
Kurs
Python'da Model Doğrulama
4 sa
30.2K
RMSE (kök ortalama kare hata), bir regresyon modelindeki hataların ortalama büyüklüğünü ölçen ve regresyon analizinde yaygın olarak kullanılan bir doğruluk değerlendirme metriğidir.
Açıklanan varyansı nicelleştiren R-kare’den farklı olarak RMSE, yanıt değişkeninin birimiyle aynı birimde doğrudan bir tahmin hatası ölçüsü sunar. Bu da hataların büyüklüğünü en aza indirmeyi ve model performansını gerçek dünya terimleriyle yorumlamayı hedeflediğimiz durumlarda onu özellikle kullanışlı kılar.
Bu yazıda RMSE’nin anlamını, hesaplanışını, yorumlanmasını ve yaygın yanlış anlaşılmalarını inceleyeceğiz. Ayrıca, Python ve R örnekleri üzerinden RMSE’nin farklı modelleme koşullarında nasıl davrandığına bakacağız.
RMSE, gözlenen değerlerle tahmin edilen değerler arasındaki farkların karelerinin ortalamasının kareköküdür. Ortalama olarak, tahminlerimizden ne kadar hata bekleyebileceğimizi söyleyen yaygın bir regresyon metriğidir.
RMSE’yi hesaplamanın matematiksel formülü şöyledir:
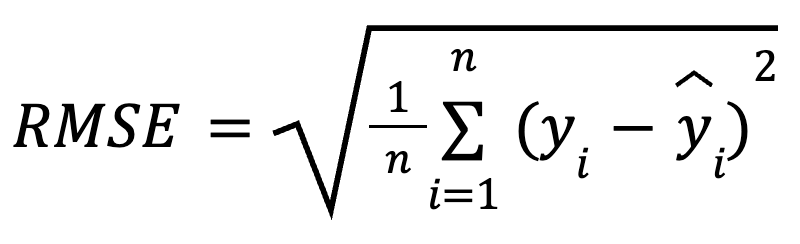
burada:
Artıkları ortalamadan önce kareye alarak, RMSE büyük hataları küçük hatalara göre daha fazla cezalandırır. Bu hassasiyet, büyük tahmin hatalarının özellikle istenmediği durumlarda onu iyi bir seçenek yapar. RMSE her zaman negatif olmayan bir değerdir ve daha düşük değerler daha iyi uyum sağlayan bir modeli gösterir.
RMSE hesaplamak kolaydır. Artıkları hesaplamak, karelerini almak, ortalamak ve karekökünü almak yeterlidir.
Bunu hesaplamanın birkaç farklı yoluna bakalım.
Bu yöntemde, artık değerleri elde etmek için tahminleri gerçek değerlerden çıkararak başlarız. Sonra her artığın karesini alır, hepsinin ortalamasını bulur ve sonunda karekökünü alırız.
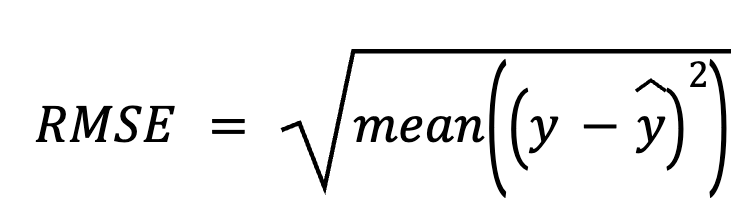
burada:
Bu doğrudan yaklaşım, bizzat tahmin hatalarının kendisini vurgular.
Bu yöntem bir yeniden ifade gibi görünse de aslında daha fazlası vardır: RMSE, MSE’nin karekökünden ibarettir.
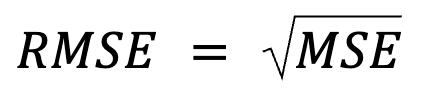
burada:
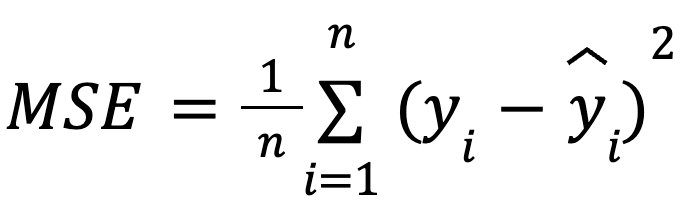
şunlarla:
Bu formülasyon kullanışlıdır çünkü MSE, model optimizasyonunda yaygın bir kayıp fonksiyonudur. Bu eşdeğerlik özellikle makine öğreniminde önemlidir; eğitim sırasında sıklıkla gradyan inişi ile minimize edilen kayıp fonksiyonu MSE’dir.
Bununla ilgili not: Tam da RMSE karekök içerdiği için birçok makine öğrenimi algoritması model eğitiminde RMSE’yi optimize etmeyi tercih etmez. Türevleri daha basit olduğundan (karekök doğrusal olmayanlık getirdiği için) bu optimizasyonlarda MSE tercih edilir. Ardından RMSE genellikle sonradan, performansı yorumlanabilir birimlerle raporlamak için kullanılır.
Çoklu regresyonda RMSE, matris cebiri kullanılarak artık vektöründen de türetilebilir:
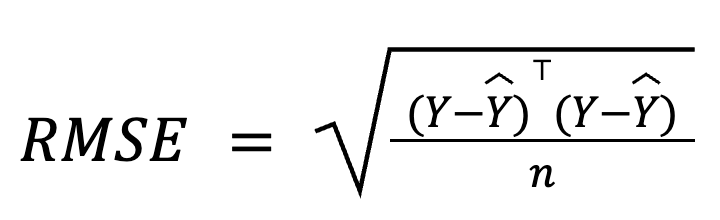
burada:
Bu matris temelli formülasyon özellikle büyük veri kümeleri veya model boru hatları için oldukça derli toplu ve hesaplama açısından verimlidir. Matematiğini çalışmak isterseniz özel bir lineer cebir kursumuz var.
RMSE, ortalama tahmin hatası olarak yorumlanır ve modelin tahmin doğruluğunu belirler. Basitçe ifade etmek gerekirse, sonuç değişkeniyle aynı ölçekte, tahminlerin ortalama olarak gerçek değerlerden ne kadar saptığını gösterir.
Daha düşük bir RMSE, daha küçük ortalama tahmin hatalarına ve dolayısıyla daha doğru tahminlere işaret eder; ancak “kabul edilebilir” RMSE bütünüyle bağlama bağlıdır. Örneğin, milimetre cinsinden badem boyunu tahmin ederken RMSE’nin 2 olması iyi olabilir, ama yıllık badem rekoltesini ton cinsinden tahmin ederken pek ikna edici olmayabilir.
Anlamlı olması için RMSE, aynı veriler üzerinde eğitilmiş modeller arasında karşılaştırılmalı ya da geçmiş performansa göre kıyaslanmalıdır.
RMSE özellikle şu senaryolarda faydalıdır:
Ancak RMSE’nin dezavantajları da vardır:
Şimdi Kaggle’daki Dondurma Satışları Veri Kümesini kullanarak R ve Python’da RMSE’nin nasıl hesaplandığını gösterelim. Her iki programlama dilinde de iki model kurup her biri için RMSE hesaplayacağız:
Python ile başlayalım.
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# Load dataset
df = pd.read_csv("Ice Cream.csv")
# Extract features and target
X = df[['Temperature']]
y = df['Revenue']
# Model 1
model1 = LinearRegression()
model1.fit(X, y)
pred1 = model1.predict(X)
rmse1 = np.sqrt(mean_squared_error(y, pred1))
print(f"Model 1 RMSE: {rmse1:.3f}")
# Model 2 with an irrelevant predictor
np.random.seed(0)
df['Noise'] = np.random.normal(0, 1, size=len(df))
X2 = df[['Temperature', 'Noise']]
model2 = LinearRegression()
model2.fit(X2, y)
pred2 = model2.predict(X2)
rmse2 = np.sqrt(mean_squared_error(y, pred2))
print(f"Model 2 RMSE: {rmse2:.3f}")Model 1 RMSE: 24.915
Model 2 RMSE: 24.911
Model 2 için RMSE’nin Model 1 ile çok benzer olduğunu görebiliriz. Model 2 daha karmaşık görünse de, yalnızca faydalı bilgi taşımayan rastgele gürültü eklediğimiz için gerçek tahmin doğruluğu kötüleşebilir.
Python’da regresyon becerilerinizi geliştirmek için şu kurslara kaydolun:
Şimdi R’de deneyelim.
# Load dataset
df <- read.csv("Ice Cream.csv")
# Model 1
model1 <- lm(Revenue ~ Temperature, data = df)
pred1 <- predict(model1, df)
rmse1 <- sqrt(mean((df$Revenue - pred1)^2))
cat("Model 1 RMSE:", round(rmse1, 3), "\n")
# Model 2 with an irrelevant predictor
set.seed(0)
df$Noise <- rnorm(nrow(df), mean = 0, sd = 1)
model2 <- lm(Revenue ~ Temperature + Noise, data = df)
pred2 <- predict(model2, df)
rmse2 <- sqrt(mean((df$Revenue - pred2)^2))
cat("Model 2 RMSE:", round(rmse2, 3), "\n")Model 1 RMSE: 24.915
Model 2 RMSE: 24.915Burada aynı örneği R’de yeniden düzenledim. İlgisiz bir yordayıcı eklediğimizde RMSE tam olarak aynı kaldı. Bu, özellikle model bu değişkene ihmal edilebilir bir ağırlık verdiğinde, gürültü değişkenleri eklendiğinde RMSE’nin her zaman değişmeyebileceğini doğrular. Ancak karmaşıklık yine de artar ve model yeni verilerde daha kötü genelleme yapabilir.
İki örnek arasında küçük bir fark fark etmiş olabilirsiniz: Python’da ilgisiz yordayıcıyı ekledikten sonra RMSE hafifçe düştü, R’de ise aynı kaldı. Bunun nedeni, her iki ortamda üretilen rastgele gürültünün (aynı dağılımdan çekildiğinden emin olmama rağmen) özdeş olmamasıdır.
R kodunuzu derlemekte zorlandıysanız veya sonucu yorumlamakta güçlük çektiyseniz şu kurslarımızı deneyin:
RMSE, daha geniş bir regresyon hata metrikleri ailesinin parçasıdır. Kısaca diğerleriyle karşılaştıralım, aralarındaki farkları netleştirelim ve her birinin ne zaman en yararlı olduğunu vurgulayalım.
RMSE, artıkları kareye aldığı için büyük hataları daha ağır cezalandırır ve aykırı değerlere daha duyarlıdır. Buna karşılık MAE (ortalama mutlak hata) aykırı değerlere karşı daha dayanıklıdır, tüm hataları eşit biçimde ele alır ve aykırıların sorun olmadığı durumlarda tipik hata büyüklüğünü ölçmek için daha iyi çalışır. RMSE kare kaybını minimize ederken, MAE mutlak kaybı minimize eder.
Genel olarak, büyük hataların özellikle maliyetli olabileceği durumlarda RMSE’yi; aykırı değerlere daha az duyarlı, medyan benzeri bir hata görünümü istediğimizde MAE’yi kullanmalıyız.
RMSE, özgün birimlerde ortalama hatayı verir; bu da pratik yorum için daha sezgisel hale getirir. Buna karşılık R-kare modelin ne kadar varyans açıkladığını anlatır ancak tahmin hatası büyüklüğünü göstermez.
Genellikle birlikte kullanılırlar: R-kare göreli uyum için, RMSE ise mutlak performans için.
RMSE, MSE’nin karekökünden ibarettir ve sonuç değişkeniyle aynı birimde olduğu için yorumlaması daha kolaydır.
Yorumun ötesinde, MSE makine öğrenimi eğitiminde optimizasyon için özellikle kullanışlıdır. RMSE üzerinde optimize etseydiniz, karekök fonksiyonu modelin daha büyük hatalara daha fazla ağırlık vermesine neden olurdu. Ayrıca MSE’nin türevi düzgündür; bu nedenle stokastik gradyan inişi gibi gradyan tabanlı algoritmalarla iyi çalışır ve eğitim sırasında verimli yakınsamayı sağlar. Kısacası, verilerin ölçeğinde sonuçlara baktığımız için RMSE’yi yorumlamak daha kolaydır; ancak derin öğrenmenin sıklıkla RMSE değil, MSE’yi optimize ettiğini bilmeliyiz.
MAPE (ortalama mutlak yüzde hata) hataları yüzde olarak döndürür; bu da veri kümeleri arasında karşılaştırma için kullanışlıdır. Ancak gerçek değerler sıfıra yakın olduğunda bozulur ve kararsız hale gelir. RMSE bu sorunu yaşamaz ve küçük hedef değerlerin bulunduğu durumlarda daha güvenilirdir.
Şu da ilginç bir ilişki: RMSE, Gauss hataları altında negatif log-olabilirlikle biçimsel olarak eşdeğerdir. Ya da şöyle söylemeliyiz: RMSE’yi minimize etmek, sabit varyanslı normal dağılmış hatalar varsayımı altında (bir regresyon modelinin) log-olabilirliğini maksimize etmeye eşdeğerdir. Burada RMSE’nin tek başına tam log-olabilirliği tahmin ettiğini söylemiyorum; ancak RMSE’yi minimize etmenin, normal hata varsayımı altında log-olabilirliği örtük olarak maksimize ettiğini söylüyorum.
Bununla birlikte, hatalar çarpıksa veya aykırı değerler varsa, Huber ya da kuantil kaybı gibi alternatifler daha iyi performans gösterebilir. Her durumda, metrik seçimimizi bir model tasarımı kararı olarak ele almalı, sonradan düşünülecek bir ayrıntı olarak görmemeliyiz.
RMSE ile ilgili yaygın mitleri netleştirelim:
Özetle RMSE, hedef değişkenin birimleri cinsinden ortalama tahmin hatasını ileten, pratik, yorumlanabilir ve sezgisel bir tahmin doğruluğu ölçüsüdür. Özellikle hata büyüklüklerinin önemli olduğu durumlarda, regresyon performans değerlendirmesi için başvurulan bir metriktir.
Ancak daha kapsamlı bir model kalite değerlendirmesi için RMSE’yi R-kare, MAE ve çapraz doğrulama puanları gibi diğer metriklerle birlikte kullanmalıyız. Bu ölçüye körü körüne güvenmek yerine her zaman ölçek, bağlam ve model karmaşıklığını dikkate almalıyız. Ayrıca RMSE’yi görsel tanı testleriyle eşleştirmek önyargıyı tespit etmeye yardımcı olabilir.
Kısacası, RMSE modelimizin gerçek anlamda ortalama olarak ne kadar yanıldığını söyler; bu da öngörücü sistemler kurarken elde tutulması gereken güçlü bir bakış açısıdır.
Bu yazıda kafanızı karıştıran bir şey olduysa endişelenmeyin. Yardımcı olacak pek çok harika kaynağımız var:
DataCamp ile öğrenin
Kurs
Kurs
Kurs
blog
Dario Radečić
15 dk.
blog
Abid Ali Awan
14 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
