
Courses
Model Validation in Python
4 giờ
30.2K
RMSE (root mean squared error – căn bậc hai của sai số bình phương trung bình) là một thước đo đánh giá độ chính xác thường dùng trong phân tích hồi quy, đo lường độ lớn trung bình của sai số trong một mô hình hồi quy.
Không giống R-squared, vốn định lượng phương sai được giải thích, RMSE cung cấp thước đo trực tiếp của sai số dự đoán theo cùng đơn vị với biến phản hồi. Điều này đặc biệt hữu ích khi mục tiêu là giảm thiểu độ lớn sai số và diễn giải hiệu suất mô hình theo các điều kiện thực tế.
Trong bài viết này, chúng tôi sẽ khám phá ý nghĩa, cách tính, cách diễn giải và những hiểu lầm phổ biến về RMSE. Chúng tôi cũng sẽ trình bày các ví dụ trong Python và R để xem RMSE thay đổi thế nào dưới các điều kiện mô hình hóa khác nhau.
RMSE là căn bậc hai của trung bình các bình phương sai khác giữa giá trị quan sát và giá trị dự đoán. Đây là một thước đo hồi quy được sử dụng rộng rãi, cho biết trung bình chúng ta có thể kỳ vọng sai số dự đoán lớn đến mức nào.
Công thức toán học để tính RMSE là:
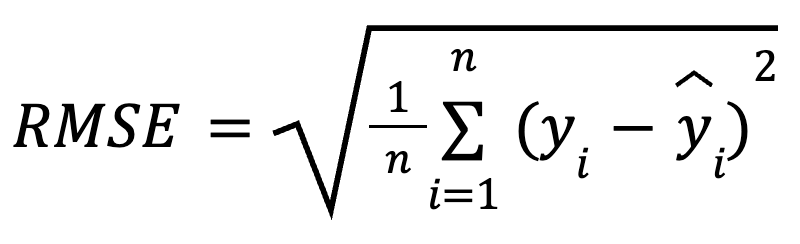
trong đó:
Bằng cách bình phương phần dư trước khi lấy trung bình, RMSE phạt nặng các sai số lớn hơn so với sai số nhỏ. Độ nhạy này khiến nó là lựa chọn tốt khi các lỗi dự đoán lớn đặc biệt không mong muốn. RMSE luôn không âm và giá trị càng thấp cho thấy mô hình khớp dữ liệu càng tốt.
RMSE rất dễ tính. Chỉ đơn giản là tính phần dư, bình phương chúng, lấy trung bình, rồi lấy căn bậc hai.
Hãy xem một vài cách khác nhau để tính.
Trong cách này, ta bắt đầu bằng cách lấy giá trị thực trừ đi dự đoán để được phần dư. Tiếp theo, bình phương từng phần dư, lấy trung bình tất cả, và cuối cùng lấy căn bậc hai.
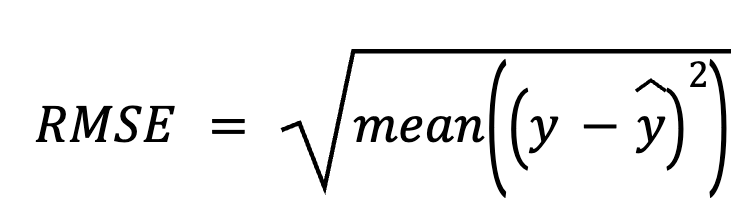
trong đó:
Cách tiếp cận trực tiếp này nhấn mạnh chính các sai số dự đoán.
Cách này nghe như diễn đạt lại, nhưng thực ra có ý nghĩa hơn: RMSE đơn giản là căn bậc hai của MSE.
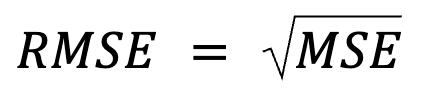
trong đó:
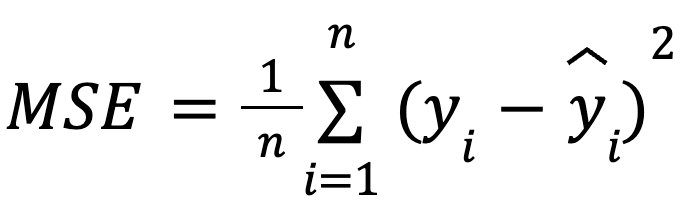
với:
Cách diễn đạt này hữu ích vì MSE là một hàm mất mát phổ biến trong tối ưu hóa mô hình. Sự tương đương này đặc biệt quan trọng trong học máy, nơi MSE thường là hàm mất mát được tối thiểu hóa trong quá trình huấn luyện thông qua gradient descent.
Nói thêm: Chính vì RMSE có phép căn bậc hai nên nhiều thuật toán học máy chọn không tối ưu trực tiếp RMSE trong huấn luyện. MSE được ưa chuộng cho các tối ưu hóa này vì đạo hàm đơn giản hơn (một lần nữa, do căn bậc hai tạo ra tính phi tuyến). Sau đó RMSE thường được dùng hậu kiểm để báo cáo hiệu suất theo các đơn vị dễ diễn giải.
Trong hồi quy đa biến, RMSE cũng có thể được suy ra từ vector phần dư bằng đại số ma trận:
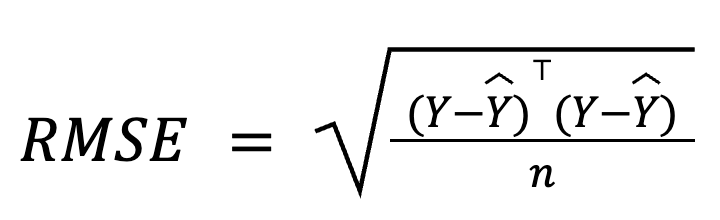
trong đó:
Biểu diễn dựa trên ma trận này đặc biệt gọn và hiệu quả tính toán, nhất là với các tập dữ liệu lớn hoặc pipeline mô hình. Chúng tôi có một khóa học đại số tuyến tính nếu bạn muốn học sâu phần toán.
RMSE được diễn giải là sai số dự đoán trung bình, quyết định độ chính xác dự đoán của mô hình. Nói đơn giản, nó cho thấy trung bình dự đoán lệch bao xa so với giá trị thực, theo cùng thang đo với biến kết quả.
RMSE thấp hơn cho thấy sai số dự đoán trung bình nhỏ hơn và do đó dự đoán chính xác hơn, nhưng mức RMSE “chấp nhận được” hoàn toàn phụ thuộc vào ngữ cảnh. Ví dụ, RMSE bằng 2 có thể tốt khi dự đoán kích thước hạnh nhân theo milimét, nhưng không thuyết phục khi dự đoán sản lượng vụ hạnh nhân hằng năm theo tấn.
Để có ý nghĩa, RMSE nên được so sánh giữa các mô hình huấn luyện trên cùng dữ liệu hoặc thông qua đối sánh chuẩn với hiệu suất lịch sử.
RMSE đặc biệt hữu ích trong các tình huống sau:
Tuy nhiên, RMSE cũng có nhược điểm:
Giờ hãy minh họa cách tính RMSE trong cả Python và R bằng Bộ dữ liệu Doanh số Kem từ Kaggle. Chúng ta sẽ xây dựng hai mô hình trong mỗi ngôn ngữ lập trình và sau đó tính RMSE cho từng mô hình:
Bắt đầu với Python.
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# Load dataset
df = pd.read_csv("Ice Cream.csv")
# Extract features and target
X = df[['Temperature']]
y = df['Revenue']
# Model 1
model1 = LinearRegression()
model1.fit(X, y)
pred1 = model1.predict(X)
rmse1 = np.sqrt(mean_squared_error(y, pred1))
print(f"Model 1 RMSE: {rmse1:.3f}")
# Model 2 with an irrelevant predictor
np.random.seed(0)
df['Noise'] = np.random.normal(0, 1, size=len(df))
X2 = df[['Temperature', 'Noise']]
model2 = LinearRegression()
model2.fit(X2, y)
pred2 = model2.predict(X2)
rmse2 = np.sqrt(mean_squared_error(y, pred2))
print(f"Model 2 RMSE: {rmse2:.3f}")Model 1 RMSE: 24.915
Model 2 RMSE: 24.911
Ta thấy RMSE cho Mô hình 2 rất giống Mô hình 1. Dù Mô hình 2 có vẻ phức tạp hơn, độ chính xác dự đoán thực tế có thể kém đi vì chúng ta chỉ thêm nhiễu ngẫu nhiên không mang lại thông tin hữu ích.
Để nâng cao kỹ năng hồi quy trong Python, hãy đăng ký các khóa học sau:
Giờ hãy thử với R.
# Load dataset
df <- read.csv("Ice Cream.csv")
# Model 1
model1 <- lm(Revenue ~ Temperature, data = df)
pred1 <- predict(model1, df)
rmse1 <- sqrt(mean((df$Revenue - pred1)^2))
cat("Model 1 RMSE:", round(rmse1, 3), "\n")
# Model 2 with an irrelevant predictor
set.seed(0)
df$Noise <- rnorm(nrow(df), mean = 0, sd = 1)
model2 <- lm(Revenue ~ Temperature + Noise, data = df)
pred2 <- predict(model2, df)
rmse2 <- sqrt(mean((df$Revenue - pred2)^2))
cat("Model 2 RMSE:", round(rmse2, 3), "\n")Model 1 RMSE: 24.915
Model 2 RMSE: 24.915Ở đây tôi đã làm lại ví dụ tương tự trong R. RMSE giữ nguyên khi ta thêm một biến dự báo không liên quan. Điều này xác nhận rằng RMSE có thể không thay đổi khi thêm biến nhiễu, đặc biệt nếu mô hình gán trọng số không đáng kể cho chúng. Tuy nhiên, độ phức tạp vẫn tăng, và mô hình có thể khái quát kém hơn trên dữ liệu mới.
Bạn có thể nhận thấy một khác biệt nhỏ giữa hai ví dụ: Trong Python, RMSE giảm nhẹ sau khi thêm biến không liên quan, trong khi ở R, RMSE giữ nguyên. Điều này xảy ra vì nhiễu ngẫu nhiên sinh ra ở mỗi môi trường (dù tôi đảm bảo phân phối giống nhau) không hề đồng nhất.
Nếu bạn gặp khó khăn khi biên dịch mã R, hoặc gặp khó khi diễn giải kết quả, hãy thử các khóa học sau:
RMSE là một phần của nhóm rộng hơn các thước đo sai số hồi quy. Hãy so sánh ngắn gọn với những thước đo khác, làm rõ khác biệt và nêu bật khi nào mỗi thước đo hữu ích nhất.
RMSE phạt nặng các lỗi lớn vì bình phương phần dư, khiến nó nhạy hơn với ngoại lệ. Ngược lại, MAE (mean absolute error – sai số tuyệt đối trung bình) ít nhạy với ngoại lệ hơn, coi mọi lỗi như nhau và hoạt động tốt hơn để đo lường kích thước lỗi điển hình khi ngoại lệ không phải là mối quan tâm. Trong khi RMSE tối thiểu hóa tổn thất bình phương, MAE tối thiểu hóa tổn thất tuyệt đối.
Nói chung, ta nên dùng RMSE khi lỗi lớn có thể gây tốn kém đặc biệt, và dùng MAE khi muốn một góc nhìn kiểu trung vị về lỗi, ít nhạy với ngoại lệ.
RMSE cung cấp sai số trung bình theo đơn vị gốc, giúp nó dễ hiểu hơn cho diễn giải thực tiễn. Trong khi đó, R-squared mô tả mô hình giải thích bao nhiêu phương sai nhưng không cho biết kích thước sai số dự đoán.
Chúng thường được dùng cùng nhau: R-squared cho độ khớp tương đối, và RMSE cho hiệu suất tuyệt đối.
RMSE chỉ là căn bậc hai của MSE, giúp dễ diễn giải hơn vì cùng đơn vị với biến kết quả.
Ngoài khía cạnh diễn giải, MSE đặc biệt hữu ích cho tối ưu hóa trong quá trình huấn luyện học máy. Hãy nhớ rằng nếu tối ưu trên RMSE, hàm căn bậc hai khiến mô hình nhấn mạnh hơn vào các lỗi lớn. Ngoài ra, MSE có đạo hàm trơn tru, nên hoạt động tốt với các thuật toán dựa trên gradient như stochastic gradient descent, giúp hội tụ hiệu quả trong huấn luyện mô hình. Tóm lại, RMSE dễ diễn giải vì kết quả ở cùng thang đo dữ liệu, nhưng cần biết rằng học sâu thường tối ưu MSE chứ không phải RMSE.
MAPE (mean absolute percentage error – sai số phần trăm tuyệt đối trung bình) trả về lỗi dưới dạng phần trăm, rất tiện để so sánh giữa các tập dữ liệu. Tuy nhiên, nó gặp vấn đề khi giá trị thực gần bằng 0, khiến thước đo không ổn định. RMSE tránh được vấn đề này và đáng tin cậy hơn khi có các giá trị mục tiêu nhỏ.
Một mối quan hệ thú vị khác: RMSE về hình thức tương đương với log‑likelihood âm dưới giả định lỗi Gaussian. Hay đúng hơn, ta nên nói rằng tối thiểu hóa RMSE tương đương với tối đa hóa log-likelihood (của mô hình hồi quy) dưới giả định lỗi phân phối chuẩn (với phương sai không đổi). Tôi không nói rằng bản thân RMSE ước lượng đầy đủ log-likelihood, mà ý tôi là việc tối thiểu hóa RMSE ngầm tối đa hóa log-likelihood dưới giả định lỗi chuẩn.
Tuy vậy, khi lỗi bị lệch hoặc có ngoại lệ, các thay thế như Huber hay quantile loss có thể hoạt động tốt hơn. Dù thế nào, ta nên coi việc chọn thước đo là một quyết định thiết kế mô hình, không phải suy nghĩ muộn.
Hãy làm rõ một số quan niệm sai lầm phổ biến về RMSE:
Tóm lại, RMSE là một thước đo thực tiễn, dễ diễn giải và trực quan về độ chính xác dự đoán, truyền tải sai số dự đoán trung bình theo đơn vị của biến mục tiêu. Đây là thước đo ưa dùng để đánh giá hiệu suất hồi quy, đặc biệt khi độ lớn sai số là quan trọng.
Tuy nhiên, RMSE nên được dùng cùng với các thước đo khác như R-squared, MAE và điểm số cross-validation để có bức tranh đầy đủ hơn về chất lượng mô hình. Ta không nên dựa mù quáng vào thước đo này mà luôn cân nhắc thang đo, ngữ cảnh và độ phức tạp mô hình. Ngoài ra, kết hợp RMSE với các chẩn đoán trực quan có thể giúp phát hiện thiên lệch.
Nói ngắn gọn, RMSE cho ta biết trung bình mô hình sai lệch bao nhiêu theo nghĩa thực tế, đây là một góc nhìn hữu ích khi xây dựng các hệ thống dự đoán.
Nếu có điều gì trong bài viết gây nhầm lẫn, đừng lo. Chúng tôi có nhiều tài nguyên hay để hỗ trợ:
Học với DataCamp
Courses
Courses
Courses