Cours
Introduction à R
4 h
3M

Même si nous nous concentrons sur l'ACP, gardons à l'esprit les cinq principales techniques de composantes principales suivantes, qui visent à résumer et à visualiser des données multivariées. L'ACP, contrairement aux autres techniques, ne fonctionne qu'avec des variables quantitatives.
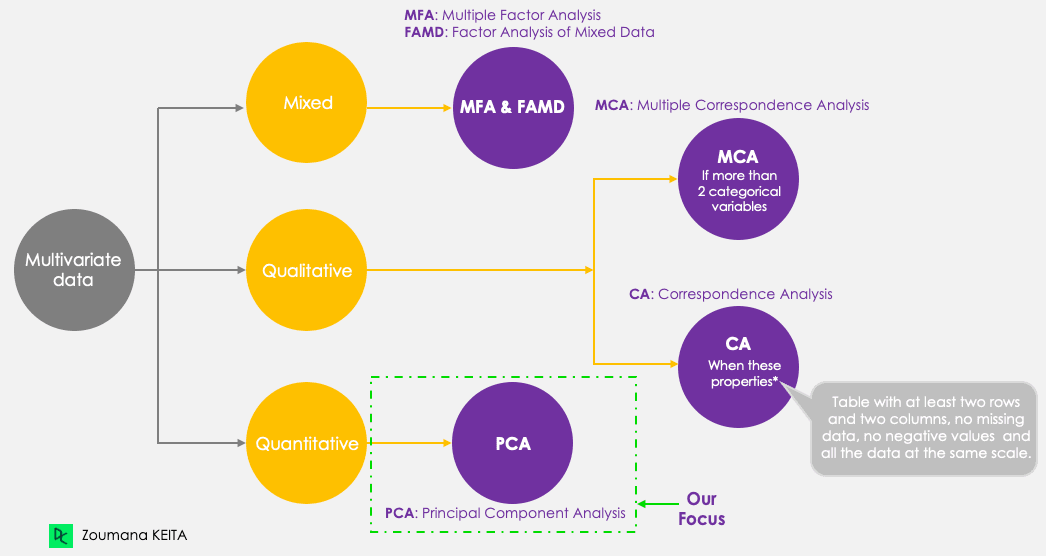
Méthodes des composantes principales
Nous n'entrerons pas dans l'explication du concept mathématique, qui peut être assez complexe. Cependant, la compréhension des cinq étapes suivantes peut vous donner une meilleure idée de la manière de calculer l'ACP.
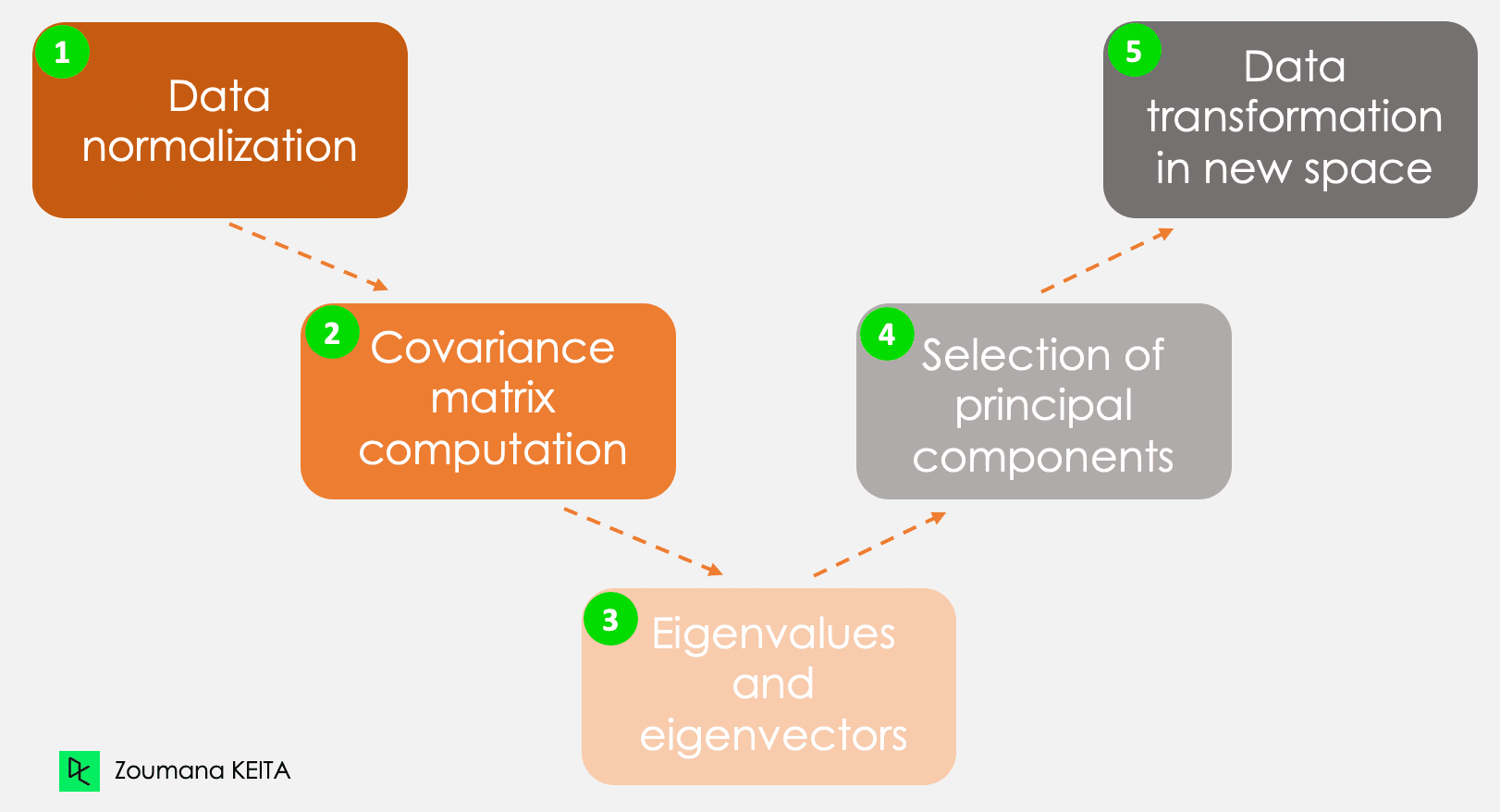
Les cinq étapes principales du calcul des composantes principales
En reprenant l'exemple de l'introduction, considérons, par exemple, les informations suivantes pour un client donné.
Ces informations ont des échelles différentes et l'exécution d'une ACP à partir de ces données conduira à un résultat biaisé. C'est là qu'intervient la normalisation des données. Il garantit que chaque attribut a le même niveau de contribution, évitant ainsi qu'une variable ne domine les autres. Pour chaque variable, la normalisation est effectuée en soustrayant sa moyenne et en la divisant par son écart-type.
Comme son nom l'indique, cette étape consiste à calculer la matrice de covariance à partir des données normalisées. Il s'agit d'une matrice symétrique, et chaque élément (i, j) correspond à la covariance entre les variables i et j.
Géométriquement, un vecteur propre représente une direction telle que "vertical" ou "90 degrés". Une valeur propre, en revanche, est un nombre représentant la quantité de variance présente dans les données pour une direction donnée. À chaque vecteur propre correspond une valeur propre.
Il y a autant de paires de vecteurs propres et de valeurs propres que de variables dans les données. Dans les données ne comportant que les dépenses mensuelles, l'âge et le taux, il y aura trois paires. Toutes les paires ne sont pas pertinentes. Ainsi, le vecteur propre ayant la valeur propre la plus élevée correspond à la première composante principale. La deuxième composante principale est le vecteur propre ayant la deuxième valeur propre la plus élevée, et ainsi de suite.
Cette étape consiste à réorienter les données originales sur un nouveau sous-espace défini par les composantes principales. Cette réorientation est effectuée en multipliant les données originales par les vecteurs propres calculés précédemment.
Il est important de se rappeler que cette transformation ne modifie pas les données originales elles-mêmes, mais qu'elle fournit une nouvelle perspective pour mieux représenter les données.
L'analyse en composantes principales a de nombreuses applications dans notre vie quotidienne, notamment (mais pas uniquement) dans les domaines de la finance, du traitement d'images, des soins de santé et de la sécurité.
Prévoir les cours des actions à partir des cours passés est une notion utilisée dans la recherche depuis des années. L'ACP peut être utilisée pour réduire la dimensionnalité et analyser les données afin d'aider les experts à trouver les composantes pertinentes qui expliquent la majeure partie de la variabilité des données. Vous pouvez en savoir plus sur la réduction de la dimensionnalité dans R dans notre cours dédié.
Une image est composée de plusieurs éléments. L'ACP est principalement appliquée à la compression d'images pour conserver les détails essentiels d'une image donnée tout en réduisant le nombre de dimensions. En outre, l'ACP peut être utilisée pour des tâches plus complexes telles que la reconnaissance d'images.
Dans la même logique de compression d'images. L'ACP est utilisée dans les examens d'imagerie par résonance magnétique (IRM) pour réduire la dimensionnalité des images afin d'améliorer la visualisation et l'analyse médicale. Elle peut également être intégrée dans des technologies médicales utilisées, par exemple, pour reconnaître une maladie donnée à partir d'images scannées.
Les systèmes biométriques utilisés pour la reconnaissance des empreintes digitales peuvent intégrer des technologies tirant parti de l'analyse en composantes principales pour extraire les caractéristiques les plus pertinentes, telles que la texture de l'empreinte digitale et des informations supplémentaires.
Maintenant que vous comprenez la théorie sous-jacente de l'ACP, vous êtes enfin prêt à la mettre en pratique.
Cette section couvre toutes les étapes de l'installation des paquets appropriés, du chargement et de la préparation des données, de l'application de l'analyse en composantes principales dans R et de l'interprétation des résultats.
Le code source est disponible dans l'espace de travail de DataCamp.
Pour mener à bien ce tutoriel, vous aurez besoin des bibliothèques suivantes, et chacune d'entre elles nécessite deux étapes principales pour être utilisée efficacement :
Il s'agit d'un paquetage R pour l'analyse des corrélations. Il se concentre principalement sur la création et la manipulation des cadres de données R. Vous trouverez ci-dessous les étapes à suivre pour installer et charger la bibliothèque.
install.packages("corrr")
library('corrr')Le paquet ggcorrplot fournit de nombreuses fonctions, mais ne se limite pas à la fonction ggplot2 qui facilite la visualisation des matrices de corrélation. Comme pour l'instruction ci-dessus, l'installation est simple.
install.packages("ggcorrplot")
library(ggcorrplot)Principalement utilisé pour l'analyse de données exploratoires multivariées, le paquet factoMineR donne accès au module ACP pour effectuer une analyse en composantes principales.
install.packages("FactoMineR")
library("FactoMineR")Ce dernier paquet fournit toutes les fonctions nécessaires pour visualiser les résultats de l'analyse en composantes principales. Ces fonctions incluent, sans s'y limiter, le scree plot, le biplot, pour ne mentionner que deux des techniques de visualisation abordées plus loin dans l'article.
Avant de charger les données et d'effectuer toute autre exploration, il est bon de comprendre et de disposer des informations de base relatives aux données avec lesquelles vous allez travailler.
L'ensemble de données sur les protéines est un ensemble de données multivariées à valeurs réelles décrivant la consommation moyenne de protéines par les citoyens de 25 pays européens.
Pour chaque pays, il y a dix colonnes. Les huit premiers correspondent aux différents types de protéines. Le dernier correspond à la valeur totale des valeurs moyennes des protéines.
Voyons un aperçu rapide des données.
Tout d'abord, nous chargeons les données à l'aide de la fonction read.csv(), puis str(), ce qui donne l'image ci-dessous.
protein_data <- read.csv("protein.csv")
str(protein_data)Nous pouvons constater que l'ensemble de données comporte 25 observations et 11 colonnes, et que chaque variable est numérique, à l'exception de la colonne Pays, qui est un texte.

Description des données relatives aux protéines
La présence de valeurs manquantes peut fausser les résultats de l'ACP. Il est donc fortement recommandé d'adopter l'approche appropriée pour s'attaquer à ces valeurs. Notre tutoriel Top Techniques to Handle Missing Values Every Data Scientist Should Know peut vous aider à faire le bon choix.
colSums(is.na(protein_data))La fonction colSums() combinée à la fonction is.na() renvoie le nombre de valeurs manquantes dans chaque colonne. Comme nous pouvons le voir ci-dessous, aucune des colonnes ne présente de valeurs manquantes.

Nombre de valeurs manquantes dans chaque colonne
Comme indiqué au début de l'article, l'ACP ne fonctionne qu'avec des valeurs numériques. Nous devons donc nous débarrasser de la colonne Pays. De même, la colonne Total n'est pas pertinente pour l'analyse puisqu'il s'agit de la combinaison linéaire des variables numériques restantes.
Le code ci-dessous crée de nouvelles données avec uniquement des colonnes numériques.
numerical_data <- protein_data[,2:10]
head(numerical_data)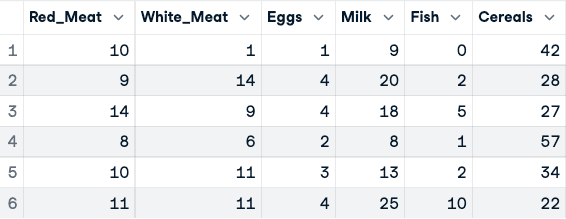
Avant la normalisation des données (seules les cinq premières colonnes sont affichées)
La normalisation peut maintenant être appliquée à l'aide de la fonction scale().
data_normalized <- scale(numerical_data)
head(data_normalized)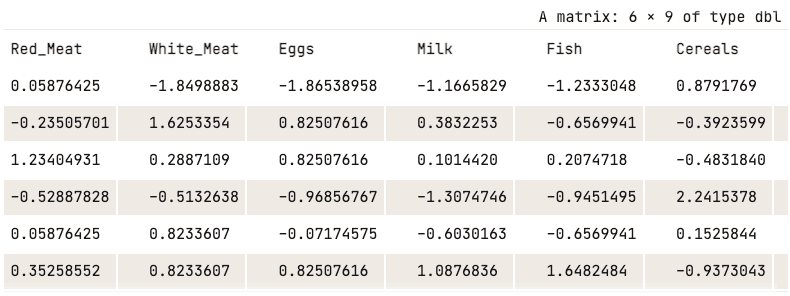
Données normalisées (seules les cinq premières colonnes sont affichées)
Toutes les ressources sont maintenant disponibles pour effectuer l'analyse ACP. Tout d'abord, la fonction princomp() calcule l'ACP et la fonction summary() affiche le résultat.
data.pca <- princomp(data_normalized)
summary(data.pca)
R Résumé de l'APC
La capture d'écran précédente montre que neuf composantes principales ont été générées (Comp.1 à Comp.9), ce qui correspond également au nombre de variables dans les données.
Chaque composante explique un pourcentage de la variance totale de l'ensemble des données. Dans la section Proportion cumulée, la première composante principale explique près de 77 % de la variance totale. Cela signifie que près des deux tiers des données de l'ensemble des 9 variables peuvent être représentées par la seule première composante principale. Le second explique 12,08% de la variance totale.
La proportion cumulée de Comp.1 et Comp.2 explique près de 89% de la variance totale. Cela signifie que les deux premières composantes principales peuvent représenter fidèlement les données.
C'est une bonne chose d'avoir les deux premiers éléments, mais que signifient-ils vraiment ?
Pour répondre à cette question, il convient d'étudier leur relation avec chaque colonne à l'aide des coefficients de pondération de chaque composante principale.
data.pca$loadings[, 1:2]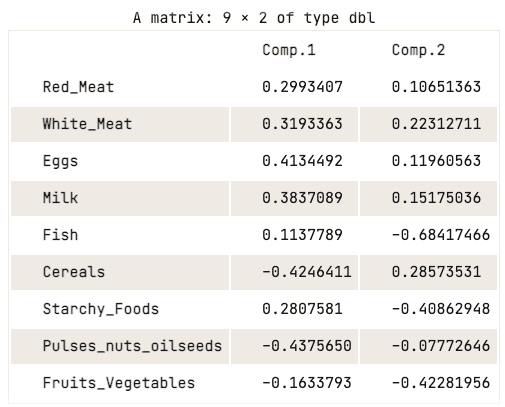
Matrice de chargement des deux premières composantes principales
La matrice de chargement montre que la première composante principale présente des valeurs positives élevées pour la viande rouge, la viande blanche, les œufs et le lait. Toutefois, les valeurs pour les céréales, les légumineuses, les fruits à coque et les oléagineux, ainsi que les fruits et légumes sont relativement négatives. Cela suggère que les pays ayant une consommation plus élevée de protéines animales sont en excès, tandis que les pays ayant une consommation plus faible sont en déficit.
En ce qui concerne la deuxième composante principale, elle présente des valeurs négatives élevées pour le poisson, les féculents et les fruits et légumes. Cela implique que les régimes alimentaires des pays sous-jacents sont fortement influencés par leur situation géographique, par exemple les régions côtières pour le poisson et les régions intérieures pour un régime riche en légumes et en pommes de terre.
L'analyse précédente de la matrice de chargement a permis de bien comprendre la relation entre chacune des deux premières composantes principales et les attributs des données. Cependant, il se peut qu'elle ne soit pas attrayante sur le plan visuel.
Il existe quelques stratégies de visualisation standard qui peuvent aider l'utilisateur à se faire une idée des données, et cette section vise à couvrir certaines de ces approches, en commençant par le scree plot.
La première approche de la liste est le scree plot. Il permet de visualiser l'importance de chaque composante principale et peut être utilisé pour déterminer le nombre de composantes principales à retenir. Le scree plot peut être généré à l'aide de la fonction fviz_eig().
fviz_eig(data.pca, addlabels = TRUE)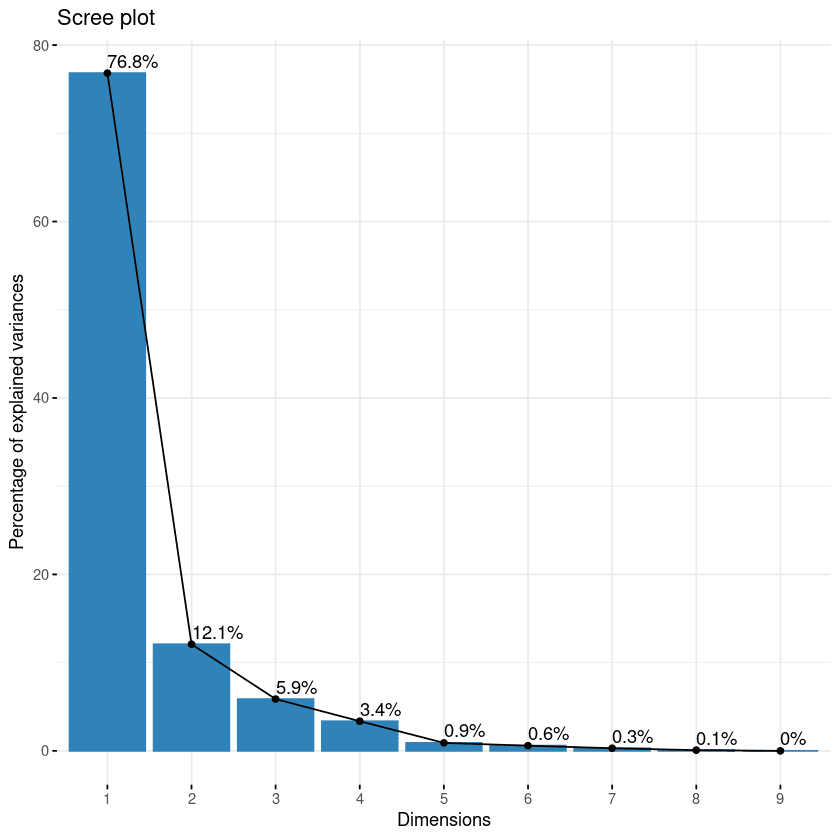
Scree plot des composantes
Ce graphique montre les valeurs propres dans une courbe descendante, de la plus élevée à la plus basse. Les deux premières composantes peuvent être considérées comme les plus significatives puisqu'elles contiennent près de 89% de l'information totale des données.
Le biplot permet de visualiser les similitudes et les dissemblances entre les échantillons et montre en outre l'impact de chaque attribut sur chacune des composantes principales.
# Graph of the variables
fviz_pca_var(data.pca, col.var = "black")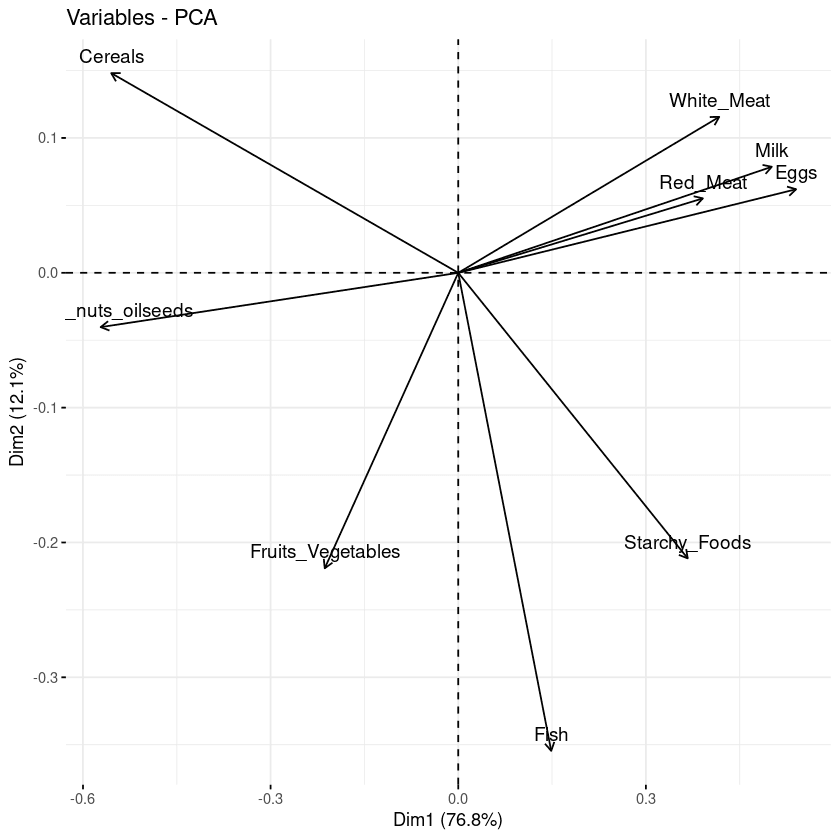
Biplot des variables par rapport aux composantes principales
Trois informations principales peuvent être observées à partir du graphique précédent.
L'objectif de la troisième visualisation est de déterminer dans quelle mesure chaque variable est représentée dans un composant donné. Cette qualité de représentation est appelée Cos2 et correspond au cosinus carré. Elle est calculée à l'aide de la fonction fviz_cos2.
fviz_cos2(data.pca, choice = "var", axes = 1:2)Le code ci-dessus a calculé la valeur du cosinus carré pour chaque variable par rapport aux deux premières composantes principales.
D'après l'illustration ci-dessous, les céréales, les graines oléagineuses, les œufs et le lait sont les quatre variables dont le cos2 est le plus élevé et qui contribuent donc le plus aux PC1 et PC2.
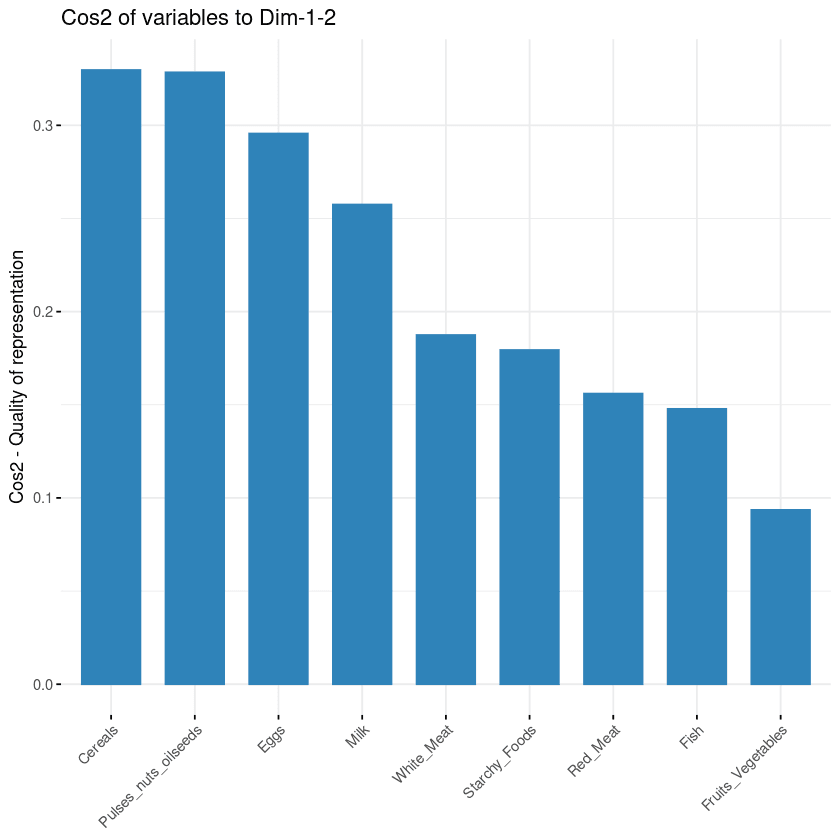
Contribution des variables aux composantes principales
Les deux dernières approches de visualisation : le biplot et l'importance des attributs peuvent être combinées pour créer un seul biplot, où les attributs ayant des scores cos2 similaires auront des couleurs similaires. Pour ce faire, la fonction fviz_pca_var est réglée avec précision comme suit :
fviz_pca_var(data.pca, col.var = "cos2",
gradient.cols = c("black", "orange", "green"),
repel = TRUE)D'après le graphique ci-dessous :
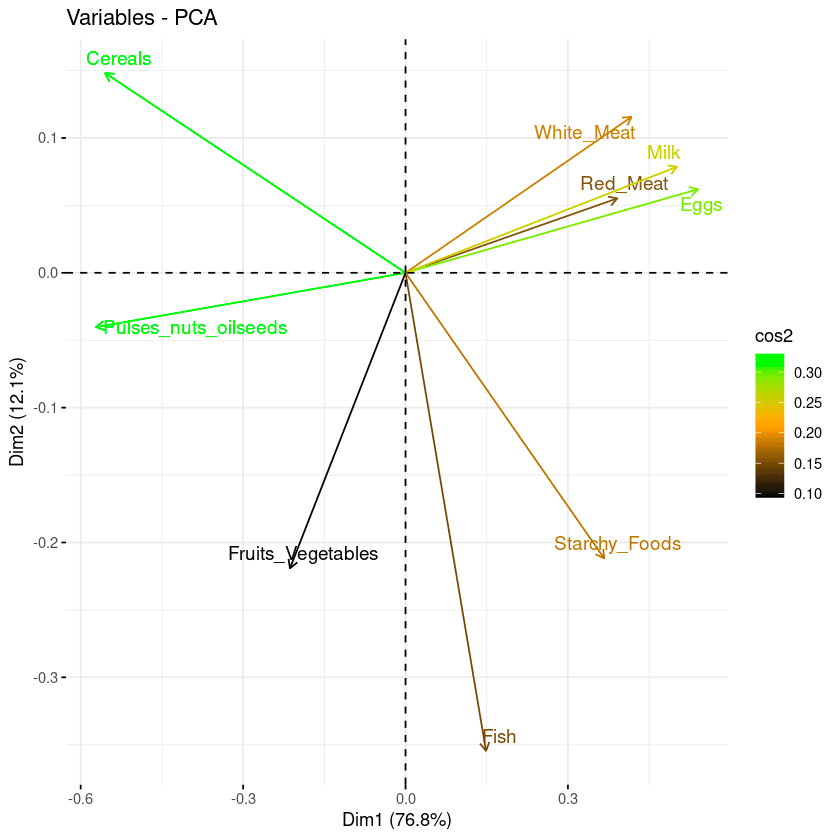
Combinaison de biplot et de cos2 score
Cet article a traité de l'analyse en composantes principales et de son importance dans l'analyse des données à l'aide de la matrice de corrélation du progiciel corrr. En plus de couvrir certaines applications du monde réel, il vous a également guidé à travers un exemple d'ACP avec différentes stratégies de visualisation, de l'utilisation de la fonction existante à l'affinement en utilisant la combinaison de biplot et cos2 pour une meilleure compréhension et visualisation de la relation entre l'analyse ACP dans r et les attributs.
Nous espérons qu'il vous permettra d'acquérir les compétences nécessaires pour visualiser et comprendre efficacement les informations cachées dans vos données.
Pour approfondir votre apprentissage de l'analyse en composantes principales, consultez le tutoriel Analyse en composantes principales en Python. Il illustre l'utilisation de l'ACP avec Python sur des ensembles de données tabulaires et d'images. Notre cours Introduction à R est une bonne étape pour maîtriser les bases de l'analyse de données en R, y compris les vecteurs, les listes et les cadres de données, et pour s'entraîner à utiliser R avec des ensembles de données réels.
Nos programmes de certification vous aident à vous démarquer et à prouver aux employeurs potentiels que vos compétences sont adaptées à l'emploi.

Cours pour R
Cours
Cours
Cours
blog
Kurtis Pykes
15 min
blog
Tutoriel
Tutoriel
Sejal Jaiswal
Tutoriel
DataCamp Team
Tutoriel
Aditya Sharma
