
Cursus
Modelvalidatie in Python
4 Hr
30.6K
RMSE (root mean squared error) is een veelgebruikte metriek voor het beoordelen van nauwkeurigheid in regressieanalyse die de gemiddelde omvang van de fouten in een regressiemodel meet.
In tegenstelling tot R-kwadraat, dat verklaarde variantie kwantificeert, geeft RMSE een directe maat voor de voorspellingsfout in dezelfde eenheden als de responsvariabele. Dat maakt het vooral nuttig wanneer het doel is om foutgroottes te minimaliseren en modelprestaties in praktische termen te interpreteren.
In dit artikel behandelen we de betekenis, berekening, interpretatie en veelvoorkomende misvattingen rond RMSE. We lopen ook voorbeelden in Python en R door om te zien hoe RMSE zich gedraagt onder verschillende modelleercondities.
RMSE is de vierkantswortel van het gemiddelde van de gekwadrateerde verschillen tussen geobserveerde en voorspelde waarden. Het is een veelgebruikte regressiemetriek die aangeeft hoeveel fout je gemiddeld van je voorspellingen kunt verwachten.
De wiskundige formule voor het berekenen van RMSE is:
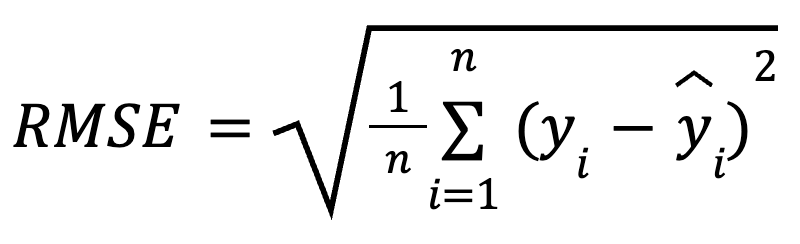
waarbij:
Door de residuals te kwadrateren voordat je het gemiddelde neemt, bestraft RMSE grotere fouten zwaarder dan kleinere. Deze gevoeligheid maakt het een goede keuze wanneer grote voorspellingsfouten extra onwenselijk zijn. RMSE is altijd niet-negatief en lagere waarden duiden op een beter passend model.
RMSE is eenvoudig te berekenen. Het komt neer op het bepalen van de residuals, die kwadrateren, het gemiddelde nemen en daar de wortel uit trekken.
Laten we een paar verschillende manieren bekijken om dit te doen.
Bij deze methode beginnen we met het aftrekken van voorspellingen van de werkelijke waarden om de residuals te krijgen. Vervolgens kwadrateren we elke residual, middelen we ze allemaal en nemen we ten slotte de vierkantswortel.
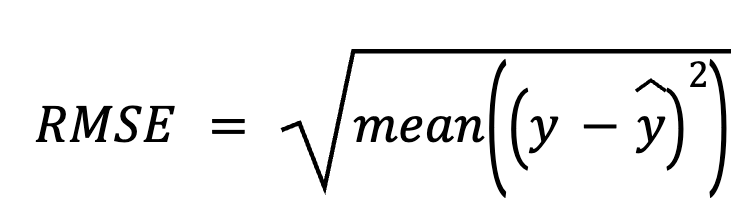
waarbij:
Deze directe benadering legt de nadruk op de voorspellingsfouten zelf.
Dit voelt als een herformulering, maar er zit meer achter: RMSE is simpelweg de vierkantswortel van de MSE.
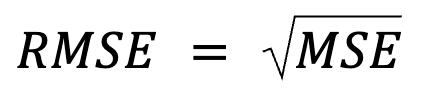
waarbij:
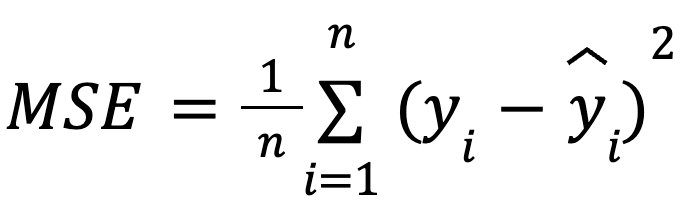
met:
Deze formulering is nuttig omdat MSE een veelgebruikte verliesfunctie is bij modeloptimalisatie. Deze gelijkwaardigheid is vooral belangrijk in machine learning, waar MSE vaak de verliesfunctie is die tijdens het trainen via gradient descent wordt geminimaliseerd.
Nog iets hierover: juist omdat RMSE een vierkantswortel introduceert, kiezen veel machinelearning-algoritmen ervoor om niet op RMSE te optimaliseren tijdens het trainen. MSE heeft de voorkeur voor deze optimalisaties omdat de afgeleiden eenvoudiger zijn (opnieuw: de wortel introduceert non-lineariteit). RMSE wordt vervolgens vaak achteraf gebruikt om prestaties te rapporteren in interpreteerbare eenheden.
Bij meervoudige regressie kan RMSE ook worden afgeleid uit de residualvector met matrixalgebra:
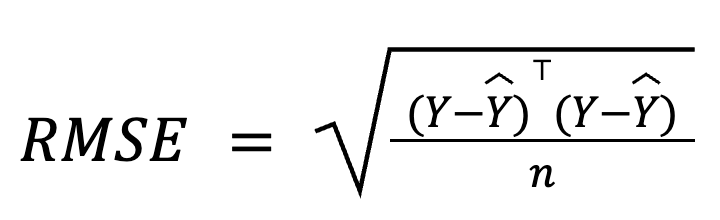
waarbij:
Deze matrixgebaseerde formulering is bijzonder compact en computationeel efficiënt, vooral voor grote datasets of modelpijplijnen. We hebben een speciale lineaire-algebra-cursus als je de wiskunde wilt bestuderen.
RMSE wordt geïnterpreteerd als de gemiddelde voorspellingsfout, die de nauwkeurigheid van het model bepaalt. Simpel gezegd: het laat zien hoe ver de voorspellingen gemiddeld van de werkelijke waarden afliggen, op dezelfde schaal als de uitkomstvariabele.
Een lagere RMSE suggereert kleinere gemiddelde voorspellingsfouten en dus nauwkeuriger voorspellingen, maar de “acceptabele” RMSE hangt volledig af van de context. Een RMSE van 2 kan bijvoorbeeld goed zijn bij het voorspellen van de amandelgrootte in millimeters, maar minder overtuigend bij het voorspellen van jaarlijkse amandelopbrengsten in tonnen.
Om betekenisvol te zijn, moet RMSE worden vergeleken tussen modellen die op dezelfde data zijn getraind of via benchmarking op historische prestaties.
RMSE is vooral handig in deze scenario’s:
RMSE heeft echter ook nadelen:
Laten we nu laten zien hoe je RMSE berekent in zowel Python als R met de Ice-Cream Sales Dataset van Kaggle. We bouwen twee modellen in elke programmeertaal en berekenen vervolgens de RMSE voor elk model:
Laten we beginnen met Python.
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# Load dataset
df = pd.read_csv("Ice Cream.csv")
# Extract features and target
X = df[['Temperature']]
y = df['Revenue']
# Model 1
model1 = LinearRegression()
model1.fit(X, y)
pred1 = model1.predict(X)
rmse1 = np.sqrt(mean_squared_error(y, pred1))
print(f"Model 1 RMSE: {rmse1:.3f}")
# Model 2 with an irrelevant predictor
np.random.seed(0)
df['Noise'] = np.random.normal(0, 1, size=len(df))
X2 = df[['Temperature', 'Noise']]
model2 = LinearRegression()
model2.fit(X2, y)
pred2 = model2.predict(X2)
rmse2 = np.sqrt(mean_squared_error(y, pred2))
print(f"Model 2 RMSE: {rmse2:.3f}")Model 1 RMSE: 24.915
Model 2 RMSE: 24.911
We zien dat de RMSE voor Model 2 erg lijkt op Model 1. Hoewel Model 2 complexer lijkt, kan de werkelijke voorspellingsnauwkeurigheid verslechteren omdat we willekeurige ruis hebben toegevoegd die geen nuttige informatie biedt.
Wil je je regressievaardigheden in Python naar een hoger niveau tillen? Schrijf je in voor deze cursussen:
Nu in R.
# Load dataset
df <- read.csv("Ice Cream.csv")
# Model 1
model1 <- lm(Revenue ~ Temperature, data = df)
pred1 <- predict(model1, df)
rmse1 <- sqrt(mean((df$Revenue - pred1)^2))
cat("Model 1 RMSE:", round(rmse1, 3), "\n")
# Model 2 with an irrelevant predictor
set.seed(0)
df$Noise <- rnorm(nrow(df), mean = 0, sd = 1)
model2 <- lm(Revenue ~ Temperature + Noise, data = df)
pred2 <- predict(model2, df)
rmse2 <- sqrt(mean((df$Revenue - pred2)^2))
cat("Model 2 RMSE:", round(rmse2, 3), "\n")Model 1 RMSE: 24.915
Model 2 RMSE: 24.915Hier heb ik hetzelfde voorbeeld in R uitgewerkt. De RMSE bleef exact gelijk toen we een irrelevante predictor toevoegden. Dit bevestigt dat RMSE niet altijd verandert bij het toevoegen van ruisvariabelen, vooral als het model ze een verwaarloosbaar gewicht geeft. De complexiteit neemt echter wel toe en het model kan slechter generaliseren naar nieuwe data.
Misschien viel je een klein verschil tussen de twee voorbeelden op: in Python daalde de RMSE licht na het toevoegen van de irrelevante predictor, terwijl in R de RMSE gelijk bleef. Dit komt doordat de willekeurige ruis die in elke omgeving werd gegenereerd (ook al kwam die uit dezelfde verdeling) niet identiek was.
Kreeg je je R-code niet aan de praat of had je moeite met de interpretatie? Probeer onze cursussen:
RMSE maakt deel uit van een bredere familie van regressiefoutmetrieke. Laten we het kort vergelijken met andere, de verschillen verduidelijken en benadrukken wanneer elk het meest nuttig is.
RMSE bestraft grote fouten zwaarder omdat het de residuals kwadrateert, waardoor het gevoeliger is voor uitschieters. MAE (mean absolute error) daarentegen is robuuster voor uitschieters, behandelt alle fouten gelijk en werkt beter om de typische foutgrootte te meten wanneer uitschieters geen zorg zijn. Terwijl RMSE de kwadratische verliesfunctie minimaliseert, minimaliseert MAE de absolute verliesfunctie.
In het algemeen gebruiken we RMSE wanneer grote fouten extra kostbaar kunnen zijn, en MAE wanneer we een mediaanachtige blik op de fout willen, minder gevoelig voor uitschieters.
RMSE geeft de gemiddelde fout in oorspronkelijke eenheden, wat het intuïtiever maakt voor praktische interpretatie. R-kwadraat daarentegen beschrijft hoeveel variantie door het model wordt verklaard, maar geeft de grootte van de voorspellingsfout niet aan.
Ze worden vaak samen gebruikt: R-kwadraat voor relatieve fit, en RMSE voor absolute prestatie.
RMSE is gewoon de vierkantswortel van MSE, waardoor het makkelijker te interpreteren is omdat het in dezelfde eenheden is als de uitkomstvariabele.
Los van de interpretatie is MSE vooral nuttig voor optimalisatie tijdens het trainen in machine learning. Onthoud: als je op RMSE zou optimaliseren, betekent de wortelfunctie dat het model meer nadruk legt op grotere fouten. Bovendien heeft MSE een gladde afgeleide, waardoor het goed werkt met gradiëntgebaseerde algoritmen zoals stochastische gradient descent, wat efficiënte convergentie tijdens het trainen mogelijk maakt. Kort gezegd: RMSE is makkelijker te interpreteren omdat we resultaten op de schaal van de data bekijken, maar deep learning optimaliseert vaak MSE, niet RMSE.
MAPE (mean absolute percentage error) geeft fouten terug als percentages, wat handig is voor vergelijken tussen datasets. Het gaat echter mis wanneer werkelijke waarden dicht bij nul liggen, waardoor het instabiel wordt. RMSE omzeilt dit probleem en is betrouwbaarder wanneer er kleine doelwaarden aanwezig zijn.
Hier is nog een interessante relatie: RMSE is formeel equivalent aan de negatieve log‑likelihood onder Gaussische fouten. Of beter gezegd: het minimaliseren van RMSE is equivalent aan het maximaliseren van de log-likelihood (van een regressiemodel) onder de aanname van normaal verdeelde fouten (met constante variantie). Ik zeg niet dat RMSE op zichzelf de volledige log-likelihood schat, maar wel dat het minimaliseren van RMSE impliciet de log-likelihood maximaliseert onder een normale foutaanname.
Wanneer fouten echter scheef verdeeld zijn of uitschieters bevatten, kunnen alternatieven zoals Huber- of kwantielverlies beter presteren. Hoe dan ook, we moeten onze metriekkeuze zien als een modelontwerpbeslissing, niet als een bijzaak.
Laten we enkele wijdverbreide mythes over RMSE verduidelijken:
Kortom, RMSE is een praktische, interpreteerbare en intuïtieve maat voor voorspellingsnauwkeurigheid die de gemiddelde voorspellingsfout in de eenheden van de doelvariabele communiceert. Het is een veelgebruikte metriek voor het evalueren van regressieprestaties, vooral wanneer foutgroottes ertoe doen.
RMSE moet echter worden gebruikt naast andere metrieke zoals R-kwadraat, MAE en cross-validatiescores om een vollediger beeld van de modelkwaliteit te krijgen. We moeten niet blind op deze maat vertrouwen, maar altijd schaal, context en modelcomplexiteit meenemen. Daarnaast kan het combineren van RMSE met visuele diagnostiek helpen om bias te detecteren.
Kort gezegd: RMSE vertelt ons hoe ver ons model er gemiddeld naast zit, in echte termen — een krachtige manier van kijken bij het bouwen van predictieve systemen.
Als iets in dit artikel verwarrend was, geen zorgen. We hebben veel goede resources om je te helpen:
Leer met DataCamp
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
