Program
Dasar-Dasar Data Python
28 Hr
Di dunia analisis data, pandas telah lama menjadi pilihan default bagi para profesional data untuk menangani data tabular di Python.
Namun, seiring bertambahnya ukuran dan kompleksitas dataset, pandas dapat mengalami hambatan kinerja, pemanfaatan multi-core yang terbatas, dan kendala memori.
Di sinilah Polars muncul sebagai alternatif modern. Polars adalah pustaka DataFrame yang ditulis dalam Rust yang menghadirkan kinerja sangat cepat, manajemen memori efisien, dan filosofi desain yang berfokus pada skalabilitas.
Dalam tutorial ini, kami akan membahas apa itu Polars dan cara melakukan beberapa operasi dasar Polars di Python. Jika Anda mencari pengalaman praktik langsung, saya sarankan melihat kursus Introduction to Polars.
Polars menawarkan serangkaian fitur unik yang membedakannya dari pandas:
Polars mendukung beragam tipe data melampaui yang dasar:
Int32, Int64, Float32, Float64.true/false.Date, Datetime, Duration, Time.List dan Struct, berguna untuk data mirip JSON.Sebagai alternatif yang lebih baru dan modern untuk pandas, Polars menawarkan beberapa manfaat:
Sekarang, mari kita lihat bagaimana kita dapat mulai menggunakan Polars sendiri di Python.
Sebelum menggunakan Polars, Anda perlu menyiapkan lingkungan dengan benar.
Polars mendukung Windows, macOS, dan Linux. Dapat diinstal di virtual environment, Python sistem, atau melalui alur kerja terkontainer (Docker).
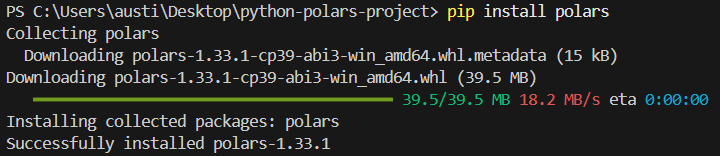
Untuk memasang pustaka polars di Python, jalankan perintah berikut di terminal.
pip install polarsAnda akan melihat pesan instalasi berikut:
Sebagai alternatif, Anda dapat memasang pustaka di lingkungan conda jika itu yang Anda gunakan.
conda install -c conda-forge polarsUntuk memeriksa apakah instalasi Anda berhasil, tulis skrip sederhana berikut:
import polars as pl
print(pl.__version__)Polars memungkinkan Anda menyetel cara berjalan dan tampilan keluarannya dengan menetapkan variabel lingkungan sebelum memulai sesi Python Anda. Misalnya:
POLARS_MAX_THREADS: Membatasi jumlah thread.POLARS_FMT_MAX_COLS: Mengatur jumlah kolom yang dicetak.POLARS_FMT_TABLE_WIDTH: Menyesuaikan lebar tampilan DataFrame.Berikut contoh cara menyetel variabel ini di shell sebelum menjalankan Python:
export POLARS_MAX_THREADS=8
export POLARS_FMT_MAX_COLS=20Sebelum menyelami fitur Polars, akan berguna jika kita memiliki dataset yang dapat digunakan secara konsisten sepanjang tutorial ini. Kita dapat membuat file CSV sederhana menggunakan modul csv bawaan Python atau pandas.
Berikut contoh yang membuat file transactions.csv dengan data sintetis:
import csv
import random
from datetime import datetime, timedelta
# Define column names
columns = ["transaction_id", "customer_id", "amount", "transaction_date"]
# Generate synthetic rows
rows = []
start_date = datetime(2023, 1, 1)
for i in range(1, 101):
customer_id = random.randint(1, 10)
amount = round(random.uniform(10, 2000), 2)
date = start_date + timedelta(days=random.randint(0, 90))
rows.append([i, customer_id, amount, date.strftime("%Y-%m-%d")])
# Write to CSV
with open("transactions.csv", "w", newline="") as f:
writer = csv.writer(f)
writer.writerow(columns)
writer.writerows(rows)Skrip ini membuat dataset 100 transaksi dengan jumlah acak, ID pelanggan, dan tanggal transaksi. Anda dapat menyesuaikan rentang dan ukurannya sesuai kebutuhan.
Simpan skrip ini, jalankan sekali, dan Anda akan memiliki file CSV untuk digunakan dalam contoh-contoh di seluruh artikel ini.
Polars dibangun di atas dua abstraksi inti: Series dan DataFrame.
Keduanya menyediakan cara kerja dengan data yang terstruktur dan efisien, mirip dengan pandas, tetapi dioptimalkan dengan backend Polars yang didukung Rust. Mari kita uraikan konsep utamanya.
Series di Polars adalah array satu dimensi, mirip dengan kolom dalam spreadsheet atau tabel basis data. Setiap Series memiliki:
Int64, Utf8, Float64, Boolean, dll.).Karena tipe data ditegakkan secara ketat, Series di Polars cenderung lebih cepat dan lebih dapat diprediksi daripada list Python.
Contoh:
import polars as pl
# Create a Series of integers
s = pl.Series("numbers", [1, 2, 3, 4, 5])
print(s)Keluaran:
shape: (5,)
Series: 'numbers' [i64]
[
1
2
3
4
5
]
DataFrame adalah struktur dua dimensi yang mengorganisir banyak Series di bawah sebuah skema. Secara konseptual, ini seperti tabel di SQL atau Excel. Baris merepresentasikan rekaman, dan kolom merepresentasikan field.
Contoh:
df = pl.DataFrame({
"id": [1, 2, 3],
"name": ["Alice", "Bob", "Charlie"],
"age": [25, 30, 35]
})
print(df)Keluaran:
shape: (3, 3)
┌─────┬─────────┬─────┐
│ id │ name │ age │
│ --- │ --- │ --- │
│ i64 │ str │ i64 │
├─────┼─────────┼─────┤
│ 1 │ Alice │ 25 │
│ 2 │ Bob │ 30 │
│ 3 │ Charlie │ 35 │
└─────┴─────────┴─────┘Setiap kolom adalah Series, dan DataFrame menegakkan skemanya.
Salah satu kekuatan Polars adalah penegakan skema yang ketat. Setiap kolom memiliki tipe data tetap, dan Polars memastikan semua operasi menghormatinya. Ini mencegah bug halus yang muncul pada operasi bertipe dinamis.
Misalnya, Anda tidak dapat secara tak sengaja menambahkan kolom string ke kolom integer tanpa konversi eksplisit.
Contoh:
df = df.with_columns(
(pl.col("age") + 5).alias("age_plus_5")
)
print(df)Di sini, age adalah i64, dan hasilnya tetap integer. Jika Anda mencoba menambahkan kolom string, Polars akan memunculkan error alih-alih diam-diam gagal.
Data dunia nyata sering memiliki nilai hilang, dan Polars menyediakan alat yang jelas untuk menanganinya:
fill_null(): Ganti null dengan nilai tertentu.drop_nulls(): Hapus baris yang mengandung null.is_null() / is_not_null(): Pengecekan boolean.Polars mengedepankan sistem ekspresi, di mana operasi didefinisikan sebagai transformasi pada kolom alih-alih loop Python baris-per-baris.
Ekspresi ini tervektorisasi, artinya beroperasi pada seluruh kolom sekaligus, yang jauh lebih cepat.
Alih-alih melakukan loop manual, Polars membangun komputasi tervektorisasi yang cepat.
Polars menawarkan dua mode eksekusi:
Berikut contoh eksekusi eager:
df = pl.DataFrame({"x": [1, 2, 3]})
print(df.select(pl.col("x") * 2)) # eager: runs instantlyBerikut contoh eksekusi lazy:
lazy_df = pl.DataFrame({"x": [1, 2, 3]}).lazy()
result = lazy_df.select(pl.col("x") * 2).collect() # execute on collect()
print(result)Di sini, tidak ada yang dihitung hingga .collect() dipanggil. Dalam alur kerja besar, ini dapat menghasilkan peningkatan kinerja yang signifikan.
Selanjutnya, kita akan melihat cara melakukan beberapa operasi dasar yang digunakan di Polars pada dataset yang kita buat.
Polars dapat mengonsumsi data dari berbagai format file dan objek memori. Ini membuatnya fleksibel untuk diintegrasikan ke dalam pipeline data modern.
Berikut cara melakukannya untuk berbagai sumber:
Dari dataset CSV yang kita buat sebelumnya:
import polars as pl
df = pl.read_csv("transactions.csv")
print(df.head())Kita juga dapat membaca dataset dari Parquet jika diperlukan.
df_parquet = pl.read_parquet("transactions.parquet")Jika Anda memiliki file JSON, Anda dapat membacanya menggunakan kode berikut:
df_json = pl.read_json("transactions.json")
#For JSON Lines (NDJSON), use the following instead:
df_json = pl.read_ndjson("transactions.json")Berikut cara membaca dataset dari Arrow Table:
import pyarrow as pa
arrow_table = pa.table({
"transaction_id": [1, 2],
"customer_id": [5, 7],
"amount": [150.25, 300.75],
"transaction_date": ["2023-01-02", "2023-01-03"]
})
df_arrow = pl.from_arrow(arrow_table)Sekarang mari kita pilih kolom atau baris tertentu dari dataset kita.
Saat menggunakan Polars, operasi umum adalah memilih kolom yang ingin Anda kerjakan dan pertahankan.
Berikut caranya:
# Select only transaction_id and amount
df.select(["transaction_id", "amount"])Anda juga dapat memfilter baris berdasarkan kondisi yang Anda tetapkan, mirip dengan pandas.
# Get only high-value transactions above $1,000
high_value = df.filter(pl.col("amount") > 1000)
print(high_value)Menerapkan ekspresi di Polars melibatkan penggunaan objek polars.Expr dalam berbagai konteks untuk melakukan transformasi data.
Anda dapat membuatnya menggunakan pl.col(), atau pl.lit().
# Add a 10% discount column to simulate promotional pricing
df.select([
pl.col("transaction_id"),
pl.col("amount"),
(pl.col("amount") * 0.9).alias("discounted_amount")
])Kita dapat menganalisis pola pengeluaran per pelanggan menggunakan group_by.
# Total and average spend per customer
agg_df = df.group_by("customer_id").agg([
pl.sum("amount").alias("total_spent"),
pl.mean("amount").alias("avg_transaction")
])
print(agg_df)Contoh keluaran:
shape: (10, 3)
┌─────────────┬────────────┬───────────────┐
│ customer_id │ total_spent│ avg_transaction│
│ --- │ --- │ --- │
│ i64 │ f64 │ f64 │
├─────────────┼────────────┼───────────────┤
│ 1 │ 5230.12 │ 523.01 │
│ 2 │ 6120.45 │ 680.05 │
│ ... │ ... │ ... │
└─────────────┴────────────┴───────────────┘Dataset yang kita hasilkan tidak memiliki null secara default, tetapi mari kita simulasikan cara menanganinya.
Nilai hilang dapat menimbulkan masalah dalam analisis lanjutan dan visualisasi data. Anda perlu mengisi nilai yang hilang agar proses berjalan lancar.
Berikut cara mengisi nilai hilang:
# Imagine 'amount' has missing values, then replace with 0
df_filled = df.with_columns(
pl.col("amount").fill_null(0)
)Null dapat menimbulkan error jika tidak ditangani. Berikut cara menghapusnya:
df_no_nulls = df.drop_nulls()Tipe data mungkin salah format dalam sebuah dataset. Berikut cara mengonversinya menggunakan metode .cast:
# Ensure customer_id is treated as string instead of int
df_casted = df.with_columns(
pl.col("customer_id").cast(pl.Utf8)
)Polars memungkinkan method chaining untuk alur kerja yang lebih rapi. Metode chaining ini umum digunakan di SQL atau pemrograman R menggunakan paket tidyverse.
Contoh: Temukan pelanggan teratas di bulan Maret berdasarkan total pengeluaran
pipeline = (
df
.with_columns(pl.col("transaction_date").str.strptime(pl.Date, format="%Y-%m-%d"))
#.col("date_str").str.to_date(format="%Y-%m-%d")
.filter(pl.col("transaction_date").dt.month() == 3) # transactions in March
.group_by("customer_id")
.agg(pl.sum("amount").alias("march_spent"))
.sort("march_spent", descending=True)
)
print(pipeline)Pipeline ini:
Metode chaining ini memungkinkan analisis pipeline dilakukan tanpa menggunakan DataFrame perantara.
Di luar dasar-dasar, Polars unggul saat bekerja dengan dataset besar berkat mesin evaluasi lazy-nya. Model ini memungkinkan Polars membangun rencana kueri terlebih dahulu, mengoptimalkannya di balik layar, lalu mengeksekusi pipeline. Hasilnya adalah lonjakan besar dalam kinerja dan efisiensi, terutama dengan jutaan baris atau transformasi kompleks.
Secara default, Polars berjalan dalam mode eager. Artinya komputasi terjadi segera, mirip dengan pandas. Mode lazy, bagaimanapun, bekerja berbeda:
.collect().Berikut contoh mode lazy:
import polars as pl
# Load dataset in lazy mode
lazy_df = pl.scan_csv("transactions.csv")
# Build a transformation pipeline
pipeline = (
lazy_df
.filter(pl.col("amount") > 1000) # step 1: filter expensive transactions
.group_by("customer_id") # step 2: group by customer
.agg(pl.sum("amount").alias("total_spent")) # step 3: aggregate
)
# Nothing has run yet, computation happens only on collect()
result = pipeline.collect()
print(result)Polars mengoptimalkan kueri dengan menerapkan teknik pushdown:
amount > 1000, Polars menerapkan filter saat membaca CSV alih-alih setelah memuat semua baris.customer_id dan amount, Polars melewati pembacaan transaction_date sepenuhnya.Saat data terlalu besar untuk dimuat ke memori, Polars menawarkan eksekusi streaming. Alih-alih memuat semuanya sekaligus, Polars memproses data dalam batch, menjaga penggunaan memori tetap stabil.
Ini sangat berguna untuk file CSV atau Parquet multi-GB.
Contoh (mode streaming):
# Enable streaming execution for huge datasets
stream_result = (
lazy_df
.group_by("customer_id")
.agg(pl.sum("amount").alias("total_spent"))
.collect(streaming=True) # execute in streaming mode
)Dengan streaming=True, Polars menghindari pembuatan tabel perantara besar di memori, menjadikannya lebih skalabel daripada pandas untuk beban kerja besar.
.collect() dan Debugging Kueri LazyMetode .collect() adalah pemicu untuk mengeksekusi pipeline lazy. Sebelumnya, Anda dapat memeriksa dan men-debug rencana kueri dengan:
.describe_plan(): Menampilkan rencana logis..describe_optimized_plan(): Menampilkan rencana yang dioptimalkan setelah Polars menerapkan pushdown dan penyederhanaan.Polars dapat membantu meningkatkan kinerja dalam menjalankan pipeline analisis Anda.
Berikut beberapa praktik terbaik:
Analisis dunia nyata sering memerlukan penggabungan dataset. Polars menyediakan rangkaian lengkap operasi join dengan eksekusi yang dioptimalkan, sehingga mudah menggabungkan tabel besar sekalipun.
Polars mendukung semua jenis join utama:
Contoh: Menggabungkan transaksi dengan metadata pelanggan
# Create customer metadata DataFrame
customers = pl.DataFrame({
"customer_id": [1, 2, 3, 4, 5],
"customer_name": ["Alice", "Bob", "Charlie", "David", "Eva"]
})
# Inner join on customer_id
df_joined = df.join(customers, on="customer_id", how="inner")
print(df_joined.head())Polars lebih unggul dari Pandas dalam kedua aspek:
Fungsi window memungkinkan perhitungan dalam kelompok atau pada baris yang berurutan tanpa mereduksi hasil, mirip fungsi window di SQL.
Polars memungkinkan Anda menghitung statistik per pelanggan atau per periode waktu menggunakan konteks window.
Berikut beberapa contoh fungsi window yang dapat Anda gunakan di Polars:
Contoh: Total berjalan per pelanggan
df_window = df.with_columns( pl.col("amount") .sort_by("transaction_date") .cum_sum() .over("customer_id") .alias("running_total") )
print(df_window.head())Fungsi rolling beroperasi pada jendela geser baris atau waktu.
Contoh: jumlah transaksi rolling 7 hari
df = df.with_columns(pl.col("transaction_date").str.strptime(pl.Date, format="%Y-%m-%d")
rolling = (
df.group_by_rolling("transaction_date", period="7d")
.agg(pl.sum("amount").alias("rolling_7d_sum"))
)
print(rolling.head())Expanding window (kumulatif) dan window berpusat juga didukung dengan menyesuaikan parameter.
Anda dapat menggunakan fungsi ranking dan agregasi kustom di dalam window.
Contoh: Memeringkat transaksi per pelanggan berdasarkan jumlah
ranked = df.with_columns(
pl.col("amount").rank("dense", descending=True).over("customer_id").alias("rank")
)
print(ranked.head())Ini menghasilkan peringkat (1 = tertinggi) untuk pengeluaran setiap pelanggan.
Fungsi window memungkinkan perhitungan kontekstual:
print(
df.group_by("customer_id").agg(pl.col("amount").cum_sum().alias("cumulative_spent"))
)Bagi analis yang terbiasa dengan SQL, Polars menyediakan konteks SQL sehingga Anda dapat mengkueri DataFrame langsung dengan sintaks SQL sambil tetap memanfaatkan kecepatan Polars.
Untuk memulai, Anda harus mendaftarkan DataFrame sebelum menjalankan SQL.
from polars import SQLContext
ctx = SQLContext()
ctx.register("transactions", df)Mari kita lihat contoh cara menjalankan kueri SQL dalam Python menggunakan Polars.
Contoh: Kueri total pengeluaran per pelanggan dalam SQL
result = ctx.execute("""
SELECT customer_id, SUM(amount) AS total_spent
FROM transactions
GROUP BY customer_id
ORDER BY total_spent DESC
""").collect()
print(result)Anda dapat mencampur SQL dan ekspresi:
sql_result = ctx.execute("SELECT * FROM transactions WHERE amount > 1500")
df_sql = sql_result.collect()
# Continue with Polars expressions
df_sql = df_sql.with_columns((pl.col("amount") * 0.95).alias("discounted"))Ini berguna untuk tim yang bertransisi dari alat berbasis SQL.
Polars dirancang bukan sebagai pulau yang berdiri sendiri, melainkan sebagai pustaka DataFrame berkinerja tinggi yang selaras dengan ekosistem data Python yang lebih luas. Interoperabilitas ini memastikan analis dan engineer dapat mengadopsi Polars secara bertahap sambil tetap memanfaatkan alat yang ada.
Berikut beberapa area integrasi:
Terakhir, mari kita lihat beberapa contoh penggunaan Polars:
df = df.with_columns([
pl.col("transaction_date").str.strptime(pl.Date, "%Y-%m-%d").alias("txn_date"),
pl.col("amount").fill_null(strategy="mean")
])result = (
pl.read_csv("transactions.csv")
.lazy()
.filter(pl.col("amount") > 1000)
.group_by("customer_id")
.agg(pl.sum("amount").alias("total_spent"))
.collect()
)Berikut contoh untuk rata-rata bergerak pada jumlah transaksi.
import polars as pl
# Load & parse dates
df = (
pl.read_csv("transactions.csv")
.with_columns(pl.col("transaction_date").str.strptime(pl.Date, "%Y-%m-%d"))
)
# (A) Overall: daily totals + 7-day rolling average
daily = (
df.sort("transaction_date")
.group_by_dynamic("transaction_date", every="1d")
.agg(pl.sum("amount").alias("daily_total"))
.sort("transaction_date")
.with_columns(
pl.col("daily_total").rolling_mean(window_size=7).alias("ma7")
)
)
# (B) Per-customer: daily totals + 7-day rolling average within each customer
daily_by_cust = (
df.sort("transaction_date")
.group_by_dynamic(index_column="transaction_date", every="1d", by="customer_id")
.agg(pl.sum("amount").alias("daily_total"))
.sort(["customer_id", "transaction_date"])
.with_columns(
pl.col("daily_total")
.rolling_mean(window_size=7)
.over("customer_id")
.alias("ma7_per_customer")
)
)
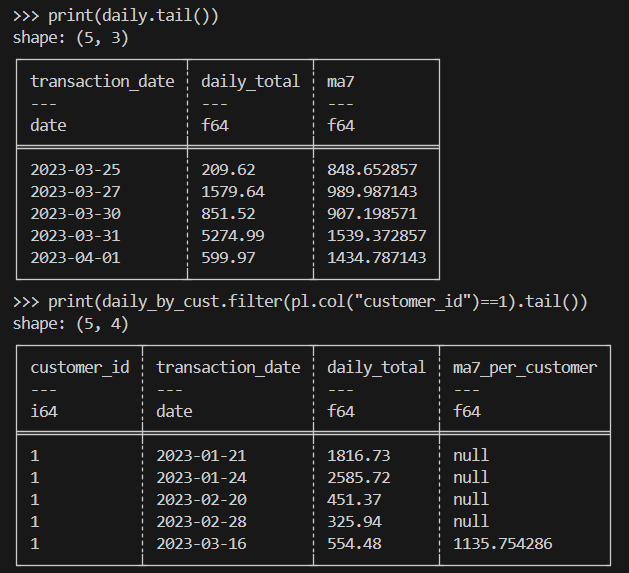
print(daily.tail())
print(daily_by_cust.filter(pl.col("customer_id")==1).tail())Berikut hasil yang diharapkan:
Saat melakukan komputasi ilmiah, Anda perlu menangani jutaan baris data eksperimen atau simulasi yang mirip transaksi secara efisien.
Berikut implementasi contoh:
import polars as pl
# Assume a very large Parquet file with columns: id, value, ts (UTC)
# Use lazy scan_* to avoid loading into memory up-front
lazy = (
pl.scan_parquet("experiments.parquet") # or: pl.scan_csv("experiments.csv")
.filter(pl.col("value") > 0) # predicate pushdown
.select(["id", "value", "ts"]) # projection pushdown
.with_columns(
# Example transformations: standardization & bucketize timestamps by hour
((pl.col("value") - pl.col("value").mean()) / pl.col("value").std())
.alias("z_value"),
pl.col("ts").dt.truncate("1h").alias("ts_hour")
)
.group_by(["id", "ts_hour"])
.agg([
pl.len().alias("n"),
pl.mean("z_value").alias("z_mean"),
pl.std("z_value").alias("z_std")
])
.sort(["id", "ts_hour"])
)
# Execute in streaming mode to keep memory usage low
result = lazy.collect(streaming=True)
# Optionally write out partitioned Parquet for downstream analysis
result.write_parquet("experiments_hourly_stats.parquet")
print(result.head())Python Polars menghadirkan pustaka DataFrame modern dan berkinerja tinggi yang mengatasi banyak keterbatasan pandas. Sementara pandas tetap populer untuk analisis ad hoc yang lebih kecil, Polars semakin menjadi alat pilihan untuk pemrosesan data yang skalabel, efisien, dan andal di Python.
Ingin belajar lebih jauh tentang Polars? Anda akan menyukai kursus Introduction to Polars kami atau artikel Introduction to Polars kami. Artikel Polars Engine kami juga mungkin menarik bagi Anda.
Kursus Teratas DataCamp
Program
Kursus
Kursus
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
