3NF'nin çözemedği belirli bağımlılık sorunlarıyla ilgilenir.
BCNF, 3NF'nin atladığı ince bir sorunu düzeltir: bir tabloda örtüşen aday anahtarlar olduğunda.
3NF, anahtar olmayan sütunların aday anahtarlara bağlı olmasına izin verir, ancak BCNF daha katıdır. BCNF'de, her belirleyici (başka bir sütunu belirleyen sütun) bir süper anahtar olmalıdır—birincil ya da aday anahtar.
3NF'nin çöktüğü yer şurasıdır:
-- Table in 3NF but violates BCNF
CREATE TABLE course_instructors (
student_id INT,
course VARCHAR(50),
instructor VARCHAR(50),
PRIMARY KEY (student_id, course)
);İş kuralları şunlardır:
Bu durum course → instructor ve instructor → course bağımlılıklarını yaratır. Hem (student_id, course) hem de (student_id, instructor) aday anahtardır, ancak course ve instructor süper anahtar olmadan birbirlerini belirler.
Sorun, öğrencisiz yeni bir eğitmen eklemeye çalıştığınızda ortaya çıkar. "Profesör Smith Veritabanı Tasarımı'nı veriyor" bilgisini, o derse bir öğrenci eklemeden giremezsiniz.
BCNF'ye ulaşmak için sorunlu bağımlılığa göre ayrıştırın:
-- BCNF solution
CREATE TABLE course_assignments (
course VARCHAR(50) PRIMARY KEY,
instructor VARCHAR(50) UNIQUE
);
CREATE TABLE student_enrollments (
student_id INT,
course VARCHAR(50),
PRIMARY KEY (student_id, course),
FOREIGN KEY (course) REFERENCES course_assignments(course)
);Artık öğrencisiz eğitmen ekleyebilirsiniz ve veritabanı yapısı iş kurallarını birebir yansıtır.
4NF, bir sütun diğerinden bağımsız birden çok değer kümesini belirlediğinde ortaya çıkan çok değerli bağımlılıkları ortadan kaldırır.
“A Sütunu”, “B Sütunu”nda birden çok değeri belirliyor ve bu değerler tablodaki diğer sütunlardan bağımsızsa çok değerli bağımlılık vardır.
Öğrenci becerilerini ve hobilerini izleyen şu tabloyu düşünün:
-- Violates 4NF due to multi-valued dependencies
CREATE TABLE student_info (
student_id INT,
skill VARCHAR(50),
hobby VARCHAR(50),
PRIMARY KEY (student_id, skill, hobby)
);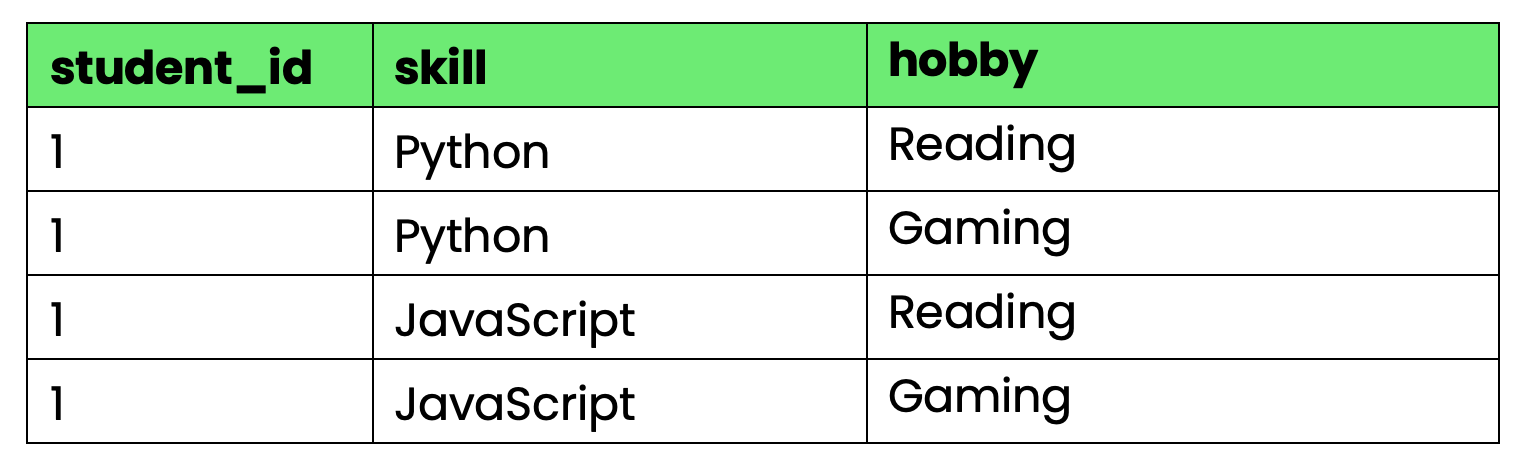
Görsel 4 - 4NF'yi ihlal eden tablo
Sorun: student_id hem becerileri hem hobileri belirliyor, ancak beceriler ve hobiler birbirinden bağımsız. Öğrenci 1 yeni bir beceri edindiğinde, her hobi kombinasyonu için satırlar oluşturmanız gerekir. Yeni bir hobi edindiğinde, her beceri kombinasyonu için satırlar gerekir.
Beceri ve hobi sayısı arttıkça bu durum patlayıcı bir fazlalık yaratır.
4NF'ye ulaşmak için bağımsız çok değerli bağımlılıkları ayırın:
-- 4NF solution
CREATE TABLE student_skills (
student_id INT,
skill VARCHAR(50),
PRIMARY KEY (student_id, skill)
);
CREATE TABLE student_hobbies (
student_id INT,
hobby VARCHAR(50),
PRIMARY KEY (student_id, hobby)
);Artık beceri ve hobileri birbirinden bağımsız ekleyebilirsiniz; Kartezyen çarpım patlamaları olmaz.
5NF (Proje-Birleştirme Normal Formu), veriyi kayıpsız yeniden oluşturmak için üç veya daha fazla tablonun birleştirilmesini gerektiren karmaşık ilişkiler olan birleştirme bağımlılıklarını ortadan kaldırır.
Bir birleştirme bağımlılığı, ayrıştırılan iki tabloyu birleştirerek orijinal tabloyu yeniden oluşturamadığınız, ancak üç veya daha fazla tabloyu birleştirerek yeniden oluşturabildiğiniz durumdur.
Şu kuralla tedarikçileri, parçaları ve projeleri düşünün: "Bir tedarikçi, bir parçayı bir projeye yalnızca o parçayı tedarik ediyor VE o projede çalışıyorsa sağlayabilir."
-- Original table with join dependency
CREATE TABLE supplier_part_project (
supplier_id INT,
part_id INT,
project_id INT,
PRIMARY KEY (supplier_id, part_id, project_id)
);5NF'ye ulaşmak için üç ikili ilişkiye ayrıştırın:
-- 5NF decomposition
CREATE TABLE supplier_parts (supplier_id INT, part_id INT);
CREATE TABLE supplier_projects (supplier_id INT, project_id INT);
CREATE TABLE project_parts (project_id INT, part_id INT);Geçerli tedarikçi-parça-proje kombinasyonlarını yalnızca üç tabloyu da birleştirerek yeniden oluşturabilirsiniz; bu da iş kuralını şema düzeyinde uygular.
6NF, her niteliği zamansal anahtarlarla kendi tablosuna koyarak normalizasyonu uç noktaya taşır.
6NF, her niteliğin zaman içinde bağımsız olarak nasıl değiştiğini izlemeniz gereken veri ambarları ve zamansal veritabanları için tasarlanmıştır.
-- 6NF example for temporal data
CREATE TABLE customer_names (
customer_id INT,
name VARCHAR(100),
valid_from DATE,
valid_to DATE
);
CREATE TABLE customer_addresses (
customer_id INT,
address VARCHAR(200),
valid_from DATE,
valid_to DATE
);Bu, her niteliğin ne zaman değiştiğini diğerlerini etkilemeden izlemenizi sağlar; ancak sorguları karmaşıklaştırır ve uzmanlaşmış zamansal veritabanı sistemleri dışında nadiren kullanılır.
Çoğu uygulama 3NF veya BCNF'de durur. Bu gelişmiş formlar belirli uç durumları çözer, ancak tipik iş uygulamaları için değmeyecek karmaşıklık ekler.
Veritabanları ve SQL hakkında daha fazlasını bu kurslarla öğrenin!
Kurs
Kurs
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Kurtis Pykes
Eğitim
Adel Nehme
