Kurs
R’ye Giriş
4 sa
3.1M

scale() ile normalize edinFactoMineR ve factoextra paketleriyle birlikte princomp() veya prcomp() kullanınBu eğitimi takip edebilmek için şunlara sahip olmalısınız:
corrr, ggcorrplot, FactoMineR, factoextra (kurulum eğitimde ele alınıyor)Odak noktamız PCA olsa da, çok değişkenli veriyi özetlemeyi ve görselleştirmeyi amaçlayan aşağıdaki beş temel bileşen yöntemini akılda tutalım. PCA, diğer tekniklerin aksine yalnızca nicel değişkenlerle çalışır.
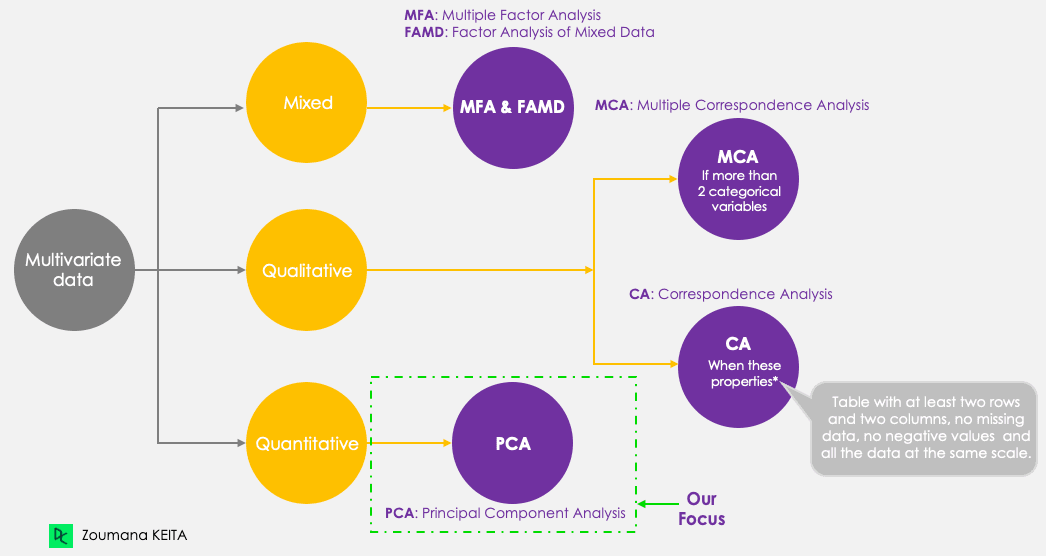
Temel bileşen yöntemleri
Oldukça karmaşık olabilen matematiksel kavrama girmeyeceğiz. Ancak, aşağıdaki beş adımı anlamak PCA'nın nasıl hesaplandığına dair daha iyi bir fikir verebilir.
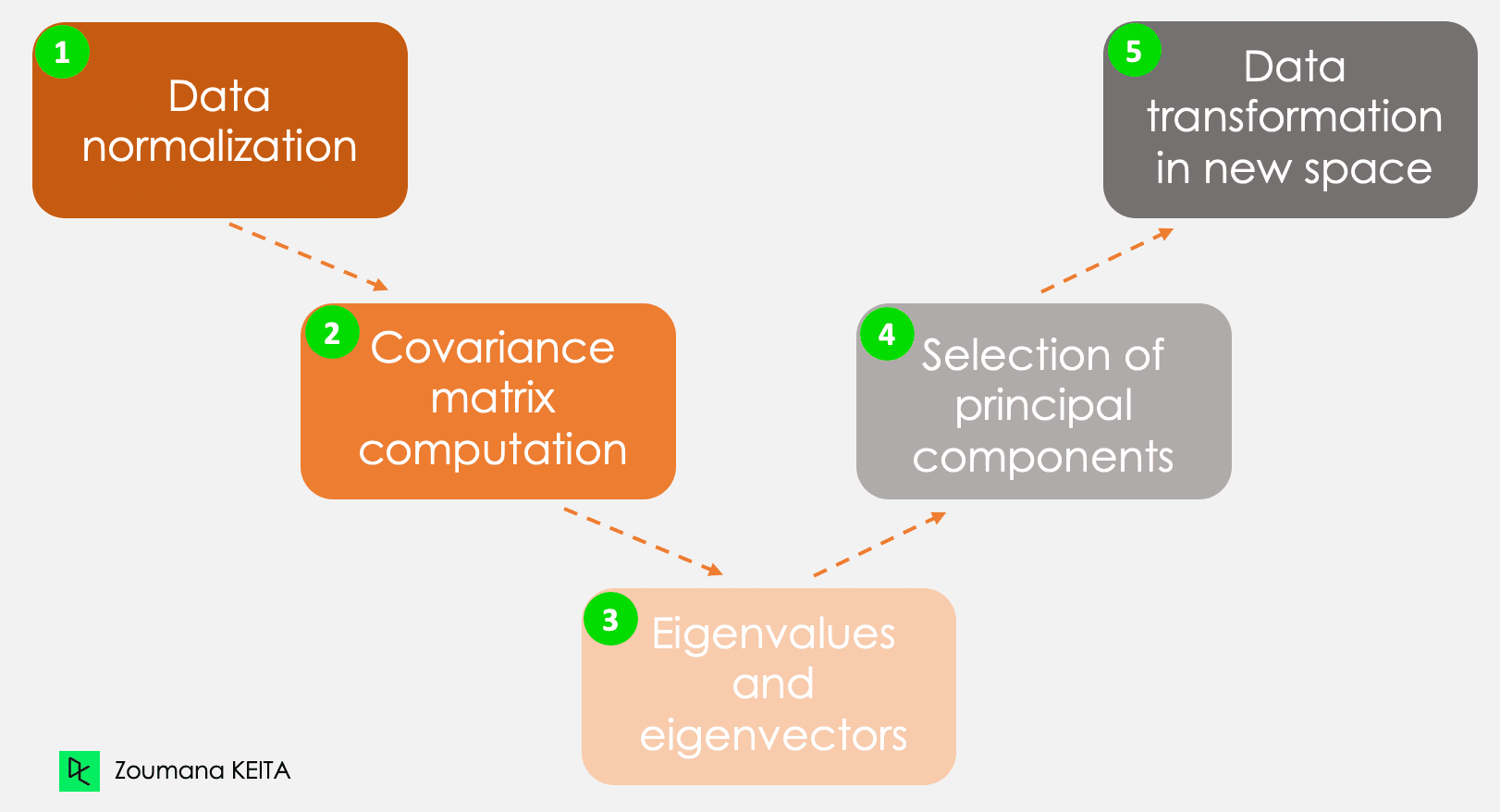
Temel bileşenleri hesaplamanın beş ana adımı
Girişteki örneği dikkate alarak, örneğin belirli bir müşteri için aşağıdaki bilgileri düşünelim.
Bu bilgiler farklı ölçeklere sahip ve bu tür verilerle PCA yapmak taraflı sonuçlara yol açar. İşte bu noktada veri normalizasyonu devreye girer. Her özniteliğin aynı düzeyde katkı yapmasını sağlar ve bir değişkenin diğerlerine baskın çıkmasını engeller. Her değişken için normalizasyon, ortalamasının çıkarılıp standart sapmasına bölünmesiyle yapılır.
Adından da anlaşılacağı gibi bu adım, normalize edilmiş veriden kovaryans matrisinin hesaplanmasıyla ilgilidir. Bu simetrik bir matristir ve her (i, j) elemanı i ve j değişkenleri arasındaki kovaryansa karşılık gelir.
Geometrik olarak bir özvektör “dikey” veya “90 derece” gibi bir yönü temsil eder. Özdeğer ise belirli bir yönde veride bulunan varyans miktarını temsil eden bir sayıdır. Her özvektörün kendisine karşılık gelen bir özdeğeri vardır.
Verideki değişken sayısı kadar özvektör ve özdeğer çifti vardır. Yalnızca aylık harcama, yaş ve puanın olduğu veride üç çift olacaktır. Tüm çiftler ilgili değildir. En yüksek özdeğere sahip özvektör birinci temel bileşene karşılık gelir. İkinci temel bileşen, ikinci en yüksek özdeğere sahip özvektördür; bu şekilde devam eder.
Bu adım, orijinal verinin temel bileşenlerce tanımlanan yeni bir alt uzaya yeniden yönlendirilmesini içerir. Bu yeniden yönlendirme, orijinal verinin önceden hesaplanan özvektörlerle çarpılmasıyla yapılır.
Bu dönüşümün orijinal verinin kendisini değiştirmediğini, bunun yerine veriyi daha iyi temsil etmek için yeni bir bakış açısı sunduğunu unutmamak önemlidir.
Temel bileşen analizinin günlük hayatımızda finans, görüntü işleme, sağlık ve güvenlik dahil (ama bunlarla sınırlı olmamak üzere) çeşitli uygulamaları vardır.
Hisse senedi fiyatlarını geçmiş fiyatlardan tahmin etmek, yıllardır araştırmalarda kullanılan bir kavramdır. PCA, boyut indirgeme ve veriyi analiz etme amacıyla uzmanların verideki değişkenliğin çoğunu açıklayan ilgili bileşenleri bulmasına yardımcı olmak için kullanılabilir. R'de boyut indirgeme hakkında daha fazla bilgi için özel kursumuzu inceleyin.
Bir görüntü çok sayıda özelliğin birleşimidir. PCA, boyut sayısını azaltırken belirli bir görüntünün temel ayrıntılarını korumak için ağırlıkla görüntü sıkıştırmada uygulanır. Ayrıca, görüntü tanıma gibi daha karmaşık görevlerde de kullanılabilir.
Görüntü sıkıştırmayla aynı mantıkla, PCA manyetik rezonans görüntüleme (MRI) taramalarında, görselleştirme ve tıbbi analiz için görüntülerin boyutunu azaltmak amacıyla kullanılır. Ayrıca, örneğin görüntü taramalarından belirli bir hastalığı tanımak için kullanılan tıbbi teknolojilere entegre edilebilir.
Parmak izi tanıma için kullanılan biyometrik sistemler, parmak izi dokusu ve ek bilgiler gibi en ilgili özellikleri çıkarmak amacıyla temel bileşen analizinden yararlanan teknolojileri entegre edebilir.
Artık PCA'nın altında yatan teoriyi anladığınıza göre, onu uygulamada görmeye hazırsınız.
Bu bölüm, ilgili paketlerin kurulumundan verinin yüklenmesi ve hazırlanmasına, R'de temel bileşen analizinin uygulanmasına ve sonuçların yorumlanmasına kadar tüm adımları kapsar.
Kaynak kod DataLab'de mevcuttur.
Bu eğitimi başarıyla gerçekleştirmek için aşağıdaki kütüphanelere ihtiyacınız olacak ve her biri için verimli kullanıma yönelik iki ana adım var:
Bu, korelasyon analizi için bir R paketidir. Esasen R veri çerçeveleri oluşturmaya ve bunları işlemeye odaklanır. Aşağıda kütüphaneyi kurma ve yükleme adımları yer alıyor.
install.packages("corrr")
library('corrr')ggcorrplot paketi, ggplot2 fonksiyonu dahil olmak üzere birçok işlev sağlar ve korelasyon matrisini görselleştirmeyi kolaylaştırır. Yukarıdaki talimatlara benzer şekilde kurulumu basittir.
install.packages("ggcorrplot")
library(ggcorrplot)Esasen çok değişkenli keşifsel veri analizi için kullanılır; factoMineR paketi, temel bileşen analizini gerçekleştirmek için PCA modülüne erişim sağlar.
install.packages("FactoMineR")
library("FactoMineR")Bu son paket, temel bileşen analizi çıktılarının görselleştirilmesi için gerekli tüm fonksiyonları sağlar. Bu fonksiyonlar arasında, ilerleyen bölümlerde ele alınacak iki görselleştirme tekniği olan scree plot ve biplot da bulunur.
install.packages("factoextra")
library(factoextra)Veriyi yüklemeden ve daha ileri keşfe başlamadan önce, üzerinde çalışacağınız veriye ilişkin temel bilgileri anlamak faydalıdır.
Protein veri seti, 25 Avrupa ülkesindeki vatandaşların ortalama protein tüketimini açıklayan, gerçek değerli çok değişkenli bir veri setidir.
Her ülke için on sütun vardır. İlk sekizi farklı protein türlerine karşılık gelir. Sonuncusu ise proteinlerin ortalama değerlerinin toplamına karşılık gelir.
Veriye hızlı bir genel bakış yapalım.
Önce veriyi read.csv() fonksiyonuyla yüklüyor, ardından aşağıdaki çıktıyı veren str() fonksiyonunu kullanıyoruz.
protein_data <- read.csv("protein.csv")
str(protein_data)Veri setinde 25 gözlem ve 11 sütun olduğunu görebiliriz. Country sütunu dışında her değişken sayısaldır; Country karakter dizisidir.

Protein verisinin açıklaması
Kayıp değerlerin varlığı, PCA'nın sonucunu taraflı hale getirebilir. Bu nedenle, bu değerlerle başa çıkmak için uygun yaklaşımı uygulamak şiddetle tavsiye edilir. Her Veri Bilimcinin Bilmesi Gereken Kayıp Değerleri Ele Alma Teknikleri eğitimimiz doğru seçimi yapmanıza yardımcı olabilir.
colSums(is.na(protein_data))colSums() fonksiyonu, is.na() ile birlikte kullanıldığında her sütundaki kayıp değer sayısını döndürür. Aşağıda görüldüğü gibi sütunların hiçbirinde kayıp değer yoktur.

Her sütundaki kayıp değer sayısı
Makalede daha önce belirtildiği gibi PCA yalnızca sayısal değerlerle çalışır. Bu nedenle Country sütunundan kurtulmamız gerekir. Ayrıca Total sütunu, kalan sayısal değişkenlerin lineer kombinasyonu olduğundan analize uygun değildir.
Aşağıdaki kod yalnızca sayısal sütunlardan oluşan yeni bir veri oluşturur.
numerical_data <- protein_data[,2:10]
head(numerical_data)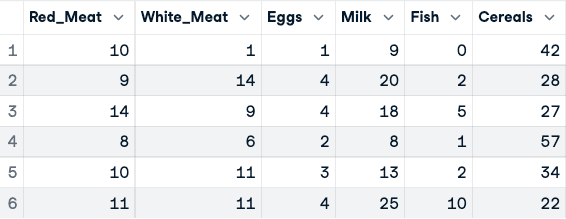
Veri normalize edilmeden önce (yalnızca ilk beş sütun gösteriliyor)
Şimdi normalizasyonu scale() fonksiyonunu kullanarak uygulayabiliriz.
data_normalized <- scale(numerical_data)
head(data_normalized)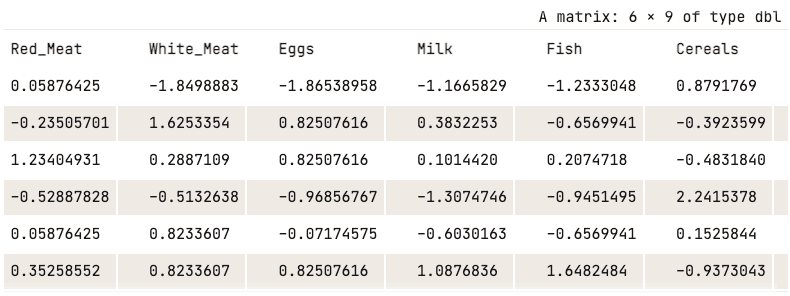
Normalize edilmiş veri (yalnızca ilk beş sütun gösteriliyor)
PCA çalıştırmadan önce değişkenler arası korelasyonları görselleştirmek, PCA'nın etkili olacağını teyit eder. Yüksek karşılıklı korelasyonlar, PCA'nın sıkıştırabileceği fazlalığı gösterir. Daha önce kurduğum corrr ve ggcorrplot paketlerini kullanacağım.
corr_matrix <- cor(data_normalized)
ggcorrplot(corr_matrix,
hc.order = TRUE,
type = "lower",
lab = TRUE)
Isı haritası, hayvansal protein kaynakları (kırmızı et, beyaz et, yumurta ve süt) arasında güçlü pozitif korelasyonlar olduğunu gösteriyor; bu da birinci temel bileşenin toplam varyansın yaklaşık %77’sini yakalamasını açıklıyor. Bu korelasyon yapısı, PCA’nın tam da yararlanmak üzere tasarlandığı şeydir.
R'deki PCA fonksiyonlarına not: Bu eğitimde kovaryans matrisi üzerinde spektral ayrıştırma uygulayan princomp() kullanılıyor. Çoğu pratik kullanım için tercih edilen alternatif prcomp()'tur — birçok değişkenli veri setlerinde sayısal olarak daha kararlı olan tekil değer ayrıştırması (SVD) kullanır. Temel çıktı farkı: princomp() yükleri $loadings içinde saklarken, prcomp() $rotation kullanır. Burada kullanılan protein veri seti gibi iyi koşullandırılmış verilerde her ikisi de eşdeğer sonuçlar üretir.
Artık PCA analizi yapmak için tüm kaynaklar hazır. Önce princomp() PCA'yı hesaplar ve summary() fonksiyonu sonucu gösterir.
data.pca <- princomp(data_normalized)
summary(data.pca)
R PCA özeti
Önceki ekranda, verilerdeki değişken sayısına karşılık gelen dokuz temel bileşen (Comp.1'den Comp.9'a) oluşturulduğunu görüyoruz.
Her bir bileşen, veri setindeki toplam varyansın belirli bir yüzdesini açıklar. Kümülatif Oran bölümünde, birinci temel bileşen toplam varyansın neredeyse %77’sini açıklar. Bu, 9 değişkenli veri setindeki verinin neredeyse üçte ikisinin yalnızca birinci temel bileşenle temsil edilebileceği anlamına gelir. İkincisi ise toplam varyansın %12.08’ini açıklar.
Comp.1 ve Comp.2'nin kümülatif oranı toplam varyansın neredeyse %89’unu açıklar. Bu, ilk iki temel bileşenin veriyi doğru şekilde temsil edebileceği anlamına gelir.
İlk iki bileşene sahip olmak harika, ama aslında ne anlama geliyorlar?
Bu soruyu, her bir temel bileşenin yüklerini kullanarak sütunlarla ilişkilerini keşfederek yanıtlayabiliriz.
data.pca$loadings[, 1:2]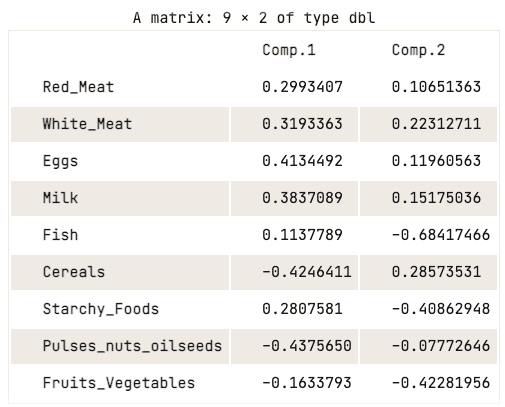
İlk iki temel bileşenin yükleme matrisi
Yükleme matrisi, birinci temel bileşenin kırmızı et, beyaz et, yumurta ve süt için yüksek pozitif değerlere sahip olduğunu gösteriyor. Buna karşılık, tahıllar, bakliyat, kuruyemiş ve yağlı tohumlar ile meyve-sebzeler için değerler nispeten negatiftir. Bu, hayvansal protein alımı daha yüksek olan ülkelerin fazlalıkta, düşük olanların ise açıkta olduğunu düşündürür.
İkinci temel bileşene gelince, balık, nişastalı gıdalar ve meyve-sebzeler için yüksek negatif değerlere sahiptir. Bu da ülkelerin diyetlerinin balık için kıyı bölgeler, sebze ve patates açısından zengin diyetler için iç bölgeler gibi bulundukları konumdan güçlü biçimde etkilendiğini ima eder.
Önceki yükleme matrisi analizi, ilk iki temel bileşen ile verideki öznitelikler arasındaki ilişkiyi iyi bir şekilde anlamamızı sağladı. Ancak, bu her zaman görsel olarak çekici olmayabilir.
Kullanıcıya veriden içgörü kazandırabilecek birkaç standart görselleştirme stratejisi vardır; bu bölüm, scree plot ile başlayarak bu yaklaşımlardan bazılarını kapsar.
Listemizdeki ilk yaklaşım scree plot’tur. Her bir temel bileşenin önemini görselleştirmek ve tutulacak temel bileşen sayısını belirlemek için kullanılır. Scree plot, fviz_eig() fonksiyonu kullanılarak üretilebilir.
fviz_eig(data.pca, addlabels = TRUE)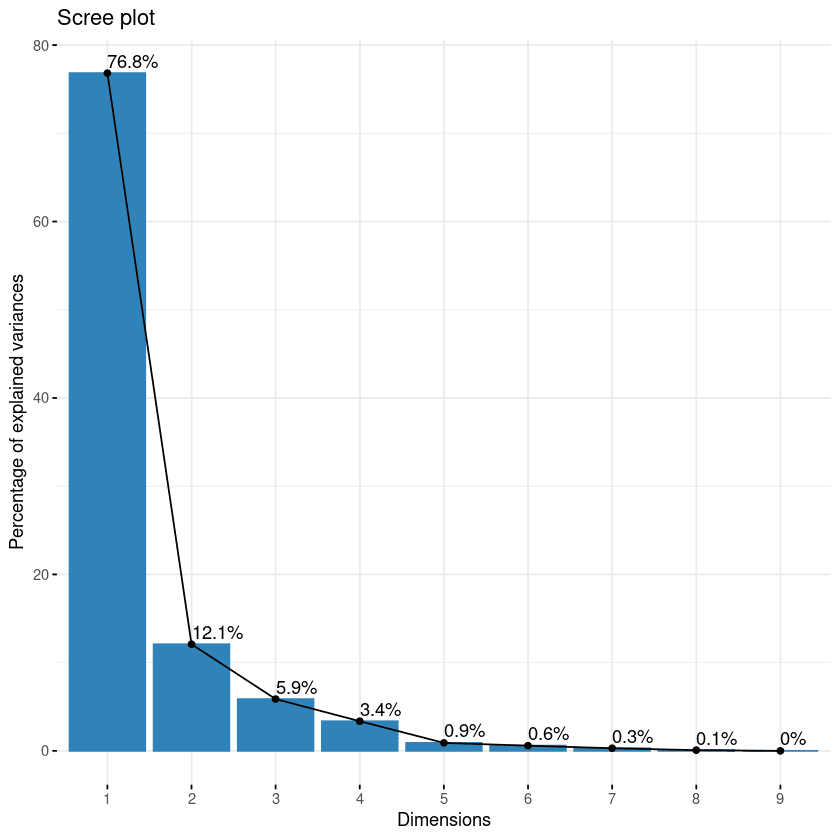
Bileşenlerin scree plot’u
Bu grafik, özdeğerleri en yüksekten en düşüğe doğru azalan bir eğri şeklinde gösterir. İlk iki bileşen, verinin toplam bilgisinin neredeyse %89’unu içerdiği için en anlamlı olanlar olarak kabul edilebilir.
Biplot ile örnekler arasındaki benzerlikleri ve farklılıkları görselleştirmek mümkündür; ayrıca her özniteliğin her bir temel bileşen üzerindeki etkisini de gösterir.
# Değişkenlerin grafiği
fviz_pca_var(data.pca, col.var = "black")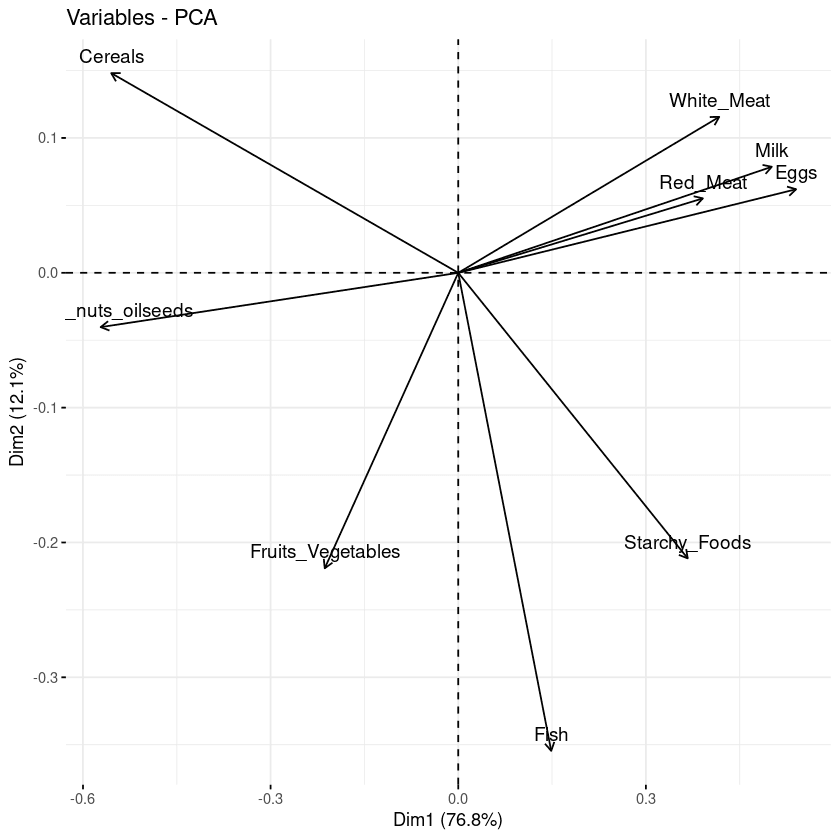
Temel bileşenlere göre değişkenlerin biplotu
Önceki grafikten üç ana bilgi gözlemlenebilir.
Üçüncü görselleştirmenin amacı, her bir değişkenin belirli bir bileşende ne kadar temsil edildiğini belirlemektir. Bu temsil kalitesi Cos2 olarak adlandırılır, kare kosinusa karşılık gelir ve fviz_cos2() fonksiyonu kullanılarak hesaplanır.
fviz_cos2(data.pca, choice = "var", axes = 1:2)Yukarıdaki kod, ilk iki temel bileşene göre her değişken için kare kosinüs değerini hesapladı.
Aşağıdaki görselde, tahıllar, bakliyat–yağlı tohumlar, yumurta ve süt en yüksek cos2'ye sahip ilk dört değişkendir; dolayısıyla PC1 ve PC2'ye en çok katkı yapanlardır.
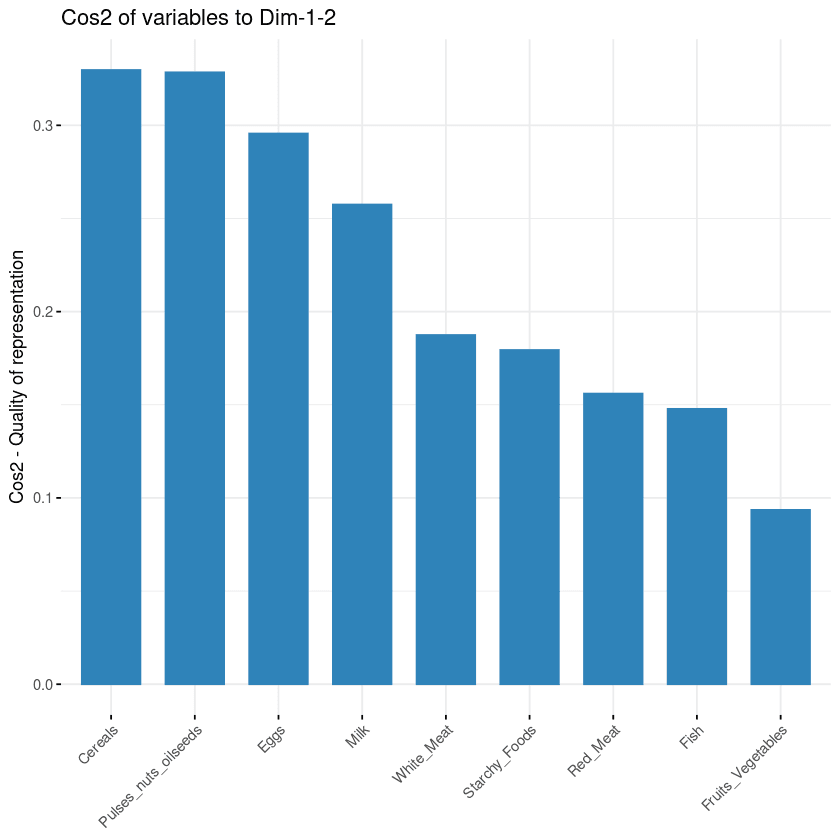
Değişkenlerin temel bileşenlere katkısı
Son iki görselleştirme yaklaşımı — biplot ve öznitelik önemi — tek bir biplotta birleştirilebilir; benzer cos2 puanlarına sahip öznitelikler benzer renklerde olur. Bu, fviz_pca_var fonksiyonu ince ayarlanarak şu şekilde yapılır:
fviz_pca_var(data.pca, col.var = "cos2",
gradient.cols = c("black", "orange", "green"),
repel = TRUE)Aşağıdaki biplottan:
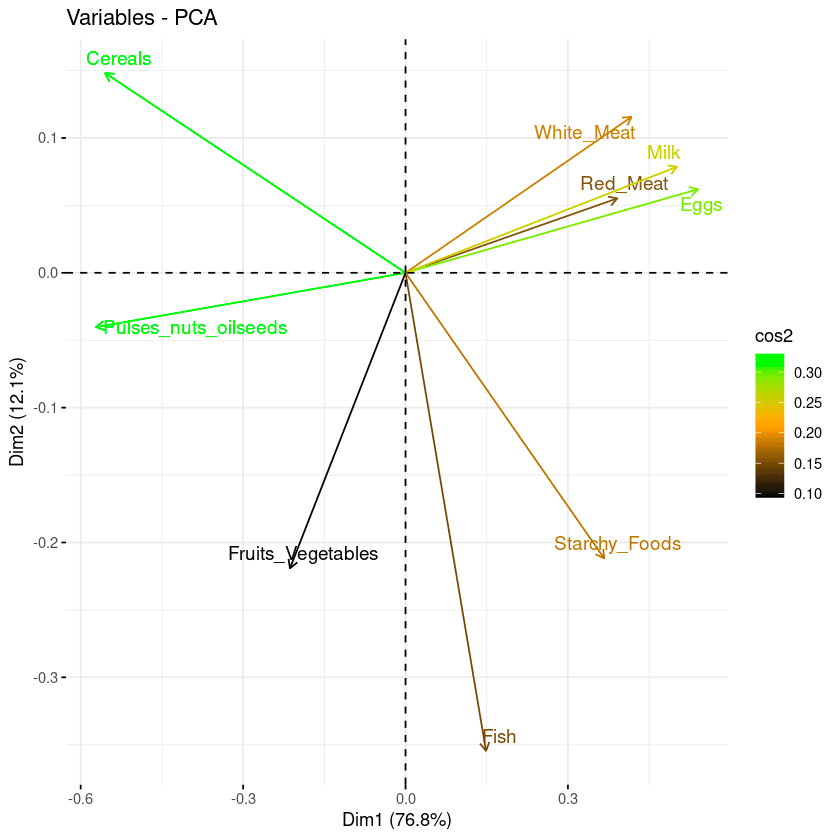
Biplot ve cos2 skorunun kombinasyonu
Kaç temel bileşenin tutulacağına karar vermek için iki pratik kural yardımcı olur:
Bu eğitimde, temel bileşen analizinin ne olduğunu ve veri analizindeki önemini ele aldım. Matematiksel temellerden başlayıp uygulamalı R koduna kadar, protein veri seti üzerinde baştan sona bir PCA akışını — normalizasyon ve princomp() uygulamasından, scree plot, biplot ve cos2 görselleştirmelerini yorumlamaya kadar — birlikte yürüttük ve temel bileşenler ile orijinal değişkenler arasındaki ilişkiyi anladık.
Bu teknikleri, boyut indirgemek, gizli yapıları ortaya çıkarmak ve kendi veri setlerinizle daha temiz makine öğrenimi iş akışları kurmak için uygulayın.
Daha ileri gitmek için şu ilgili kaynakları keşfedin:
R için Kurslar
Kurs
Kurs
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Kurtis Pykes
Eğitim
Adel Nehme
