
Kursus
Validasi Model di Python
4 Hr
30.6K
RMSE (root mean squared error) adalah metrik evaluasi akurasi yang umum digunakan dalam analisis regresi untuk mengukur rata-rata besarnya kesalahan dalam sebuah model regresi.
Berbeda dengan R-squared, yang mengukur ragam yang dijelaskan, RMSE memberikan ukuran langsung atas kesalahan prediksi dalam satuan yang sama dengan variabel respons. Hal ini sangat berguna ketika tujuan utamanya adalah meminimalkan besarnya kesalahan dan menafsirkan kinerja model dalam istilah dunia nyata.
Dalam artikel ini, kita akan membahas makna, perhitungan, interpretasi, dan kesalahpahaman umum terkait RMSE. Kita juga akan meninjau contoh di Python dan R untuk melihat bagaimana RMSE berperilaku dalam berbagai kondisi pemodelan.
RMSE adalah akar kuadrat dari rata-rata kuadrat selisih antara nilai observasi dan nilai prediksi. Ini adalah metrik regresi yang banyak digunakan untuk memberi tahu kita seberapa besar kesalahan yang dapat diharapkan dari prediksi kita, rata-rata.
Rumus matematis untuk menghitung RMSE adalah:
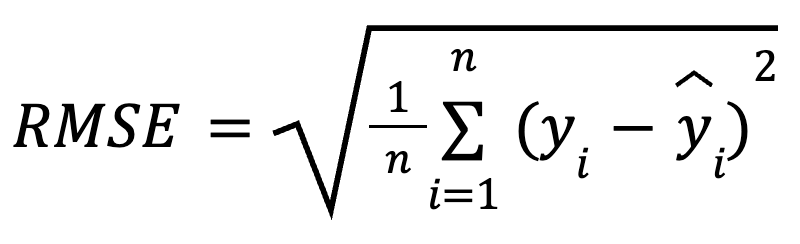
dengan:
Dengan menguadratkan residual sebelum dirata-ratakan, RMSE memberikan penalti lebih besar pada kesalahan yang besar dibandingkan kesalahan yang kecil. Sensitivitas ini membuatnya cocok ketika kesalahan prediksi yang besar sangat tidak diinginkan. RMSE selalu tidak negatif, dan nilai yang lebih rendah menunjukkan model yang lebih pas.
RMSE mudah dihitung. Caranya cukup dengan menghitung residual, menguadratkannya, mencari rata-ratanya, lalu mengambil akar kuadratnya.
Mari pertimbangkan beberapa cara berbeda untuk menghitungnya.
Dalam metode ini, kita mulai dengan mengurangkan prediksi dari nilai aktual untuk mendapatkan residual. Selanjutnya, kita kuadratkan setiap residual, rata-ratakan semuanya, dan akhirnya ambil akar kuadratnya.
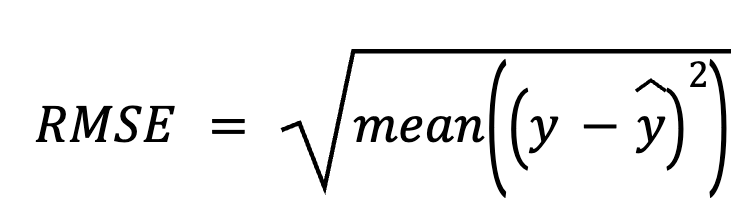
dengan:
Pendekatan langsung ini menekankan pada kesalahan prediksi itu sendiri.
Ini terdengar seperti pengungkapan ulang, tetapi sebenarnya ada lebih dari itu: RMSE hanyalah akar kuadrat dari MSE.
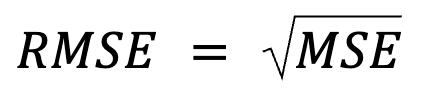
dengan:
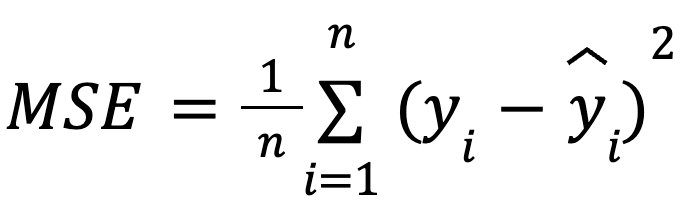
dengan:
Formulasi ini berguna karena MSE adalah fungsi rugi yang umum dalam optimisasi model. Kesetaraan ini sangat penting dalam machine learning, di mana MSE sering menjadi fungsi rugi yang diminimalkan selama pelatihan melalui gradient descent.
Tambahan: Justru karena RMSE memperkenalkan akar kuadrat, banyak algoritma machine learning memilih untuk tidak menggunakan RMSE selama pelatihan model. MSE lebih disukai untuk optimisasi ini karena turunannya lebih sederhana (sekali lagi, karena akar kuadrat memperkenalkan nonlinieritas). RMSE kemudian sering digunakan secara post hoc untuk melaporkan kinerja dalam satuan yang dapat ditafsirkan.
Dalam regresi berganda, RMSE juga dapat diturunkan dari vektor residual menggunakan aljabar matriks:
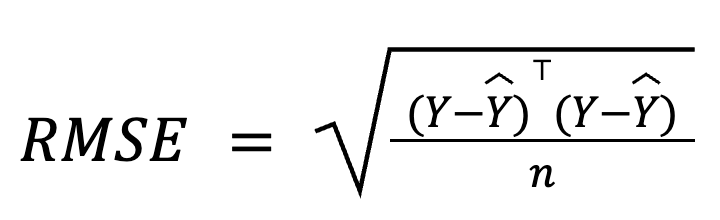
dengan:
Formulasi berbasis matriks ini sangat ringkas dan efisien secara komputasi, terutama untuk dataset besar atau pipeline model. Kami memiliki kursus aljabar linear khusus jika Anda ingin mempelajari matematikanya.
RMSE ditafsirkan sebagai rata-rata kesalahan prediksi, yang menentukan akurasi prediksi model. Sederhananya, ini menunjukkan, rata-rata, seberapa jauh prediksi dari nilai aktual, dalam skala yang sama dengan variabel keluaran.
RMSE yang lebih rendah menunjukkan rata-rata kesalahan prediksi yang lebih kecil dan, karenanya, prediksi yang lebih akurat, tetapi RMSE yang “dapat diterima” sepenuhnya bergantung pada konteks. Misalnya, RMSE sebesar 2 mungkin bagus saat memprediksi ukuran almond dalam milimeter, tetapi tidak begitu meyakinkan saat memprediksi hasil panen almond tahunan dalam ton.
Agar bermakna, RMSE harus dibandingkan antar model yang dilatih pada data yang sama atau melalui benchmarking terhadap kinerja historis.
RMSE sangat membantu dalam skenario berikut:
Namun, RMSE memiliki kekurangan:
Sekarang mari ilustrasikan cara menghitung RMSE di Python dan R menggunakan Ice-Cream Sales Dataset dari Kaggle. Kita akan membangun dua model di masing-masing bahasa pemrograman dan kemudian menghitung RMSE untuk setiap model:
Mari mulai dengan Python.
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# Load dataset
df = pd.read_csv("Ice Cream.csv")
# Extract features and target
X = df[['Temperature']]
y = df['Revenue']
# Model 1
model1 = LinearRegression()
model1.fit(X, y)
pred1 = model1.predict(X)
rmse1 = np.sqrt(mean_squared_error(y, pred1))
print(f"Model 1 RMSE: {rmse1:.3f}")
# Model 2 with an irrelevant predictor
np.random.seed(0)
df['Noise'] = np.random.normal(0, 1, size=len(df))
X2 = df[['Temperature', 'Noise']]
model2 = LinearRegression()
model2.fit(X2, y)
pred2 = model2.predict(X2)
rmse2 = np.sqrt(mean_squared_error(y, pred2))
print(f"Model 2 RMSE: {rmse2:.3f}")Model 1 RMSE: 24.915
Model 2 RMSE: 24.911
Kita dapat melihat bahwa RMSE untuk Model 2 sangat mirip dengan Model 1. Meskipun Model 2 tampak lebih kompleks, akurasi prediksinya justru bisa memburuk karena kita hanya menambahkan derau acak yang tidak menambah informasi berguna.
Untuk meningkatkan keterampilan regresi Anda di Python, daftar di kursus berikut:
Sekarang, mari coba di R.
# Load dataset
df <- read.csv("Ice Cream.csv")
# Model 1
model1 <- lm(Revenue ~ Temperature, data = df)
pred1 <- predict(model1, df)
rmse1 <- sqrt(mean((df$Revenue - pred1)^2))
cat("Model 1 RMSE:", round(rmse1, 3), "\n")
# Model 2 with an irrelevant predictor
set.seed(0)
df$Noise <- rnorm(nrow(df), mean = 0, sd = 1)
model2 <- lm(Revenue ~ Temperature + Noise, data = df)
pred2 <- predict(model2, df)
rmse2 <- sqrt(mean((df$Revenue - pred2)^2))
cat("Model 2 RMSE:", round(rmse2, 3), "\n")Model 1 RMSE: 24.915
Model 2 RMSE: 24.915Di sini saya menyusun ulang contoh yang sama dalam R. RMSE tetap persis sama ketika kita memasukkan prediktor yang tidak relevan. Ini menegaskan bahwa RMSE tidak selalu berubah saat menambahkan variabel derau, terutama jika model memberikan bobot yang dapat diabaikan pada variabel tersebut. Namun, kompleksitas tetap meningkat, dan model bisa saja melakukan generalisasi lebih buruk pada data baru.
Anda mungkin memperhatikan perbedaan kecil antara dua contoh: Di Python, RMSE sedikit menurun setelah menambahkan prediktor yang tidak relevan, sedangkan di R, RMSE tetap sama. Ini terjadi karena derau acak yang dihasilkan di masing-masing lingkungan (meskipun saya pastikan ditarik dari distribusi yang sama) tidak identik.
Jika Anda mengalami kesulitan menjalankan kode R Anda, atau kesulitan menafsirkan hasilnya, coba kursus kami:
RMSE adalah bagian dari keluarga metrik kesalahan regresi yang lebih luas. Mari bandingkan secara singkat dengan yang lain, jelaskan perbedaannya, dan soroti kapan masing-masing paling berguna.
RMSE memberikan penalti lebih besar pada kesalahan besar karena menguadratkan residual, sehingga lebih sensitif terhadap outlier. MAE (mean absolute error), sebaliknya, lebih tangguh terhadap outlier, memperlakukan semua kesalahan secara setara, dan lebih baik untuk mengukur ukuran kesalahan tipikal saat outlier bukan masalah. Sementara RMSE meminimalkan rugil kuadrat, MAE meminimalkan rugi absolut.
Secara umum, kita sebaiknya menggunakan RMSE ketika kesalahan besar sangat mahal, dan MAE ketika kita menginginkan pandangan seperti median atas kesalahan, yang kurang sensitif terhadap outlier.
RMSE memberikan rata-rata kesalahan dalam satuan asli, sehingga lebih intuitif untuk interpretasi praktis. Sebaliknya, R-squared menjelaskan seberapa banyak ragam yang dijelaskan oleh model tetapi tidak menunjukkan besar kesalahan prediksi.
Keduanya sering digunakan bersama: R-squared untuk kecocokan relatif, dan RMSE untuk kinerja absolut.
RMSE hanyalah akar kuadrat dari MSE, sehingga lebih mudah ditafsirkan karena berada dalam satuan yang sama dengan variabel keluaran.
Selain interpretasi, MSE sangat berguna untuk optimisasi selama pelatihan machine learning. Ingat bahwa jika Anda mengoptimalkan dengan RMSE, fungsi akar kuadrat membuat model lebih menekankan kesalahan yang lebih besar. Juga, MSE memiliki turunan yang mulus, sehingga cocok dengan algoritma berbasis gradien seperti stochastic gradient descent, yang memungkinkan konvergensi efisien selama pelatihan model. Singkatnya, RMSE lebih mudah ditafsirkan karena kita melihat hasil pada skala data, tetapi perlu diketahui bahwa deep learning sering mengoptimalkan MSE, bukan RMSE.
MAPE (mean absolute percentage error) mengembalikan kesalahan dalam bentuk persentase, yang berguna untuk perbandingan antar dataset. Namun, metrik ini bermasalah ketika nilai aktual mendekati nol, sehingga tidak stabil. RMSE menghindari masalah ini dan lebih andal saat terdapat nilai target yang kecil.
Berikut hubungan menarik lainnya: RMSE secara formal setara dengan negative log‑likelihood di bawah kesalahan Gaussian. Atau mungkin lebih tepat dikatakan bahwa meminimalkan RMSE setara dengan memaksimalkan log-likelihood (dari model regresi) dengan asumsi kesalahan berdistribusi normal (dengan ragam konstan). Saya tidak mengatakan bahwa RMSE sendiri mengestimasi keseluruhan log-likelihood, tetapi saya mengatakan bahwa meminimalkan RMSE secara implisit memaksimalkan log-likelihood dengan asumsi kesalahan normal.
Namun, ketika kesalahan bersifat miring atau memiliki outlier, alternatif seperti Huber atau quantile loss dapat bekerja lebih baik. Bagaimanapun, kita harus memperlakukan pilihan metrik sebagai keputusan desain model, bukan pemikiran belakangan.
Mari luruskan beberapa mitos yang tersebar luas tentang RMSE:
Sebagai penutup, RMSE adalah ukuran akurasi prediksi yang praktis, mudah ditafsirkan, dan intuitif yang mengomunikasikan rata-rata kesalahan prediksi dalam satuan variabel target. Ini adalah metrik andalan untuk evaluasi kinerja regresi, terutama ketika besarnya kesalahan penting.
Namun, RMSE sebaiknya digunakan bersama metrik lain seperti R-squared, MAE, dan skor cross-validation untuk mendapatkan gambaran yang lebih lengkap tentang kualitas model. Kita tidak boleh bergantung buta pada metrik ini, tetapi selalu mempertimbangkan skala, konteks, dan kompleksitas model. Selain itu, memasangkan RMSE dengan diagnostik visual dapat membantu mendeteksi bias.
Singkatnya, RMSE memberi tahu kita seberapa keliru model kita, rata-rata, dalam istilah nyata, yang merupakan perspektif kuat untuk dijaga saat membangun sistem prediktif.
Jika ada bagian dalam artikel ini yang membingungkan, jangan khawatir. Kami memiliki banyak sumber daya hebat untuk membantu:
Belajar dengan DataCamp
Kursus
Kursus
Kursus
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
