
Curso
Manipulación de datos en SQL
4 h
324.1K
Si no quieres volver a lidiar con datos incoherentes y redundantes, la normalización de bases de datos es la solución.
Ya conoces la frustración que supone actualizar la información de un cliente en una tabla y descubrir que hay versiones obsoletas repartidas por otras cinco. Tus consultas devuelven resultados contradictorios, tus informes muestran números diferentes dependiendo de la tabla de la que extraes los datos y pasas horas depurando problemas de integridad de datos que no deberían existir. Estos problemas solo se multiplican a medida que crece tu base de datos.
La normalización de bases de datos elimina estos problemas al organizar tus datos según principios matemáticos probados. El proceso utiliza formas normales para garantizar que cada dato exista en un solo lugar, lo que hace que tu base de datos sea fiable y eficiente.
Te mostraré el proceso completo de normalización, desde los conceptos básicos hasta las formas normales avanzadas, con ejemplos prácticos que transforman datos desordenados en estructuras de bases de datos limpias y fáciles de mantener.
La normalización es lo que evita que tu base de datos se convierta en una pesadilla de mantenimiento. Veamos por qué es importante una normalización adecuada para las aplicaciones del mundo real.
La redundancia es el asesino silencioso del rendimiento de las bases de datos. Cuando almacenas la misma información en varios lugares, no solo estás desperdiciando espacio de almacenamiento, sino que también estás creando inconsistencias que rompen la lógica de tu aplicación.
Sin normalización, actualizar la dirección de un cliente significa buscar en todas las tablas que almacenan datos de direcciones. Si te olvidas de uno, tus informes mostrarán información contradictoria. Tus usuarios ven direcciones diferentes en pantallas diferentes. Tus análisis dejan de ser fiables.
La normalización soluciona esto asegurándose de que cada dato se encuentre en un único lugar. Cuando actualizas la dirección de ese cliente, cambia automáticamente en todas partes porque todo hace referencia a la misma fuente.
La integridad se vuelve a prueba de balas cuando se normaliza correctamente. Las restricciones de clave externa evitan los registros huérfanos. No puedes eliminar accidentalmente a un cliente que aún tenga pedidos activos. Tu base de datos aplica las reglas de negocio a nivel de datos, no solo en el código de la aplicación.
Esto se traduce en menos errores, un código más limpio y aplicaciones que se comportan de forma predecible incluso cuando varios sistemas acceden a los mismos datos.
Las anomalías de modificación desaparecen con una normalización adecuada. Esto ocurre cuando insertas, actualizas o eliminas datos y creas inconsistencias o necesitas soluciones alternativas complejas.
Las anomalías de inserción te obligan a añadir datos ficticios solo para crear un registro. Las anomalías de actualización requieren que cambies la misma información en varias filas. Elimina anomalías elimina más información de la prevista cuando eliminas un solo registro.
Las bases de datos normalizadas eliminan estos problemas organizando los datos de manera que cada dato aparezca una sola vez.
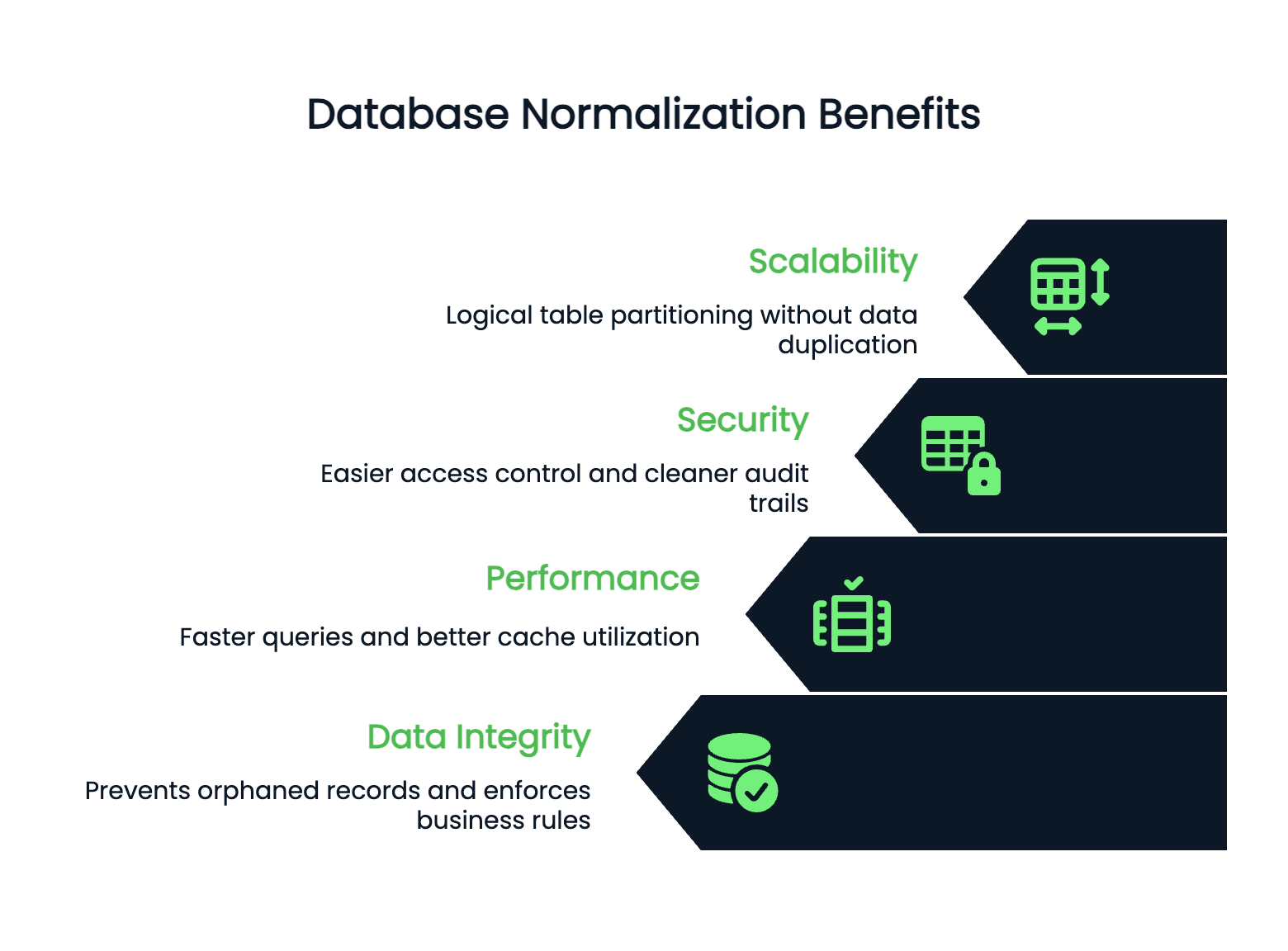
El rendimiento y la escalabilidad mejoran cuando la estructura de la base de datos está limpia. Las tablas normalizadas suelen ser más pequeñas, lo que se traduce en consultas más rápidas y un mejor uso de la caché. Los índices funcionan mejor en tablas más pequeñas y específicas.
Tu base de datos puede escalarse horizontalmente porque los datos normalizados tienen límites claros. Puedes particionar tablas de forma lógica sin duplicar información entre fragmentos.
La seguridad es más fácil de gestionar en bases de datos normalizadas. Puedes controlar el acceso a nivel de tabla con confianza, ya que los datos confidenciales se almacenan en ubicaciones específicas y bien definidas. No hay que preocuparse por los números de tarjetas de crédito de los clientes ocultos en tablas inesperadas.
Las pistas de auditoría también son más claras: sabes exactamente dónde se producen los cambios y puedes hacer un seguimiento de ellos sin tener que buscar entre datos redundantes dispersos por todo el esquema.
En resumen, la normalización transforma datos caóticos en una base fiable que crece con tu aplicación.
Veamos cuáles son los requisitos previos para la normalización.
Antes de empezar a normalizar tablas, debes comprender cómo funciona la normalización. Repasemos los conceptos esenciales que guiarán tus decisiones a lo largo del proceso.
Las claves son la base del diseño de bases de datos relacionales: identifican registros y conectan tablas entre sí.
Una clave principal identifica de forma única cada fila de una tabla. No puede haber dos filas con el mismo valor de clave principal, y este no puede ser nulo. Piensa en ello como un número de la seguridad social para tus datos: cada registro tiene uno único y no existen duplicados.
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
email VARCHAR(255),
name VARCHAR(100)
);Aquí, « customer_id » es la clave principal. Cada cliente obtiene un ID único que usarás para hacer referencia a ese cliente específico desde otras tablas.
Una clave candidata es cualquier columna (o combinación de columnas) que podría servir como clave principal. Tu tabla customers podría tener tanto customer_id como email como claves candidatas, ya que ambas identifican de forma única a los clientes. Seleccionas una como clave principal y las demás siguen siendo claves candidatas.
Las claves externas crean relaciones entre tablas. Hacen referencia a la clave principal de otra tabla y establecen conexiones que mantienen la integridad de los datos.
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
order_date DATE,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);customer_id en la tabla orders es una clave externa. Debe coincidir con un customer_id que exista en la tabla customers. Esto evita los pedidos huérfanos y garantiza que todos los pedidos pertenezcan a un cliente real.
Las claves aplican reglas de negocio a nivel de la base de datos, lo que hace que tus datos sean más fiables que con la validación solo a nivel de aplicación.
Las dependencias funcionales describen cómo se relacionan las columnas entre sí dentro de una tabla. Son la base matemática que impulsa las decisiones de normalización.
Existe una dependencia funcional cuando el valor de una columna determina el valor de otra columna. Escribimos esto como « A → B », que significa «A determina B» o «B depende de A».
En una tabla « customers », customer_id → email porque cada ID de cliente se asigna a una sola dirección de correo electrónico. Si conoces el ID del cliente, puedes determinar el correo electrónico con certeza.

Imagen 1: Ejemplo de dependencia funcional
Aquí, customer_id → email y customer_id → name porque el ID de cliente determina tanto el correo electrónico como el nombre.
Las dependencias funcionales revelan problemas de redundancia.
Si tienes una tabla en la que order_id → customer_name pero estás almacenando el nombre del cliente en cada fila del pedido, tienes redundancia. El nombre del cliente depende de tu ID, no del ID del pedido.
La preservación de la dependencia ( ) significa que tus tablas normalizadas siguen manteniendo todas las dependencias funcionales originales. Cuando divides una tabla durante la normalización, no debes perder la capacidad de aplicar las reglas de negocio que existían en la tabla original.
La descomposición sin pérdidas garantiza que puedas reconstruir la tabla original uniendo las tablas normalizadas. No se pierde ninguna información al dividir tablas: las uniones recuperan exactamente los mismos datos con los que empezaste.
Estos conceptos funcionan conjuntamente: las dependencias funcionales identifican lo que hay que separar, mientras que la preservación de las dependencias y la descomposición sin pérdidas garantizan que no se rompa nada en el proceso.
Comprender estas relaciones te ayuda a tomar decisiones de normalización inteligentes que mejoran tu base de datos sin perder funcionalidad.
Ahora veamos el proceso de normalización real, comenzando con datos desordenados y transformándolos paso a paso. Cada forma normal se basa en la anterior, por lo que no puedes pasar directamente de datos no normalizados a 3NF.
La primera forma normal elimina los grupos repetidos y garantiza que todas las columnas contengan valores atómicos. Más información sobre la primera forma normal (1NF) en la guía detallada sobre l.
Los valores atómicos significan que cada celda contiene exactamente un dato: sin listas, sin valores separados por comas, sin múltiples puntos de datos apiñados en un solo campo. Esta es la base que hace posible todo lo demás.
Esto es lo que incumple la 1NF:
CREATE TABLE orders_bad (
order_id INT,
customer_name VARCHAR(100),
products VARCHAR(500),
quantities VARCHAR(50)
);
Imagen 2 - Tabla que incumple la 1NF
Las columnas « products » y « quantities » contienen varios valores separados por comas. No puedes consultar fácilmente «todos los pedidos que contienen ordenadores portátiles» ni calcular las cantidades totales sin analizar cadenas.
Para convertir esto a 1NF, divide los grupos repetidos en filas separadas:
-- First normal form (1NF)
CREATE TABLE orders_1nf (
order_id INT,
customer_name VARCHAR(100),
product VARCHAR(100),
quantity INT
);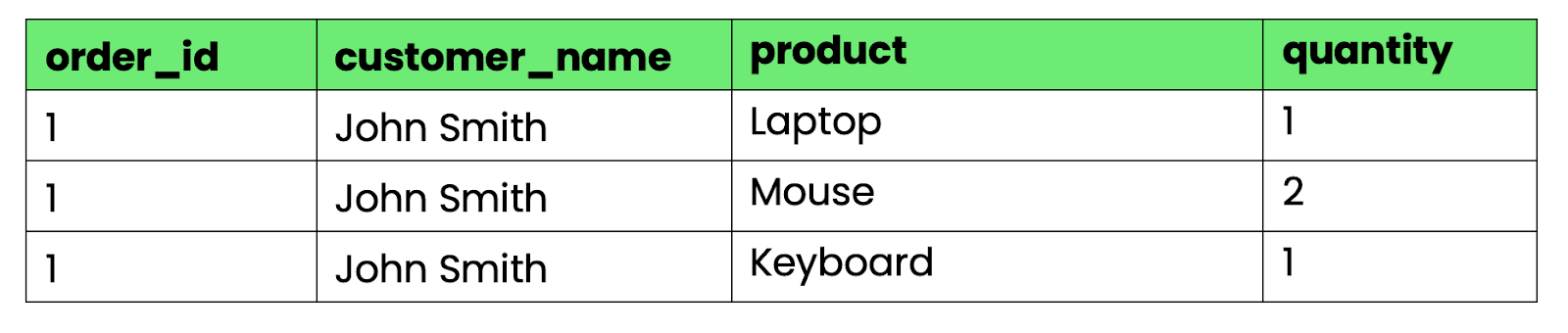
Imagen 3 - Tabla que cumple con 1NF
Ahora, cada celda contiene exactamente un valor. Puedes consultar, ordenar y agregar los datos mediante operaciones SQL estándar.
La segunda forma normal elimina las dependencias parciales, es decir, cuando las columnas que no son clave dependen solo de una parte de una clave primaria compuesta.
La segunda forma normal (2NF) es más compleja de lo que parece a simple vista. Más información sobre more en nuestra guía detallada.
Una tabla está en 2NF si está en 1NF y todas las columnas que no son clave dependen de toda la clave primaria, no solo de una parte de ella.
Nuestra tabla 1NF tiene un problema. Si utilizamos order_id y product como clave primaria compuesta, customer_name solo depende de order_id, no del producto. Esto crea redundancia: el nombre del cliente se repite para cada producto de un pedido.
-- Still has partial dependencies
-- customer_name depends only on order_id, not on (order_id, product)
CREATE TABLE orders_1nf (
order_id INT,
customer_name VARCHAR(100), -- Partial dependency!
product VARCHAR(100),
quantity INT,
PRIMARY KEY (order_id, product)
);Para lograr la 2NF, divide la tabla en función de las dependencias:
-- Orders table (customer info depends on order_id)
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_name VARCHAR(100)
);
-- Order items table (quantity depends on both order_id and product)
CREATE TABLE order_items (
order_id INT,
product VARCHAR(100),
quantity INT,
PRIMARY KEY (order_id, product),
FOREIGN KEY (order_id) REFERENCES orders(order_id)
);Ahora, customer_name solo aparece una vez por pedido, lo que elimina la redundancia. Cada tabla tiene columnas que dependen de toda la clave primaria.
La tercera forma normal elimina las dependencias transitivas, que se producen cuando columnas que no son clave dependen de otras columnas que tampoco lo son, en lugar de depender de laclave primaria. Sumérgete en la tercera forma normal (3NF) más allá de los conceptos básicos.
Existe una dependencia transitiva cuando «Columna A» determina «Columna B» y «Columna B» determina «Columna C», creando una dependencia indirecta de A a C.
Ampliemos nuestra tabla de pedidos con la información de la dirección del cliente:
-- Has transitive dependencies
CREATE TABLE orders_2nf (
order_id INT PRIMARY KEY,
customer_name VARCHAR(100),
customer_city VARCHAR(50),
customer_state VARCHAR(50),
customer_zip VARCHAR(10)
);Aquí está el problema: customer_name → customer_city y customer_city → customer_state. El estado depende de la ciudad, no directamente del orden. Esto crea redundancia: cada pedido de la misma ciudad repite la información del estado.
Para lograr la 3NF, elimina las dependencias transitivas creando tablas separadas:
-- Customers table (removes transitive dependencies)
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
customer_name VARCHAR(100),
city_id INT,
FOREIGN KEY (city_id) REFERENCES cities(city_id)
);
-- Cities table
CREATE TABLE cities (
city_id INT PRIMARY KEY,
city_name VARCHAR(50),
state VARCHAR(50),
zip VARCHAR(10)
);
-- Orders table (now references customer, not customer details)
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
order_date DATE,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);Ahora toda la información geográfica se encuentra en un solo lugar. Si una ciudad cambia de estado (algo poco habitual, pero posible), actualiza una fila en lugar de buscar en todos los pedidos de esa ciudad.
Cada forma normal resuelve problemas específicos de redundancia, al tiempo que mantiene la capacidad de reconstruir los datos originales mediante uniones.
Las tres primeras formas normales resuelven la mayoría de los problemas reales que se plantean en las bases de datos, pero algunos casos extremos requieren una normalización más profunda. Estas formas avanzadas tratan cuestiones específicas de dependencia que la 3NF no puede resolver.
BCNF soluciona un problema sutil que 3NF pasa por alto: cuando una tabla tiene claves candidatas superpuestas.
La 3NF permite que las columnas no clave dependan de claves candidatas, pero la BCNF es más estricta. En BCNF, cada determinante (una columna que determina otra columna) debe ser una superclave, ya sea una clave primaria o una clave candidata.
Aquí es donde se rompe el 3NF:
-- Table in 3NF but violates BCNF
CREATE TABLE course_instructors (
student_id INT,
course VARCHAR(50),
instructor VARCHAR(50),
PRIMARY KEY (student_id, course)
);Las reglas de negocio son:
Esto crea dependencias de course → instructor y instructor → course. Tanto (student_id, course) como (student_id, instructor) son claves candidatas, pero course y instructor se determinan entre sí sin ser superclaves.
El problema aparece cuando intentas añadir un nuevo instructor sin alumnos. No puedes insertar «El profesor Smith imparte Diseño de bases de datos» sin añadir también un alumno a ese curso.
Para lograr el BCNF, descompone en función de la dependencia problemática:
-- BCNF solution
CREATE TABLE course_assignments (
course VARCHAR(50) PRIMARY KEY,
instructor VARCHAR(50) UNIQUE
);
CREATE TABLE student_enrollments (
student_id INT,
course VARCHAR(50),
PRIMARY KEY (student_id, course),
FOREIGN KEY (course) REFERENCES course_assignments(course)
);Ahora puedes añadir profesores sin alumnos, y la estructura de la base de datos se ajusta exactamente a las normas de la empresa.
La 4NF elimina las dependencias multivalor, es decir, cuando una columna determina varios conjuntos independientes de valores.
Existe una dependencia multivalor cuando la «columna A» determina varios valores en la «columna B» y esos valores son independientes de otras columnas de la tabla.
Considera esta tabla que realiza un seguimiento de las habilidades y aficiones de los alumnos:
-- Violates 4NF due to multi-valued dependencies
CREATE TABLE student_info (
student_id INT,
skill VARCHAR(50),
hobby VARCHAR(50),
PRIMARY KEY (student_id, skill, hobby)
);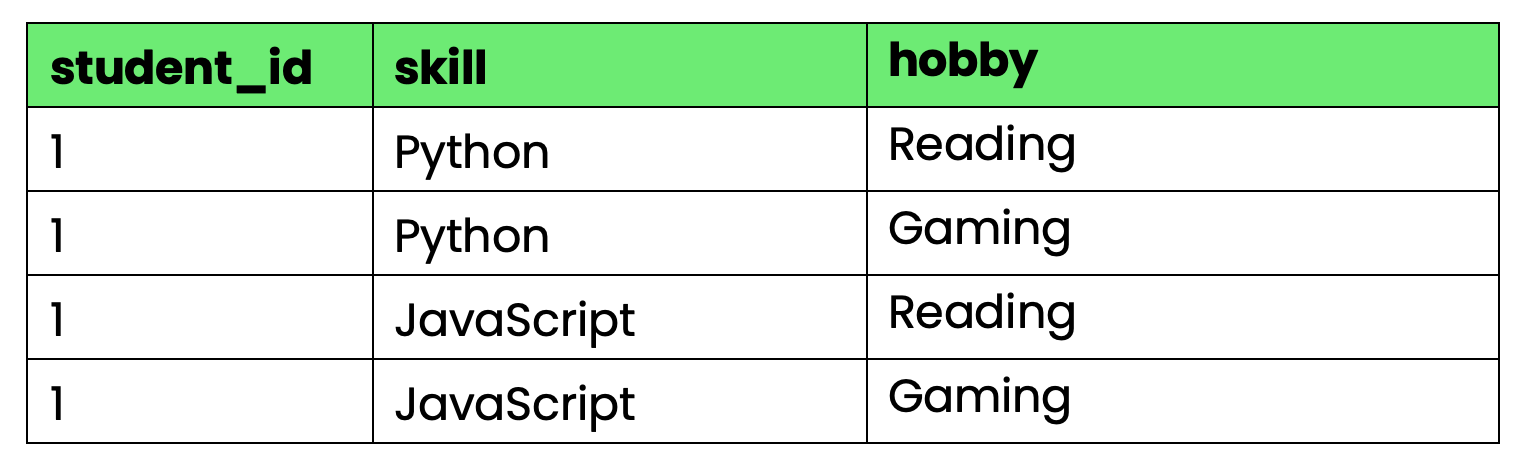
Imagen 4 - Tabla que incumple la 4NF
El problema: student_id determina tanto las habilidades como los pasatiempos, pero las habilidades y los pasatiempos son independientes entre sí. Cuando el alumno 1 aprende una nueva habilidad, debes crear filas para cada combinación de aficiones. Cuando empiezan un nuevo hobby, necesitas filas para cada combinación de habilidades.
Esto crea una redundancia explosiva a medida que aumenta el número de habilidades y aficiones.
Para lograr la 4NF, separa las dependencias multivalor independientes:
-- 4NF solution
CREATE TABLE student_skills (
student_id INT,
skill VARCHAR(50),
PRIMARY KEY (student_id, skill)
);
CREATE TABLE student_hobbies (
student_id INT,
hobby VARCHAR(50),
PRIMARY KEY (student_id, hobby)
);Ahora puedes añadir habilidades y aficiones de forma independiente sin crear explosiones de productos cartesianos.
5NF (forma normal de unión de proyectos) elimina las dependencias de unión: relaciones complejas que requieren tres o más tablas para reconstruir datos sin pérdidas.
Existe una dependencia de unión cuando no puedes reconstruir la tabla original uniendo dos tablas descompuestas, pero sí puedes reconstruirla uniendo tres o más tablas.
Ten en cuenta los proveedores, las piezas y los proyectos con esta regla: «Un proveedor solo puede suministrar una pieza para un proyecto si suministra esa pieza Y trabaja en ese proyecto».
-- Original table with join dependency
CREATE TABLE supplier_part_project (
supplier_id INT,
part_id INT,
project_id INT,
PRIMARY KEY (supplier_id, part_id, project_id)
);Para lograr el 5NF, descompón en tres relaciones binarias:
-- 5NF decomposition
CREATE TABLE supplier_parts (supplier_id INT, part_id INT);
CREATE TABLE supplier_projects (supplier_id INT, project_id INT);
CREATE TABLE project_parts (project_id INT, part_id INT);Solo puedes reconstruir combinaciones válidas de proveedor-pieza-proyecto uniendo las tres tablas, lo que aplica la regla de negocio a nivel de esquema.
6NF lleva la normalización al extremo al colocar cada atributo en su propia tabla con claves temporales.
6NF está diseñado para almacenes de datos y bases de datos temporales en las que es necesario realizar un seguimiento independiente de cómo cambia cada atributo a lo largo del tiempo.
-- 6NF example for temporal data
CREATE TABLE customer_names (
customer_id INT,
name VARCHAR(100),
valid_from DATE,
valid_to DATE
);
CREATE TABLE customer_addresses (
customer_id INT,
address VARCHAR(200),
valid_from DATE,
valid_to DATE
);Esto te permite realizar un seguimiento de cuándo se ha modificado cada atributo sin afectar a los demás, pero complica las consultas y rara vez se utiliza fuera de los sistemas de bases de datos temporales especializados.
La mayoría de las aplicaciones se detienen en 3NF o BCNF. Estas formas avanzadas resuelven casos extremos específicos, pero añaden una complejidad que no merece la pena para las aplicaciones empresariales típicas.
¡Aprende más sobre bases de datos y SQL con estos cursos!
Curso
Curso
Curso
blog
Tim Lu
12 min
blog
Elena Kosourova
15 min
Tutorial
Oluseye Jeremiah
Tutorial
Sejal Jaiswal
Tutorial
Abid Ali Awan
Tutorial
Anneleen Rummens
