Programma
Fondamenti di dati in Python
28 h
Nel mondo dell’analisi dei dati, pandas è da tempo la scelta predefinita dei professionisti dei dati per gestire i dati tabellari in Python.
Tuttavia, man mano che i dataset crescono in dimensioni e complessità, pandas può incontrare colli di bottiglia nelle prestazioni, uso limitato del multi-core e vincoli di memoria.
Qui entra in gioco Polars come alternativa moderna. Polars è una libreria DataFrame scritta in Rust che offre prestazioni fulminee, gestione efficiente della memoria e una filosofia di design focalizzata sulla scalabilità.
In questo tutorial, vedremo cos’è Polars e come eseguire alcune operazioni di base con Polars in Python. Se cerchi un’esperienza pratica, ti consiglio di dare un’occhiata al corso Introduction to Polars.
Polars offre un set di funzionalità uniche che lo distinguono da pandas:
Polars supporta un’ampia gamma di tipi di dato oltre alle basi:
Int32, Int64, Float32, Float64.true/false.Date, Datetime, Duration, Time.List e Struct, utili per dati in stile JSON.Essendo l’alternativa più nuova e moderna a pandas, Polars offre diversi vantaggi:
Vediamo ora come iniziare a usare Polars in Python.
Prima di usare Polars, devi configurare correttamente l’ambiente.
Polars supporta Windows, macOS e Linux. Può essere installato in ambienti virtuali, nel Python di sistema o tramite workflow containerizzati (Docker).
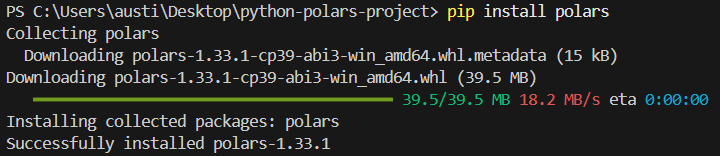
Per installare la libreria polars in Python, esegui il seguente comando nel terminale.
pip install polarsDovresti vedere il seguente messaggio di installazione:
In alternativa, puoi installare la libreria nell’ambiente conda se è quello con cui stai lavorando.
conda install -c conda-forge polarsPer verificare che l’installazione sia andata a buon fine, scrivi il seguente semplice script:
import polars as pl
print(pl.__version__)Polars ti permette di ottimizzare come viene eseguito e come visualizza gli output impostando variabili d’ambiente prima di avviare la sessione Python. Per esempio:
POLARS_MAX_THREADS: limita il numero di thread.POLARS_FMT_MAX_COLS: controlla il numero di colonne stampate.POLARS_FMT_TABLE_WIDTH: regola la larghezza di visualizzazione dei DataFrame.Ecco un esempio di come imposteresti queste variabili in una shell prima di eseguire Python:
export POLARS_MAX_THREADS=8
export POLARS_FMT_MAX_COLS=20Prima di approfondire le funzionalità di Polars, è utile avere un dataset da usare in modo coerente per tutto il tutorial. Possiamo generare un semplice file CSV usando il modulo csv integrato di Python o pandas.
Ecco un esempio che crea un file transactions.csv con dati sintetici:
import csv
import random
from datetime import datetime, timedelta
# Define column names
columns = ["transaction_id", "customer_id", "amount", "transaction_date"]
# Generate synthetic rows
rows = []
start_date = datetime(2023, 1, 1)
for i in range(1, 101):
customer_id = random.randint(1, 10)
amount = round(random.uniform(10, 2000), 2)
date = start_date + timedelta(days=random.randint(0, 90))
rows.append([i, customer_id, amount, date.strftime("%Y-%m-%d")])
# Write to CSV
with open("transactions.csv", "w", newline="") as f:
writer = csv.writer(f)
writer.writerow(columns)
writer.writerows(rows)Questo script crea un dataset di 100 transazioni con importi, ID cliente e date di transazione casuali. Puoi adattare intervalli e dimensioni in base alle tue esigenze.
Salva questo script, eseguilo una volta e avrai un file CSV da usare negli esempi in tutto l’articolo.
Polars si basa su due astrazioni principali: Series e DataFrame.
Insieme forniscono un modo strutturato ed efficiente di lavorare con i dati, simile nello spirito a pandas, ma ottimizzato con il backend in Rust di Polars. Vediamo i concetti principali.
Una Series in Polars è un array monodimensionale, simile a una colonna in un foglio di calcolo o in una tabella di database. Ogni Series ha:
Int64, Utf8, Float64, Boolean, ecc.).Poiché il tipo di dato è applicato in modo rigoroso, le Series in Polars tendono a essere più veloci e prevedibili delle liste Python.
Esempio:
import polars as pl
# Create a Series of integers
s = pl.Series("numbers", [1, 2, 3, 4, 5])
print(s)Output:
shape: (5,)
Series: 'numbers' [i64]
[
1
2
3
4
5
]
Un DataFrame è una struttura bidimensionale che organizza più Series sotto uno schema. Concettualmente, è come una tabella in SQL o Excel. Le righe rappresentano i record e le colonne rappresentano i campi.
Esempio:
df = pl.DataFrame({
"id": [1, 2, 3],
"name": ["Alice", "Bob", "Charlie"],
"age": [25, 30, 35]
})
print(df)Output:
shape: (3, 3)
┌─────┬─────────┬─────┐
│ id │ name │ age │
│ --- │ --- │ --- │
│ i64 │ str │ i64 │
├─────┼─────────┼─────┤
│ 1 │ Alice │ 25 │
│ 2 │ Bob │ 30 │
│ 3 │ Charlie │ 35 │
└─────┴─────────┴─────┘Ogni colonna è una Series e il DataFrame applica il suo schema.
Uno dei punti di forza di Polars è l’applicazione rigorosa dello schema. Ogni colonna ha un tipo di dato fisso e Polars garantisce che tutte le operazioni lo rispettino. Questo evita bug sottili che emergono con operazioni a tipizzazione dinamica.
Per esempio, non puoi sommare per errore una colonna di stringhe a una colonna di interi senza una conversione esplicita.
Esempio:
df = df.with_columns(
(pl.col("age") + 5).alias("age_plus_5")
)
print(df)Qui, age è i64 e il risultato resta un intero. Se provassi ad aggiungere una colonna di stringhe, Polars solleverebbe un errore invece di fallire in silenzio.
I dati reali spesso hanno valori mancanti e Polars offre strumenti chiari per gestirli:
fill_null(): sostituisce i null con un valore dato.drop_nulls(): rimuove le righe contenenti null.is_null() / is_not_null(): controlli booleani.Polars promuove un sistema di espressioni, in cui le operazioni sono definite come trasformazioni su colonne anziché cicli Python riga per riga.
Queste espressioni sono vettorializzate, cioè operano su intere colonne in una volta sola, risultando molto più veloci.
Invece di ciclare manualmente, Polars costruisce un’elaborazione vettoriale veloce.
Polars offre due modalità di esecuzione:
Ecco un esempio di esecuzione eager:
df = pl.DataFrame({"x": [1, 2, 3]})
print(df.select(pl.col("x") * 2)) # eager: runs instantlyEcco un esempio di esecuzione lazy:
lazy_df = pl.DataFrame({"x": [1, 2, 3]}).lazy()
result = lazy_df.select(pl.col("x") * 2).collect() # execute on collect()
print(result)Qui non viene calcolato nulla finché non si chiama .collect(). Nei workflow di grandi dimensioni, questo può portare a notevoli miglioramenti di prestazioni.
Ora vedremo come eseguire alcune operazioni di base usate in Polars sul dataset che abbiamo creato.
Polars può acquisire dati da più formati di file e oggetti in memoria. Questo lo rende flessibile da integrare nelle pipeline dati moderne.
Ecco come puoi farlo per diverse fonti:
Dal dataset CSV che abbiamo creato prima:
import polars as pl
df = pl.read_csv("transactions.csv")
print(df.head())Possiamo anche leggere il dataset da Parquet se necessario.
df_parquet = pl.read_parquet("transactions.parquet")Se invece hai un file JSON, puoi leggerlo con questo codice:
df_json = pl.read_json("transactions.json")
#For JSON Lines (NDJSON), use the following instead:
df_json = pl.read_ndjson("transactions.json")Ecco come leggere dataset da una Arrow Table:
import pyarrow as pa
arrow_table = pa.table({
"transaction_id": [1, 2],
"customer_id": [5, 7],
"amount": [150.25, 300.75],
"transaction_date": ["2023-01-02", "2023-01-03"]
})
df_arrow = pl.from_arrow(arrow_table)Ora selezioniamo colonne o righe specifiche dal nostro dataset.
Con Polars, un’operazione comune è selezionare le colonne su cui vuoi lavorare e mantenere.
Ecco come puoi farlo:
# Select only transaction_id and amount
df.select(["transaction_id", "amount"])Puoi anche filtrare le righe in base a condizioni che imposti, in modo simile a pandas.
# Get only high-value transactions above $1,000
high_value = df.filter(pl.col("amount") > 1000)
print(high_value)Applicare espressioni in Polars significa usare l’oggetto polars.Expr in vari contesti per eseguire trasformazioni sui dati.
Puoi crearle usando pl.col() o pl.lit().
# Add a 10% discount column to simulate promotional pricing
df.select([
pl.col("transaction_id"),
pl.col("amount"),
(pl.col("amount") * 0.9).alias("discounted_amount")
])Possiamo analizzare i modelli di spesa per cliente usando group_by.
# Total and average spend per customer
agg_df = df.group_by("customer_id").agg([
pl.sum("amount").alias("total_spent"),
pl.mean("amount").alias("avg_transaction")
])
print(agg_df)Output di esempio:
shape: (10, 3)
┌─────────────┬────────────┬───────────────┐
│ customer_id │ total_spent│ avg_transaction│
│ --- │ --- │ --- │
│ i64 │ f64 │ f64 │
├─────────────┼────────────┼───────────────┤
│ 1 │ 5230.12 │ 523.01 │
│ 2 │ 6120.45 │ 680.05 │
│ ... │ ... │ ... │
└─────────────┴────────────┴───────────────┘Il nostro dataset generato non ha null di default, ma simuliamo come li gestiremmo.
I valori mancanti possono creare problemi nelle analisi successive e nella visualizzazione dei dati. Dovrai riempire eventuali valori mancanti per assicurare che tutto fili liscio.
Ecco come puoi riempire i valori mancanti:
# Imagine 'amount' has missing values, then replace with 0
df_filled = df.with_columns(
pl.col("amount").fill_null(0)
)I null possono causare errori se non gestiti. Ecco come eliminarli:
df_no_nulls = df.drop_nulls()I tipi di dato potrebbero essere formattati in modo errato in un dataset. Ecco come puoi convertirli usando il metodo .cast:
# Ensure customer_id is treated as string instead of int
df_casted = df.with_columns(
pl.col("customer_id").cast(pl.Utf8)
)Polars permette il method chaining per workflow più puliti. Questo metodo è comunemente usato in SQL o in R con il pacchetto tidyverse.
Esempio: trova i migliori clienti a marzo per spesa totale
pipeline = (
df
.with_columns(pl.col("transaction_date").str.strptime(pl.Date, format="%Y-%m-%d"))
#.col("date_str").str.to_date(format="%Y-%m-%d")
.filter(pl.col("transaction_date").dt.month() == 3) # transactions in March
.group_by("customer_id")
.agg(pl.sum("amount").alias("march_spent"))
.sort("march_spent", descending=True)
)
print(pipeline)Questa pipeline:
Questo metodo di chaining permette di eseguire un’analisi a pipeline senza usare DataFrame intermedi.
Oltre alle basi, Polars eccelle con dataset di grandi dimensioni grazie al suo motore di valutazione lazy. Questo modello consente a Polars di costruire prima un piano di query, ottimizzarlo sotto il cofano e solo poi eseguire la pipeline. Il risultato è un enorme aumento di prestazioni ed efficienza, specialmente con milioni di righe o trasformazioni complesse.
Per impostazione predefinita, Polars funziona in modalità eager. Ciò significa che i calcoli avvengono immediatamente, in modo simile a pandas. La modalità lazy, invece, funziona diversamente:
.collect().Ecco un esempio in modalità lazy:
import polars as pl
# Load dataset in lazy mode
lazy_df = pl.scan_csv("transactions.csv")
# Build a transformation pipeline
pipeline = (
lazy_df
.filter(pl.col("amount") > 1000) # step 1: filter expensive transactions
.group_by("customer_id") # step 2: group by customer
.agg(pl.sum("amount").alias("total_spent")) # step 3: aggregate
)
# Nothing has run yet, computation happens only on collect()
result = pipeline.collect()
print(result)Polars ottimizza le query applicando tecniche di pushdown:
amount > 1000, Polars applica quel filtro durante la lettura del CSV invece che dopo aver caricato tutte le righe.customer_id e amount, Polars evita di leggere completamente transaction_date.Quando i dati sono troppo grandi per entrare in memoria, Polars offre l’esecuzione in streaming. Invece di caricare tutto in una volta, Polars elabora i dati in batch, mantenendo stabile l’uso di memoria.
Questo è particolarmente utile per file CSV o Parquet di molti GB.
Esempio (modalità streaming):
# Enable streaming execution for huge datasets
stream_result = (
lazy_df
.group_by("customer_id")
.agg(pl.sum("amount").alias("total_spent"))
.collect(streaming=True) # execute in streaming mode
)Con streaming=True, Polars evita di costruire enormi tabelle intermedie in memoria, risultando più scalabile di pandas per carichi di lavoro grandi.
.collect() e debug delle query lazyIl metodo .collect() è il trigger per eseguire una pipeline lazy. Prima, puoi ispezionare e fare debug del piano di query con:
.describe_plan(): mostra il piano logico..describe_optimized_plan(): mostra il piano ottimizzato dopo che Polars applica pushdown e semplificazioni.Polars può aiutarti a migliorare le prestazioni nell’esecuzione delle tue pipeline di analisi.
Ecco alcune best practice:
Nell’analisi reale spesso serve combinare dataset. Polars offre un set completo di operazioni di join con esecuzione ottimizzata, rendendo semplice unire anche tabelle grandi.
Polars supporta tutti i principali tipi di join:
Esempio: unire le transazioni con i metadati dei clienti
# Create customer metadata DataFrame
customers = pl.DataFrame({
"customer_id": [1, 2, 3, 4, 5],
"customer_name": ["Alice", "Bob", "Charlie", "David", "Eva"]
})
# Inner join on customer_id
df_joined = df.join(customers, on="customer_id", how="inner")
print(df_joined.head())Polars è superiore a pandas in entrambi gli ambiti:
Le funzioni finestra consentono calcoli all’interno di gruppi o su righe ordinate, senza collassare i risultati, in modo simile alle window function di SQL.
Polars ti permette di calcolare statistiche per cliente o per periodo di tempo usando contesti finestra.
Ecco alcuni esempi di funzioni finestra che puoi usare in Polars:
Esempio: totali progressivi per cliente
df_window = df.with_columns( pl.col("amount") .sort_by("transaction_date") .cum_sum() .over("customer_id") .alias("running_total") )
print(df_window.head())Le funzioni rolling operano su una finestra scorrevole di righe o tempo.
Esempio: somma rolling su 7 giorni delle transazioni
df = df.with_columns(pl.col("transaction_date").str.strptime(pl.Date, format="%Y-%m-%d")
rolling = (
df.group_by_rolling("transaction_date", period="7d")
.agg(pl.sum("amount").alias("rolling_7d_sum"))
)
print(rolling.head())Finestra espandente (cumulativa) e finestre centrate sono anch’esse supportate regolando i parametri.
Puoi usare funzioni di ranking e aggregazioni personalizzate all’interno di finestre.
Esempio: classifica le transazioni per cliente in base all’importo
ranked = df.with_columns(
pl.col("amount").rank("dense", descending=True).over("customer_id").alias("rank")
)
print(ranked.head())Questo produce classifiche (1 = più alto) per la spesa di ciascun cliente.
Le funzioni finestra consentono calcoli contestuali:
print(
df.group_by("customer_id").agg(pl.col("amount").cum_sum().alias("cumulative_spent"))
)Per gli analisti abituati a SQL, Polars fornisce un contesto SQL per interrogare direttamente i DataFrame con sintassi SQL, sfruttando al contempo la velocità di Polars.
Per iniziare, devi registrare un DataFrame prima di eseguire SQL.
from polars import SQLContext
ctx = SQLContext()
ctx.register("transactions", df)Vediamo un esempio di come eseguire una query SQL in Python usando Polars.
Esempio: query della spesa totale per cliente in SQL
result = ctx.execute("""
SELECT customer_id, SUM(amount) AS total_spent
FROM transactions
GROUP BY customer_id
ORDER BY total_spent DESC
""").collect()
print(result)Puoi mescolare SQL ed espressioni:
sql_result = ctx.execute("SELECT * FROM transactions WHERE amount > 1500")
df_sql = sql_result.collect()
# Continue with Polars expressions
df_sql = df_sql.with_columns((pl.col("amount") * 0.95).alias("discounted"))Questo è utile per team che stanno passando da strumenti basati su SQL.
Polars non è pensato come un’isola a sé stante, ma come una libreria DataFrame ad alte prestazioni che si integra bene con il più ampio ecosistema dei dati in Python. Questa interoperabilità consente ad analisti e ingegneri di adottare Polars in modo graduale continuando a sfruttare gli strumenti esistenti.
Ecco alcune aree di integrazione:
Infine, diamo un’occhiata rapida ad alcuni esempi di utilizzo di Polars:
df = df.with_columns([
pl.col("transaction_date").str.strptime(pl.Date, "%Y-%m-%d").alias("txn_date"),
pl.col("amount").fill_null(strategy="mean")
])result = (
pl.read_csv("transactions.csv")
.lazy()
.filter(pl.col("amount") > 1000)
.group_by("customer_id")
.agg(pl.sum("amount").alias("total_spent"))
.collect()
)Ecco un esempio per le medie mobili degli importi di transazione.
import polars as pl
# Load & parse dates
df = (
pl.read_csv("transactions.csv")
.with_columns(pl.col("transaction_date").str.strptime(pl.Date, "%Y-%m-%d"))
)
# (A) Overall: daily totals + 7-day rolling average
daily = (
df.sort("transaction_date")
.group_by_dynamic("transaction_date", every="1d")
.agg(pl.sum("amount").alias("daily_total"))
.sort("transaction_date")
.with_columns(
pl.col("daily_total").rolling_mean(window_size=7).alias("ma7")
)
)
# (B) Per-customer: daily totals + 7-day rolling average within each customer
daily_by_cust = (
df.sort("transaction_date")
.group_by_dynamic(index_column="transaction_date", every="1d", by="customer_id")
.agg(pl.sum("amount").alias("daily_total"))
.sort(["customer_id", "transaction_date"])
.with_columns(
pl.col("daily_total")
.rolling_mean(window_size=7)
.over("customer_id")
.alias("ma7_per_customer")
)
)
print(daily.tail())
print(daily_by_cust.filter(pl.col("customer_id")==1).tail())Ecco il risultato atteso:
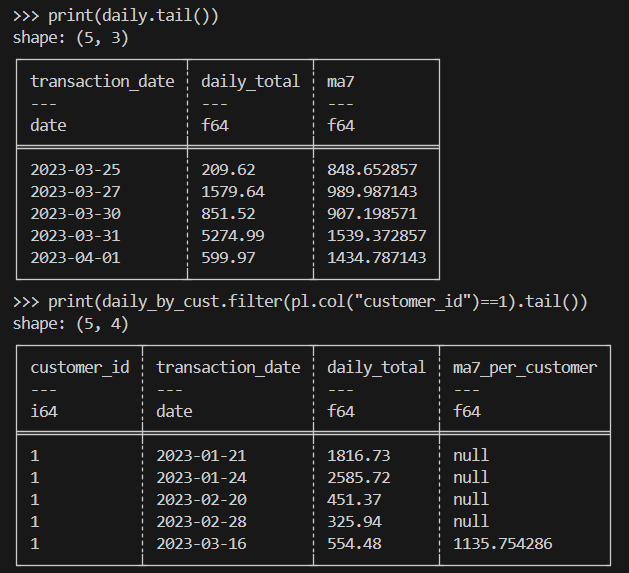
Nel calcolo scientifico, dovrai gestire in modo efficiente milioni di righe di dati sperimentali o simulati simili a transazioni.
Ecco un’implementazione di esempio:
import polars as pl
# Assume a very large Parquet file with columns: id, value, ts (UTC)
# Use lazy scan_* to avoid loading into memory up-front
lazy = (
pl.scan_parquet("experiments.parquet") # or: pl.scan_csv("experiments.csv")
.filter(pl.col("value") > 0) # predicate pushdown
.select(["id", "value", "ts"]) # projection pushdown
.with_columns(
# Example transformations: standardization & bucketize timestamps by hour
((pl.col("value") - pl.col("value").mean()) / pl.col("value").std())
.alias("z_value"),
pl.col("ts").dt.truncate("1h").alias("ts_hour")
)
.group_by(["id", "ts_hour"])
.agg([
pl.len().alias("n"),
pl.mean("z_value").alias("z_mean"),
pl.std("z_value").alias("z_std")
])
.sort(["id", "ts_hour"])
)
# Execute in streaming mode to keep memory usage low
result = lazy.collect(streaming=True)
# Optionally write out partitioned Parquet for downstream analysis
result.write_parquet("experiments_hourly_stats.parquet")
print(result.head())Python Polars offre una libreria DataFrame moderna e ad alte prestazioni che supera molte delle limitazioni di pandas. Sebbene pandas resti popolare per analisi più piccole e ad hoc, Polars è sempre più lo strumento di riferimento per un’elaborazione dati scalabile, efficiente e affidabile in Python.
Vuoi saperne di più su Polars? Ti piaceranno il nostro corso Introduction to Polars o il nostro articolo Introduction to Polars. Potrebbe interessarti anche il nostro articolo sul Polars Engine.
I migliori corsi DataCamp
Programma
Corso
Corso
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min

