
Corso
Manipolazione dei dati in SQL
4 h
328.2K
Se non vuoi più avere a che fare con dati incoerenti e ridondanti, la normalizzazione del database è la strada giusta.
Conosci la frustrazione di aggiornare le informazioni di un cliente in una tabella per poi trovare versioni obsolete sparse in altre cinque. Le query restituiscono risultati in conflitto, i report mostrano numeri diversi a seconda della tabella da cui attingi, e passi ore a eseguire il debug di problemi di integrità dei dati che non dovrebbero esistere. Questi problemi si moltiplicano man mano che il database cresce.
La normalizzazione del database elimina questi mal di testa organizzando i dati secondo principi matematici consolidati. Il processo utilizza le forme normali per assicurarsi che ogni informazione esista in un solo posto, rendendo il tuo database affidabile ed efficiente.
Ti mostrerò l'intero processo di normalizzazione, dai concetti di base alle forme normali avanzate, con esempi pratici che trasformano dati disordinati in strutture di database pulite e manutenibili.
La normalizzazione è ciò che impedisce al tuo database di diventare un incubo di manutenzione. Vediamo perché una corretta normalizzazione conta nelle applicazioni reali.
La ridondanza è il killer silenzioso delle prestazioni dei database. Quando conservi le stesse informazioni in più punti, non stai solo sprecando spazio - stai preparando il terreno per incoerenze che mandano in crisi la logica dell'applicazione.
Senza normalizzazione, aggiornare l'indirizzo di un cliente significa inseguire ogni tabella che memorizza i dati di indirizzo. Se ne salti una, i report mostreranno informazioni in conflitto. Gli utenti vedranno indirizzi diversi su schermate diverse. Le tue analisi diventano inaffidabili.
La normalizzazione risolve questo problema assicurando che ogni dato viva in un solo posto. Quando aggiorni l'indirizzo di quel cliente, cambia ovunque automaticamente perché tutto fa riferimento alla stessa fonte.
L'integrità diventa a prova di proiettile quando normalizzi correttamente. I vincoli di chiave esterna impediscono record orfani. Non puoi eliminare per errore un cliente che ha ancora ordini attivi. Il database applica le regole di business a livello di dati, non solo nel codice dell'applicazione.
Questo significa meno bug, codice più pulito e applicazioni che si comportano in modo prevedibile anche quando più sistemi accedono agli stessi dati.
Le anomalie di modifica scompaiono con una corretta normalizzazione. Succedono quando inserisci, aggiorni o elimini dati creando inconsistenze o richiedendo complicati workaround.
Le anomalie di inserimento ti costringono ad aggiungere dati fittizi solo per creare un record. Le anomalie di aggiornamento richiedono di cambiare la stessa informazione in più righe. Le anomalie di cancellazione rimuovono più informazioni del previsto quando elimini un singolo record.
I database normalizzati eliminano questi problemi organizzando i dati in modo che ogni fatto appaia una e una sola volta.
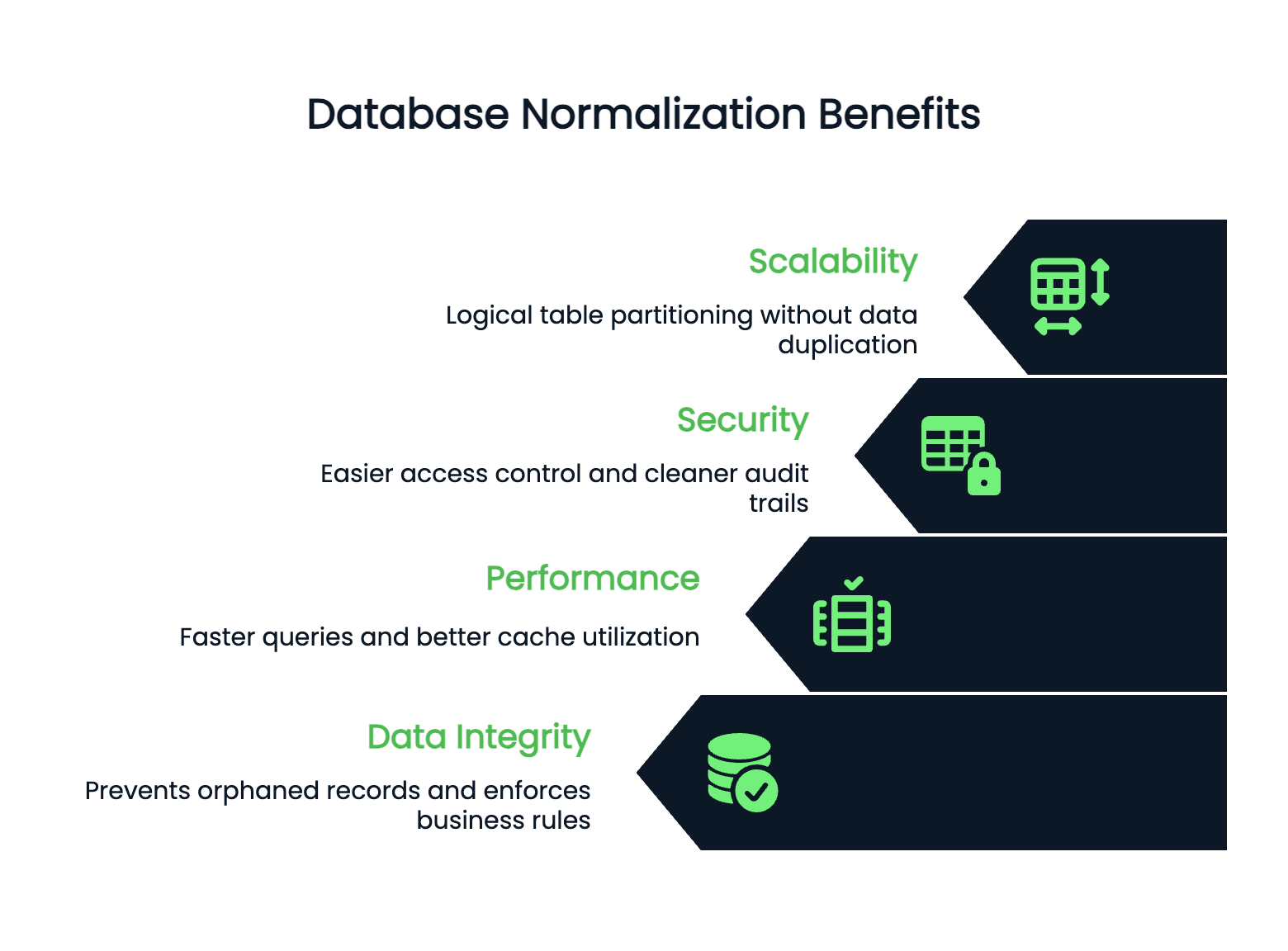
Le prestazioni e la scalabilità migliorano quando la struttura del database è pulita. Le tabelle normalizzate sono di solito più piccole, il che significa query più veloci e migliore utilizzo della cache. Gli indici funzionano più efficacemente su tabelle più piccole e focalizzate.
Il database può scalare orizzontalmente perché i dati normalizzati hanno confini chiari. Puoi partizionare logicamente le tabelle senza duplicare informazioni tra shard.
La sicurezza diventa più facile da gestire nei database normalizzati. Puoi controllare l'accesso a livello di tabella con fiducia perché i dati sensibili vivono in luoghi specifici e ben definiti. Niente più preoccupazioni per numeri di carta di credito nascosti in tabelle inaspettate.
Anche i log di audit sono più puliti: sai esattamente dove avvengono le modifiche e puoi tracciarle senza dover cercare tra dati ridondanti sparsi nello schema.
In sintesi, la normalizzazione trasforma dati caotici in una base affidabile che cresce insieme alla tua applicazione.
Vediamo ora quali sono i prerequisiti per la normalizzazione.
Prima di iniziare a normalizzare le tabelle, devi capire cosa fa funzionare la normalizzazione. Copriamo i concetti essenziali che guideranno le tue decisioni durante l'intero processo.
Le chiavi sono le fondamenta del design dei database relazionali: identificano i record e collegano le tabelle tra loro.
Una chiave primaria identifica in modo univoco ogni riga in una tabella. Nessuna due righe possono avere lo stesso valore di chiave primaria e non può essere null. Pensala come un codice fiscale per i tuoi dati: ogni record ne ha esattamente uno, e non esistono duplicati.
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
email VARCHAR(255),
name VARCHAR(100)
);Qui, customer_id è la chiave primaria. Ogni cliente ottiene un ID univoco che userai per fare riferimento a quel cliente specifico da altre tabelle.
Una chiave candidata è qualsiasi colonna (o combinazione di colonne) che potrebbe fungere da chiave primaria. La tua tabella customers potrebbe avere sia customer_id sia email come chiavi candidate, poiché entrambe identificano univocamente i clienti. Ne scegli una come chiave primaria e le altre restano chiavi candidate.
Le chiavi esterne creano relazioni tra tabelle. Fanno riferimento alla chiave primaria di un'altra tabella e stabiliscono collegamenti che mantengono l'integrità dei dati.
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
order_date DATE,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);Il customer_id nella tabella orders è una chiave esterna. Deve corrispondere a un customer_id esistente nella tabella customers. Questo impedisce ordini orfani e garantisce che ogni ordine appartenga a un cliente reale.
Le chiavi applicano le regole di business a livello di database, il che rende i tuoi dati più affidabili rispetto alla sola validazione lato applicazione.
Le dipendenze funzionali descrivono come le colonne si relazionano tra loro all'interno di una tabella. Sono la base matematica che guida le decisioni di normalizzazione.
Una dipendenza funzionale esiste quando il valore di una colonna determina il valore di un'altra. La scriviamo come A → B, che significa "A determina B" o "B dipende da A".
In una tabella customers, customer_id → email perché ogni ID cliente mappa esattamente a un indirizzo email. Se conosci l'ID cliente, puoi determinare l'email con certezza.

Immagine 1 - Esempio di dipendenza funzionale
Qui, customer_id → email e customer_id → name perché l'ID cliente determina sia l'email sia il nome.
Le dipendenze funzionali rivelano problemi di ridondanza.
Se hai una tabella in cui order_id → customer_name ma stai memorizzando il nome del cliente in ogni riga dell'ordine, hai ridondanza. Il nome del cliente dipende dal suo ID, non dall'ID dell'ordine.
La preservazione delle dipendenze significa che le tabelle normalizzate mantengono tutte le dipendenze funzionali originali. Quando dividi una tabella durante la normalizzazione, non dovresti perdere la capacità di far rispettare le regole di business presenti nella tabella originale.
La decomposizione senza perdita garantisce che tu possa ricostruire la tabella originale unendo le tabelle normalizzate. Non perdi alcuna informazione quando dividi le tabelle: le join riportano esattamente gli stessi dati di partenza.
Questi concetti lavorano insieme: le dipendenze funzionali identificano cosa va separato, mentre la preservazione delle dipendenze e la decomposizione senza perdita assicurano di non rompere nulla nel processo.
Comprendere queste relazioni ti aiuta a prendere decisioni intelligenti di normalizzazione che migliorano il database senza perdere funzionalità.
Ora percorriamo il processo di normalizzazione vero e proprio, partendo da dati disordinati e trasformandoli passo dopo passo. Ogni forma normale si basa sulla precedente, quindi non puoi passare direttamente da dati non normalizzati alla 3NF.
La prima forma normale elimina i gruppi ripetuti e assicura che ogni colonna contenga valori atomici. Scopri di più nella guida approfondita alla First Normal Form (1NF).
Valori atomici significano che ogni cella contiene esattamente un'informazione: niente liste, niente valori separati da virgole, niente più punti dati stipati in un singolo campo. Questa è la base che rende possibile tutto il resto.
Ecco cosa viola la 1NF:
CREATE TABLE orders_bad (
order_id INT,
customer_name VARCHAR(100),
products VARCHAR(500),
quantities VARCHAR(50)
);
Immagine 2 - Tabella che viola la 1NF
Le colonne products e quantities contengono più valori separati da virgole. Non puoi interrogare facilmente "tutti gli ordini che contengono laptop" o calcolare le quantità totali senza fare parsing di stringhe.
Per convertire questa tabella in 1NF, dividi i gruppi ripetuti in righe separate:
-- First normal form (1NF)
CREATE TABLE orders_1nf (
order_id INT,
customer_name VARCHAR(100),
product VARCHAR(100),
quantity INT
);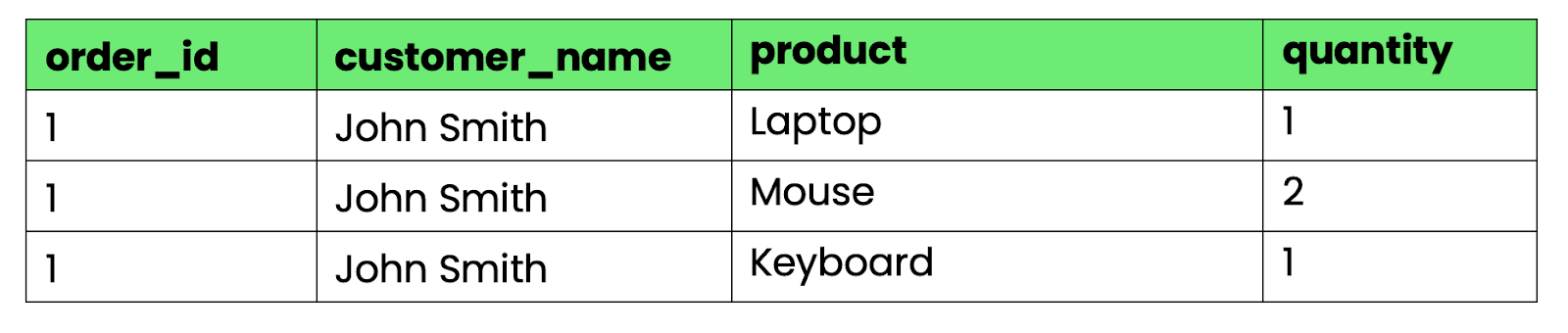
Immagine 3 - Tabella che soddisfa la 1NF
Ora ogni cella contiene esattamente un valore. Puoi interrogare, ordinare e aggregare i dati usando operazioni SQL standard.
La seconda forma normale rimuove le dipendenze parziali, quando colonne non chiave dipendono solo da una parte di una chiave primaria composta.
C'è più nella Second Normal Form (2NF) di quanto sembri. Scopri di più nella nostra guida approfondita.
Una tabella è in 2NF se è in 1NF e ogni colonna non chiave dipende dall'intera chiave primaria, non solo da una parte di essa.
La nostra tabella in 1NF ha un problema. Se usiamo order_id e product come chiave primaria composta, customer_name dipende solo da order_id, non dal prodotto. Questo crea ridondanza: il nome del cliente si ripete per ogni prodotto in un ordine.
-- Still has partial dependencies
-- customer_name depends only on order_id, not on (order_id, product)
CREATE TABLE orders_1nf (
order_id INT,
customer_name VARCHAR(100), -- Partial dependency!
product VARCHAR(100),
quantity INT,
PRIMARY KEY (order_id, product)
);Per raggiungere la 2NF, dividi la tabella in base alle dipendenze:
-- Orders table (customer info depends on order_id)
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_name VARCHAR(100)
);
-- Order items table (quantity depends on both order_id and product)
CREATE TABLE order_items (
order_id INT,
product VARCHAR(100),
quantity INT,
PRIMARY KEY (order_id, product),
FOREIGN KEY (order_id) REFERENCES orders(order_id)
);Ora customer_name appare una sola volta per ordine, eliminando la ridondanza. Ogni tabella ha colonne che dipendono dall'intera chiave primaria.
La terza forma normale elimina le dipendenze transitive, che si verificano quando colonne non chiave dipendono da altre colonne non chiave invece che dalla chiave primaria. Approfondisci la Third Normal Form (3NF) oltre le basi.
Una dipendenza transitiva esiste quando "Colonna A" determina "Colonna B" e "Colonna B" determina "Colonna C", creando una dipendenza indiretta da A a C.
Estendiamo la nostra tabella degli ordini con le informazioni sull'indirizzo del cliente:
-- Has transitive dependencies
CREATE TABLE orders_2nf (
order_id INT PRIMARY KEY,
customer_name VARCHAR(100),
customer_city VARCHAR(50),
customer_state VARCHAR(50),
customer_zip VARCHAR(10)
);Ecco il problema: customer_name → customer_city e customer_city → customer_state. Lo stato dipende dalla città, non direttamente dall'ordine. Questo crea ridondanza: ogni ordine della stessa città ripete l'informazione sullo stato.
Per raggiungere la 3NF, rimuovi le dipendenze transitive creando tabelle separate:
-- Customers table (removes transitive dependencies)
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
customer_name VARCHAR(100),
city_id INT,
FOREIGN KEY (city_id) REFERENCES cities(city_id)
);
-- Cities table
CREATE TABLE cities (
city_id INT PRIMARY KEY,
city_name VARCHAR(50),
state VARCHAR(50),
zip VARCHAR(10)
);
-- Orders table (now references customer, not customer details)
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
order_date DATE,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);Ora le informazioni geografiche vivono in un solo posto. Se una città cambia stato (raro ma possibile), aggiorni una riga invece di cercare tra tutti gli ordini di quella città.
Ogni forma normale risolve specifici problemi di ridondanza mantenendo la possibilità di ricostruire i dati originali tramite join.
Le prime tre forme normali coprono la maggior parte dei problemi reali, ma alcuni casi limite richiedono una normalizzazione più profonda. Queste forme avanzate gestiscono problemi di dipendenza specifici che la 3NF non può risolvere.
La BCNF corregge un problema sottile che la 3NF non coglie: quando una tabella ha chiavi candidate sovrapposte.
La 3NF consente che colonne non chiave dipendano da chiavi candidate, ma la BCNF è più rigorosa. In BCNF, ogni determinante (una colonna che determina un'altra colonna) deve essere una superchiave — una chiave primaria o candidata.
Ecco dove la 3NF va in crisi:
-- Table in 3NF but violates BCNF
CREATE TABLE course_instructors (
student_id INT,
course VARCHAR(50),
instructor VARCHAR(50),
PRIMARY KEY (student_id, course)
);Le regole di business sono:
Questo crea dipendenze course → instructor e instructor → course. Sia (student_id, course) sia (student_id, instructor) sono chiavi candidate, ma course e instructor si determinano a vicenda senza essere superchiavi.
Il problema emerge quando provi ad aggiungere un nuovo docente senza studenti. Non puoi inserire "Il Professor Smith insegna Database Design" senza aggiungere anche uno studente a quel corso.
Per raggiungere la BCNF, decomponi in base alla dipendenza problematica:
-- BCNF solution
CREATE TABLE course_assignments (
course VARCHAR(50) PRIMARY KEY,
instructor VARCHAR(50) UNIQUE
);
CREATE TABLE student_enrollments (
student_id INT,
course VARCHAR(50),
PRIMARY KEY (student_id, course),
FOREIGN KEY (course) REFERENCES course_assignments(course)
);Ora puoi aggiungere docenti senza studenti e la struttura del database rispecchia esattamente le regole di business.
La 4NF elimina le dipendenze multivalore, quando una colonna determina più insiemi indipendenti di valori.
Una dipendenza multivalore esiste quando "Colonna A" determina molteplici valori in "Colonna B", e questi valori sono indipendenti dalle altre colonne della tabella.
Considera questa tabella che traccia competenze e hobby degli studenti:
-- Violates 4NF due to multi-valued dependencies
CREATE TABLE student_info (
student_id INT,
skill VARCHAR(50),
hobby VARCHAR(50),
PRIMARY KEY (student_id, skill, hobby)
);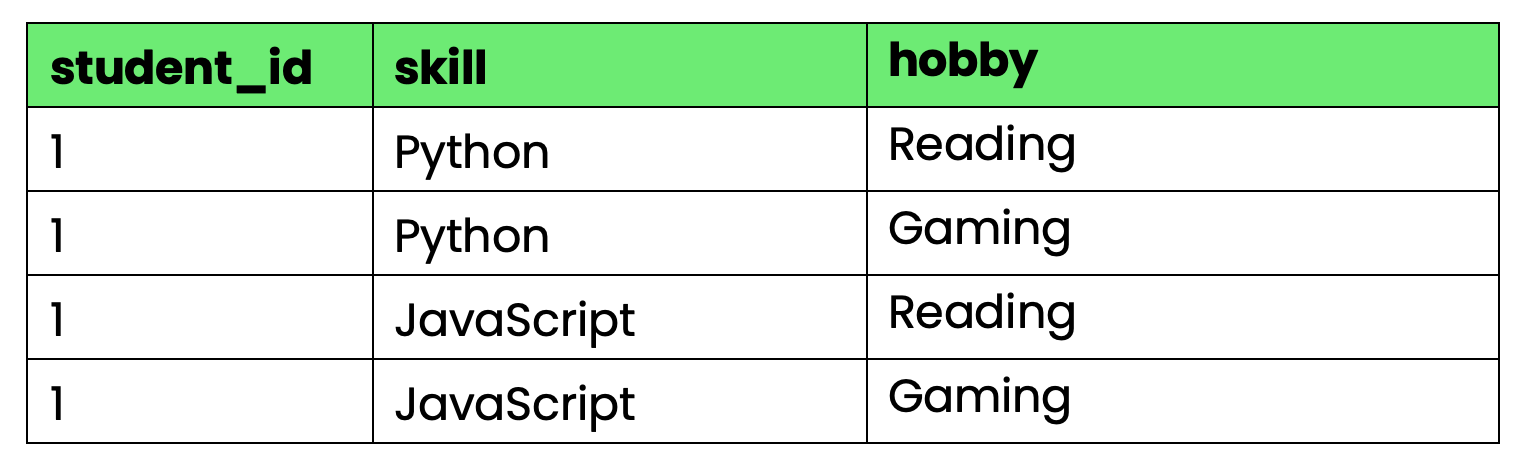
Immagine 4 - Tabella che viola la 4NF
Il problema: student_id determina sia competenze sia hobby, ma competenze e hobby sono indipendenti tra loro. Quando lo studente 1 impara una nuova competenza, devi creare righe per ogni combinazione con gli hobby. Quando acquisisce un nuovo hobby, servono righe per ogni combinazione con le competenze.
Questo crea una ridondanza esplosiva all'aumentare del numero di competenze e hobby.
Per raggiungere la 4NF, separa le dipendenze multivalore indipendenti:
-- 4NF solution
CREATE TABLE student_skills (
student_id INT,
skill VARCHAR(50),
PRIMARY KEY (student_id, skill)
);
CREATE TABLE student_hobbies (
student_id INT,
hobby VARCHAR(50),
PRIMARY KEY (student_id, hobby)
);Ora puoi aggiungere competenze e hobby in modo indipendente senza creare esplosioni di prodotto cartesiano.
La 5NF (Project-Join Normal Form) elimina le dipendenze di join: relazioni complesse che richiedono tre o più tabelle per ricostruire i dati senza perdita.
Una dipendenza di join esiste quando non puoi ricostruire la tabella originale unendo due tabelle decomposte, ma puoi ricostruirla unendo tre o più tabelle.
Considera fornitori, parti e progetti con questa regola: "Un fornitore può fornire una parte a un progetto solo se il fornitore fornisce quella parte E lavora su quel progetto."
-- Original table with join dependency
CREATE TABLE supplier_part_project (
supplier_id INT,
part_id INT,
project_id INT,
PRIMARY KEY (supplier_id, part_id, project_id)
);Per raggiungere la 5NF, decomponi in tre relazioni binarie:
-- 5NF decomposition
CREATE TABLE supplier_parts (supplier_id INT, part_id INT);
CREATE TABLE supplier_projects (supplier_id INT, project_id INT);
CREATE TABLE project_parts (project_id INT, part_id INT);Puoi ricostruire solo combinazioni valide fornitore-parte-progetto unendo tutte e tre le tabelle, il che applica la regola di business a livello di schema.
La 6NF porta la normalizzazione all'estremo mettendo ogni attributo nella propria tabella con chiavi temporali.
La 6NF è pensata per data warehouse e database temporali in cui devi tracciare come ogni attributo cambia nel tempo in modo indipendente.
-- 6NF example for temporal data
CREATE TABLE customer_names (
customer_id INT,
name VARCHAR(100),
valid_from DATE,
valid_to DATE
);
CREATE TABLE customer_addresses (
customer_id INT,
address VARCHAR(200),
valid_from DATE,
valid_to DATE
);Questo ti consente di tracciare quando è cambiato ciascun attributo senza influire sugli altri, ma rende le query complesse ed è raramente usata al di fuori di sistemi temporali specializzati.
La maggior parte delle applicazioni si ferma alla 3NF o alla BCNF. Queste forme avanzate risolvono casi limite specifici ma aggiungono complessità che di solito non vale la pena per le applicazioni business tipiche.
Approfondisci database e SQL con questi corsi!
Corso
Corso
Corso
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min

