
Program
Associate Data Scientist dalam Python
90 Hr
Regresi linear adalah teknik fundamental dalam statistika dan machine learning yang membantu memodelkan hubungan antar variabel. Secara sederhana, teknik ini memungkinkan kita memprediksi suatu keluaran berdasarkan satu atau lebih faktor yang memengaruhinya. Metode ini banyak diterapkan dalam penetapan harga properti, peramalan penjualan, penilaian risiko, dan banyak bidang lainnya.
Dalam tutorial ini, kita akan membahas regresi linear di scikit-learn, mencakup cara kerjanya, mengapa teknik ini berguna, dan bagaimana mengimplementasikannya menggunakan scikit-learn. Di akhir, Anda akan mampu membangun dan mengevaluasi model regresi linear untuk membuat prediksi berbasis data.
Scatter plot Harga Rumah versus Jumlah Kamar
Di luar kegunaannya yang langsung untuk menentukan harga rumah, regresi linear memainkan peran penting dalam machine learning.
Terlepas dari kesederhanaannya, regresi linear tetap merupakan alat yang tak tergantikan dalam machine learning karena efisiensi, keterjelasan, dan fleksibilitasnya.
Pustaka scikit-learn memudahkan implementasi regresi linear. Pustaka ini memiliki banyak keunggulan.
model.fit(X_train, y_train).Jika Anda baru mengenal scikit-learn, Anda dapat melihat kursus kami tentang Machine Learning dengan scikit-learn untuk pengenalan langsung ke pustaka Python ini.
Seperti yang telah kita lihat, dalam regresi linear sederhana, data dimodelkan menggunakan "garis best-fit." Rumus untuk garis ini adalah:
![]()
di mana m adalah kemiringan garis dan b adalah intersep.
"Regresi linear berganda" menggeneralisasi kasus satu prediktor menjadi beberapa prediktor (jumlah kamar, kedekatan dengan laut, pendapatan median lingkungan). Rumusnya digeneralisasi menjadi:
![]()
di mana setiap xi adalah variabel bebas dan bi yang bersesuaian adalah koefisiennya. Dalam tiga dimensi, garis digeneralisasi menjadi bidang. Dalam dimensi yang lebih tinggi, bidang menjadi "hiperbidang."
Bagaimana kita menafsirkan koefisien dan intersep? Intersep adalah nilai prediksi y ketika semua variabel bebas bernilai 0, atau dengan kata lain, nilai dasar dari variabel terikat ketika tidak ada kontribusi dari prediktor. Setiap koefisien bi merepresentasikan perubahan pada variabel terikat y untuk perubahan satu satuan pada xi, dengan menahan konstan semua variabel bebas lainnya.
Menginstal scikit-learn itu mudah. Cukup gunakan perintah pip install scikit-learn. Jika Anda ingin menginstal versi tertentu, misalnya 1.2.2, ubah perintahnya untuk menyertakan versinya: pip install scikit-learn==1.2.2. Jika Anda menggunakan Anaconda, scikit-learn seharusnya sudah terpasang. Jika karena suatu alasan Anda masih perlu memasangnya saat menggunakan distribusi Anaconda, gunakan perintah conda install scikit-learn.
Beberapa pustaka diperlukan atau direkomendasikan saat menggunakan scikit-learn. Pustaka numpy diperlukan untuk menyimpan fitur dan label. Pustaka pandas direkomendasikan untuk memuat, melakukan prapemrosesan, dan mengeksplorasi dataset.
Jika Anda menggunakan scikit-learn, kemungkinan besar Anda sudah menggunakan pandas untuk persiapan data. Untuk memplot hasil, Anda mungkin akan menggunakan matplotlib atau seaborn atau keduanya. Pustaka-pustaka ini dapat dipasang menggunakan pip install, seperti pada contoh di atas. Anda bahkan dapat memasang beberapa pustaka menggunakan satu perintah:
pip install scikit-learn numpy pandas matplotlib seaborn.
Sebelum kita memuat dataset, mari impor pustaka yang biasa digunakan.
# Import libraries.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as snsMari gunakan dataset perumahan California yang terkenal.
# Read in California housing dataset.
from sklearn.datasets import fetch_california_housing
housing = fetch_california_housing()Mari bagi data menjadi himpunan pelatihan dan pengujian. Kita mengimpor metode train_test_split() dari sklearn.model_selection, lalu memanggilnya dengan menentukan persentase set uji, dan random_state. Kita juga akan menggunakan regresi linear sederhana, memakai fitur yang berkaitan dengan rata-rata jumlah kamar.
# Import train_test_split.
from sklearn.model_selection import train_test_split
# Create features X and target y.
X = pd.DataFrame(housing.data, columns=housing.feature_names)[["AveRooms"]]
y = housing.target # Median house value in $100,000s
# Split the dataset into training (80%) and testing (20%) sets.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)Sekarang setelah kita membagi data menjadi set uji dan latih, mari melakukan standarisasi fitur. Proses ini memastikan semua variabel berada pada skala yang sama, yang dapat meningkatkan kinerja model dan stabilitas numerik.
# Import StandardScaler.
from sklearn.preprocessing import StandardScaler
# Instantiate StandardScaler.
scaler = StandardScaler()
# Fit and transform training data.
X_train_scaled = scaler.fit_transform(X_train)
# Also transform test data.
X_test_scaled = scaler.transform(X_test)Dalam kode ini, StandardScaler adalah alat prapemrosesan data yang digunakan untuk menghilangkan mean dan menskalakan fitur ke varians satuan. Ini membantu mencegah fitur tertentu mendominasi model karena perbedaan skala.
Scaler di-fit pada data pelatihan menggunakan metode fit_transform(). Data uji kemudian diubah secara terpisah menggunakan metode transform() untuk memastikan penskalaan menggunakan faktor yang sama dengan data pelatihan, sehingga mencegah kebocoran data.
Untuk membuat model regresi linear, impor LinearRegression() dari sklearn.linear_model. Panggil dan tetapkan ke sebuah variabel.
# Import LinearRegression.
from sklearn.linear_model import LinearRegression
# Instantiate linear regression model.
model = LinearRegression()Melatih model dengan data pelatihan sangatlah mudah.
# Fit the model to the training data.
model.fit(X_train_scaled, y_train)Sekarang setelah kita melatih model, kita lakukan prediksi pada set uji.
# Make predictions on the testing data.
y_pred = model.predict(X_test_scaled)Setelah kita membuat prediksi pada set uji, kita perlu mengetahui seberapa baik hasilnya sesuai dengan kenyataan. Ada beberapa metrik yang tersedia untuk mengevaluasi kinerja algoritme regresi. Beberapa yang paling umum adalah koefisien determinasi (R2), mean squared error (MSE), dan root mean squared error (RMSE).
Koefisien determinasi, dilambangkan R2, mengukur seberapa baik model regresi menjelaskan variabilitas variabel target. Dengan kata lain, metrik ini mengkuantifikasi seberapa besar variabilitas pada variabel target yang dijelaskan oleh prediktor, yang dikenal sebagai goodness of fit.
Untuk lebih memahaminya, mari lihat rumusnya:
![]()
di mana yactual adalah nilai aktual variabel target, ypredicted adalah nilai prediksi dari model, dan ȳ adalah mean dari nilai aktual. Rumus ini membantu kita memahami seberapa banyak varians pada variabel target yang dijelaskan oleh model. Penyebut mewakili total varians dalam data, sementara pembilang mewakili varians yang tidak terjelaskan setelah menerapkan model regresi. Rasionya, oleh karena itu, memberikan persentase varians yang dijelaskan oleh model.
Bagaimana menafsirkan R2?
Beberapa hal penting untuk diingat.
Mengevaluasi kinerja model menggunakan koefisien determinasi mudah dilakukan dengan scikit-learn.
# Import metrics.
from sklearn.metrics import mean_squared_error, r2_score
# Calculate and print R^2 score.
r2 = r2_score(y_test, y_pred)
print(f"R-squared: {r2:.4f}")R-squared: 0.0138Metrik lain yang umum digunakan adalah mean squared error (MSE) dan root mean squared error (RMSE). Metrik ini mengukur seberapa jauh prediksi model menyimpang dari nilai aktual.
MSE menghitung rata-rata selisih kuadrat antara nilai aktual dan prediksi:
untuk jumlah observasi total n. Karena error dikuadratkan sebelum dirata-ratakan, error yang lebih besar mendapatkan penalti lebih tinggi dibanding error yang lebih kecil, sehingga MSE sensitif terhadap pencilan. MSE yang lebih rendah menandakan kecocokan model yang lebih baik.
Untuk mengatasi hal ini, digunakan RMSE, yang merupakan akar kuadrat dari MSE. Karena RMSE berada dalam satuan yang sama dengan variabel target, metrik ini memberikan ukuran yang lebih mudah ditafsirkan tentang seberapa jauh prediksi meleset, rata-rata.
Menghitung MSE dan RMSE mudah dilakukan dengan scikit-learn.
# Calculate and print MSE.
mse = mean_squared_error(y_test, y_pred)
print(f"Mean squared error: {mse:.4f}")
# Calculate and print RMSE.
rmse = mse ** 0.5
print(f"Root mean squared error: {rmse:.4f}")Mean squared error: 1.2923
Root mean squared error: 1.1368Mari jalankan ulang model menggunakan semua fitur yang tersedia, bukan hanya rata-rata jumlah kamar. Apakah Anda memperkirakan hasilnya lebih baik atau lebih buruk?
# Uses all features.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# Load data set.
housing = fetch_california_housing()
# Split into X, y.
X = pd.DataFrame(housing.data, columns=housing.feature_names)
y = housing.target # Median house value in $100,000s
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Scale the data.
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Create model and fit it to the training data.
model = LinearRegression()
model.fit(X_train_scaled, y_train)
# Make predictions.
y_pred = model.predict(X_test_scaled)
# Calculate and print errors.
r2 = r2_score(y_test, y_pred)
print(f"R-squared: {r2:.4f}")
mse = mean_squared_error(y_test, y_pred)
print(f"Mean squared error: {mse:.4f}")
rmse = mse ** 0.5
print(f"Root mean squared error: {rmse:.4f}")R-squared: 0.5758
Mean squared error: 0.5559
Root mean squared error: 0.7456Kita melihat hasilnya jauh lebih baik dibanding ketika hanya menggunakan satu fitur. Namun, ini menimbulkan pertanyaan apakah kita memerlukan semua fitur. Apakah beberapa fitur lebih relevan daripada yang lain? Memilih fitur yang paling relevan dari dataset dikenal sebagai seleksi fitur.
Seleksi fitur penting karena beberapa alasan.
Ketika beberapa fitur memiliki korelasi tinggi, fitur-fitur tersebut bersifat redundan, artinya pada dasarnya memberikan informasi yang sama kepada model. Situasi ini disebut sebagai multikolinearitas. Meskipun multikolinearitas tidak selalu memengaruhi akurasi model prediktif, hal ini mempersulit seleksi fitur dan penafsiran, khususnya pada regresi linear dan model terkait.
Variance Inflation Factor (VIF) adalah metrik yang digunakan untuk mendeteksi multikolinearitas di antara prediktor. Untuk setiap prediktor, VIF dihitung sebagai:
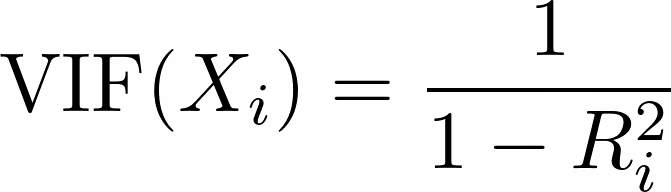
di mana Ri2 adalah nilai R2 yang diperoleh ketika prediktor Xi diregresikan terhadap semua prediktor lain dalam model. VIF yang lebih tinggi berarti prediktor tersebut sangat berkorelasi dengan variabel lainnya.
# Import libraries.
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_california_housing
from statsmodels.stats.outliers_influence import variance_inflation_factor
# Load the dataset.
housing = fetch_california_housing()
X = pd.DataFrame(housing.data, columns=housing.feature_names)
# Compute the correlation matrix.
corr_matrix = X.corr()
# Identify pairs of features with high collinearity (correlation > 0.8 or < -0.8).
high_corr_features = [(col1, col2, corr_matrix.loc[col1, col2])
for col1 in corr_matrix.columns
for col2 in corr_matrix.columns
if col1 != col2 and abs(corr_matrix.loc[col1, col2]) > 0.8]
# Convert to a DataFrame for better visualization.
collinearity_df = pd.DataFrame(high_corr_features, columns=["Feature 1", "Feature 2", "Correlation"])
print("\nHighly Correlated Features:\n", collinearity_df)
# Compute Variance Inflation Factor (VIF) for each feature.
vif_data = pd.DataFrame()
vif_data["Feature"] = X.columns
vif_data["VIF"] = [variance_inflation_factor(X.values, i) for i in range(X.shape[1])]
# Print VIF values.
print("\nVariance Inflation Factor (VIF) for each feature:\n", vif_data) Highly Correlated Features:
Feature 1 Feature 2 Correlation
0 AveRooms AveBedrms 0.847621
1 AveBedrms AveRooms 0.847621
2 Latitude Longitude -0.924664
3 Longitude Latitude -0.924664
Variance Inflation Factor (VIF) for each feature:
Feature VIF
0 MedInc 11.511140
1 HouseAge 7.195917
2 AveRooms 45.993601
3 AveBedrms 43.590314
4 Population 2.935745
5 AveOccup 1.095243
6 Latitude 559.874071
7 Longitude 633.711654Mari kita hapus AveBedrms dari model.
# Import libraries.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# Load California housing dataset.
housing = fetch_california_housing()
# Create DataFrame and remove "AveBedrms" feature.
X = pd.DataFrame(housing.data, columns=housing.feature_names).drop(columns=["AveBedrms"])
y = housing.target # Median house value in $100,000s
# Split data into training and testing sets.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Scale the data (Standardization).
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Create a linear regression model and train it.
model = LinearRegression()
model.fit(X_train_scaled, y_train)
# Make predictions on the test set.
y_pred = model.predict(X_test_scaled)
# Calculate performance metrics.
r2 = r2_score(y_test, y_pred)
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
# Print evaluation metrics
print(f"R-squared: {r2:.4f}")
print(f"Mean squared error: {mse:.4f}")
print(f"Root mean squared error: {rmse:.4f}")R-squared: 0.5823
Mean squared error: 0.5473
Root mean squared error: 0.7398Hasilnya (sedikit) membaik.
Membangun model regresi hanyalah langkah pertama; memahami keluarannya sama pentingnya. Dengan menganalisis koefisien model, kita dapat menentukan fitur mana yang paling berpengaruh terhadap prediksi.
Setelah model regresi linear dilatih, koefisien dapat diakses menggunakan model.coef_. Intersep dapat diakses menggunakan model.intercept_.
Setelah model regresi linear dilatih menggunakan LinearRegression(), koefisien dapat diakses menggunakan model.coef_ dan intersep dapat diakses menggunakan model.intercept_.
print("Intercept:", model.intercept_)
coeff_df = pd.DataFrame({"Feature": X.columns, "Coefficient": model.coef_})
print("\nFeature Coefficients:\n", coeff_df) Intercept: 2.0719469373788777
Feature Coefficients:
Feature Coefficient
0 MedInc 0.725747
1 HouseAge 0.121519
2 Latitude -0.943105
3 Longitude -0.900735Karena Scikit-Learn tidak menyediakan metode bawaan summary() seperti Statsmodels, kita dapat mengekstrak dan memvisualisasikan pentingnya setiap fitur secara manual menggunakan koefisien regresi. Fitur dengan nilai mutlak koefisien yang lebih besar memiliki dampak yang lebih kuat pada variabel target. Pertimbangkan kode berikut.
# Sort dataframe by coefficients.
coef_df_sorted = coef_df.sort_values(by="Coefficient", ascending=False)
# Create plot.
plt.figure(figsize=(8,6))
plt.barh(coef_df["Feature"], coef_df_sorted["Coefficient"], color="blue")
plt.xlabel("Coefficient Value")
plt.ylabel("Feature")
plt.title("Feature Importance (Linear Regression Coefficients)")
plt.show()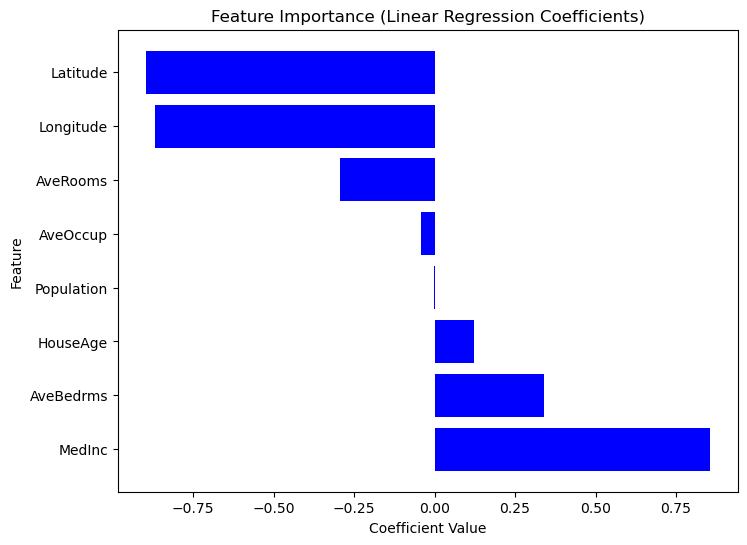
Grafik Pentingnya Fitur Berdasarkan Nilai Koefisien
Sekarang, mari visualisasikan residual dan kecocokan regresi.
# Compute residuals.
residuals = y_test - y_pred
# Create plots.
plt.figure(figsize=(12,5))
# Plot 1: Residuals Distribution.
plt.subplot(1,2,1)
sns.histplot(residuals, bins=30, kde=True, color="blue")
plt.axvline(x=0, color='red', linestyle='--')
plt.title("Residuals Distribution")
plt.xlabel("Residuals (y_actual - y_predicted)")
plt.ylabel("Frequency")
# Plot 2: Regression Fit (Actual vs Predicted).
plt.subplot(1,2,2)
sns.scatterplot(x=y_test, y=y_pred, alpha=0.5)
plt.plot([min(y_test), max(y_test)], [min(y_test), max(y_test)], color='red', linestyle='--') # Perfect fit line
plt.title("Regression Fit: Actual vs Predicted")
plt.xlabel("Actual Prices (in $100,000s)")
plt.ylabel("Predicted Prices (in $100,000s)")
# Show plots.
plt.tight_layout()
plt.show()
Plot untuk Memvisualisasikan Residual dan Kecocokan Regresi
Distribusi residual (plot kiri) seharusnya terpusat di sekitar nol, menandakan bahwa error terdistribusi secara acak. Jika residual mengikuti distribusi normal, model cocok dengan baik, tetapi jika ada kemiringan atau tren, hal ini dapat menunjukkan error sistematis. Kecocokan regresi (plot kanan) membandingkan nilai aktual vs. prediksi, dengan garis putus-putus merah mewakili kecocokan sempurna. Jika titik-titik mengikuti garis dengan rapat, prediksi akurat, tetapi jika muncul pola (misalnya, kurva), hubungan tersebut mungkin tidak benar-benar linear.
Visualisasi ini membantu mendiagnosis overfitting atau underfitting, mengungkap pola pada residual yang menunjukkan relasi yang terlewat, dan memberikan penilaian yang jelas tentang efektivitas model.
Regresi linear banyak digunakan lintas industri untuk prediksi dan pengambilan keputusan. Dalam properti, teknik ini memperkirakan harga rumah berdasarkan faktor seperti ukuran dan lokasi.
Penjualan dan pemasaran menggunakannya untuk peramalan permintaan dan optimasi anggaran, sementara layanan kesehatan menerapkannya untuk penilaian risiko penyakit. Dalam keuangan, teknik ini membantu prediksi harga saham dan penilaian kredit, dan dalam manufaktur, teknik ini membantu pengendalian kualitas dan prediksi kegagalan.
Regresi linear tetap menjadi salah satu teknik yang paling fundamental dan paling banyak digunakan dalam machine learning dan pemodelan statistik. Meskipun sederhana, teknik ini merupakan alat yang kuat untuk memahami hubungan antar variabel dan membuat prediksi dalam berbagai aplikasi dunia nyata.
Berikut adalah poin-poin penting dari tutorial ini:
Untuk informasi lebih lanjut tentang interpolasi string Python, lihat sumber daya DataCamp.
Kursus Teratas di DataCamp
Program
Kursus
Kursus
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
