
Corso
Validazione dei modelli in Python
4 h
30.2K
L’RMSE (root mean squared error) è una metrica di valutazione dell’accuratezza comunemente usata nell’analisi di regressione che misura l’ampiezza media degli errori in un modello di regressione.
A differenza dell’R‑quadrato, che quantifica la varianza spiegata, l’RMSE fornisce una misura diretta dell’errore di previsione nelle stesse unità della variabile risposta. Questo lo rende particolarmente utile quando l’obiettivo è ridurre al minimo l’ampiezza degli errori e interpretare le prestazioni del modello in termini concreti.
In questo articolo esploreremo significato, calcolo, interpretazione e idee sbagliate comuni sull’RMSE. Vedremo anche esempi in Python e R per capire come l’RMSE si comporta in diverse condizioni di modellazione.
L’RMSE è la radice quadrata della media dei quadrati delle differenze tra valori osservati e previsti. È una metrica di regressione ampiamente usata che ci dice quanto errore aspettarci in media dalle nostre previsioni.
La formula matematica per calcolare l’RMSE è:
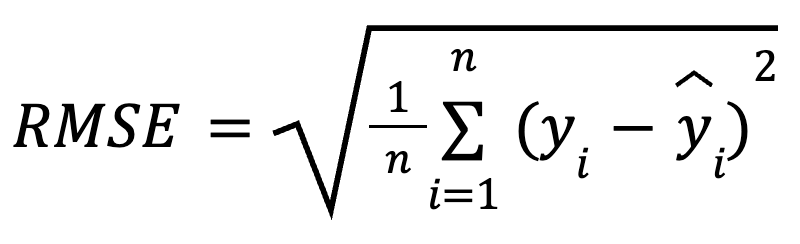
dove:
Elevando al quadrato i residui prima di farne la media, l’RMSE penalizza gli errori più grandi più dei piccoli. Questa sensibilità lo rende una buona scelta quando errori di previsione elevati sono particolarmente indesiderabili. L’RMSE è sempre non negativo e valori più bassi indicano un modello che si adatta meglio.
L’RMSE è semplice da calcolare. Si tratta semplicemente di calcolare i residui, elevarli al quadrato, farne la media e prenderne la radice quadrata.
Vediamo alcuni modi diversi per calcolarlo.
In questo metodo, partiamo sottraendo le previsioni dai valori effettivi per ottenere i residui. Poi eleviamo al quadrato ciascun residuo, ne facciamo la media e infine prendiamo la radice quadrata.
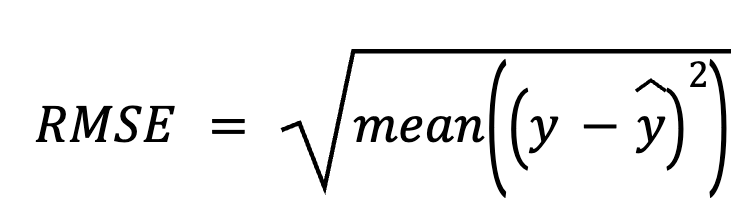
dove:
Questo approccio diretto mette in risalto gli errori di previsione in sé.
Sembra solo una riformulazione, ma c’è dell’altro: l’RMSE è semplicemente la radice quadrata dell’MSE.
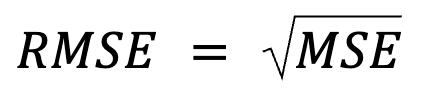
dove:
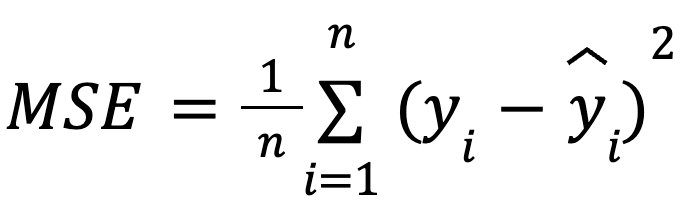
con:
Questa formulazione è utile perché l’MSE è una funzione di perdita comune nell’ottimizzazione dei modelli. Questa equivalenza è particolarmente importante nel machine learning, dove l’MSE è spesso la loss minimizzata durante l’addestramento tramite discesa del gradiente.
Ancora su questo punto: è proprio perché l’RMSE introduce una radice quadrata che molti algoritmi di machine learning scelgono di non usare l’RMSE durante l’addestramento. L’MSE è preferito per queste ottimizzazioni perché ha derivate più semplici (di nuovo, perché la radice quadrata introduce non linearità). L’RMSE viene poi spesso usato a posteriori per riportare le prestazioni in unità interpretabili.
Nella regressione multipla, l’RMSE può essere derivato dal vettore dei residui usando l’algebra lineare:
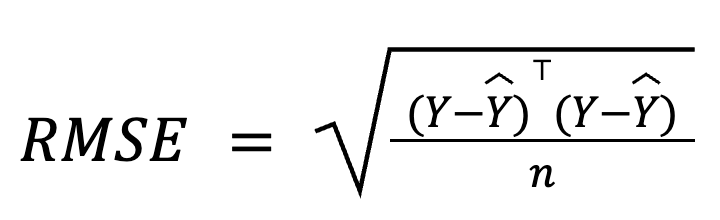
dove:
Questa formulazione in matrici è particolarmente compatta ed efficiente dal punto di vista computazionale, soprattutto per dataset grandi o pipeline di modelli. Se vuoi approfondire la matematica, abbiamo un corso di algebra lineare dedicato.
L’RMSE si interpreta come l’errore medio di previsione, che determina l’accuratezza predittiva del modello. In parole semplici, mostra, in media, quanto le previsioni si discostano dai valori reali, sulla stessa scala della variabile di esito.
Un RMSE più basso suggerisce errori medi più piccoli e quindi previsioni più accurate, ma l’RMSE “accettabile” dipende interamente dal contesto. Per esempio, un RMSE di 2 può andare bene quando si prevede la dimensione delle mandorle in millimetri, ma non è così convincente quando si prevedono le rese annuali di mandorle in tonnellate.
Per essere significativo, l’RMSE andrebbe confrontato tra modelli addestrati sugli stessi dati oppure tramite benchmark con le prestazioni storiche.
L’RMSE è particolarmente utile in questi scenari:
Tuttavia, l’RMSE ha anche dei lati negativi:
Vediamo ora come calcolare l’RMSE sia in Python sia in R usando il Ice-Cream Sales Dataset di Kaggle. Costruiremo due modelli in ciascun linguaggio e poi calcoleremo l’RMSE per ciascun modello:
Iniziamo con Python.
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# Load dataset
df = pd.read_csv("Ice Cream.csv")
# Extract features and target
X = df[['Temperature']]
y = df['Revenue']
# Model 1
model1 = LinearRegression()
model1.fit(X, y)
pred1 = model1.predict(X)
rmse1 = np.sqrt(mean_squared_error(y, pred1))
print(f"Model 1 RMSE: {rmse1:.3f}")
# Model 2 with an irrelevant predictor
np.random.seed(0)
df['Noise'] = np.random.normal(0, 1, size=len(df))
X2 = df[['Temperature', 'Noise']]
model2 = LinearRegression()
model2.fit(X2, y)
pred2 = model2.predict(X2)
rmse2 = np.sqrt(mean_squared_error(y, pred2))
print(f"Model 2 RMSE: {rmse2:.3f}")Model 1 RMSE: 24.915
Model 2 RMSE: 24.911
Vediamo che l’RMSE per il Modello 2 è molto simile al Modello 1. Anche se il Modello 2 può sembrare più complesso, la sua accuratezza predittiva può peggiorare poiché abbiamo incluso rumore casuale che non aggiunge alcuna informazione utile.
Per migliorare le tue competenze sulla regressione in Python, iscriviti a questi corsi:
Ora proviamo in R.
# Load dataset
df <- read.csv("Ice Cream.csv")
# Model 1
model1 <- lm(Revenue ~ Temperature, data = df)
pred1 <- predict(model1, df)
rmse1 <- sqrt(mean((df$Revenue - pred1)^2))
cat("Model 1 RMSE:", round(rmse1, 3), "\n")
# Model 2 with an irrelevant predictor
set.seed(0)
df$Noise <- rnorm(nrow(df), mean = 0, sd = 1)
model2 <- lm(Revenue ~ Temperature + Noise, data = df)
pred2 <- predict(model2, df)
rmse2 <- sqrt(mean((df$Revenue - pred2)^2))
cat("Model 2 RMSE:", round(rmse2, 3), "\n")Model 1 RMSE: 24.915
Model 2 RMSE: 24.915Qui ho riproposto lo stesso esempio in R. L’RMSE è rimasto esattamente uguale quando abbiamo incluso un predittore irrilevante. Questo conferma che l’RMSE potrebbe non cambiare sempre aggiungendo variabili di rumore, soprattutto se il modello assegna loro un peso trascurabile. Tuttavia, la complessità aumenta comunque e il modello potrebbe generalizzare peggio su nuovi dati.
Potresti aver notato una piccola differenza tra i due esempi: in Python, l’RMSE è diminuito leggermente dopo aver aggiunto il predittore irrilevante, mentre in R l’RMSE è rimasto invariato. Ciò è accaduto perché il rumore casuale generato in ciascun ambiente (anche se mi sono assicurato che fosse estratto dalla stessa distribuzione) non era identico.
Se hai avuto problemi a compilare il codice R o a interpretarne il risultato, prova i nostri corsi:
L’RMSE fa parte di una famiglia più ampia di metriche di errore per la regressione. Confrontiamolo brevemente con altre metriche, chiarendo le differenze e quando ciascuna è più utile.
L’RMSE penalizza maggiormente gli errori grandi perché eleva al quadrato i residui, rendendolo più sensibile ai valori anomali. La MAE (mean absolute error), al contrario, è più robusta agli outlier, tratta tutti gli errori allo stesso modo e funziona meglio per misurare l’errore tipico quando gli outlier non sono un problema. Mentre l’RMSE minimizza la perdita quadratica, la MAE minimizza la perdita assoluta.
In generale, usa l’RMSE quando gli errori grandi possono essere particolarmente costosi e la MAE quando vuoi una visione “tipo mediana” dell’errore, meno sensibile agli outlier.
L’RMSE fornisce l’errore medio nelle unità originali, il che lo rende più intuitivoe per l’interpretazione pratica. Invece, R‑quadrato descrive quanta varianza è spiegata dal modello ma non indica l’ampiezza dell’errore di previsione.
Spesso si usano insieme: R‑quadrato per l’adattamento relativo e RMSE per le prestazioni assolute.
L’RMSE è semplicemente la radice quadrata dell’MSE, il che lo rende più facile da interpretare perché è nelle stesse unità della variabile di esito.
Oltre all’interpretazione, però, l’MSE è particolarmente utile per l’ottimizzazione durante l’addestramento nel machine learning. Ricorda che, se ottimizzassi sull’RMSE, la funzione radice quadrata farebbe sì che il modello dia più enfasi agli errori più grandi. Inoltre, l’MSE ha una derivata regolare, quindi funziona bene con algoritmi basati sul gradiente come la stochastic gradient descent, consentendo una convergenza efficiente durante l’addestramento. In breve, l’RMSE è più facile da interpretare perché guardiamo risultati sulla scala dei dati, ma sappi che il deep learning spesso ottimizza l’MSE, non l’RMSE.
La MAPE (mean absolute percentage error) restituisce gli errori in percentuale, il che è comodo per confrontare tra dataset. Tuttavia, va in crisi quando i valori effettivi sono vicini a zero, rendendola instabile. L’RMSE evita questo problema ed è più affidabile quando sono presenti valori target piccoli.
Ecco un’altra relazione interessante: l’RMSE è formalmente equivalente alla log‑verosimiglianza negativa sotto errori gaussiani. O meglio, dovremmo forse dire che minimizzare l’RMSE equivale a massimizzare la log‑verosimiglianza (di un modello di regressione) sotto l’assunzione di errori normalmente distribuiti (a varianza costante). Non sto dicendo che l’RMSE di per sé stimi la log‑verosimiglianza completa, ma sto dicendo che minimizzare l’RMSE massimizza implicitamente la log‑verosimiglianza sotto un’assunzione di errore normale.
Tuttavia, quando gli errori sono asimmetrici o presentano outlier, alternative come la perdita di Huber o la quantile loss possono funzionare meglio. In ogni caso, dovremmo trattare la scelta della metrica come una decisione di progettazione del modello, non come un ripensamento.
Chiarifichiamo alcuni miti diffusi sull’RMSE:
In sintesi, l’RMSE è una misura pratica, interpretabile e intuitiva dell’accuratezza di previsione che comunica l’errore medio di previsione nelle unità della variabile target. È una metrica di riferimento per valutare le prestazioni nella regressione, soprattutto quando l’ampiezza degli errori conta.
Tuttavia, l’RMSE andrebbe usato insieme ad altre metriche come R‑quadrato, MAE e punteggi di cross‑validation per ottenere un quadro più completo della qualità del modello. Non dovremmo affidarci ciecamente a questa misura, ma considerare sempre scala, contesto e complessità del modello. Inoltre, affiancare l’RMSE a diagnostiche visive può aiutare a rilevare bias.
In breve, l’RMSE ci dice quanto il nostro modello sbaglia, in media, in termini reali: una prospettiva potente da mantenere quando si costruiscono sistemi predittivi.
Se qualcosa in questo articolo ti ha confuso, non preoccuparti. Abbiamo molte ottime risorse per aiutarti:
Impara con DataCamp
Corso
Corso
Corso
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min
blog
Abid Ali Awan
15 min

