Tracks
Kiến thức cơ bản về dữ liệu trong Python
28 giờ
Trong thế giới phân tích dữ liệu, pandas từ lâu đã là lựa chọn mặc định để xử lý dữ liệu dạng bảng trong Python đối với các chuyên gia dữ liệu.
Tuy nhiên, khi tập dữ liệu ngày càng lớn và phức tạp, pandas có thể gặp nút thắt cổ chai về hiệu năng, khả năng tận dụng đa lõi hạn chế và ràng buộc về bộ nhớ.
Đó là lúc Polars xuất hiện như một lựa chọn hiện đại thay thế. Polars là thư viện DataFrame được viết bằng Rust, cung cấp hiệu năng cực nhanh, quản lý bộ nhớ hiệu quả và triết lý thiết kế tập trung vào khả năng mở rộng.
Trong hướng dẫn này, chúng tôi sẽ giới thiệu Polars là gì và cách thực hiện một số thao tác cơ bản với Polars trong Python. Nếu bạn muốn thực hành trực tiếp, tôi khuyên bạn nên xem khóa học Introduction to Polars.
Polars mang đến một bộ tính năng độc đáo giúp nó khác biệt với pandas:
Polars hỗ trợ nhiều kiểu dữ liệu vượt ra ngoài những kiểu cơ bản:
Int32, Int64, Float32, Float64.true/false.Date, Datetime, Duration, Time.List và Struct, hữu ích cho dữ liệu giống JSON.Là lựa chọn mới hơn và hiện đại hơn so với pandas, Polars mang lại nhiều lợi ích:
Bây giờ, hãy xem cách bạn có thể bắt đầu sử dụng Polars trong Python.
Trước khi dùng Polars, bạn cần thiết lập môi trường cho đúng.
Polars hỗ trợ Windows, macOS và Linux. Có thể cài đặt trong môi trường ảo, Python hệ thống hoặc qua quy trình đóng gói (Docker).
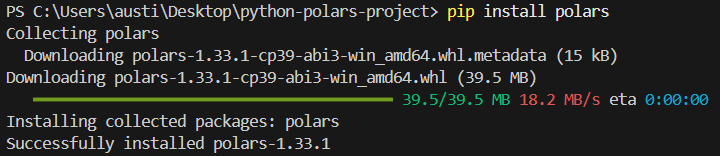
Để cài đặt thư viện polars trong Python, chạy lệnh sau trong terminal.
pip install polarsBạn sẽ thấy thông báo cài đặt như sau:
Ngoài ra, bạn có thể cài đặt thư viện trong môi trường conda nếu đó là môi trường bạn đang sử dụng.
conda install -c conda-forge polarsĐể kiểm tra cài đặt đã thành công hay chưa, viết đoạn script đơn giản sau:
import polars as pl
print(pl.__version__)Polars cho phép tinh chỉnh cách chạy và cách hiển thị đầu ra bằng cách đặt các biến môi trường trước khi bắt đầu phiên Python. Ví dụ:
POLARS_MAX_THREADS: Giới hạn số luồng.POLARS_FMT_MAX_COLS: Kiểm soát số cột được in ra.POLARS_FMT_TABLE_WIDTH: Điều chỉnh độ rộng hiển thị DataFrame.Dưới đây là ví dụ về cách đặt các biến này trong shell trước khi chạy Python:
export POLARS_MAX_THREADS=8
export POLARS_FMT_MAX_COLS=20Trước khi đi sâu vào các tính năng của Polars, sẽ hữu ích nếu có một tập dữ liệu để dùng nhất quán trong suốt hướng dẫn này. Chúng ta có thể tạo một tệp CSV đơn giản bằng mô-đun csv tích hợp của Python hoặc pandas.
Dưới đây là ví dụ tạo tệp transactions.csv với dữ liệu tổng hợp:
import csv
import random
from datetime import datetime, timedelta
# Define column names
columns = ["transaction_id", "customer_id", "amount", "transaction_date"]
# Generate synthetic rows
rows = []
start_date = datetime(2023, 1, 1)
for i in range(1, 101):
customer_id = random.randint(1, 10)
amount = round(random.uniform(10, 2000), 2)
date = start_date + timedelta(days=random.randint(0, 90))
rows.append([i, customer_id, amount, date.strftime("%Y-%m-%d")])
# Write to CSV
with open("transactions.csv", "w", newline="") as f:
writer = csv.writer(f)
writer.writerow(columns)
writer.writerows(rows)Script này tạo một tập dữ liệu gồm 100 giao dịch với số tiền, mã khách hàng và ngày giao dịch ngẫu nhiên. Bạn có thể điều chỉnh phạm vi và kích thước theo nhu cầu.
Lưu script này, chạy một lần và bạn sẽ có một tệp CSV để dùng trong các ví dụ xuyên suốt bài viết.
Polars được xây dựng dựa trên hai trừu tượng cốt lõi: Series và DataFrame.
Kết hợp lại, chúng cung cấp cách làm việc với dữ liệu có cấu trúc và hiệu quả, tương tự tinh thần của pandas nhưng được tối ưu bởi backend Rust của Polars. Hãy cùng phân tích các khái niệm chính.
Series trong Polars là một mảng một chiều, giống như một cột trong bảng tính hoặc bảng cơ sở dữ liệu. Mỗi Series có:
Int64, Utf8, Float64, Boolean, v.v.).Vì kiểu dữ liệu được áp đặt chặt chẽ, Series trong Polars thường nhanh hơn và dễ dự đoán hơn so với danh sách Python.
Ví dụ:
import polars as pl
# Create a Series of integers
s = pl.Series("numbers", [1, 2, 3, 4, 5])
print(s)Đầu ra:
shape: (5,)
Series: 'numbers' [i64]
[
1
2
3
4
5
]
DataFrame là cấu trúc hai chiều tổ chức nhiều Series theo một lược đồ. Về khái niệm, nó giống như một bảng trong SQL hoặc Excel. Hàng biểu diễn các bản ghi và cột biểu diễn các trường.
Ví dụ:
df = pl.DataFrame({
"id": [1, 2, 3],
"name": ["Alice", "Bob", "Charlie"],
"age": [25, 30, 35]
})
print(df)Đầu ra:
shape: (3, 3)
┌─────┬─────────┬─────┐
│ id │ name │ age │
│ --- │ --- │ --- │
│ i64 │ str │ i64 │
├─────┼─────────┼─────┤
│ 1 │ Alice │ 25 │
│ 2 │ Bob │ 30 │
│ 3 │ Charlie │ 35 │
└─────┴─────────┴─────┘Mỗi cột là một Series và DataFrame áp đặt lược đồ của nó.
Một điểm mạnh của Polars là áp đặt lược đồ nghiêm ngặt. Mỗi cột có kiểu dữ liệu cố định và Polars đảm bảo mọi thao tác đều tôn trọng kiểu đó. Điều này ngăn các lỗi tinh vi thường gặp trong các phép toán kiểu động.
Ví dụ, bạn không thể vô tình cộng một cột chuỗi với một cột số nguyên nếu không chuyển đổi rõ ràng.
Ví dụ:
df = df.with_columns(
(pl.col("age") + 5).alias("age_plus_5")
)
print(df)Ở đây, age là i64 và kết quả vẫn là số nguyên. Nếu bạn thử cộng một cột chuỗi, Polars sẽ báo lỗi thay vì âm thầm thất bại.
Dữ liệu thực tế thường có giá trị thiếu, và Polars cung cấp công cụ rõ ràng để xử lý chúng:
fill_null(): Thay null bằng một giá trị cho trước.drop_nulls(): Loại bỏ các hàng chứa null.is_null() / is_not_null(): Kiểm tra Boolean.Polars thúc đẩy hệ thống biểu thức, trong đó các thao tác được định nghĩa là biến đổi trên cột thay vì các vòng lặp Python theo hàng.
Các biểu thức này được vector hóa, nghĩa là chúng hoạt động trên toàn bộ cột cùng lúc, nhanh hơn nhiều.
Thay vì lặp thủ công, Polars xây dựng phép tính vector hóa nhanh.
Polars cung cấp hai chế độ thực thi:
Ví dụ về thực thi eager:
df = pl.DataFrame({"x": [1, 2, 3]})
print(df.select(pl.col("x") * 2)) # eager: runs instantlyVí dụ về thực thi lazy:
lazy_df = pl.DataFrame({"x": [1, 2, 3]}).lazy()
result = lazy_df.select(pl.col("x") * 2).collect() # execute on collect()
print(result)Ở đây, không có gì được tính cho đến khi gọi .collect(). Trong các quy trình lớn, điều này có thể mang lại cải thiện hiệu năng đáng kể.
Tiếp theo, chúng ta sẽ thực hiện một số thao tác cơ bản với Polars trên tập dữ liệu đã tạo.
Polars có thể nạp dữ liệu từ nhiều định dạng tệp và đối tượng trong bộ nhớ. Điều này giúp linh hoạt khi tích hợp vào các pipeline dữ liệu hiện đại.
Dưới đây là cách làm với các nguồn khác nhau:
Từ tập CSV ta đã tạo trước đó:
import polars as pl
df = pl.read_csv("transactions.csv")
print(df.head())Chúng ta cũng có thể đọc tập dữ liệu từ Parquet nếu cần.
df_parquet = pl.read_parquet("transactions.parquet")Nếu bạn có tệp JSON, bạn có thể đọc bằng đoạn mã sau:
df_json = pl.read_json("transactions.json")
#For JSON Lines (NDJSON), use the following instead:
df_json = pl.read_ndjson("transactions.json")Cách đọc dữ liệu từ Arrow Table:
import pyarrow as pa
arrow_table = pa.table({
"transaction_id": [1, 2],
"customer_id": [5, 7],
"amount": [150.25, 300.75],
"transaction_date": ["2023-01-02", "2023-01-03"]
})
df_arrow = pl.from_arrow(arrow_table)Bây giờ hãy chọn các cột hoặc hàng cụ thể từ tập dữ liệu của chúng ta.
Khi dùng Polars, thao tác thường gặp là chọn những cột bạn muốn làm việc và giữ lại.
Cách thực hiện như sau:
# Select only transaction_id and amount
df.select(["transaction_id", "amount"])Bạn cũng có thể lọc hàng dựa trên các điều kiện, tương tự pandas.
# Get only high-value transactions above $1,000
high_value = df.filter(pl.col("amount") > 1000)
print(high_value)Áp dụng biểu thức trong Polars liên quan đến việc sử dụng đối tượng polars.Expr trong các ngữ cảnh khác nhau để thực hiện biến đổi dữ liệu.
Bạn có thể tạo chúng bằng pl.col() hoặc pl.lit().
# Add a 10% discount column to simulate promotional pricing
df.select([
pl.col("transaction_id"),
pl.col("amount"),
(pl.col("amount") * 0.9).alias("discounted_amount")
])Chúng ta có thể phân tích thói quen chi tiêu theo khách hàng bằng group_by.
# Total and average spend per customer
agg_df = df.group_by("customer_id").agg([
pl.sum("amount").alias("total_spent"),
pl.mean("amount").alias("avg_transaction")
])
print(agg_df)Đầu ra mẫu:
shape: (10, 3)
┌─────────────┬────────────┬───────────────┐
│ customer_id │ total_spent│ avg_transaction│
│ --- │ --- │ --- │
│ i64 │ f64 │ f64 │
├─────────────┼────────────┼───────────────┤
│ 1 │ 5230.12 │ 523.01 │
│ 2 │ 6120.45 │ 680.05 │
│ ... │ ... │ ... │
└─────────────┴────────────┴───────────────┘Tập dữ liệu sinh ra của chúng ta mặc định không có null, nhưng hãy giả lập cách xử lý nếu có.
Giá trị thiếu có thể gây vấn đề trong phân tích hạ nguồn và trực quan hóa dữ liệu. Bạn sẽ cần điền các giá trị thiếu để mọi thứ diễn ra trơn tru.
Cách điền giá trị thiếu:
# Imagine 'amount' has missing values, then replace with 0
df_filled = df.with_columns(
pl.col("amount").fill_null(0)
)Null có thể gây lỗi nếu không xử lý. Cách loại bỏ như sau:
df_no_nulls = df.drop_nulls()Kiểu dữ liệu có thể bị định dạng sai trong một tập dữ liệu. Dưới đây là cách chuyển đổi bằng phương thức .cast:
# Ensure customer_id is treated as string instead of int
df_casted = df.with_columns(
pl.col("customer_id").cast(pl.Utf8)
)Polars cho phép xâu chuỗi phương thức để quy trình làm việc gọn gàng hơn. Cách xâu chuỗi này thường dùng trong SQL hoặc lập trình R với gói tidyverse.
Ví dụ: Tìm khách hàng chi tiêu nhiều nhất trong tháng 3
pipeline = (
df
.with_columns(pl.col("transaction_date").str.strptime(pl.Date, format="%Y-%m-%d"))
#.col("date_str").str.to_date(format="%Y-%m-%d")
.filter(pl.col("transaction_date").dt.month() == 3) # transactions in March
.group_by("customer_id")
.agg(pl.sum("amount").alias("march_spent"))
.sort("march_spent", descending=True)
)
print(pipeline)Pipeline này:
Cách xâu chuỗi này cho phép phân tích theo pipeline mà không cần dùng các DataFrame trung gian.
Vượt ra ngoài các thao tác cơ bản, Polars tỏa sáng khi làm việc với tập dữ liệu lớn nhờ động cơ đánh giá lười. Mô hình này cho phép Polars xây dựng kế hoạch truy vấn trước, tối ưu bên dưới rồi mới thực thi pipeline. Kết quả là hiệu năng và hiệu quả được cải thiện mạnh, đặc biệt với hàng triệu dòng hoặc biến đổi phức tạp.
Mặc định, Polars chạy ở chế độ eager. Điều này nghĩa là phép tính xảy ra ngay, tương tự pandas. Chế độ lazy thì khác:
.collect() thì các biến đổi mới được thực hiện.Ví dụ chế độ lazy:
import polars as pl
# Load dataset in lazy mode
lazy_df = pl.scan_csv("transactions.csv")
# Build a transformation pipeline
pipeline = (
lazy_df
.filter(pl.col("amount") > 1000) # step 1: filter expensive transactions
.group_by("customer_id") # step 2: group by customer
.agg(pl.sum("amount").alias("total_spent")) # step 3: aggregate
)
# Nothing has run yet, computation happens only on collect()
result = pipeline.collect()
print(result)Polars tối ưu truy vấn bằng cách áp dụng kỹ thuật pushdown:
amount > 1000, Polars áp dụng bộ lọc khi đọc CSV thay vì sau khi nạp toàn bộ hàng.customer_id và amount, Polars sẽ bỏ qua việc đọc transaction_date hoàn toàn.Khi dữ liệu quá lớn để chứa trong bộ nhớ, Polars cung cấp thực thi dạng streaming. Thay vì nạp mọi thứ cùng lúc, Polars xử lý dữ liệu theo lô, giữ mức sử dụng bộ nhớ ổn định.
Điều này đặc biệt hữu ích với các tệp CSV hoặc Parquet nhiều GB.
Ví dụ (chế độ streaming):
# Enable streaming execution for huge datasets
stream_result = (
lazy_df
.group_by("customer_id")
.agg(pl.sum("amount").alias("total_spent"))
.collect(streaming=True) # execute in streaming mode
)Với streaming=True, Polars tránh tạo các bảng trung gian khổng lồ trong bộ nhớ, giúp mở rộng tốt hơn pandas cho khối lượng công việc lớn.
.collect() và gỡ lỗi truy vấn lazyPhương thức .collect() là nút kích hoạt thực thi pipeline lazy. Trước đó, bạn có thể kiểm tra và gỡ lỗi kế hoạch truy vấn với:
.describe_plan(): Hiển thị kế hoạch logic..describe_optimized_plan(): Hiển thị kế hoạch đã tối ưu sau khi Polars áp dụng pushdown và đơn giản hóa.Polars có thể giúp tăng tốc pipeline phân tích của bạn.
Dưới đây là một số thực tiễn tốt:
Phân tích thực tế thường cần kết hợp các tập dữ liệu. Polars cung cấp đầy đủ các phép join với thực thi tối ưu, giúp gộp các bảng lớn một cách dễ dàng.
Polars hỗ trợ tất cả các kiểu join chính:
Ví dụ: Join giao dịch với metadata khách hàng
# Create customer metadata DataFrame
customers = pl.DataFrame({
"customer_id": [1, 2, 3, 4, 5],
"customer_name": ["Alice", "Bob", "Charlie", "David", "Eva"]
})
# Inner join on customer_id
df_joined = df.join(customers, on="customer_id", how="inner")
print(df_joined.head())Polars vượt trội hơn Pandas ở cả hai khía cạnh:
Hàm cửa sổ cho phép tính toán trong phạm vi nhóm hoặc theo các hàng có thứ tự, mà không làm gộp kết quả, tương tự hàm cửa sổ trong SQL.
Polars cho phép tính thống kê theo khách hàng hoặc theo giai đoạn thời gian bằng ngữ cảnh cửa sổ.
Dưới đây là một số ví dụ về hàm cửa sổ bạn có thể dùng trong Polars:
Ví dụ: Tổng tích lũy theo khách hàng
df_window = df.with_columns( pl.col("amount") .sort_by("transaction_date") .cum_sum() .over("customer_id") .alias("running_total") )
print(df_window.head())Hàm rolling hoạt động trên một cửa sổ trượt của các hàng hoặc thời gian.
Ví dụ: Tổng rolling 7 ngày của giao dịch
df = df.with_columns(pl.col("transaction_date").str.strptime(pl.Date, format="%Y-%m-%d"))
rolling = (
df.group_by_rolling("transaction_date", period="7d")
.agg(pl.sum("amount").alias("rolling_7d_sum"))
)
print(rolling.head())Cửa sổ mở rộng (tích lũy) và cửa sổ căn giữa cũng được hỗ trợ bằng cách điều chỉnh tham số.
Bạn có thể dùng các hàm xếp hạng và tổng hợp tùy chỉnh trong ngữ cảnh cửa sổ.
Ví dụ: Xếp hạng giao dịch theo khách hàng dựa trên số tiền
ranked = df.with_columns(
pl.col("amount").rank("dense", descending=True).over("customer_id").alias("rank")
)
print(ranked.head())Điều này tạo ra xếp hạng (1 = cao nhất) cho mức chi tiêu của mỗi khách hàng.
Hàm cửa sổ cho phép các phép tính theo ngữ cảnh:
print(
df.group_by("customer_id").agg(pl.col("amount").cum_sum().alias("cumulative_spent"))
)Đối với các nhà phân tích quen với SQL, Polars cung cấp ngữ cảnh SQL để bạn có thể truy vấn DataFrame trực tiếp bằng cú pháp SQL trong khi vẫn tận dụng tốc độ của Polars.
Để bắt đầu, bạn phải đăng ký một DataFrame trước khi chạy SQL.
from polars import SQLContext
ctx = SQLContext()
ctx.register("transactions", df)Hãy xem ví dụ cách chạy truy vấn SQL trong Python bằng Polars.
Ví dụ: Truy vấn tổng chi theo khách hàng bằng SQL
result = ctx.execute("""
SELECT customer_id, SUM(amount) AS total_spent
FROM transactions
GROUP BY customer_id
ORDER BY total_spent DESC
""").collect()
print(result)Bạn có thể kết hợp SQL và biểu thức:
sql_result = ctx.execute("SELECT * FROM transactions WHERE amount > 1500")
df_sql = sql_result.collect()
# Continue with Polars expressions
df_sql = df_sql.with_columns((pl.col("amount") * 0.95).alias("discounted"))Điều này hữu ích cho các nhóm đang chuyển đổi từ công cụ dựa trên SQL.
Polars không được thiết kế như một hòn đảo độc lập, mà là thư viện DataFrame hiệu năng cao tương thích tốt với hệ sinh thái dữ liệu Python rộng lớn. Tính tương tác này đảm bảo nhà phân tích và kỹ sư có thể áp dụng Polars dần dần trong khi vẫn tận dụng các công cụ hiện có.
Một số khía cạnh tích hợp:
Cuối cùng, hãy nhanh chóng xem một vài ví dụ về việc sử dụng Polars:
df = df.with_columns([
pl.col("transaction_date").str.strptime(pl.Date, "%Y-%m-%d").alias("txn_date"),
pl.col("amount").fill_null(strategy="mean")
])result = (
pl.read_csv("transactions.csv")
.lazy()
.filter(pl.col("amount") > 1000)
.group_by("customer_id")
.agg(pl.sum("amount").alias("total_spent"))
.collect()
)Dưới đây là ví dụ về đường trung bình động cho số tiền giao dịch.
import polars as pl
# Load & parse dates
df = (
pl.read_csv("transactions.csv")
.with_columns(pl.col("transaction_date").str.strptime(pl.Date, "%Y-%m-%d"))
)
# (A) Overall: daily totals + 7-day rolling average
daily = (
df.sort("transaction_date")
.group_by_dynamic("transaction_date", every="1d")
.agg(pl.sum("amount").alias("daily_total"))
.sort("transaction_date")
.with_columns(
pl.col("daily_total").rolling_mean(window_size=7).alias("ma7")
)
)
# (B) Per-customer: daily totals + 7-day rolling average within each customer
daily_by_cust = (
df.sort("transaction_date")
.group_by_dynamic(index_column="transaction_date", every="1d", by="customer_id")
.agg(pl.sum("amount").alias("daily_total"))
.sort(["customer_id", "transaction_date"])
.with_columns(
pl.col("daily_total")
.rolling_mean(window_size=7)
.over("customer_id")
.alias("ma7_per_customer")
)
)
print(daily.tail())
print(daily_by_cust.filter(pl.col("customer_id")==1).tail())Kết quả dự kiến như sau:
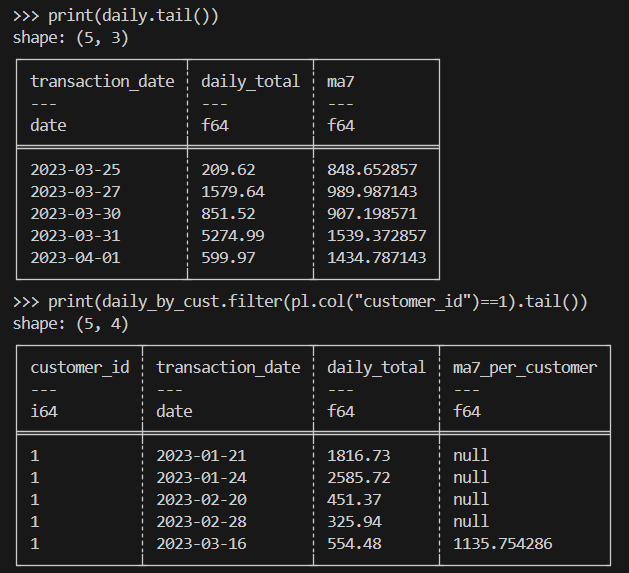
Khi làm tính toán khoa học, bạn sẽ cần xử lý hiệu quả hàng triệu dòng dữ liệu thí nghiệm hoặc dữ liệu mô phỏng giống giao dịch.
Dưới đây là một hiện thực mẫu:
import polars as pl
# Assume a very large Parquet file with columns: id, value, ts (UTC)
# Use lazy scan_* to avoid loading into memory up-front
lazy = (
pl.scan_parquet("experiments.parquet") # or: pl.scan_csv("experiments.csv")
.filter(pl.col("value") > 0) # predicate pushdown
.select(["id", "value", "ts"]) # projection pushdown
.with_columns(
# Example transformations: standardization & bucketize timestamps by hour
((pl.col("value") - pl.col("value").mean()) / pl.col("value").std())
.alias("z_value"),
pl.col("ts").dt.truncate("1h").alias("ts_hour")
)
.group_by(["id", "ts_hour"])
.agg([
pl.len().alias("n"),
pl.mean("z_value").alias("z_mean"),
pl.std("z_value").alias("z_std")
])
.sort(["id", "ts_hour"])
)
# Execute in streaming mode to keep memory usage low
result = lazy.collect(streaming=True)
# Optionally write out partitioned Parquet for downstream analysis
result.write_parquet("experiments_hourly_stats.parquet")
print(result.head())Python Polars mang đến một thư viện DataFrame hiện đại, hiệu năng cao, khắc phục nhiều hạn chế của pandas. Dù pandas vẫn phổ biến cho các phân tích nhỏ, ad-hoc, Polars ngày càng trở thành công cụ được ưa chuộng cho xử lý dữ liệu quy mô lớn, hiệu quả và đáng tin cậy trong Python.
Muốn tìm hiểu thêm về Polars? Bạn sẽ thích khóa học Introduction to Polars của chúng tôi hoặc bài viết Introduction to Polars. Bài viết về Polars Engine của chúng tôi cũng có thể khiến bạn quan tâm.
Các khóa học hàng đầu trên DataCamp
Tracks
Courses
Courses