Program
Python Veri Temelleri
28 sa
Veri analizi dünyasında, pandas uzun zamandır Python’da tablolu verileri işlemek için veri profesyonellerinin varsayılan tercihi olmuştur.
Ancak veri kümeleri boyut ve karmaşıklık olarak büyüdükçe, pandas çok çekirdekli kullanımın sınırlı kalması, bellek kısıtları ve performans darboğazlarıyla karşılaşabilir.
İşte bu noktada Polars, modern bir alternatif olarak öne çıkar. Polars, Rust ile yazılmış bir DataFrame kütüphanesidir; son derece hızlı performans, verimli bellek yönetimi ve ölçeklenebilirliğe odaklı bir tasarım felsefesi sunar.
Bu eğitimde Polars’ın ne olduğunu ve Python’da bazı temel Polars işlemlerinin nasıl yapılacağını paylaşacağız. Uygulamalı deneyim arıyorsanız, Introduction to Polars kursuna göz atmanızı öneririm.
Polars’ı pandas’tan ayıran özgün özellikler şunlardır:
Polars, temel türlerin ötesinde geniş bir veri türü yelpazesini destekler:
Int32, Int64, Float32, Float64.true/false değerleri.Date, Datetime, Duration, Time.List ve Struct türleri.Pandas’a göre daha yeni ve modern bir alternatif olan Polars, çeşitli avantajlar sunar:
Şimdi, Python’da Polars’ı kendimiz nasıl kullanmaya başlayabileceğimize bakalım.
Polars’ı kullanmadan önce ortamı doğru şekilde yapılandırmanız gerekir.
Polars Windows, macOS ve Linux’ü destekler. Sanal ortamlara, sistem Python’una veya konteynerleştirilmiş iş akışlarıyla (Docker) kurulabilir.
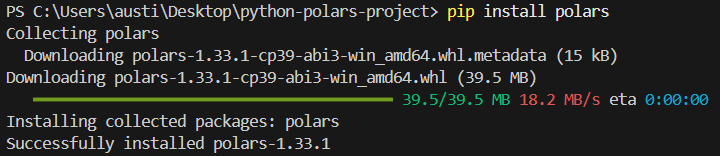
polars kütüphanesini Python’da kurmak için terminalde aşağıdaki komutu çalıştırın.
pip install polarsAşağıdaki kurulum mesajını görmelisiniz:
Alternatif olarak, kütüphaneyi çalıştığınız ortam conda ise conda ortamına kurabilirsiniz.
conda install -c conda-forge polarsKurulumun başarılı olup olmadığını kontrol etmek için aşağıdaki basit betiği yazın:
import polars as pl
print(pl.__version__)Polars, Python oturumunuza başlamadan önce ortam değişkenleri ayarlayarak nasıl çalışacağını ve çıktıların nasıl görüntüleneceğini ayarlamanıza olanak tanır. Örneğin:
POLARS_MAX_THREADS: İş parçacığı sayısını sınırlar.POLARS_FMT_MAX_COLS: Yazdırılan sütun sayısını kontrol eder.POLARS_FMT_TABLE_WIDTH: DataFrame görüntü genişliğini ayarlar.Python’ı çalıştırmadan önce bu değişkenlerin kabukta nasıl ayarlanacağına bir örnek:
export POLARS_MAX_THREADS=8
export POLARS_FMT_MAX_COLS=20Polars’ın özelliklerine dalmadan önce, bu eğitim boyunca tutarlı şekilde kullanabileceğimiz bir veri kümesine sahip olmak faydalı olacaktır. Python’un yerleşik csv modülü veya pandas ile basit bir CSV dosyası oluşturabiliriz.
Aşağıda sentetik verilerle transactions.csv dosyası oluşturan bir örnek yer alıyor:
import csv
import random
from datetime import datetime, timedelta
# Define column names
columns = ["transaction_id", "customer_id", "amount", "transaction_date"]
# Generate synthetic rows
rows = []
start_date = datetime(2023, 1, 1)
for i in range(1, 101):
customer_id = random.randint(1, 10)
amount = round(random.uniform(10, 2000), 2)
date = start_date + timedelta(days=random.randint(0, 90))
rows.append([i, customer_id, amount, date.strftime("%Y-%m-%d")])
# Write to CSV
with open("transactions.csv", "w", newline="") as f:
writer = csv.writer(f)
writer.writerow(columns)
writer.writerows(rows)Bu betik; rastgele tutarlarda, müşteri kimliklerinde ve işlem tarihlerinde 100 adet işlemden oluşan bir veri kümesi oluşturur. Aralıkları ve boyutu ihtiyacınıza göre ayarlayabilirsiniz.
Bu betiği kaydedip bir kez çalıştırın; makale boyunca kullanacağınız bir CSV dosyanız olacaktır.
Polars, iki temel soyutlama üzerine kuruludur: Series ve DataFrame.
Birlikte, pandas’a ruhen benzer fakat Polars’ın Rust destekli arka ucu ile optimize edilmiş, yapılandırılmış ve verimli bir çalışma şekli sunarlar. Başlıca kavramları inceleyelim.
Polars’ta Series, bir hesap tablosundaki veya veritabanı tablosundaki sütuna benzer tek boyutlu bir dizidir. Her Series’in:
Int64, Utf8, Float64, Boolean vb.).Veri türü sıkı biçimde uygulandığından, Polars’taki Series’ler Python listelerinden daha hızlı ve öngörülebilirdir.
Örnek:
import polars as pl
# Create a Series of integers
s = pl.Series("numbers", [1, 2, 3, 4, 5])
print(s)Çıktı:
shape: (5,)
Series: 'numbers' [i64]
[
1
2
3
4
5
]
DataFrame, birden fazla Series’i bir şema altında bir araya getiren iki boyutlu bir yapıdır. Kavramsal olarak SQL veya Excel’deki tablo gibidir. Satırlar kayıtları, sütunlar alanları temsil eder.
Örnek:
df = pl.DataFrame({
"id": [1, 2, 3],
"name": ["Alice", "Bob", "Charlie"],
"age": [25, 30, 35]
})
print(df)Çıktı:
shape: (3, 3)
┌─────┬─────────┬─────┐
│ id │ name │ age │
│ --- │ --- │ --- │
│ i64 │ str │ i64 │
├─────┼─────────┼─────┤
│ 1 │ Alice │ 25 │
│ 2 │ Bob │ 30 │
│ 3 │ Charlie │ 35 │
└─────┴─────────┴─────┘Her sütun bir Series’tir ve DataFrame kendi şemasını uygular.
Polars’ın güçlü yönlerinden biri sıkı şema uygulamasıdır. Her sütunun sabit bir veri türü vardır ve Polars tüm işlemlerin buna uymasını sağlar. Bu, dinamik tiplendirilmiş işlemlerde ortaya çıkan sinsi hataları önler.
Örneğin, açık dönüştürme olmadan bir metin sütununu bir tamsayı sütununa yanlışlıkla ekleyemezsiniz.
Örnek:
df = df.with_columns(
(pl.col("age") + 5).alias("age_plus_5")
)
print(df)Burada age i64 türündedir ve sonuç tamsayı olarak kalır. Bir metin sütununu eklemeye çalışırsanız, Polars gizlice başarısız olmak yerine hata verir.
Gerçek dünya verilerinde sıkça eksik değerler bulunur ve Polars bunları ele almak için net araçlar sunar:
fill_null(): Null değerleri verilen bir değerle değiştirir.drop_nulls(): Null içeren satırları kaldırır.is_null() / is_not_null(): Boolean kontroller.Polars, işlemlerin Python döngüleri yerine sütunlar üzerinde dönüşümler olarak tanımlandığı bir ifade sistemini teşvik eder.
Bu ifadeler vektörleştirilmiştir; yani işlemler tüm sütunlar üzerinde bir kerede çalışır ve bu çok daha hızlıdır.
Elle döngü yazmak yerine Polars, hızlı bir vektörleştirilmiş hesaplama kurar.
Polars iki yürütme modu sunar:
Eager yürütmeye bir örnek:
df = pl.DataFrame({"x": [1, 2, 3]})
print(df.select(pl.col("x") * 2)) # eager: runs instantlyLazy yürütmeye bir örnek:
lazy_df = pl.DataFrame({"x": [1, 2, 3]}).lazy()
result = lazy_df.select(pl.col("x") * 2).collect() # execute on collect()
print(result)Burada, .collect() çağrılana kadar hiçbir şey hesaplanmaz. Büyük iş akışlarında bu, çarpıcı performans iyileştirmelerine yol açabilir.
Şimdi, oluşturduğumuz veri kümesi üzerinde Polars’ta kullanılan bazı temel işlemleri gerçekleştirmeye bakalım.
Polars, birden fazla dosya biçiminden ve bellek nesnelerinden veri alabilir. Bu da modern veri boru hatlarına entegrasyon için esneklik sağlar.
Farklı kaynaklar için bunu şu şekilde yapabilirsiniz:
Daha önce oluşturduğumuz CSV veri kümesinden:
import polars as pl
df = pl.read_csv("transactions.csv")
print(df.head())Gerekirse veri kümesini Parquet’ten de okuyabiliriz.
df_parquet = pl.read_parquet("transactions.parquet")Bunun yerine bir JSON dosyanız varsa, şu kodla okuyabilirsiniz:
df_json = pl.read_json("transactions.json")
#For JSON Lines (NDJSON), use the following instead:
df_json = pl.read_ndjson("transactions.json")Arrow Table’dan veri kümelerini şu şekilde okursunuz:
import pyarrow as pa
arrow_table = pa.table({
"transaction_id": [1, 2],
"customer_id": [5, 7],
"amount": [150.25, 300.75],
"transaction_date": ["2023-01-02", "2023-01-03"]
})
df_arrow = pl.from_arrow(arrow_table)Şimdi veri kümemizden belirli sütunları veya satırları seçelim.
Polars kullanırken yaygın bir işlem, üzerinde çalışmak ve tutmak istediğiniz sütunları seçmektir.
Bunu şu şekilde yapabilirsiniz:
# Select only transaction_id and amount
df.select(["transaction_id", "amount"])Pandas’a benzer şekilde, belirlediğiniz koşullara göre satırları filtreleyebilirsiniz.
# Get only high-value transactions above $1,000
high_value = df.filter(pl.col("amount") > 1000)
print(high_value)Polars’ta ifadeler uygulamak, veri dönüşümlerini gerçekleştirmek için çeşitli bağlamlarda polars.Expr nesnesini kullanmayı içerir.
Bunları pl.col() veya pl.lit() ile oluşturabilirsiniz.
# Add a 10% discount column to simulate promotional pricing
df.select([
pl.col("transaction_id"),
pl.col("amount"),
(pl.col("amount") * 0.9).alias("discounted_amount")
])group_by kullanarak müşteriye göre harcama kalıplarını analiz edebiliriz.
# Total and average spend per customer
agg_df = df.group_by("customer_id").agg([
pl.sum("amount").alias("total_spent"),
pl.mean("amount").alias("avg_transaction")
])
print(agg_df)Örnek çıktı:
shape: (10, 3)
┌─────────────┬────────────┬───────────────┐
│ customer_id │ total_spent│ avg_transaction│
│ --- │ --- │ --- │
│ i64 │ f64 │ f64 │
├─────────────┼────────────┼───────────────┤
│ 1 │ 5230.12 │ 523.01 │
│ 2 │ 6120.45 │ 680.05 │
│ ... │ ... │ ... │
└─────────────┴────────────┴───────────────┘Oluşturduğumuz veri kümesinde varsayılan olarak null yok, ancak bunları nasıl ele alacağımızı simüle edelim.
Eksik değerler, sonraki analiz ve görselleştirmelerde sorunlara yol açabilir. Sorunsuz ilerlemek için eksik değerleri doldurmanız gerekir.
Eksik değerleri şu şekilde doldurabilirsiniz:
# Imagine 'amount' has missing values, then replace with 0
df_filled = df.with_columns(
pl.col("amount").fill_null(0)
)Null’lar ele alınmazsa hatalara neden olabilir. Şu şekilde kaldırabilirsiniz:
df_no_nulls = df.drop_nulls()Bir veri kümesinde veri türleri yanlış biçimlendirilmiş olabilir. .cast yöntemiyle şu şekilde dönüştürebilirsiniz:
# Ensure customer_id is treated as string instead of int
df_casted = df.with_columns(
pl.col("customer_id").cast(pl.Utf8)
)Polars, daha temiz iş akışları için yöntem zincirlemeye izin verir. Bu zincirleme yöntemi SQL veya R programlamada tidyverse paketiyle yaygın olarak kullanılır.
Örnek: Mart ayında en çok harcayan müşterileri bulun
pipeline = (
df
.with_columns(pl.col("transaction_date").str.strptime(pl.Date, format="%Y-%m-%d"))
#.col("date_str").str.to_date(format="%Y-%m-%d")
.filter(pl.col("transaction_date").dt.month() == 3) # transactions in March
.group_by("customer_id")
.agg(pl.sum("amount").alias("march_spent"))
.sort("march_spent", descending=True)
)
print(pipeline)Bu boru hattı:
Bu zincirleme yöntemi, ara DataFrame’ler kullanmadan bir boru hattı analizi yapmayı sağlar.
Temelin ötesinde, Polars büyük veri kümeleriyle çalışırken tembel değerlendirme motoru sayesinde parlıyor. Bu model Polars’ın önce bir sorgu planı oluşturmasına, bunu kaputun altında optimize etmesine ve yalnızca ardından boru hattını yürütmesine olanak tanır. Sonuç, özellikle milyonlarca satır veya karmaşık dönüşümler söz konusu olduğunda performans ve verimlilikte büyük bir artıştır.
Varsayılan olarak Polars eager modda çalışır. Bu, pandas’a benzer şekilde hesaplamaların anında gerçekleştiği anlamına gelir. Lazy mod ise farklı çalışır:
.collect() çağırdığınızda yürütülür.Lazy mod örneği:
import polars as pl
# Load dataset in lazy mode
lazy_df = pl.scan_csv("transactions.csv")
# Build a transformation pipeline
pipeline = (
lazy_df
.filter(pl.col("amount") > 1000) # step 1: filter expensive transactions
.group_by("customer_id") # step 2: group by customer
.agg(pl.sum("amount").alias("total_spent")) # step 3: aggregate
)
# Nothing has run yet, computation happens only on collect()
result = pipeline.collect()
print(result)Polars, pushdown tekniklerini uygulayarak sorguları optimize eder:
amount > 1000 ile filtrelerken, Polars bu filtreyi tüm satırlar yüklendikten sonra değil, CSV okunurken uygular.customer_id ve amount seçerseniz, Polars transaction_date sütununu tamamen okumayı atlar.Veri belleğe sığmayacak kadar büyük olduğunda, Polars akış yürütme sunar. Her şeyi bir kerede yüklemek yerine, Polars veriyi partiler halinde işler ve bellek kullanımını dengede tutar.
Bu, çok GB’lık CSV veya Parquet dosyaları için özellikle yararlıdır.
Örnek (akış modu):
# Enable streaming execution for huge datasets
stream_result = (
lazy_df
.group_by("customer_id")
.agg(pl.sum("amount").alias("total_spent"))
.collect(streaming=True) # execute in streaming mode
)streaming=True ile Polars, devasa ara tabloları bellekte kurmaktan kaçınır; bu da büyük iş yüklerinde pandas’tan daha ölçeklenebilir hale getirir.
.collect() ile Yürütme ve Lazy Sorguları Hata Ayıklama.collect() yöntemi, lazy bir boru hattını yürütmeyi tetikler. Bundan önce sorgu planını inceleyip hata ayıklamak için şunları kullanabilirsiniz:
.describe_plan(): Mantıksal planı gösterir..describe_optimized_plan(): Polars pushdown ve sadeleştirmeleri uyguladıktan sonra optimize edilmiş planı gösterir.Polars, analiz boru hatlarınızı çalıştırırken performansı artırmanıza yardımcı olabilir.
İşte bazı iyi uygulamalar:
Gerçek dünyadaki analizler sıklıkla veri kümelerini birleştirmeyi gerektirir. Polars, optimize edilmiş yürütme ile tam bir join işlemleri seti sunar; böylece büyük tabloları bile kolayca birleştirebilirsiniz.
Polars tüm başlıca join türlerini destekler:
Örnek: İşlemleri müşteri metaverileriyle birleştirme
# Create customer metadata DataFrame
customers = pl.DataFrame({
"customer_id": [1, 2, 3, 4, 5],
"customer_name": ["Alice", "Bob", "Charlie", "David", "Eva"]
})
# Inner join on customer_id
df_joined = df.join(customers, on="customer_id", how="inner")
print(df_joined.head())Polars her iki alanda da Pandas’tan üstündür:
Pencere fonksiyonları, SQL pencere fonksiyonlarına benzer şekilde, sonuçları daraltmadan gruplar içinde veya sıralı satırlarda hesaplamalar yapılmasını sağlar.
Polars, pencere bağlamları kullanarak müşteri başına veya zaman dönemine göre istatistikler hesaplamanıza olanak tanır.
Polars’ta kullanabileceğiniz bazı pencere fonksiyonları şunlardır:
Örnek: Müşteri bazında kümülatif toplamlar
df_window = df.with_columns( pl.col("amount") .sort_by("transaction_date") .cum_sum() .over("customer_id") .alias("running_total") )
print(df_window.head())Rolling fonksiyonlar, kayan bir satır veya zaman penceresi üzerinde çalışır.
Örnek: İşlemlerin 7 günlük yuvarlanan toplamı
df = df.with_columns(pl.col("transaction_date").str.strptime(pl.Date, format="%Y-%m-%d")
rolling = (
df.group_by_rolling("transaction_date", period="7d")
.agg(pl.sum("amount").alias("rolling_7d_sum"))
)
print(rolling.head())Parametreleri ayarlayarak genişleyen pencereler (kümülatif) ve merkez hizalı pencereler de desteklenir.
Pencereler içinde sıralama fonksiyonları ve özel toplamalar kullanabilirsiniz.
Örnek: İşlemleri müşteri bazında tutara göre sıralayın
ranked = df.with_columns(
pl.col("amount").rank("dense", descending=True).over("customer_id").alias("rank")
)
print(ranked.head())Bu, her müşterinin harcaması için (1 = en yüksek) sıralamalar üretir.
Pencere fonksiyonları bağlamsal hesaplamalara olanak tanır:
print(
df.group_by("customer_id").agg(pl.col("amount").cum_sum().alias("cumulative_spent"))
)SQL’e alışkın analistler için Polars, DataFrame’leri doğrudan SQL söz dizimiyle sorgulayabileceğiniz bir SQL bağlamı sağlar; böylece Polars’ın hızından yararlanmaya devam edersiniz.
Başlamak için, SQL çalıştırmadan önce bir DataFrame kaydetmeniz gerekir.
from polars import SQLContext
ctx = SQLContext()
ctx.register("transactions", df)Polars kullanarak Python içinde bir SQL sorgusunun nasıl çalıştırılacağına bir örnek bakalım.
Örnek: SQL ile müşteri başına toplam harcamayı sorgulayın
result = ctx.execute("""
SELECT customer_id, SUM(amount) AS total_spent
FROM transactions
GROUP BY customer_id
ORDER BY total_spent DESC
""").collect()
print(result)SQL ve ifadeleri karıştırabilirsiniz:
sql_result = ctx.execute("SELECT * FROM transactions WHERE amount > 1500")
df_sql = sql_result.collect()
# Continue with Polars expressions
df_sql = df_sql.with_columns((pl.col("amount") * 0.95).alias("discounted"))Bu, SQL tabanlı araçlardan geçen ekipler için kullanışlıdır.
Polars, başlı başına bir ada olarak değil, daha geniş Python veri ekosistemiyle iyi çalışan, yüksek performanslı bir DataFrame kütüphanesi olarak tasarlanmıştır. Bu birlikte çalışabilirlik, analist ve mühendislerin Polars’ı kademeli olarak benimserken mevcut araçlardan yararlanmaya devam etmesini sağlar.
İşte bazı entegrasyon alanları:
Son olarak, Polars’ın kullanımına dair bazı örneklere kısaca bakalım:
df = df.with_columns([
pl.col("transaction_date").str.strptime(pl.Date, "%Y-%m-%d").alias("txn_date"),
pl.col("amount").fill_null(strategy="mean")
])result = (
pl.read_csv("transactions.csv")
.lazy()
.filter(pl.col("amount") > 1000)
.group_by("customer_id")
.agg(pl.sum("amount").alias("total_spent"))
.collect()
)İşlem tutarları için hareketli ortalamalara bir örnek:
import polars as pl
# Load & parse dates
df = (
pl.read_csv("transactions.csv")
.with_columns(pl.col("transaction_date").str.strptime(pl.Date, "%Y-%m-%d"))
)
# (A) Overall: daily totals + 7-day rolling average
daily = (
df.sort("transaction_date")
.group_by_dynamic("transaction_date", every="1d")
.agg(pl.sum("amount").alias("daily_total"))
.sort("transaction_date")
.with_columns(
pl.col("daily_total").rolling_mean(window_size=7).alias("ma7")
)
)
# (B) Per-customer: daily totals + 7-day rolling average within each customer
daily_by_cust = (
df.sort("transaction_date")
.group_by_dynamic(index_column="transaction_date", every="1d", by="customer_id")
.agg(pl.sum("amount").alias("daily_total"))
.sort(["customer_id", "transaction_date"])
.with_columns(
pl.col("daily_total")
.rolling_mean(window_size=7)
.over("customer_id")
.alias("ma7_per_customer")
)
)
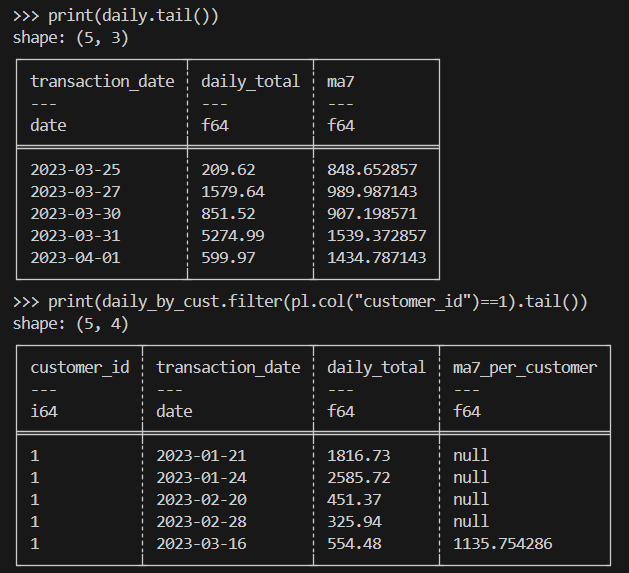
print(daily.tail())
print(daily_by_cust.filter(pl.col("customer_id")==1).tail())Beklenen sonuç şöyle:
Bilimsel hesaplama yaparken, deneysel veya benzetim tabanlı işlem benzeri milyonlarca satır veriyi verimli şekilde ele almanız gerekir.
Örnek bir uygulama:
import polars as pl
# Assume a very large Parquet file with columns: id, value, ts (UTC)
# Use lazy scan_* to avoid loading into memory up-front
lazy = (
pl.scan_parquet("experiments.parquet") # or: pl.scan_csv("experiments.csv")
.filter(pl.col("value") > 0) # predicate pushdown
.select(["id", "value", "ts"]) # projection pushdown
.with_columns(
# Example transformations: standardization & bucketize timestamps by hour
((pl.col("value") - pl.col("value").mean()) / pl.col("value").std())
.alias("z_value"),
pl.col("ts").dt.truncate("1h").alias("ts_hour")
)
.group_by(["id", "ts_hour"])
.agg([
pl.len().alias("n"),
pl.mean("z_value").alias("z_mean"),
pl.std("z_value").alias("z_std")
])
.sort(["id", "ts_hour"])
)
# Execute in streaming mode to keep memory usage low
result = lazy.collect(streaming=True)
# Optionally write out partitioned Parquet for downstream analysis
result.write_parquet("experiments_hourly_stats.parquet")
print(result.head())Python Polars, pandas’ın birçok sınırlamasını ele alan modern ve yüksek performanslı bir DataFrame kütüphanesi sunar. Pandas, daha küçük ve ad-hoc analizler için popülerliğini korurken, Polars giderek Python’da ölçeklenebilir, verimli ve güvenilir veri işleme için tercih edilen araç haline gelmektedir.
Polars hakkında daha fazla öğrenmek ister misiniz? Şunları seveceksiniz: Introduction to Polars kursu veya Introduction to Polars makalesi. Ayrıca Polars Engine makalemiz de ilginizi çekebilir.
En İyi DataCamp Kursları
Program
Kurs
Kurs
blog
Dario Radečić
15 dk.
blog
Abid Ali Awan
14 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
