Courses
Nhập môn Ngôn ngữ lập trình R
4 giờ
3.1M

scale() trước khi chạy PCA để đảm bảo các biến đóng góp ngang nhauprincomp() hoặc prcomp() trong R cùng với các gói FactoMineR và factoextra để phân tích và trực quan hóaĐể theo dõi hướng dẫn này, bạn nên có:
corrr, ggcorrplot, FactoMineR, factoextra (cách cài đặt được đề cập trong hướng dẫn)Dù trọng tâm là PCA, hãy lưu ý năm kỹ thuật thành phần chính chính sau đây nhằm tóm tắt và trực quan hóa dữ liệu đa biến. Khác với các kỹ thuật khác, PCA chỉ làm việc với các biến định lượng.
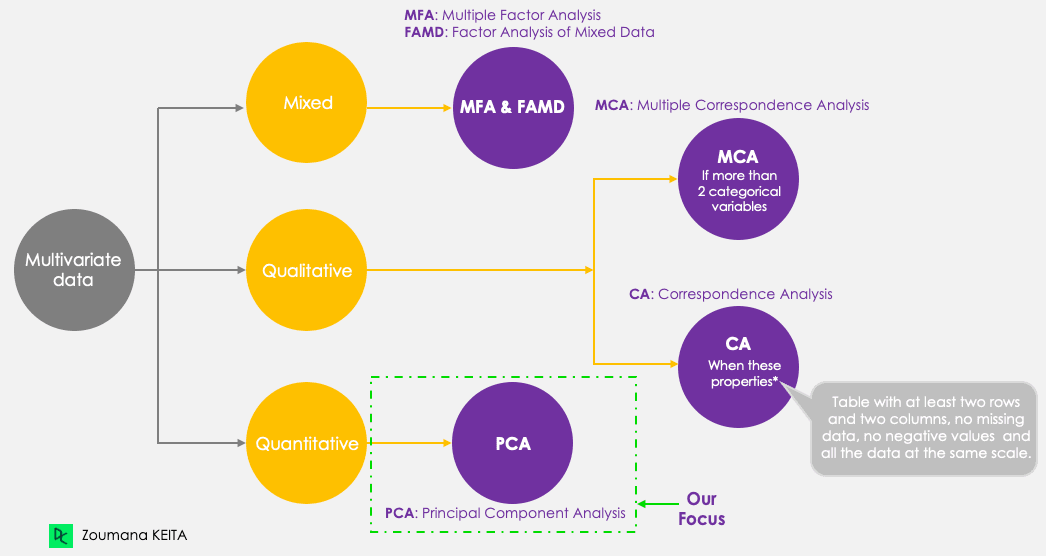
Các phương pháp thành phần chính
Chúng ta sẽ không đi sâu vào giải thích toán học vốn khá phức tạp. Tuy nhiên, hiểu năm bước sau sẽ giúp bạn hình dung rõ hơn cách tính PCA.
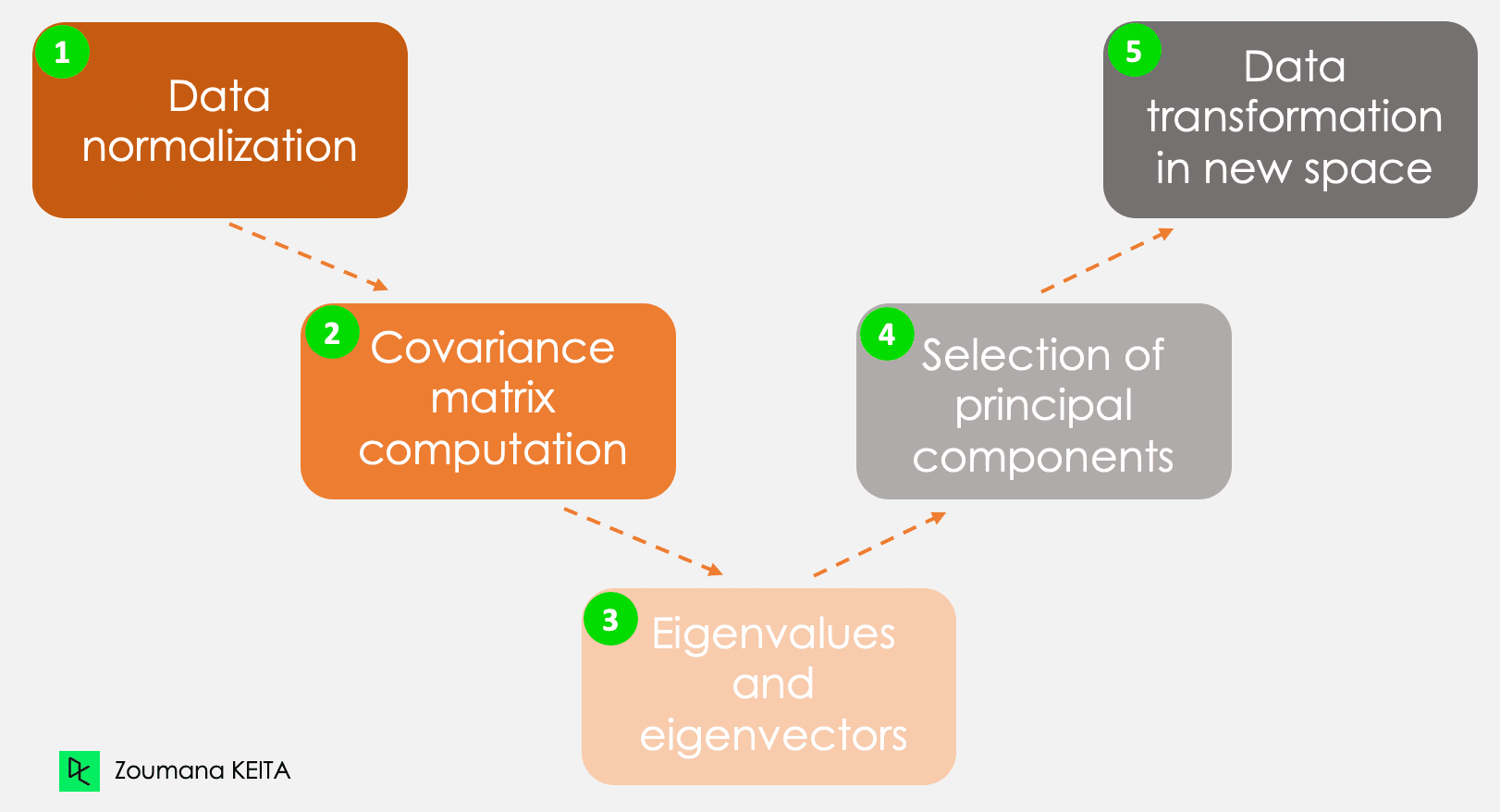
Năm bước chính để tính các thành phần chính
Dựa trên ví dụ trong phần mở đầu, giả sử với một khách hàng ta có thông tin sau.
Các thông tin này có các thang đo khác nhau và thực hiện PCA trực tiếp sẽ dẫn đến kết quả thiên lệch. Lúc này cần chuẩn hóa dữ liệu. Việc này đảm bảo mỗi thuộc tính đóng góp tương đương, tránh việc một biến lấn át các biến khác. Với mỗi biến, chuẩn hóa bằng cách trừ đi trung bình của nó và chia cho độ lệch chuẩn.
Đúng như tên gọi, bước này tính ma trận hiệp phương sai từ dữ liệu đã chuẩn hóa. Đây là ma trận đối xứng, mỗi phần tử (i, j) tương ứng với hiệp phương sai giữa biến i và j.
Về hình học, một vector riêng biểu diễn một hướng như “thẳng đứng” hay “90 độ”. Còn trị riêng là con số thể hiện lượng phương sai của dữ liệu theo một hướng cho trước. Mỗi vector riêng có một trị riêng tương ứng.
Số cặp vector riêng và trị riêng bằng số biến trong dữ liệu. Với dữ liệu chỉ có chi tiêu hàng tháng, tuổi, và điểm đánh giá, sẽ có ba cặp. Không phải cặp nào cũng quan trọng. Vector riêng có trị riêng lớn nhất là thành phần chính thứ nhất. Thành phần chính thứ hai là vector riêng có trị riêng lớn thứ hai, v.v.
Bước này chiếu lại dữ liệu gốc lên không gian con mới được xác định bởi các thành phần chính. Việc chiếu được thực hiện bằng cách nhân dữ liệu gốc với các vector riêng đã tính.
Quan trọng là phép biến đổi này không làm thay đổi dữ liệu gốc, mà cung cấp một góc nhìn mới để biểu diễn dữ liệu tốt hơn.
PCA có rất nhiều ứng dụng trong đời sống hàng ngày, bao gồm (nhưng không chỉ giới hạn ở) tài chính, xử lý ảnh, chăm sóc sức khỏe và bảo mật.
Dự báo giá cổ phiếu từ dữ liệu lịch sử đã được nghiên cứu nhiều năm. PCA có thể được dùng để giảm chiều dữ liệu và phân tích, giúp chuyên gia tìm ra các thành phần liên quan giải thích phần lớn biến thiên của dữ liệu. Bạn có thể tìm hiểu thêm về giảm chiều dữ liệu trong R qua khóa học chuyên sâu của chúng tôi.
Một ảnh bao gồm nhiều đặc trưng. PCA thường được áp dụng để nén ảnh, giữ lại các chi tiết quan trọng của ảnh trong khi giảm số chiều. Ngoài ra, PCA còn được dùng cho các nhiệm vụ phức tạp hơn như nhận dạng hình ảnh.
Tương tự logic nén ảnh. PCA được dùng trong chụp cộng hưởng từ (MRI) để giảm số chiều của ảnh nhằm trực quan hóa và phân tích y khoa tốt hơn. PCA cũng có thể tích hợp vào các công nghệ y tế, ví dụ nhận diện một bệnh nào đó từ ảnh quét.
Các hệ thống sinh trắc học dùng để nhận diện vân tay có thể tích hợp các công nghệ dựa trên PCA để trích xuất các đặc trưng liên quan nhất, như kết cấu vân tay và các thông tin bổ sung.
Giờ bạn đã hiểu lý thuyết nền tảng của PCA, hãy xem nó vận hành thực tế.
Phần này bao gồm toàn bộ các bước từ cài đặt gói, nạp và chuẩn bị dữ liệu, áp dụng PCA trong R, đến diễn giải kết quả.
Mã nguồn có sẵn trên DataLab.
Để thực hiện thành công hướng dẫn này, bạn sẽ cần các thư viện sau, và mỗi thư viện cần hai bước chính để dùng hiệu quả:
Đây là gói R cho phân tích tương quan. Nó tập trung vào việc tạo và xử lý data frame trong R. Dưới đây là các bước cài và nạp thư viện.
install.packages("corrr")
library('corrr')Gói ggcorrplot cung cấp nhiều hàm, bao gồm (nhưng không giới hạn ở) các hàm từ ggplot2 giúp dễ dàng trực quan hóa ma trận tương quan. Tương tự hướng dẫn trên, việc cài đặt rất đơn giản.
install.packages("ggcorrplot")
library(ggcorrplot)Chủ yếu dùng cho phân tích thăm dò đa biến; gói FactoMineR cung cấp module PCA để thực hiện phân tích thành phần chính.
install.packages("FactoMineR")
library("FactoMineR")Gói cuối này cung cấp các hàm cần thiết để trực quan hóa đầu ra của PCA. Bao gồm nhưng không giới hạn ở scree plot, biplot — hai kỹ thuật sẽ được đề cập sau trong bài.
install.packages("factoextra")
library(factoextra)Trước khi nạp dữ liệu và khám phá sâu hơn, nên hiểu và nắm thông tin cơ bản liên quan đến bộ dữ liệu bạn sẽ làm việc.
Bộ dữ liệu protein là dữ liệu đa biến giá trị thực mô tả lượng tiêu thụ protein trung bình của người dân ở 25 quốc gia châu Âu.
Với mỗi quốc gia có mười cột. Tám cột đầu tương ứng với các loại protein khác nhau. Cột cuối là tổng giá trị trung bình của protein.
Hãy xem qua dữ liệu nhanh.
Đầu tiên, nạp dữ liệu bằng hàm read.csv(), sau đó dùng str() để có hình ảnh như bên dưới.
protein_data <- read.csv("protein.csv")
str(protein_data)Ta thấy tập dữ liệu có 25 quan sát và 11 cột. Mỗi biến đều là số ngoại trừ cột Country, là chuỗi ký tự.

Mô tả dữ liệu protein
Sự hiện diện của giá trị thiếu có thể gây thiên lệch kết quả PCA. Vì vậy, rất nên áp dụng phương pháp phù hợp để xử lý các giá trị này. Hướng dẫn Các kỹ thuật hàng đầu để xử lý giá trị thiếu mà mọi nhà khoa học dữ liệu nên biết có thể giúp bạn chọn đúng cách.
colSums(is.na(protein_data))Hàm colSums() kết hợp với is.na() trả về số lượng giá trị thiếu trên mỗi cột. Như thấy bên dưới, không có cột nào bị thiếu giá trị.

Số giá trị thiếu trên mỗi cột
Như đã nói ở đầu bài, PCA chỉ làm việc với giá trị số. Do đó, ta cần bỏ cột Country. Ngoài ra, cột Total không liên quan đến phân tích vì nó là tổ hợp tuyến tính của các biến số còn lại.
Đoạn mã dưới đây tạo dữ liệu mới chỉ gồm các cột số.
numerical_data <- protein_data[,2:10]
head(numerical_data)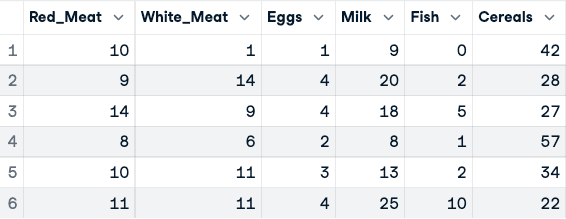
Trước khi chuẩn hóa dữ liệu (chỉ hiển thị năm cột đầu)
Bây giờ có thể chuẩn hóa bằng hàm scale().
data_normalized <- scale(numerical_data)
head(data_normalized)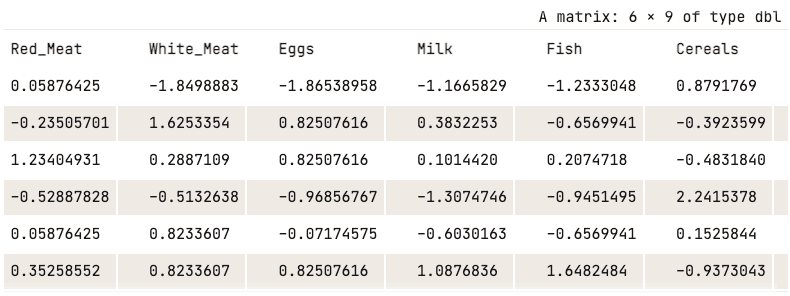
Dữ liệu đã chuẩn hóa (chỉ hiển thị năm cột đầu)
Trước khi chạy PCA, trực quan hóa tương quan giữa các biến giúp xác nhận PCA sẽ hiệu quả. Tương quan cao giữa các biến cho thấy dư thừa mà PCA có thể nén lại. Tôi sẽ dùng các gói corrr và ggcorrplot đã cài ở trên.
corr_matrix <- cor(data_normalized)
ggcorrplot(corr_matrix,
hc.order = TRUE,
type = "lower",
lab = TRUE) ...)
Bản đồ nhiệt cho thấy tương quan dương mạnh giữa các nguồn protein động vật (thịt đỏ, thịt trắng, trứng và sữa), giải thích vì sao thành phần chính đầu tiên nắm gần 77% tổng phương sai. Cấu trúc tương quan này chính là điều PCA hướng đến để khai thác.
Lưu ý về các hàm PCA trong R: Hướng dẫn này dùng princomp(), áp dụng phân rã phổ (spectral decomposition) trên ma trận hiệp phương sai. Với hầu hết trường hợp thực tế, prcomp() là lựa chọn ưu tiên — nó dùng phân rã giá trị kỳ dị (SVD), ổn định số hơn cho dữ liệu có nhiều biến. Khác biệt đầu ra chính: princomp() lưu hệ số tải trong $loadings, trong khi prcomp() dùng $rotation. Cả hai cho kết quả tương đương trên dữ liệu được điều kiện hóa tốt như bộ protein ở đây.
Giờ mọi thứ đã sẵn sàng để thực hiện phân tích PCA. Đầu tiên, princomp() tính PCA, và hàm summary() hiển thị kết quả.
data.pca <- princomp(data_normalized)
summary(data.pca)
Tóm tắt PCA trong R
Từ ảnh chụp màn hình, ta thấy có chín thành phần chính được tạo ra (Comp.1 đến Comp.9), tương ứng với số biến trong dữ liệu.
Mỗi thành phần giải thích một tỷ lệ phần trăm phương sai tổng trong bộ dữ liệu. Ở phần Cumulative Proportion (tỷ lệ lũy tích), thành phần chính thứ nhất giải thích gần 77% tổng phương sai. Điều này ngụ ý rằng gần hai phần ba thông tin của tập 9 biến có thể được biểu diễn chỉ bằng thành phần chính đầu tiên. Thành phần thứ hai giải thích 12,08% tổng phương sai.
Tỷ lệ lũy tích của Comp.1 và Comp.2 giải thích gần 89% tổng phương sai. Nghĩa là hai thành phần chính đầu tiên có thể biểu diễn dữ liệu khá chính xác.
Tuyệt, có hai thành phần đầu — nhưng chúng thực sự có ý nghĩa gì?
Có thể trả lời bằng cách xem chúng liên hệ với từng cột như thế nào thông qua các hệ số tải (loadings) của mỗi thành phần chính.
data.pca$loadings[, 1:2]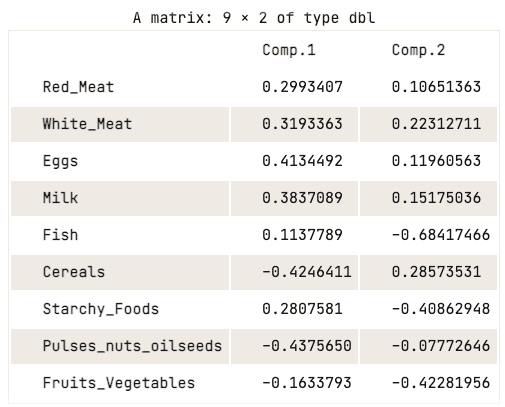
Ma trận hệ số tải của hai thành phần chính đầu tiên
Ma trận hệ số tải cho thấy thành phần chính đầu tiên có giá trị dương cao cho cả thịt đỏ, thịt trắng, trứng và sữa. Ngược lại, giá trị cho ngũ cốc, cây họ đậu, hạt & dầu, và trái cây & rau củ là âm tương đối. Điều này gợi ý các quốc gia có mức tiêu thụ protein động vật cao thì “dư thừa”, trong khi các quốc gia tiêu thụ thấp thì “thiếu hụt”.
Với thành phần chính thứ hai, nó có giá trị âm cao cho cá, thực phẩm giàu tinh bột, và trái cây & rau củ. Điều này ngụ ý chế độ ăn của các quốc gia bị chi phối mạnh bởi vị trí địa lý, ví dụ khu vực ven biển thì ăn cá nhiều, còn nội địa thì giàu rau củ và khoai.
Phân tích ma trận hệ số tải ở trên giúp hiểu tốt mối quan hệ giữa hai thành phần chính đầu tiên và các thuộc tính trong dữ liệu. Tuy nhiên, trực quan có thể chưa hấp dẫn.
Có một vài chiến lược trực quan hóa tiêu chuẩn giúp người dùng rút ra insight từ dữ liệu, và phần này sẽ trình bày một số cách, bắt đầu với scree plot.
Cách đầu tiên là scree plot. Nó dùng để trực quan tầm quan trọng của từng thành phần chính và có thể dùng để quyết định số thành phần cần giữ lại. Scree plot được tạo bằng hàm fviz_eig().
fviz_eig(data.pca, addlabels = TRUE)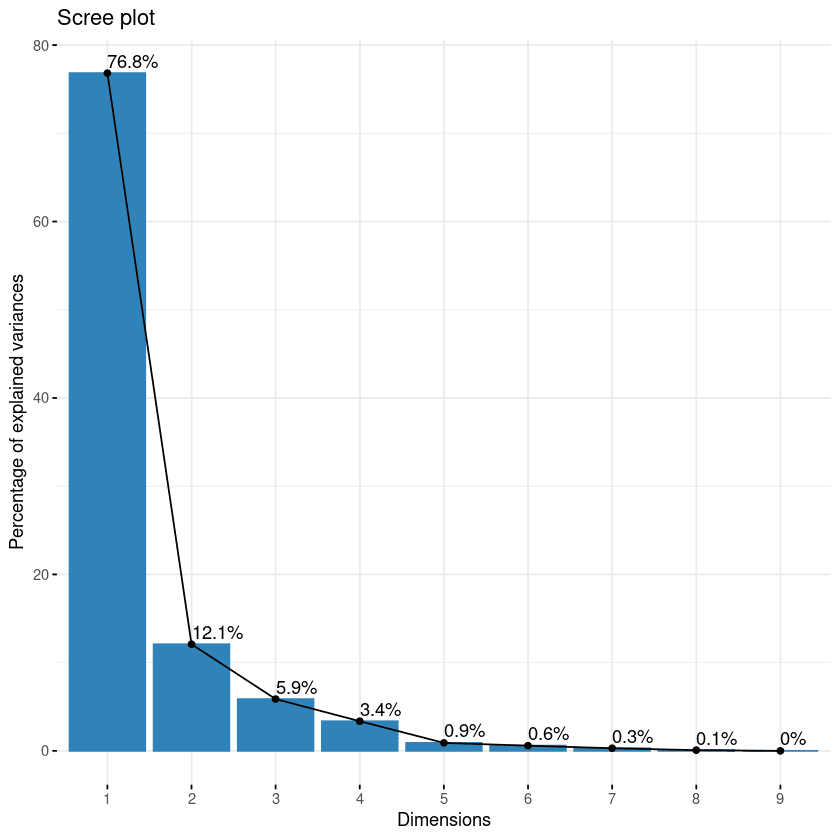
Scree plot của các thành phần
Biểu đồ này hiển thị các trị riêng theo đường cong đi xuống, từ lớn đến nhỏ. Hai thành phần đầu có thể xem là quan trọng nhất vì chúng chứa gần 89% tổng thông tin của dữ liệu.
Với biplot, có thể thấy các điểm tương đồng và khác biệt giữa các mẫu, đồng thời thể hiện ảnh hưởng của từng thuộc tính lên mỗi thành phần chính.
# Đồ thị các biến
fviz_pca_var(data.pca, col.var = "black")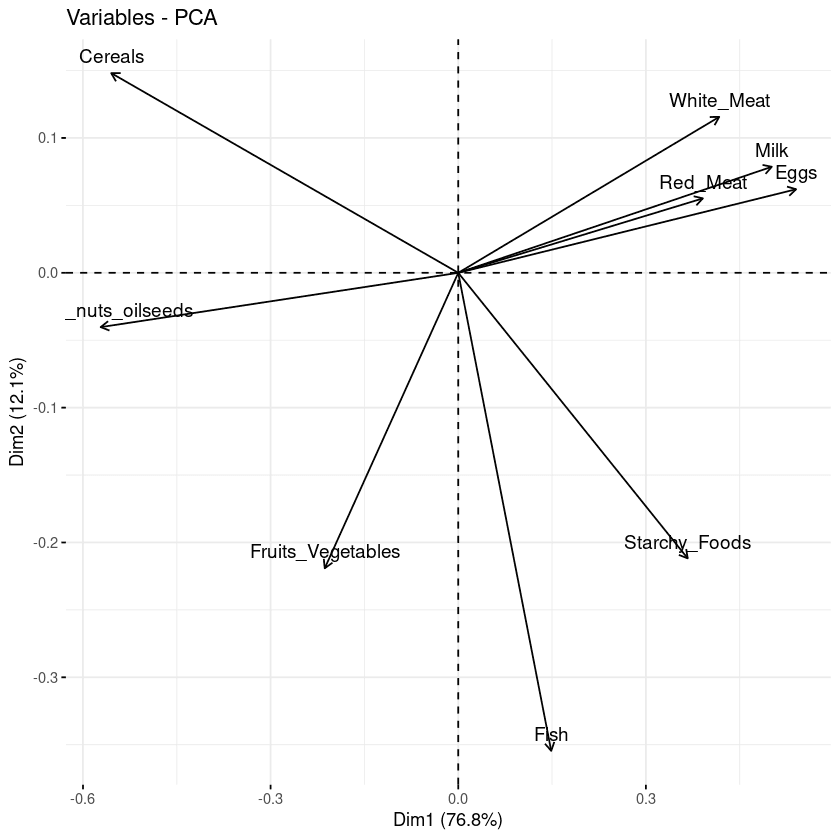
Biplot các biến theo các thành phần chính
Có ba thông tin chính có thể quan sát từ biểu đồ trên.
Mục tiêu của hình thứ ba là xác định mỗi biến được biểu diễn bao nhiêu trong một thành phần cho trước. Chất lượng biểu diễn này gọi là Cos2, tương ứng với cosin bình phương, và được tính bằng hàm fviz_cos2().
fviz_cos2(data.pca, choice = "var", axes = 1:2)Đoạn mã trên tính giá trị cosin bình phương cho mỗi biến đối với hai thành phần chính đầu tiên.
Từ minh họa dưới đây, ngũ cốc, cây họ đậu & hạt dầu, trứng và sữa là bốn biến có cos2 cao nhất, do đó đóng góp nhiều nhất cho PC1 và PC2.
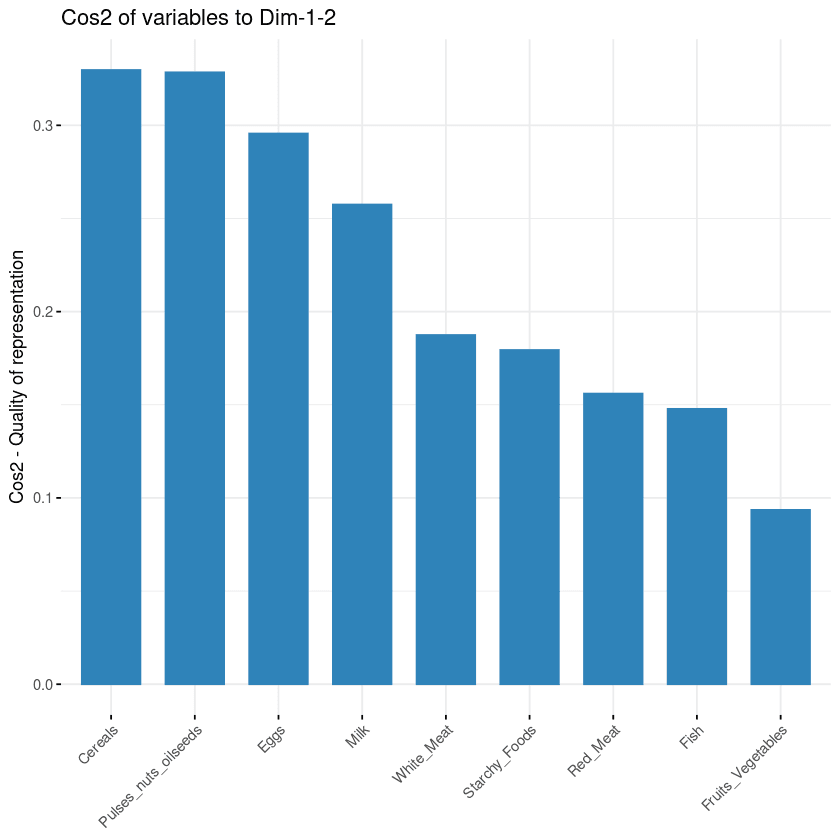
Đóng góp của các biến vào các thành phần chính
Hai cách trực quan cuối (biplot và tầm quan trọng thuộc tính) có thể kết hợp thành một biplot duy nhất, trong đó các thuộc tính có điểm cos2 tương tự sẽ có màu giống nhau. Thực hiện bằng cách tinh chỉnh hàm fviz_pca_var như sau:
fviz_pca_var(data.pca, col.var = "cos2",
gradient.cols = c("black", "orange", "green"),
repel = TRUE)Từ biplot dưới đây:
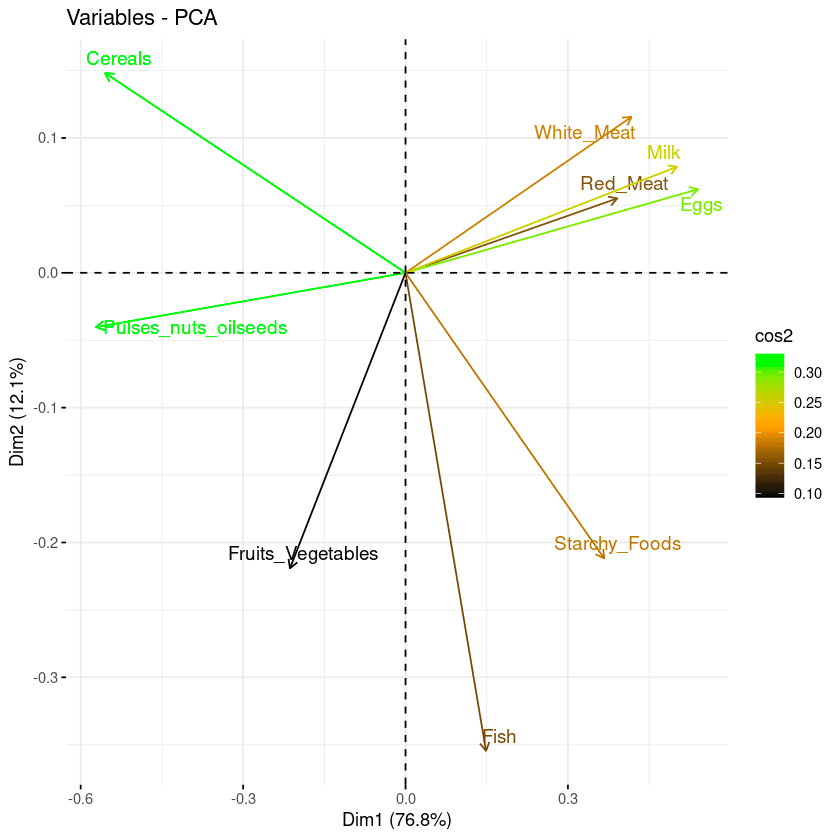
Kết hợp biplot và điểm cos2
Hai quy tắc thực tiễn giúp quyết định số thành phần chính cần giữ:
Trong hướng dẫn này, tôi đã trình bày PCA là gì và tầm quan trọng của nó trong phân tích dữ liệu. Từ nền tảng toán học đến mã R thực hành, chúng ta đã đi qua toàn bộ quy trình PCA trên bộ dữ liệu protein — từ chuẩn hóa và áp dụng princomp() đến diễn giải scree plot, biplot và trực quan cos2 để hiểu mối quan hệ giữa các thành phần chính và các biến gốc.
Hãy áp dụng các kỹ thuật này để giảm số chiều, làm lộ cấu trúc ẩn và xây dựng các pipeline học máy gọn gàng hơn với dữ liệu của chính bạn.
Để tìm hiểu thêm, khám phá các tài nguyên liên quan sau:
Khóa học cho R
Courses
Courses
Courses