Kursus
Pengantar R
4 Hr
3.1M

scale() sebelum menjalankan PCA untuk memastikan kontribusi variabel yang setaraprincomp() atau prcomp() di R dengan paket FactoMineR dan factoextra untuk analisis dan visualisasiUntuk mengikuti tutorial ini, Anda sebaiknya memiliki:
corrr, ggcorrplot, FactoMineR, factoextra (instalasi dibahas dalam tutorial)Walaupun fokus kita adalah PCA, mari ingat lima teknik komponen utama berikut yang bertujuan meringkas dan memvisualisasikan data multivariat. Berbeda dari teknik lain, PCA hanya bekerja dengan variabel kuantitatif.
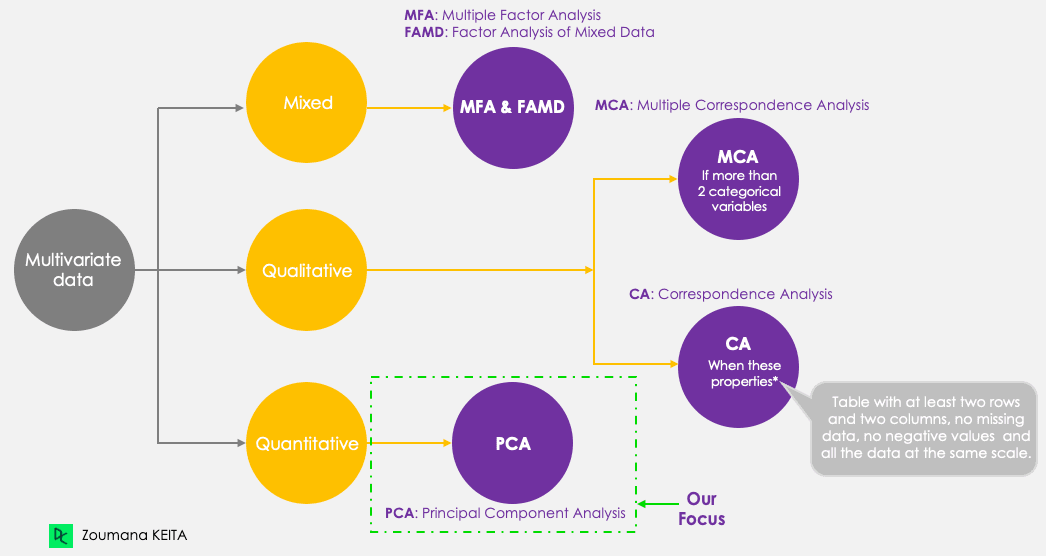
Metode komponen utama
Kita tidak akan membahas penjelasan matematisnya yang cukup kompleks. Namun, memahami lima langkah berikut dapat memberi gambaran lebih baik tentang cara menghitung PCA.
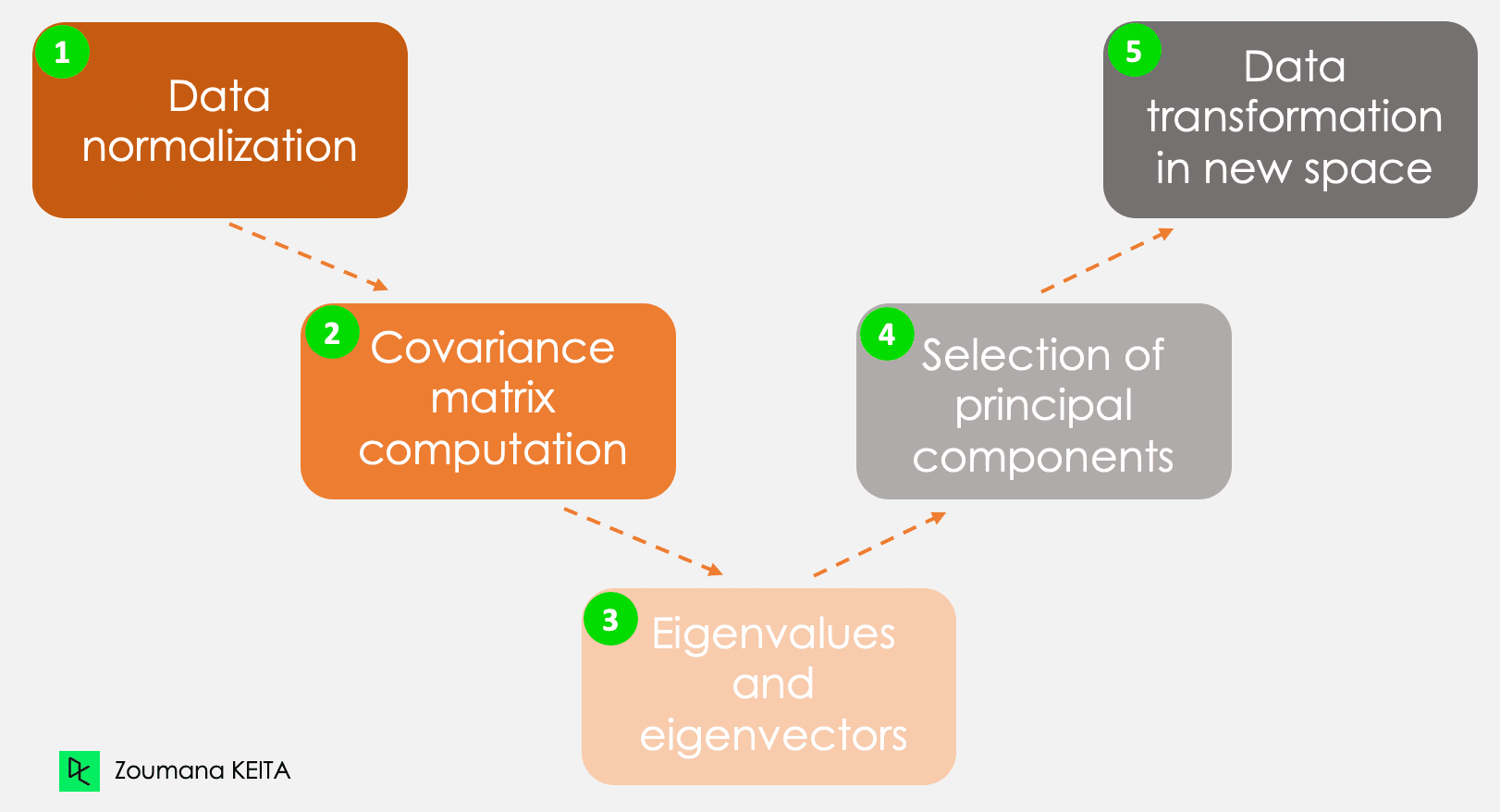
Lima langkah utama menghitung komponen utama
Merujuk contoh pada pengantar, pertimbangkan informasi berikut untuk seorang klien.
Informasi ini memiliki skala berbeda dan melakukan PCA pada data semacam itu akan menghasilkan bias. Di sinilah normalisasi data diperlukan. Ini memastikan setiap atribut memiliki tingkat kontribusi yang sama, mencegah satu variabel mendominasi yang lain. Untuk tiap variabel, normalisasi dilakukan dengan mengurangkan rata-ratanya dan membaginya dengan simpangan baku.
Sesuai namanya, langkah ini menghitung matriks kovarian dari data yang telah dinormalisasi. Ini adalah matriks simetris, dan setiap elemen (i, j) sesuai dengan kovarian antara variabel i dan j.
Secara geometris, sebuah eigenvector merepresentasikan arah seperti “vertikal” atau “90 derajat”. Sementara eigenvalue adalah angka yang merepresentasikan jumlah varians pada data untuk arah tertentu. Setiap eigenvector memiliki eigenvalue yang bersesuaian.
Jumlah pasangan eigenvector dan eigenvalue sama dengan jumlah variabel dalam data. Pada data yang hanya berisi pengeluaran bulanan, usia, dan rating, akan ada tiga pasangan. Tidak semua pasangan relevan. Karena itu, eigenvector dengan eigenvalue tertinggi adalah komponen utama pertama. Komponen utama kedua adalah eigenvector dengan eigenvalue tertinggi kedua, dan seterusnya.
Langkah ini melibatkan pengorientasian ulang data asli ke subruang baru yang didefinisikan oleh komponen utama. Reorientasi dilakukan dengan mengalikan data asli dengan eigenvector yang telah dihitung.
Penting diingat bahwa transformasi ini tidak mengubah data asli, tetapi memberikan perspektif baru untuk merepresentasikan data dengan lebih baik.
Principal component analysis memiliki beragam aplikasi dalam kehidupan sehari-hari, termasuk (namun tidak terbatas pada) keuangan, pemrosesan citra, kesehatan, dan keamanan.
Peramalan harga saham dari harga masa lalu telah lama digunakan dalam riset. PCA dapat digunakan untuk reduksi dimensi dan analisis data guna membantu para ahli menemukan komponen relevan yang menjelaskan sebagian besar variabilitas data. Anda dapat mempelajari lebih lanjut tentang reduksi dimensi di R dalam kursus kami yang khusus membahas topik ini.
Sebuah gambar tersusun dari banyak fitur. PCA terutama diterapkan pada kompresi gambar untuk mempertahankan detail penting suatu gambar sambil mengurangi jumlah dimensi. Selain itu, PCA dapat digunakan untuk tugas yang lebih kompleks seperti pengenalan gambar.
Dengan logika serupa pada kompresi gambar, PCA digunakan dalam pemindaian magnetic resonance imaging (MRI) untuk mengurangi dimensi gambar demi visualisasi dan analisis medis yang lebih baik. PCA juga dapat diintegrasikan ke teknologi medis, misalnya untuk mengenali suatu penyakit dari hasil pemindaian gambar.
Sistem biometrik untuk pengenalan sidik jari dapat mengintegrasikan teknologi yang memanfaatkan principal component analysis untuk mengekstrak fitur paling relevan, seperti tekstur sidik jari dan informasi tambahan.
Sekarang Anda memahami teori dasar PCA, saatnya melihat cara kerjanya secara langsung.
Bagian ini mencakup semua langkah dari instalasi paket yang relevan, memuat dan menyiapkan data, menerapkan principal component analysis di R, hingga menafsirkan hasilnya.
Kode sumber tersedia di DataLab.
Untuk berhasil mengikuti tutorial ini, Anda memerlukan pustaka berikut, dan masing-masing memerlukan dua langkah utama untuk digunakan secara efisien:
Ini adalah paket R untuk analisis korelasi. Fokus utamanya adalah membuat dan menangani data frame R. Berikut langkah untuk menginstal dan memuat pustaka.
install.packages("corrr")
library('corrr')Paket ggcorrplot menyediakan banyak fungsi, termasuk fungsi ggplot2 yang memudahkan visualisasi matriks korelasi. Sama seperti instruksi di atas, instalasinya sederhana.
install.packages("ggcorrplot")
library(ggcorrplot)Terutama digunakan untuk analisis data eksploratori multivariat; paket factoMineR menyediakan modul PCA untuk melakukan principal component analysis.
install.packages("FactoMineR")
library("FactoMineR")Paket terakhir ini menyediakan semua fungsi relevan untuk memvisualisasikan keluaran principal component analysis. Fungsi-fungsi ini termasuk tetapi tidak terbatas pada scree plot dan biplot—dua teknik visualisasi yang akan dibahas nanti dalam artikel.
install.packages("factoextra")
library(factoextra)Sebelum memuat data dan melakukan eksplorasi lebih lanjut, ada baiknya memahami dan mengetahui informasi dasar terkait data yang akan Anda gunakan.
Dataset protein adalah dataset multivariat bernilai riil yang menggambarkan konsumsi protein rata-rata oleh warga 25 negara Eropa.
Untuk setiap negara, ada sepuluh kolom. Delapan pertama sesuai dengan berbagai jenis protein. Yang terakhir sesuai dengan nilai total dari nilai rata-rata protein.
Mari lihat gambaran cepat data.
Pertama, kita memuat data menggunakan fungsi read.csv(), lalu str() yang menghasilkan gambar di bawah.
protein_data <- read.csv("protein.csv")
str(protein_data)Kita dapat melihat bahwa dataset memiliki 25 observasi dan 11 kolom. Setiap variabel bersifat numerik kecuali kolom Country, yang merupakan string karakter.

Deskripsi data protein
Adanya nilai hilang dapat menyebabkan hasil PCA menjadi bias. Karena itu, sangat dianjurkan melakukan pendekatan yang tepat untuk menangani nilai tersebut. Tutorial kami Teknik Teratas Menangani Nilai Hilang yang Harus Diketahui Setiap Data Scientist dapat membantu Anda memilih pendekatan yang tepat.
colSums(is.na(protein_data))Fungsi colSums() yang dikombinasikan dengan is.na() mengembalikan jumlah nilai hilang di setiap kolom. Seperti terlihat di bawah, tidak ada kolom yang memiliki nilai hilang.

Jumlah nilai hilang di setiap kolom
Seperti dinyatakan di awal artikel, PCA hanya bekerja dengan nilai numerik. Jadi, kita perlu menghilangkan kolom Country. Selain itu, kolom Total tidak relevan untuk analisis karena merupakan kombinasi linear dari variabel numerik yang tersisa.
Kode di bawah membuat data baru yang hanya berisi kolom numerik.
numerical_data <- protein_data[,2:10]
head(numerical_data)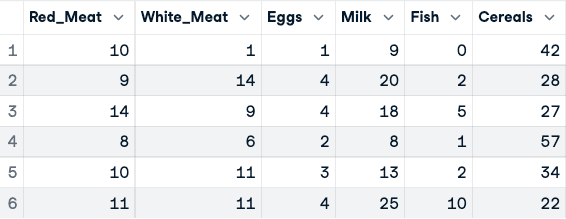
Sebelum normalisasi data (hanya lima kolom pertama yang ditampilkan)
Sekarang, normalisasi dapat diterapkan menggunakan fungsi scale().
data_normalized <- scale(numerical_data)
head(data_normalized)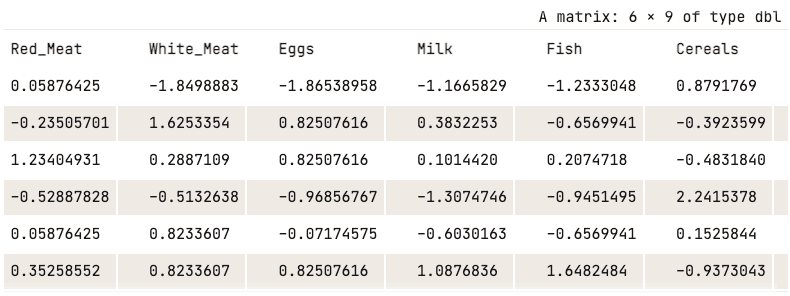
Data ternormalisasi (hanya lima kolom pertama yang ditampilkan)
Sebelum menjalankan PCA, memvisualisasikan korelasi antarvariabel mengonfirmasi bahwa PCA akan efektif. Interkorelasi tinggi menunjukkan redundansi yang dapat dikompresi oleh PCA. Saya akan menggunakan paket corrr dan ggcorrplot yang telah diinstal sebelumnya.
corr_matrix <- cor(data_normalized)
ggcorrplot(corr_matrix,
hc.order = TRUE,
type = "lower",
lab = TRUE)
Peta panas menunjukkan korelasi positif yang kuat antar sumber protein hewani (daging merah, daging putih, telur, dan susu), yang menjelaskan mengapa komponen utama pertama menangkap hampir 77% dari total varians. Struktur korelasi ini memang dirancang untuk dimanfaatkan oleh PCA.
Catatan tentang fungsi PCA di R: Tutorial ini menggunakan princomp(), yang menerapkan dekomposisi spektral pada matriks kovarian. Untuk sebagian besar kasus praktis, prcomp() lebih direkomendasikan — ia menggunakan singular value decomposition (SVD), yang lebih stabil secara numerik untuk dataset dengan banyak variabel. Perbedaan keluaran utama: princomp() menyimpan loadings di $loadings, sedangkan prcomp() menggunakan $rotation. Keduanya menghasilkan hasil yang ekuivalen pada data yang terkondisi baik seperti dataset protein yang digunakan di sini.
Sekarang semua sumber daya tersedia untuk melakukan analisis PCA. Pertama, princomp() menghitung PCA, dan fungsi summary() menampilkan hasilnya.
data.pca <- princomp(data_normalized)
summary(data.pca)
Ringkasan PCA di R
Dari tangkapan layar sebelumnya, kita melihat bahwa ada sembilan komponen utama yang dihasilkan (Comp.1 hingga Comp.9), yang juga sesuai dengan jumlah variabel dalam data.
Setiap komponen menjelaskan persentase dari total varians dalam dataset. Pada bagian Cumulative Proportion, komponen utama pertama menjelaskan hampir 77% dari total varians. Ini menyiratkan bahwa hampir dua pertiga data pada 9 variabel dapat direpresentasikan hanya oleh komponen utama pertama. Komponen kedua menjelaskan 12,08% dari total varians.
Proporsi kumulatif Comp.1 dan Comp.2 menjelaskan hampir 89% dari total varians. Ini berarti dua komponen utama pertama sudah dapat merepresentasikan data dengan baik.
Bagus, dua komponen pertama sudah ada — tetapi apa maknanya?
Ini dapat dijawab dengan mengeksplorasi bagaimana keduanya berkaitan dengan setiap kolom menggunakan loadings dari masing-masing komponen utama.
data.pca$loadings[, 1:2]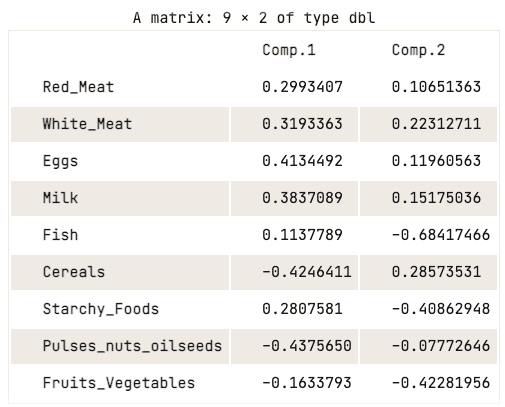
Matriks loading dari dua komponen utama pertama
Matriks loading menunjukkan bahwa komponen utama pertama memiliki nilai positif tinggi untuk daging merah, daging putih, telur, dan susu. Namun, nilai untuk serealia, kacang-kacangan, kacang dan biji minyak, serta buah dan sayur relatif negatif. Ini menunjukkan bahwa negara dengan asupan protein hewani yang lebih tinggi berada pada sisi surplus, sementara negara dengan asupan lebih rendah berada pada sisi defisit.
Sementara untuk komponen utama kedua, ia memiliki nilai negatif tinggi untuk ikan, makanan bertepung, dan buah serta sayur. Ini menyiratkan bahwa pola diet negara-negara yang mendasarinya sangat dipengaruhi oleh lokasi, seperti wilayah pesisir untuk ikan, dan wilayah pedalaman untuk diet kaya sayuran dan kentang.
Analisis matriks loading sebelumnya memberikan pemahaman yang baik tentang hubungan antara masing-masing dari dua komponen utama pertama dan atribut pada data. Namun, mungkin kurang menarik secara visual.
Ada beberapa strategi visualisasi standar yang dapat membantu pengguna mendapatkan wawasan dari data, dan bagian ini bertujuan membahas beberapa pendekatan tersebut, dimulai dengan scree plot.
Pendekatan pertama adalah scree plot. Plot ini digunakan untuk memvisualisasikan pentingnya setiap komponen utama dan dapat digunakan untuk menentukan jumlah komponen utama yang dipertahankan. Scree plot dapat dibuat menggunakan fungsi fviz_eig().
fviz_eig(data.pca, addlabels = TRUE)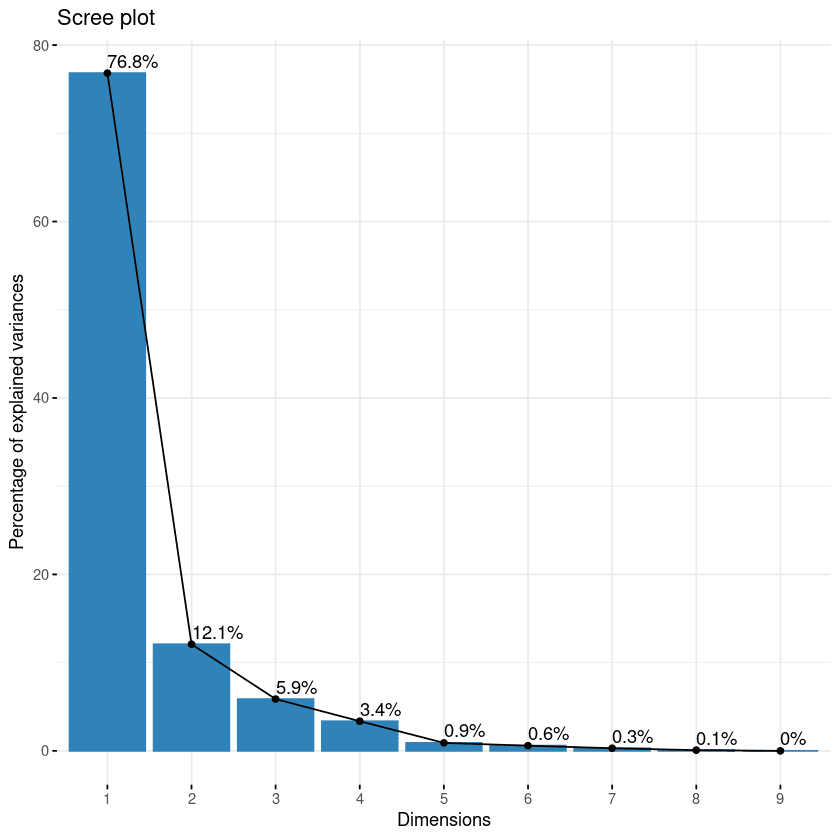
Scree plot komponen
Plot ini menampilkan eigenvalue dalam kurva menurun, dari yang tertinggi ke terendah. Dua komponen pertama dapat dianggap paling signifikan karena mengandung hampir 89% dari total informasi data.
Dengan biplot, kita dapat memvisualisasikan kemiripan dan perbedaan antar sampel, dan juga menunjukkan dampak tiap atribut pada masing-masing komponen utama.
# Grafik variabel
fviz_pca_var(data.pca, col.var = "black")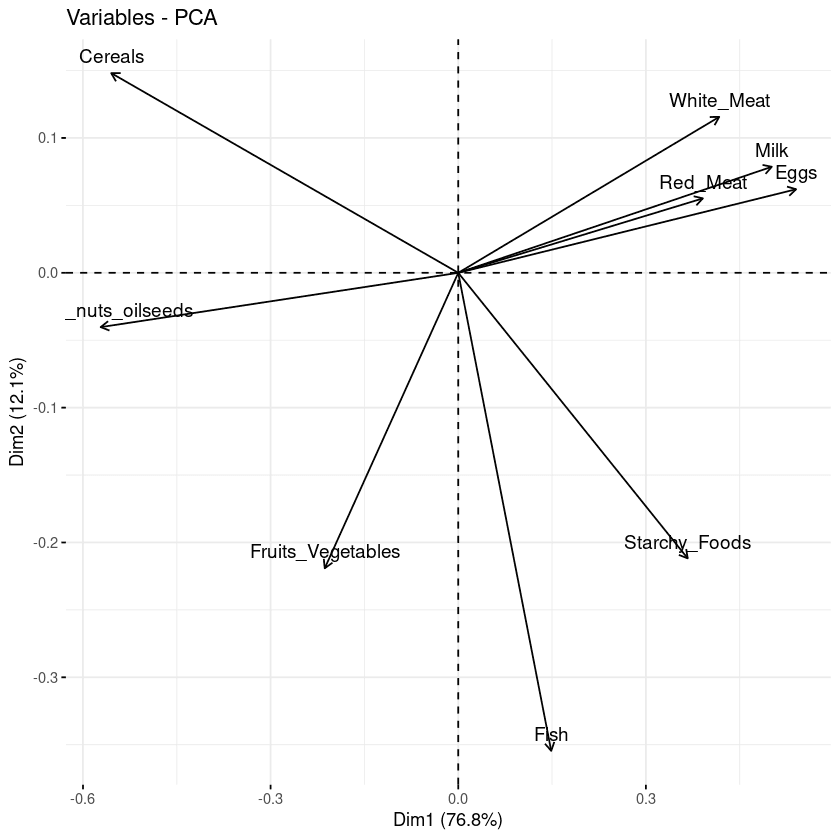
Biplot variabel terhadap komponen utama
Tiga informasi utama dapat diamati dari plot sebelumnya.
Tujuan visualisasi ketiga adalah menentukan seberapa besar tiap variabel terwakili dalam sebuah komponen. Kualitas representasi semacam ini disebut Cos2 dan sesuai dengan cosinus kuadrat, serta dihitung menggunakan fungsi fviz_cos2().
fviz_cos2(data.pca, choice = "var", axes = 1:2)Kode di atas menghitung nilai cosinus kuadrat untuk setiap variabel terhadap dua komponen utama pertama.
Dari ilustrasi di bawah, serealia, kacang-kacangan dan biji minyak, telur, dan susu adalah empat variabel teratas dengan cos2 tertinggi, sehingga paling berkontribusi pada PC1 dan PC2.
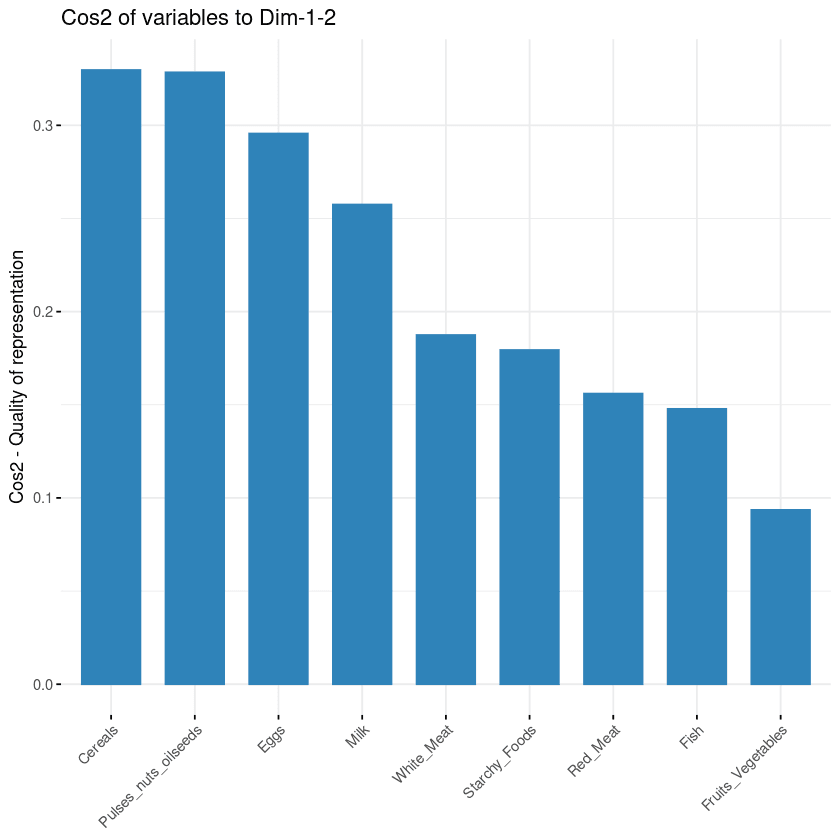
Kontribusi variabel terhadap komponen utama
Dua pendekatan visualisasi terakhir—biplot dan pentingnya atribut—dapat digabungkan menjadi satu biplot, di mana atribut dengan skor cos2 serupa akan memiliki warna serupa. Ini dicapai dengan menyetel fungsi fviz_pca_var sebagai berikut:
fviz_pca_var(data.pca, col.var = "cos2",
gradient.cols = c("black", "orange", "green"),
repel = TRUE)Dari biplot di bawah:
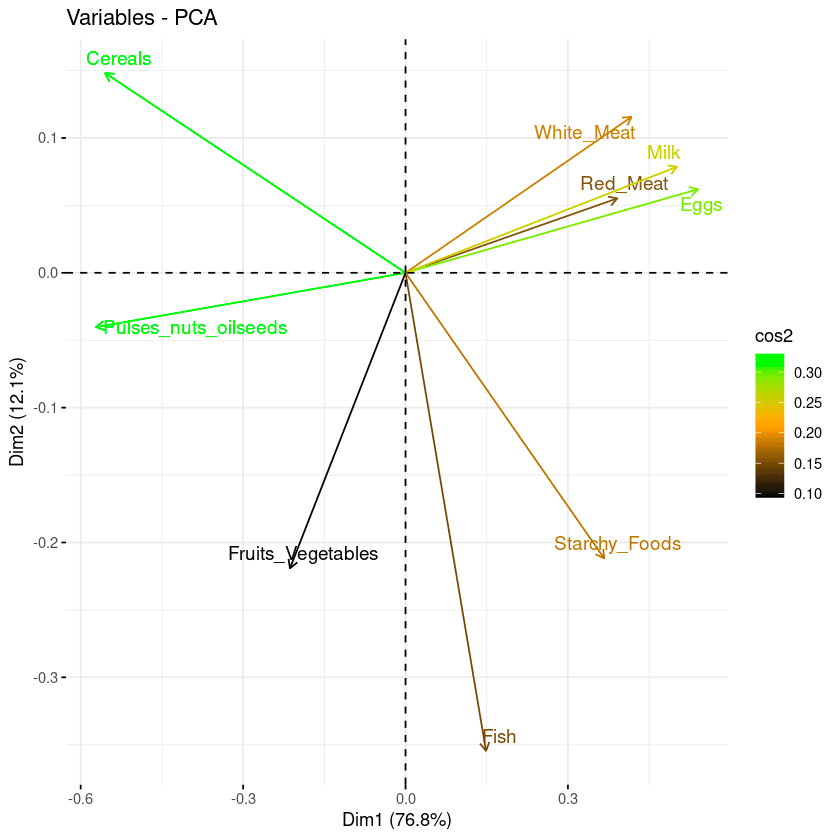
Kombinasi biplot dan skor cos2
Dua aturan praktis membantu memutuskan berapa banyak komponen utama yang dipertahankan:
Dalam tutorial ini, saya membahas apa itu principal component analysis dan pentingnya dalam analitik data. Mulai dari landasan matematis hingga kode R praktis, kita menelusuri alur kerja PCA lengkap pada dataset protein — mulai dari normalisasi dan penerapan princomp() hingga menafsirkan scree plot, biplot, dan visualisasi cos2 untuk memahami hubungan antara komponen utama dan variabel asli.
Terapkan teknik ini untuk mereduksi dimensi, menyingkap struktur tersembunyi, dan membangun pipeline machine learning yang lebih rapi dengan dataset Anda sendiri.
Untuk melangkah lebih jauh, jelajahi sumber berikut:
Kursus untuk R
Kursus
Kursus
Kursus
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
