Cursus
Introductie tot R
4 Hr
3.1M

scale() voordat je PCA draait, zodat variabelen evenveel bijdragenprincomp() of prcomp() in R met de pakketten FactoMineR en factoextra voor analyse en visualisatieOm deze tutorial te volgen, heb je nodig:
corrr, ggcorrplot, FactoMineR, factoextra (installatie komt later in de tutorial aan bod)Hoewel we focussen op PCA, is het goed om de vijf belangrijkste methoden voor hoofdcomponenten te onthouden die multivariate data samenvatten en visualiseren. In tegenstelling tot de andere technieken werkt PCA alleen met kwantitatieve variabelen.
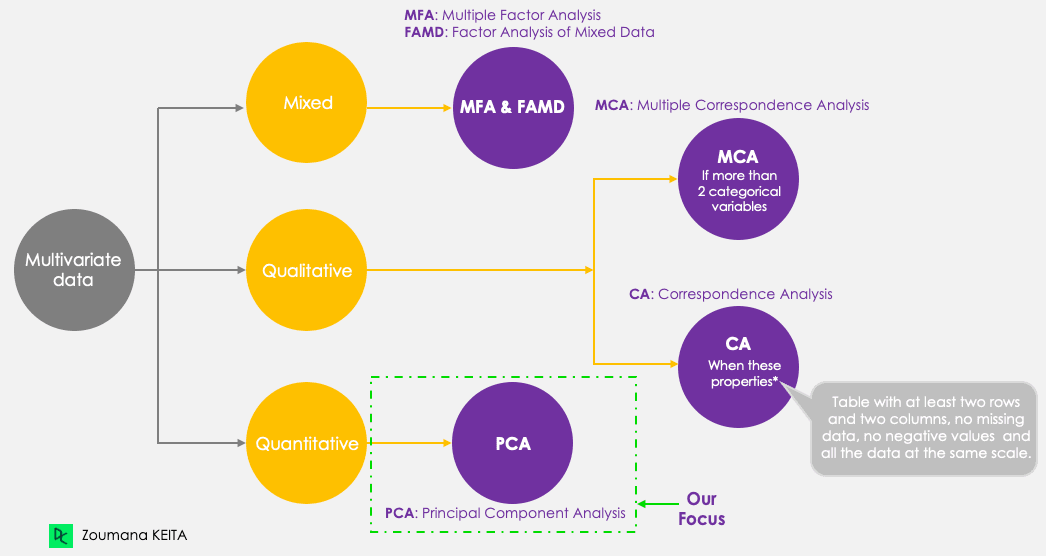
Methoden voor hoofdcomponenten
We gaan niet in op de wiskundige details, die vrij complex kunnen zijn. Met het volgende vijfstappenplan krijg je echter een beter idee van hoe je PCA berekent.
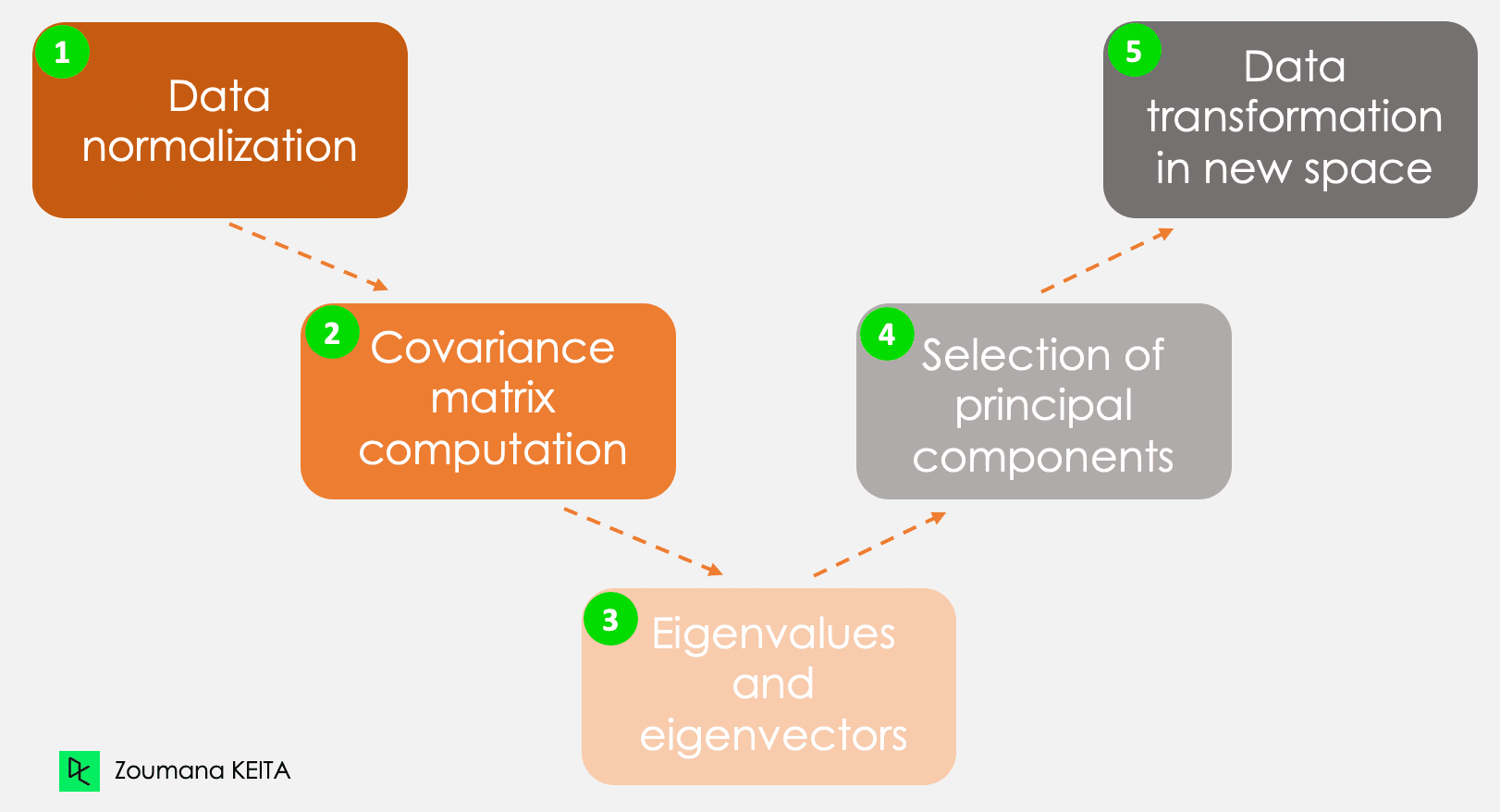
De vijf hoofdstappen voor het berekenen van hoofdcomponenten
Kijkend naar het voorbeeld uit de introductie, stel dat we voor een bepaalde klant de volgende informatie hebben.
Deze gegevens hebben verschillende schalen en PCA op zulke data levert een vertekend resultaat op. Daarom normaliseren we de data: zo draagt elk kenmerk gelijk bij en domineert geen variabele de rest. Voor elke variabele trek je het gemiddelde af en deel je door de standaarddeviatie.
Zoals de naam aangeeft, bereken je in deze stap de covariantiematrix op basis van de genormaliseerde data. Dit is een symmetrische matrix waarbij elk element (i, j) de covariantie tussen variabelen i en j weergeeft.
Geometrisch staat een eigenvector voor een richting, zoals “verticaal” of “90 graden”. Een eigenwaarde is het getal dat de hoeveelheid variantie in de data in die richting weergeeft. Elke eigenvector heeft een bijbehorende eigenwaarde.
Het aantal paren eigenvectoren en eigenwaarden is gelijk aan het aantal variabelen in de data. In data met alleen maandelijkse uitgaven, leeftijd en beoordeling zijn er dus drie paren. Niet alle paren zijn relevant. De eigenvector met de hoogste eigenwaarde is de eerste hoofdcomponent. De tweede hoofdcomponent komt overeen met de eigenvector met de op een na hoogste eigenwaarde, enzovoort.
In deze stap projecteer je de oorspronkelijke data op een nieuwe subruimte gedefinieerd door de hoofdcomponenten. Dit doe je door de oorspronkelijke data te vermenigvuldigen met de eerder berekende eigenvectoren.
Belangrijk: deze transformatie wijzigt de oorspronkelijke data niet, maar biedt een nieuw perspectief om de data beter te representeren.
PCA kent tal van toepassingen in het dagelijks leven, waaronder (maar zeker niet beperkt tot) financiën, beeldverwerking, gezondheidszorg en beveiliging.
Het voorspellen van aandelenkoersen op basis van historische prijzen wordt al jaren onderzocht. PCA kan worden gebruikt voor dimensiereductie en data-analyse om componenten te vinden die het grootste deel van de variabiliteit verklaren. Leer meer over dimensiereductie in R in onze cursus.
Een afbeelding bestaat uit veel kenmerken. PCA wordt vooral gebruikt voor beeldcompressie: de essentiële details blijven behouden terwijl het aantal dimensies afneemt. Daarnaast kan PCA worden ingezet voor complexere taken zoals beeldherkenning.
In dezelfde geest als beeldcompressie wordt PCA gebruikt bij MRI-scans om de dimensionaliteit te verlagen voor betere visualisatie en medische analyse. Het kan ook worden geïntegreerd in medische technologieën om bijvoorbeeld een ziekte op basis van scans te herkennen.
Biometrische systemen voor vingerafdrukherkenning kunnen PCA inzetten om de meest relevante kenmerken te extraheren, zoals textuur en aanvullende informatie.
Nu je de theoretische basis begrijpt, is het tijd om PCA in actie te zien.
In dit onderdeel doorlopen we alle stappen: pakketten installeren, data laden en voorbereiden, PCA toepassen in R en de resultaten interpreteren.
De broncode is beschikbaar in DataLab.
Voor deze tutorial heb je de volgende libraries nodig. Elk pakket vereist twee stappen voor effectief gebruik:
Dit R-pakket is bedoeld voor correlatieanalyse. Het richt zich vooral op het maken en bewerken van R data frames. Hieronder de stappen om te installeren en te laden.
install.packages("corrr")
library('corrr')Het ggcorrplot-pakket biedt meerdere functies en bevat onder meer de ggplot2-functie om eenvoudig een correlatiematrix te visualiseren. Net als hierboven is de installatie rechttoe rechtaan.
install.packages("ggcorrplot")
library(ggcorrplot)Vooral gebruikt voor multivariate, verkennende data-analyse. Het factoMineR-pakket biedt toegang tot het PCA-module om principal component analysis uit te voeren.
install.packages("FactoMineR")
library("FactoMineR")Dit laatste pakket levert alle relevante functies om de uitkomsten van de principal component analysis te visualiseren. Denk aan screeplot en biplot — twee visualisatietechnieken die later in dit artikel aan bod komen.
install.packages("factoextra")
library(factoextra)Voordat je de data laadt en verder verkent, is het goed om basisinformatie over de data te kennen waarmee je gaat werken.
De protein-dataset is een reële, multivariate dataset die de gemiddelde eiwitconsumptie van inwoners uit 25 Europese landen beschrijft.
Voor elk land zijn er tien kolommen. De eerste acht corresponderen met verschillende soorten eiwitten. De laatste correspondeert met de totale waarde van de gemiddelde eiwitinname.
Laten we snel een overzicht van de data nemen.
Eerst laden we de data met de functie read.csv(), vervolgens str(), wat tot de onderstaande weergave leidt.
protein_data <- read.csv("protein.csv")
str(protein_data)We zien dat de dataset 25 observaties en 11 kolommen heeft. Elke variabele is numeriek, behalve de kolom Country, die een tekstveld is.

Beschrijving van de proteinedata
Ontbrekende waarden kunnen het PCA-resultaat vertekenen. Het is daarom aan te raden de juiste aanpak te kiezen om met die waarden om te gaan. Onze tutorial Toptechnieken om ontbrekende waarden te behandelen helpt je bij die keuze.
colSums(is.na(protein_data))De functie colSums() gecombineerd met is.na() geeft het aantal ontbrekende waarden per kolom. Zoals hieronder te zien, hebben geen van de kolommen ontbrekende waarden.

Aantal ontbrekende waarden per kolom
Zoals eerder vermeld werkt PCA alleen met numerieke waarden. We verwijderen daarom de kolom Country. Ook is de kolom Total niet relevant, omdat dit de lineaire combinatie is van de overige numerieke variabelen.
De onderstaande code maakt nieuwe data met alleen numerieke kolommen.
numerical_data <- protein_data[,2:10]
head(numerical_data)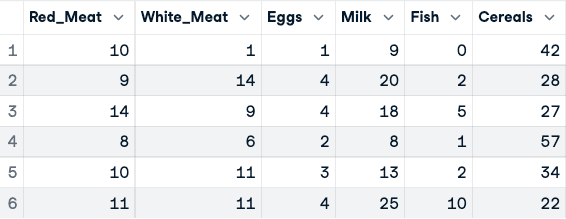
Voor de normalisatie van de data (alleen de eerste vijf kolommen getoond)
Nu kunnen we normaliseren met de functie scale().
data_normalized <- scale(numerical_data)
head(data_normalized)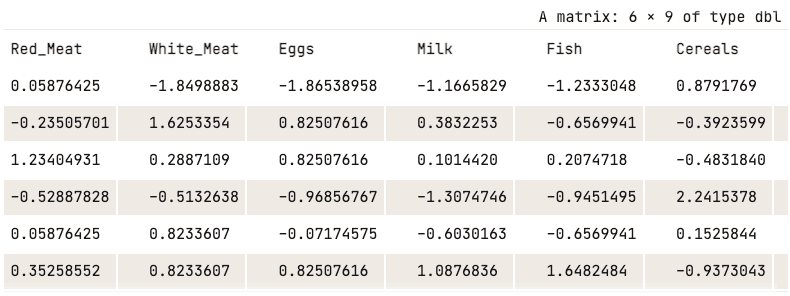
Genormaliseerde data (alleen de eerste vijf kolommen getoond)
Voor je PCA draait, helpt het om correlaties tussen variabelen te visualiseren. Sterke onderlinge correlaties duiden op redundantie die PCA kan comprimeren. Ik gebruik de eerder geïnstalleerde pakketten corrr en ggcorrplot.
corr_matrix <- cor(data_normalized)
ggcorrplot(corr_matrix,
hc.order = TRUE,
type = "lower",
lab = TRUE)
De heatmap laat sterke positieve correlaties zien tussen dierlijke eiwitbronnen (rood vlees, wit vlees, eieren en melk). Dit verklaart waarom de eerste hoofdcomponent bijna 77% van de totale variantie verklaart. Deze correlatiestructuur is precies wat PCA benut.
Opmerking over PCA-functies in R: Deze tutorial gebruikt princomp(), dat spectrale decompositie toepast op de covariantiematrix. Voor de meeste praktische toepassingen verdient prcomp() de voorkeur — dit gebruikt singular value decomposition (SVD), wat numeriek stabieler is bij datasets met veel variabelen. Het belangrijkste verschil in output: princomp() slaat loadings op in $loadings, terwijl prcomp() $rotation gebruikt. Op goed geconditioneerde data, zoals de proteinedataset hier, leveren beide equivalente resultaten op.
Alle middelen zijn nu aanwezig om de PCA-analyse uit te voeren. Eerst berekent princomp() de PCA en summary() toont het resultaat.
data.pca <- princomp(data_normalized)
summary(data.pca)
R PCA-samenvatting
In de bovenstaande weergave zien we dat er negen hoofdcomponenten zijn gegenereerd (Comp.1 t/m Comp.9), wat overeenkomt met het aantal variabelen in de data.
Elke component verklaart een percentage van de totale variantie in de dataset. In de sectie Cumulative Proportion verklaart de eerste hoofdcomponent bijna 77% van de totale variantie. Dit betekent dat bijna twee derde van de data in de set van 9 variabelen door alleen de eerste hoofdcomponent kan worden weergegeven. De tweede verklaart 12,08% van de totale variantie.
De cumulatieve proportie van Comp.1 en Comp.2 verklaart bijna 89% van de totale variantie. Dit betekent dat de eerste twee hoofdcomponenten de data nauwkeurig kunnen representeren.
Mooi, die eerste twee componenten, maar wat betekenen ze nu precies?
Dat kun je beantwoorden door te bekijken hoe ze samenhangen met elke kolom via de loadings van elke hoofdcomponent.
data.pca$loadings[, 1:2]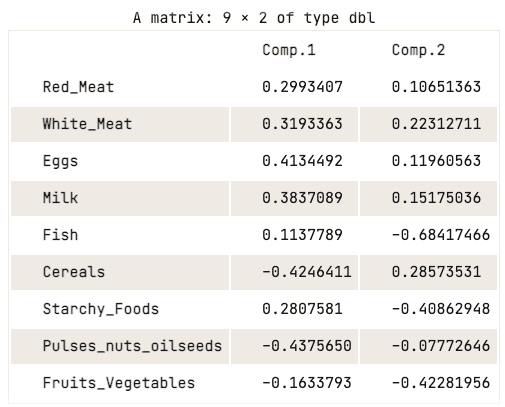
Loadingmatrix van de eerste twee hoofdcomponenten
De loadingmatrix laat zien dat de eerste hoofdcomponent hoge positieve waarden heeft voor rood vlees, wit vlees, eieren en melk. De waarden voor granen, peulvruchten, noten en oliehoudende zaden, en groente en fruit zijn juist relatief negatief. Dit suggereert dat landen met een hogere inname van dierlijke eiwitten in surplus zijn, terwijl landen met een lagere inname in tekort zijn.
Voor de tweede hoofdcomponent zien we hoge negatieve waarden voor vis, zetmeelrijke voeding en groente en fruit. Dit impliceert dat het dieet van de betreffende landen sterk wordt beïnvloed door de ligging, zoals kustregio’s voor vis, en binnenlandregio’s met een dieet rijk aan groente en aardappelen.
De analyse van de loadingmatrix gaf een goed beeld van de relatie tussen elk van de eerste twee hoofdcomponenten en de kenmerken in de data. Maar visueel is dat misschien minder aantrekkelijk.
Er zijn een paar standaardvisualisaties die helpen om inzichten uit de data te halen. Dit gedeelte behandelt enkele van die benaderingen, te beginnen met de screeplot.
De eerste benadering is de screeplot. Die gebruik je om het belang van elke hoofdcomponent te visualiseren en om te bepalen hoeveel componenten je behoudt. De screeplot maak je met de functie fviz_eig().
fviz_eig(data.pca, addlabels = TRUE)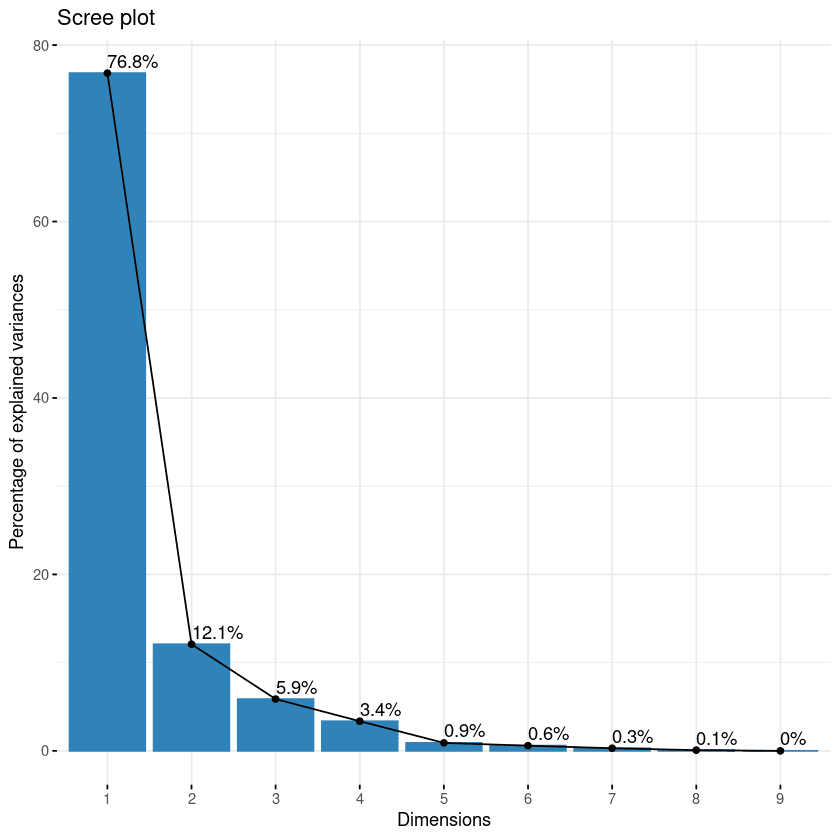
Screeplot van de componenten
Deze plot toont de eigenwaarden in een dalende curve van hoog naar laag. De eerste twee componenten zijn het belangrijkst, omdat ze samen bijna 89% van de totale informatie in de data bevatten.
Met de biplot kun je de overeenkomsten en verschillen tussen de samples visualiseren en zie je bovendien de impact van elk kenmerk op de hoofdcomponenten.
# Grafiek van de variabelen
fviz_pca_var(data.pca, col.var = "black")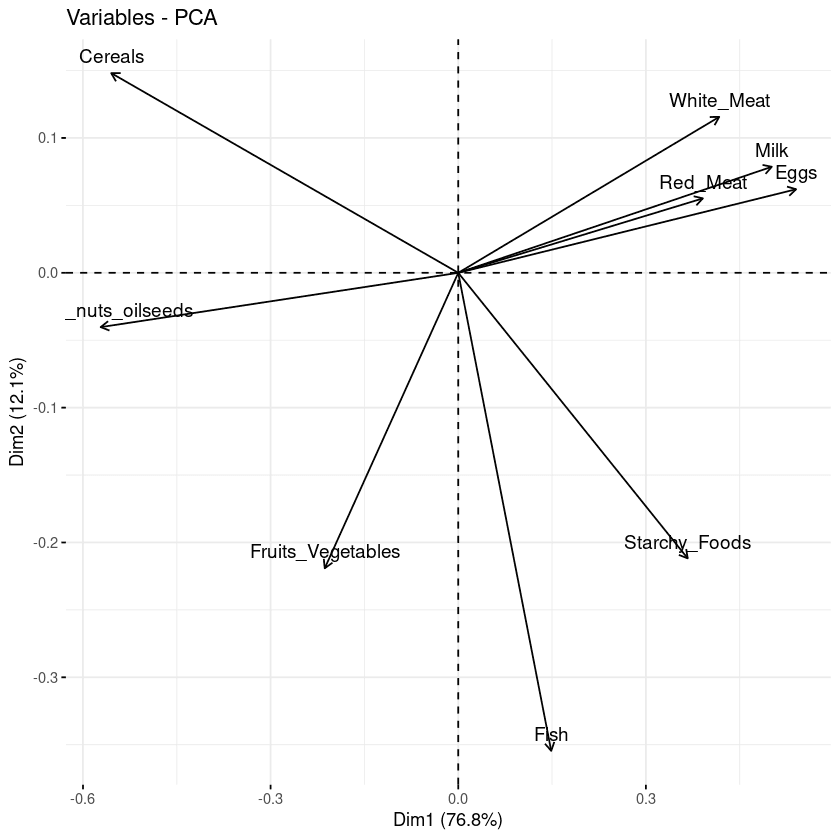
Biplot van de variabelen ten opzichte van de hoofdcomponenten
Drie hoofdobservaties uit de bovenstaande plot:
Het doel van de derde visualisatie is te bepalen in welke mate elke variabele in een bepaalde component wordt gerepresenteerd. Deze representatiekwaliteit heet Cos2 en komt overeen met de kwadraatcosinus. Je berekent dit met de functie fviz_cos2().
fviz_cos2(data.pca, choice = "var", axes = 1:2)De bovenstaande code berekent de kwadraatcosinus voor elke variabele ten opzichte van de eerste twee hoofdcomponenten.
Uit de onderstaande illustratie blijkt dat granen, peulvruchten en oliehoudende zaden, eieren en melk de vier variabelen met de hoogste cos2 zijn en dus het meest bijdragen aan PC1 en PC2.
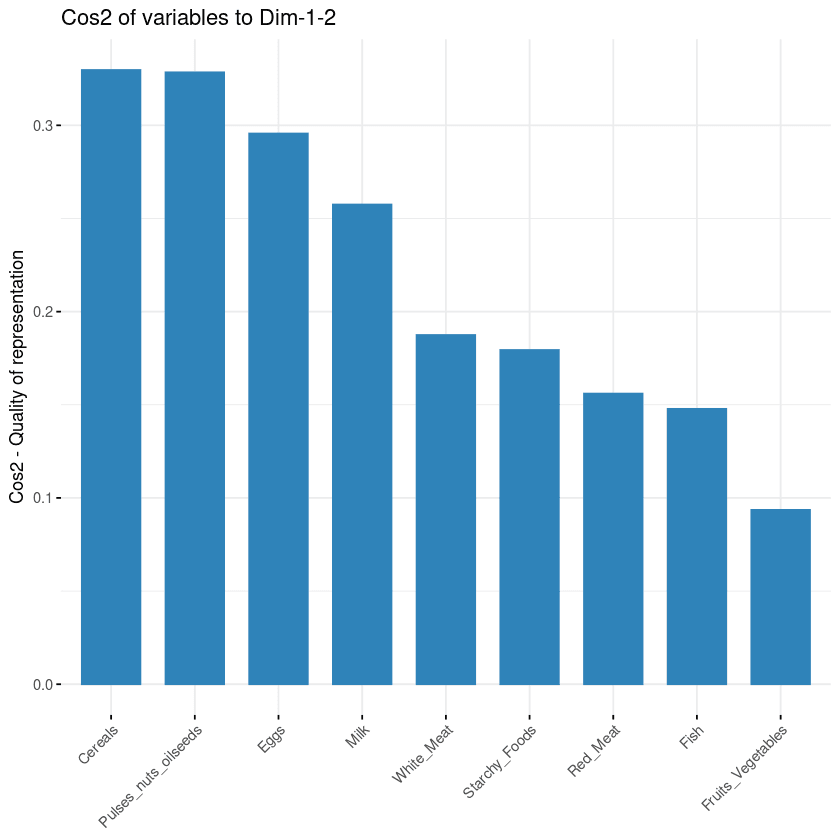
Bijdrage van variabelen aan hoofdcomponenten
De laatste twee visualisaties — biplot en belangrijkheid van kenmerken — kun je combineren in één biplot, waarbij kenmerken met vergelijkbare cos2-scores vergelijkbare kleuren hebben. Dat doe je door de functie fviz_pca_var als volgt te fine-tunen:
fviz_pca_var(data.pca, col.var = "cos2",
gradient.cols = c("black", "orange", "green"),
repel = TRUE)In de biplot hieronder:
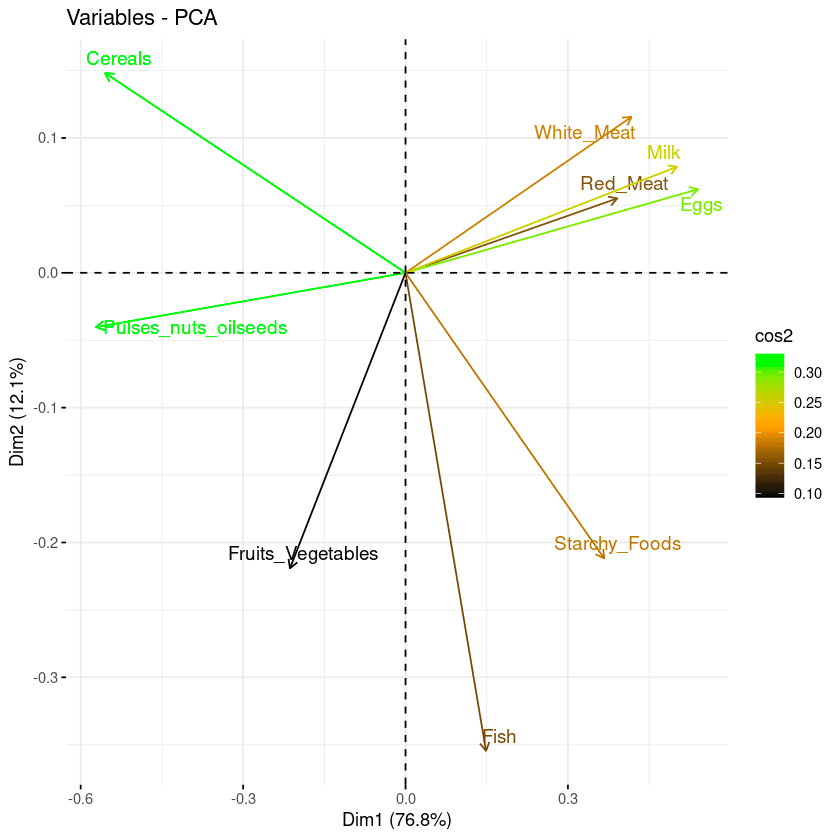
Combinatie van biplot en cos2-score
Twee praktische regels helpen bepalen hoeveel hoofdcomponenten je behoudt:
In deze tutorial heb ik uitgelegd wat principal component analysis is en waarom het belangrijk is in data-analyse. Van de wiskundige basis tot en met hands-on R-code doorliepen we een volledige PCA‑workflow op de proteinedataset — van normaliseren en princomp() toepassen tot het interpreteren van screeplots, biplots en cos2‑visualisaties om de relatie tussen hoofdcomponenten en de oorspronkelijke variabelen te begrijpen.
Pas deze technieken toe om dimensionaliteit te reduceren, verborgen structuur zichtbaar te maken en schonere machine‑learning‑pijplijnen te bouwen met je eigen datasets.
Ga verder met deze gerelateerde resources:
Cursussen voor R
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
