Leerpad
Python-gegevensbasisprincipes
28 Hr
In de wereld van data-analyse is pandas lange tijd de standaardkeuze geweest voor het verwerken van tabelgegevens in Python door dataprofessionals.
Naarmate datasets echter groeien in omvang en complexiteit, kan pandas last krijgen van prestatieknelpunten, beperkte benutting van meerdere cores en geheugenbeperkingen.
Hier komt Polars om de hoek kijken als een modern alternatief. Polars is een DataFrame-bibliotheek, geschreven in Rust, die razendsnelle prestaties, efficiënt geheugenbeheer en een ontwerpfilosofie gericht op schaalbaarheid biedt.
In deze tutorial leggen we uit wat Polars is en hoe je enkele basisbewerkingen met Polars in Python uitvoert. Wil je graag hands-on aan de slag? Bekijk dan de Introduction to Polars-cursus.
Polars biedt een unieke set features die het onderscheiden van pandas:
Polars ondersteunt een breed scala aan datatypes, voorbij de basis:
Int32, Int64, Float32, Float64.true/false-waarden.Date, Datetime, Duration, Time.List- en Struct-types, nuttig voor JSON-achtige data.Als nieuwer en moderner alternatief voor pandas biedt Polars meerdere voordelen:
Laten we nu bekijken hoe je zelf met Polars aan de slag kunt in Python.
Voordat je Polars gebruikt, moet je de omgeving correct instellen.
Polars ondersteunt Windows, macOS en Linux. Je kunt het installeren in virtuele omgevingen, systeem-Python of via gecontaineriseerde workflows (Docker).
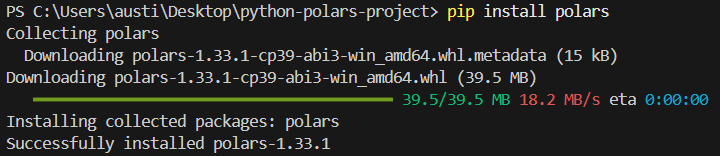
Om de polars-bibliotheek in Python te installeren, voer je de volgende opdracht in de terminal uit.
pip install polarsJe zou het volgende installatiebericht moeten zien:
Als alternatief kun je de bibliotheek installeren in de conda-omgeving als je daarmee werkt.
conda install -c conda-forge polarsOm te controleren of je installatie is geslaagd, schrijf je het volgende eenvoudige script:
import polars as pl
print(pl.__version__)Met Polars kun je afstemmen hoe het draait en hoe de uitvoer wordt weergegeven door omgevingsvariabelen in te stellen voordat je je Python-sessie start. Bijvoorbeeld:
POLARS_MAX_THREADS: Beperk het aantal threads.POLARS_FMT_MAX_COLS: Bepaal het aantal af te drukken kolommen.POLARS_FMT_TABLE_WIDTH: Pas de weergavebreedte van DataFrames aan.Hier is een voorbeeld van hoe je deze variabelen instelt in een shell voordat je Python draait:
export POLARS_MAX_THREADS=8
export POLARS_FMT_MAX_COLS=20Voor we in de features van Polars duiken, is het handig om een dataset te hebben die we door deze tutorial heen consequent kunnen gebruiken. We kunnen een eenvoudige CSV genereren met de ingebouwde csv-module van Python of met pandas.
Hier is een voorbeeld dat een transactions.csv-bestand maakt met synthetische data:
import csv
import random
from datetime import datetime, timedelta
# Define column names
columns = ["transaction_id", "customer_id", "amount", "transaction_date"]
# Generate synthetic rows
rows = []
start_date = datetime(2023, 1, 1)
for i in range(1, 101):
customer_id = random.randint(1, 10)
amount = round(random.uniform(10, 2000), 2)
date = start_date + timedelta(days=random.randint(0, 90))
rows.append([i, customer_id, amount, date.strftime("%Y-%m-%d")])
# Write to CSV
with open("transactions.csv", "w", newline="") as f:
writer = csv.writer(f)
writer.writerow(columns)
writer.writerows(rows)Dit script creëert een dataset van 100 transacties met willekeurige bedragen, klant-ID’s en transactiedata. Je kunt bereik en grootte naar wens aanpassen.
Sla dit script op, voer het één keer uit en je hebt een CSV-bestand om te gebruiken in de voorbeelden in dit artikel.
Polars is gebouwd op twee kernabstracties: de Series en de DataFrame.
Samen bieden ze een gestructureerde, efficiënte manier om met data te werken, vergelijkbaar met pandas, maar geoptimaliseerd met de door Rust aangedreven backend van Polars. Laten we de hoofdconcepten doornemen.
Een Series in Polars is een eendimensionale array, vergelijkbaar met een kolom in een spreadsheet of databasetabel. Elke Series heeft:
Int64, Utf8, Float64, Boolean, enz.).Omdat het datatype strikt wordt gehandhaafd, zijn Series in Polars sneller en voorspelbaarder dan Python-lijsten.
Voorbeeld:
import polars as pl
# Create a Series of integers
s = pl.Series("numbers", [1, 2, 3, 4, 5])
print(s)Uitvoer:
shape: (5,)
Series: 'numbers' [i64]
[
1
2
3
4
5
]
Een DataFrame is een tweedimensionale structuur die meerdere Series samen onder een schema organiseert. Conceptueel is het als een tabel in SQL of Excel. Rijen zijn records en kolommen zijn velden.
Voorbeeld:
df = pl.DataFrame({
"id": [1, 2, 3],
"name": ["Alice", "Bob", "Charlie"],
"age": [25, 30, 35]
})
print(df)Uitvoer:
shape: (3, 3)
┌─────┬─────────┬─────┐
│ id │ name │ age │
│ --- │ --- │ --- │
│ i64 │ str │ i64 │
├─────┼─────────┼─────┤
│ 1 │ Alice │ 25 │
│ 2 │ Bob │ 30 │
│ 3 │ Charlie │ 35 │
└─────┴─────────┴─────┘Elke kolom is een Series en het DataFrame handhaaft zijn schema.
Een van de sterke punten van Polars is strikte schemahandhaving. Elke kolom heeft een vast datatype en Polars zorgt dat alle bewerkingen dit respecteren. Dit voorkomt subtiele bugs die ontstaan bij dynamisch getypte operaties.
Zo kun je niet per ongeluk een stringkolom optellen bij een integerkolom zonder expliciete conversie.
Voorbeeld:
df = df.with_columns(
(pl.col("age") + 5).alias("age_plus_5")
)
print(df)Hier is age van het type i64 en het resultaat blijft een integer. Als je zou proberen een stringkolom op te tellen, zou Polars een fout geven in plaats van stilzwijgend te falen.
Echte data bevat vaak missende waarden en Polars biedt duidelijke tools om daarmee om te gaan:
fill_null(): Vervang null-waarden door een opgegeven waarde.drop_nulls(): Verwijder rijen met null-waarden.is_null() / is_not_null(): Booleaanse checks.Polars stimuleert een expressiesysteem, waarbij bewerkingen worden gedefinieerd als transformaties op kolommen in plaats van Python-loops per rij.
Deze expressies zijn gevectoriseerd, wat betekent dat ze op hele kolommen tegelijk werken, wat veel sneller is.
In plaats van handmatig te loopen, bouwt Polars een snelle gevectoriseerde berekening.
Polars biedt twee uitvoeringsmodi:
Hier is een voorbeeld van eager-uitvoering:
df = pl.DataFrame({"x": [1, 2, 3]})
print(df.select(pl.col("x") * 2)) # eager: runs instantlyHier is een voorbeeld van lazy-uitvoering:
lazy_df = pl.DataFrame({"x": [1, 2, 3]}).lazy()
result = lazy_df.select(pl.col("x") * 2).collect() # execute on collect()
print(result)Hier wordt niets berekend tot .collect() wordt aangeroepen. In grote workflows kan dit tot flinke prestatieverbeteringen leiden.
Vervolgens bekijken we hoe je enkele basisbewerkingen uitvoert in Polars op de dataset die we hebben gemaakt.
Polars kan data inlezen uit meerdere bestandsformaten en geheugenobjecten. Dit maakt integratie in moderne datapijplijnen flexibel.
Zo doe je dat voor verschillende bronnen:
Vanuit de CSV-dataset die we eerder maakten:
import polars as pl
df = pl.read_csv("transactions.csv")
print(df.head())We kunnen de dataset ook inlezen uit Parquet indien nodig.
df_parquet = pl.read_parquet("transactions.parquet")Als je in plaats daarvan een JSON-bestand hebt, kun je dat zo inlezen:
df_json = pl.read_json("transactions.json")
#For JSON Lines (NDJSON), use the following instead:
df_json = pl.read_ndjson("transactions.json")Zo lees je datasets uit een Arrow Table:
import pyarrow as pa
arrow_table = pa.table({
"transaction_id": [1, 2],
"customer_id": [5, 7],
"amount": [150.25, 300.75],
"transaction_date": ["2023-01-02", "2023-01-03"]
})
df_arrow = pl.from_arrow(arrow_table)Laten we nu specifieke kolommen of rijen uit onze dataset kiezen.
Een veelvoorkomende bewerking in Polars is het selecteren van de kolommen waarmee je wilt werken en die je wilt behouden.
Zo doe je dat:
# Select only transaction_id and amount
df.select(["transaction_id", "amount"])Je kunt ook rijen filteren op basis van door jou ingestelde voorwaarden, vergelijkbaar met pandas.
# Get only high-value transactions above $1,000
high_value = df.filter(pl.col("amount") > 1000)
print(high_value)Het toepassen van expressies in Polars houdt in dat je het object polars.Expr gebruikt in verschillende contexten om datatransformaties uit te voeren.
Je kunt ze creëren met pl.col() of pl.lit().
# Add a 10% discount column to simulate promotional pricing
df.select([
pl.col("transaction_id"),
pl.col("amount"),
(pl.col("amount") * 0.9).alias("discounted_amount")
])We kunnen bestedingspatronen per klant analyseren met group_by.
# Total and average spend per customer
agg_df = df.group_by("customer_id").agg([
pl.sum("amount").alias("total_spent"),
pl.mean("amount").alias("avg_transaction")
])
print(agg_df)Voorbeelduitvoer:
shape: (10, 3)
┌─────────────┬────────────┬───────────────┐
│ customer_id │ total_spent│ avg_transaction│
│ --- │ --- │ --- │
│ i64 │ f64 │ f64 │
├─────────────┼────────────┼───────────────┤
│ 1 │ 5230.12 │ 523.01 │
│ 2 │ 6120.45 │ 680.05 │
│ ... │ ... │ ... │
└─────────────┴────────────┴───────────────┘Onze gegenereerde dataset heeft standaard geen nulls, maar laten we simuleren hoe we ermee omgaan.
Missende waarden kunnen problemen veroorzaken in downstream-analyse en datavisualisatie. Je moet missende waarden invullen om alles soepel te laten verlopen.
Zo vul je missende waarden in:
# Imagine 'amount' has missing values, then replace with 0
df_filled = df.with_columns(
pl.col("amount").fill_null(0)
)Nulls kunnen fouten veroorzaken als je er niet mee omgaat. Zo verwijder je ze:
df_no_nulls = df.drop_nulls()Datatypes kunnen onjuist geformatteerd zijn in een dataset. Zo converteer je ze met de methode .cast:
# Ensure customer_id is treated as string instead of int
df_casted = df.with_columns(
pl.col("customer_id").cast(pl.Utf8)
)Polars ondersteunt method chaining voor schonere workflows. Deze ketenmethode wordt vaak gebruikt in SQL of R-programmering met het tidyverse-pakket.
Voorbeeld: Vind topklanten in maart op basis van totale uitgaven
pipeline = (
df
.with_columns(pl.col("transaction_date").str.strptime(pl.Date, format="%Y-%m-%d"))
#.col("date_str").str.to_date(format="%Y-%m-%d")
.filter(pl.col("transaction_date").dt.month() == 3) # transactions in March
.group_by("customer_id")
.agg(pl.sum("amount").alias("march_spent"))
.sort("march_spent", descending=True)
)
print(pipeline)Deze pipeline:
Met deze ketenmethode kun je een pijplijnanalyse doen zonder tussentijdse DataFrames te gebruiken.
Naast de basis blinkt Polars uit bij het werken met grote datasets dankzij de lazy-evaluatiemotor. Dit model laat Polars eerst een queryplan bouwen, dit onder de motorkap optimaliseren en pas daarna de pijplijn uitvoeren. Het resultaat is een flinke boost in prestaties en efficiëntie, vooral bij miljoenen rijen of complexe transformaties.
Standaard draait Polars in eager-modus. Dit betekent dat berekeningen direct plaatsvinden, vergelijkbaar met pandas. De lazy-modus werkt echter anders:
.collect() aanroept.Hier is een voorbeeld van lazy-modus:
import polars as pl
# Load dataset in lazy mode
lazy_df = pl.scan_csv("transactions.csv")
# Build a transformation pipeline
pipeline = (
lazy_df
.filter(pl.col("amount") > 1000) # step 1: filter expensive transactions
.group_by("customer_id") # step 2: group by customer
.agg(pl.sum("amount").alias("total_spent")) # step 3: aggregate
)
# Nothing has run yet, computation happens only on collect()
result = pipeline.collect()
print(result)Polars optimaliseert queries met pushdown-technieken:
amount > 1000 past Polars die filter toe tijdens het lezen van de CSV in plaats van na het laden van alle rijen.customer_id en amount selecteert, slaat Polars transaction_date volledig over.Wanneer data te groot is om in het geheugen te passen, biedt Polars streaminguitvoering. In plaats van alles in één keer te laden, verwerkt Polars data in batches, waardoor het geheugengebruik stabiel blijft.
Dit is vooral nuttig voor CSV- of Parquet-bestanden van meerdere GB.
Voorbeeld (streamingmodus):
# Enable streaming execution for huge datasets
stream_result = (
lazy_df
.group_by("customer_id")
.agg(pl.sum("amount").alias("total_spent"))
.collect(streaming=True) # execute in streaming mode
)Met streaming=True voorkomt Polars het opbouwen van enorme tussentabellen in het geheugen, waardoor het schaalbaarder is dan pandas voor grote workloads.
.collect() en lazy-queries debuggenDe methode .collect() is de trigger om een lazy-pijplijn uit te voeren. Daarvoor kun je het queryplan inspecteren en debuggen met:
.describe_plan(): toont het logische plan..describe_optimized_plan(): toont het geoptimaliseerde plan nadat Polars pushdowns en vereenvoudigingen heeft toegepast.Polars kan helpen om de prestaties van je analysepijplijnen te verbeteren.
Hier zijn enkele best practices:
Voor echte analyses moet je vaak datasets combineren. Polars biedt een volledige reeks join-bewerkingen met geoptimaliseerde uitvoering, waarmee je zelfs grote tabellen eenvoudig samenvoegt.
Polars ondersteunt alle belangrijke join-typen:
Voorbeeld: transacties samenvoegen met klantmetadata
# Create customer metadata DataFrame
customers = pl.DataFrame({
"customer_id": [1, 2, 3, 4, 5],
"customer_name": ["Alice", "Bob", "Charlie", "David", "Eva"]
})
# Inner join on customer_id
df_joined = df.join(customers, on="customer_id", how="inner")
print(df_joined.head())Polars is superieur aan pandas op beide vlakken:
Vensterfuncties maken berekeningen binnen groepen of over geordende rijen mogelijk, zonder de resultaten samen te vouwen, vergelijkbaar met SQL-windowfuncties.
Met Polars kun je statistieken per klant of per tijdsperiode berekenen met venstercontexten.
Hier zijn enkele voorbeelden van vensterfuncties die je in Polars kunt gebruiken:
Voorbeeld: cumulatieve totalen per klant
df_window = df.with_columns( pl.col("amount") .sort_by("transaction_date") .cum_sum() .over("customer_id") .alias("running_total") )
print(df_window.head())Rolling-functies werken over een schuivend venster van rijen of tijd.
Voorbeeld: 7-daagse rolling-som van transacties
df = df.with_columns(pl.col("transaction_date").str.strptime(pl.Date, format="%Y-%m-%d")
rolling = (
df.group_by_rolling("transaction_date", period="7d")
.agg(pl.sum("amount").alias("rolling_7d_sum"))
)
print(rolling.head())Expanding windows (cumulatief) en gecentreerde vensters worden ook ondersteund door parameters aan te passen.
Je kunt rangschikkingsfuncties en aangepaste aggregaties binnen vensters gebruiken.
Voorbeeld: rangschik transacties per klant op bedrag
ranked = df.with_columns(
pl.col("amount").rank("dense", descending=True).over("customer_id").alias("rank")
)
print(ranked.head())Dit levert rangnummers op (1 = hoogste) voor de uitgaven van elke klant.
Vensterfuncties maken contextuele berekeningen mogelijk:
print(
df.group_by("customer_id").agg(pl.col("amount").cum_sum().alias("cumulative_spent"))
)Voor analisten die gewend zijn aan SQL biedt Polars een SQL-context, zodat je DataFrames rechtstreeks met SQL-syntax kunt bevragen en toch profiteert van de snelheid van Polars.
Om te beginnen moet je een DataFrame registreren voordat je SQL draait.
from polars import SQLContext
ctx = SQLContext()
ctx.register("transactions", df)Laten we kijken hoe je een SQL-query uitvoert binnen Python met Polars.
Voorbeeld: totale uitgaven per klant in SQL opvragen
result = ctx.execute("""
SELECT customer_id, SUM(amount) AS total_spent
FROM transactions
GROUP BY customer_id
ORDER BY total_spent DESC
""").collect()
print(result)Je kunt SQL en expressies combineren:
sql_result = ctx.execute("SELECT * FROM transactions WHERE amount > 1500")
df_sql = sql_result.collect()
# Continue with Polars expressions
df_sql = df_sql.with_columns((pl.col("amount") * 0.95).alias("discounted"))Dit is handig voor teams die overstappen van SQL-gebaseerde tools.
Polars is niet ontworpen als een op zichzelf staand eiland, maar als een high-performance DataFrame-bibliotheek die goed samenwerkt met het bredere Python-data-ecosysteem. Deze interoperabiliteit zorgt ervoor dat analisten en engineers Polars geleidelijk kunnen adopteren en toch bestaande tools benutten.
Hier zijn enkele integratiegebieden:
Tot slot bekijken we snel enkele voorbeelden van Polars in gebruik:
df = df.with_columns([
pl.col("transaction_date").str.strptime(pl.Date, "%Y-%m-%d").alias("txn_date"),
pl.col("amount").fill_null(strategy="mean")
])result = (
pl.read_csv("transactions.csv")
.lazy()
.filter(pl.col("amount") > 1000)
.group_by("customer_id")
.agg(pl.sum("amount").alias("total_spent"))
.collect()
)Hier is een voorbeeld voor voortschrijdende gemiddelden van transactiebedragen.
import polars as pl
# Load & parse dates
df = (
pl.read_csv("transactions.csv")
.with_columns(pl.col("transaction_date").str.strptime(pl.Date, "%Y-%m-%d"))
)
# (A) Overall: daily totals + 7-day rolling average
daily = (
df.sort("transaction_date")
.group_by_dynamic("transaction_date", every="1d")
.agg(pl.sum("amount").alias("daily_total"))
.sort("transaction_date")
.with_columns(
pl.col("daily_total").rolling_mean(window_size=7).alias("ma7")
)
)
# (B) Per-customer: daily totals + 7-day rolling average within each customer
daily_by_cust = (
df.sort("transaction_date")
.group_by_dynamic(index_column="transaction_date", every="1d", by="customer_id")
.agg(pl.sum("amount").alias("daily_total"))
.sort(["customer_id", "transaction_date"])
.with_columns(
pl.col("daily_total")
.rolling_mean(window_size=7)
.over("customer_id")
.alias("ma7_per_customer")
)
)
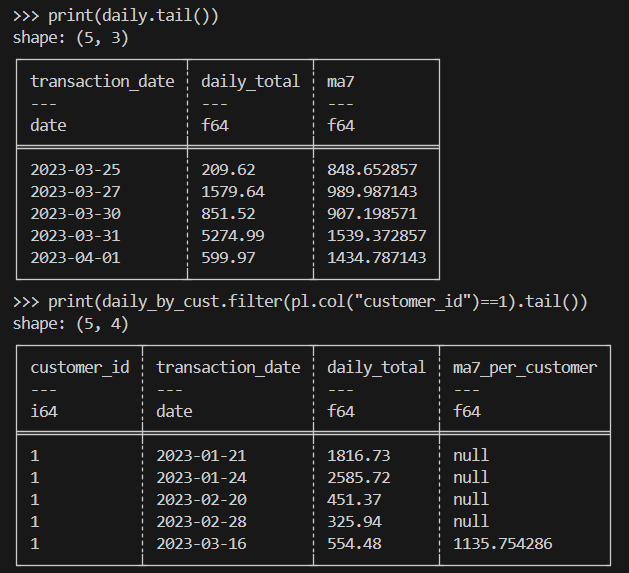
print(daily.tail())
print(daily_by_cust.filter(pl.col("customer_id")==1).tail())Hier is het verwachte resultaat:
Bij wetenschappelijke computing moet je miljoenen rijen experimentele of gesimuleerde, transactie-achtige data efficiënt verwerken.
Hier is een voorbeeldimplementatie:
import polars as pl
# Assume a very large Parquet file with columns: id, value, ts (UTC)
# Use lazy scan_* to avoid loading into memory up-front
lazy = (
pl.scan_parquet("experiments.parquet") # or: pl.scan_csv("experiments.csv")
.filter(pl.col("value") > 0) # predicate pushdown
.select(["id", "value", "ts"]) # projection pushdown
.with_columns(
# Example transformations: standardization & bucketize timestamps by hour
((pl.col("value") - pl.col("value").mean()) / pl.col("value").std())
.alias("z_value"),
pl.col("ts").dt.truncate("1h").alias("ts_hour")
)
.group_by(["id", "ts_hour"])
.agg([
pl.len().alias("n"),
pl.mean("z_value").alias("z_mean"),
pl.std("z_value").alias("z_std")
])
.sort(["id", "ts_hour"])
)
# Execute in streaming mode to keep memory usage low
result = lazy.collect(streaming=True)
# Optionally write out partitioned Parquet for downstream analysis
result.write_parquet("experiments_hourly_stats.parquet")
print(result.head())Python Polars biedt een moderne, high-performance DataFrame-bibliotheek die veel beperkingen van pandas aanpakt. Hoewel pandas populair blijft voor kleinere, ad-hoc analyses, is Polars steeds vaker de tool bij uitstek voor schaalbare, efficiënte en betrouwbare gegevensverwerking in Python.
Wil je meer leren over Polars? Dan vind je onze Introduction to Polars-cursus of ons Introduction to Polars-artikel vast interessant. Ook ons artikel over de Polars Engine kan je interesseren.
Topcursussen op DataCamp
Leerpad
Cursus
Cursus
blog
Adel Nehme
15 min
