
Leerpad
Associate Data Scientist in Python
90 Hr
Lineaire regressie is een fundamentele techniek in statistiek en machine learning om de relatie tussen variabelen te modelleren. Simpel gezegd stelt het ons in staat een uitkomst te voorspellen op basis van één of meer beïnvloedende factoren. Het wordt veel toegepast bij vastgoedprijzen, verkoopprognoses, risicobeoordeling en in vele andere domeinen.
In deze tutorial verkennen we lineaire regressie in scikit-learn: hoe het werkt, waarom het nuttig is en hoe je het implementeert met scikit-learn. Aan het einde kun je een lineair regressiemodel bouwen en evalueren om datagedreven voorspellingen te doen.
Spreidingsdiagram van huizenprijs versus aantal kamers
Naast de directe toepasbaarheid voor het bepalen van huizenprijzen speelt lineaire regressie een belangrijke rol in machine learning.
Ondanks de eenvoud blijft lineaire regressie onmisbaar in machine learning dankzij de efficiëntie, interpreteerbaarheid en veelzijdigheid.
Met de scikit-learn-bibliotheek is lineaire regressie eenvoudig te implementeren. Deze bibliotheek heeft veel voordelen.
model.fit(X_train, y_train).Ben je nieuw met scikit-learn? Bekijk dan onze cursus Machine learning met scikit-learn voor een praktische introductie tot de Python-bibliotheek.
Zoals we hebben gezien, wordt bij simpele lineaire regressie de data gemodelleerd met een "best fit-lijn". De formule voor deze lijn is:
![]()
waarbij m de helling is en b het intercept.
"Meervoudige lineaire regressie" generaliseert het geval van één voorspeller naar meerdere voorspellers (aantal kamers, nabijheid van de oceaan, mediaan inkomen van de buurt). De formule wordt gegeneraliseerd naar:
![]()
waarbij elk xi een onafhankelijke variabele is en de bijbehorende bi de coëfficiënt. In drie dimensies wordt de lijn een vlak. In hogere dimensies wordt dat vlak een "hypervlak".
Hoe interpreteren we de coëfficiënten en het intercept? Het intercept is de voorspelde waarde van y wanneer alle onafhankelijke variabelen 0 zijn; met andere woorden: de basiswaarde van de afhankelijke variabele zonder bijdrage van de voorspellers. Elke coëfficiënt bi vertegenwoordigt de verandering in de afhankelijke variabele y bij een toename van één eenheid in xi, terwijl alle andere onafhankelijke variabelen constant blijven.
Scikit-learn installeren is eenvoudig. Gebruik gewoon het commando pip install scikit-learn. Wil je een specifieke versie installeren, bijvoorbeeld 1.2.2, voeg dan de versie toe: pip install scikit-learn==1.2.2. Gebruik je Anaconda, dan zou scikit-learn al geïnstalleerd moeten zijn. Moet je het toch nog installeren met de Anaconda-distributie, gebruik dan conda install scikit-learn.
Verschillende bibliotheken zijn nodig of aan te raden bij gebruik van scikit-learn. De numpy-bibliotheek is nodig voor het opslaan van features en labels. De pandas-bibliotheek wordt aanbevolen voor het laden, preprocessen en verkennen van datasets.
Als je met scikit-learn werkt, gebruik je waarschijnlijk al pandas voor je datapreparatie. Voor het plotten van resultaten gebruik je meestal matplotlib of seaborn of beide. Al deze bibliotheken kun je installeren met pip install, vergelijkbaar met het voorbeeld hierboven. Je kunt zelfs meerdere bibliotheken in één keer installeren:
pip install scikit-learn numpy pandas matplotlib seaborn.
Voordat we de dataset laden, importeren we de usual suspects.
# Import libraries.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as snsLaten we de bekende California housing-dataset gebruiken.
# Read in California housing dataset.
from sklearn.datasets import fetch_california_housing
housing = fetch_california_housing()Laten we de data splitsen in trainings- en testsets. We importeren de methode train_test_split() uit sklearn.model_selection, roepen die aan met een testsetpercentage en een random_state. We gebruiken ook simpele lineaire regressie, met de feature die hoort bij het gemiddelde aantal kamers.
# Import train_test_split.
from sklearn.model_selection import train_test_split
# Create features X and target y.
X = pd.DataFrame(housing.data, columns=housing.feature_names)[["AveRooms"]]
y = housing.target # Median house value in $100,000s
# Split the dataset into training (80%) and testing (20%) sets.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)Nu we de data in test- en trainsets hebben gesplitst, gaan we de features standaardiseren. Dit zorgt ervoor dat alle variabelen op dezelfde schaal staan, wat de modelprestatie en numerieke stabiliteit kan verbeteren.
# Import StandardScaler.
from sklearn.preprocessing import StandardScaler
# Instantiate StandardScaler.
scaler = StandardScaler()
# Fit and transform training data.
X_train_scaled = scaler.fit_transform(X_train)
# Also transform test data.
X_test_scaled = scaler.transform(X_test)In deze code is StandardScaler een preprocessing-tool die het gemiddelde verwijdert en features schaalt naar een variantie van 1. Dit voorkomt dat bepaalde features het model domineren door verschillen in schaal.
De scaler wordt op de trainingsdata gefit met fit_transform(). De testdata wordt vervolgens apart getransformeerd met transform(), zodat dezelfde factoren worden gebruikt als bij de trainingsdata en datalek wordt voorkomen.
Om een lineair regressiemodel te maken, importeer je LinearRegression() uit sklearn.linear_model. Roep het aan en wijs het toe aan een variabele.
# Import LinearRegression.
from sklearn.linear_model import LinearRegression
# Instantiate linear regression model.
model = LinearRegression()Het model fitten met trainingsdata is rechttoe rechtaan.
# Fit the model to the training data.
model.fit(X_train_scaled, y_train)Nu we ons model hebben getraind, maken we voorspellingen op de testset.
# Make predictions on the testing data.
y_pred = model.predict(X_test_scaled)Nu we voorspellingen op de testset hebben gedaan, willen we weten hoe goed die overeenkomen met de werkelijkheid. Er zijn verschillende metrics om de prestatie van een regressie-algoritme te evalueren. Enkele van de meest gebruikte zijn de determinatiecoëfficiënt (R2), mean squared error (MSE) en root mean squared error (RMSE).
De determinatiecoëfficiënt, aangeduid als R2, meet hoe goed een regressiemodel de variabiliteit van de doelvariabele verklaart. Met andere woorden: het kwantificeert hoeveel van de variatie in de doelvariabele wordt verklaard door de voorspellers, oftewel de goodness of fit.
Om dit beter te begrijpen, bekijken we de formule:
![]()
waarbij yactual de werkelijke waarden van de doelvariabele zijn, ypredicted de voorspelde waarden van het model, en ȳ het gemiddelde van de werkelijke waarden. Deze formule laat zien hoeveel variantie in de doelvariabele door het model wordt verklaard. De noemer stelt de totale variantie in de data voor, terwijl de teller de onverklaarde variantie na toepassing van het regressiemodel weergeeft. De verhouding geeft dus het percentage verklaarde variantie door het model.
Hoe interpreteren we R2?
Een paar belangrijke aandachtspunten.
De modelprestatie evalueren met de determinatiecoëfficiënt is eenvoudig met scikit-learn.
# Import metrics.
from sklearn.metrics import mean_squared_error, r2_score
# Calculate and print R^2 score.
r2 = r2_score(y_test, y_pred)
print(f"R-squared: {r2:.4f}")R-squared: 0.0138Andere veelgebruikte metrics zijn de mean squared error (MSE) en de root mean squared error (RMSE). Deze metrics meten hoe ver de voorspellingen van een model afwijken van de werkelijke waarden.
MSE berekent het gemiddelde van de kwadratische verschillen tussen werkelijke en voorspelde waarden:
voor het totale aantal observaties n. Omdat de fouten worden gekwadrateerd voordat ze gemiddeld worden, worden grotere fouten zwaarder bestraft dan kleinere; daardoor is MSE gevoelig voor uitschieters. Een lagere MSE duidt op een betere modellering.
Om dit te adresseren wordt RMSE gebruikt, simpelweg de vierkantswortel van MSE. Omdat RMSE in dezelfde eenheid staat als de doelvariabele, is het een beter te interpreteren maat voor hoe ver voorspellingen gemiddeld naast zitten.
MSE en RMSE berekenen is eenvoudig met scikit-learn.
# Calculate and print MSE.
mse = mean_squared_error(y_test, y_pred)
print(f"Mean squared error: {mse:.4f}")
# Calculate and print RMSE.
rmse = mse ** 0.5
print(f"Root mean squared error: {rmse:.4f}")Mean squared error: 1.2923
Root mean squared error: 1.1368Laten we het model opnieuw draaien met al onze beschikbare features, niet alleen het gemiddelde aantal kamers. Verwacht je betere of slechtere resultaten?
# Uses all features.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# Load data set.
housing = fetch_california_housing()
# Split into X, y.
X = pd.DataFrame(housing.data, columns=housing.feature_names)
y = housing.target # Median house value in $100,000s
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Scale the data.
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Create model and fit it to the training data.
model = LinearRegression()
model.fit(X_train_scaled, y_train)
# Make predictions.
y_pred = model.predict(X_test_scaled)
# Calculate and print errors.
r2 = r2_score(y_test, y_pred)
print(f"R-squared: {r2:.4f}")
mse = mean_squared_error(y_test, y_pred)
print(f"Mean squared error: {mse:.4f}")
rmse = mse ** 0.5
print(f"Root mean squared error: {rmse:.4f}")R-squared: 0.5758
Mean squared error: 0.5559
Root mean squared error: 0.7456We zien dat de resultaten flink beter zijn dan met slechts één feature. Dit roept echter de vraag op of we alle features nodig hebben. Zijn sommige features relevanter dan andere? Het kiezen van de meest relevante features uit de dataset heet featureselectie.
Featureselectie is om meerdere redenen belangrijk.
Als meerdere features sterk gecorreleerd zijn, zijn ze redundant: ze geven het model in wezen dezelfde informatie. Deze situatie heet multicollineariteit. Hoewel multicollineariteit niet altijd de nauwkeurigheid van voorspellende modellen beïnvloedt, bemoeilijkt het featureselectie en interpretatie, vooral bij lineaire regressie en aanverwante modellen.
De Variance Inflation Factor (VIF) is een maatstaf om multicollineariteit tussen voorspellers op te sporen. Voor elke voorspeller wordt de VIF berekend als:
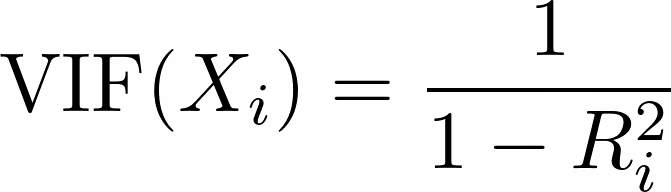
waarbij Ri2 de R2-waarde is die je krijgt wanneer voorspeller Xi wordt geregressieerd op alle andere voorspellers in het model. Een hogere VIF betekent dat de voorspeller sterk gecorreleerd is met andere variabelen.
# Import libraries.
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_california_housing
from statsmodels.stats.outliers_influence import variance_inflation_factor
# Load the dataset.
housing = fetch_california_housing()
X = pd.DataFrame(housing.data, columns=housing.feature_names)
# Compute the correlation matrix.
corr_matrix = X.corr()
# Identify pairs of features with high collinearity (correlation > 0.8 or < -0.8).
high_corr_features = [(col1, col2, corr_matrix.loc[col1, col2])
for col1 in corr_matrix.columns
for col2 in corr_matrix.columns
if col1 != col2 and abs(corr_matrix.loc[col1, col2]) > 0.8]
# Convert to a DataFrame for better visualization.
collinearity_df = pd.DataFrame(high_corr_features, columns=["Feature 1", "Feature 2", "Correlation"])
print("\nHighly Correlated Features:\n", collinearity_df)
# Compute Variance Inflation Factor (VIF) for each feature.
vif_data = pd.DataFrame()
vif_data["Feature"] = X.columns
vif_data["VIF"] = [variance_inflation_factor(X.values, i) for i in range(X.shape[1])]
# Print VIF values.
print("\nVariance Inflation Factor (VIF) for each feature:\n", vif_data) Highly Correlated Features:
Feature 1 Feature 2 Correlation
0 AveRooms AveBedrms 0.847621
1 AveBedrms AveRooms 0.847621
2 Latitude Longitude -0.924664
3 Longitude Latitude -0.924664
Variance Inflation Factor (VIF) for each feature:
Feature VIF
0 MedInc 11.511140
1 HouseAge 7.195917
2 AveRooms 45.993601
3 AveBedrms 43.590314
4 Population 2.935745
5 AveOccup 1.095243
6 Latitude 559.874071
7 Longitude 633.711654Laten we AveBedrms uit het model verwijderen.
# Import libraries.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# Load California housing dataset.
housing = fetch_california_housing()
# Create DataFrame and remove "AveBedrms" feature.
X = pd.DataFrame(housing.data, columns=housing.feature_names).drop(columns=["AveBedrms"])
y = housing.target # Median house value in $100,000s
# Split data into training and testing sets.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Scale the data (Standardization).
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Create a linear regression model and train it.
model = LinearRegression()
model.fit(X_train_scaled, y_train)
# Make predictions on the test set.
y_pred = model.predict(X_test_scaled)
# Calculate performance metrics.
r2 = r2_score(y_test, y_pred)
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
# Print evaluation metrics
print(f"R-squared: {r2:.4f}")
print(f"Mean squared error: {mse:.4f}")
print(f"Root mean squared error: {rmse:.4f}")R-squared: 0.5823
Mean squared error: 0.5473
Root mean squared error: 0.7398De resultaten zijn (marginaal) verbeterd.
Een regressiemodel bouwen is pas de eerste stap; het begrijpen van de uitkomsten is net zo belangrijk. Door de coëfficiënten te analyseren, ontdekken we welke features de grootste invloed hebben op de voorspellingen.
Zodra een lineair regressiemodel is getraind, zijn de coëfficiënten toegankelijk via model.coef_. Het intercept is beschikbaar via model.intercept_.
Zodra een lineair regressiemodel is getraind met LinearRegression(), zijn de coëfficiënten toegankelijk via model.coef_ en het intercept via model.intercept_.
print("Intercept:", model.intercept_)
coeff_df = pd.DataFrame({"Feature": X.columns, "Coefficient": model.coef_})
print("\nFeature Coefficients:\n", coeff_df) Intercept: 2.0719469373788777
Feature Coefficients:
Feature Coefficient
0 MedInc 0.725747
1 HouseAge 0.121519
2 Latitude -0.943105
3 Longitude -0.900735Omdat Scikit-Learn geen ingebouwde methode summary() biedt zoals Statsmodels, kunnen we handmatig het belang van elke feature extraheren en visualiseren met regressiecoëfficiënten. Features met grotere absolute coëfficiënten hebben een sterkere impact op de doelvariabele. Bekijk de volgende code.
# Sort dataframe by coefficients.
coef_df_sorted = coef_df.sort_values(by="Coefficient", ascending=False)
# Create plot.
plt.figure(figsize=(8,6))
plt.barh(coef_df["Feature"], coef_df_sorted["Coefficient"], color="blue")
plt.xlabel("Coefficient Value")
plt.ylabel("Feature")
plt.title("Feature Importance (Linear Regression Coefficients)")
plt.show()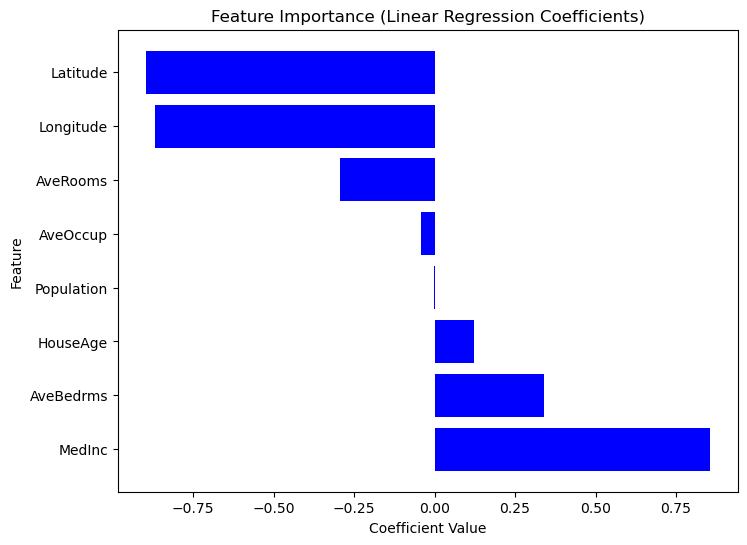
Grafiek van featurebelang op basis van coëfficiëntwaarden
Laten we nu de residuen en de regressiefit visualiseren.
# Compute residuals.
residuals = y_test - y_pred
# Create plots.
plt.figure(figsize=(12,5))
# Plot 1: Residuals Distribution.
plt.subplot(1,2,1)
sns.histplot(residuals, bins=30, kde=True, color="blue")
plt.axvline(x=0, color='red', linestyle='--')
plt.title("Residuals Distribution")
plt.xlabel("Residuals (y_actual - y_predicted)")
plt.ylabel("Frequency")
# Plot 2: Regression Fit (Actual vs Predicted).
plt.subplot(1,2,2)
sns.scatterplot(x=y_test, y=y_pred, alpha=0.5)
plt.plot([min(y_test), max(y_test)], [min(y_test), max(y_test)], color='red', linestyle='--') # Perfect fit line
plt.title("Regression Fit: Actual vs Predicted")
plt.xlabel("Actual Prices (in $100,000s)")
plt.ylabel("Predicted Prices (in $100,000s)")
# Show plots.
plt.tight_layout()
plt.show()
Plots om residuen en regressiefit te visualiseren
De residuenverdeling (linkerplot) zou rond nul gecentreerd moeten zijn, wat aangeeft dat fouten willekeurig verdeeld zijn. Als de residuen een normale verdeling volgen, past het model goed; bij scheefheid of een patroon kan dat wijzen op systematische fouten. De regressiefit (rechterplot) vergelijkt werkelijke met voorspelde waarden; de rode stippellijn stelt een perfecte fit voor. Als punten dicht bij de lijn liggen, zijn voorspellingen accuraat; verschijnt er een patroon (bijv. een kromme), dan is de relatie mogelijk niet echt lineair.
Deze visualisaties helpen over- of underfitting te signaleren, patronen in residuen te onthullen die op ontbrekende relaties duiden, en geven een helder beeld van de effectiviteit van het model.
Lineaire regressie wordt in veel sectoren ingezet voor voorspelling en besluitvorming. In vastgoed schat het huizenprijzen op basis van factoren zoals grootte en locatie.
Sales en marketing gebruiken het voor vraagvoorspelling en budgetoptimalisatie, terwijl de zorg het toepast voor risicobeoordeling van ziekten. In finance helpt het bij aandelenkoersvoorspellingen en kredietbeoordeling, en in de industrie bij kwaliteitscontrole en het voorspellen van uitval.
Lineaire regressie blijft een van de meest fundamentele en breed toegepaste technieken in machine learning en statistische modellering. Ondanks de eenvoud is het een krachtig hulpmiddel om relaties tussen variabelen te begrijpen en voorspellingen te doen in diverse praktijksituaties.
Dit zijn de belangrijkste inzichten uit de tutorial:
Voor meer informatie over Python-stringinterpolatie kun je de resources van DataCamp bekijken.
Topcursussen bij DataCamp
Leerpad
Cursus
Cursus
blog
Adel Nehme
15 min
