
Tracks
Chuyên viên phân tích dữ liệu trong Python
90 giờ
Hồi quy tuyến tính là một kỹ thuật nền tảng trong thống kê và học máy giúp mô hình hóa mối quan hệ giữa các biến. Nói đơn giản, nó cho phép chúng ta dự đoán một kết quả dựa trên một hoặc nhiều yếu tố ảnh hưởng. Phương pháp này được ứng dụng rộng rãi trong định giá bất động sản, dự báo doanh số, đánh giá rủi ro và nhiều lĩnh vực khác.
Trong hướng dẫn này, chúng ta sẽ khám phá hồi quy tuyến tính trong scikit-learn, bao gồm cách hoạt động, lý do hữu ích và cách triển khai bằng scikit-learn. Kết thúc bài, bạn sẽ có thể xây dựng và đánh giá một mô hình hồi quy tuyến tính để đưa ra dự đoán dựa trên dữ liệu.
Biểu đồ phân tán Giá nhà theo Số phòng
Vượt ra ngoài tính hữu ích tức thì trong việc xác định giá nhà, hồi quy tuyến tính đóng vai trò quan trọng trong học máy.
Dù đơn giản, hồi quy tuyến tính vẫn là công cụ không thể thiếu trong học máy nhờ hiệu quả, khả năng diễn giải và tính linh hoạt.
Thư viện scikit-learn giúp việc triển khai hồi quy tuyến tính trở nên dễ dàng. Thư viện này có nhiều ưu điểm.
model.fit(X_train, y_train).Nếu bạn mới dùng scikit-learn, bạn có thể xem khóa học Machine Learning với scikit-learn để có phần giới thiệu thực hành về thư viện Python này.
Như đã thấy, trong hồi quy tuyến tính đơn, dữ liệu được mô hình hóa bằng một "đường thẳng khớp tốt nhất". Công thức của đường thẳng này là:
![]()
trong đó m là độ dốc của đường thẳng và b là hệ số chặn.
"Hồi quy tuyến tính bội" tổng quát hóa trường hợp một biến dự báo thành nhiều biến dự báo (số phòng, gần biển, thu nhập trung vị của khu vực). Công thức được tổng quát thành:
![]()
trong đó mỗi xi là một biến độc lập và bi tương ứng là hệ số của nó. Trong không gian ba chiều, đường thẳng được tổng quát thành một mặt phẳng. Ở số chiều cao hơn, mặt phẳng trở thành một "siêu phẳng".
Diễn giải các hệ số và hệ số chặn như thế nào? Hệ số chặn là giá trị dự đoán của y khi tất cả biến độc lập bằng 0, hay nói cách khác là giá trị cơ sở của biến phụ thuộc khi không có đóng góp từ các biến dự báo. Mỗi hệ số bi biểu thị mức thay đổi của biến phụ thuộc y khi xi thay đổi một đơn vị, giữ các biến độc lập khác không đổi.
Cài đặt scikit-learn rất dễ. Chỉ cần dùng lệnh pip install scikit-learn. Nếu bạn muốn cài đúng một phiên bản, ví dụ 1.2.2, thì thêm phiên bản vào lệnh: pip install scikit-learn==1.2.2. Nếu bạn dùng Anaconda, scikit-learn thường đã được cài sẵn. Nếu vì lý do nào đó bạn vẫn cần cài khi dùng bản phân phối Anaconda, hãy dùng lệnh conda install scikit-learn.
Một số thư viện là cần thiết hoặc được khuyến nghị khi dùng scikit-learn. Thư viện numpy cần để lưu trữ đặc trưng và nhãn. Thư viện pandas được khuyến nghị để tải, tiền xử lý và khám phá dữ liệu.
Nếu bạn dùng scikit-learn, rất có thể bạn cũng đang dùng pandas cho việc chuẩn bị dữ liệu. Để vẽ biểu đồ kết quả, bạn sẽ dùng matplotlib hoặc seaborn hoặc cả hai. Bất kỳ thư viện nào trong số này đều có thể cài bằng pip install, tương tự ví dụ trên. Bạn thậm chí có thể cài nhiều thư viện bằng một lệnh:
pip install scikit-learn numpy pandas matplotlib seaborn.
Trước khi tải bộ dữ liệu, hãy import những thư viện quen thuộc.
# Import libraries.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as snsHãy dùng bộ dữ liệu nhà ở California nổi tiếng.
# Read in California housing dataset.
from sklearn.datasets import fetch_california_housing
housing = fetch_california_housing()Hãy chia dữ liệu thành tập huấn luyện và tập kiểm tra. Chúng ta import phương thức train_test_split() từ sklearn.model_selection, sau đó gọi nó, chỉ định tỷ lệ tập kiểm tra và random_state. Chúng ta cũng sẽ dùng hồi quy tuyến tính đơn, sử dụng đặc trưng tương ứng với số phòng trung bình.
# Import train_test_split.
from sklearn.model_selection import train_test_split
# Create features X and target y.
X = pd.DataFrame(housing.data, columns=housing.feature_names)[["AveRooms"]]
y = housing.target # Median house value in $100,000s
# Split the dataset into training (80%) and testing (20%) sets.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)Giờ đây khi đã chia dữ liệu thành tập kiểm tra và tập huấn luyện, hãy chuẩn hóa các đặc trưng. Quá trình này đảm bảo mọi biến nằm trên cùng một thang đo, có thể cải thiện hiệu năng mô hình và độ ổn định số học.
# Import StandardScaler.
from sklearn.preprocessing import StandardScaler
# Instantiate StandardScaler.
scaler = StandardScaler()
# Fit and transform training data.
X_train_scaled = scaler.fit_transform(X_train)
# Also transform test data.
X_test_scaled = scaler.transform(X_test)Trong đoạn mã này, StandardScaler là công cụ tiền xử lý dữ liệu dùng để loại bỏ trung bình và chuẩn hóa phương sai về 1. Điều này giúp ngăn một số đặc trưng chi phối mô hình do khác biệt về thang đo.
Bộ chuẩn hóa được fit trên dữ liệu huấn luyện bằng phương thức fit_transform(). Dữ liệu kiểm tra sau đó được biến đổi riêng bằng transform() để đảm bảo dùng cùng các hệ số chuẩn hóa như dữ liệu huấn luyện, tránh rò rỉ dữ liệu.
Để tạo mô hình hồi quy tuyến tính, import LinearRegression() từ sklearn.linear_model. Khởi tạo và gán cho một biến.
# Import LinearRegression.
from sklearn.linear_model import LinearRegression
# Instantiate linear regression model.
model = LinearRegression()Fit mô hình với dữ liệu huấn luyện rất đơn giản.
# Fit the model to the training data.
model.fit(X_train_scaled, y_train)Giờ khi đã huấn luyện mô hình, chúng ta tạo dự đoán trên tập kiểm tra.
# Make predictions on the testing data.
y_pred = model.predict(X_test_scaled)Sau khi đã dự đoán trên tập kiểm tra, chúng ta cần biết mức độ khớp với thực tế. Có một số thước đo để đánh giá hiệu năng của thuật toán hồi quy. Phổ biến nhất là hệ số xác định (R2), sai số bình phương trung bình (MSE) và căn sai số bình phương trung bình (RMSE).
Hệ số xác định, ký hiệu R2, đo lường mức độ mô hình hồi quy giải thích được biến động của biến mục tiêu. Nói cách khác, nó định lượng mức độ biến động của biến mục tiêu được giải thích bởi các biến dự báo, còn gọi là độ phù hợp.
Để hiểu rõ hơn, hãy xem công thức:
![]()
trong đó yactual là các giá trị thực của biến mục tiêu, ypredicted là các giá trị dự đoán từ mô hình, và ȳ là giá trị trung bình của các giá trị thực. Công thức này giúp ta hiểu bao nhiêu phần phương sai trong biến mục tiêu được mô hình giải thích. Mẫu số biểu diễn tổng phương sai trong dữ liệu, còn tử số biểu diễn phần phương sai chưa được giải thích sau khi áp dụng mô hình hồi quy. Do đó, tỷ lệ này cho biết phần trăm phương sai được mô hình giải thích.
Diễn giải R2 như thế nào?
Một số điểm cần lưu ý.
Đánh giá hiệu năng mô hình bằng hệ số xác định rất dễ với scikit-learn.
# Import metrics.
from sklearn.metrics import mean_squared_error, r2_score
# Calculate and print R^2 score.
r2 = r2_score(y_test, y_pred)
print(f"R-squared: {r2:.4f}")R-squared: 0.0138Các thước đo phổ biến khác là sai số bình phương trung bình (MSE) và căn sai số bình phương trung bình (RMSE). Các thước đo này đo lường mức độ sai lệch giữa dự đoán của mô hình và giá trị thực.
MSE tính trung bình bình phương chênh lệch giữa giá trị thực và giá trị dự đoán:
cho tổng số quan sát n. Vì sai số được bình phương trước khi lấy trung bình, các sai số lớn bị phạt nặng hơn sai số nhỏ, khiến MSE nhạy cảm với ngoại lệ. MSE thấp hơn cho thấy mô hình khớp tốt hơn.
Để khắc phục vấn đề này, người ta dùng RMSE, đơn giản là căn bậc hai của MSE. Vì RMSE có cùng đơn vị với biến mục tiêu, nó cung cấp thước đo dễ diễn giải hơn về mức độ sai lệch trung bình của dự đoán.
Tính MSE và RMSE với scikit-learn rất dễ.
# Calculate and print MSE.
mse = mean_squared_error(y_test, y_pred)
print(f"Mean squared error: {mse:.4f}")
# Calculate and print RMSE.
rmse = mse ** 0.5
print(f"Root mean squared error: {rmse:.4f}")Mean squared error: 1.2923
Root mean squared error: 1.1368Hãy chạy lại mô hình với tất cả các đặc trưng sẵn có, không chỉ số phòng trung bình. Bạn kỳ vọng kết quả tốt hơn hay tệ hơn?
# Uses all features.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# Load data set.
housing = fetch_california_housing()
# Split into X, y.
X = pd.DataFrame(housing.data, columns=housing.feature_names)
y = housing.target # Median house value in $100,000s
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Scale the data.
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Create model and fit it to the training data.
model = LinearRegression()
model.fit(X_train_scaled, y_train)
# Make predictions.
y_pred = model.predict(X_test_scaled)
# Calculate and print errors.
r2 = r2_score(y_test, y_pred)
print(f"R-squared: {r2:.4f}")
mse = mean_squared_error(y_test, y_pred)
print(f"Mean squared error: {mse:.4f}")
rmse = mse ** 0.5
print(f"Root mean squared error: {rmse:.4f}")R-squared: 0.5758
Mean squared error: 0.5559
Root mean squared error: 0.7456Ta thấy kết quả tốt hơn khá nhiều so với khi chỉ dùng một đặc trưng. Tuy nhiên, điều này đặt ra câu hỏi liệu chúng ta có cần tất cả các đặc trưng không. Có đặc trưng nào liên quan hơn các đặc trưng khác không? Việc chọn ra các đặc trưng liên quan nhất từ bộ dữ liệu được gọi là chọn đặc trưng.
Chọn đặc trưng quan trọng vì một số lý do.
Khi nhiều đặc trưng có tương quan cao, chúng là dư thừa, tức là chúng cung cấp cho mô hình thông tin gần như giống nhau. Tình huống này gọi là đa cộng tuyến. Dù đa cộng tuyến không phải lúc nào cũng ảnh hưởng đến độ chính xác của mô hình dự báo, nó làm phức tạp việc chọn đặc trưng và diễn giải, đặc biệt trong hồi quy tuyến tính và các mô hình liên quan.
Hệ số Phóng đại Phương sai (VIF) là thước đo dùng để phát hiện đa cộng tuyến giữa các biến dự báo. Với mỗi biến dự báo, VIF được tính như sau:
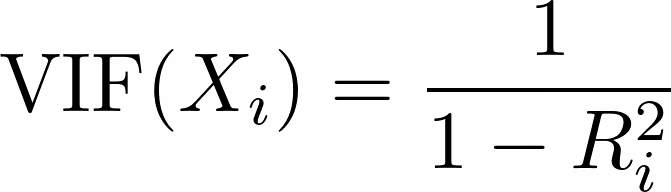
trong đó Ri2 là giá trị R2 thu được khi biến dự báo Xi được hồi quy theo tất cả các biến dự báo còn lại trong mô hình. VIF cao hơn nghĩa là biến dự báo tương quan mạnh với các biến khác.
# Import libraries.
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_california_housing
from statsmodels.stats.outliers_influence import variance_inflation_factor
# Load the dataset.
housing = fetch_california_housing()
X = pd.DataFrame(housing.data, columns=housing.feature_names)
# Compute the correlation matrix.
corr_matrix = X.corr()
# Identify pairs of features with high collinearity (correlation > 0.8 or < -0.8).
high_corr_features = [(col1, col2, corr_matrix.loc[col1, col2])
for col1 in corr_matrix.columns
for col2 in corr_matrix.columns
if col1 != col2 and abs(corr_matrix.loc[col1, col2]) > 0.8]
# Convert to a DataFrame for better visualization.
collinearity_df = pd.DataFrame(high_corr_features, columns=["Feature 1", "Feature 2", "Correlation"])
print("\nHighly Correlated Features:\n", collinearity_df)
# Compute Variance Inflation Factor (VIF) for each feature.
vif_data = pd.DataFrame()
vif_data["Feature"] = X.columns
vif_data["VIF"] = [variance_inflation_factor(X.values, i) for i in range(X.shape[1])]
# Print VIF values.
print("\nVariance Inflation Factor (VIF) for each feature:\n", vif_data) Highly Correlated Features:
Feature 1 Feature 2 Correlation
0 AveRooms AveBedrms 0.847621
1 AveBedrms AveRooms 0.847621
2 Latitude Longitude -0.924664
3 Longitude Latitude -0.924664
Variance Inflation Factor (VIF) for each feature:
Feature VIF
0 MedInc 11.511140
1 HouseAge 7.195917
2 AveRooms 45.993601
3 AveBedrms 43.590314
4 Population 2.935745
5 AveOccup 1.095243
6 Latitude 559.874071
7 Longitude 633.711654Hãy loại bỏ AveBedrms khỏi mô hình.
# Import libraries.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# Load California housing dataset.
housing = fetch_california_housing()
# Create DataFrame and remove "AveBedrms" feature.
X = pd.DataFrame(housing.data, columns=housing.feature_names).drop(columns=["AveBedrms"])
y = housing.target # Median house value in $100,000s
# Split data into training and testing sets.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Scale the data (Standardization).
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Create a linear regression model and train it.
model = LinearRegression()
model.fit(X_train_scaled, y_train)
# Make predictions on the test set.
y_pred = model.predict(X_test_scaled)
# Calculate performance metrics.
r2 = r2_score(y_test, y_pred)
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
# Print evaluation metrics
print(f"R-squared: {r2:.4f}")
print(f"Mean squared error: {mse:.4f}")
print(f"Root mean squared error: {rmse:.4f}")R-squared: 0.5823
Mean squared error: 0.5473
Root mean squared error: 0.7398Kết quả được cải thiện (nhẹ).
Xây dựng mô hình hồi quy chỉ là bước đầu; hiểu các đầu ra của nó cũng quan trọng không kém. Bằng cách phân tích các hệ số của mô hình, chúng ta có thể xác định đặc trưng nào có tác động lớn nhất đến dự đoán.
Khi mô hình hồi quy tuyến tính đã được huấn luyện, có thể truy cập các hệ số bằng model.coef_. Hệ số chặn có thể truy cập bằng model.intercept_.
Khi một mô hình hồi quy tuyến tính được huấn luyện bằng LinearRegression(), các hệ số có thể truy cập bằng model.coef_ và hệ số chặn có thể truy cập bằng model.intercept_.
print("Intercept:", model.intercept_)
coeff_df = pd.DataFrame({"Feature": X.columns, "Coefficient": model.coef_})
print("\nFeature Coefficients:\n", coeff_df) Intercept: 2.0719469373788777
Feature Coefficients:
Feature Coefficient
0 MedInc 0.725747
1 HouseAge 0.121519
2 Latitude -0.943105
3 Longitude -0.900735Vì Scikit-Learn không cung cấp sẵn phương thức summary() như Statsmodels, chúng ta có thể tự trích xuất và trực quan hóa tầm quan trọng của từng đặc trưng bằng các hệ số hồi quy. Đặc trưng có giá trị tuyệt đối của hệ số lớn hơn sẽ tác động mạnh hơn đến biến mục tiêu. Xem đoạn mã sau.
# Sort dataframe by coefficients.
coef_df_sorted = coef_df.sort_values(by="Coefficient", ascending=False)
# Create plot.
plt.figure(figsize=(8,6))
plt.barh(coef_df["Feature"], coef_df_sorted["Coefficient"], color="blue")
plt.xlabel("Coefficient Value")
plt.ylabel("Feature")
plt.title("Feature Importance (Linear Regression Coefficients)")
plt.show()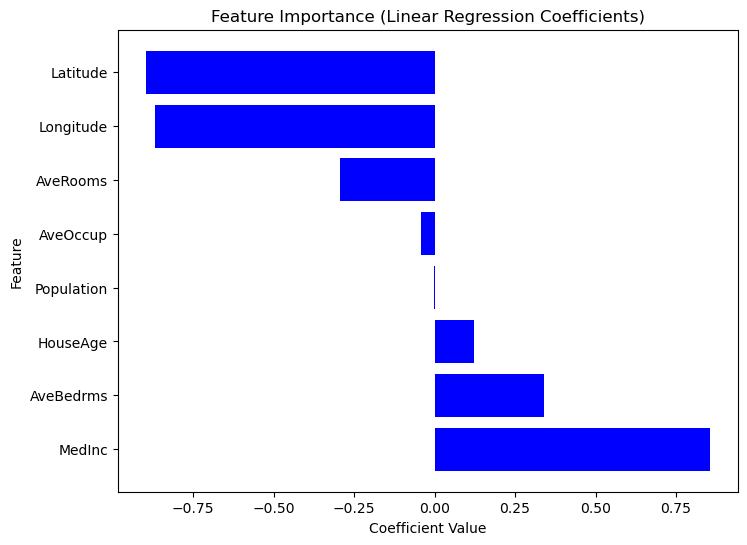
Biểu đồ Tầm quan trọng của Đặc trưng Dựa trên Giá trị Hệ số
Giờ hãy trực quan hóa phần dư và đường hồi quy phù hợp.
# Compute residuals.
residuals = y_test - y_pred
# Create plots.
plt.figure(figsize=(12,5))
# Plot 1: Residuals Distribution.
plt.subplot(1,2,1)
sns.histplot(residuals, bins=30, kde=True, color="blue")
plt.axvline(x=0, color='red', linestyle='--')
plt.title("Residuals Distribution")
plt.xlabel("Residuals (y_actual - y_predicted)")
plt.ylabel("Frequency")
# Plot 2: Regression Fit (Actual vs Predicted).
plt.subplot(1,2,2)
sns.scatterplot(x=y_test, y=y_pred, alpha=0.5)
plt.plot([min(y_test), max(y_test)], [min(y_test), max(y_test)], color='red', linestyle='--') # Perfect fit line
plt.title("Regression Fit: Actual vs Predicted")
plt.xlabel("Actual Prices (in $100,000s)")
plt.ylabel("Predicted Prices (in $100,000s)")
# Show plots.
plt.tight_layout()
plt.show()
Biểu đồ trực quan hóa Phần dư và Độ khớp Hồi quy
Phân phối phần dư (biểu đồ bên trái) nên được tập trung quanh 0, cho thấy sai số phân bố ngẫu nhiên. Nếu phần dư tuân theo phân phối chuẩn, mô hình khớp tốt; còn nếu có độ lệch hoặc xu hướng, có thể gợi ý lỗi hệ thống. Độ khớp hồi quy (biểu đồ bên phải) so sánh giá trị thực so với giá trị dự đoán, với đường nét đứt màu đỏ biểu diễn đường khớp hoàn hảo. Nếu các điểm bám sát đường này, dự đoán là chính xác; nhưng nếu xuất hiện một mẫu (ví dụ, đường cong), có thể quan hệ không thật sự tuyến tính.
Những hình ảnh trực quan này giúp chẩn đoán quá khớp hoặc thiếu khớp, hé lộ các mẫu trong phần dư cho thấy mối quan hệ còn thiếu, và cung cấp đánh giá rõ ràng về hiệu quả của mô hình.
Hồi quy tuyến tính được sử dụng rộng rãi trong nhiều ngành cho mục đích dự đoán và ra quyết định. Trong bất động sản, nó ước tính giá nhà dựa trên các yếu tố như diện tích và vị trí.
Bán hàng và marketing dùng để dự báo nhu cầu và tối ưu ngân sách, trong khi y tế áp dụng để đánh giá nguy cơ bệnh tật. Trong tài chính, nó hỗ trợ dự đoán giá cổ phiếu và chấm điểm tín dụng, còn trong sản xuất, nó giúp kiểm soát chất lượng và dự đoán hỏng hóc.
Hồi quy tuyến tính vẫn là một trong những kỹ thuật cơ bản và được sử dụng rộng rãi nhất trong học máy và mô hình thống kê. Dù đơn giản, nó là công cụ mạnh mẽ để hiểu mối quan hệ giữa các biến và đưa ra dự đoán trong nhiều ứng dụng thực tế.
Dưới đây là những điểm chính rút ra từ hướng dẫn:
Để tìm hiểu thêm về nội suy chuỗi trong Python, hãy xem các tài nguyên của DataCamp.
Các khóa học hàng đầu của DataCamp
Tracks
Courses
Courses
blogs
Matt Crabtree
10 phút