
Curso
Manipulação de dados em SQL
4 h
324.3K
Se você nunca mais quer lidar com dados inconsistentes e redundantes, a normalização do banco de dados é a melhor opção.
Você sabe como é frustrante atualizar as informações de um cliente em uma tabela e descobrir que existem versões desatualizadas espalhadas por outras cinco tabelas. Suas consultas retornam resultados conflitantes, seus relatórios mostram números diferentes dependendo da tabela da qual você extrai os dados e você passa horas depurando problemas de integridade de dados que não deveriam existir. Esses problemas só aumentam conforme o seu banco de dados cresce.
A normalização do banco de dados acaba com essas dores de cabeça, organizando seus dados de acordo com princípios matemáticos comprovados. O processo usa formulários normais para garantir que cada informação esteja em um único lugar, tornando seu banco de dados confiável e eficiente.
Vou mostrar todo o processo de normalização, desde os conceitos básicos até as formas normais avançadas, com exemplos práticos que transformam dados confusos em estruturas de banco de dados limpas e fáceis de manter.
A normalização é o que evita que seu banco de dados vire um pesadelo de manutenção. Vamos ver por que a normalização correta é importante para aplicações do mundo real.
A redundância é o inimigo silencioso do desempenho do banco de dados. Quando você guarda as mesmas informações em vários lugares, não tá só desperdiçando espaço de armazenamento, mas também criando inconsistências que podem bagunçar a lógica do seu aplicativo.
Sem normalização, atualizar o endereço de um cliente significa procurar em todas as tabelas que armazenam dados de endereço. Se você deixar passar um, seus relatórios vão mostrar informações contraditórias. Os seus usuários veem endereços diferentes em telas diferentes. Suas análises ficam meio duvidosas.
A normalização resolve isso garantindo que cada dado fique em um único lugar. Quando você atualiza o endereço desse cliente, ele muda automaticamente em todos os lugares, porque tudo está ligado à mesma fonte.
A integridade fica à prova de balas quando você normaliza da maneira certa. As restrições de chave estrangeira evitam registros órfãos. Não dá pra apagar sem querer um cliente que ainda tem pedidos ativos. Seu banco de dados aplica regras de negócios no nível dos dados, não só no código do aplicativo.
Isso significa menos bugs, código mais limpo e aplicativos que funcionam como você espera, mesmo quando vários sistemas acessam os mesmos dados.
As anomalias de modificação desaparecem com a normalização correta. Isso rola quando você insere, atualiza ou apaga dados e cria inconsistências ou precisa de soluções complicadas.
As anomalias de inserção fazem você ter que adicionar dados falsos só pra criar um registro. As anomalias de atualização exigem que você altere as mesmas informações em várias linhas. Excluir anomalias remove mais informações do que o pretendido quando você exclui um único registro.
Os bancos de dados normalizados acabam com esses problemas organizando os dados de forma que cada fato apareça só uma vez.
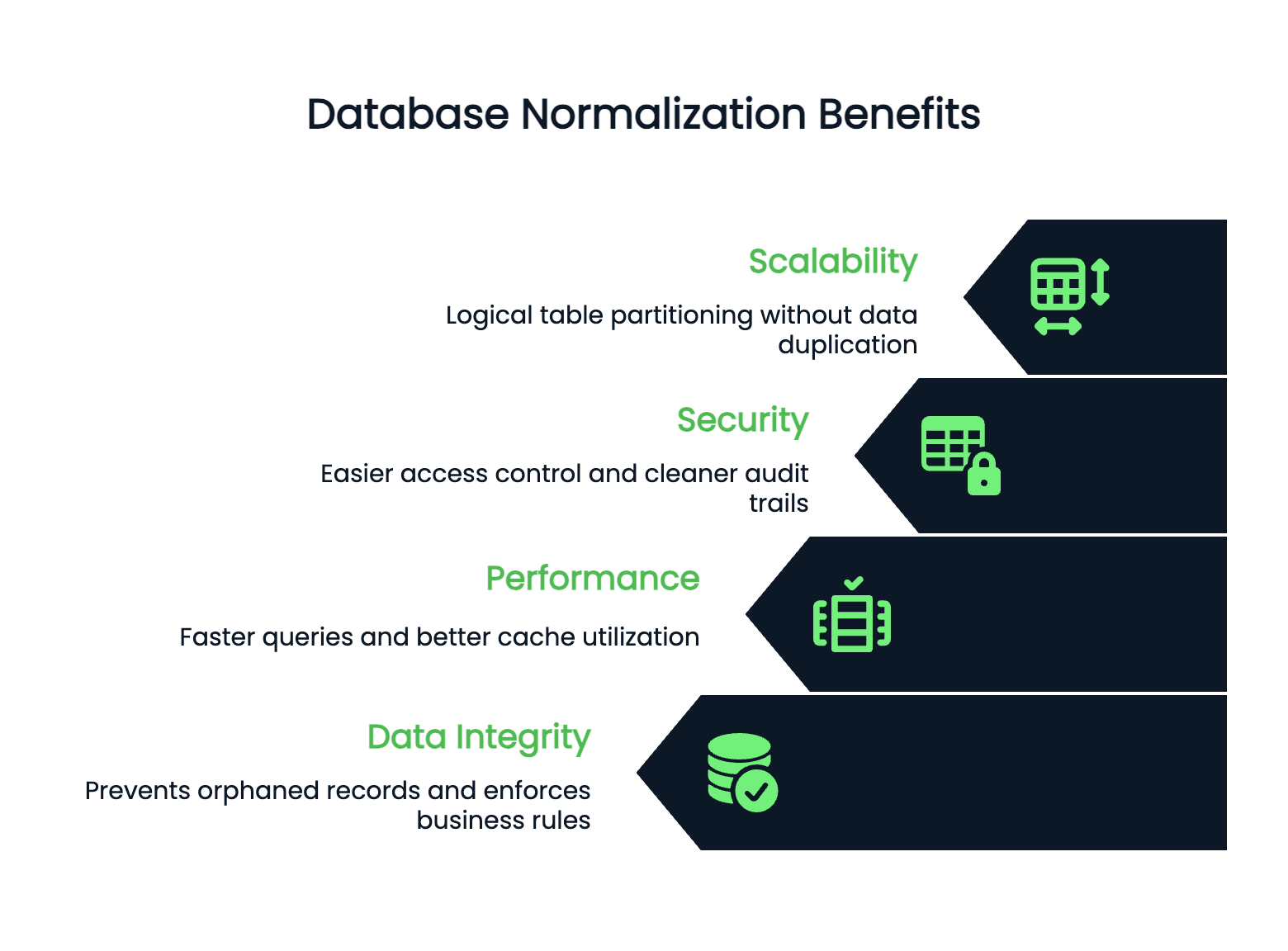
O desempenho e a escalabilidade melhoram quando a estrutura do seu banco de dados está limpa. As tabelas normalizadas são normalmente menores, o que significa consultas mais rápidas e melhor utilização do cache. Os índices funcionam melhor em tabelas menores e mais específicas.
Seu banco de dados pode ser escalonado horizontalmente porque os dados normalizados têm limites claros. Você pode dividir tabelas de forma lógica sem duplicar informações entre fragmentos.
A segurança fica mais fácil de gerenciar em bancos de dados normalizados. Você pode controlar o acesso no nível da tabela com segurança, porque os dados confidenciais ficam em lugares específicos e bem definidos. Não precisa se preocupar com os números dos cartões de crédito dos clientes ficando escondidos em tabelas inesperadas.
As trilhas de auditoria também ficam mais claras — você sabe exatamente onde as mudanças rolam e pode acompanhá-las sem precisar procurar em dados redundantes espalhados pelo seu esquema.
Resumindo, a normalização transforma dados confusos numa base confiável que cresce junto com a sua aplicação.
Vamos ver quais são os pré-requisitos para a normalização a seguir.
Antes de começar a normalizar tabelas, você precisa entender como funciona a normalização. Vamos ver os conceitos essenciais que vão te ajudar a tomar decisões durante todo o processo.
As chaves são a base do design de bancos de dados relacionais - elas identificam registros e conectam tabelas entre si.
Uma chave primária identifica de forma única cada linha de uma tabela. Duas linhas não podem ter o mesmo valor de chave primária, e ele não pode ser nulo. Pense nisso como um número de segurança social para os seus dados - cada registro recebe exatamente um, e não existem duplicatas.
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
email VARCHAR(255),
name VARCHAR(100)
);Aqui, “ customer_id ” é a chave primária. Cada cliente recebe um ID único que você vai usar pra referenciar esse cliente específico em outras tabelas.
Uma chave candidata é qualquer coluna (ou combinação de colunas) que pode servir como chave primária. A tua tabela “ customers ” pode ter tanto “ customer_id ” quanto “ email ” como chaves candidatas, já que ambas identificam os clientes de forma única. Você escolhe um como chave primária e os outros continuam sendo chaves candidatas.
As chaves estrangeiras criam relações entre tabelas. Elas fazem referência à chave primária de outra tabela e criam conexões que mantêm a integridade dos dados.
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
order_date DATE,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);customer_id na tabela orders é uma chave estrangeira. Tem que combinar com um nome de usuário ( customer_id ) que existe na tabela customers. Isso evita pedidos órfãos e garante que todos os pedidos pertençam a um cliente real.
As chaves aplicam regras de negócios no nível do banco de dados, o que torna seus dados mais confiáveis do que a validação só no aplicativo.
As dependências funcionais mostram como as colunas se relacionam entre si dentro de uma tabela. São a base matemática que orienta as decisões de normalização.
Tem uma dependência funcional quando o valor de uma coluna determina o valor de outra coluna. A gente escreve isso como “ A → B ”, que quer dizer “A determina B” ou “B depende de A”.
Em uma tabela “ customers ”, customer_id → email porque cada ID de cliente corresponde exatamente a um endereço de e-mail. Se você souber o ID do cliente, pode descobrir o e-mail com certeza.

Imagem 1 - Exemplo de dependência funcional
Aqui, customer_id → email e customer_id → name porque o ID do cliente determina tanto o e-mail quanto o nome.
As dependências funcionais mostram problemas de redundância.
Se você tem uma tabela onde order_id → customer_name, mas tá guardando o nome do cliente em cada linha do pedido, você tem redundância. O nome do cliente depende do seu documento de identificação, não do número do pedido.
Preservação de dependências significa que suas tabelas normalizadas ainda mantêm todas as dependências funcionais originais. Quando você divide uma tabela durante a normalização, não deve perder a capacidade de aplicar as regras de negócios que existiam na tabela original.
A decomposição sem perdas garante que você pode reconstruir a tabela original juntando as tabelas normalizadas. Você não perde nenhuma informação ao dividir tabelas - as junções trazem de volta exatamente os mesmos dados com os quais você começou.
Esses conceitos funcionam juntos: as dependências funcionais mostram o que precisa ser separado, enquanto a preservação da dependência e a decomposição sem perdas garantem que você não vai estragar nada no processo.
Entender essas relações ajuda você a tomar decisões inteligentes de normalização que melhoram seu banco de dados sem perder funcionalidade.
Agora vamos ver como é o processo de normalização, começando com dados bagunçados e transformando-os passo a passo. Cada forma normal se baseia na anterior, então você não pode ir direto de dados não normalizados para 3NF.
A primeira forma normal elimina grupos repetidos e garante que todas as colunas tenham valores atômicos. Saiba mais sobre a Primeira Forma Normal (1NF) no guia detalhado.
Valores atômicos significam que cada célula tem exatamente uma informação - sem listas, sem valores separados por vírgulas, sem vários pontos de dados amontoados em um único campo. Essa é a base que torna tudo o resto possível.
Aqui está o que viola a 1NF:
CREATE TABLE orders_bad (
order_id INT,
customer_name VARCHAR(100),
products VARCHAR(500),
quantities VARCHAR(50)
);
Imagem 2 - Tabela que não segue a 1NF
As colunas “ products ” e “ quantities ” têm vários valores separados por vírgulas. Não dá pra fazer uma consulta fácil do tipo “todas as encomendas com laptops” ou calcular quantidades totais sem analisar as strings.
Para converter isso para 1NF, separe os grupos repetidos em linhas separadas:
-- First normal form (1NF)
CREATE TABLE orders_1nf (
order_id INT,
customer_name VARCHAR(100),
product VARCHAR(100),
quantity INT
);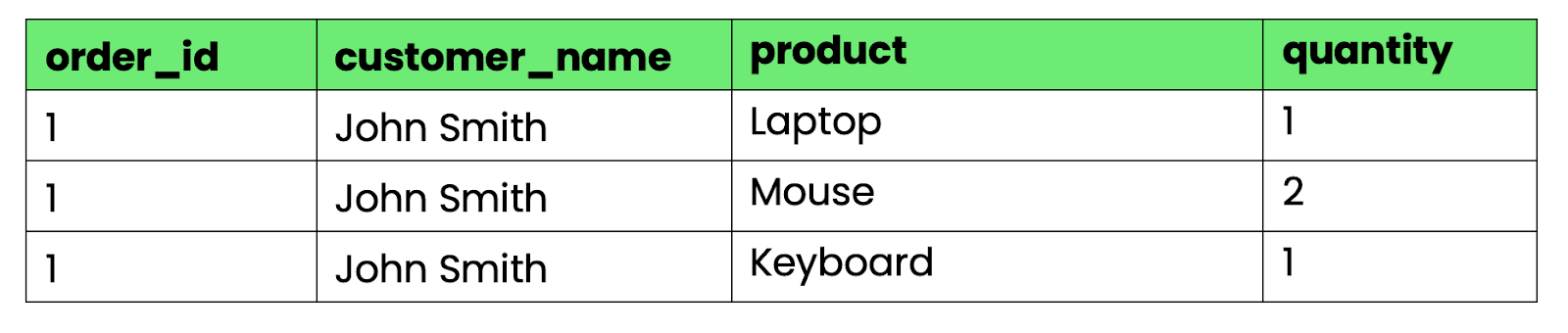
Imagem 3 - Tabela que satisfaz a 1NF
Agora, cada célula tem exatamente um valor. Você pode consultar, classificar e agregar os dados usando operações SQL padrão.
A segunda forma normal tira dependências parciais - quando colunas que não são chaves dependem só de uma parte de uma chave primária composta.
A Segunda Forma Normal (2NF) é mais complexa do que parece à primeira vista. Saiba mais sobre o mno nosso guia detalhado.
Uma tabela está em 2NF se estiver em 1NF e todas as colunas que não são chaves dependerem da chave primária inteira, não só de parte dela.
A nossa tabela 1NF tem um problema. Se usarmos order_id e product como uma chave primária composta, customer_name vai depender só de order_id, e não do produto. Isso cria redundância - o nome do cliente aparece várias vezes para cada produto em um pedido.
-- Still has partial dependencies
-- customer_name depends only on order_id, not on (order_id, product)
CREATE TABLE orders_1nf (
order_id INT,
customer_name VARCHAR(100), -- Partial dependency!
product VARCHAR(100),
quantity INT,
PRIMARY KEY (order_id, product)
);Para chegar à 2NF, divide a tabela com base nas dependências:
-- Orders table (customer info depends on order_id)
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_name VARCHAR(100)
);
-- Order items table (quantity depends on both order_id and product)
CREATE TABLE order_items (
order_id INT,
product VARCHAR(100),
quantity INT,
PRIMARY KEY (order_id, product),
FOREIGN KEY (order_id) REFERENCES orders(order_id)
);Agora, “ customer_name ” só aparece uma vez por pedido, acabando com a repetição. Cada tabela tem colunas que dependem de toda a chave primária.
A terceira forma normal elimina dependências transitivas, que acontecem quando colunas que não são chaves dependem de outras colunas que também não são chaves, em vez de depender da chave primária. Mergulhe na Terceira Forma Normal (3NF) além do básico.
Uma dependência transitiva existe quando a “Coluna A” determina a “Coluna B” e a “Coluna B” determina a “Coluna C”, criando uma dependência indireta de A para C.
Vamos expandir nossa tabela de pedidos com informações sobre o endereço do cliente:
-- Has transitive dependencies
CREATE TABLE orders_2nf (
order_id INT PRIMARY KEY,
customer_name VARCHAR(100),
customer_city VARCHAR(50),
customer_state VARCHAR(50),
customer_zip VARCHAR(10)
);E aí tá o problema: customer_name → customer_city e customer_city → customer_state. O estado depende da cidade, não diretamente da ordem. Isso cria redundância - cada pedido da mesma cidade repete as informações do estado.
Para chegar ao 3NF, tire as dependências transitivas criando tabelas separadas:
-- Customers table (removes transitive dependencies)
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
customer_name VARCHAR(100),
city_id INT,
FOREIGN KEY (city_id) REFERENCES cities(city_id)
);
-- Cities table
CREATE TABLE cities (
city_id INT PRIMARY KEY,
city_name VARCHAR(50),
state VARCHAR(50),
zip VARCHAR(10)
);
-- Orders table (now references customer, not customer details)
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
order_date DATE,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);Agora, as informações geográficas estão todas num só lugar. Se uma cidade mudar de estado (raro, mas possível), você atualiza uma linha em vez de procurar em todos os pedidos dessa cidade.
Cada forma normal resolve problemas específicos de redundância, mantendo a capacidade de reconstruir seus dados originais por meio de junções.
As três primeiras formas normais resolvem a maioria dos problemas reais de bancos de dados, mas alguns casos extremos precisam de uma normalização mais profunda. Essas formas avançadas lidam com problemas específicos de dependência que o 3NF não consegue resolver.
O BCNF resolve um problema sutil que o 3NF não consegue resolver: quando uma tabela tem chaves candidatas sobrepostas.
O 3NF permite que colunas que não são chaves dependam de chaves candidatas, mas o BCNF é mais rígido. Na BCNF, cada determinante (uma coluna que determina outra coluna) precisa ser uma superchave - seja uma chave primária ou uma chave candidata.
É aqui que a 3NF falha:
-- Table in 3NF but violates BCNF
CREATE TABLE course_instructors (
student_id INT,
course VARCHAR(50),
instructor VARCHAR(50),
PRIMARY KEY (student_id, course)
);As regras de negócio são:
Isso cria dependências para course → instructor e instructor → course. Tanto (student_id, course) quanto (student_id, instructor) são chaves candidatas, mas course e instructor determinam uma à outra sem serem superchaves.
O problema aparece quando você tenta adicionar um novo instrutor sem alunos. Você não pode colocar “O professor Smith ensina Design de Banco de Dados” sem também adicionar um aluno a esse curso.
Para conseguir o BCNF, vamos decompor com base na dependência problemática:
-- BCNF solution
CREATE TABLE course_assignments (
course VARCHAR(50) PRIMARY KEY,
instructor VARCHAR(50) UNIQUE
);
CREATE TABLE student_enrollments (
student_id INT,
course VARCHAR(50),
PRIMARY KEY (student_id, course),
FOREIGN KEY (course) REFERENCES course_assignments(course)
);Agora você pode adicionar instrutores sem alunos, e a estrutura do banco de dados corresponde exatamente às regras de negócios.
A 4NF elimina dependências multivaloradas - quando uma coluna determina vários conjuntos independentes de valores.
Uma dependência multivalor existe quando a “Coluna A” determina vários valores na “Coluna B” e esses valores são independentes de outras colunas na tabela.
Olha só essa tabela que acompanha as habilidades e os hobbies dos alunos:
-- Violates 4NF due to multi-valued dependencies
CREATE TABLE student_info (
student_id INT,
skill VARCHAR(50),
hobby VARCHAR(50),
PRIMARY KEY (student_id, skill, hobby)
);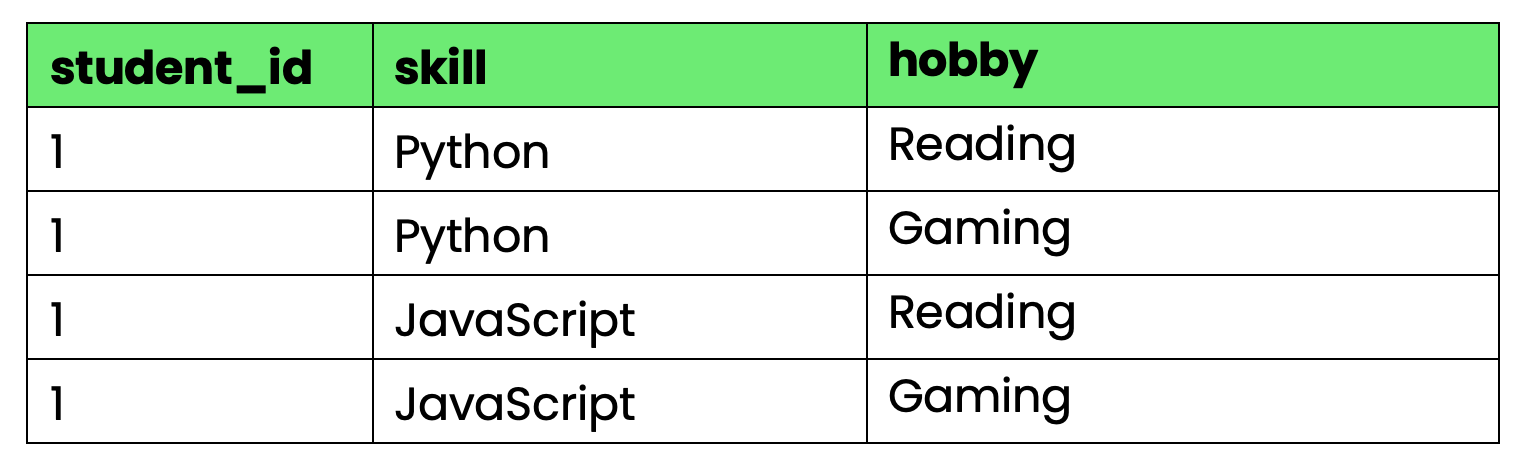
Imagem 4 - Tabela que não segue a 4NF
O problema: student_id determina tanto as habilidades quanto os hobbies, mas habilidades e hobbies são independentes um do outro. Quando o aluno 1 aprende uma nova habilidade, você precisa criar linhas para cada combinação de hobby. Quando eles começam um novo hobby, você precisa de linhas para cada combinação de habilidades.
Isso cria uma redundância enorme à medida que o número de habilidades e hobbies aumenta.
Para chegar ao 4NF, separe as dependências multivaloradas independentes:
-- 4NF solution
CREATE TABLE student_skills (
student_id INT,
skill VARCHAR(50),
PRIMARY KEY (student_id, skill)
);
CREATE TABLE student_hobbies (
student_id INT,
hobby VARCHAR(50),
PRIMARY KEY (student_id, hobby)
);Agora você pode adicionar habilidades e hobbies de forma independente, sem criar explosões de produtos cartesianos.
5NF (Forma Normal de Junção de Projetos) elimina dependências de junção: relações complexas que exigem três ou mais tabelas para reconstruir dados sem perda.
Uma dependência de junção existe quando você não consegue reconstruir a tabela original juntando duas tabelas decompostas, mas consegue reconstruí-la juntando três ou mais tabelas.
Pense nos fornecedores, peças e projetos com essa regra: “Um fornecedor só pode fornecer uma peça para um projeto se ele fornecer essa peça E trabalhar nesse projeto.”
-- Original table with join dependency
CREATE TABLE supplier_part_project (
supplier_id INT,
part_id INT,
project_id INT,
PRIMARY KEY (supplier_id, part_id, project_id)
);Para chegar ao 5NF, divide em três relações binárias:
-- 5NF decomposition
CREATE TABLE supplier_parts (supplier_id INT, part_id INT);
CREATE TABLE supplier_projects (supplier_id INT, project_id INT);
CREATE TABLE project_parts (project_id INT, part_id INT);Você só pode reconstruir combinações válidas de fornecedor-peça-projeto juntando as três tabelas, o que faz com que a regra de negócios seja aplicada no nível do esquema.
O 6NF leva a normalização ao extremo, colocando cada atributo em sua própria tabela com chaves temporais.
O 6NF foi feito pra armazenar dados e bancos de dados temporários, onde você precisa acompanhar como cada atributo muda com o tempo de forma independente.
-- 6NF example for temporal data
CREATE TABLE customer_names (
customer_id INT,
name VARCHAR(100),
valid_from DATE,
valid_to DATE
);
CREATE TABLE customer_addresses (
customer_id INT,
address VARCHAR(200),
valid_from DATE,
valid_to DATE
);Isso permite que você acompanhe quando cada atributo foi alterado sem afetar os outros, mas torna as consultas complexas e raramente é usado fora de sistemas de banco de dados temporais especializados.
A maioria das aplicações para no 3NF ou no BCNF. Essas formas avançadas resolvem casos específicos, mas adicionam uma complexidade que não vale a pena para aplicações comerciais típicas.
Aprenda mais sobre bancos de dados e SQL com esses cursos!
Curso
Curso
Curso
blog
Kurtis Pykes
11 min
blog
Summer Worsley
13 min
Tutorial
Javier Canales Luna
Tutorial
DataCamp Team
Tutorial
Oluseye Jeremiah
Tutorial
Sejal Jaiswal

